AI速报系列:Gemini 3.1 Pro Introduction
谷歌发布Gemini 3.1 Pro,强化复杂任务处理能力。该模型基于原生多模态架构,整合了Deep Think推理技术,显著提升了跨学科科研、软件工程等复杂问题的解决能力。采用MoE架构动态分配任务,支持连续视频和音频流处理。定价策略较竞品更具优势,输入端便宜60%。安全测试显示其风险可控,未达到自主进化警戒线。基准测试表明,Gemini 3.1 Pro重新确立了谷歌在AI领域的领先地位。

2026/2/20 谷歌发布了GEMINI 3.1 PRO, 那么让我们来看看这一范式相比之前的改变。 虽然谷歌一般在重大更新的时候会使用 .5 标识 例如 Gemini 2.5 pro 但是这次使用的是 .1 标识。
Gemini 3.1 Pro 的设计初衷是为了解决需要强逻辑的复杂问题 。在 Gemini 3 系列的原生多模态(Native Multimodality)基础之上,并整合了先前发布的 Gemini 3 Deep Think 模式所积累的推理技术 。通过引入更为复杂的推理算法,3.1 Pro 能够处理跨学科的科研课题、多步骤的软件工程项目以及长程的任务规划 。这种能力的提升使得 AI 不再仅仅是一个对话助手,而是一个能够主动规划、自我修正并最终交付成果的智能代理(Agent)。 其实这也是近期的大方向 例如 Z.ai 的 GLM 5 , Antrophic 的 4.6 opus 更聚焦于 agentic 这种操作模式 (不过近期其实也迎来了新玩法 例如 agent swarm 这种AI自动化制作的multi agent 系统 )
回顾一下谷歌的历代模型
| 版本号 | 发布日期 | 状态 | 核心技术变革描述 |
|---|---|---|---|
| Bard (LaMDA) | 2023年3月21日 | 已停用 | 谷歌首次尝试实验性对话服务 |
| Gemini 1.0 (Pro/Ultra) | 2023年12月 | 已停用 | 原生多模态设计的开端 |
| Gemini 1.5 Pro | 2024年2月15日 | 已停用 | 引入百万级长上下文窗口 |
| Gemini 2.0 Flash | 2025年1月30日 | 已停用 | 聚焦多模态速度与代理交互可靠性 |
| Gemini 2.5 Pro | 2025年3月25日 | 活跃 | 引入初步的“Deep Think”推理模式 |
| Gemini 3 Pro | 2025年11月18日 | 活跃 | 稀疏混合专家架构 (Sparse MoE) 的全面应用 |
| Gemini 3 Flash | 2025年12月17日 | 活跃 | 平衡速度、成本与 Pro 级智能的边缘优化 |
| Gemini 3.1 Pro | 2026年2月19日 | 活跃 | 推理性能翻倍,全面优化代理化工作流 |
Gemini 3.1 Pro 的发布处于行业竞争激烈的阶段, GLM5 opus4.6 GPT5.3 但是GeminI 3.1 pro 的发布属于是证明了 谷歌 在人工智能一直都是领头羊天花板的实力 , 可以直接看benchmark 和竞技场投票 :
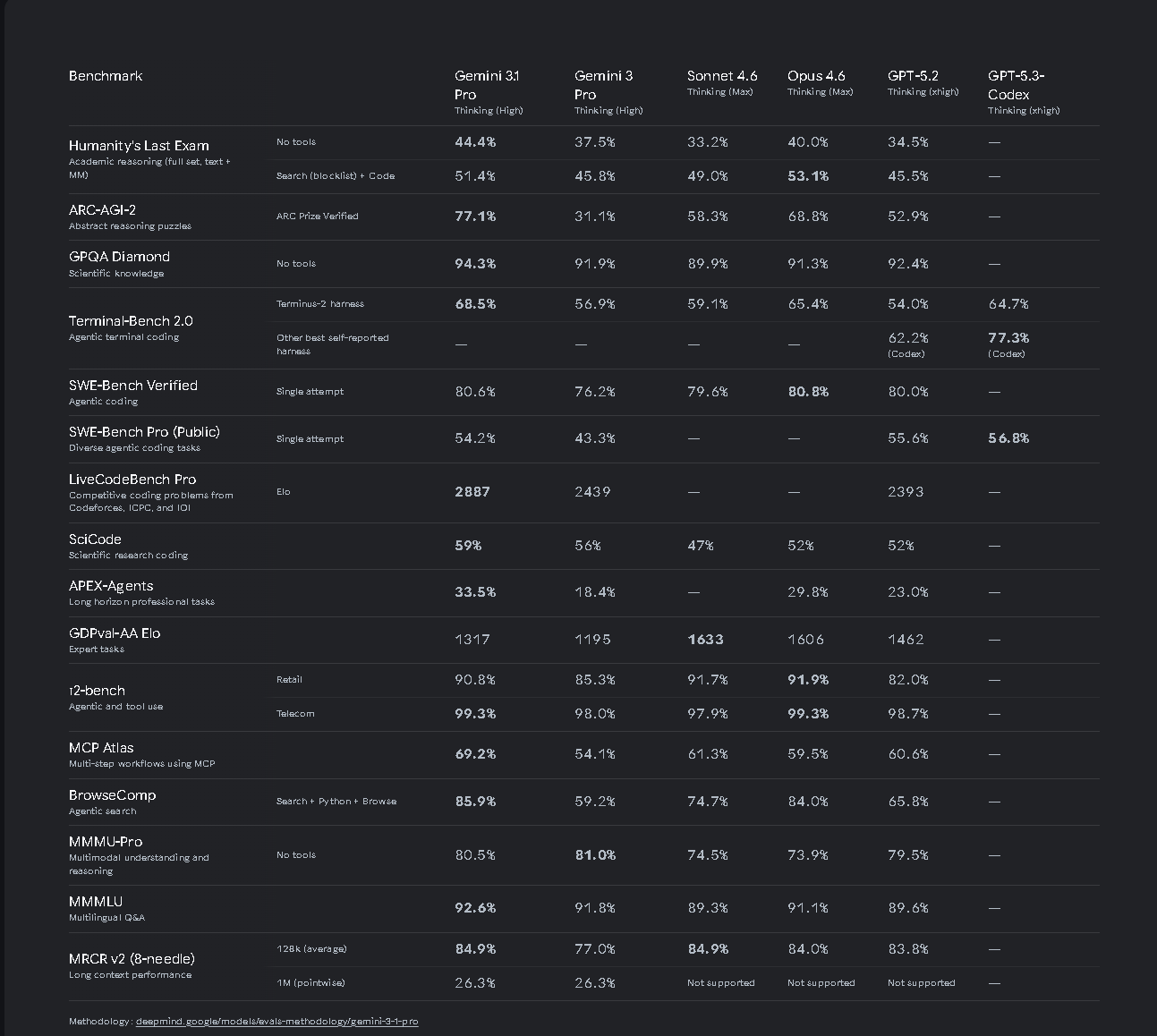
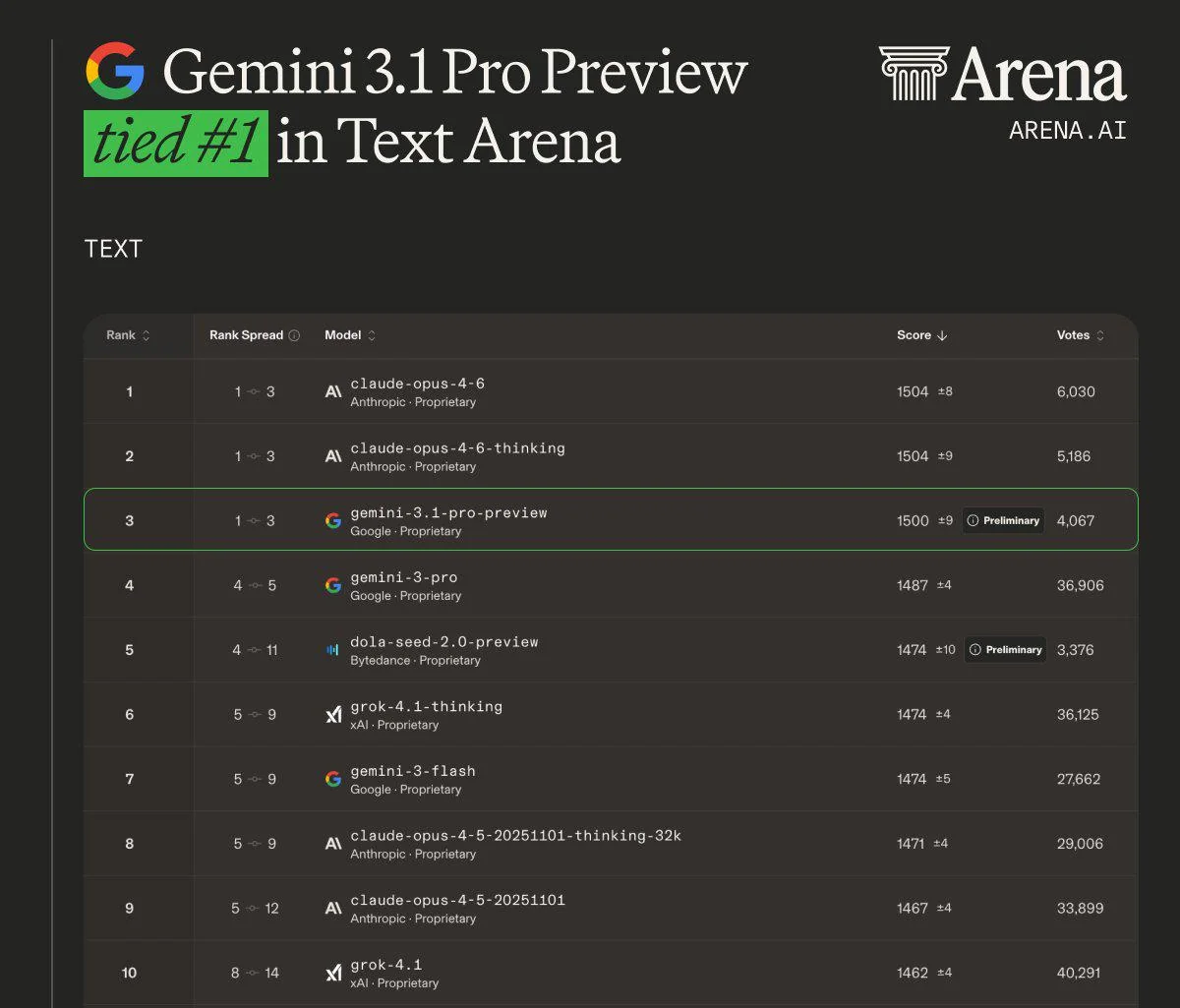
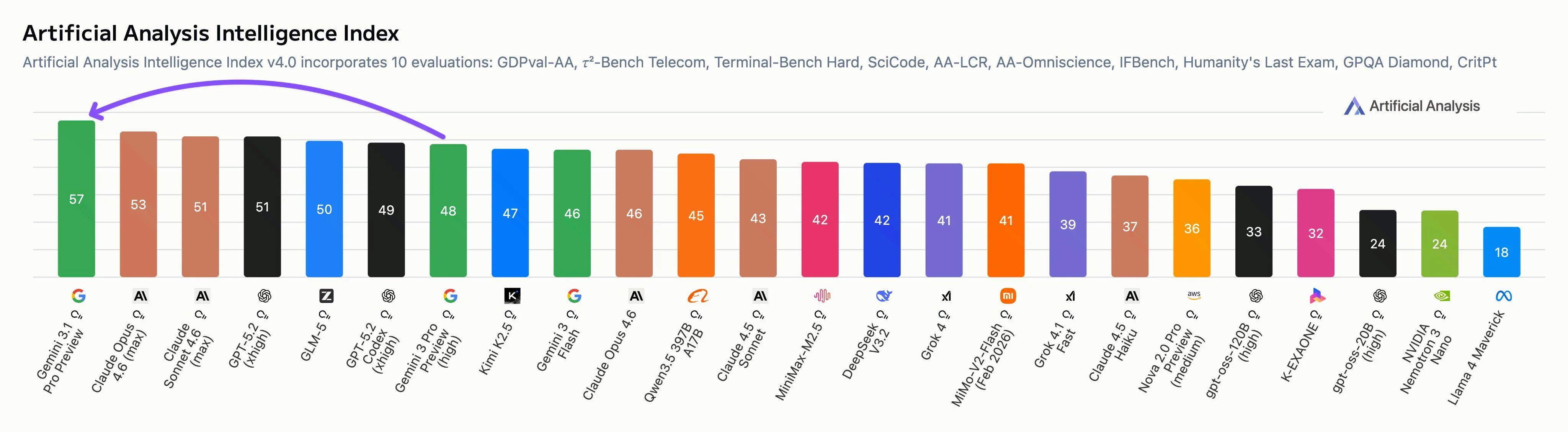
可以清晰的看见谷歌这次3.1 实力的飞跃
Gemini 3.1 pro 模型架构:
- MoE (混合专家)
- 原生多模态
MoE 简单来说就是 模型会动态地根据输入数据的类型(如文本、代码、图像特征或音频频谱)将 Token 路由(Route)给最合适的专家子网络,也就是这个模型里面有各个专家 它们有各种自己擅长的事,会自动分配任务到专家,这样就只用运行专家网络就行。 详细可以看我之前发布的文章
原生多模态 (Unified Native Multimodality)
与市面上许多通过“拼凑”不同模态模型的方案不同 (大多数模型(如早期的 GPT-4V)其实是把几个独立的模型“缝合”在一起。它有一个专门管视觉的模型,先把图片翻译成电脑能懂的语言,再传给负责逻辑的文字模型),Gemini 3.1 Pro 是从第一行代码开始就基于原生多模态理念构建的 。 也就是 所有的神经元都是同时学习文字、图片、音频和视频的。它不需要中间商翻译,它的神经元能直接“感知”像素和波形
这种原生多模态有几个好处:
它能瞬间完成“跨界思考”。由于它是原生训练的,它能直接在脑子里把声音,画面,文字联系起来。
它能直接处理连续的视频流和原始音频流 ,其实也就是理解动态 ,动态包括什么节奏 ,就说话举例 说话可以压不同的重音 会有不同的强调重点。
API 计费结构明细
Gemini 3.1 Pro 的价格表:
| 计费项目 | <= 200k Token 环境下单价 (每百万 Token) | > 200k Token 环境下单价 (每百万 Token) |
|---|---|---|
| 输入 (Input) | $2.00 | $4.00 |
| 输出 (Output) | $12.00 | $18.00 |
| 上下文缓存 (Caching) | $0.20 | $0.40 |
| 搜索增强 (Grounding) | 5000 次/月免费,后 $14 / 1000 次查询 | 同左 |
相比于 Anthropic 的 Claude Opus 4.6,Gemini 3.1 Pro 在输入端便宜了约 60%,在输出端便宜了约 52%,可见Gemini3.1pro具有极高的性价比竞争力 。
安全性、合规性与前沿风险控制
谷歌在 Gemini 3.1 Pro 的开发过程中,运用“前沿安全(Frontier Safety)”框架来测试模型安全性。谷歌披露了针对几种极端风险的测试结果
| 风险领域 | 评估结论 (基于 3.1 Pro / Deep Think) | 安全阈值状态 |
|---|---|---|
| 化学/生物/放射性 (CBRN) | 模型能提供准确信息,但无法生成用于制造大规模杀伤性武器的独特关键指令 | 未达到警告水平 |
| 网络安全 (Cyber) | 模型展示了比前代更强的漏洞识别能力,已触及警报阈值,但尚未达到显著提升低水平黑客能力的程度 | 触发警报阈值 |
| 有害操纵 (Harmful Manipulation) | 针对信仰改变的测试显示其操纵效力低于非 AI 基准的警戒线,最高赔率比为 3.6x | 未达到警告水平 |
| 机器学习自主研发 | 在 RE-Bench 测试中得分提高 22%,展现出辅助开发新型 AI 模型的能力提升 | 未达到自主进化风险 |
回望谷歌在 AI 赛道的这一路,总难免生出几分唏嘘。
它曾是当之无愧的行业奠基者与领头羊,Transformer 架构的横空出世,为整个大模型时代铺好了路,很长一段时间里,谷歌都握着 AI 领域最核心的技术话语权。可生成式 AI 的浪潮来得猝不及防,ChatGPT 的一夜爆火,让这家习惯了领跑的巨头,瞬间陷入了被动追赶的境地,产品落地的滞后、发布会的翻车、外界的唱衰,一度让它从云端跌落。
直到今天,当 Gemini 3.1 Pro 稳稳地站在行业基准测试的头部位置,补齐了推理、长上下文、多模态的所有短板,再回望这段路,才生出几分释然。没有什么一骑绝尘的传奇,也没有什么酣畅淋漓的逆袭,不过是一家坚持不懈的公司,在浪潮里摔过跤、慌过神,最终还是凭着骨子里的技术底色,跌跌撞撞地,重新走回了它本该在的位置。
[Google 官方博客: Gemini 3.1 Pro: A smarter model for your most complex tasks]
https://blog.google/innovation-and-ai/models-and-research/gemini-models/gemini-3-1-pro/
[Google DeepMind 模型卡: Gemini 3.1 Pro]
https://deepmind.google/models/model-cards/gemini-3-1-pro/
[权威媒体报道 LiveMint: Google launches Gemini 3.1 Pro with advanced reasoning abilities]
[权威媒体报道 India Today: Gemini 3.1 Pro is here, benchmarks says Google is once again leader in AI]
[Google Cloud / Vertex AI 官方文档: Gemini 3.1 Pro]
https://docs.cloud.google.com/vertex-ai/generative-ai/docs/models/gemini/3-1-pro
[开发者更新日志: Release notes | Gemini API]
https://ai.google.dev/gemini-api/docs/changelog
[前沿安全评估报告 Google DeepMind: Gemini 3.1 Pro]

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)