黑马大模型RAG与Agent智能体实战教程LangChain提示词——28、RAG开发——PyPDFLoader(PDF加载器、pypdf、document对象、文件对象)
查看现有文件结构,了解代码风格,然后创建 PyPDFLoader 示例文件。创建 PyPDFLoader 示例文件,参考现有代码风格。检查代码中的 lint 错误:已创建 PyPDFLoader 示例文件。PyPDFLoader 简介:说明它是 LangChain 中的 PDF 加载器,需要安装pypdf库6 个示例示例1:基本用法mode参数对比(pagevssinglepassword参数(加
教程:https://www.bilibili.com/video/BV1yjz5BLEoY
代码:https://github.com/shangxiang0907/HeiMa-AI-LLM-RAG-Agent-Dev
文章目录
RAG开发-26、PyPDFLoader
介绍
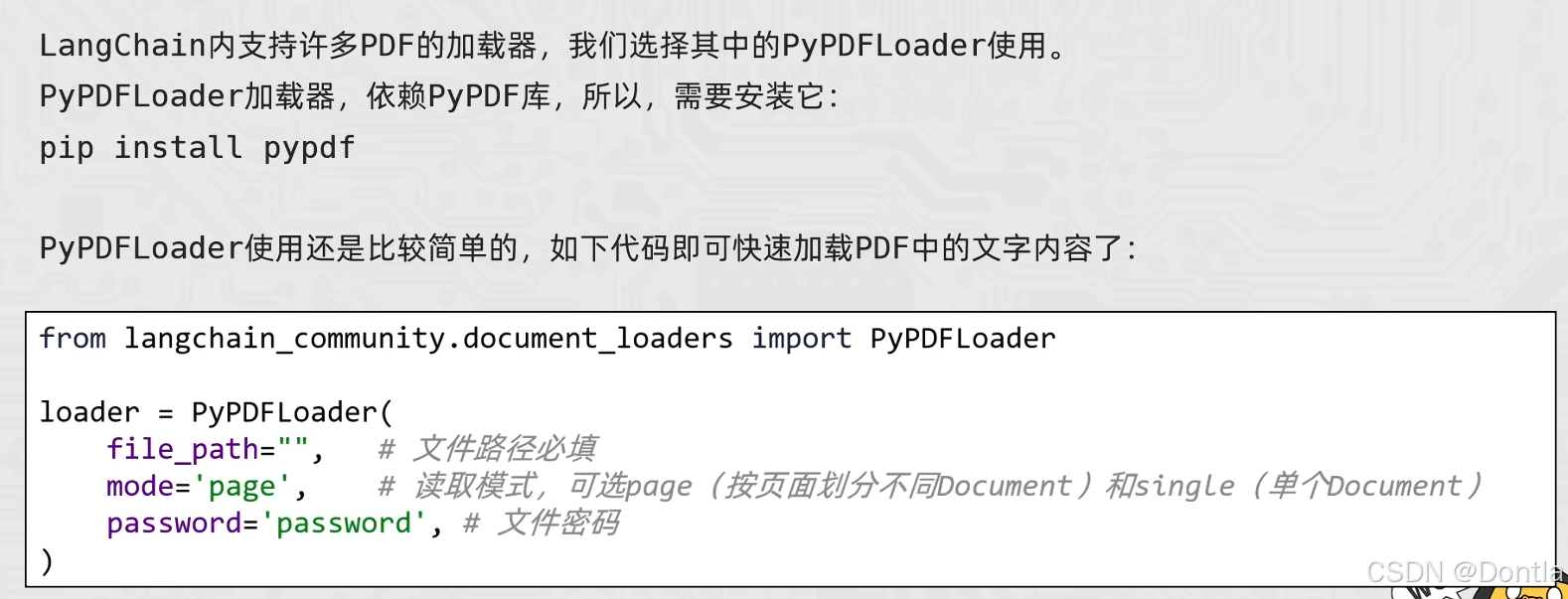
pip install pypdf
→提示词:帮我根据图中内容,在目录@AI_LLM_RAG_Agent_Dev 中创建代码31,介绍PyPDFLoader
←AI回复
查看现有文件结构,了解代码风格,然后创建 PyPDFLoader 示例文件。
[2 tools called]
创建 PyPDFLoader 示例文件,参考现有代码风格。
[1 tool called]
检查代码中的 lint 错误:
[1 tool called]
已创建 PyPDFLoader 示例文件 31_LangChain_PyPDFLoader.py。文件包含:
-
PyPDFLoader 简介:说明它是 LangChain 中的 PDF 加载器,需要安装
pypdf库 -
6 个示例:
- 示例1:基本用法
- 示例2:
mode参数对比(pagevssingle) - 示例3:
password参数(加密 PDF) - 示例4:文档元数据
- 示例5:
lazy_load()方法 - 示例6:安装要求
-
参数说明:
file_path:文件路径(必填)mode:读取模式,'page'(按页面划分)或'single'(单个 Document)password:文件密码(可选)
代码风格与现有文件(如 30_LangChain_TextLoader.py 和 29_LangChain_JSONLoader.py)保持一致,包含详细的中文注释和说明。
注意:由于目录中已有 30_LangChain_TextLoader.py,我将新文件编号为 31。如需使用其他编号,请告知。
下载sample.pdf
https://ontheline.trincoll.edu/images/bookdown/sample-local-pdf.pdf
放到代码当前工作路径的data目录下(current working directory)
31_LangChain_PyPDFLoader.py
"""
LangChain PyPDFLoader 文档加载器示例
本示例对应课件中关于 PyPDFLoader 的内容,重点演示:
1. PyPDFLoader 简介:
- LangChain 内支持许多 PDF 的加载器,我们选择其中的 PyPDFLoader 使用
- PyPDFLoader 依赖 PyPDF 库,需要安装:pip install pypdf
- PyPDFLoader 使用简单,可以快速加载 PDF 中的文字内容
2. PyPDFLoader 参数:
- file_path: 文件路径(必填)
- mode: 读取模式,可选 'page'(按页面划分不同 Document)和 'single'(单个 Document)
- password: 文件密码(可选,用于加密的 PDF 文件)
3. mode 参数说明:
- 'page': 按页面划分,每个页面生成一个独立的 Document 对象
- 'single': 将整个 PDF 作为一个 Document 对象
核心概念:
- PyPDFLoader:用于加载 PDF 文件的文档加载器
- Document:LangChain 文档的统一载体类
- mode:文档加载模式,控制如何将 PDF 内容分割为 Document 对象
"""
import os
from typing import List
from dotenv import load_dotenv
from langchain_community.document_loaders import PyPDFLoader
from langchain_core.documents import Document
def create_sample_pdf() -> str:
"""
创建示例 PDF 文件用于演示。
注意:由于创建 PDF 文件需要额外的库(如 reportlab),
这里我们假设用户会提供自己的 PDF 文件,或者使用现有的 PDF 文件。
Returns:
str: PDF 文件路径提示
"""
pdf_dir = "./data"
os.makedirs(pdf_dir, exist_ok=True)
print("提示:请将您的 PDF 文件放置在 ./data/ 目录下")
print("或者修改代码中的 file_path 参数指向您的 PDF 文件路径")
return pdf_dir
def pypdfloader_basic_demo() -> None:
"""
演示 PyPDFLoader 的基本用法。
展示如何使用 PyPDFLoader 加载 PDF 文件。
"""
print("=" * 80)
print("【示例1】PyPDFLoader 基本用法")
print("-" * 80)
# 创建数据目录
pdf_dir = create_sample_pdf()
print()
# 示例 PDF 文件路径(用户需要提供实际的 PDF 文件)
# 这里使用一个示例路径,实际使用时需要替换为真实的 PDF 文件路径
pdf_file = "./data/sample.pdf"
# 检查文件是否存在
if not os.path.exists(pdf_file):
print(f"提示:找不到文件 {pdf_file}")
print("请将您的 PDF 文件放置在该路径,或修改 pdf_file 变量指向您的 PDF 文件")
print("\n示例代码:")
print("-" * 80)
print("""
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="your_pdf_file.pdf", # 文件路径必填
mode='page', # 读取模式,可选page(按页面划分不同Document)和single(单个Document)
password='password', # 文件密码(如果PDF有密码保护)
)
docs = loader.load()
print(f"成功加载 {len(docs)} 个文档")
""")
return
# 使用 PyPDFLoader 加载 PDF 文件
print(f"使用 PyPDFLoader 加载 PDF 文件:{pdf_file}")
print("-" * 80)
try:
loader = PyPDFLoader(
file_path=pdf_file,
mode='page', # 按页面划分
)
docs = loader.load()
print(f"成功加载 {len(docs)} 个文档(页面)")
print(f"\n文档内容预览(前 3 个页面):")
print("-" * 80)
for i, doc in enumerate(docs[:3], start=1):
print(f"\n【页面 {i}】")
print(f"内容长度:{len(doc.page_content)} 个字符")
print(f"内容预览(前 200 个字符):")
print(doc.page_content[:200] + "...")
print(f"元数据:{doc.metadata}")
if len(docs) > 3:
print(f"\n... (还有 {len(docs) - 3} 个页面)")
except Exception as e:
print(f"加载失败:{e}")
print("\n可能的原因:")
print("1. PDF 文件路径不正确")
print("2. PDF 文件已损坏")
print("3. PDF 文件需要密码(请使用 password 参数)")
print("4. 未安装 pypdf 库(请运行:pip install pypdf)")
print()
def pypdfloader_mode_demo() -> None:
"""
演示 PyPDFLoader 的 mode 参数区别。
展示 'page' 模式和 'single' 模式的不同效果。
"""
print("=" * 80)
print("【示例2】PyPDFLoader - mode 参数对比")
print("-" * 80)
pdf_file = "./data/sample.pdf"
if not os.path.exists(pdf_file):
print(f"提示:找不到文件 {pdf_file},请先准备一个 PDF 文件")
return
# mode='page':按页面划分
print("\n1. mode='page' - 按页面划分不同 Document")
print("-" * 80)
try:
loader_page = PyPDFLoader(
file_path=pdf_file,
mode='page', # 每个页面生成一个 Document
)
docs_page = loader_page.load()
print(f"成功加载 {len(docs_page)} 个文档(每个页面一个文档)")
if docs_page:
print(f"第一个文档(第1页)内容长度:{len(docs_page[0].page_content)} 个字符")
print(f"第一个文档元数据:{docs_page[0].metadata}")
if len(docs_page) > 1:
print(f"第二个文档(第2页)内容长度:{len(docs_page[1].page_content)} 个字符")
except Exception as e:
print(f"加载失败:{e}")
# mode='single':单个 Document
print("\n2. mode='single' - 单个 Document")
print("-" * 80)
try:
loader_single = PyPDFLoader(
file_path=pdf_file,
mode='single', # 整个 PDF 作为一个 Document
)
docs_single = loader_single.load()
print(f"成功加载 {len(docs_single)} 个文档(整个 PDF 作为一个文档)")
if docs_single:
print(f"文档内容长度:{len(docs_single[0].page_content)} 个字符")
print(f"文档元数据:{docs_single[0].metadata}")
print(f"内容预览(前 200 个字符):")
print(docs_single[0].page_content[:200] + "...")
except Exception as e:
print(f"加载失败:{e}")
print()
def pypdfloader_password_demo() -> None:
"""
演示 PyPDFLoader 的 password 参数。
展示如何加载加密的 PDF 文件。
"""
print("=" * 80)
print("【示例3】PyPDFLoader - password 参数(加密 PDF)")
print("-" * 80)
# 示例:加载加密的 PDF 文件
encrypted_pdf_file = "./data/encrypted_sample.pdf"
if not os.path.exists(encrypted_pdf_file):
print(f"提示:找不到加密的 PDF 文件 {encrypted_pdf_file}")
print("如果您有加密的 PDF 文件,可以使用以下代码加载:")
print("-" * 80)
print("""
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="encrypted_pdf_file.pdf",
mode='page',
password='your_password', # 提供 PDF 密码
)
docs = loader.load()
""")
return
print(f"尝试加载加密的 PDF 文件:{encrypted_pdf_file}")
print("-" * 80)
# 尝试不使用密码加载(应该会失败)
print("\n1. 不使用密码加载(应该失败)")
try:
loader_no_password = PyPDFLoader(
file_path=encrypted_pdf_file,
mode='page',
)
docs = loader_no_password.load()
print("意外成功:PDF 可能没有密码保护")
except Exception as e:
print(f"预期的错误:{e}")
# 尝试使用密码加载
print("\n2. 使用密码加载")
print("提示:请将 'your_password' 替换为实际的 PDF 密码")
try:
loader_with_password = PyPDFLoader(
file_path=encrypted_pdf_file,
mode='page',
password='your_password', # 替换为实际密码
)
docs = loader_with_password.load()
print(f"成功加载 {len(docs)} 个文档")
except Exception as e:
print(f"加载失败:{e}")
print("可能的原因:密码不正确或文件路径错误")
print()
def pypdfloader_metadata_demo() -> None:
"""
演示 PyPDFLoader 加载的文档元数据。
展示 PDF 文档的元数据信息。
"""
print("=" * 80)
print("【示例4】PyPDFLoader - 文档元数据")
print("-" * 80)
pdf_file = "./data/sample.pdf"
if not os.path.exists(pdf_file):
print(f"提示:找不到文件 {pdf_file},请先准备一个 PDF 文件")
return
try:
loader = PyPDFLoader(
file_path=pdf_file,
mode='page',
)
docs = loader.load()
print(f"成功加载 {len(docs)} 个文档\n")
print("文档元数据示例:")
print("-" * 80)
# 显示前几个文档的元数据
for i, doc in enumerate(docs[:3], start=1):
print(f"\n文档 {i}(页面 {i})元数据:")
for key, value in doc.metadata.items():
print(f" {key}: {value}")
# 统计元数据字段
if docs:
all_keys = set()
for doc in docs:
all_keys.update(doc.metadata.keys())
print(f"\n所有文档共有的元数据字段:{sorted(all_keys)}")
except Exception as e:
print(f"加载失败:{e}")
print()
def pypdfloader_lazy_load_demo() -> None:
"""
演示 PyPDFLoader 的 lazy_load() 方法。
lazy_load() 方法用于延迟流式传输文档,对大型 PDF 文件很有用。
"""
print("=" * 80)
print("【示例5】PyPDFLoader lazy_load() 方法 - 延迟流式加载")
print("-" * 80)
pdf_file = "./data/sample.pdf"
if not os.path.exists(pdf_file):
print(f"提示:找不到文件 {pdf_file},请先准备一个 PDF 文件")
return
try:
loader = PyPDFLoader(
file_path=pdf_file,
mode='page',
)
print("使用 lazy_load() 方法逐个加载文档:")
print("-" * 80)
for i, document in enumerate(loader.lazy_load(), start=1):
print(f"\n文档 {i}(页面 {i}):")
print(f" 内容长度:{len(document.page_content)} 个字符")
print(f" 内容预览(前 150 个字符):{document.page_content[:150]}...")
print(f" 元数据:{document.metadata}")
if i >= 3: # 只显示前 3 个
print("\n... (其余文档省略)")
break
except Exception as e:
print(f"加载失败:{e}")
print()
def pypdfloader_installation_demo() -> None:
"""
演示 PyPDFLoader 的安装要求。
展示如何安装所需的依赖库。
"""
print("=" * 80)
print("【示例6】PyPDFLoader 安装要求")
print("-" * 80)
print("PyPDFLoader 依赖 PyPDF 库,需要先安装:")
print("-" * 80)
print("\n安装命令:")
print(" pip install pypdf")
print("\n或者使用 conda:")
print(" conda install -c conda-forge pypdf")
print("\n验证安装:")
print("-" * 80)
try:
import pypdf
print(f"✓ PyPDF 已安装,版本:{pypdf.__version__}")
except ImportError:
print("✗ PyPDF 未安装")
print("请运行:pip install pypdf")
try:
from langchain_community.document_loaders import PyPDFLoader
print("✓ PyPDFLoader 可以正常导入")
except ImportError as e:
print(f"✗ PyPDFLoader 导入失败:{e}")
print("请确保已安装 langchain-community:pip install langchain-community")
print()
def main() -> None:
"""
主函数:演示 PyPDFLoader 的各种使用方法。
"""
print("=" * 80)
print("LangChain PyPDFLoader 文档加载器示例")
print("=" * 80)
print()
# 加载环境变量(虽然 PyPDFLoader 不需要 API Key,但保持一致性)
load_dotenv()
# 示例6:安装要求(先运行,让用户知道需要安装什么)
pypdfloader_installation_demo()
# 示例1:PyPDFLoader 基本用法
pypdfloader_basic_demo()
# 示例2:mode 参数对比
pypdfloader_mode_demo()
# 示例3:password 参数(加密 PDF)
pypdfloader_password_demo()
# 示例4:文档元数据
pypdfloader_metadata_demo()
# 示例5:lazy_load() 方法
pypdfloader_lazy_load_demo()
print("=" * 80)
print("演示结束")
print("=" * 80)
print("\n提示:")
print("- PyPDFLoader 需要先安装 pypdf 库:pip install pypdf")
print("- 请将您的 PDF 文件放置在 ./data/ 目录下,或修改代码中的 file_path 参数")
print("- mode='page':每个页面生成一个独立的 Document 对象")
print("- mode='single':整个 PDF 作为一个 Document 对象")
print("- 如果 PDF 文件有密码保护,请使用 password 参数")
print("- 更多文档加载器请参考:https://docs.langchain.com/oss/python/integrations/document_loaders")
if __name__ == "__main__":
main()
运行代码
python3 AI_LLM_RAG_Agent_Dev/31_LangChain_PyPDFLoader.py
结果
================================================================================
LangChain PyPDFLoader 文档加载器示例
================================================================================
================================================================================
【示例6】PyPDFLoader 安装要求
--------------------------------------------------------------------------------
PyPDFLoader 依赖 PyPDF 库,需要先安装:
--------------------------------------------------------------------------------
安装命令:
pip install pypdf
或者使用 conda:
conda install -c conda-forge pypdf
验证安装:
--------------------------------------------------------------------------------
✓ PyPDF 已安装,版本:6.7.1
✓ PyPDFLoader 可以正常导入
================================================================================
【示例1】PyPDFLoader 基本用法
--------------------------------------------------------------------------------
提示:请将您的 PDF 文件放置在 ./data/ 目录下
或者修改代码中的 file_path 参数指向您的 PDF 文件路径
使用 PyPDFLoader 加载 PDF 文件:./data/sample.pdf
--------------------------------------------------------------------------------
Ignoring wrong pointing object 8 0 (offset 0)
成功加载 3 个文档(页面)
文档内容预览(前 3 个页面):
--------------------------------------------------------------------------------
【页面 1】
内容长度:2976 个字符
内容预览(前 200 个字符):
1
Sample PDF Created for testing PDFObject This PDF is three pages long. Three long pages. Or three short pages if you’re optimistic. Is it the same as saying “three long minutes”, knowing that all...
元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3, 'page': 0, 'page_label': '1'}
【页面 2】
内容长度:3584 个字符
内容预览(前 200 个字符):
2
ipsum dolor sit amet, consectetur adipiscing elit. Integer nec odio. Praesent libero. Sed cursus ante dapibus diam. Sed nisi. Nulla quis sem at nibh elementum imperdiet. Duis sagittis ipsum. Praese...
元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3, 'page': 1, 'page_label': '2'}
【页面 3】
内容长度:2638 个字符
内容预览(前 200 个字符):
3
elementum. Morbi in ipsum sit amet pede facilisis laoreet. Donec lacus nunc, viverra nec, blandit vel, egestas et, augue. Vestibulum tincidunt malesuada tellus. Ut ultrices ultrices enim. Curabitur...
元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3, 'page': 2, 'page_label': '3'}
================================================================================
【示例2】PyPDFLoader - mode 参数对比
--------------------------------------------------------------------------------
1. mode='page' - 按页面划分不同 Document
--------------------------------------------------------------------------------
Ignoring wrong pointing object 8 0 (offset 0)
成功加载 3 个文档(每个页面一个文档)
第一个文档(第1页)内容长度:2976 个字符
第一个文档元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3, 'page': 0, 'page_label': '1'}
第二个文档(第2页)内容长度:3584 个字符
2. mode='single' - 单个 Document
--------------------------------------------------------------------------------
Ignoring wrong pointing object 8 0 (offset 0)
成功加载 1 个文档(整个 PDF 作为一个文档)
文档内容长度:9202 个字符
文档元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3}
内容预览(前 200 个字符):
1
Sample PDF Created for testing PDFObject This PDF is three pages long. Three long pages. Or three short pages if you’re optimistic. Is it the same as saying “three long minutes”, knowing that all...
================================================================================
【示例3】PyPDFLoader - password 参数(加密 PDF)
--------------------------------------------------------------------------------
提示:找不到加密的 PDF 文件 ./data/encrypted_sample.pdf
如果您有加密的 PDF 文件,可以使用以下代码加载:
--------------------------------------------------------------------------------
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader(
file_path="encrypted_pdf_file.pdf",
mode='page',
password='your_password', # 提供 PDF 密码
)
docs = loader.load()
================================================================================
【示例4】PyPDFLoader - 文档元数据
--------------------------------------------------------------------------------
Ignoring wrong pointing object 8 0 (offset 0)
成功加载 3 个文档
文档元数据示例:
--------------------------------------------------------------------------------
文档 1(页面 1)元数据:
producer: Mac OS X 10.11.3 Quartz PDFContext
creator: Word
creationdate: D:20160319061844Z00'00'
title: Sample PDF
author: Philip Hutchison
subject:
moddate: D:20160319061844Z00'00'
keywords:
aapl:keywords: []
source: ./data/sample.pdf
total_pages: 3
page: 0
page_label: 1
文档 2(页面 2)元数据:
producer: Mac OS X 10.11.3 Quartz PDFContext
creator: Word
creationdate: D:20160319061844Z00'00'
title: Sample PDF
author: Philip Hutchison
subject:
moddate: D:20160319061844Z00'00'
keywords:
aapl:keywords: []
source: ./data/sample.pdf
total_pages: 3
page: 1
page_label: 2
文档 3(页面 3)元数据:
producer: Mac OS X 10.11.3 Quartz PDFContext
creator: Word
creationdate: D:20160319061844Z00'00'
title: Sample PDF
author: Philip Hutchison
subject:
moddate: D:20160319061844Z00'00'
keywords:
aapl:keywords: []
source: ./data/sample.pdf
total_pages: 3
page: 2
page_label: 3
所有文档共有的元数据字段:['aapl:keywords', 'author', 'creationdate', 'creator', 'keywords', 'moddate', 'page', 'page_label', 'producer', 'source', 'subject', 'title', 'total_pages']
================================================================================
【示例5】PyPDFLoader lazy_load() 方法 - 延迟流式加载
--------------------------------------------------------------------------------
使用 lazy_load() 方法逐个加载文档:
--------------------------------------------------------------------------------
Ignoring wrong pointing object 8 0 (offset 0)
文档 1(页面 1):
内容长度:2976 个字符
内容预览(前 150 个字符):1
Sample PDF Created for testing PDFObject This PDF is three pages long. Three long pages. Or three short pages if you’re optimistic. Is it the sam...
元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3, 'page': 0, 'page_label': '1'}
文档 2(页面 2):
内容长度:3584 个字符
内容预览(前 150 个字符):2
ipsum dolor sit amet, consectetur adipiscing elit. Integer nec odio. Praesent libero. Sed cursus ante dapibus diam. Sed nisi. Nulla quis sem at nib...
元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3, 'page': 1, 'page_label': '2'}
文档 3(页面 3):
内容长度:2638 个字符
内容预览(前 150 个字符):3
elementum. Morbi in ipsum sit amet pede facilisis laoreet. Donec lacus nunc, viverra nec, blandit vel, egestas et, augue. Vestibulum tincidunt male...
元数据:{'producer': 'Mac OS X 10.11.3 Quartz PDFContext', 'creator': 'Word', 'creationdate': "D:20160319061844Z00'00'", 'title': 'Sample PDF', 'author': 'Philip Hutchison', 'subject': '', 'moddate': "D:20160319061844Z00'00'", 'keywords': '', 'aapl:keywords': '[]', 'source': './data/sample.pdf', 'total_pages': 3, 'page': 2, 'page_label': '3'}
... (其余文档省略)
================================================================================
演示结束
================================================================================
提示:
- PyPDFLoader 需要先安装 pypdf 库:pip install pypdf
- 请将您的 PDF 文件放置在 ./data/ 目录下,或修改代码中的 file_path 参数
- mode='page':每个页面生成一个独立的 Document 对象
- mode='single':整个 PDF 作为一个 Document 对象
- 如果 PDF 文件有密码保护,请使用 password 参数
- 更多文档加载器请参考:https://docs.langchain.com/oss/python/integrations/document_loaders

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献420条内容
已为社区贡献420条内容

所有评论(0)