Training Software Engineering Agents and Verifiers with SWE-Gym
ICML’25
在开始这篇论文之前,先说个背景。
swe-bench的训练集是没有docker镜像环境的。之前我们测试的时候使用的是test dataset,测试集是肯定要有镜像环境,不然如何测试代码到底能否运行?这个SWE-gym针对的就是训练集没有测试环境,所以agent修改完代码无法得到运行反馈开展的。SWE-Gym 论文解决的问题:
- SWE-Bench 训练集只有 git patch,没有 Docker 镜像
- 所以没法让模型在训练阶段获得"跑单元测试"这个反馈信号
Abstract
1. Introduction
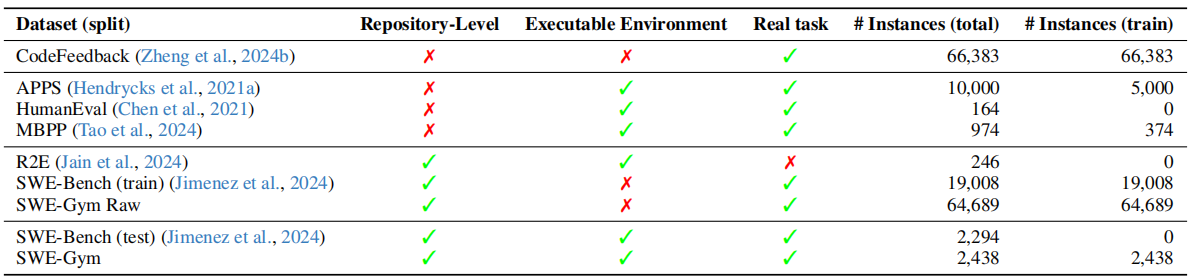
这张表是在比较 SWE-Gym 和 SWE-Bench 测试集(括号内是 SWE-Bench 的数据)的统计特征
Size(规模)
- Instances:任务数量。SWE-Gym 有 2,438 个,SWE-Bench 测试集有 2,294 个
- Repos:来自几个代码仓库。都是 11 个
Issue Text(issue 描述)
- Length by Words:issue 描述的平均词数。SWE-Gym 约 240 词,比 SWE-Bench 的 195 词更长,说明任务描述更复杂
Codebase(代码库)
- Non-test Files:非测试文件数量。SWE-Gym 平均 971 个文件,但 SWE-Bench 有 2,944 个,说明 SWE-Bench 的仓库更大
- Non-test Lines:非测试代码行数。两者都在 34 万行左右,量级相当
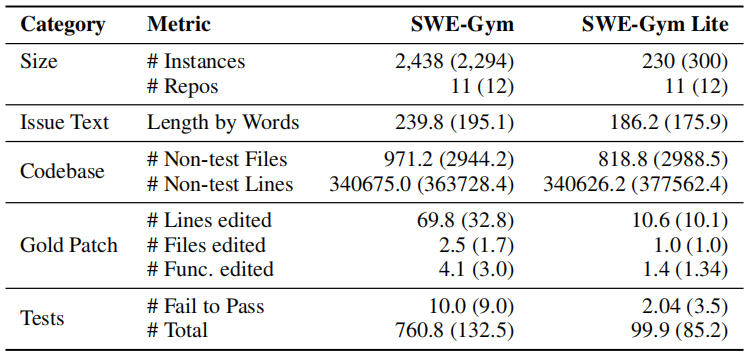
Gold Patch(标准答案补丁) 这三个指标最能说明任务难度:
- Lines edited:平均修改行数。SWE-Gym 是 69.8 行,而 SWE-Bench 只有 32.8 行,SWE-Gym 的任务改动量是 SWE-Bench 的两倍多
- Files edited:平均修改文件数。SWE-Gym 是 2.5 个文件,SWE-Bench 是 1.7 个
- Func. edited:平均修改函数数。SWE-Gym 是 4.1 个,SWE-Bench 是 3.0 个
Tests(测试)
- Fail to Pass:需要从失败变为通过的测试数。SWE-Gym 平均 10 个,SWE-Bench 是 9 个,差不多
- Total:总测试数量。SWE-Gym 平均 760 个,SWE-Bench 只有 132 个,说明 SWE-Gym 的测试套件规模大得多
SWE-Gym 支持训练最先进的开放权重 SWE 智能体。基于面向通用软件开发的 OpenHands(Wang 等,2024c)智能体框架[agent scaffold](§2),我们仅使用从 SWE-Gym 中采样的 491 条智能体-环境交互轨迹对 32B Qwen-2.5 coder模型(Hui 等,2024b)进行微调,在 SWE-Bench Lite 和 SWE-Bench Verified 上的解决率分别取得了 +12.3%(达到 15.3%)和 +13.6%(达到 20.6%)的显著绝对提升(§4.2)。
SWE-Gym 在不同智能体框架下均表现有效。在另一个基于专用工作流的智能体框架[agent scaffold](MoatlessTools;Örwall 2024;§2)中,我们进行了自我提升实验——语言模型与 SWE-Gym 交互,从中获得奖励信号,并通过拒绝采样微调来不断自我改进。这一自我提升机制使模型在 SWE-Bench Lite 上的性能最高提升至 19.7%。
SWE-Gym 支持训练验证器模型[verifier models],从而实现推理时扩展。我们利用 SWE-Gym 中包含的测试套件来判断采样的智能体轨迹是否成功。
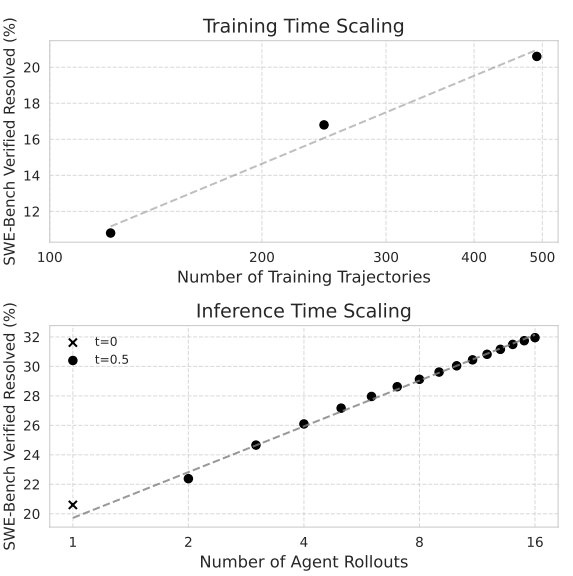
图1:SWE-Gym 能够为软件工程智能体实现可扩展的性能提升。上图: 扩大训练数据量能带来持续的性能提升——随着我们获取更多训练轨迹,模型表现不断改善,在 491 条轨迹时仍未出现性能饱和的迹象。评估时使用温度参数 t = 0。下图: 在推理时间扩展方面,我们为每个任务生成多条候选轨迹,并使用一个在 SWE-Gym 上训练的验证器从中选出最优结果。该方法展示了与采样解的数量大致呈对数线性的性能增益。t = 0(t是temperature)(从回归中排除)被用作第一个假设,以与上图保持一致;后续的采样轨迹使用 t = 0.5。
基于这些样本,我们训练了一个验证器模型[verifier model](即结果监督奖励模型[an outcome-supervised reward model];Cobbe 等,2021),用于估计一条轨迹的成功概率。这使得推理时扩展成为可能——我们对多条智能体轨迹进行采样,并根据验证器选择估计奖励最高的那条。这进一步将 SWE-Bench Verified 上的解决率提升至 32.0%(绝对提升 +11.4%)(§5.1.1;图1下),SWE-Bench Lite 上达到 26.0%(§5.1.2),在公开权重的系统中创下了新的最优水平(表9)。我们在 SWE-Gym 上的基线训练方法和推理时扩展方法随着算力的增加持续取得更好的结果(图1)。在训练阶段,性能随采样轨迹数量的增加而持续提升,直至我们当前 491 条轨迹的上限,这表明当前性能的瓶颈在于采样的算力预算,而非 SWE-Gym 中任务的数量。类似地,使用由 SWE-Gym 训练的智能体和验证器,图1下半部分表明,在推理阶段投入更多算力可以稳步提升性能。
为什么是"采样轨迹"?
这里的"轨迹"是指一次完整的 agent 解题过程,包括它看了哪些文件、执行了哪些命令、最终生成了什么补丁。采样的意思是让 GPT-4o 和 Claude 在 SWE-Gym 环境里真实跑任务,记录下整个过程。
为什么只有 491 条?
论文里明确说了:不是任务不够,是钱不够。 SWE-Gym 有 2,438 个任务,但每跑一次任务要调用 GPT-4o/Claude API,费用大概 $1 以上一个任务,还要启动 Docker 环境执行代码。491 条是他们算力预算的上限,论文也明确指出性能还没饱和,多采样还能继续涨。
你说得对,这就是 SFT,不是 RL。
具体做法是:
- 用 GPT-4o/Claude 在 SWE-Gym 跑任务,收集轨迹
- 只保留成功的轨迹(单元测试通过的)
- 用这 491 条成功轨迹对 Qwen-2.5-32B 做监督微调
这叫拒绝采样微调(Rejection Sampling Fine-tuning)——采样很多,拒绝掉失败的,只用成功的训练。本质上是模仿学习,不是 RL。
那为什么不做 RL?
论文也承认这个问题,在结论里把"用 PPO 等 RL 方法做自我改进"列为未来工作。他们也试过自我改进(用微调后的模型自己采样再训练),但效果反而下降了,说明简单的 on-policy SFT 在这个任务上还不够稳定。
SWE-Gym 和 SWE-Bench 来自完全不同的代码仓库。"These repositories are separate from those used in SWE-Bench to avoid contamination."
2. Related Work
解决 GitHub issue 的智能体。Agents that solve GitHub issues.
用于训练软件智能体的环境。Environments for training software agents.
后训练:从聊天机器人和推理模型到智能体 Post-training: From chatbots and reasoners to agents.
3. SWE-Gym Environment
这段话里描述的pull request的样子。
场景: 用户在 pandas 仓库提了一个 issue
输入1 - issue 的自然语言描述:
标题:pd.read_csv() 读取含中文列名的文件时报 UnicodeDecodeError 描述:当 CSV 文件包含中文列名时,使用默认参数调用 pd.read_csv('data.csv') 会抛出 UnicodeDecodeError, 但指定 encoding='utf-8' 后可以正常读取。 应该自动检测编码而不是直接报错。输入2 - 仓库初始状态:
# pandas/io/parsers.py 当前代码 def read_csv(filepath, encoding=None, ...): if encoding is None: encoding = 'ascii' # ← 问题在这里 ...输出 - git patch 形式的 Pull Request:
--- a/pandas/io/parsers.py +++ b/pandas/io/parsers.py @@ -42,7 +42,7 @@ def read_csv(filepath, encoding=None, ...): if encoding is None: - encoding = 'ascii' + encoding = 'utf-8' ...这个 patch 就是 PR 的核心内容,它精确描述了:
- 改了哪个文件:
pandas/io/parsers.py- 删了哪行:
encoding = 'ascii'(前面带-)- 加了哪行:
encoding = 'utf-8'(前面带+)所以 agent 的任务本质上就是:读懂 issue 描述 → 找到有问题的代码 → 生成这样一个 diff 文件。之后用单元测试验证这个 patch 是否真的修好了问题。
3.1. Dataset Construction
Identify Repositories. 筛选代码仓库。
Extracting Training Instances from Repositories. 从代码仓库中提取训练实例。
我们使用 SWE-Bench 的实例提取脚本将这些仓库转换为任务实例,每个实例对应一个 GitHub issue,包含该 issue 的自然语言描述、issue 创建时的仓库快照[a snapshot of the repository]以及一组单元测试[a set of unit tests]。
仓库快照(a snapshot of the repository)
"快照"的意思是某个特定时间点的代码库完整副本。
具体来说,每个 GitHub issue 都是在某个时间点提出的,比如 2021年3月15日有人发现了一个 bug。那么"仓库快照"就是指这个 issue 被提出那一天的代码库状态,而不是今天最新的代码。
为什么要用那个时间点的快照?因为之后的代码可能已经被其他 PR 修改过了,如果用最新代码,环境就对不上了。所以需要"穿越回"issue 提出时的状态,这样 agent 面对的才是当时真实的问题场景。
技术上通过
git checkout <commit_id>就能还原到那个时间点。
在 358 个代码仓库中,我们共提取了 64,689 个任务实例。我们将该数据集称为 SWE-Gym Raw,其规模是前人工作(Jimenez 等,2024)所收集的 19k 实例的三倍以上,涵盖的代码仓库数量也近乎是其十倍。
尽管 SWE-Gym Raw 的实例包含代码、issue 描述和解决方案,但它们不包含可执行环境,也无法保证其单元测试能够有效评估解决方案的正确性。因此,我们聚焦于实例数量较多的 11 个代码仓库,并为其半手动地创建可执行环境。
Version Training Instances. 对训练实例进行版本关联。
将实例与其对应的版本号(如 1.2.3)相关联,并逐版本配置环境,可以避免重复的配置工作,从而使环境收集过程更加高效。我们对 SWE-Bench 的版本管理脚本进行了泛化,使其支持通过脚本执行来确定版本,并基于仓库中的可用信息(如 pyproject.toml、git tag 等)半自动地为每个实例收集版本信息。
这里说逐版本配置,是将版本分组。
假设 pandas 仓库有这些实例:
issue #1001 → pandas 版本 1.3.0 issue #1002 → pandas 版本 1.3.0 issue #1003 → pandas 版本 1.3.0 issue #2001 → pandas 版本 1.4.0 issue #2002 → pandas 版本 1.4.0如果不按版本分组,逐个配置:
- 配置 issue #1001 的环境:安装 pandas 1.3.0 的所有依赖
- 配置 issue #1002 的环境:重新安装 pandas 1.3.0 的所有依赖(完全重复)
- 配置 issue #1003 的环境:再次安装 pandas 1.3.0 的所有依赖(又重复)
- ……
如果按版本分组:
- 配置 pandas 1.3.0 的环境:安装一次依赖,#1001、#1002、#1003 共用这个环境
- 配置 pandas 1.4.0 的环境:安装一次依赖,#2001、#2002 共用这个环境
所以本质上就是:同一个版本的代码库,依赖项是完全相同的,没必要为每个 issue 单独装一遍。按版本归类之后,同版本的几十个 issue 只需要配置一次 Docker 环境,大幅减少了重复工作。
Setup Executable Environments and Verify Instances. 配置可执行环境并验证实例。
单元测试(a set of unit tests)
单元测试是代码仓库自带的。但这里有个关键细节:
SWE-Bench 的做法是专门挑选那些对应 PR 里新增或修改了测试的 issue。也就是说:
- 原始仓库里有一批旧测试
- 开发者提交修复 PR 的同时,新增了专门针对这个 bug 的测试
- 这些新增的测试在打补丁之前会失败,打了补丁之后会通过
所以"一组单元测试"特指这批能区分修复前后状态的测试,而不是仓库里所有的测试。这也是为什么表2里有个指标叫"Fail to Pass"——就是统计有多少测试从失败变成通过,这才是验证 agent 是否真正解决了问题的核心信号。
关于3.1提到的SWE-bench的任务示例爬取脚本和验证脚本。
1. 实例提取脚本(Instance Extraction)
swe-bench的readme.md里没有具体说这个脚本是什么,但是好像在/data/16T/pyq/SWE-bench/swebench/collect 这个文件夹下?因为这个文件夹下貌似有SWE-bench/swebench/collect/get_tasks_pipeline.py, SWE-bench/swebench/collect/build_dataset.py, SWE-bench/swebench/collect/print_pulls.py。后面需要开始编程的时候,仔细查看一下代码仓库。
2. 验证脚本(Execution-based Validation)
这就是
run_evaluation脚本
我在SWE-bench的代码仓库也确实找到了这个脚本。
/data/16T/pyq/SWE-bench/swebench/harness/run_evaluation.py以下内容来自https://github.com/SWE-bench/SWE-bench 的readme.md
Test your installation by running:
python -m swebench.harness.run_evaluation \ --predictions_path gold \ --max_workers 1 \ --instance_ids sympy__sympy-20590 \ --run_id validate-gold
3. 数据集结构
每个实例包含以下字段:
{ "instance_id": "owner__repo-pr_number", "base_commit": "commit_hash", ← 仓库快照就靠这个还原 "problem_statement": "Issue描述", "patch": "gold patch(标准答案)", "test_patch": "测试补丁" }其中
base_commit就是还原"仓库快照"的关键——通过这个 commit hash 可以精确还原到 issue 提出时的代码状态。
3.2. SWE-Gym Lite
解决软件工程任务的计算开销极大,使用前沿模型时每个任务的费用通常在 1 美元以上(Wang 等,2024c)。为了通过加快智能体评测来提升研究效率,Jimenez 等(2024)推出了 SWE-Bench Lite,这是从 SWE-Bench 中精选出的 300 个标准实例子集。遵循 SWE-Bench Lite 的筛选流程,我们划定了包含 230 个实例的 SWE-Gym Lite 子集。与 SWE-Bench Lite 类似,该子集排除了需要修改多个文件的任务、问题描述不清晰的任务、标准代码 diff 过于复杂的任务,以及专注于错误信息验证的测试。
3.3. Dataset Statistics
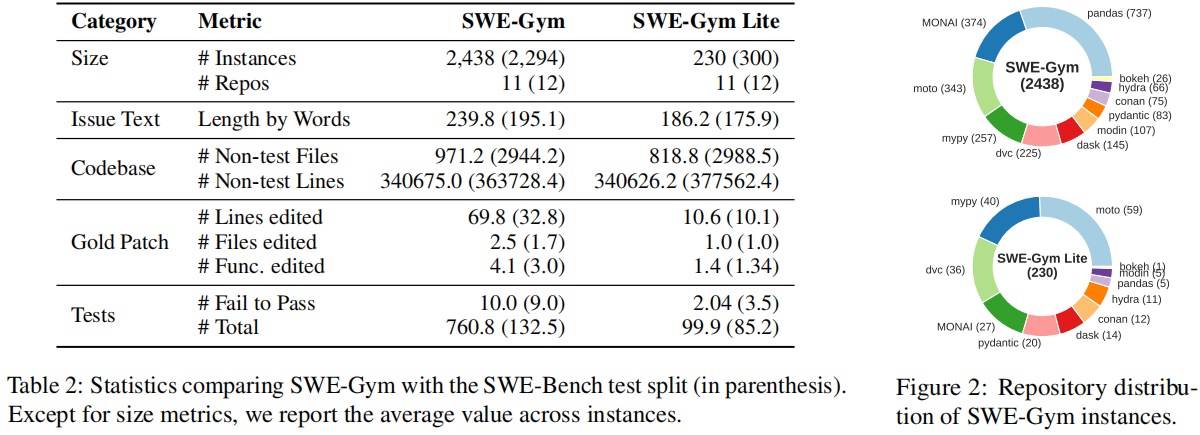
图2 显示,任务在各代码仓库间的分布呈现出长尾模式。值得注意的是,与 pandas 相关的任务占总量的近三分之一,而与 bokeh 相关的任务仅占约百分之一。我们的分析表明,SWE-Gym 中的任务平均难度高于 SWE-Bench 中的任务。
表2 显示,SWE-Gym 与 SWE-Bench 在统计特征上总体相似,但存在若干关键差异。SWE-Gym 中的代码库平均文件数量少于 SWE-Bench,但代码总行数相近。然而,与 SWE-Bench 的标准补丁相比,SWE-Gym 中的标准补丁涉及的修改行数和文件数要多得多。此外,我们发现模型在 SWE-Gym 上的表现始终低于在 SWE-Bench 上的表现。除了模型和框架对 SWE-Bench 过拟合之外,在 SWE-Gym 上性能下降也可能是由于我们纳入了 pandas 和 MONAI 等复杂度较高的代码仓库。
4. Training LMs as Agents with SWE-Gym
4.1. Setting
Agent Scaffolds.智能体框架。
Policy Improvement Algorithm. 策略改进算法。
Technical Details. 技术细节。
4.2. Training General-Purpose Prompting Agents
Trajectory Collection. 轨迹收集。
在 SWE-Gym 轨迹上进行训练能将语言模型转化为有效的问题修复智能体。Training on SWE-Gym trajectories turns LM into effective agents to fix issues.
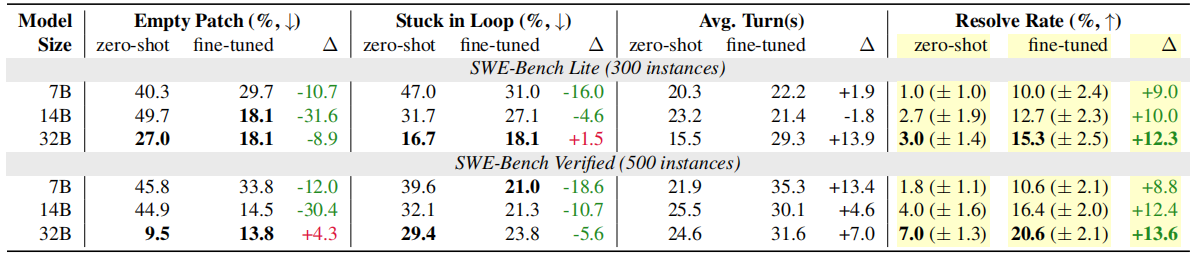
Training reduces stuck-in-loop behavior.训练减少了陷入循环的行为。
在智能体任务中,开放权重语言模型常常陷入循环,即模型在多个回合中持续生成相同的动作,这在使用通用提示时尤为明显(§2)。因此,我们报告"陷入循环率"[Stuck in Loop](%),即智能体连续三次重复相同动作的轨迹比例。如表3所示,零样本预训练模型经常陷入循环;即使是最大的 32B 模型,也在 29.4% 的 SWE-Bench Verified 任务中陷入循环。在 SWE-Gym 轨迹上微调后,陷入循环率在 SWE-Bench Lite 和 Verified 两个测试集上均持续降低了 4.6%–18.6%,但 32B 模型在 SWE-Bench Lite 上例外,由于其初始循环率已经很低,反而上升了 1.5%。
这个太真实了,我之前使用gsm8k上训练过的qwen3-8b模型就这样,因为老是重复执行相同的指令导致超过max_token,直接就失败了,连一个instance都跑不下来。
这与空补丁率的下降相吻合,表明智能体能够执行更多的代码编辑操作。性能随模型规模的增大而提升。不出所料,更大的基础模型在解决率、空补丁率和陷入循环率等指标上均持续表现更优(表3)。
Performance scales with model size. 性能随模型规模的增大而提升。
不出所料,更大的基础模型在解决率、空补丁率和陷入循环率等指标上均持续表现更优(表3)。
Self-improvement remains ineffective. 自我提升目前仍然无效。
除了在强教师模型采样的轨迹上进行微调之外,我们还尝试了直接在被更新策略自身采样的轨迹上进行微调。我们使用微调后的 32B 模型对每个 SWE-Gym 实例采样 6 条轨迹(温度 t = 0.5),共获得 868 条成功轨迹(即在线策略轨迹[on-policy trajectories])。我们进一步在 868 条在线策略轨迹与此前收集的 491 条离线策略轨迹的混合数据上对基础 32B 模型进行微调。在 SWE-Bench Lite 上评估该微调模型时,我们发现解决率从 15.3% 下降至 8.7%,表明自我提升目前尚不奏效。
我们假设,采用更先进的策略优化方法(如近端策略优化[proximal policy optimization],PPO;Schulman 等,2017)或更强的基础模型,有望取得更好的结果。这些方向仍是未来值得深入探索的有前景的研究路径。
4.3. Self-Improvement with Specialized Workflow
与 OpenHands 在长期规划上的自由度不同,MoatlessTools 将语言模型的动作空间限制在预定义的专用工作流内[pre-defined specialized workflows],从而缩短了任务视野。对于开放权重语言模型而言,专用工作流的表现优于通用提示方法。
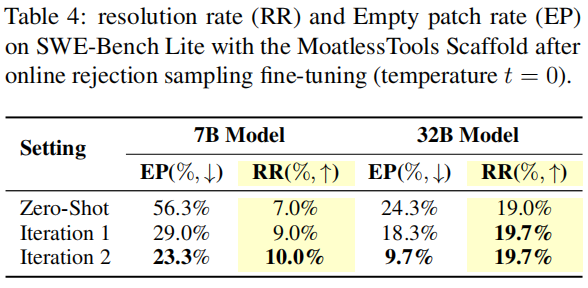
如表3和表4所示,7B 和 32B 语言模型在 MoatlessTools 下的零样本解决率分别为 7% 和 19%,而在 OpenHands 下仅为 1.0% 和 3.0%(均在 SWE-Bench Lite 上测试)。鉴于 MoatlessTools 更好的零样本性能和更短的任务视野,我们假设使用该框架结合 SWE-Gym 训练,可以在无需强教师模型的情况下实现自我提升。
受限于计算预算,我们仅使用 7B 和 32B 模型进行该实验,并对 32B 模型采用 LoRA(Hu 等,2022)以提高训练效率。我们使用 7B 模型进行消融实验。
We use iterative rejection sampling fine-tuning for policy improvement. 我们采用迭代拒绝采样微调方法来进行策略改进。
每次迭代包括两个步骤:(a)在 SWE-Gym-Lite 上对每个任务执行 30 次高温度(1.0)采样,并将成功的轨迹加入微调数据集;(b)在这些筛选后的轨迹上对策略进行微调。
经过两次迭代后,进一步的提升已可忽略不计。
Data Bias Impacts Performance. 数据偏差影响性能。
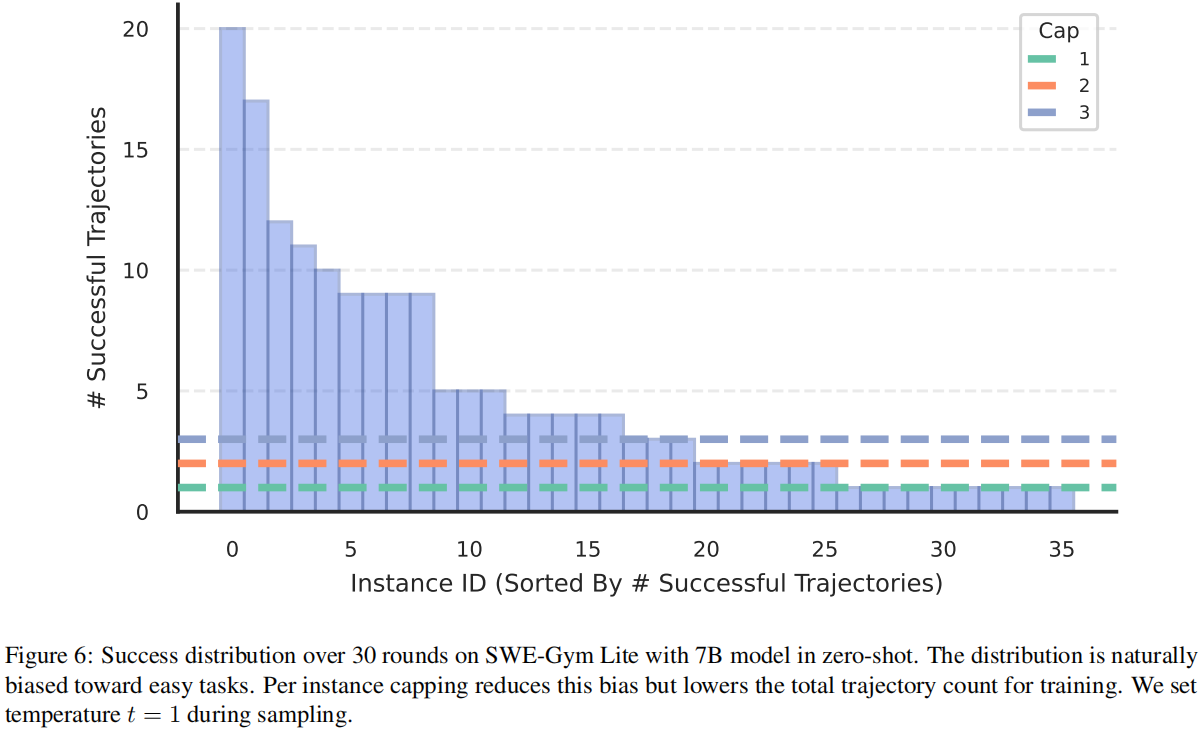
与 Brown 等(2024)的研究一致,重复采样表明任务成功概率呈长尾分布(图6),更多的采样次数能增加被解决的实例数量。尽管更广泛的任务覆盖有助于训练,但这会引入对简单任务的偏差,导致在所有成功轨迹上训练并非最优,这一现象最早在数学推理领域被 Tong 等(2024)观察到。
Mitigating Bias with Per-Instance Capping. 通过单实例上限缓解偏差。
我们引入了单实例上限方法[per-instance capping],即限制每个任务中被选取样本的最大数量。如图6所示,该方法能够在数据集偏差和规模之间取得平衡。上限过低会减少数据集规模并降低性能(§5.2),而上限过高则会使分布偏向简单任务。经验上,上限设为 2 能取得良好的平衡,性能略优于使用全量数据集,同时还能提升训练速度(表6)。我们按所需模型响应轮数对轨迹进行排序,优先选取轮数更少的轨迹。

Results. 实验结果。
经过两轮策略改进迭代后(表4),7B 模型的解决率在第一次迭代后从 7.0% 提升至 9.0%,第二次迭代后进一步提升至 10.0%。相比之下,32B 模型在第一次迭代后从 19.0% 提升至 19.7%,此后不再有进一步提升。我们将 32B 模型提升有限归因于框架受限的动作空间以及拒绝采样微调方法本身的局限性。
5. Scaling Agent Performance with SWE-Gym
我们探索了 SWE-Gym 所支持的两个扩展方向以提升智能体性能:推理时扩展[inference-time scaling](§5.1)和训练时数据扩展[training-time data scaling](§5.2)。
5.1. Inference-Time Scaling with Verifiers
从 SWE-Gym 中采样的轨迹不仅可用于训练策略模型,还可用于训练验证器(即奖励)模型。我们训练了一个结果监督奖励模型(outcome-supervised reward model, ORM)(Cobbe 等,2021),该模型以任务执行的相关上下文(包括问题描述、智能体轨迹和当前 git diff)作为输入,生成一个估计智能体解决问题概率的分数。
我们尝试使用该模型对 SWE 智能体策略所采样的候选轨迹进行重排序,并证明这种学习得到的验证器能够实现有效的推理时扩展,从而进一步提升性能。
5.1.1. Verifier for General-Purpose Prompting
对于采用通用提示的 OpenHands 智能体(Wang 等,2024b;c;§2),我们训练了一个验证器(ORM),其输入为轨迹[trajectory] ,以观察与动作[observations and actions]交替排列的序列表示,输出为标量奖励值[scalar reward] r ∈ [0, 1]。
观察值 包括任务问题描述[task problem statement]、命令执行输出[command execution output]、错误信息[error messages]等;动作[action]
可以是智能体执行的 bash 命令或文件操作(如编辑、查看)[file operations (e.g., edit, view)]。
Training and Inference. 训练与推理。
我们对 32B 的 Qwen2.5-Coder-Instruct 进行微调,使其分别用输出 token <YES> 和 <NO> 来标记轨迹是否成功。训练数据方面,我们复用了 §4.2 中为智能体训练而在 SWE-Gym 上采样的两组轨迹:(1)离线策略轨迹[off-policy trajectories],包含 443 条成功轨迹;(2)在线策略轨迹[on-policy trajectories],包含从微调后的 Qwen2.5-Coder-Instruct-32B 采样的 875 条成功轨迹。
我们将在线策略轨迹和离线策略轨迹合并,从每个子集中随机采样等量的失败轨迹(各 1,318 条),共同构成验证器训练数据集(共 2,636 条轨迹)。我们对模型进行微调,使其对成功轨迹预测 <YES>,对失败轨迹预测 <NO>。
在推理阶段,以提示和智能体轨迹[the agent trajectory] 为条件,我们使用 SGLang(Zheng 等,2024a)获取下一个 token 为 <YES>(ly)或 <NO>(ln)的对数概率。随后,通过对对数概率进行归一化来计算成功概率作为奖励值:r = exp(ly)/(exp(ly) + exp(ln))。
用分类任务来实现打分
直觉上你可能觉得验证器应该直接输出一个 0~1 的数字分数。但这篇论文的做法不是这样,而是把它变成了一个二分类任务——让模型预测下一个 token 是
<YES>还是<NO>。
语言模型本质上是在预测下一个 token 的概率分布。对于输入的轨迹,模型内部其实已经在计算:P(下一个token = <YES>) = 0.73 P(下一个token = <NO>) = 0.27这个概率本身就是一个连续的分数,天然就在 0~1 之间,完全可以直接拿来当奖励值用。
公式的含义
r = exp(ly) / (exp(ly) + exp(ln))这其实就是 softmax,作用是把对数概率(log probability)归一化成概率:
ly= log P(<YES>)ln= log P(<NO>)exp(ly)= P(<YES>)- 整个公式 = P(<YES>) / (P(<YES>) + P(<NO>))
之所以要归一化,是因为模型实际上对几万个 token 都有概率分布,只取 <YES> 和 <NO> 两个的话需要重新归一化,让它们的概率之和为 1。(即,虽然只要求输出YES或者NO,但是模型内部可能也有 OR NOT 这样的潜在token)
整个流程总结
输入轨迹 → 模型预测 <YES>/<NO> 的概率 → 用概率作为奖励分数 → 选分数最高的轨迹
Metrics. 评估指标。
我们报告两个指标:(1)Pass@k,即在 k 次采样中至少有一个成功解的任务比例;(2)Best@k,即验证器从每个任务的 k 次采样中选出奖励最高的轨迹的成功率。
Pass@k 衡量解的发现能力(是 Best@k 的上界);Best@k 评估验证器的准确性。均值和方差的计算方法详见 §B.1,遵循 Lightman 等(2023)的方法。
Results. 实验结果。
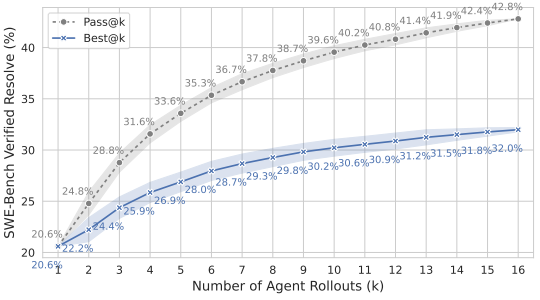
图3展示了以微调后的 32B 模型作为智能体模型时,Pass@k 和 Best@k 如何随采样轨迹数量的增加而变化。Pass@k 表现出显著提升,随着 k 从 1 增加到 8,解决率从 20.6% 上升至 37.8%,在 k=16 时进一步达到 42.8%。Best@k 指标依赖于验证器选出最优轨迹的能力,表现出较为温和但稳定的提升,从 20.6@1 提升至 29.8@8,并进一步达到 32.0@16。
Pass@k 与 Best@k 之间的差距源于训练所得验证器性能的不完善,这表明编程智能体的奖励建模仍有提升空间。令人意外的是,我们发现使用 LoRA(Hu 等,2022)结合 Unsloth(Unsloth Team,2024)对验证器模型进行微调(29.8@8)的效果优于全参数微调(27.2@8),这可能得益于正则化效果。此外,如图1(下)所示,Best@k 曲线在对数尺度上呈现出良好的线性关系,表明其具有令人期待的扩展规律。
Training data matters for verifier. 训练数据对验证器至关重要
我们对验证器模型训练数据的选取方式进行了多种变体实验。在对 Qwen-2.5-Coder-Instruct-32B 进行全参数微调时,我们使用了在线策略轨迹与离线策略轨迹的不同混合比例,以及成功轨迹与失败轨迹的不同分布组合。
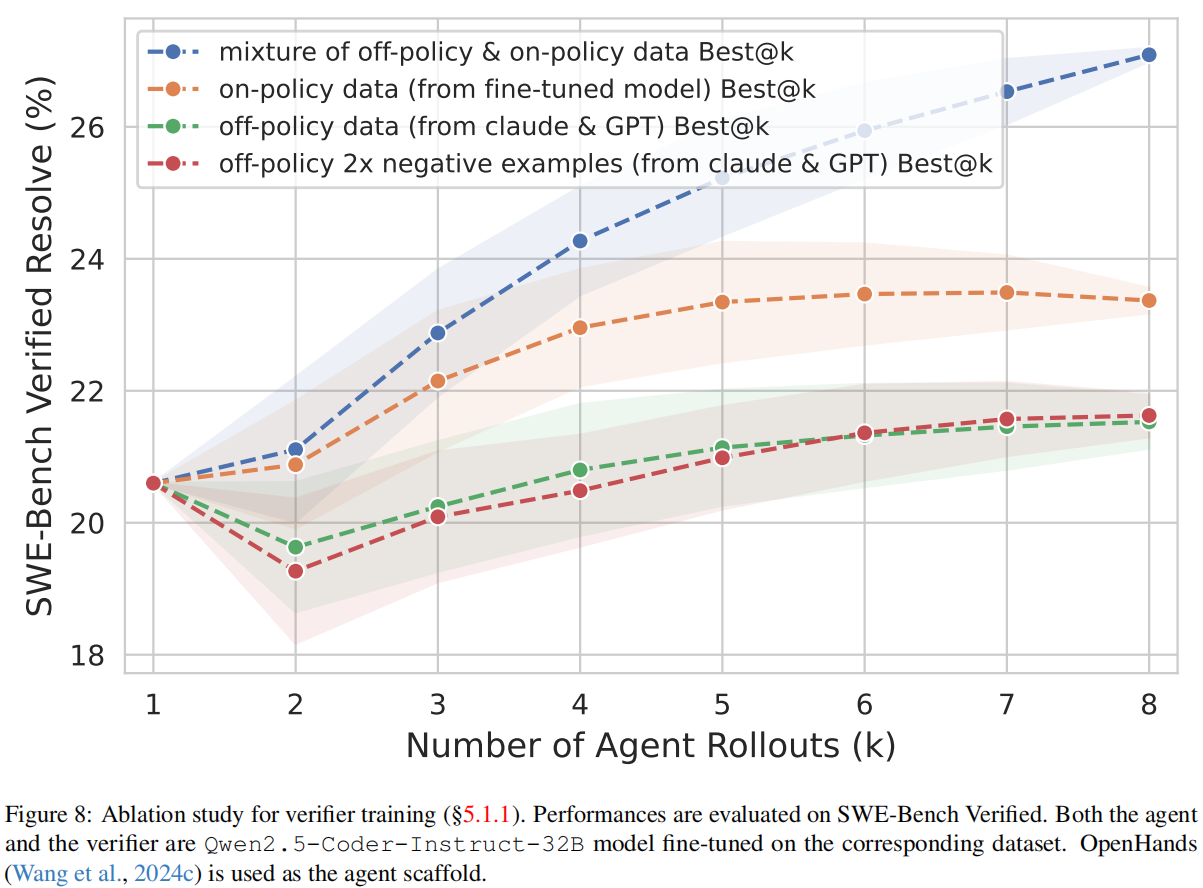
如图8所示,我们的消融研究表明,训练数据的选取对验证器性能有显著影响。使用离线策略数据与在线策略数据的混合进行训练效果最佳(即我们的默认设置),解决率达到 27@8。
相比之下,仅使用来自微调模型的在线策略数据只能带来有限的中等程度提升,而仅在来自 Claude 和 GPT 的离线策略数据上训练则会导致性能较早地停滞在约 22% 的解决率。我们的研究结果表明,验证器训练最得益于同时包含离线策略样本和在线策略样本的多样化数据集。
5.1.2. Verifier for Specialized Workflow
对于采用专用工作流的 MoatlessTools 智能体,由于它不像 OpenHands CodeActAgent 那样具有回合制的动作-观察轨迹,我们通过借鉴 Zhang 等(2024a)的解析流程来准备验证器输入,该流程将任务描述、相关智能体上下文和生成的补丁组合在一起。
我们训练验证器将上述输入映射为一个表示任务是否成功的单一 token。[We train the verifier to map from this input to a single token indicating task success.]遵循 §5.1.1 中描述的训练流程,我们使用第二轮采样的在线策略轨迹,结合 LoRA(Hu 等,2022)分别训练 7B 和 32B 验证器。为了解决训练数据集中存在的简单数据偏差,我们将每个实例的成功轨迹数量上限设为 2,并通过对失败案例进行下采样使其与成功案例数量相匹配,从而平衡数据集。
Results. 实验结果。
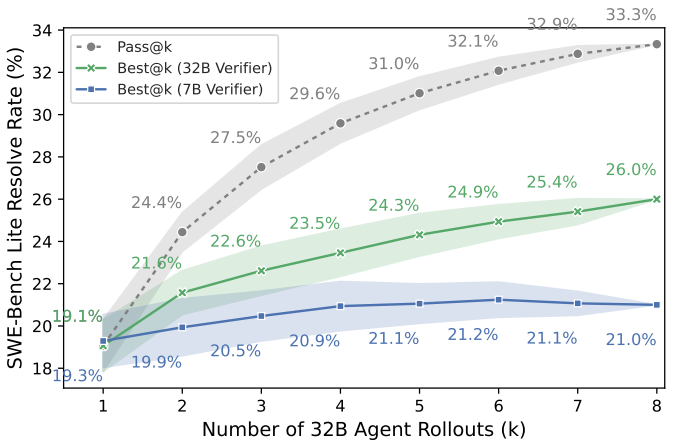
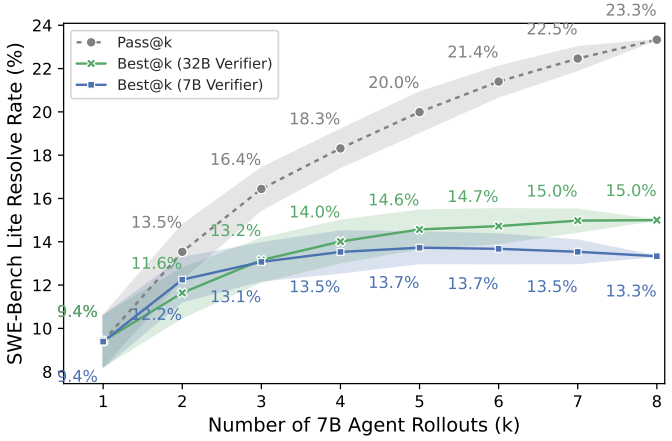
我们通过在温度为 0.5 时对智能体策略采样 k = 8 条轨迹来评估验证器。如图4和图7所示,这些验证器在不同验证器和策略规模下均能实现有效扩展:7B 验证器与 7B 策略配合时,在 SWE-Bench Lite 上的解决率从 10% 提升至 13.3%;32B 验证器与 32B 策略配合时,解决率从 19.7% 提升至 26.3%。
在对 7B 和 32B 智能体的轨迹进行排序时,7B 验证器在 k = 4 之后性能趋于饱和。相比之下,32B 验证器在 k = 8 时仍持续提升,表明验证器规模对扩展行为有显著影响。
5.2. Training-Time Scaling with Data
我们随后研究了使用 §4.2 中采样的 491 条轨迹时,扩展训练数据量对智能体性能的影响。我们通过下采样模拟了三种扩展方法:(1)轨迹扩展,即随机丢弃部分轨迹(图5);(2)唯一任务实例扩展,即每个任务实例只保留一条成功轨迹(图9);(3)仓库扩展,即按顺序逐仓库纳入所有实例,以评估仓库级别的多样性。
Setup. 实验设置。
使用 OpenHands(Wang 等,2024c)和 §4.2 中描述的微调方法,我们在 SWE-Bench Verified 上评估了这些扩展方法:轨迹数量扩展通过从 §4.2 的完整轨迹数据集中下采样实现(最多 491 条);唯一实例扩展对轨迹按实例 ID 去重(最多 294 条);仓库扩展则按字母顺序对仓库排序并依次纳入每个仓库的全部轨迹(如前 25% 包含前 N 个仓库的完整轨迹)。
对于每种扩展方法,我们比较了在完整数据集的 25%、50% 和 100% 上训练的模型,并使用上述各方法对训练子集进行采样。
Scaling trends suggest instance and repository diversity is not yet a bottleneck. 扩展趋势表明实例和仓库多样性尚未成为瓶颈。
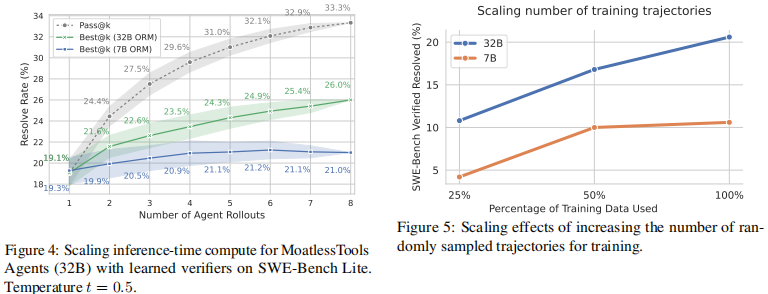
图5展示了显著的扩展规律,随着训练轨迹数量的随机增加,解决率持续提升,32B 模型尤为明显。这些结果表明,SWE-Gym 当前的规模和仓库多样性很可能尚未成为性能瓶颈——通过投入更多算力来采样更多训练轨迹,有望进一步提升性能。
图9显示,在去重效果开始显现之前,不同扩展方法的整体性能相当。随机扩展(不去重)虽然取得了更高的最终性能,但这很可能是由于其拥有更多轨迹(491 条对比 294 条),而非更好的扩展效率。在各去重方法中,仓库扩展在使用 25% 数据时表现出更强的初始性能,表明完整的仓库覆盖可能在训练早期提供更连贯的学习信号。
这些结果表明,SWE-Gym 的仓库和实例多样性尚未成为瓶颈——无论是否存在重复或仓库分布如何,仅通过采样更多智能体轨迹数据用于训练,就有望进一步提升性能。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)