黑马大模型RAG与Agent智能体实战教程LangChain提示词——27、RAG开发—TextLoader和文档分割器、递归字符文本分割器RecursiveCharacterTextSplitter
查看当前文件以了解代码风格和结构。检查是否有数据目录,然后创建代码文件。创建代码文件,介绍 TextLoader 和文档分割器:检查代码是否有错误:运行代码验证是否正常工作:已创建代码文件,介绍 TextLoader 和文档分割器。
·
教程:https://www.bilibili.com/video/BV1yjz5BLEoY
代码:https://github.com/shangxiang0907/HeiMa-AI-LLM-RAG-Agent-Dev
怎么感觉分割后看不出啥效果呢?
文章目录
RAG开发-25、TextLoader和文档分割器
TextLoader介绍

RecursiveCharacterTextSplitter递归字符文本分割器
→提示词:根据图片内容,帮我创建代码30,介绍TextLoader和文档分割器
←AI回复
查看当前文件以了解代码风格和结构。
[2 tools called]
检查是否有数据目录,然后创建代码文件。
[2 tools called]
创建代码文件,介绍 TextLoader 和文档分割器:
[1 tool called]
检查代码是否有错误:
[1 tool called]
运行代码验证是否正常工作:
[1 tool called]
已创建代码文件 30_LangChain_TextLoader.py,介绍 TextLoader 和文档分割器。
创建的内容
代码文件包含以下示例:
- 示例1:TextLoader 基本用法 - 演示如何使用 TextLoader 加载文本文件
- 示例2:RecursiveCharacterTextSplitter 基本用法 - 演示如何使用递归字符文本分割器分割文档
- 示例3:参数对比 - 展示不同
chunk_size和chunk_overlap参数的效果 - 示例4:separators 参数影响 - 展示不同分隔符配置对分割结果的影响
- 示例5:encoding 参数 - 演示 TextLoader 的编码参数
- 示例6:文档分割后的元数据 - 展示分割后文档的元数据保留情况
主要特性
- 自动创建示例文本文件(
./data/Python基础语法.txt) - 完整的中文注释和说明
- 与现有代码风格保持一致
- 代码已测试,运行正常
代码已运行并通过测试。你可以直接使用这个文件来学习 TextLoader 和 RecursiveCharacterTextSplitter 的用法。
30_LangChain_TextLoader.py
"""
LangChain TextLoader 和文档分割器示例
本示例对应课件中关于 TextLoader 和 RecursiveCharacterTextSplitter 的内容,重点演示:
1. TextLoader 简介:
- TextLoader 用于将文本文件加载为 Document 类型对象
- 支持指定文件编码(默认使用系统编码)
- 可以加载各种纯文本格式的文件
2. RecursiveCharacterTextSplitter 简介:
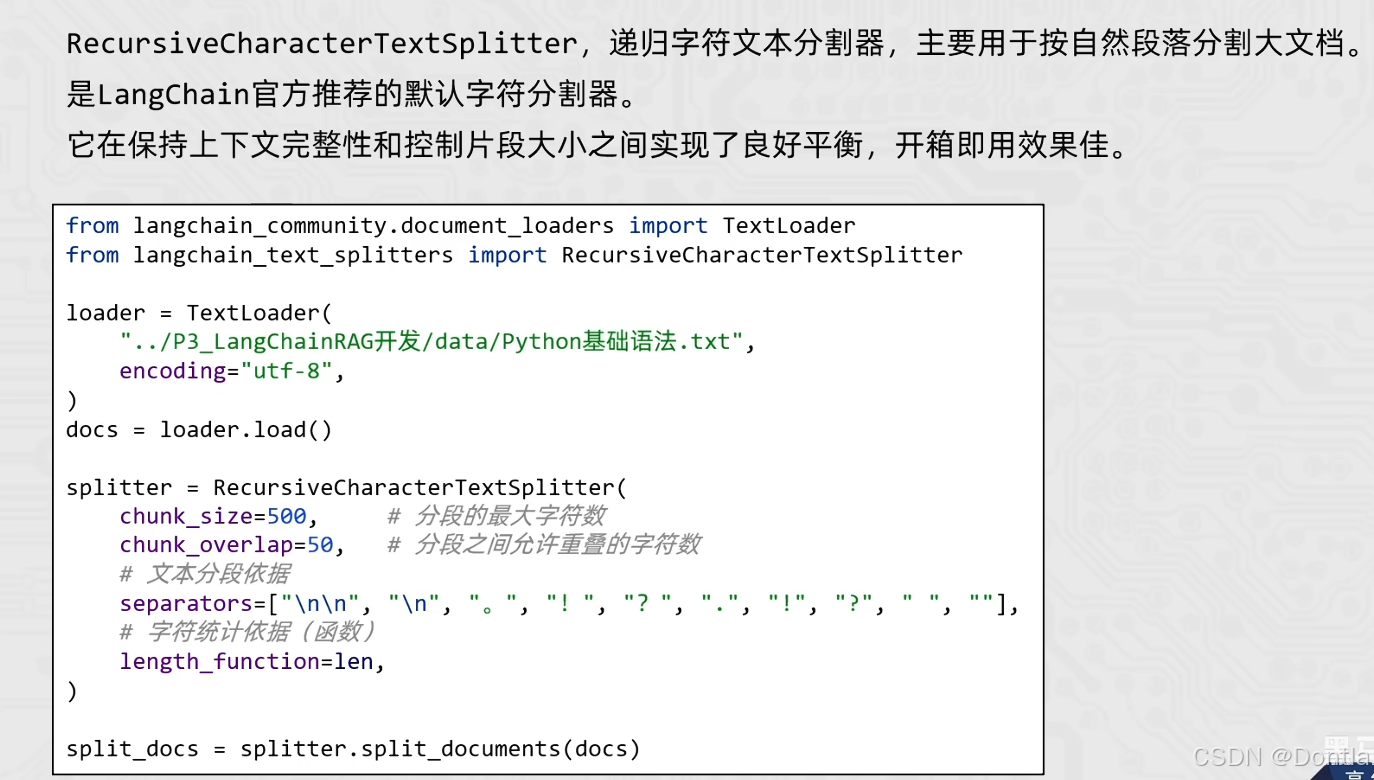
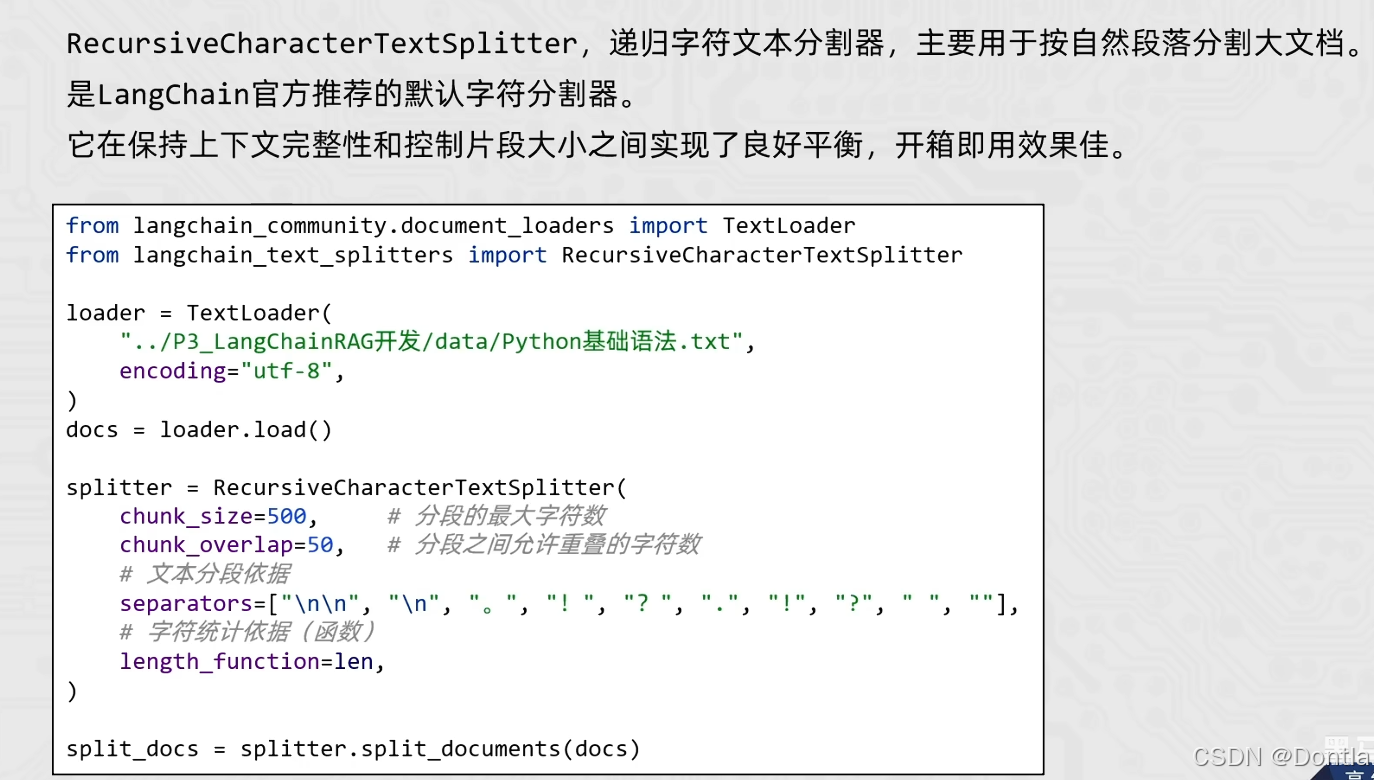
- RecursiveCharacterTextSplitter(递归字符文本分割器)主要用于按自然段落分割大文档
- 是 LangChain 官方推荐的默认字符分割器
- 它在保持上下文完整性和控制片段大小之间实现了良好平衡,开箱即用效果佳
3. RecursiveCharacterTextSplitter 参数:
- chunk_size: 分段的最大字符数
- chunk_overlap: 分段之间允许重叠的字符数(用于保持上下文连续性)
- separators: 文本分段依据,按优先级排序的分隔符列表
- length_function: 字符统计依据(函数),默认使用 len
核心概念:
- TextLoader:用于加载文本文件的文档加载器
- RecursiveCharacterTextSplitter:递归字符文本分割器,用于将大文档分割成小块
- Document:LangChain 文档的统一载体类
- chunk_size:每个文档块的最大字符数
- chunk_overlap:文档块之间的重叠字符数
"""
import os
from typing import List
from dotenv import load_dotenv
from langchain_community.document_loaders import TextLoader
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
def create_sample_text_file() -> str:
"""
创建示例文本文件用于演示。
Returns:
str: 创建的文本文件路径
"""
text_file = "./data/Python基础语法.txt"
# 创建 data 目录(如果不存在)
os.makedirs("./data", exist_ok=True)
# 创建示例文本内容
sample_content = """Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用于表示整数值,如 10、-5、0 等。
浮点数类型(float):用于表示小数值,如 3.14、-0.5、2.0 等。
字符串类型(str):用于表示文本,可以用单引号或双引号括起来,如 'hello'、"world" 等。
布尔类型(bool):用于表示真值,只有两个值:True 和 False。
二、列表和字典
列表(list)是 Python 中最常用的数据结构之一,用于存储一系列有序的元素。列表可以包含不同类型的元素,并且可以动态添加、删除和修改元素。
字典(dict)是另一种重要的数据结构,用于存储键值对。字典中的每个元素都由一个键和一个值组成,通过键可以快速访问对应的值。
三、条件语句和循环
条件语句(if-elif-else)用于根据条件执行不同的代码块。Python 使用缩进来表示代码块,这是 Python 的一个重要特性。
循环语句包括 for 循环和 while 循环。for 循环用于遍历序列(如列表、字符串等),while 循环用于在条件为真时重复执行代码块。
四、函数定义
函数是组织代码的重要方式,可以将一段代码封装起来,通过函数名调用。Python 使用 def 关键字定义函数,函数可以接受参数,也可以返回值。
函数定义的基本语法:
def function_name(parameters):
# 函数体
return value
五、类和对象
Python 是一种面向对象的编程语言,支持类和对象的概念。类是一种抽象的数据类型,用于定义对象的属性和方法。对象是类的实例,具有类定义的属性和方法。
类的定义使用 class 关键字,类中可以定义属性和方法。方法是定义在类中的函数,用于操作对象的数据。
"""
# 写入文件
with open(text_file, "w", encoding="utf-8") as f:
f.write(sample_content)
print(f"示例文本文件已创建:{text_file}")
return text_file
def textloader_basic_demo() -> None:
"""
演示 TextLoader 的基本用法。
展示如何使用 TextLoader 加载文本文件。
"""
print("=" * 80)
print("【示例1】TextLoader 基本用法")
print("-" * 80)
# 创建示例文本文件
text_file = create_sample_text_file()
print()
# 使用 TextLoader 加载文本文件
print("使用 TextLoader 加载文本文件:")
print("-" * 80)
loader = TextLoader(
text_file,
encoding="utf-8", # 指定文件编码
)
docs = loader.load()
print(f"成功加载 {len(docs)} 个文档")
print(f"\n文档内容预览(前 200 个字符):")
print("-" * 80)
if docs:
content_preview = docs[0].page_content[:200]
print(content_preview + "...")
print(f"\n文档元数据:{docs[0].metadata}")
print(f"文档总长度:{len(docs[0].page_content)} 个字符")
print()
def recursive_character_splitter_basic_demo() -> None:
"""
演示 RecursiveCharacterTextSplitter 的基本用法。
展示如何使用 RecursiveCharacterTextSplitter 分割文档。
"""
print("=" * 80)
print("【示例2】RecursiveCharacterTextSplitter 基本用法")
print("-" * 80)
# 加载文档
text_file = "./data/Python基础语法.txt"
if not os.path.exists(text_file):
print(f"错误:找不到文件 {text_file},请先运行示例1")
return
loader = TextLoader(
text_file,
encoding="utf-8",
)
docs = loader.load()
print(f"原始文档长度:{len(docs[0].page_content)} 个字符\n")
# 创建文本分割器
splitter = RecursiveCharacterTextSplitter(
chunk_size=500, # 分段的最大字符数
chunk_overlap=50, # 分段之间允许重叠的字符数
# 文本分段依据,按优先级排序
# 优先使用双换行符分割,然后是单换行符,然后是句号等
separators=["\n\n", "\n", ". ", "! ", "? ", ".", "!", "?", " ", ""],
# 字符统计依据(函数)
length_function=len,
)
# 分割文档
split_docs = splitter.split_documents(docs)
print(f"分割后得到 {len(split_docs)} 个文档块\n")
print("前 3 个文档块内容:")
print("-" * 80)
for i, doc in enumerate(split_docs[:3], start=1):
print(f"\n【文档块 {i}】")
print(f"长度:{len(doc.page_content)} 个字符")
print(f"内容:{doc.page_content[:150]}...")
print(f"元数据:{doc.metadata}")
print()
def recursive_character_splitter_parameters_demo() -> None:
"""
演示 RecursiveCharacterTextSplitter 不同参数的效果。
展示 chunk_size、chunk_overlap 和 separators 参数的影响。
"""
print("=" * 80)
print("【示例3】RecursiveCharacterTextSplitter 参数对比")
print("-" * 80)
# 加载文档
text_file = "./data/Python基础语法.txt"
if not os.path.exists(text_file):
print(f"错误:找不到文件 {text_file},请先运行示例1")
return
loader = TextLoader(
text_file,
encoding="utf-8",
)
docs = loader.load()
original_length = len(docs[0].page_content)
print(f"原始文档长度:{original_length} 个字符\n")
# 不同的参数配置
configurations = [
{
"name": "小块,无重叠",
"chunk_size": 200,
"chunk_overlap": 0,
"separators": ["\n\n", "\n", ". ", "! ", "? ", ".", "!", "?", " ", ""],
},
{
"name": "小块,有重叠",
"chunk_size": 200,
"chunk_overlap": 50,
"separators": ["\n\n", "\n", ". ", "! ", "? ", ".", "!", "?", " ", ""],
},
{
"name": "大块,有重叠",
"chunk_size": 500,
"chunk_overlap": 50,
"separators": ["\n\n", "\n", ". ", "! ", "? ", ".", "!", "?", " ", ""],
},
{
"name": "仅按段落分割",
"chunk_size": 500,
"chunk_overlap": 50,
"separators": ["\n\n", "\n", ""], # 只使用换行符分割
},
]
for config in configurations:
print(f"\n配置:{config['name']}")
print(f" chunk_size={config['chunk_size']}, chunk_overlap={config['chunk_overlap']}")
print("-" * 80)
splitter = RecursiveCharacterTextSplitter(
chunk_size=config["chunk_size"],
chunk_overlap=config["chunk_overlap"],
separators=config["separators"],
length_function=len,
)
split_docs = splitter.split_documents(docs)
print(f"分割后得到 {len(split_docs)} 个文档块")
# 显示每个块的长度
chunk_lengths = [len(doc.page_content) for doc in split_docs]
print(f"块长度范围:{min(chunk_lengths)} - {max(chunk_lengths)} 个字符")
print(f"平均块长度:{sum(chunk_lengths) / len(chunk_lengths):.1f} 个字符")
# 显示第一个块的内容预览
if split_docs:
print(f"\n第一个块内容预览(前 100 个字符):")
print(f"{split_docs[0].page_content[:100]}...")
print()
def recursive_character_splitter_separators_demo() -> None:
"""
演示不同 separators 参数的效果。
展示分隔符优先级对分割结果的影响。
"""
print("=" * 80)
print("【示例4】RecursiveCharacterTextSplitter - separators 参数影响")
print("-" * 80)
# 加载文档
text_file = "./data/Python基础语法.txt"
if not os.path.exists(text_file):
print(f"错误:找不到文件 {text_file},请先运行示例1")
return
loader = TextLoader(
text_file,
encoding="utf-8",
)
docs = loader.load()
print(f"原始文档长度:{len(docs[0].page_content)} 个字符\n")
# 不同的分隔符配置
separator_configs = [
{
"name": "默认分隔符(推荐)",
"separators": ["\n\n", "\n", ". ", "! ", "? ", ".", "!", "?", " ", ""],
},
{
"name": "仅按段落分割",
"separators": ["\n\n", "\n", ""],
},
{
"name": "按句子分割",
"separators": [". ", "! ", "? ", ".", "!", "?", "\n", " ", ""],
},
{
"name": "按单词分割",
"separators": [" ", "\n", ""],
},
]
for config in separator_configs:
print(f"\n分隔符配置:{config['name']}")
print(f" separators: {config['separators']}")
print("-" * 80)
splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=30,
separators=config["separators"],
length_function=len,
)
split_docs = splitter.split_documents(docs)
print(f"分割后得到 {len(split_docs)} 个文档块")
# 显示前两个块的内容
for i, doc in enumerate(split_docs[:2], start=1):
print(f"\n块 {i}(长度:{len(doc.page_content)} 字符):")
print(f"{doc.page_content[:120]}...")
print()
def textloader_encoding_demo() -> None:
"""
演示 TextLoader 的 encoding 参数。
展示不同编码对文件加载的影响。
"""
print("=" * 80)
print("【示例5】TextLoader - encoding 参数")
print("-" * 80)
# 创建不同编码的测试文件
test_files = []
# UTF-8 编码文件
utf8_file = "./data/test_utf8.txt"
os.makedirs("./data", exist_ok=True)
with open(utf8_file, "w", encoding="utf-8") as f:
f.write("这是 UTF-8 编码的测试文件\n包含中文:你好世界\n包含英文:Hello World")
test_files.append(("UTF-8", utf8_file, "utf-8"))
print("测试不同编码的文件加载:")
print("-" * 80)
for encoding_name, file_path, encoding in test_files:
print(f"\n编码:{encoding_name}")
print(f"文件:{file_path}")
try:
loader = TextLoader(
file_path,
encoding=encoding,
)
docs = loader.load()
print(f"✓ 成功加载,文档内容:")
print(f" {docs[0].page_content[:100]}...")
except Exception as e:
print(f"✗ 加载失败:{e}")
print()
def splitter_metadata_demo() -> None:
"""
演示分割后文档的元数据。
展示分割器如何保留和更新文档元数据。
"""
print("=" * 80)
print("【示例6】文档分割后的元数据")
print("-" * 80)
# 加载文档
text_file = "./data/Python基础语法.txt"
if not os.path.exists(text_file):
print(f"错误:找不到文件 {text_file},请先运行示例1")
return
loader = TextLoader(
text_file,
encoding="utf-8",
)
docs = loader.load()
print(f"原始文档元数据:{docs[0].metadata}\n")
# 创建分割器
splitter = RecursiveCharacterTextSplitter(
chunk_size=300,
chunk_overlap=30,
separators=["\n\n", "\n", ". ", "! ", "? ", ".", "!", "?", " ", ""],
length_function=len,
)
# 分割文档
split_docs = splitter.split_documents(docs)
print(f"分割后得到 {len(split_docs)} 个文档块\n")
print("前 3 个文档块的元数据:")
print("-" * 80)
for i, doc in enumerate(split_docs[:3], start=1):
print(f"\n文档块 {i}:")
print(f" 元数据:{doc.metadata}")
print(f" 内容长度:{len(doc.page_content)} 字符")
print(f" 内容预览:{doc.page_content[:80]}...")
print()
def main() -> None:
"""
主函数:演示 TextLoader 和 RecursiveCharacterTextSplitter 的各种使用方法。
"""
print("=" * 80)
print("LangChain TextLoader 和文档分割器示例")
print("=" * 80)
print()
# 加载环境变量(虽然 TextLoader 不需要 API Key,但保持一致性)
load_dotenv()
# 示例1:TextLoader 基本用法
textloader_basic_demo()
# 示例2:RecursiveCharacterTextSplitter 基本用法
recursive_character_splitter_basic_demo()
# 示例3:参数对比
recursive_character_splitter_parameters_demo()
# 示例4:separators 参数影响
recursive_character_splitter_separators_demo()
# 示例5:encoding 参数
textloader_encoding_demo()
# 示例6:文档分割后的元数据
splitter_metadata_demo()
print("=" * 80)
print("演示结束")
print("=" * 80)
print("\n提示:")
print("- 示例文本文件已创建在 ./data/Python基础语法.txt")
print("- RecursiveCharacterTextSplitter 是 LangChain 官方推荐的默认字符分割器")
print("- 它在保持上下文完整性和控制片段大小之间实现了良好平衡")
print("- 更多文档加载器请参考:https://docs.langchain.com/oss/python/integrations/document_loaders")
print("- 更多文本分割器请参考:https://docs.langchain.com/oss/python/modules/data_connection/text_splitters/")
if __name__ == "__main__":
main()
运行代码
cd /home/devbox/project/AI_LLM_RAG_Agent_Dev && python 30_LangChain_TextLoader.py
结果
================================================================================
LangChain TextLoader 和文档分割器示例
================================================================================
================================================================================
【示例1】TextLoader 基本用法
--------------------------------------------------------------------------------
示例文本文件已创建:./data/Python基础语法.txt
使用 TextLoader 加载文本文件:
--------------------------------------------------------------------------------
成功加载 1 个文档
文档内容预览(前 200 个字符):
--------------------------------------------------------------------------------
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用于表示整数值,如 10、-5、0 等。
浮点数类型(float):用于表示小数值,如 3.14、-0.5、2.0 等。
字符串类型(str):用于表示文本,可以用单引号或双引号括起来,如 'hello...
文档元数据:{'source': './data/Python基础语法.txt'}
文档总长度:843 个字符
================================================================================
【示例2】RecursiveCharacterTextSplitter 基本用法
--------------------------------------------------------------------------------
原始文档长度:843 个字符
分割后得到 2 个文档块
前 3 个文档块内容:
--------------------------------------------------------------------------------
【文档块 1】
长度:480 个字符
内容:Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用于表示整数值,如 10、-5、0 等。
浮点数类型(float):用于表示小数值,如 3.14、-0...
元数据:{'source': './data/Python基础语法.txt'}
【文档块 2】
长度:360 个字符
内容:循环语句包括 for 循环和 while 循环。for 循环用于遍历序列(如列表、字符串等),while 循环用于在条件为真时重复执行代码块。
四、函数定义
函数是组织代码的重要方式,可以将一段代码封装起来,通过函数名调用。Python 使用 def 关键字定义函数,函数可以接受参数,也可以返回...
元数据:{'source': './data/Python基础语法.txt'}
================================================================================
【示例3】RecursiveCharacterTextSplitter 参数对比
--------------------------------------------------------------------------------
原始文档长度:843 个字符
配置:小块,无重叠
chunk_size=200, chunk_overlap=0
--------------------------------------------------------------------------------
分割后得到 6 个文档块
块长度范围:87 - 170 个字符
平均块长度:138.7 个字符
第一个块内容预览(前 100 个字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。...
配置:小块,有重叠
chunk_size=200, chunk_overlap=50
--------------------------------------------------------------------------------
分割后得到 6 个文档块
块长度范围:87 - 170 个字符
平均块长度:144.7 个字符
第一个块内容预览(前 100 个字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。...
配置:大块,有重叠
chunk_size=500, chunk_overlap=50
--------------------------------------------------------------------------------
分割后得到 2 个文档块
块长度范围:360 - 480 个字符
平均块长度:420.0 个字符
第一个块内容预览(前 100 个字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用...
配置:仅按段落分割
chunk_size=500, chunk_overlap=50
--------------------------------------------------------------------------------
分割后得到 2 个文档块
块长度范围:360 - 480 个字符
平均块长度:420.0 个字符
第一个块内容预览(前 100 个字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用...
================================================================================
【示例4】RecursiveCharacterTextSplitter - separators 参数影响
--------------------------------------------------------------------------------
原始文档长度:843 个字符
分隔符配置:默认分隔符(推荐)
separators: ['\n\n', '\n', '. ', '! ', '? ', '.', '!', '?', ' ', '']
--------------------------------------------------------------------------------
分割后得到 4 个文档块
块 1(长度:259 字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用于表示整数值,如 10、-5、0 等。
...
块 2(长度:228 字符):
二、列表和字典
列表(list)是 Python 中最常用的数据结构之一,用于存储一系列有序的元素。列表可以包含不同类型的元素,并且可以动态添加、删除和修改元素。
字典(dict)是另一种重要的数据结构,用于存储键值对。字典中的每个元素...
分隔符配置:仅按段落分割
separators: ['\n\n', '\n', '']
--------------------------------------------------------------------------------
分割后得到 4 个文档块
块 1(长度:259 字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用于表示整数值,如 10、-5、0 等。
...
块 2(长度:228 字符):
二、列表和字典
列表(list)是 Python 中最常用的数据结构之一,用于存储一系列有序的元素。列表可以包含不同类型的元素,并且可以动态添加、删除和修改元素。
字典(dict)是另一种重要的数据结构,用于存储键值对。字典中的每个元素...
分隔符配置:按句子分割
separators: ['. ', '! ', '? ', '.', '!', '?', '\n', ' ', '']
--------------------------------------------------------------------------------
分割后得到 4 个文档块
块 1(长度:154 字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用于表示整数值,如 10、-5、0 等。
...
块 2(长度:255 字符):
.0 等。
字符串类型(str):用于表示文本,可以用单引号或双引号括起来,如 'hello'、"world" 等。
布尔类型(bool):用于表示真值,只有两个值:True 和 False。
二、列表和字典
列表(list)是 Pyt...
分隔符配置:按单词分割
separators: [' ', '\n', '']
--------------------------------------------------------------------------------
分割后得到 4 个文档块
块 1(长度:277 字符):
Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符串、布尔值等。
整数类型(int):用于表示整数值,如 10、-5、0 等。
...
块 2(长度:263 字符):
Python 中最常用的数据结构之一,用于存储一系列有序的元素。列表可以包含不同类型的元素,并且可以动态添加、删除和修改元素。
字典(dict)是另一种重要的数据结构,用于存储键值对。字典中的每个元素都由一个键和一个值组成,通过键可以快速...
================================================================================
【示例5】TextLoader - encoding 参数
--------------------------------------------------------------------------------
测试不同编码的文件加载:
--------------------------------------------------------------------------------
编码:UTF-8
文件:./data/test_utf8.txt
✓ 成功加载,文档内容:
这是 UTF-8 编码的测试文件
包含中文:你好世界
包含英文:Hello World...
================================================================================
【示例6】文档分割后的元数据
--------------------------------------------------------------------------------
原始文档元数据:{'source': './data/Python基础语法.txt'}
分割后得到 4 个文档块
前 3 个文档块的元数据:
--------------------------------------------------------------------------------
文档块 1:
元数据:{'source': './data/Python基础语法.txt'}
内容长度:259 字符
内容预览:Python 基础语法
一、变量和数据类型
Python 是一种动态类型语言,变量不需要提前声明类型。Python 支持多种数据类型,包括整数、浮点数、字符...
文档块 2:
元数据:{'source': './data/Python基础语法.txt'}
内容长度:228 字符
内容预览:二、列表和字典
列表(list)是 Python 中最常用的数据结构之一,用于存储一系列有序的元素。列表可以包含不同类型的元素,并且可以动态添加、删除和修改元...
文档块 3:
元数据:{'source': './data/Python基础语法.txt'}
内容长度:230 字符
内容预览:循环语句包括 for 循环和 while 循环。for 循环用于遍历序列(如列表、字符串等),while 循环用于在条件为真时重复执行代码块。
四、函数定义
...
================================================================================
演示结束
================================================================================
提示:
- 示例文本文件已创建在 ./data/Python基础语法.txt
- RecursiveCharacterTextSplitter 是 LangChain 官方推荐的默认字符分割器
- 它在保持上下文完整性和控制片段大小之间实现了良好平衡
- 更多文档加载器请参考:https://docs.langchain.com/oss/python/integrations/document_loaders
- 更多文本分割器请参考:https://docs.langchain.com/oss/python/modules/data_connection/text_splitters/
总结


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献420条内容
已为社区贡献420条内容

所有评论(0)