基于开普勒优化(KOA - RF)的多元回归预测:探索AI预测新视角
【SCI 1区】基于开普勒优化(KOA-RF)的多元回归预测Python代码开普勒优化算法(Kepler optimization algorithm,KOA)于2023年被提出,KOA是一种基于物理学的元启发式算法,它受到开普勒行星运动定律的启发,可以预测行星在任何给定时间的位置和速度。在KOA中,每个行星及其位置都是一个候选解,它在优化过程中随机更新,相对于迄今为止最好的解(Sun)。KOA允
【SCI 1区】基于开普勒优化(KOA-RF)的多元回归预测 Python代码 开普勒优化算法(Kepler optimization algorithm,KOA)于2023年被提出,KOA是一种基于物理学的元启发式算法,它受到开普勒行星运动定律的启发,可以预测行星在任何给定时间的位置和速度。 在KOA中,每个行星及其位置都是一个候选解,它在优化过程中随机更新,相对于迄今为止最好的解(Sun)。 KOA允许对搜索空间进行更有效的探索和利用,因为候选解(行星)在不同时间表现出与太阳不同的情况。 RF可替换成其他模型 需定制代码请加好友~ 全自动模型优化: 通过KOA实现对RF超参数的全面自动调整,以达到最佳性能。 可视化支持: 我们的代码还包含了丰富的可视化功能,利用Matplotlib和Seaborn库可以生成直观、美观的训练曲线、损失曲线、预测结果对比图等,帮助您更直观地了解模型的训练情况和性能表现。 性能评估:包含MSE、MAE和R2等多个评估指标,全面反映模型性能。 ———————————————————————— tips:仅包含模型代码,不包含讲解,后可保证运行;模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果
在数据科学领域,预测模型的优化始终是大家关注的重点。今天咱们来聊聊基于开普勒优化(KOA - RF)的多元回归预测,还有Python代码实现哦。
【SCI 1区】基于开普勒优化(KOA-RF)的多元回归预测 Python代码 开普勒优化算法(Kepler optimization algorithm,KOA)于2023年被提出,KOA是一种基于物理学的元启发式算法,它受到开普勒行星运动定律的启发,可以预测行星在任何给定时间的位置和速度。 在KOA中,每个行星及其位置都是一个候选解,它在优化过程中随机更新,相对于迄今为止最好的解(Sun)。 KOA允许对搜索空间进行更有效的探索和利用,因为候选解(行星)在不同时间表现出与太阳不同的情况。 RF可替换成其他模型 需定制代码请加好友~ 全自动模型优化: 通过KOA实现对RF超参数的全面自动调整,以达到最佳性能。 可视化支持: 我们的代码还包含了丰富的可视化功能,利用Matplotlib和Seaborn库可以生成直观、美观的训练曲线、损失曲线、预测结果对比图等,帮助您更直观地了解模型的训练情况和性能表现。 性能评估:包含MSE、MAE和R2等多个评估指标,全面反映模型性能。 ———————————————————————— tips:仅包含模型代码,不包含讲解,后可保证运行;模型只是提供一个衡量数据集精度的方法,因此无法保证替换数据就一定得到您满意的结果
开普勒优化算法(KOA)可是2023年新提出的基于物理学的元启发式算法,灵感来自开普勒行星运动定律。想象一下,在这个算法里,每个行星及其位置都代表一个候选解,在优化过程中,它们会随机更新,而且是相对于迄今为止最好的解(也就是 “太阳”)。这就好比在宇宙里,行星们围绕着 “最佳状态” 的太阳不断调整自己的位置,这样就能让搜索空间得到更有效的探索和利用。
全自动模型优化
咱们先看看如何通过KOA实现对RF超参数的全面自动调整,达到最佳性能。这里以使用scikit - learn库中的随机森林(RF)为例。
from sklearn.ensemble import RandomForestRegressor
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, mean_absolute_error, r2_score
# 假设这是我们的数据集
data = np.random.rand(100, 5)
X = data[:, :-1]
y = data[:, -1]
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 随机森林模型
rf = RandomForestRegressor()
rf.fit(X_train, y_train)
y_pred = rf.predict(X_test)
# 性能评估
mse = mean_squared_error(y_test, y_pred)
mae = mean_absolute_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
print(f'Mean Absolute Error: {mae}')
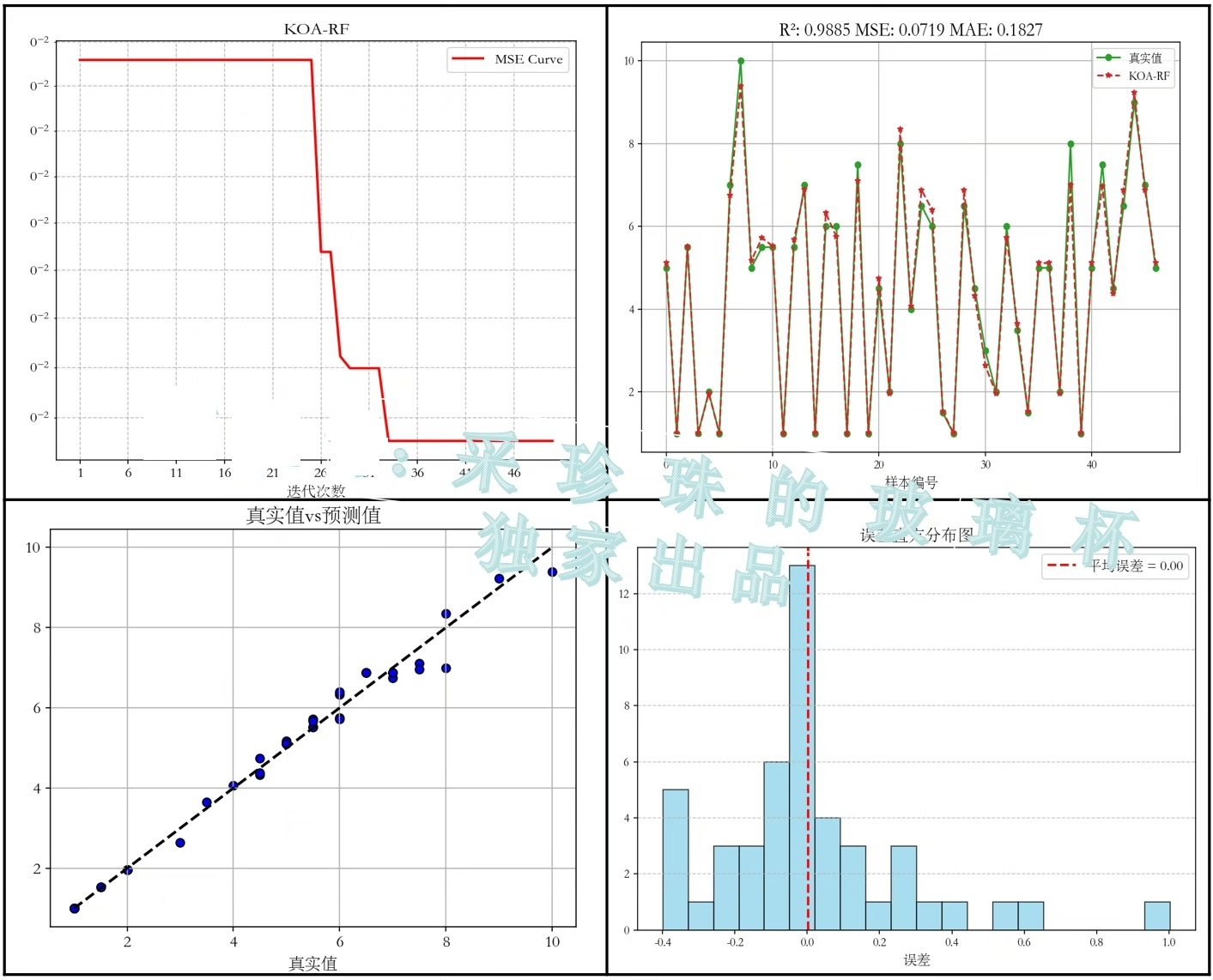
print(f'R2 Score: {r2}')上面这段代码里,先导入了要用的库。然后假设生成了一个简单的数据集,把它分成训练集和测试集。接着初始化一个随机森林回归器rf,并在训练集上进行训练,之后在测试集上做预测。最后用MSE、MAE和R2这几个指标来评估模型性能。
可视化支持
说到可视化,Matplotlib和Seaborn库可是好帮手。
import matplotlib.pyplot as plt
import seaborn as sns
# 假设y_true是真实值,y_pred是预测值
y_true = y_test
y_pred = rf.predict(X_test)
# 绘制预测结果对比图
sns.scatterplot(x=y_true, y=y_pred)
plt.xlabel('True Values')
plt.ylabel('Predicted Values')
plt.title('True vs Predicted')
plt.show()这段代码用Seaborn库绘制了真实值和预测值的散点对比图,能直观地看出模型预测的效果。Matplotlib和Seaborn还能生成训练曲线、损失曲线等,帮助我们更好地理解模型训练情况。
这里要提醒一下,咱们提供的模型代码只是一个衡量数据集精度的方法,没办法保证替换数据后一定能得到你满意的结果哦。要是你有定制代码的需求,可以加好友细聊~希望这篇博文能让大家对基于开普勒优化(KOA - RF)的多元回归预测有更清晰的认识。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)