小白程序员快速入门LangChain大模型框架,轻松构建AI应用
小白程序员快速入门LangChain大模型框架,轻松构建AI应用
LangChain是一个强大的开源框架,专为构建大语言模型应用而生。本文介绍了LangChain的核心模块,包括模型、提示、链、代理、记忆和索引,并详细阐述了每个模块的功能和应用场景。通过学习LangChain,程序员可以快速掌握大模型开发技术,构建出功能丰富的AI应用。
前排提示,文末有大模型AGI-CSDN独家资料包哦!
1、框架介绍
LangChain 是一个用于构建大语言模型应用的开源框架,2022年10月作为开源项目推出,目前已经在开发社区颇具名气,构建起了自己的一片开发生态。
LangChain 在 2023 年 3 月获得了 Benchmark Capital 的 1000 万美元种子轮融资,在近期又拿到了红杉2000-2500万美金的融资,估值已经提升到了2亿美金左右。
它提供了一系列模块,这些模块可以组合在一起,用于创建复杂的应用程序,也可以单独用于简单的应用程序。它逻辑上主要有6大模块:Models、prompt、chains、agents、memory、indexes。
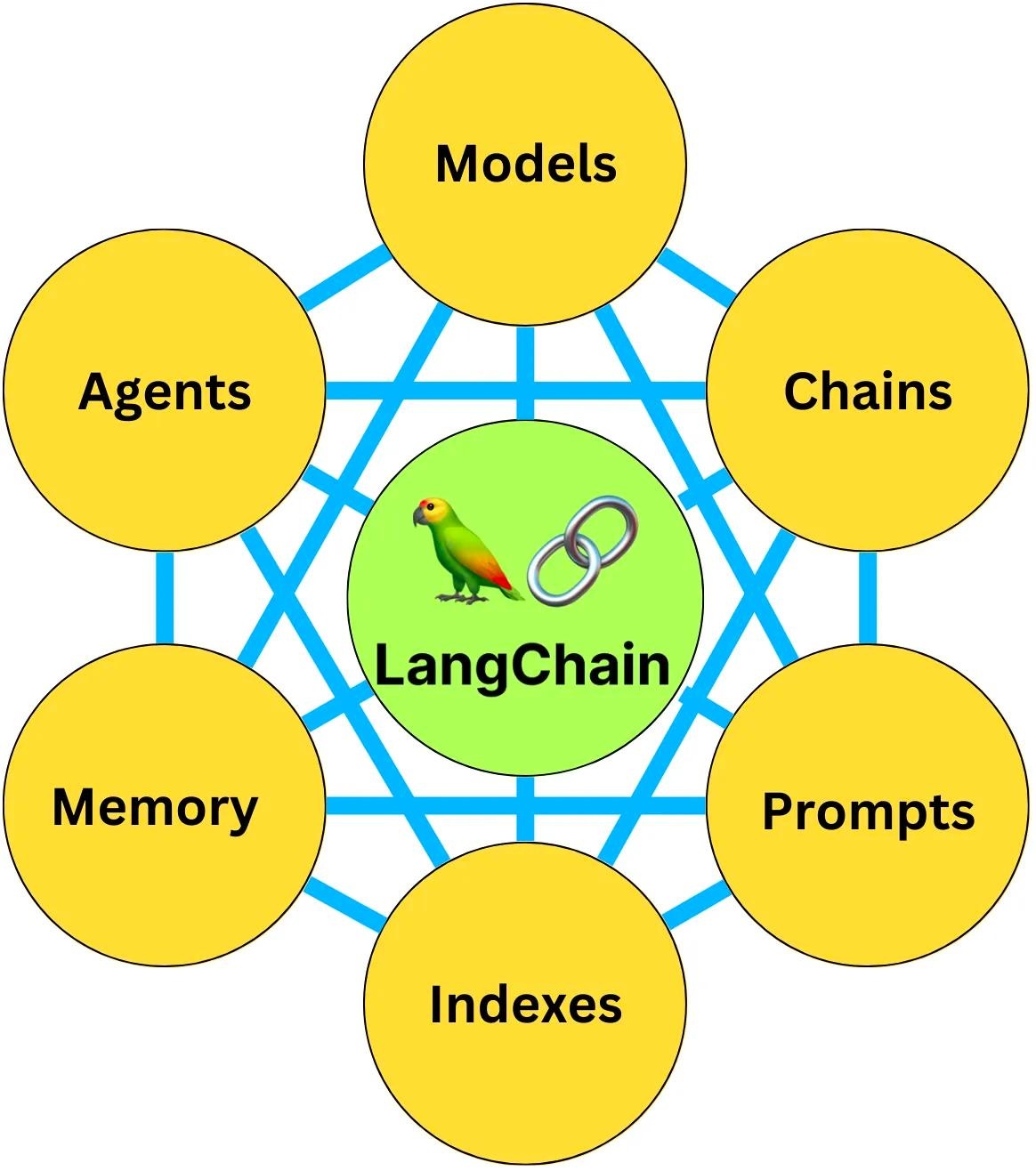
一个LangChain应用是通过很多个组件实现的,LangChain主要支持6种组件:
- Models:模型,各种类型的模型和模型集成,比如ChatGPT、ChatGLM、T5等大语言模型
- Prompts:提示,包括提示管理、自定义提示词。
- Agents:代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止; 授予大模型对于外部工具的使用权限。
- Memory:记忆,用来保存和模型交互时的上下文状态
- Indexes:索引,用来结构化文档,以便和模型交互
- Chains:链,一系列对各种组件的调用
2、模块介绍
(1)、Agent
Agent 使用LLM来确定采取哪些行动以及顺序。 一个动作可以是使用工具并观察其输出,或返回给用户。
代理的灵活使用,可以增强大模型的能力。
例如,通过agent,我们可以赋予大模型 访问网络、访问数据库以及其他工具的能力。
from langchain.agents import initialize_agent,Tool
from langchain.llms import OpenAI
from langchain.tools import BaseTool
from agents.brand_search import BrandInfoSearchWrapper
import langchain
langchain.debug = Truefrom langchain.chat_models import ChatOpenAI
# llm = ChatOpenAI(temperature=0,model_name="gpt-3.5-turbo")
llm = ChatOpenAI(temperature=0,model_name="gpt-35-turbo-16k")
brand_serach = BrandInfoSearchWrapper(top_k=1,domain="zhihu.com")
tools = [
Tool(
name="BrandSearch",
func=brand_serach.run,
description="当问题中包含品牌信息是使用"
)
]
agent = initialize_agent(
tools, llm, agent="zero-shot-react-description", verbose=True)
# print("prompt",agent.agent.llm_chain.prompt.template)print("问题:")
print("答案:" + agent.run("美宝莲这个品牌的化妆品在中国市场占有率如何?"))
- zero-shot-react-description:仅基于工具的描述来确定要使用的工具。可以提供任意数量的工具。此代理需要为每个工具提供描述。
- react-docstore:主要与文档存储进行交互。必须提供两个Search和Lookup 工具。
Search工具用于搜索文档,而Lookup工具应该查找最近找到的文档中的一个术语。 - self-ask-with-search:基于搜索引擎查找问题的答案。必须提供了Google搜索API作为工具。
(2)、Memory
LLMs本身是无状态的,对于连续的提问,大语言模型会独立地处理每个传入的查询。在某些应用程序中(聊天机器人是一个很好的例子),记住以前的交互非常重要,无论是在短期还是长期层面上。Memory模块主要用于存储历史的交互记录。
常用模式:
- 将历史消息交互列表,在下一次提问时,作为上下文信息。
- 将历史消息交互列,构建向量存储在VectorDB中,并在每次调用时查询最重要的K个文档。不明确跟踪交互的顺序。
langchain 提供多种组件完成交互记忆的存储:
-
(a)、ConversationBufferMemory
该组件类似我们上面的描述,只不过它会将聊天内容记录在内存中,而不需要每次再手动拼接聊天记录。
-
(b)、ConversationBufferWindowMemory
相比较第一个记忆组件,该组件增加了一个窗口参数,会保存最近看 k 论的聊天内容。
-
©、ConversationTokenBufferMemory
在内存中保留最近交互的缓冲区,并使用 token 长度而不是交互次数来确定何时刷新交互。
-
(d)、ConversationSummaryMemory
相比第一个记忆组件,该组件只会存储一个用户和机器人之间的聊天内容的摘要。
-
(e)、ConversationSummaryBufferMemory
结合了上面两个思路,存储一个用户和机器人之间的聊天内容的摘要并使用 token 长度来确定何时刷新交互。
-
(g)、VectorStoreRetrieverMemory
它是将所有之前的对话通过向量的方式存储到 VectorDB(向量数据库)中,在每一轮新的对话中,会根据用户的输入信息,匹配向量数据库中最相似的 K 组对话。
(3)、Indexes
索引应用于知识库文档的构建和检索,以便 LLM 可以最好地获取问题相关的背景知识。
主要步骤:
- 文档加载
- 文字分割
- 构建 Embedding
- 向量存储
langchain 生态提供了多种向量库的接入方式:
- AnalyticDB
- Annoy
- AtlasDB
- Chroma
- Deep Lake
- ElasticSearch
- FAISS
- LanceDB
- Milvus
- MyScale
- OpenSearch
- PGVector
- Pinecone
- Qdrant
- Redis
- SupabaseVectorStore
- Tair
- Weaviate
- Zilliz
(4)、Chains
使用单独的LLM对于一些简单的应用程序来说是可以的,但许多更复杂的应用程序往往难以获得满意的效果。
链允许我们将多个组件组合在一起,每个组件只完成目标明确的某一项操作,然后将格式化后的响应传递给 下一个组件,从而来构建更复杂的应用。
代码示例:
# location 链
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=1,model_name="gpt-35-turbo-16k")
template = """你的工作是根据用户的城市,推荐一道该地区的经典菜肴。
%用户城市
{user_location}
你的答案:
"""prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
location_chain = LLMChain(llm=llm, prompt=prompt_template)
# meal 链template = """给你一道菜,就如何在家做这道菜给出一个简短而简单的食谱。
%菜名
{user_meal}
YOUR RESPONSE:
"""prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
meal_chain = LLMChain(llm=llm, prompt=prompt_template)
# 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
review = overall_chain.run("北京")
大模型输出结果:
> Entering new SimpleSequentialChain chain...
北京的经典菜肴是炸酱面。炸酱面是北京传统的面食之一,以酱肉和面条为主要材料。这道菜肴以面条爽滑细嫩,配上浓郁的酱料和加入的豆腐丁、黄瓜丝、大葱丝等配料,口感丰富,味道独特。炸酱面在北京有悠久的历史,是一道代表北京美食文化的经典菜肴。
炸酱面的制作方法如下:
材料:
- 面条
- 猪肉末
- 韩式豆瓣酱
- 豆腐丁
- 黄瓜丝
- 大葱丝
- 生抽
- 酱油
- 糖
- 盐
- 食用油
步骤:
1. 将猪肉末放入炒锅中炒熟。
2. 加入适量的韩式豆瓣酱继续炒煮几分钟,使酱料更加香味浓郁。
3. 加入少许生抽、酱油、糖和盐,调成酱料。
4. 煮开水,将面条煮熟后捞出备用。
5. 在炸锅中倒入适量的食用油,将豆腐丁炸熟。
6. 将煮熟的面条放在碗中,加入炸好的豆腐丁、黄瓜丝和大葱丝。
7. 倒入准备好的酱料,搅拌均匀即可。
炸酱面制作完成,可以根据个人口味加入适量的辣椒油或花生碎增添口感。
> Finished chain.
Langchain提供的链式处理模式:
- SimpleSequentialChain: 顺序链的最简单形式,其中每个步骤都有一个单一的输入/输出,并且一个步骤的输出是下一步的输入。
- SequentialChain: 相比 SimpleSequentialChain 只允许有单个输入输出,它是一种更通用的顺序链形式,允许多个输入/输出。
- TransformChain: 转换链允许我们创建一个自定义的转换函数来处理输入,将处理后的结果用作下一个链的输入。
示例代码:
# 转换链:输入变量:text,输出变量:output_texttransform_chain = TransformChain(
input_variables=["text"], output_variables=["output_text"], transform=transform_func
)
# 使用顺序链sequential_chain = SimpleSequentialChain(chains=[transform_chain, llm_chain])
# 开始执行
sequential_chain.run(state_of_the_union)
# 结果
3、Function calling
ChatGPT 提供了Function calling功能,这个功能方便我们更加简单的构建大模型处理链。
functions的格式是一个json数组,每一个json是一个函数,包含:
- name:函数名,
- description:描述,
- parameters参数,
- param_description:参数描述。
- required 需要的参数。
示例代码:
response = openai.ChatCompletion.create(
messages=[
{"role": "system", "content": "你是电商领域营销专家"},
{"role": "user", "content": prompt}
],
temperature=0,
stream=False,
headers=headers,
# max_tokens=2048,# top_p=1,functions = [{
"name":"brand_parse",
"description":"给出品牌分析",
"parameters":{
"type":"object",
"properties":{
"brand_name":{"type":"string","description":"分析的品牌名称"},
"value1":{"type":"string","description":"一段话描述品牌知名度,如果不了解请输入:无法给出评价"},
"value2":{"type":"string","description":"一段话描述品牌影响力,如果不了解请输入:无法给出评价"},
"value3":{"type":"string","description":"一段话描述品牌市场规模,如果不了解请输入:无法给出评价"},
"value4":{"type":"string","description":"一段话描述品牌调性,如果不了解请输入:无法给出评价"},
"value5":{"type":"string","description":"一段话描述产品风格,如果不了解请输入:无法给出评价"},
"value6":{"type":"string","description":"一段话描述品牌受众,如果不了解请输入:无法给出评价"}
},
"required":["value1","value2","value3","value4","value5","value6"],
},
}],
function_call={"name":"brand_parse"}
)
输出结果:
{"value1":"皮尔卡丹是一个非常知名的品牌,几乎每个人都听说过它。","value2":"皮尔卡丹在时尚界有很大的影响力,它的设计风格独特且受到广泛认可。","value3":"皮尔卡丹在连衣裙类目领域市场规模很大,是该领域的领导者之一。","value4":"皮尔卡丹的调性时尚、优雅,给人一种高贵大气的感觉。","value5":"皮尔卡丹的产品风格时尚、简约,注重细节和质感。","value6":"皮尔卡丹的受众主要是年轻女性,他们注重时尚和品质。"}
读者福利:倘若大家对大模型感兴趣,那么这套大模型学习资料一定对你有用。
针对0基础小白:
如果你是零基础小白,快速入门大模型是可行的。
大模型学习流程较短,学习内容全面,需要理论与实践结合
学习计划和方向能根据资料进行归纳总结
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)
第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
这里我们能提供零基础学习书籍和视频。作为最快捷也是最有效的方式之一,跟着老师的思路,由浅入深,从理论到实操,其实大模型并不难。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献123条内容
已为社区贡献123条内容

所有评论(0)