别再给AI助理写死记忆规则了:MemSkill让智能体自己学会怎么记
本文提出MemSkill框架,让AI智能体能够自主学习和进化记忆技能,而非依赖预设规则。该系统包含三个核心组件:Controller负责动态选择记忆技能,Executor执行多技能组合操作,Designer通过分析失败案例不断优化技能库。实验表明,在对话、问答和具身任务中,MemSkill均超越现有记忆系统。该研究突破了传统CRUD记忆模式的局限,使智能体能够根据不同场景需求自主发展专业化记忆策略
别再给AI助理写死记忆规则了:MemSkill让智能体自己学会怎么记
你会把"记笔记"这件事写成一套死规则交给秘书吗?当然不会。好秘书的记笔记技能是从实战中磨练出来的,而且会随着工作内容的变化不断进化。MemSkill就是要让LLM智能体也拥有这种能力。
- 论文:MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents
- 链接:https://arxiv.org/abs/2602.02474v1
- 作者:Haozhen Zhang, Quanyu Long, Jianzhu Bao, Tao Feng, Weizhi Zhang, Haodong Yue, Wenya Wang
- 会议:ICML 2026
- 代码:https://github.com/ViktorAxelsen/MemSkill
一句话总结:MemSkill把智能体的记忆操作从4个硬编码的CRUD原语,升级为一个可通过强化学习选择、可通过LLM设计器进化的"技能库",在对话记忆、文档问答和具身任务三类场景中全面超越Mem0、LangMem、MemoryOS等当前最强记忆系统。
📖 先看一个场景:为什么记忆规则写死了不行
假设你搭了一个AI聊天助理,它需要记住用户的偏好、计划、经历。现在主流的做法是给它4条记忆规则:
1. Insert:遇到新信息就插入
2. Update:遇到已有信息的更新就修改
3. Delete:遇到过时信息就删除
4. Skip:没有重要信息就跳过
听起来很完备?来看实际场景:
场景一:用户说"我下周二要去纽约出差,顺便和老同学聚餐"。这句话里有时间、地点、事件、人际关系——是Insert一条综合记录,还是拆成多条?时间和地点要不要单独建索引?
场景二:用户说"算了,纽约不去了,改成波士顿"。这是Update原来的出差记录?还是Delete出差记录再Insert一条新的?聚餐安排还有效吗?
场景三:在ALFWorld这种具身任务中,智能体发现"杯子在柜台上",然后"把杯子拿起来",再"把杯子放到水槽里"。记忆系统需要跟踪的是物体位置的变化链,这和对话记忆完全是两码事——用同样的Insert/Update/Delete规则来处理,效果能好吗?
核心问题:4条固定规则硬编码了人类对"怎么记忆"的假设,但不同场景下的最优记忆策略完全不同。对话场景需要捕捉时间上下文和实体关系,具身任务需要追踪物体状态和动作约束。一套规则打天下,注定做不好。
MemSkill的解法很直接:不写死规则,让智能体从实践中自己学。 初始给4个基础原语作为种子,然后在训练过程中不断进化出新的、领域特定的记忆技能。
🏗️ 架构全景:三个组件构成闭环
MemSkill的设计很克制,只有三个核心组件,但它们构成了一个精巧的闭环。
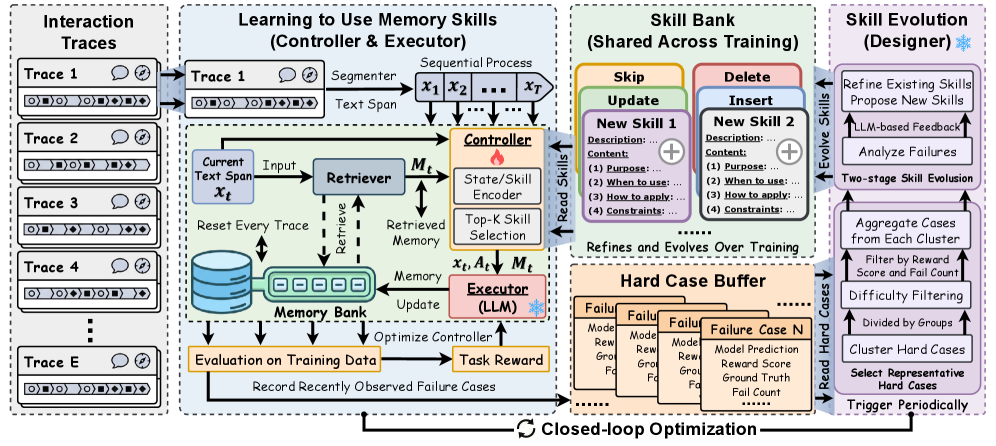
图2:MemSkill全景。给定交互轨迹,Controller从技能库中选择Top-K个技能,Executor根据这些技能生成记忆更新,更新后的记忆用于回答下游任务。任务奖励回传给Controller做策略优化,失败案例进入困难案例缓冲区,Designer定期分析这些案例来进化技能库。
系统维护两个存储:
- Memory Bank:每条交互轨迹独立的记忆库,存储提取出的结构化记忆
- Skill Bank:所有轨迹共享的技能库,初始有4个基础原语(Insert/Update/Delete/Skip),随训练不断扩充
Controller:学会在什么情况下用什么技能
Controller解决的是技能选择问题——面对当前的文本片段和已有记忆,应该调用哪些技能?
技术实现上,它用嵌入模型把"当前状态"和"每个技能的描述"映射到同一个向量空间:
ht=fctx(xt,Mt)(状态嵌入)h_t = f_{\text{ctx}}(x_t, M_t) \quad \text{(状态嵌入)}ht=fctx(xt,Mt)(状态嵌入)
ui=fskill(desc(si))(技能嵌入)u_i = f_{\text{skill}}(\text{desc}(s_i)) \quad \text{(技能嵌入)}ui=fskill(desc(si))(技能嵌入)
然后通过内积计算兼容性分数,再做softmax得到概率分布:
zt,i=ht⊤ui,pθ(i∣ht)=softmax(zt)iz_{t,i} = h_t^\top u_i, \quad p_\theta(i \mid h_t) = \text{softmax}(z_t)_izt,i=ht⊤ui,pθ(i∣ht)=softmax(zt)i
最后用Gumbel-Top-K采样选择K个技能。为什么用Gumbel-Top-K而不是简单的argmax?因为技能库在训练中会动态增长——新技能加入时,Controller需要有探索空间去尝试它们,而不是永远只选老技能。Gumbel采样在保持可微性的同时引入了随机探索。
选出的K个技能构成一个有序集合 At=(at,1,…,at,K)A_t = (a_{t,1}, \dots, a_{t,K})At=(at,1,…,at,K),其联合概率是无放回采样的链式分解:
πθ(At∣st)=∏j=1Kpθ(at,j∣st)1−∑ℓ<jpθ(at,ℓ∣st)\pi_\theta(A_t \mid s_t) = \prod_{j=1}^K \frac{p_\theta(a_{t,j} \mid s_t)}{1 - \sum_{\ell < j} p_\theta(a_{t,\ell} \mid s_t)}πθ(At∣st)=j=1∏K1−∑ℓ<jpθ(at,ℓ∣st)pθ(at,j∣st)
这个设计有个好处:自动适应技能库大小的变化。不管技能库从4个扩展到14个还是24个,Controller的参数不需要改动,只是softmax的候选集变大了。
训练方式:PPO强化学习。奖励信号来自下游任务表现(如问答的F1分数、具身任务的成功率)。这里的关键insight是——记忆操作的好坏无法即时判断,必须等到记忆被实际使用后才能知道。这种延迟奖励的特性天然适合RL。
裁剪目标函数:
Lpolicy(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]\mathcal{L}_{\text{policy}}(\theta) = \mathbb{E}_t \left[ \min \left( r_t(\theta) \hat{A}_t, \text{clip}(r_t(\theta), 1-\epsilon, 1+\epsilon) \hat{A}_t \right) \right]Lpolicy(θ)=Et[min(rt(θ)A^t,clip(rt(θ),1−ϵ,1+ϵ)A^t)]
Executor:一次调用完成多技能组合
Executor是一个固定的LLM(不参与训练),接收三个输入:
- 当前文本片段 xtx_txt
- 检索到的相关记忆 MtM_tMt
- Controller选定的技能集 AtA_tAt
输出是结构化的记忆更新指令(INSERT/UPDATE/DELETE动作块)。
关键设计:Executor在一次LLM调用中完成所有技能的组合执行。传统方法(如Mem0)在每一轮对话中都要单独调用LLM判断该用哪个操作,处理长历史时需要大量的LLM调用。MemSkill把多个技能打包在一个prompt里,让LLM一次性输出所有记忆操作。
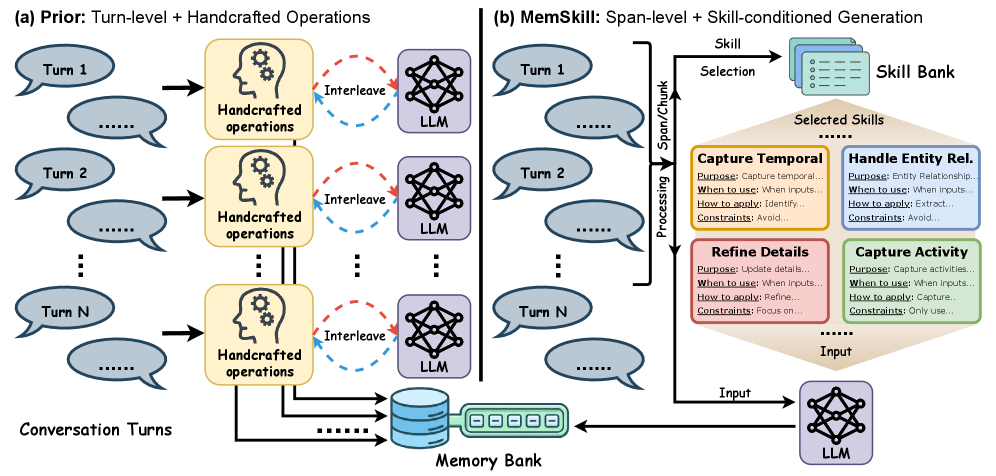
图1:左侧是传统方法,每轮对话都要LLM独立判断使用哪个操作。右侧是MemSkill,把一个文本跨度和多个技能打包输入,一次生成完整的记忆更新。效率差距在长对话中尤为明显。
Designer:从失败案例中进化技能库
Designer是MemSkill区别于所有已有方法的核心创新。它不是一个训练中的模块,而是一个定期运行的LLM分析流程。
Step 1:收集困难案例
维护一个滑动窗口缓冲区,记录训练中失败率高的案例。每个案例有一个难度分数:
d(q)=(1−r(q))⋅c(q)d(q) = (1 - r(q)) \cdot c(q)d(q)=(1−r(q))⋅c(q)
r(q)r(q)r(q) 是任务奖励,c(q)c(q)c(q) 是该案例的累积失败次数。这个设计很聪明——不是随机选失败案例,而是优先关注反复失败的案例,这些才是技能库真正覆盖不了的"盲区"。
Step 2:聚类选代表
对困难案例做embedding聚类,从每个簇中选代表性案例。这样Designer看到的不是一堆重复的相似失败,而是不同类型的问题。
Step 3:两阶段分析
用LLM做两轮分析:
-
诊断阶段:分析每个失败案例是存储失败(该记的没记)、检索失败(记了但没找到)还是记忆质量失败(记了但记得不对)。输出JSON格式的诊断报告。
-
处方阶段:基于诊断结果,提出具体的技能改进——修改现有技能的描述/触发条件,或者提出全新的技能。
Step 4:回滚保护
如果新技能导致验证集性能下降,系统自动回滚到之前最佳版本的技能库。这个安全机制保证了技能进化不会"越改越差"。
探索激励:新技能加入后,Controller可能还是倾向于选老技能(因为老技能已经在训练中积累了高概率)。为了给新技能试用机会,设计了一个探索机制——如果新技能被选中的概率总和低于阈值 τt\tau_tτt,就给它们加一个logit增益 δt\delta_tδt:
∑i∈Snewpθ(i∣st)≥τt\sum_{i \in \mathcal{S}_{\text{new}}} p_\theta(i \mid s_t) \ge \tau_ti∈Snew∑pθ(i∣st)≥τt
这像是给新员工一个"试用期保护"——即使一开始表现不如老员工,也给他们展示能力的机会。
🔬 技能到底长什么样?
说了半天"技能",它具体是什么?每个技能是一段结构化文本,包含描述(用于Controller检索)和内容(用于指导Executor执行)。
初始原语技能
| 技能 | 描述 | 内容要点 |
|---|---|---|
| INSERT | 捕获新的持久性事实 | 仅在信息稳定且后续可能有用时插入 |
| UPDATE | 修订已有记忆项 | 当文本提供更正或新细节时使用 |
| DELETE | 删除不正确/过时/被取代的记忆 | 仅在有确凿证据时删除 |
| SKIP | 确认无需更改 | 当文本不包含记忆相关的新信息时使用 |
LoCoMo(对话场景)进化出的技能
通过Designer分析对话中的失败案例,进化出了这些技能:
-
CAPTURE_TEMPORAL_CONTEXT:当提到特定事件或活动及其时间信息时,识别时间要素(开始、结束、时长、顺序),记录完整的时间上下文。约束:只关注明确提到的时间信息,不做推断。
-
CAPTURE_ACTIVITY_DETAILS:当提到活动、事件或参与活动的计划时,记录活动的类型、地点、参与者、时间等细节。
-
CAPTURE_ENTITY_NUANCES:当提到实体的昵称、别名、比较性陈述时,捕获这些细微差别,避免后续问答中混淆。
-
HANDLE_ENTITY_RELATIONSHIPS:管理实体间的复杂关系网络。
ALFWorld(具身任务)进化出的技能
具身任务的需求完全不同,进化出的技能也截然不同:
-
CAPTURE_ACTION_CONSTRAINTS:捕获动作的详细约束,包括物体状态和移动限制。比如"必须先打开冰箱门才能把食物放进去"。
-
TRACK_OBJECT_LOCATION:显式跟踪完成任务所需物体的位置和状态。比如"鸡蛋从柜台→手中→微波炉"的位置变化链。
-
TRACK_OBJECT_MOVEMENTS:跟踪物体的移动轨迹和当前状态。
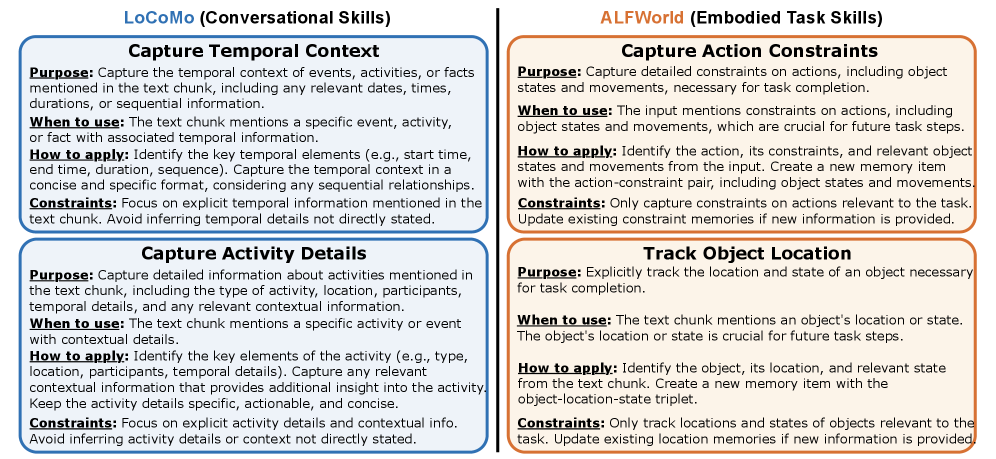
图4:左侧是LoCoMo对话场景进化出的技能,侧重时间上下文和实体关系;右侧是ALFWorld具身场景进化出的技能,侧重动作约束和物体追踪。两个领域的技能完全不同,说明Designer确实在根据任务特性定制记忆策略。
这种领域特异性正是MemSkill的核心价值——不是人类预设"对话场景需要什么技能",而是系统从失败中自己发现的。
🧪 实验:四个数据集的全面验证
实验设置
数据集:
- LoCoMo:长对话记忆基准,测试多轮对话中的信息提取和问答
- LongMemEval:长期交互记忆评估,跨会话记忆能力
- HotpotQA:多跳文档问答,测试记忆在知识密集型任务中的表现
- ALFWorld:文本具身任务(ALF-Seen和ALF-Unseen两个分割)
基线:No-Memory、Chain-of-Notes(CoN)、ReadAgent、MemoryBank、A-MEM、Mem0、LangMem、MemoryOS
基础模型:LLaMA-3.3-70B-Instruct(训练主力)、Qwen3-Next-80B-A3B-Instruct(迁移测试)
评估指标:LLM-Judge分数(L-J)、F1分数、成功率(SR)、平均步数(#Steps)
主实验结果
| 模型 | LoCoMo L-J | LongMemEval L-J | ALF-Seen SR | ALF-Unseen SR |
|---|---|---|---|---|
| LLaMA 3.3 基线 | ||||
| No-Memory | — | — | 17.14 | 20.15 |
| MemoryBank | 39.94 | 43.86 | 16.43 | 20.90 |
| A-MEM | 37.49 | 38.31 | 12.14 | 17.91 |
| Mem0 | 39.22 | 43.41 | 15.00 | 20.90 |
| LangMem | 41.04 | 43.25 | 14.29 | 14.93 |
| MemoryOS | 44.59 | 40.55 | 15.71 | 14.18 |
| MemSkill | 50.96 | 55.19 | 47.86 | 47.01 |
| Qwen 3 基线 | ||||
| No-Memory | — | — | 18.57 | 26.12 |
| MemoryOS | 44.59 | 40.30 | 19.29 | 18.66 |
| MemSkill | 52.07 | 55.99 | 60.00 | 64.18 |
几个值得关注的数字:
LoCoMo上MemSkill(50.96)比MemoryOS(44.59)高了6.37分。MemoryOS是2025年提出的记忆系统,已经集成了比较完善的记忆管理策略。MemSkill在其基础上的提升幅度很可观。
ALFWorld上的提升更加戏剧性。MemSkill在ALF-Seen上从MemoryOS的15.71%提升到47.86%——翻了3倍。这说明具身任务对记忆策略的领域适配性要求极高,通用的记忆规则在这个场景下几乎失效。
Qwen模型的表现更好。在ALFWorld上,Qwen版本的MemSkill达到了60.00%和64.18%的成功率,比LLaMA版本还高。但注意:这里的技能库是用LLaMA训练的,然后直接迁移到Qwen——技能的跨模型迁移能力得到了验证。
消融实验
在LoCoMo上的消融结果:
| 变体 | LLaMA L-J | Qwen L-J |
|---|---|---|
| MemSkill(完整版) | 50.96 | 52.07 |
| w/o Controller(随机选技能) | 45.86 | 41.24 |
| w/o Designer(静态技能库) | 44.11 | 34.71 |
| Refine-only(只优化不加新技能) | 44.90 | 46.97 |
三个关键发现:
Designer是最重要的组件。去掉Designer后,LLaMA上下降6.85分,Qwen上下降17.36分。这直接说明:静态技能库即使有Controller做智能选择,也远不如一个会进化的技能库。
Controller也不可少。随机选择技能比有策略地选择差了5.10分(LLaMA),说明"选什么技能"和"有什么技能"同样重要。
添加新技能比只优化旧技能更有效。Refine-only变体只允许Designer修改现有技能,不允许提出新技能。它比完整版差6.06分(LLaMA),但比静态版好0.79分。这说明:优化现有技能有帮助,但发现全新的技能模式更关键。
分布外泛化:从对话迁移到文档问答
这个实验很有说服力。在LoCoMo(对话场景)上训练好的技能库,不做任何修改,直接应用到HotpotQA(文档级多跳问答)。
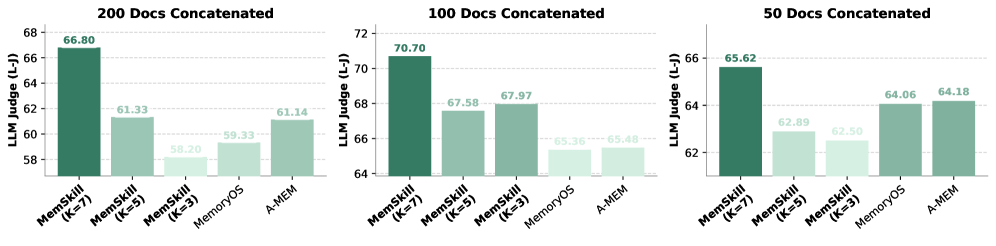
图3:横轴是拼接文档数量(50/100/200篇),纵轴是LLM-Judge分数。MemSkill在所有设置下都优于MemoryOS和A-MEM。随着文档数量增加(上下文变长),MemSkill的优势越来越明显。K=7(选7个技能)在200篇文档时表现最佳。
关键发现:
-
文档越多,MemSkill优势越大。200篇文档拼接时,MemSkill-K7的分数显著高于基线。这说明MemSkill学到的技能在处理长上下文时特别有价值——不只是"记什么",还包含了"如何在大量信息中高效提取关键内容"的策略。
-
技能数量K的影响。在短上下文(50篇)时,K=3和K=7差别不大;在长上下文(200篇)时,K=7明显更好。这合理——上下文越复杂,需要同时应用的技能种类越多。
-
泛化的本质。为什么在对话上训练的技能能迁移到文档问答?因为MemSkill学到的技能不是绑定到"对话"这个表面形式的——“捕获时间上下文”、"追踪实体关系"这些能力在文档问答中同样适用。
🧠 深入技术细节
为什么用PPO而不是其他RL算法?
Controller的技能选择是一个组合优化问题:从N个技能中选K个(有序)。这个动作空间不是连续的,且组合数 (NK)⋅K!\binom{N}{K} \cdot K!(KN)⋅K! 可能很大。
PPO的优势在于:
- 延迟奖励的处理:记忆操作的好坏要等到后续问答时才知道,PPO的advantage估计能有效处理这种信用分配问题
- 策略稳定性:clip机制防止每次更新跨度过大,对于动态变化的技能库来说很重要
- 离散动作空间:PPO天然支持离散动作,配合Gumbel-Top-K采样可以处理变长的候选集
Span-level vs Turn-level记忆提取
传统方法是turn-level——每轮对话处理一次记忆更新。MemSkill采用span-level——把多轮对话打包成一个文本跨度(span),一次性处理。
为什么span-level更好?
- 效率:一个100轮的对话,turn-level需要100次LLM调用;span-level可能只需要10次(10个span)
- 上下文完整性:跨多轮的信息(如"他上次说过…后来又说…")在span内可以被完整看到
- 技能组合的灵活性:一个span内可能同时需要Insert新信息、Update旧记录、Delete过时条目——多个技能在一次调用中协同工作
记忆检索机制
论文没有在记忆检索上做特别的创新(这不是MemSkill的重点),使用的是标准的语义相似度检索:给定当前文本,从Memory Bank中检索Top-R个最相关的记忆项。但技能对检索结果的利用方式是创新的——比如"HANDLE_ENTITY_RELATIONSHIPS"技能会指导Executor关注检索到的记忆中的实体关系网络,而"TRACK_OBJECT_LOCATION"技能会指导Executor关注物体位置的变化链。
💡 批判性思考
这篇论文做对了什么
1. 找准了问题的本质
记忆系统的瓶颈不在检索,而在"记什么、怎么记"。MemSkill把这个问题从人工设计转化为可学习的,方向完全正确。已有的Mem0、LangMem在检索和存储效率上做了很多优化,但记忆操作本身还是写死的——MemSkill是第一个把记忆操作本身变成可学习对象的工作。
2. 闭环设计很优雅
Controller学技能选择 → Executor生成记忆 → 下游任务评估 → 奖励回传Controller → 失败案例进入Designer → Designer进化技能库 → 新技能进入Controller的候选集。整个闭环中没有多余的模块,每个组件都有明确的职责。
3. 实验设计覆盖面广
四个数据集覆盖了对话、文档问答、具身任务三个大类;跨模型迁移(LLaMA→Qwen)和跨任务迁移(对话→文档QA)验证了泛化性;消融实验逐一验证了每个组件的贡献。
需要注意的问题
1. Designer的成本和稳定性
Designer需要调用LLM分析失败案例并生成新技能——这个过程本身就是有噪声的。LLM可能把问题诊断错(比如明明是检索失败,诊断为存储失败),也可能提出质量低的新技能。论文有回滚机制保底,但在大规模部署时,Designer的分析质量会直接影响系统的进化方向。
2. 技能库膨胀的隐忧
从4个初始技能增长到十几个,这是可控的。但论文没有讨论技能库的上限管理——如果训练足够久、场景足够多样,技能库会不会膨胀到上百个?Controller的Top-K选择在候选集很大时还能保持准确吗?技能之间的冗余和冲突怎么处理?
3. 对基础模型能力的依赖
论文用的是LLaMA-3.3-70B和Qwen3-80B这种强模型做Executor和Designer。对于7B或更小的模型:
- Executor可能无法准确遵循复杂技能的指令
- Designer的分析能力可能不够,进化出的技能质量打折
- 论文没有在小模型上做实验,这个方向的可行性是个问号
4. ALFWorld的对比不够公平?
在ALFWorld上,MemSkill的成功率(47.86%/47.01%,LLaMA版本)显著高于所有基线(最高20.90%)。差距大到有点不真实——这让我怀疑基线方法是否在ALFWorld上做了充分的适配。记忆系统(如Mem0、LangMem)主要是为对话场景设计的,直接搬到具身任务上可能水土不服。MemSkill的优势可能部分来自于它通过Designer适配了具身场景。
5. 真实延迟
Controller(嵌入+Top-K选择)和Executor(一次LLM调用)的推理延迟是可控的。但在训练阶段,每次Controller更新都需要完整的"选技能→生成记忆→跑下游任务→拿奖励"的loop,加上Designer定期的分析开销,训练成本应该不低。论文没有报告具体的训练时间和计算资源。
🔗 与相关工作的定位
把MemSkill放在更大的图景中看:
| 维度 | Mem0/LangMem | A-MEM | MemoryOS | MemSkill |
|---|---|---|---|---|
| 记忆操作 | 固定4种原语 | 自动提取 | 多层管理 | 可学习+可进化 |
| 操作触发 | 规则/启发式 | LLM判断 | 分层路由 | RL策略学习 |
| 领域适配 | 无 | 无 | 无 | 通过Designer自动适配 |
| 训练需求 | 无需训练 | 无需训练 | 无需训练 | 需要RL训练 |
| 推理开销 | 每轮1次LLM | 每轮1次LLM | 每轮多次LLM | 1次嵌入+1次LLM |
MemSkill的定位很清晰:用训练时的额外成本换取推理时的更高质量。对于需要长期部署的智能体来说,这个trade-off是合理的。
与同期的SkillRL(arXiv: 2602.08234)对比,两者都在做"技能进化",但方向不同:
- SkillRL:从交互轨迹中蒸馏出行动技能(怎么做任务),用于增强RL训练
- MemSkill:进化出记忆技能(怎么记信息),用于增强记忆系统
它们解决的是智能体的两个不同侧面:SkillRL关注"做得更好",MemSkill关注"记得更好"。两者理论上可以组合使用。
📌 关键信息速查
| 项目 | 内容 |
|---|---|
| 标题 | MemSkill: Learning and Evolving Memory Skills for Self-Evolving Agents |
| 核心贡献 | 将记忆操作从固定原语升级为可学习、可进化的技能库 |
| 三组件 | Controller(PPO训练的技能选择策略)+ Executor(LLM执行技能)+ Designer(LLM分析失败案例进化技能) |
| 初始技能 | Insert / Update / Delete / Skip |
| 进化技能示例 | Capture Temporal Context, Track Object Location, Capture Action Constraints 等 |
| LoCoMo 最佳 | L-J 52.07(Qwen),比MemoryOS高7.48分 |
| ALFWorld 最佳 | SR 64.18%(Qwen-Unseen),比MemoryOS高45.52个百分点 |
| 泛化验证 | LoCoMo训练的技能库零样本迁移到LongMemEval和HotpotQA均有效 |
| 代码 | https://github.com/ViktorAxelsen/MemSkill |
如果觉得有用,欢迎点赞、在看、转发三连~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)