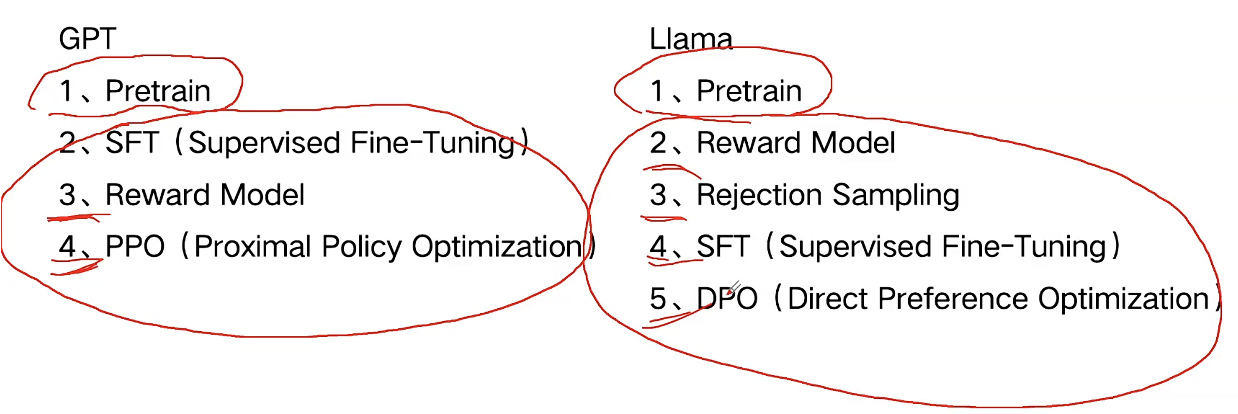
Course 09:开源生态和OpenAI的差异详解
一般来讲,LLM输出下一个字的选择面是10-15万选1(10-15万个概率的总误差)
概览LLM大语言模型的训练过程
pretrain:最大训练数据集+耗时
1、不停的阅读巨量的人类文字资料
2、学习人类如何使用文字(一字一字地学习)
3、学习到最多的人类知识,学习到大量的文字表达方式
4、Pretrain阶段一般需要多大的数据量
一般训练一次需要多少算力(花多少钱):
m百万:1,000,000
b 十亿:1,000,000,000
t 万亿:1,000,000,000,000
e.g: Llama 3 使用了15t Tokens(12-13万亿汉字)
Llama 4 Scout 使用了40t Tokens
Llama 4 Maverick 使用了22t Tokens
一个模型,最开始是什么都不会的,怎么学?


总结:pretrain(自监督学习)输出像“接话茬”,并不是在“做任务” ,没有ReAct等一系列能力
SFT (Supervised Fine-Tuning):有监督的微调训练
1、什么是有监督、无监督
使用有标签的数据进行训练,学习过程叫做有监督学习:
商家送货速度棒棒哒!->正向
送货速度可太慢了,差评。->负向
“这可太好吃了”“味道确实是真不错”->相似
“多吃水果对身体有好处”“痛风病人不要吃海鲜”->不相似
使用无标签的数据进行训练,学习过程叫做无监督学习
SFT阶段:预设未来LLM做什么类型的任务,就用什么样的数据去做“指令微调(Instruction Tuning):
对话任务、分类任务、判断任务、折理任务、代码生成任务
SFT,open AI:预训练=>后训练
step1 雇佣80个博士,撰写1.3万条Q&A
llama qwen:100万条量级Q&A
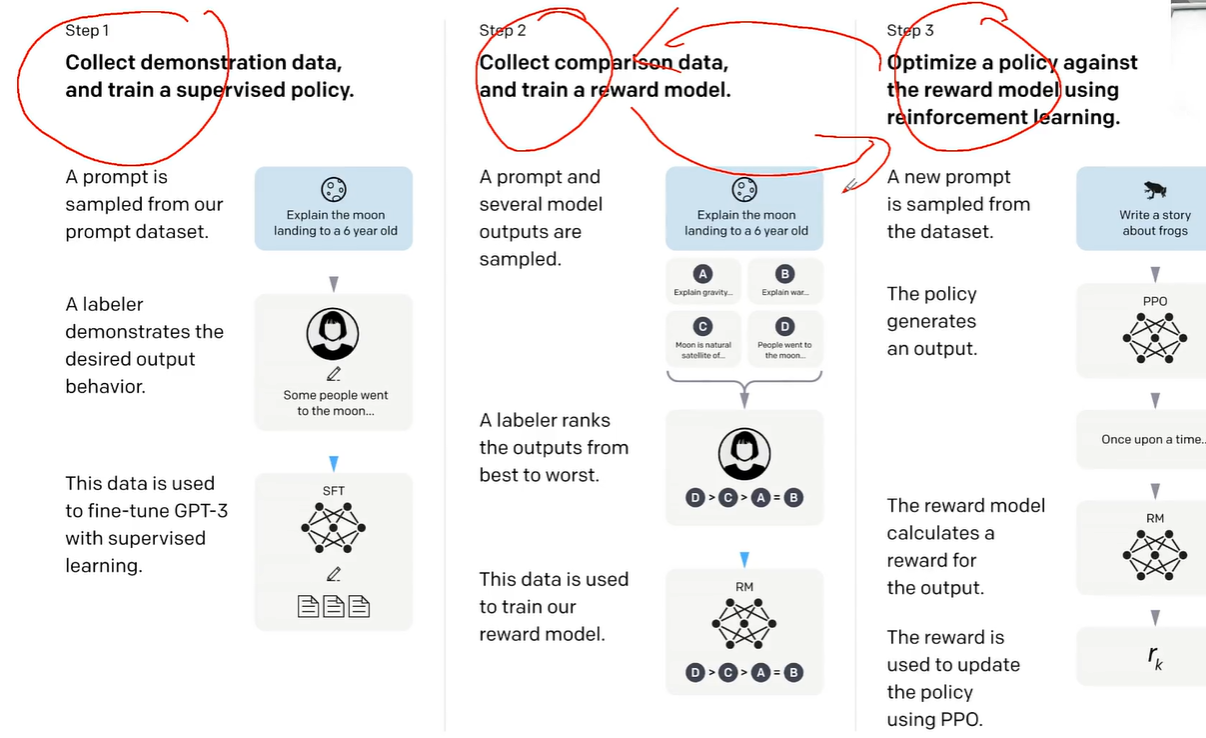
Reward Model
开始使用LLM生成的数据做训练了
评估 这种事本身是一个很难的
构建一个评估体系RM:
1、准备一系列Prompt,让模型给每个Prompt 生成多个Response(几万到几十万条Prompt)
2、设计一下如何标注,打分?评级?排序?
3、找一批人来做标注工作(肯尼亚2美元每天的标注工)
model对齐人类标注的答案排序,理解人类的偏好Preference Data
PPO (Proximal Policy Optimizatior)
RLHF 基于人类反馈的强化学习
llama创新解法:SFT百万级条数,选择合成数据
lllama 3.1循环6次(post-train):best model 基于几十万条colleted prompts =>生成百万条(每条生成大概20个)回答(合成数据)=>rejection sampling 择优转成SFT数据(Q&A)
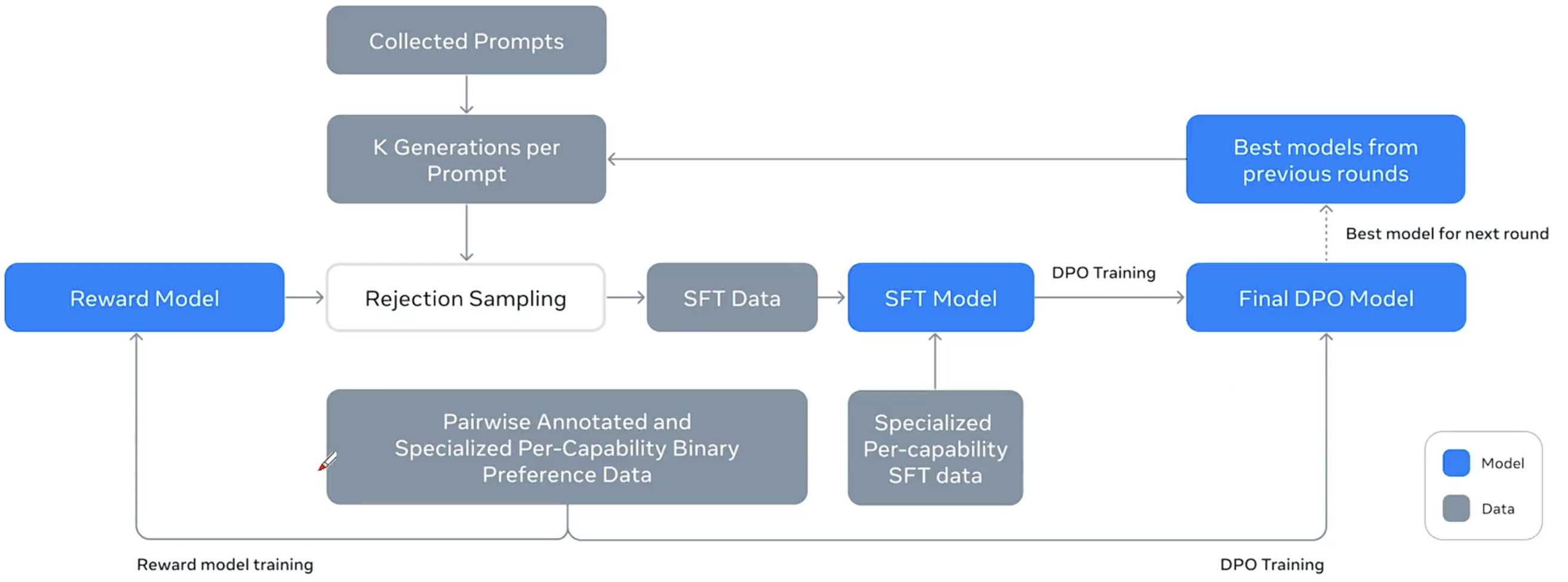
PPO =>DPO Meta的第二个创新解法,

模型的本质
LLM主要任务是分类任务(多少个选项,就输出对应数量的概率)
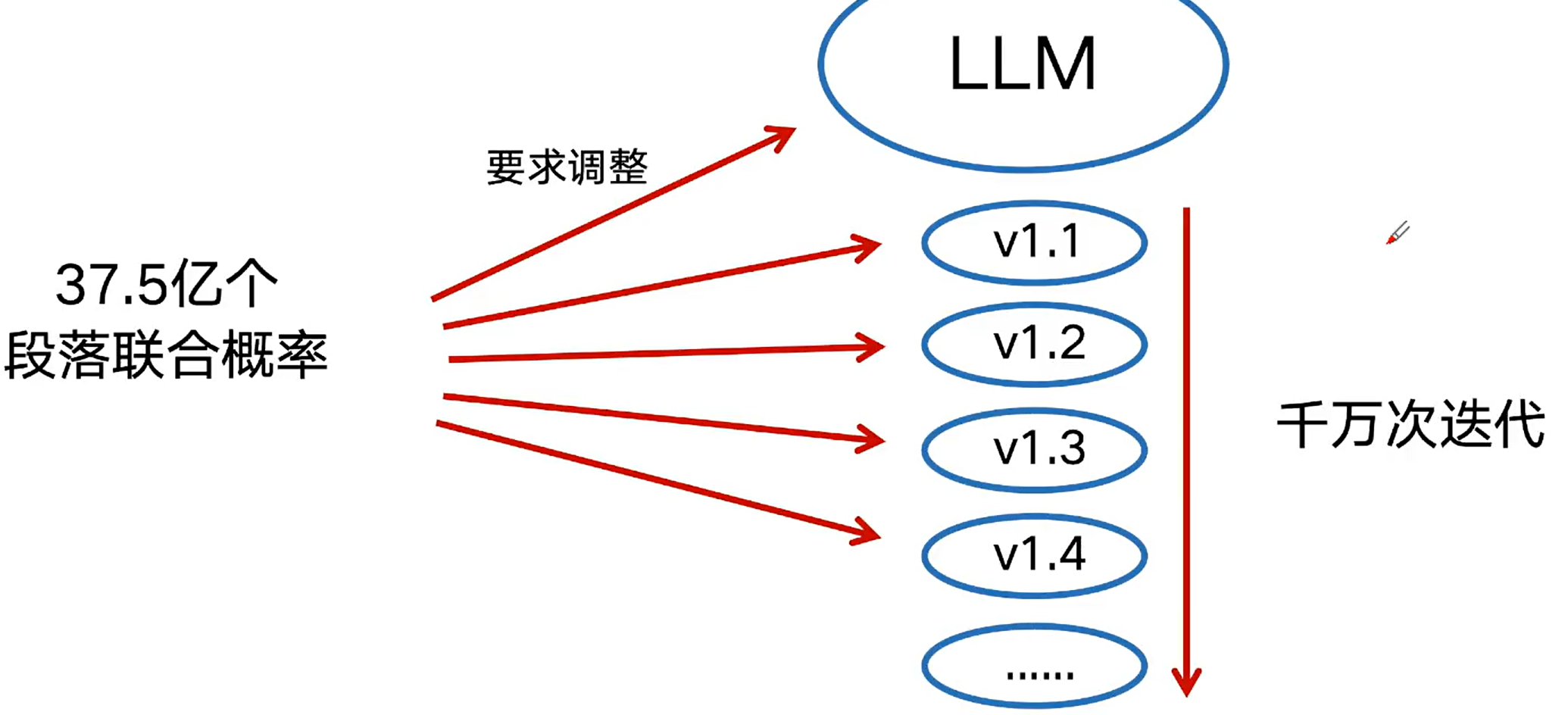
选项数量爆表=>远超人脑定义公式的能力=>万精油公式(神经网络模式来推演)=>机器学习(模型训练、模型学习)=>给定一组起始参数=>计算总误差(损失函数)=>参数调整方向(梯度)和步长(与学习率配合)=>最优参数组合
设计模型,就是设计能解决真实任务的数学公式集
最常见的模型,分类问题
输入:给定一组符合要求的输入数据(需要判断类别) 已知:类别总数为n(n选1) 输出:经过一系列数学公式计算后,输出n个概率,分别代表属于某类别的概率
如
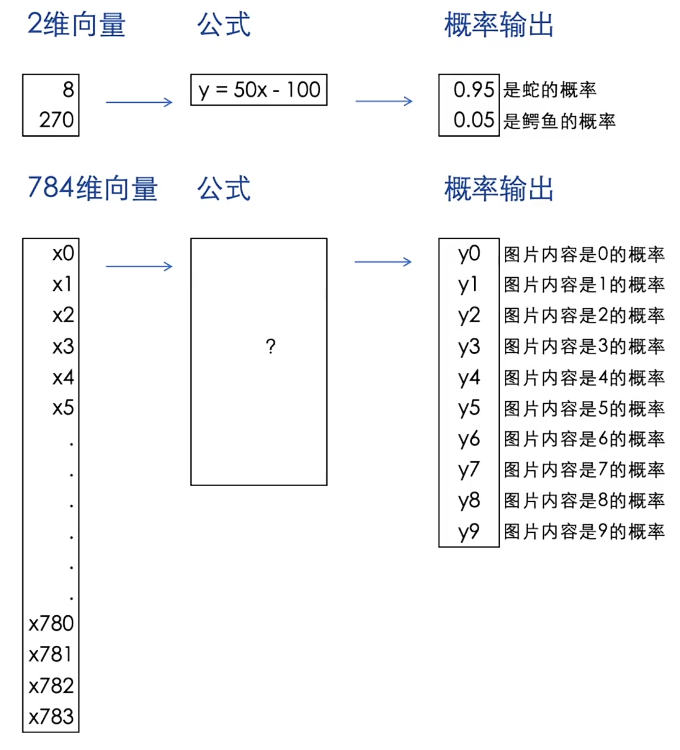
1、输入:一张数字的图片(需要判断图片中的数字是几)已知:类别总数为10(10选1)
输出:经过一系列数学公式计算后,
输出10个概率,分别代表图片中是某数字的概率
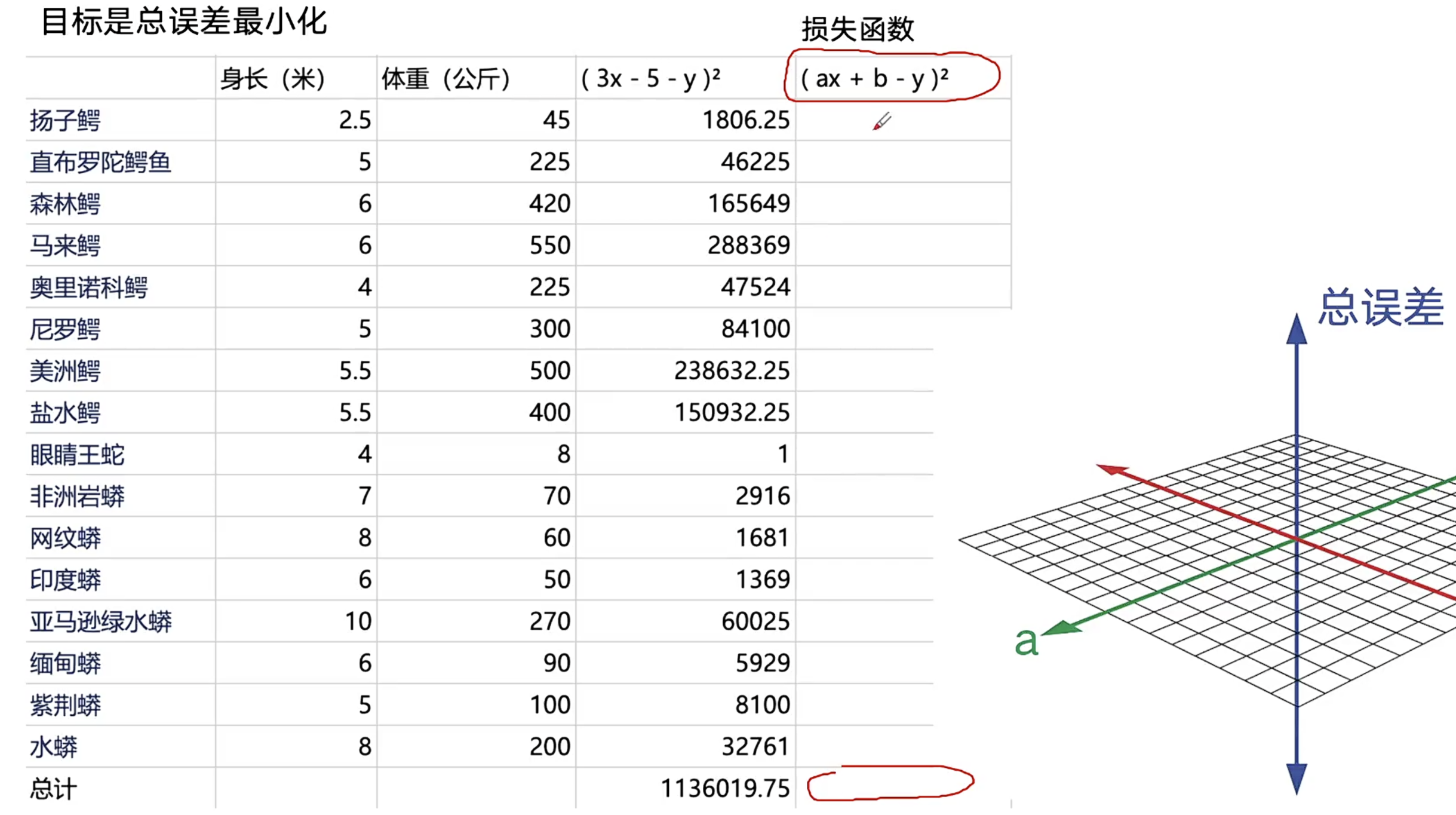
2、输入:动物的身长和体重(需要判断是哪一种动物) 已知:类别总数为200(200选1) 输出:经过一系列数学公式计算后,
输出200个概率,分别代表输入数据是某动物的概率
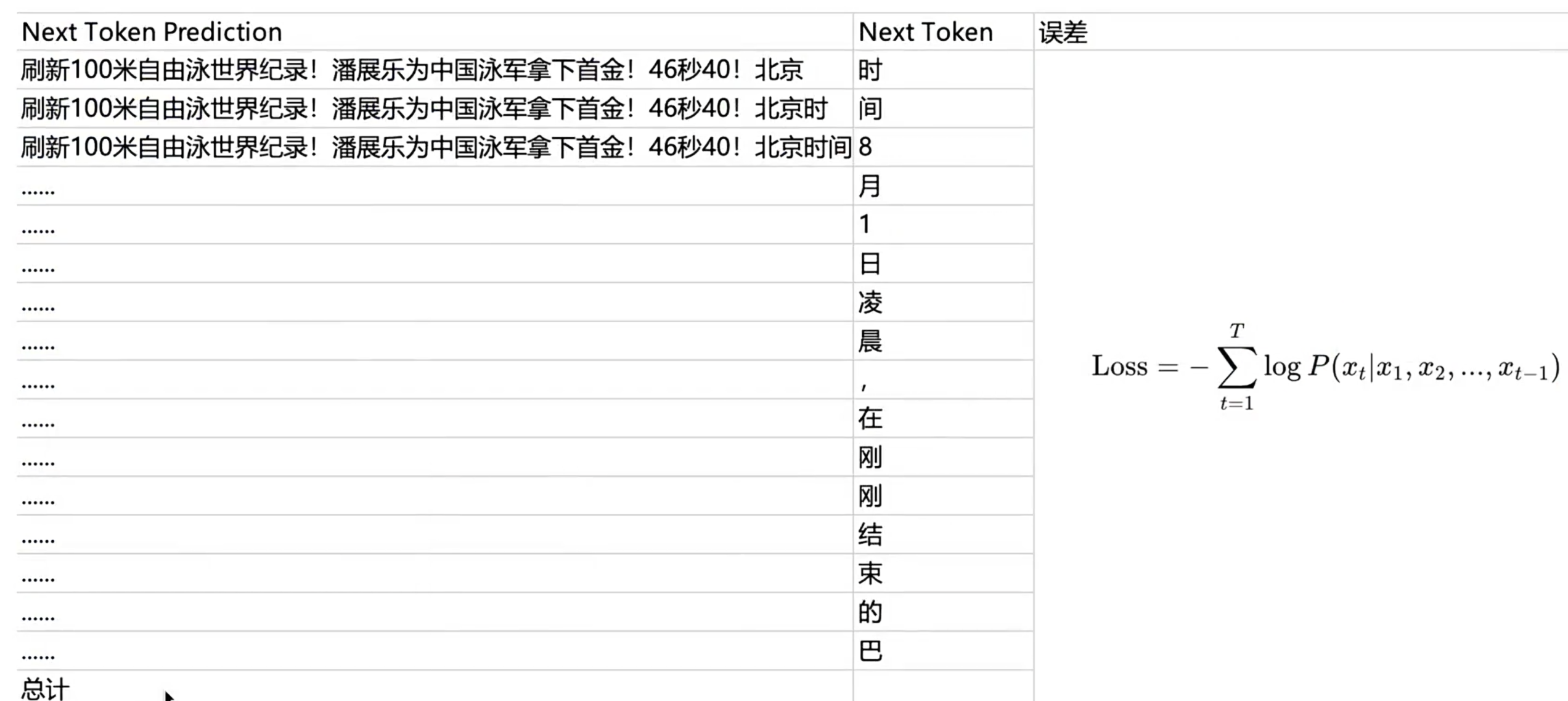
3、输入:刷新100米自由泳世界纪录!潘展乐为(需要判断下一个字是什么字) 已知:类别总数为3000(3000选1)
输出:经过一系列数学公式计算后,输出3000个概率,分别代表下一个汉字的概率
极简模型:线性公式
数据训练的目的--确定数学公式和公式参数
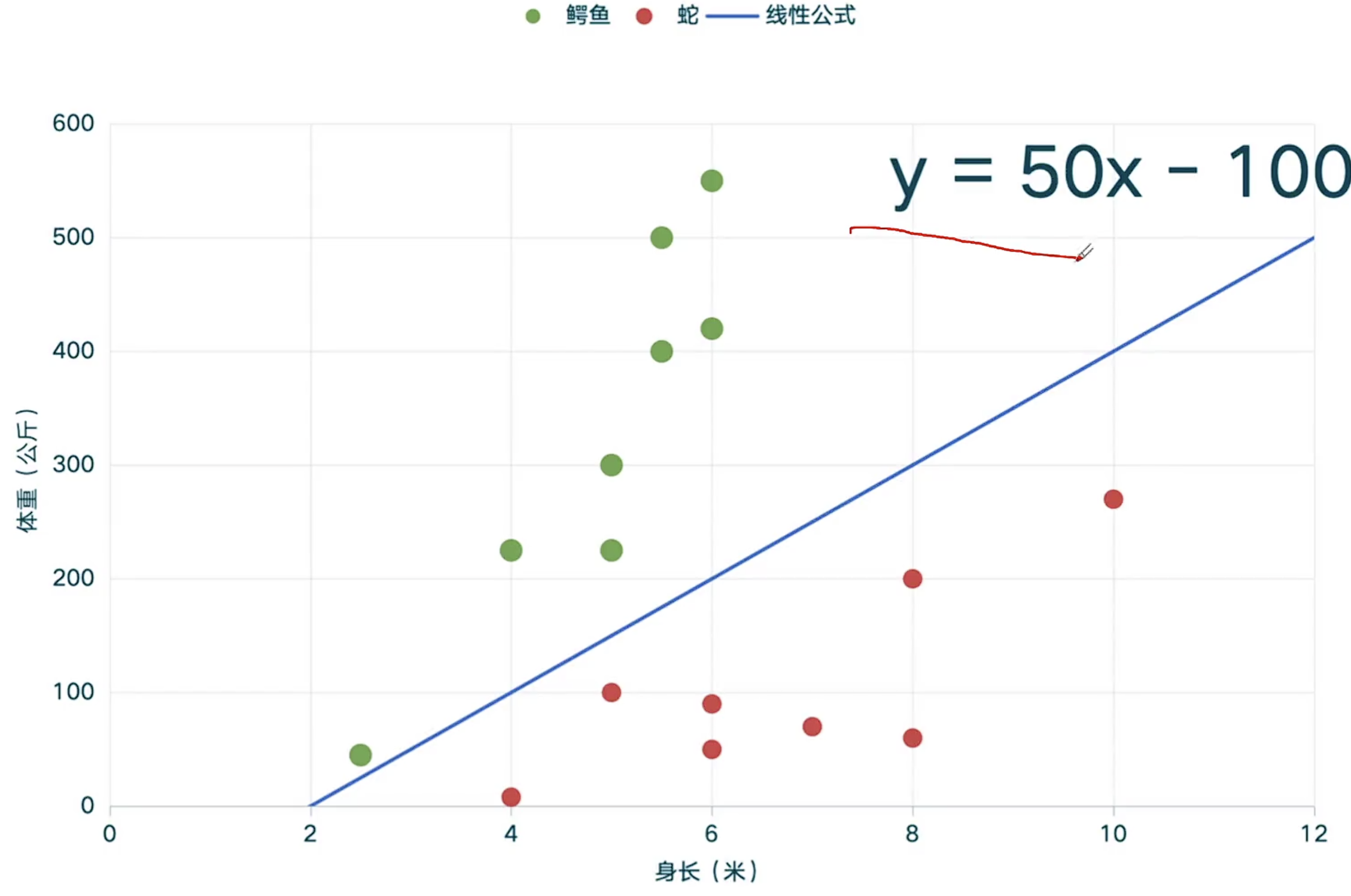
真实模型和任务:复杂指数级攀升
公式复杂度也有上限

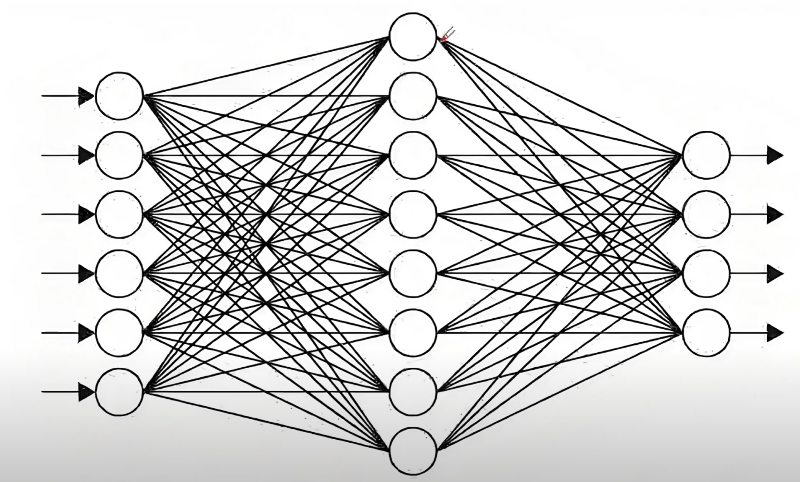
万金油公式---神经网络
模拟人脑,设计一种一劳永逸的公式结构
应用软件举例:基于MNIST数据库的图像识别

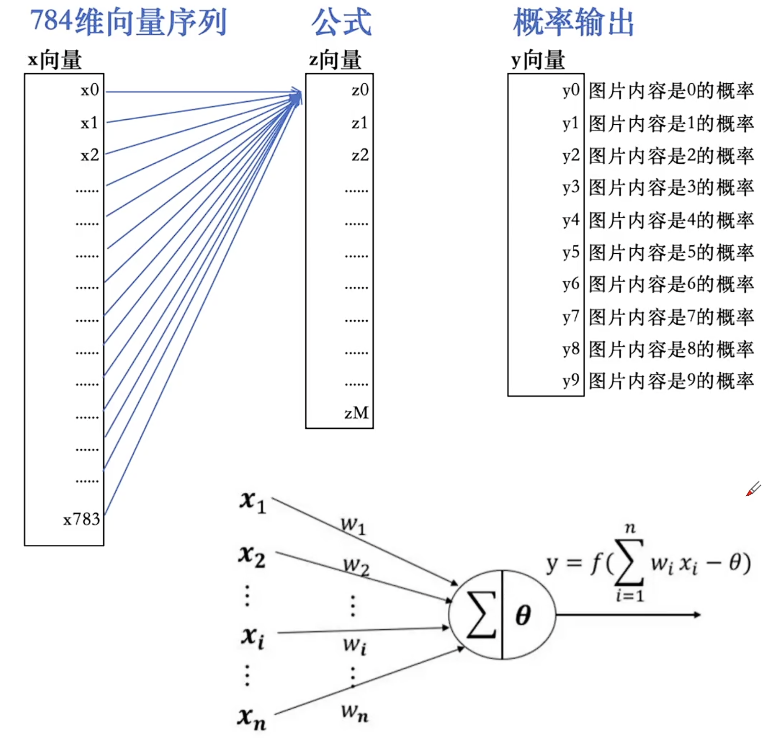
28✖28=784维
计算万金油公式的神经元图示
类比:GPT3 1750亿个参数 GPT4有1.8万亿个参数W

极简变换:线性与非线性
线性
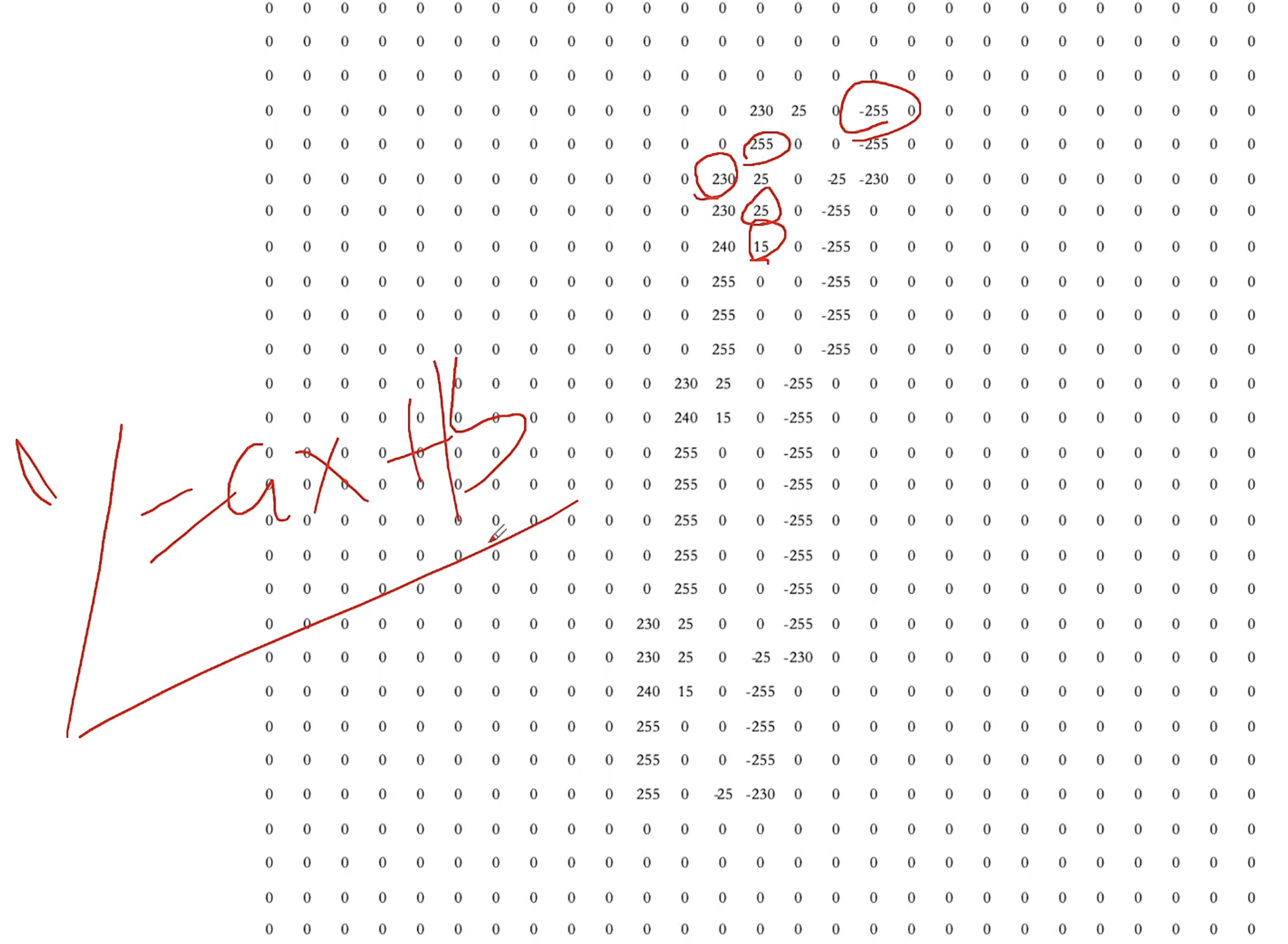
非线性

特征提取:784维向量聚焦
1、概率输出,归一化
2、深度神经网络(层数多)价值:实现更细微差别的人物,但层数要避免过拟合
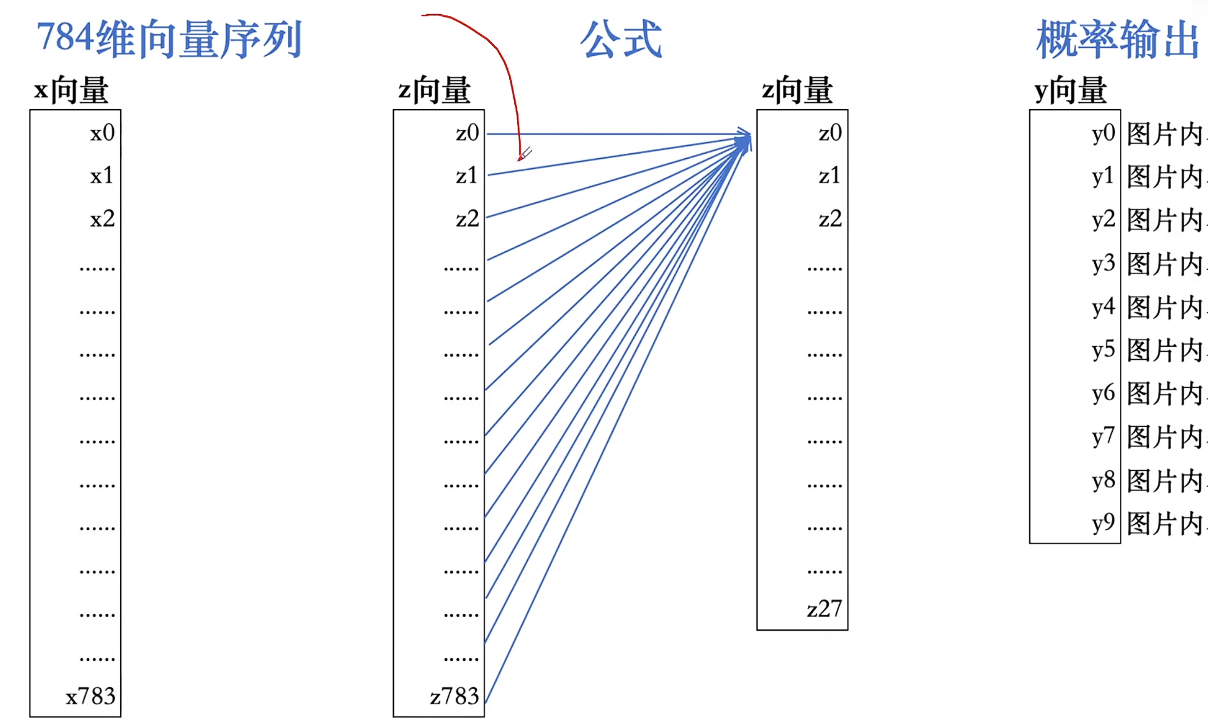
人为赋值和简化参数

计算真实参数:求助LM
确定参数:求助机器学习
机器学习本质:
通过计算机完成大规模数学计算,以找到相对更优的参数组合的过程,我们所说的模型训练。
随机初始化:先跑起来再调整
算法工程师定义误差=>所有数据的偏差总结出总误差
穷尽可能是参数,目标就是要想办法得到一组a和b的值 使总误差最小化。
动态变化方向--求偏导数:梯度下降
总误差每更新一次,重新确定方向--梯度,梯度下降就是总误差变小
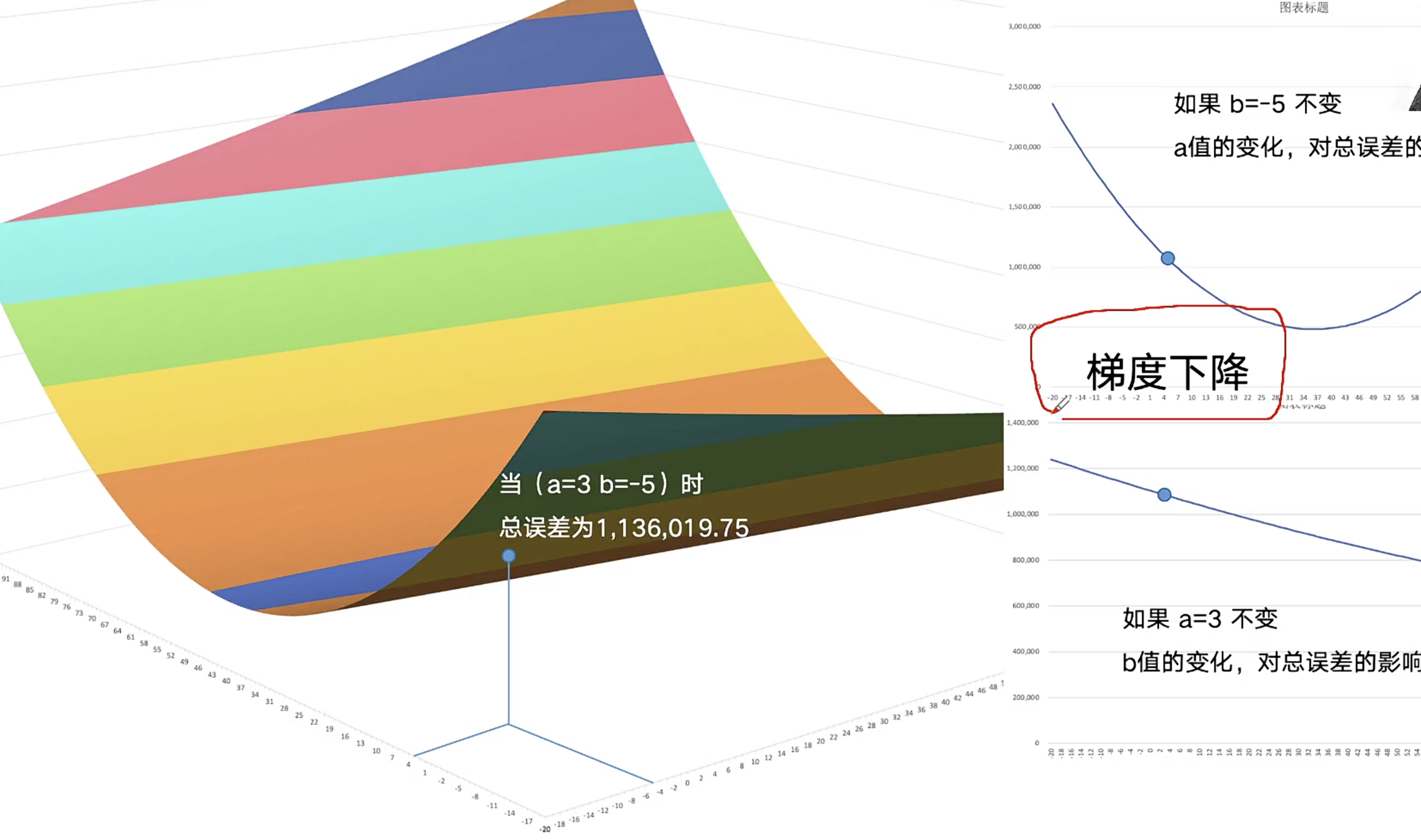
动态变化幅度--步长
牛顿下山:总误差缩小速度变慢之后,要缩短步长
某公式的极限:收敛
某个公式产生的总误差的极限集中在一个区间,不再能变小=>总误差的定义公式(损失函数)的极限
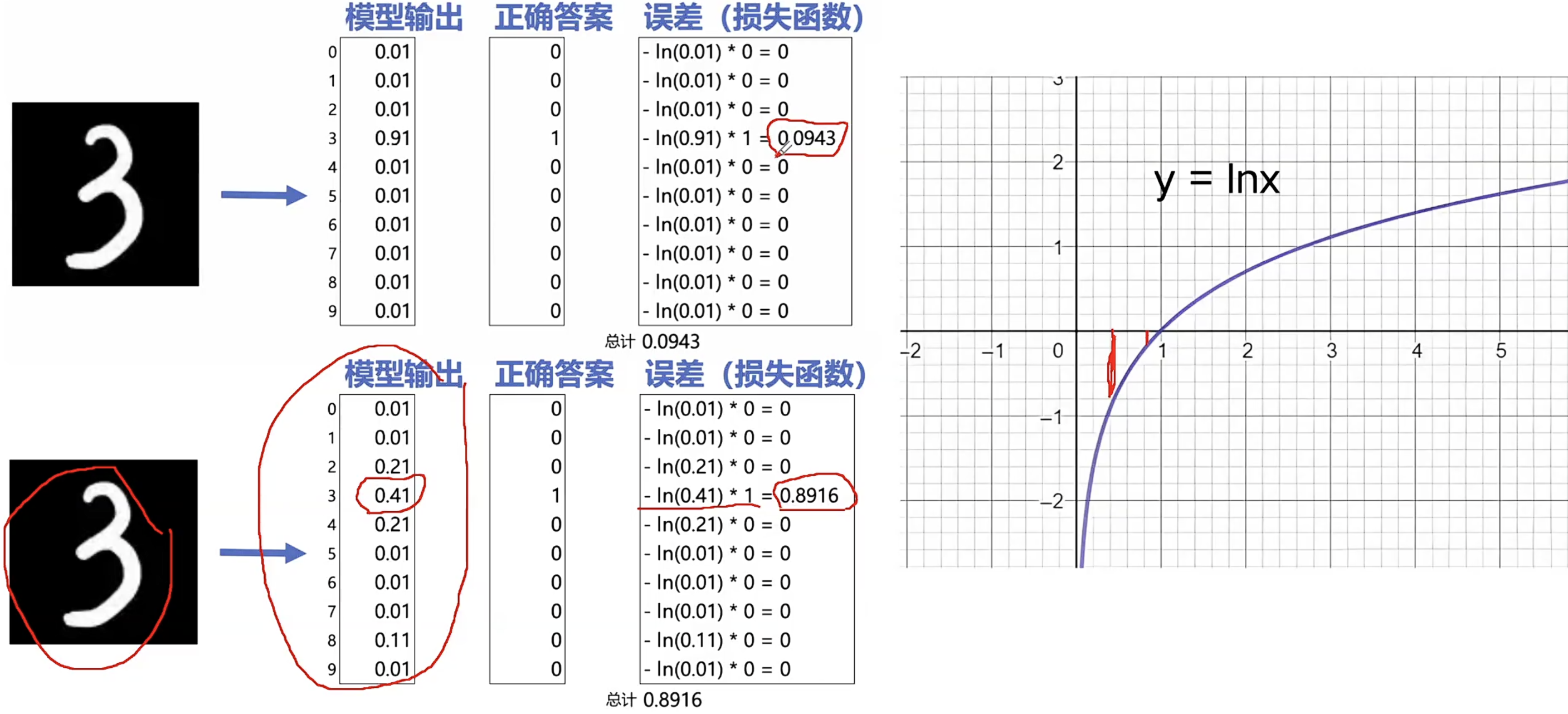
MNIST训练过程
6万张训练图片=>6万个总误差值,每个总误差对应785✖784+785✖28+29✖10=637,710参数
1、随机初始化一组参数
2、在训练数据集中,利用神经网络进行分类
3、计算分类结果的误差
4、计算637,710个参数的值应该如何变化可以减小误差
5、计算出一组新的参数值 6、回到步骤2
LLM预训练和SFT阶段的 总误差定义方式一样
一般来讲,LLM输出下一个字的选择面是10-15万选1(10-15万个概率的总误差)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 16
16 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)