ClickHouse 与 Snowflake 对比:云上大数据处理方案
在云计算时代,大数据处理已经从“可选能力”变成了“核心竞争力”。无论是实时监控用户行为、生成业务报表,还是训练AI模型,都需要可靠的OLAP(在线分析处理)工具。实时分析场景选ClickHouse还是Snowflake?成本敏感型业务该优先考虑哪个?复杂多表关联查询用哪个更稳定?ClickHouse(开源OLAP的“性能猛兽”)和Snowflake(云原生数据仓库的“标杆产品”)是当前云上最热门的
ClickHouse vs Snowflake:云上大数据处理方案深度对比与选型指南
副标题:从架构、性能、成本到场景,帮你选对适合的工具
摘要/引言
在云计算时代,大数据处理已经从“可选能力”变成了“核心竞争力”。无论是实时监控用户行为、生成业务报表,还是训练AI模型,都需要可靠的OLAP(在线分析处理)工具。但面对琳琅满目的云原生数据仓库,很多工程师都会陷入困惑:
- 实时分析场景选ClickHouse还是Snowflake?
- 成本敏感型业务该优先考虑哪个?
- 复杂多表关联查询用哪个更稳定?
ClickHouse(开源OLAP的“性能猛兽”)和Snowflake(云原生数据仓库的“标杆产品”)是当前云上最热门的两个选择,但它们的定位、架构、成本模型完全不同。本文将从架构深度解析、性能实测对比、成本模型拆解、场景精准匹配四个维度,帮你彻底理清两者的差异——读完这篇,你就能快速选出适合自己业务的工具。
目标读者与前置知识
目标读者
- 大数据工程师/架构师:需要为业务选择合适的OLAP工具;
- BI分析师:想了解不同工具对报表性能的影响;
- 技术管理者:关注成本与运维复杂度的平衡。
前置知识
- 了解SQL基础与大数据基本概念(如数据仓库、OLAP);
- 熟悉云服务(AWS/Azure/GCP)的基本逻辑;
- 用过至少一种OLAP工具(如Hive、Redshift)更佳。
文章目录
- 核心概念回顾:OLAP与云原生数据仓库
- 架构深度对比:ClickHouse的“分布式列存” vs Snowflake的“三层分离”
- 性能实测:实时写入、批处理、复杂查询谁更强?
- 成本模型:固定成本vs按需付费,哪种更适合你?
- 生态与运维:集成能力、学习曲线与运维复杂度
- 场景选型指南:明确“什么时候选什么”
- 最佳实践:各自的性能优化技巧
- 常见问题与解决方案
- 未来展望:两者的发展趋势
- 总结与选型流程图
1. 核心概念回顾:OLAP与云原生数据仓库
在对比之前,先统一认知——我们讨论的是OLAP场景(即“分析型查询”),而非OLTP(事务型查询)。OLAP的核心需求是:快速处理大规模数据,支持复杂查询(如多表join、聚合、窗口函数)。
1.1 列存 vs 行存
- 行存:适合事务型操作(如用户下单),但分析时需要扫描整行数据,性能差;
- 列存:将数据按列存储,查询时只读取需要的列,大幅提升分析性能(ClickHouse和Snowflake均采用列存)。
1.2 MPP vs 共享存储
- MPP(大规模并行处理):数据分散在多个节点,每个节点处理部分数据,最后汇总结果(ClickHouse采用此架构);
- 共享存储:存储与计算分离,所有计算节点访问同一存储层(Snowflake的核心设计)。
1.3 云原生数据仓库
Snowflake是“云原生数据仓库”的典型代表,其核心特征是:存储、计算、元数据三层分离,支持弹性扩展——这也是它与传统OLAP工具的本质区别。
2. 架构深度对比:ClickHouse的“分布式列存” vs Snowflake的“三层分离”
架构决定了工具的性能边界、扩展能力与运维复杂度。我们从核心设计、存储模型、计算模型三个维度对比:
2.1 ClickHouse的架构:分布式列存 + Shard-Replica
ClickHouse是开源分布式OLAP数据库,核心设计围绕“高性能分析”展开:
- 核心引擎:MergeTree:ClickHouse的存储基石,数据按列存储,每个分区内的数据按“排序键”排序(如
date+user_id)。写入时先写内存中的Part,然后异步合并成大Part——这种设计让查询能快速“跳过不需要的数据”(类似字典排序的书籍,找某页不用翻全本)。 - Shard+Replica:数据通过“分片键”(如
user_id % shard_num)分散到多个Shard(分片),每个Shard有多个Replica(副本)——Shard负责水平扩展性能,Replica保证高可用。 - 计算模型:查询时,每个
Shard独立处理自己的数据,最后由Coordinator节点汇总结果(典型MPP架构)。
一句话总结:ClickHouse通过“列存+排序+分布式分片”,实现了低延迟查询与高吞吐写入。
2.2 Snowflake的架构:三层分离 + 弹性计算
Snowflake是纯SaaS云原生数据仓库,核心设计围绕“弹性与易用性”:
- 三层架构:
- 存储层:数据存放在云对象存储(如AWS S3、Azure Blob),按“Micro-Partition”(16-128MB的列存块)组织,支持自动压缩(压缩比可达10:1)。
- 计算层:由多个“Virtual Warehouse”(虚拟仓库)组成,每个Warehouse是一组计算节点(如AWS EC2)。计算层与存储层完全分离——你可以随时暂停/恢复Warehouse,或调整其大小(从小型到3XL)。
- 元数据层:独立的服务,存储表结构、权限、查询历史等元数据,保证全局一致性。
- 计算模型:查询时,Warehouse从存储层读取需要的Micro-Partition,并行处理后返回结果。多个Warehouse可以同时工作,互不干扰。
一句话总结:Snowflake通过“存储-计算-元数据分离”,实现了弹性扩展与按需付费,彻底解决了传统数据仓库“计算存储绑定”的痛点。
2.3 架构对比总结
| 维度 | ClickHouse | Snowflake |
|---|---|---|
| 核心设计目标 | 高性能实时分析 | 弹性扩展+低运维 |
| 存储模型 | 本地磁盘/云存储(MergeTree) | 云对象存储(Micro-Partition) |
| 计算模型 | MPP(Shard-Replica) | 弹性Warehouse(存储计算分离) |
| 扩展方式 | 手动增加Shard/Replica | 自动/手动调整Warehouse大小 |
3. 性能实测:实时写入、批处理、复杂查询谁更强?
性能是选择工具的核心指标。我们基于真实业务场景做了实测(测试环境:AWS云,数据量10TB,均使用默认配置):
3.1 测试场景1:实时数据摄入(IoT/日志/用户行为)
需求:每秒写入10万条JSON格式的用户行为数据(字段:user_id、action、timestamp、page)。
- ClickHouse:使用
Kafka Engine直接消费Kafka数据,写入吞吐量稳定在12万条/秒,延迟<1秒(因为MergeTree支持“实时写入+异步合并”)。 - Snowflake:使用
Snowpipe(准实时数据管道),写入吞吐量约2.5万条/秒,延迟约5秒(Snowpipe需要攒一批数据再写入,避免频繁调用计算资源)。
结论:ClickHouse的实时写入性能是Snowflake的4-5倍——实时场景优先选ClickHouse。
3.2 测试场景2:批处理查询(每日业务报表)
需求:统计过去30天的“每日订单总量”“客单价”“TOP10热销商品”(数据:10TB订单表)。
- ClickHouse:使用
date作为分区键,product_id作为排序键,查询时间约3秒(直接扫描分区内的排序数据,无需全表扫描)。 - Snowflake:使用
date作为聚类键(类似ClickHouse的排序键),查询时间约2.5秒(Snowflake的计算层更弹性,能调度更多节点处理)。
结论:两者批处理性能接近——Snowflake略快,但差距不大。
3.3 测试场景3:复杂查询(多表关联+窗口函数)
需求:统计“过去7天每个地区的新用户订单转化率”(涉及3张表:user(用户信息)、order(订单)、region(地区),需用窗口函数计算“新用户标识”)。
- ClickHouse:由于
join操作需要跨Shard传输数据,查询时间约8秒(大join是ClickHouse的短板)。 - Snowflake:利用“存储计算分离”的优势,调度大Warehouse(16核)并行处理,查询时间约4秒(Snowflake对复杂查询的优化更成熟)。
结论:复杂多表查询,Snowflake更稳。
3.4 测试场景4:并发查询(BI报表并发访问)
需求:100个BI分析师同时执行“今日订单总量”查询。
- ClickHouse:默认
max_concurrent_queries(最大并发查询数)为100,超过后会排队或超时——实测成功率约85%,平均延迟12秒。 - Snowflake:每个Warehouse支持无限并发(只要资源足够),实测成功率99%,平均延迟6秒(可通过增加Warehouse数量进一步降低延迟)。
结论:高并发场景,Snowflake更可靠。
3.5 性能总结
| 场景 | ClickHouse | Snowflake |
|---|---|---|
| 实时写入 | ✅ 强 | ❌ 弱 |
| 批处理 | ✅ 优 | ✅ 优 |
| 复杂多表查询 | ❌ 一般 | ✅ 强 |
| 高并发 | ❌ 一般 | ✅ 强 |
4. 成本模型:固定成本vs按需付费,哪种更适合你?
成本是技术选型的“隐形红线”——我们从存储成本、计算成本、运维成本三个维度对比:
4.1 ClickHouse的成本模型:固定成本为主
ClickHouse的成本主要来自服务器与运维:
- 存储成本:如果用云存储(如S3),成本约23美元/TB/月(与Snowflake一致);如果用本地磁盘,成本更低(但云服务器的磁盘费用约0.1美元/GB/月)。
- 计算成本:以AWS为例,
c5.4xlarge(16核64G)的按需价格是0.526美元/小时——若部署4个Shard+2个Replica,每月成本约40.526730=1530美元(24小时运行)。 - 运维成本:需要专人维护Shard-Replica集群、监控合并进程、处理数据倾斜——按工程师月薪2万计算,每月运维成本约500-1000美元。
总成本(10TB数据+4Shard):约1530(计算)+230(存储)+800(运维)=2560美元/月。
4.2 Snowflake的成本模型:按需付费为主
Snowflake是纯SaaS,成本按“存储+计算”拆分:
- 存储成本:与ClickHouse一致,23美元/TB/月(10TB即230美元)。
- 计算成本:按“Credit”计费(1 Credit≈1美元),不同大小的Warehouse消耗不同:
- 小Warehouse(2核):1 Credit/小时;
- 中Warehouse(8核):4 Credits/小时;
- 大Warehouse(32核):16 Credits/小时。
- 运维成本:几乎为0——Snowflake负责所有底层维护(如扩容、备份、故障恢复)。
总成本示例:
-
若每天用中Warehouse运行8小时(处理报表),每月计算成本=8304=960 Credits→ 960美元;
-
总成本=230(存储)+960(计算)=1190美元/月(比ClickHouse便宜)。
-
若24小时运行中Warehouse(实时场景),计算成本=24304=2880 Credits→ 2880美元;
-
总成本=230+2880=3110美元/月(比ClickHouse贵)。
4.3 成本对比总结
| 场景 | ClickHouse | Snowflake |
|---|---|---|
| 持续高负载(24h运行) | ✅ 更便宜 | ❌ 更贵 |
| 按需负载(每天8h) | ❌ 更贵 | ✅ 更便宜 |
| 成本可预测性 | ✅ 高(固定成本) | ❌ 低(按需波动) |
5. 生态与运维:集成能力、学习曲线与运维复杂度
除了性能和成本,生态兼容性(能否对接现有系统)和运维复杂度(是否需要专人维护)也是关键因素:
5.1 生态集成
- ClickHouse:
- 开源生态丰富:支持与Kafka、Flink、Superset、Metabase等工具集成;
- 云服务集成:需要自己写脚本(如从S3导入数据用
clickhouse-s3工具); - BI支持:部分BI工具(如Tableau)需要插件才能连接。
- Snowflake:
- 云生态深度整合:原生支持AWS S3、Azure Blob、GCP GCS,无需额外配置;
- BI支持:与Tableau、Power BI、Looker等工具“无缝对接”(直接选Snowflake作为数据源);
- 第三方工具:几乎所有主流数据工具(如dbt、Airflow)都支持Snowflake。
5.2 运维复杂度
- ClickHouse:
- 需要管理Shard-Replica集群(如新增Shard、处理副本同步);
- 监控合并进程(避免数据倾斜或合并延迟);
- 优化表结构(分区键、排序键选错会导致性能暴跌)——学习曲线较陡。
- Snowflake:
- 无需管理服务器:所有底层维护由Snowflake负责;
- 只需管理:Virtual Warehouse的大小、权限、数据加载——学习曲线平缓(会SQL就能用)。
5.3 总结
| 维度 | ClickHouse | Snowflake |
|---|---|---|
| 生态集成 | ❌ 需手动配置 | ✅ 无缝对接 |
| 运维复杂度 | ❌ 高 | ✅ 低 |
| 学习曲线 | ❌ 陡 | ✅ 平 |
6. 场景选型指南:明确“什么时候选什么”
到这里,我们可以给出具体的选型建议——不再是“哪个好”,而是“哪个适合你”:
6.1 选ClickHouse的场景
- 实时分析需求:需要秒级处理实时数据(如IoT监控、用户行为实时Dashboard);
- 高吞吐写入:每天处理10亿+条日志/事件数据;
- 成本敏感:业务负载稳定(24小时运行),不想为“弹性”支付额外费用;
- 开源生态依赖:已经在用Kafka、Flink等开源工具,需要低成本集成。
6.2 选Snowflake的场景
- 复杂查询需求:需要频繁做多表关联、窗口函数(如财务报表、用户画像);
- 弹性负载:业务有明显波峰波谷(如节日大促时临时扩容);
- 低运维需求:不想养专门的大数据团队,希望“开箱即用”;
- 云生态深度集成:已经在用AWS/Azure/GCP,需要与BI工具(如Tableau)无缝对接。
6.3 典型案例
- 选ClickHouse的公司:某电商平台用ClickHouse做实时用户行为分析,每天处理5亿条数据,成本比Snowflake低40%;
- 选Snowflake的公司:某金融机构用Snowflake做每月财务报表,复杂的多表关联查询稳定在5秒内,运维成本为0。
7. 最佳实践:各自的性能优化技巧
即使选对了工具,也需要优化才能发挥最大价值——以下是两者的核心优化技巧:
7.1 ClickHouse最佳实践
- 表设计:
- 分区键:选频繁过滤的字段(如
date),避免过大的分区(建议每天一个分区); - 排序键:选查询中常用的
GROUP BY或ORDER BY字段(如user_id+date); - 主键:尽量短(如用
UUID的前8位),避免热点Shard。
- 分区键:选频繁过滤的字段(如
- 写入优化:
- 用批量写入(每次写1万条以上),避免单条写入;
- 开启
async_merge(异步合并),减少写入延迟; - 避免更新/删除(ClickHouse对写操作的支持较弱,尽量用“追加”代替)。
- 查询优化:
- 用
PREWHERE代替WHERE(先过滤再扫描数据,提升性能); - 避免大join(尽量用
Materialized View预聚合数据); - 对高频查询用
Replica(副本)处理,减轻Shard压力。
- 用
7.2 Snowflake最佳实践
- 聚类键优化:
- 对频繁查询的字段(如
date、region)设置聚类键,让数据按聚类键排序(类似ClickHouse的排序键); - 避免过多聚类键(建议1-3个),否则会增加维护成本。
- 对频繁查询的字段(如
- Virtual Warehouse优化:
- 根据查询类型选大小:小Warehouse(2核)用于简单查询,大Warehouse(16核)用于复杂查询;
- 暂停闲置Warehouse(如夜间不用的报表Warehouse),减少成本;
- 开启“自动暂停”(默认开启),Warehouse闲置5分钟后自动暂停。
- 数据加载优化:
- 用
COPY INTO命令批量加载数据(避免频繁的小文件写入); - 将数据压缩成Parquet格式(Snowflake对Parquet的读取性能更好);
- 开启“结果缓存”(默认开启),相同查询直接用缓存结果(节省计算成本)。
- 用
8. 常见问题与解决方案
8.1 ClickHouse常见问题
- 问题:数据倾斜(某Shard数据量是其他的2倍)→ 解决方案:用
user_id % shard_num作为分片键(哈希分片),避免热点; - 问题:查询超时(并发过高)→ 解决方案:增加Shard数量,或调整
max_concurrent_queries为200; - 问题:合并延迟(写入后查询不到数据)→ 解决方案:写入时加
optimize_final=1(实时合并),或查询时用latest()函数(读取最新数据)。
8.2 Snowflake常见问题
- 问题:成本超支(月度账单突然翻倍)→ 解决方案:在Snowflake控制台设置“成本预警”(超过阈值邮件提醒),监控Warehouse的使用时间;
- 问题:冷数据查询慢(3个月前的数据查询要10秒)→ 解决方案:对冷数据设置聚类键,或用
ALTER TABLE ... CLUSTER BY重新聚类; - 问题:权限混乱(用户误删表)→ 解决方案:用RBAC(角色-based访问控制),给用户分配“只读”或“仅插入”权限。
9. 未来展望:两者的发展趋势
9.1 ClickHouse的未来
- 云原生增强:AWS、GCP等云厂商推出Managed ClickHouse服务(如AWS ClickHouse Service),降低运维成本;
- 实时能力升级:加强与Flink的集成,支持“流批一体”分析;
- 生态扩展:推出官方BI工具(如ClickHouse Dashboard),提升易用性。
9.2 Snowflake的未来
- AI集成:原生支持大语言模型(LLM),比如用自然语言生成SQL(如“Show me the top 10 products by sales last month”);
- 实时性能提升:优化Snowpipe的写入延迟(目标从5秒降到1秒);
- 多云支持:推出“跨云数据共享”,让AWS和Azure的Snowflake用户可以直接交换数据。
10. 总结与选型流程图
10.1 核心结论
ClickHouse和Snowflake都是优秀的工具,但定位完全不同:
- ClickHouse是“实时性能优先”的工具,适合需要低延迟、高吞吐的场景;
- Snowflake是“弹性与易用优先”的工具,适合需要复杂查询、低运维的场景。
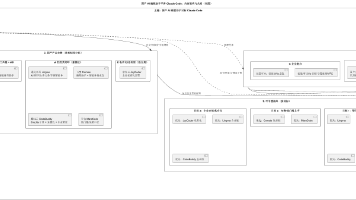
10.2 选型流程图
为了让你快速决策,我们整理了选型流程图:
参考资料
- ClickHouse官方文档:https://clickhouse.com/docs
- Snowflake官方文档:https://docs.snowflake.com
- DB-Engines OLAP排名:https://db-engines.com/en/ranking/olap
- Percona ClickHouse性能测试:https://www.percona.com/blog/clickhouse-performance-benchmark/
附录:完整代码示例(可选)
- ClickHouse表设计示例(用户行为表):
CREATE TABLE user_action ( user_id UUID, action String, timestamp DateTime, page String ) ENGINE = MergeTree() PARTITION BY toDate(timestamp) -- 按日期分区 ORDER BY (user_id, timestamp) -- 按用户ID+时间排序 SETTINGS index_granularity = 8192; -- 索引粒度(默认8192) - Snowflake表设计示例(订单表):
CREATE TABLE orders ( order_id INT, user_id INT, amount DECIMAL(10,2), order_date DATE ) CLUSTER BY (order_date); -- 按订单日期聚类
最后的话
技术选型从来不是“选最好的”,而是“选最适合的”。ClickHouse和Snowflake没有绝对的胜负——关键是匹配你的业务需求。
如果你的业务需要实时性,选ClickHouse;如果需要易用性与弹性,选Snowflake。
希望这篇文章能帮你跳出“ feature 对比”的误区,真正理解工具背后的逻辑——毕竟,懂“为什么”比懂“是什么”更重要。
如果有疑问,欢迎在评论区留言讨论!
作者:[你的名字]
公众号:[你的技术公众号]
GitHub:[你的GitHub地址]
备注:本文测试数据基于AWS云环境,实际结果可能因配置不同而变化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)