AI Agent的“记忆困境“与破局之道
摘要: 当前AI应用普遍面临"记忆缺失"问题,传统解决方案(扩大上下文窗口、RAG检索、微调模型)存在成本高、信息稀释或隐私风险等局限。本文提出构建独立记忆系统的必要性,借鉴人类记忆的分层特性,设计三层架构(L0抽象→L1概览→L2细节),结合智能提取和语义检索,实现主动加工而非被动存储。通过结构化提取关键信息并动态加权检索,使AI具备理解、组织和遗忘的能力,真正突破"
Cortex Memory 是一个基于Rust构建的高性能AI记忆框架,为AI智能体提供持久化、智能化的长期记忆能力。它采用独特的三层记忆架构(L0抽象 → L1概览 → L2细节),结合向量语义检索和智能知识提取,让AI真正"记住"用户。
⭐ GitHub 开源: https://github.com/sopaco/cortex-mem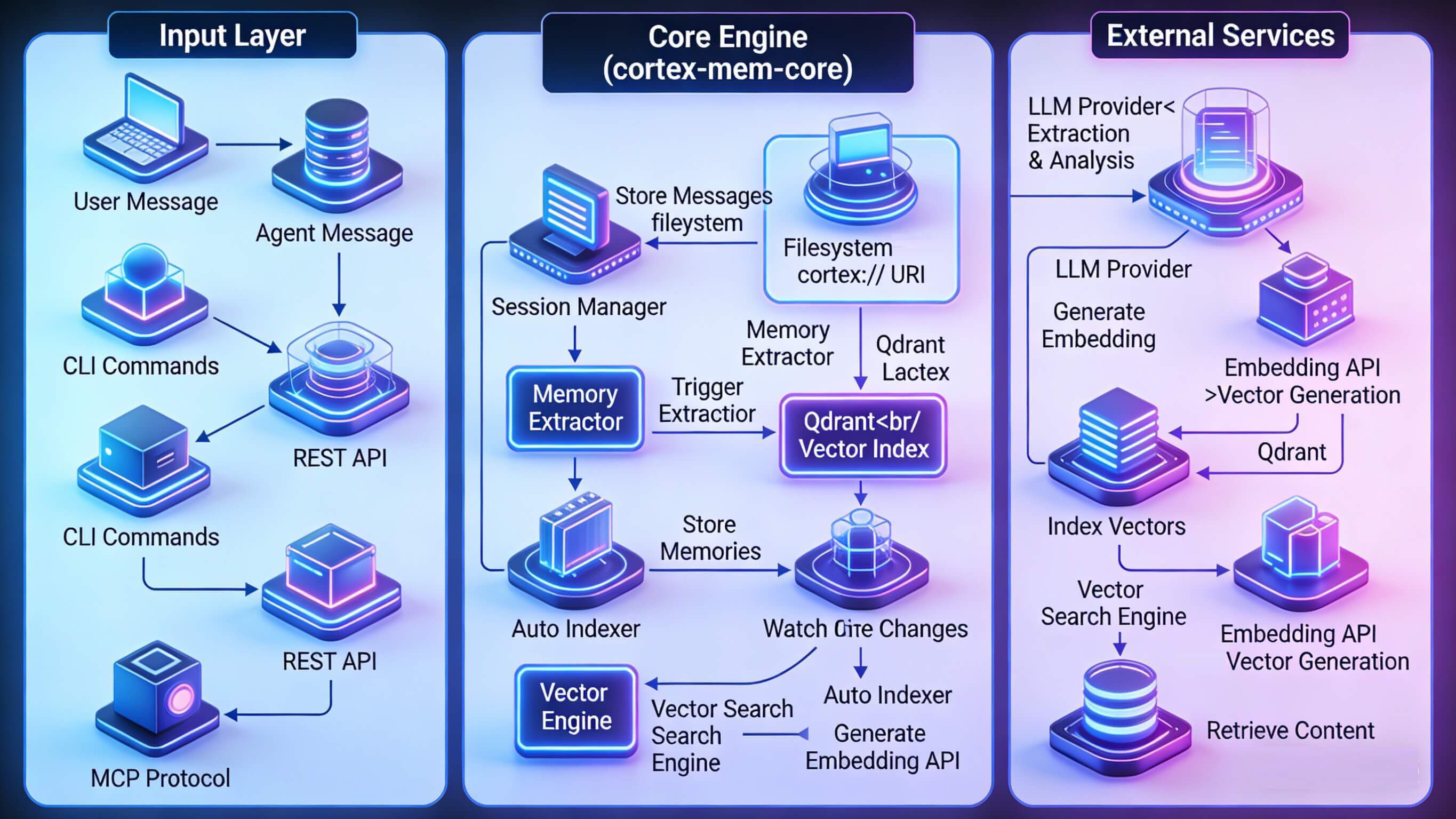
本篇主题:从行业痛点出发,探讨当前AI应用普遍面临的"记忆缺失"问题,分析现有方案的局限性,并提出构建独立记忆系统的必要性。
当我们谈论AI智能体的"智能"时,往往忽略了最基础的能力——记住。
一个真实的场景
你有没有这样的经历:和ChatGPT聊了一个下午,详细讨论了你的项目架构、技术选型、团队情况。第二天你兴冲冲地打开新对话,想继续昨天的讨论——却发现它对你的项目一无所知。
这不是bug,这是当前AI应用的"出厂设置"。
在AI行业狂飙突进的2024-2025年,我们见证了Claude、GPT-4o、Gemini在推理能力上的飞跃,也看到了Figure机器人叠衣服的惊艳演示。但有一个问题始终萦绕在从业者心头:为什么我们的AI助手仍然像一条金鱼,只有7秒的记忆?
记忆困境的本质
让我们把视角拉高一点。
传统软件系统天生带有"记忆"——数据库、缓存、文件系统,每一条数据都有它的归宿。但LLM(大语言模型)从设计哲学上就是"无状态"的:每一次对话都是全新的开始,模型参数冻结后就不再变化。
这种设计有其合理性——它保证了模型输出的可控性和可预测性。但对于构建真正的AI助手来说,这成了一个致命的短板。
想想看,一个不能记住你名字、偏好、过去对话的助手,能称之为"智能"吗?
行业的不完美尝试
这个问题并非没人意识到。事实上,市面上已经出现了多种尝试:
方案一:扩大上下文窗口
“既然模型记不住,那就把历史对话都塞进上下文里。”
从4K到128K,再到Claude的200K、Gemini的1M tokens,上下文窗口竞赛从未停止。但这个方案有几个显而易见的问题:
- 成本爆炸:每次对话都要重新处理历史,token消耗呈线性增长
- 信息稀释:在百万tokens中找到关键信息,就像大海捞针
- 无法跨会话:新开一个对话,一切归零
方案二:RAG检索增强
“那就用向量数据库检索相关历史。”
RAG(Retrieval-Augmented Generation)确实是当前的主流方案。但大多数实现存在一个根本性的缺陷:它们只存储,不理解。
把对话记录切片、向量化、存入数据库——这个过程本身没问题。但问题在于:原始对话并不等于"记忆"。人类记忆是一个高度结构化、分层级、会遗忘和强化的系统,而不是一个平铺的文档库。
方案三:微调模型
“把用户偏好训练进模型参数里。”
这个想法很美好,但现实很骨感。微调成本高昂、更新周期长、容易过拟合,而且——你怎么确保用户隐私数据不会被泄露到模型参数中?
一个不同的思路
说到这里,我想分享一个观点:AI的记忆系统,不应该是一个"补丁",而应该是一个"器官"。
什么是器官?它有明确的功能定位、有清晰的输入输出、有自我维护的机制。它不是简单地存储数据,而是对数据进行理解、组织、提取和遗忘。
这个认知,源于我在构建Cortex Memory时的思考。
我观察到,人类记忆有几个关键特征是当前AI系统普遍缺失的:
- 分层组织:我们能记住一个事件的"大意"(抽象层),也能回忆起具体细节(细节层),根据需要在不同精度间切换
- 自动提炼:对话结束后,大脑会自动提取关键信息形成长期记忆,而非原封不动存储
- 语义检索:我们不是按关键词回忆,而是按"意义"关联
- 动态遗忘:不重要的信息会被逐渐淡化,避免记忆过载
这些特征指向一个方向:AI记忆系统需要一套独立的架构,而非简单地在现有系统上"打补丁"。
记忆系统的核心架构
基于上述思考,一个真正有效的AI记忆系统应该是什么样的?
这个架构的核心思想是:记忆不是被动存储,而是主动加工。
当一段对话发生时,系统不仅保存原始内容,还会调用LLM自动提取关键事实、决策和实体。这些提取出的信息会被组织成用户画像,形成持久化的知识库。当需要回忆时,系统通过语义理解而非关键词匹配来检索,并根据查询意图自动选择合适的精度层级。
三层记忆的精妙之处
这里我想重点谈谈"三层记忆架构"的设计哲学。
为什么是三层?这不是拍脑袋决定的。
想象你在图书馆找一本书。你不会一上来就去翻每本书的全文(太慢),也不会只看书名(太粗糙)。你会先浏览分类目录,找到相关区域;然后看书架上的书脊摘要,锁定几本候选;最后才翻开具体的书页内容。
这就是三层记忆的工作方式:
L0抽象层:用一句话描述"这段对话大体在说什么"。比如"用户讨论了微服务架构的迁移方案"。这层信息量最小,但能快速排除不相关内容。
L1概览层:结构化的摘要,包含关键决策、涉及实体、核心结论。这层提供足够的上下文,让你判断是否需要深入。
L2细节层:原始对话的完整记录。当你确定这段对话相关,才加载全部内容。
检索时,三层协同工作:
最终得分 = 0.2 × L0相似度 + 0.3 × L1相似度 + 0.5 × L2相似度
这个加权公式背后的逻辑是:抽象层提供快速筛选能力,概览层提供上下文判断,细节层提供最终确认。由粗到精,逐层收敛。
从"能记"到"会记"
有了分层架构,另一个问题随之而来:系统怎么知道该记住什么?
这就是智能提取的价值所在。
当你告诉AI助手"我最近在减肥,对高糖食物比较敏感",这句话如果原封不动存入数据库,下次搜索"用户喜欢什么食物"可能就找不到。但如果系统能够提取出:
事实: 用户正在减肥,偏好低糖饮食
类别: 偏好
置信度: 0.85
重要性: 中
那么下次推荐餐厅时,AI就能自然地避开甜品店。
这种提取能力依赖于LLM的结构化输出。通过精心设计的Prompt,系统能够从自然语言对话中抽取出结构化的事实、决策和实体,自动构建用户画像。
这种机制让AI不再只是"记住了",而是"理解了"。它知道哪些信息是重要的,应该归到哪个类别,和其他信息有什么关联。
记忆的多维度视角
还有一个容易被忽视的问题:记忆的"归属"。
一段对话,可能同时涉及用户偏好、会话上下文、AI助手的知识边界。一个好的记忆系统需要能够从多个维度组织和检索记忆。
- 用户维度:记录用户的长期偏好、背景、目标,形成"用户画像"
- 会话维度:记录特定对话的上下文,便于后续引用
- 助手维度:记录AI助手从对话中学到的知识边界和能力盲区
- 资源维度:记录对话中提及的外部资源、链接、文档
这种多维组织让检索更加精准。当用户问"上次那个Python教程",系统可以在会话维度找到"上次"的上下文,在资源维度找到"Python教程",精准定位到用户想要的信息。
写在最后
回到开头的问题:为什么AI助手像金鱼?
答案已经清晰了——不是技术能力不够,而是架构设计缺失。我们花了太多精力在让AI"更聪明"(更强的推理能力),却忽视了让它"更持久"(更好的记忆系统)。
好在,行业正在觉醒。从LangChain的Memory模块,到MemGPT的长期记忆方案,再到MCP协议对上下文共享的标准化尝试,"记忆"正在成为AI工程化的核心议题。
而我认为,一个真正成熟的AI记忆系统,应该做到:
- 不只是存储,而是理解、组织、提炼
- 不只是检索,而是根据意图智能召回
- 不只是单一维度,而是多视角组织
- 不只是会话内,而是跨会话持久化
这条路还很长,但方向已经明确。当AI真正拥有了记忆,它才能从一个"工具",进化为一个"伙伴"。
下一篇文章,我将深入探讨"三层记忆架构的设计哲学",分享Cortex Memory在技术实现层面的思考与权衡。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)