FileVibe全攻略(五):AI图片解读与流式响应实战
本文讲解FileVibe的AI图片解读功能实现。围绕三个核心问题:加密图片如何传给AI(后端解密+Data URL)、图文如何一起发送(多模态API的content数组)、AI生成等待如何优化(流式响应+ReadableStream)。逐行拆解analyzeImage、handleStreamingResponse、parseMarkdown核心代码,重点分析XSS防护的双层设计(textCont
你有没有这种体验:在用一些AI工具写文字的时候,文字是一个一个往外蹦的,而不是等半天突然冒出一大段。这种边生成边显示的效果,就是流式响应(Streaming Response)。
FileVibe的AI图片解读功能也是这样。用户在预览区打开一张图片,右边聊天区会自动感知到“已选择图片”,用户在输入框里打字提问,AI就会一边思考一边把答案逐字显示出来——而且图片和文字是同时发给AI的。
今天我们就来拆这个功能。我会带着你一步步思考:为什么要这么写?如果是我自己写,我会怎么想?同类情况应该怎么处理?
获取源代码:Gitee FileVibe
一、先想清楚:这个功能要解决什么问题?
1.1 用户场景:他到底想要什么?
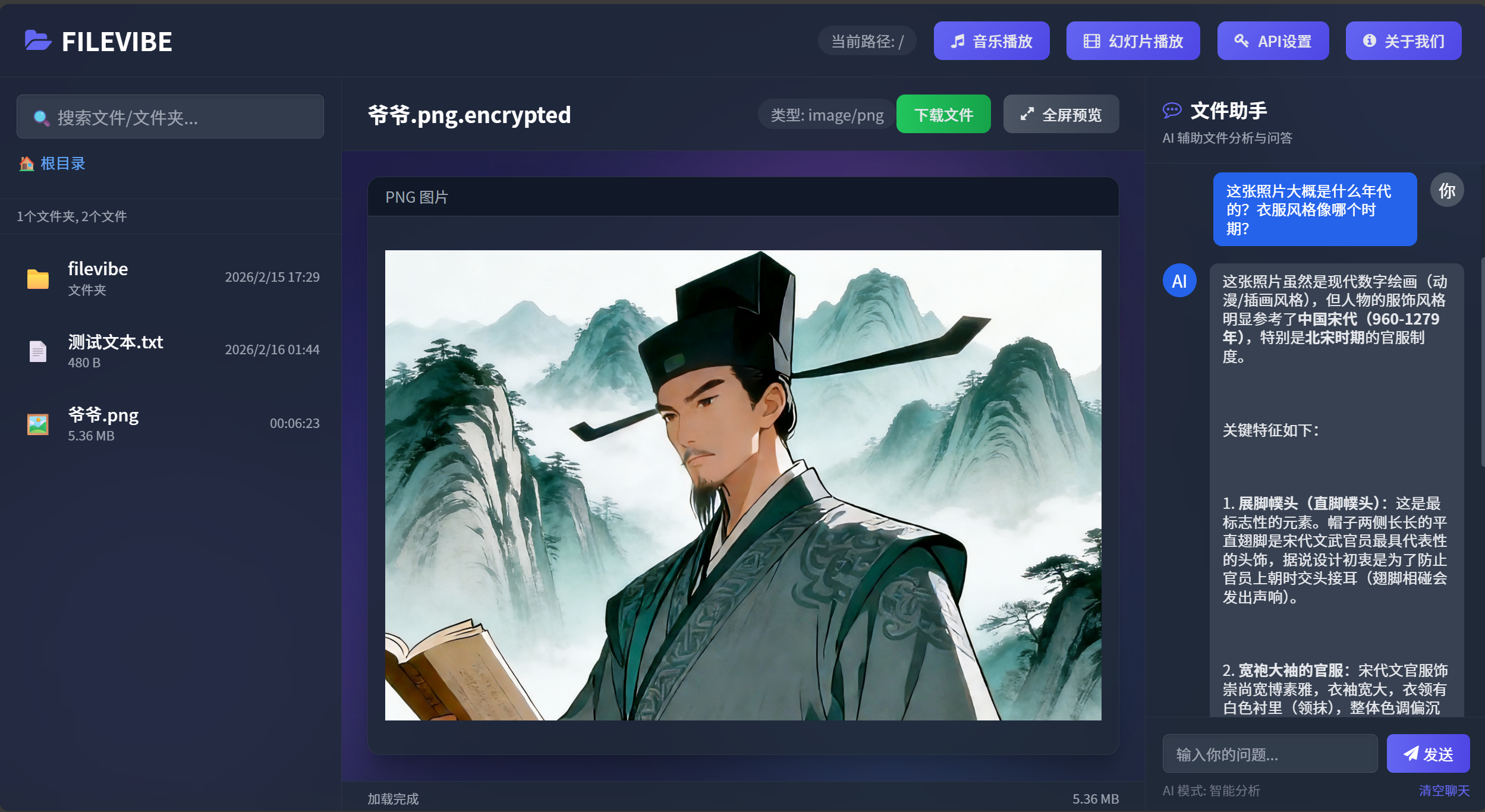
想象你是FileVibe的用户。你电脑里有一张老照片,是你爷爷年轻时的。你想知道:
这张照片大概是什么年代的?衣服风格像哪个时期?
你希望直接选中图片,打个字,AI就能回答你。
这就是用户要的——跟图片对话。
1.2 技术挑战:我们要跨过哪些坎?
把这个需求翻译成技术语言,就是:
| 用户说 | 技术上意味着 |
|---|---|
| “我选中一张图片” | 要把图片数据传给AI |
| “我打个字” | 要把文字和图片一起发给AI |
| “AI回答我” | 要调用能看懂图片的AI模型 |
| “快点显示” | 不能用等全部生成完再显示的方式 |
再往深想一层:
- 图片是加密的:FileVibe的文件都是AES加密的,不能直接把加密文件发给AI
- AI生成要时间:一个完整回答可能5-10秒,让用户干等会疯掉
- AI回答有格式:标题、列表、代码块,直接显示纯文本很难看
- AI回答可能不安全:万一AI返回
<script>alert('xss')</script>,直接插到页面里就完蛋了
所以我们要解决:
| 问题 | 解法 |
|---|---|
| 加密图片怎么给AI看? | 后端解密,前端转成Data URL |
| 图片和文字怎么一起发? | 多模态API,一次请求同时传 |
| 等待时间太长怎么办? | 流式响应,边生成边显示 |
| 回答有格式怎么办? | 解析Markdown,转成HTML |
| 回答不安全怎么办? | XSS防护,双层保险 |
1.3 选型思考:为什么是模力方舟?
选AI服务时,我脑子里过了一遍选项:
- 自己部署模型?不行,太贵太复杂,一个小工具不值得
- OpenAI API?可以,但国内访问不稳定,还得考虑网络问题
- 国产AI平台?有,但得选个靠谱的
最后选了模力方舟(Moark)。为什么?我列个表:
| 考虑因素 | 模力方舟 | 其他平台 |
|---|---|---|
| 是否支持图片理解 | ✅ 多模态模型很多 | 不一定 |
| 调用方式 | Serverless API,直接HTTP调 | 大多也是 |
| 免费额度 | ✅ GLM-4.6V-Flash完全免费 | 有的要付费 |
| 国内访问 | ✅ 国产,稳定 | 国外可能慢 |
| API格式 | ✅ 兼容OpenAI,学习成本低 | 各平台不同 |
思考过程:免费 + 国产 + 好用 = 模力方舟。就这么简单。

二、第一步:图片从哪来?(解密环节)
2.1 问题:文件是加密的,怎么给AI看?
FileVibe有个核心特性:所有文件都是AES-256加密的。硬盘上存的都是.encrypted文件,直接读是乱码。
但AI要的是图片数据,不是乱码。怎么办?
思考过程:
- 不能让前端解密,密钥在前端不安全
- 不能把密钥传给AI,AI不需要知道
- 所以解密必须在后端做,前端拿解密后的数据
2.2 解法:后端解密,前端转Data URL
这是server.js里的事,不是今天重点,但得知道:
// server.js - /api/read接口
let buf = await fs.readFile(file);
if (file.endsWith('.encrypted') && req.session.key) {
buf = decryptBuffer(buf, req.session.key); // 后端解密
}
前端preview.js拿到的是解密后的二进制数据,转成Data URL:
// preview.js - 图片预览部分
const imgUrl = data.isBinary
? `data:${mimeType};base64,${data.contentBase64}`
: `data:${mimeType};base64,${btoa(data.content)}`;
这个imgUrl长什么样?
data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEAYABgAAD...
这是一种Data URL格式:data:[MIME类型];base64,[数据]。浏览器可以直接当图片URL用,<img src="...">就能显示。
2.3 关键点:谁负责什么?
| 模块 | 职责 |
|---|---|
| server.js | 解密文件,返回二进制数据 |
| preview.js | 把二进制转成Data URL,渲染图片 |
| preview.js | 广播file-selected事件,把imgUrl传出去 |
| chat.js | 收到imgUrl,直接发给AI |
chat.js根本不需要知道文件是加密的——它拿到的已经是处理好的图片URL。这就是职责分离。
2.4 同类情况怎么处理?
如果你的应用也有类似场景(比如文件加密、图片处理、数据转换),记住这个原则:
每个模块只做自己擅长的事,做完交给下一个模块,不操心别人怎么做。
- 后端擅长安全,就做解密
- 预览模块擅长渲染,就做Data URL转换
- 聊天模块擅长AI对话,就直接用现成的URL
这样代码才清晰,出了问题也好定位。
三、第二步:图片和文字怎么一起发?
3.1 问题:用户输入和图片怎么组合?
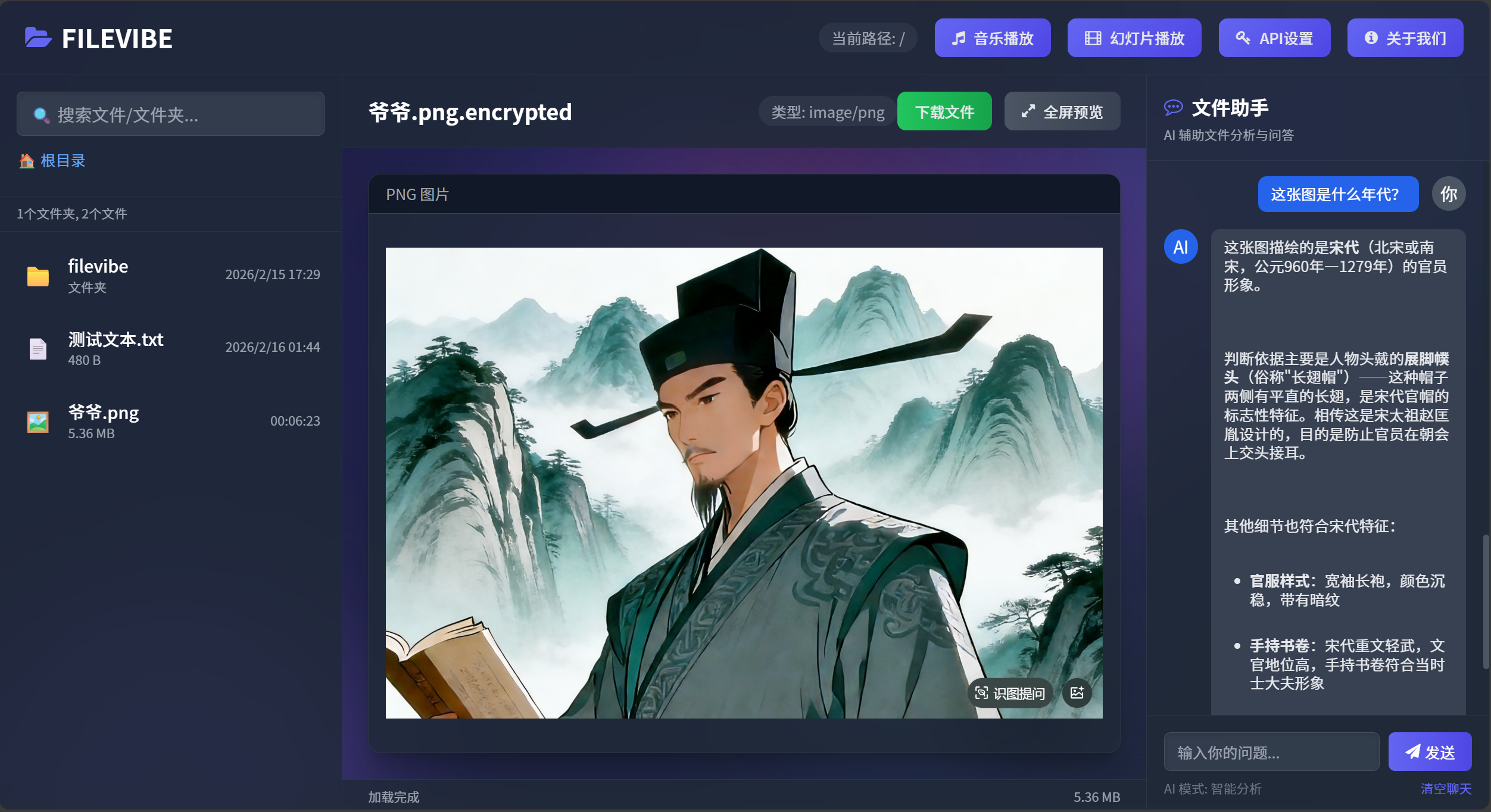
用户的操作可能是这样的:
- 在左边点了一张图片
- 在右边聊天框输入“这张图是什么年代?”
- 点击发送
这时候要发给AI的,是图片 + “这张图是什么年代?” 这两个东西。
思考过程:
- 不能先发图片再发文字,AI需要同时看到两者才能理解
- 必须一次请求同时包含图片和文字
- 找API文档,看怎么传多模态数据
3.2 解法:多模态API的content数组
模力方舟兼容OpenAI的API格式,多模态请求长这样:
{
"messages": [
{
"role": "user",
"content": [
{ "type": "image_url", "image_url": { "url": imageUrl } },
{ "type": "text", "text": userMessage }
]
}
]
}
content字段不再是一个字符串,而是一个数组,可以同时放图片和文字。
3.3 代码实现:怎么把两者拼起来?
看chat.js里的generateAIResponse:
async function generateAIResponse(userMessage) {
try {
// 检查是否有选中的图片文件
if (currentFile && currentFile.type && currentFile.type.startsWith('image/')) {
// 调用图片解读API(同时传图片和文字)
await analyzeImage(currentFile.url, userMessage); // ← userMessage就是聊天框输入的文本
} else {
// 普通文本对话
await generateTextResponse(userMessage);
}
} catch (error) {
console.error('AI回复失败:', error);
addChatMessage('ai', `抱歉,我无法处理你的请求。错误: ${error.message}`);
}
}
关键点:analyzeImage接收两个参数——imageUrl和userMessage。前者来自之前file-selected事件存的currentFile,后者是用户刚输入的文字。
再看analyzeImage内部:
body: JSON.stringify({
messages: [
{
"role": "system",
"content": "You are a helpful and harmless assistant."
},
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": imageUrl // ← 图片URL
}
},
{
"type": "text",
"text": userMessage // ← 用户输入的文本
}
]
}
],
// ...
})
思考过程:
messages数组可以有多个角色:system设定AI人格,user是用户输入- 每个角色可以有多个
content项,类型可以是image_url或text - AI看到这个请求就知道:用户发了一张图片,还问了一个问题
四、第三步:怎么处理AI的返回?(流式响应)
4.1 问题:AI生成要时间,让用户干等?
AI生成一段完整的回答,可能需要5-10秒。如果让用户盯着一个转圈圈等10秒,体验极差。
思考过程:
- 用户点发送后,最想要的是立即看到反馈
- 哪怕只是“AI正在思考…”也比空白好
- 如果能像打字一样一个字一个字显示,用户会觉得AI在“思考”,而不是卡住了
这就是流式响应的由来。
4.2 解法:stream: true + ReadableStream
在请求里加一个参数:
stream: true
告诉API:你别等全部生成完再返回,生成一点发一点。
API返回的就不再是完整的JSON,而是一个流(Stream)。浏览器可以用response.body.getReader()逐块读取。
4.3 代码实现:怎么逐块读取?
看handleStreamingResponse:
async function handleStreamingResponse(response) {
const reader = response.body.getReader();
const decoder = new TextDecoder();
let buffer = '';
try {
while (true) {
const { done, value } = await reader.read();
if (done) break;
// 解码这一块数据
buffer += decoder.decode(value, { stream: true });
// 按行分割(SSE格式是每行一个数据)
const lines = buffer.split('\n');
buffer = lines.pop(); // 保留不完整的行
for (const line of lines) {
if (!line.trim() || !line.startsWith('data: ')) continue;
const dataStr = line.substring(6); // 去掉"data: "
if (dataStr === '[DONE]') break;
try {
const data = JSON.parse(dataStr);
const delta = data.choices?.[0]?.delta;
if (delta?.content) {
updateStreamingMessage(delta.content); // 逐字更新UI
}
} catch (e) {
console.error('解析失败:', e); // 跳过不完整的JSON
}
}
}
completeStreamingMessage(); // 流结束,解析Markdown
} finally {
reader.releaseLock(); // 释放资源
}
}
逐行解释:
第1-2行:getReader()从响应体拿到一个可读流,decoder用来把二进制数据转成字符串。
第4行:buffer用来暂存不完整的数据。为什么需要?因为网络传输是分块的,可能一个完整的JSON被切成两半,比如收到{"cho,下一块才是ices": [...]}。buffer就是用来拼凑的。
第8-10行:reader.read()每次返回一块数据。done为true表示流结束。
第13行:把新数据加到buffer后面。
第16行:按行分割。SSE(Server-Sent Events)格式是每行一个data: {...}。
第17行:lines.pop()把最后一行放回buffer——因为最后一行可能不完整。
第19-21行:跳过空行和非data行。
第22行:去掉开头的data: ,剩下JSON字符串。
第23行:如果是[DONE],表示流结束。
第26-30行:解析JSON,取出delta.content——这就是新生成的那一小段文字。
第28行:updateStreamingMessage把这段文字追加到当前AI消息里。
第36行:流结束,调用completeStreamingMessage做收尾工作。
第38行:finally里释放流锁,避免资源泄露。
4.4 关键点:为什么要有buffer?
思考:如果不用buffer,直接处理每一块数据,会有什么问题?
假设第一块数据是:data: {"choices":[{"delta":{"content":"你好"}}]}\ndata: {"choices":[{"delta":{
第二块数据是:"content":"世界"}}]}\ndata: [DONE]
第一块最后一行不完整,如果直接处理会解析失败。用buffer暂存,等第二块来了再拼起来,就能完整解析。
同类情况:凡是处理流式数据(网络请求、文件读取、WebSocket),都要考虑分块边界的问题。buffer是标准解法。
4.5 流式消息管理:怎么区分多条消息?
用户可能连续发多个请求,每条消息有自己的内容。怎么确保A消息的内容不会跑到B消息里?
let _streamingCounter = 0;
let _currentStreamingId = null;
function addStreamingMessage() {
_streamingCounter += 1;
const contentId = `streamingContent-${_streamingCounter}`;
_currentStreamingId = _streamingCounter;
// 创建空的AI消息容器
const messageDiv = document.createElement('div');
messageDiv.innerHTML = `...<p id="${contentId}"></p>...`;
document.getElementById('chatMessages').appendChild(messageDiv);
}
function updateStreamingMessage(content) {
if (!_currentStreamingId) return;
const el = document.getElementById(`streamingContent-${_currentStreamingId}`);
if (el) {
el.textContent += content;
}
}
思考过程:
- 每条消息需要一个唯一ID
- 用计数器生成ID最简单:1、2、3…
_currentStreamingId记录当前正在接收的是哪条- 更新时根据ID找到对应的DOM元素
为什么不用时间戳做ID? 因为用户可能在1秒内连发两条,时间戳可能重复。
为什么不用UUID? 没必要,简单计数器就够了。
五、第四步:怎么把Markdown变好看?
5.1 问题:AI返回的是带格式的文本
AI返回的内容可能是这样的:
这张照片虽然是**现代数字绘画(动漫/插画风格**)
但人物的服饰风格明显参考了**中国宋代(960-1279年)**
特别是**北宋时期**的**官服制度**。
直接显示成纯文本很难看。用户期待的是:
- 粗体真的变粗
- 列表前面有点
- 代码块有背景色、等宽字体
5.2 解法:解析Markdown,转成HTML
FileVibe自己写了个简单的Markdown解析器,不用第三方库。
function parseMarkdown(text) {
if (!text) return '';
let result = text
// 标题
.replace(/^### (.*$)/gim, '<h3 class="text-lg font-bold mt-4 mb-2">$1</h3>')
.replace(/^## (.*$)/gim, '<h2 class="text-xl font-bold mt-5 mb-3">$1</h2>')
.replace(/^# (.*$)/gim, '<h1 class="text-2xl font-bold mt-6 mb-4">$1</h1>')
// 粗体和斜体
.replace(/\*\*(.*?)\*\*/gim, '<strong>$1</strong>')
.replace(/\*(.*?)\*/gim, '<em>$1</em>')
// 代码块
.replace(/```(\w*?)\n([\s\S]*?)```/gim,
'<pre class="bg-gray-800 p-4 rounded-md overflow-x-auto"><code class="text-sm">$2</code></pre>')
// 行内代码
.replace(/`(.*?)`/gim, '<code class="bg-gray-800 px-1 py-0.5 rounded text-sm">$1</code>')
// 列表
.replace(/^\- (.*$)/gim, '<li class="list-disc ml-6">$1</li>');
return result;
}
逐行解释:
第5行:/^### (.*$)/gim 匹配以### 开头的行,$1是后面的内容。gim标志:g全局匹配、i不区分大小写、m多行模式。
第8行:/\*\*(.*?)\*\*/gim 匹配**内容**这样的粗体。.*?是非贪婪匹配,确保只匹配最近的一对**。
第11行:/```(\w*?)\n([\s\S]*?)```/gim 匹配代码块:
(\w*?)匹配语言名称(如python),非贪婪\n匹配换行([\s\S]*?)匹配代码内容,包括换行,非贪婪
第14行:/(.*?)/gim 匹配行内代码,比如print()。
第16行:/^\- (.*$)/gim 匹配以- 开头的列表项。
5.3 为什么要自己写,不用现成库?
思考:
- 引入一个Markdown库,可能增加几十KB体积
- 库的功能可能过剩,FileVibe只需要基本的标题、列表、代码块
- 自己写可以精确控制生成的HTML类名,和Tailwind CSS完美配合
同类情况:如果你的项目只需要某个功能的一小部分,自己实现比引入库更轻量。当然,如果功能复杂(比如表格、脚注),还是用库更稳妥。
六、第五步:怎么防止XSS攻击?
6.1 问题:AI返回的内容可能不安全
AI是第三方服务,你无法控制它返回什么。万一它返回:
<script>alert('XSS')</script>
<img src=x onerror=alert('XSS')>
直接插到页面里,用户的浏览器就会执行这些恶意代码。
思考:绝对不能信任AI返回的内容,必须做防护。
6.2 解法:双层防护
FileVibe用了两层防护:
第一层:流式接收时用textContent
function updateStreamingMessage(content) {
const el = document.getElementById(`streamingContent-${_currentStreamingId}`);
if (el) {
el.textContent += content; // 注意:用textContent,不是innerHTML
}
}
textContent只当纯文本处理,不会解析HTML。所以就算收到<script>,也只会显示成<script>,不会执行。
第二层:最后解析时先转义
function completeStreamingMessage() {
const streamingContent = document.getElementById(contentId);
// 第一层防护:从textContent取纯文本(确保没有可执行代码)
const markdownText = streamingContent.textContent;
// 第二层防护:先HTML转义
const escapedText = escapeHtml(markdownText);
// 再解析Markdown
const htmlText = parseMarkdown(escapedText);
// 最后插入格式化后的HTML
streamingContent.innerHTML = htmlText;
}
function escapeHtml(text) {
const map = {
'&': '&',
'<': '<',
'>': '>',
'"': '"',
"'": '''
};
return text.replace(/[&<>'"]/g, m => map[m]);
}
转义函数做了什么?
把特殊字符替换成HTML实体:
<→<>→>&→&"→"'→'
这样浏览器看到<script>,只会显示成<script>文本,不会当作标签执行。
6.3 为什么不在接收过程中直接转义?
因为Markdown解析需要原样的文本。比如:
<你好>
如果先转义变成<你好>,再解析Markdown,就找不到<开头的标签了。所以顺序是:
- 流式接收时用
textContent存纯文本(安全) - 接收完后从
textContent取纯文本(安全) - 先转义(防XSS)
- 再解析Markdown(转成好看的HTML)
- 最后用
innerHTML插入(此时已经安全)
6.4 同类情况怎么处理?
任何时候,只要你要把外部输入插入到DOM里,都要做XSS防护:
| 输入来源 | 防护方式 |
|---|---|
| 用户输入 | 显示时用textContent,或转义后innerHTML |
| API返回 | 同上 |
| URL参数 | 同上 |
| localStorage数据 | 同上 |
原则:永远不要信任外部数据,永远先转义后插入。
七、总结:整个流程是怎么串起来的?
把上面所有环节串起来,就是完整的AI图片解读流程:
[用户操作]
↓
点击图片 → list.js触发'open-file'事件
↓
preview.js监听到 → 调用/api/read获取解密后的图片数据
↓
preview.js把二进制转成Data URL → 渲染图片 → 触发'file-selected'事件
↓
main.js监听到 → 调用chat.js的updateCurrentFile()
↓
chat.js记录currentFile = { url: 'data:...', name: 'xxx.jpg' }
↓
[用户输入文字,点击发送]
↓
chat.js的generateAIResponse被调用 → 检测到有currentFile
↓
调用analyzeImage(currentFile.url, userMessage)
↓
addStreamingMessage()创建空的消息容器
↓
fetch模力方舟API,设置stream: true
↓
服务器开始流式返回数据
↓
handleStreamingResponse逐块读取 → 每收到一段内容就updateStreamingMessage
↓
updateStreamingMessage用textContent追加内容(安全第一)
↓
流结束 → completeStreamingMessage被调用
↓
从textContent取纯文本 → escapeHtml转义 → parseMarkdown解析
↓
用innerHTML插入格式化后的内容
↓
用户看到格式漂亮的AI回答
八、写在最后
回顾整个实现,你会发现每个决策背后都有为什么:
| 决策 | 为什么 |
|---|---|
| 后端解密 | 密钥不能放前端 |
| Data URL传图片 | 浏览器原生支持,简单 |
| 图片和文字一起发 | AI需要同时理解两者 |
| 流式响应 | 改善等待体验 |
| buffer暂存 | 处理网络分块 |
| 计数器做ID | 区分多条消息 |
| 自己写Markdown解析 | 轻量,可控 |
| 双层XSS防护 | 安全第一 |
写代码不只是写代码,是在做决策。每个决策背后都要想清楚:为什么要这么选?有没有更好的?如果出了问题会怎样?
FileVibe的AI图片解读功能,就是这些决策的集合。希望你看完这篇文章后,不只是会抄这几段代码,而是能理解为什么要这么写,以后遇到类似场景,也能自己做出好的决策。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)