一篇文章讲清楚:在单片机上部署AI的整个流程!(TinyML+STM32)
本文介绍了将AI模型部署到单片机的完整流程,主要分为8个步骤:1)数据采集,强调真实性和全面性;2)数据预处理,需保持PC端与MCU端一致性;3)模型设计,需考虑MCU资源限制;4)评估优化,关注模型大小、内存和时延等;5)模型转换,将TensorFlow转为TFLite格式;6)部署模型,使用TensorFlow Lite Micro在MCU运行。重点讲解了数据采集的关键作用、预处理的重要性以及
本公众号的老粉丝比较清楚,我们正在做嵌入式AI的课程,其中最主要的目的是教会大家如何将AI部署到单片机中,让单片机学会思考,可以实现自动推理。
最近文章很久没有更新,是因为小编在忙着录制课程,已经报名课程的同学感觉直播讲课太慢并且还不能快放,所以我们将直播课程改为了“录播+直播答疑”的形式。
今天小编带大家讲清楚整个部署的流程是什么样的!
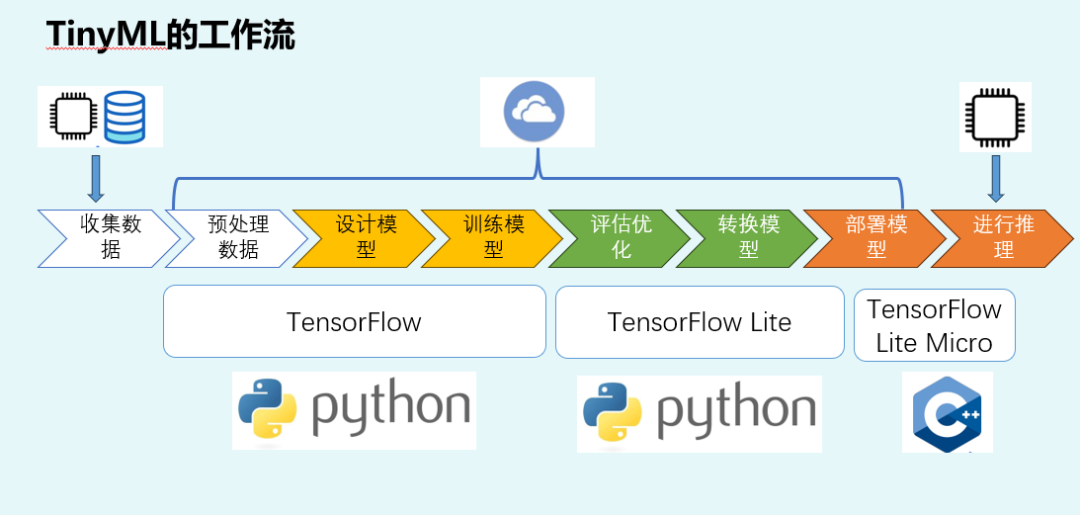
上面这张图是本次课程出场次数比较多的“老演员”。下面本文以上面图为例,讲解清楚整个流程。
从上面流程中可以发现,共分为了8个主要的步骤。其中最上面带着芯片图片的代表相关工作是在单片机或MCU测完成的。即:数据采集和运行推理是在MCU测进行的。其他步骤在云端或者PC端运行。
一:收集数据(数据采集)
收集数据是整个TInyML的第一步,目的是为了进行模型训练。
数据采集是“把物理世界的真实信号,转换为MCU可以识别的数字信号”。比如把环境或者设备的状态转变为温度,把(电机负载的转换为电流、把声音转换为麦克风的信号、把震动或者冲击转换为加速度计或陀螺仪。
再用一句简单的话讲解:其实就是单片机的ADC
虽然看似简单的一句话,但是整个AI模型设计中起到至关重要的一环(我理解为它是最重要的一环,关于如何进行数据采集我还专门整理了一节课进行重点讲解)。因为我们采集数据是为了进行模型训练,当我们用于训练的数据不够准确时,训练出来的模型肯定就是不准确的,最终导致推理出来的效果是不理想的。
数据采集的注意至少包括下面的几点:
1.需要收集与系统相关的数据:
虽然大模型会自动忽略与系统不相关的数据,但我们仍然需要训练与想要设计的系统相关的数据。
举个例子:当我们想要设计一个“震动检测的模型”,但是我们喂给大模型的数据是“食堂的菜单”,那么最终的结果就是:这个数据会被大模型视为无效数据。

2.收集的数据需要接近于真实的应用场景。
除了接近于真实常营,并且应该尽可能的覆盖全部的应用场景。比如温度数据:我们需要弄清楚我们的系统关心的是环境温度还是机器内部的温度?
如果我们要设计的系统比较关心的是环境温度,那么我们采集机器内部(腔体)的温度,就是不完美的。
3.多多益善
如果一个变量会随着温度变化,那么需要尽可能收集整个温度变化范围内的数据。
二、预处理数据
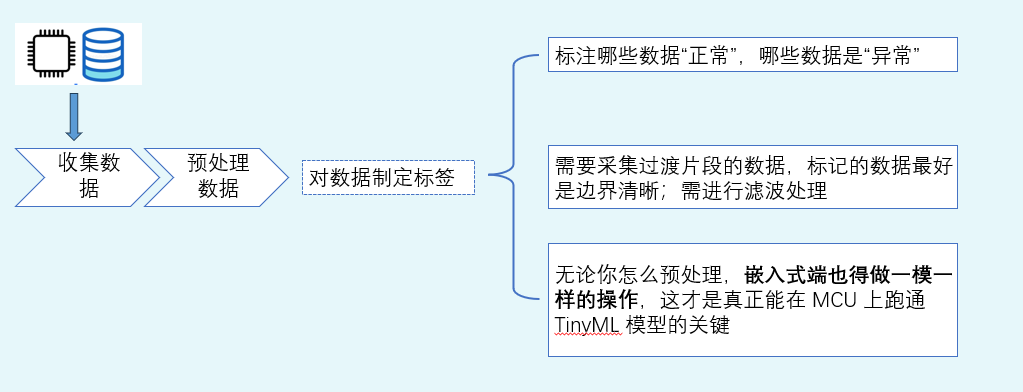
预处理其实就是对数据进行贴标签。标注哪些数据是正常的,哪些数据是异常的。
-
如果我们的任务是分类(比如手势 A/B/C、正常/异常),数据采集时就要明确:哪一段属于哪个类别,类别切换时怎么处理过渡段,“异常”是否拆分子类(不同类型异常)
-
如果任务是回归(比如拟合某个连续值),要明确:输出值怎么取(传感器真值?标定后的真值?),输出值的单位、范围、精度等。
标签规则不清晰,后续训练结果看似能跑,但实际部署会出现大量“推理不准确”的情况。
数据预处理这个步骤,还有一个比较重要的作用是:先把原始信号加工成更适合学习的特征。因为我们如果直接把原始数据丢进模型训练,往往效率不高,模型还会变得很大。
用稍微学术一点的语句举个例子:语音/声音类任务通常不会直接喂原始波形,而是转成谱图或 MFCC;振动类任务也经常会做窗口切分、统计特征或频域特征。
使用嵌入式工程师可以听懂的语言来讲解的话:数据预处理可以理解为“数据的滤波算法”。
在进行数据预处理时,有一个非常重要的原则:我们训练模型时用什么预处理,部署时必须用同一套逻辑。也就是在 PC 端和 MCU 端用同一套公式与流程。
三、设计模型
设计模型以及训练模型是在PC或者云服务器进行的。在咱们的课程中主要是以TensorFlow为框架。

TensorFlow是一个由 Google 开发的开源机器学习框架,用来设计、训练和部署各种神经网络模型;
到了“设计模型”这一环节,很多人容易犯的错是:照着大模型思路堆层数、加通道,结果训练看似不错,但部署发现 MCU 资源不够。
注意事项:
当我们进行模型设计的时候,需要在设计之初,就开始思考目标 MCU 的 Flash/RAM/时延预算等等各种参数。因为最终模型要部署到端侧,并且很可能要量化。
四、评估优化
TinyML 的评估从来不是只看准确率。因为在 MCU 上你还要关心:
-
模型大小是否能放进 Flash、
-
推理过程中 RAM 峰值是否超预算
-
单次推理时延是否满足实时性
-
在噪声与工况变化下是否稳定等等情况。
如果我们已经设计的模型需要进行优化,那么往往需要从
-
结构调整减少层数/通道
-
替换更轻量结构
-
输入优化(降低分辨率、减少特征维度)
-
量化准备:为 int8 推理做准备(端侧最常见)等几个维度来思考量化方向。
我可以把这一环节理解为:模型从“能用”走向“能部署、能长期稳定用”。
五、转换模型
转换模型的目的是把在PC或者云服务器训练出来的模型转换为可以在MCU端运行的推理模型。TinyML 工作流里必经的一步是:把 TensorFlow 模型转换成 TensorFlow Lite(.tflite) 格式。
TensorFlow Lite:在TensorFlow的基础上裁剪出来的一个可以运行在移动设备上的推理模型。它不支持对模型进行训练,仅支持使用之前在平台或者PC上训练过的模型进行推理。

六、部署模型
当目标平台变成 MCU,推理框架也随之切换为 TensorFlow Lite Micro(TFLM)。它的定位很明确:让 .tflite 在没有操作系统、资源有限的 MCU 上运行。

模型部署其实可以理解为:
(1)把 .tflite 模型转换成 C 数组或二进制资源,编进固件,
(2)集成 TFLM 源码(或使用裁剪后的库)
(3)注册需要的算子(模型用到哪些算子就注册哪些)
(4)分配 Tensor Arena(静态内存区,用于中间张量与运行缓冲)
等几个步骤。
在我们的课程中有详细的讲解,我会一步一步的告诉大家怎么把一个.tflite格式的文件转换为C语言数组、怎么下载并移植TFLM的源码。
再次汇总一下,老演员登场:TInyML的流程是下面的几部:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)