脑电大模型系列——第一弹:BENDR
摘要: BENDR提出一种基于Transformer的自监督学习框架,利用海量无标注EEG数据(TUEG数据集,1.5TB临床记录)预训练通用脑电表征。通过卷积编码器降采样和掩码对比学习,模型学习从上下文推断缺失信号特征的能力。在5种跨范式任务(运动想象、P300等)测试中,BENDR显著超越传统方法,尤其在数据稀缺场景下表现优异。该工作为脑电基础模型研究奠定基础,代码已开源。
论文基本信息
Paper: BENDR: Using Transformers and a Contrastive Self-Supervised Learning Task to Learn From Massive Amounts of EEG
机构: UofT (多伦多大学)
Publication: Frontiers in Human Neuroscience
Year: 2021
背景
脑机接口(BCI)领域面临一个根本性困境:深度神经网络(DNN)需要大量数据训练,但高质量的标注EEG数据极其稀缺。具体来说:
- 收集并标注100个BCI试验比标注100张图像困难得多
- 传统浅层神经网络在BCI中表现反而优于深层网络,因为深层网络容易过拟合
- EEG数据存在巨大的个体差异(不同被试、不同会话、不同设备)
BENDR开辟了"基础模型"(Foundation Model)路线在脑科学中的应用:通过自监督学习从海量无标注神经生理数据中提取通用表征,再适配特定临床或BCI应用。
方法
(1)数据集
预训练数据集:TUEG👇
- Temple University Hospital EEG Corpus
- 10,000+被试,临床记录,年龄1-90+岁,51%女性
- 部分被试间隔8个月多次记录
- 使用19通道10-20系统,约1.5TB原始数据
- 提取60秒片段(15,360样本),用于学习通用EEG分布
(2)预处理
首先做每段序列的线性缩放和平移,把该段的幅值范围归一到 [-1, 1];但为了不完全丢掉“全数据集相对幅度信息”,额外加入一个常数通道编码该段相对幅值范围(相对整个数据集的 max-min 比例)。然后将原始EEG信号统一重采样到256Hz。最后针对不同规格脑电帽的异构问题进行通道统一化处理,把通道对齐到 10-20 导联标准中的19个EEG 通道;缺失通道补 0,多余通道丢弃;加上前面的相对幅度常数通道,最终固定为 20 通道输入。
(3)预训练策略
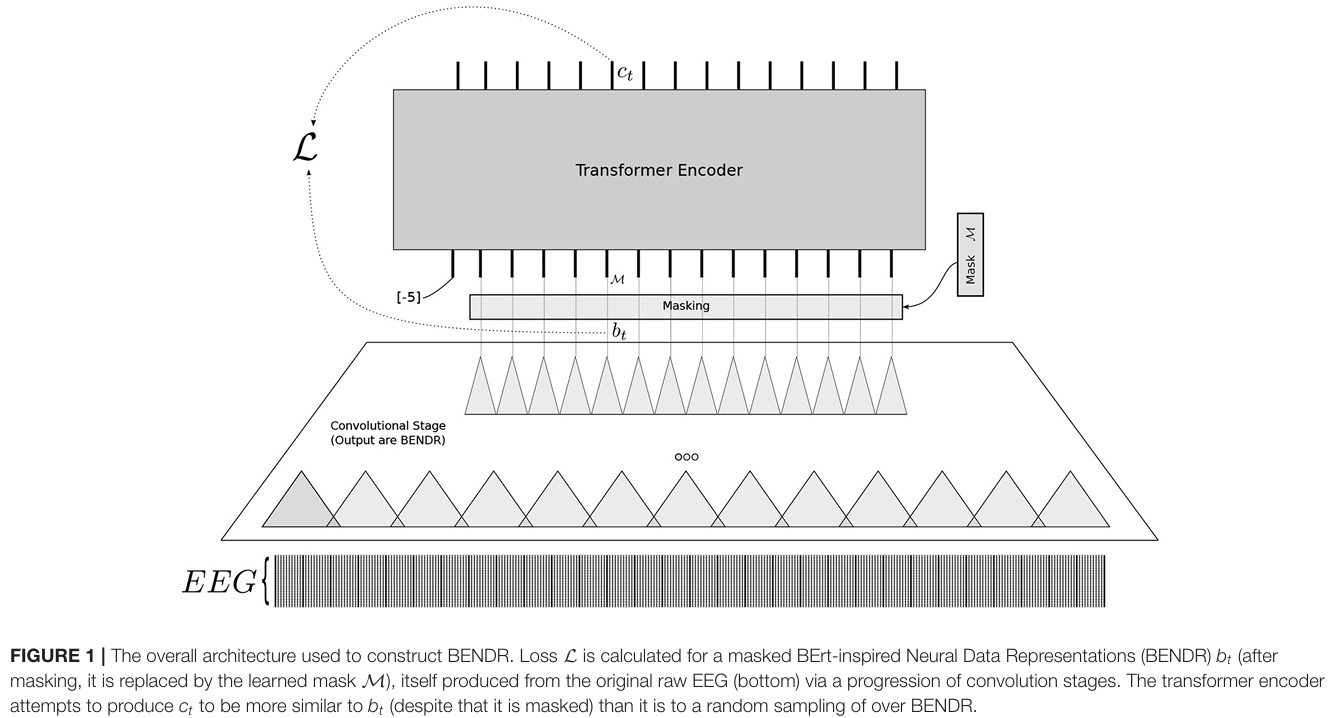
经过预处理后的信号先通过6层1D卷积编码器下采样96倍生成BENDR表示序列,再经掩码处理(5%概率随机选择初始起点,连续掩码10个向量)输入8层Transformer编码器生成上下文表示,针对掩码位置计算对比学习损失,即最大化该位置Transformer输出与原始BENDR表示的余弦相似度,同时最小化与20个同序列负样本的相似度,迫使模型学习从上下文推断缺失信号特征的通用EEG表示能力。
(4)通道异构
BENDR通过"强制对齐"解决通道异构——用标准19通道模板(如下所示)映射所有数据,缺失填零、多余丢弃。
Fp1, Fp2, F7, F3, Fz, F4, F8, T3, C3, Cz,
C4, T4, T5, P3, Pz, P4, T6, O1, O2
(5)预训练损失
BENDR的预训练损失由对比损失和正则化损失两部分相加而成。首先,原始EEG信号经过卷积编码器压缩为BENDR表示序列,随后随机选取部分位置(概率5%)进行连续掩码(每处掩码10个向量,约3.75秒),用可学习的掩码向量替换原始BENDR。掩码后的序列输入Transformer编码器,生成上下文表示。对比损失针对每个掩码位置计算:最大化该位置Transformer输出与原始BENDR表示的余弦相似度,同时最小化与20个同序列随机负样本的相似度,通过温度系数0.1缩放后计算InfoNCE损失,迫使模型从上下文推断缺失信号特征。
正则化损失则计算所有BENDR向量的L2范数平方均值,权重为1,防止表示数值过大。最终总损失为两者之和,通过反向传播更新卷积编码器、Transformer、投影矩阵及掩码向量的参数。
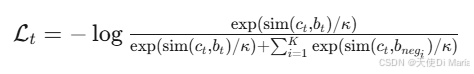
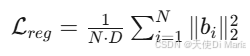
实验
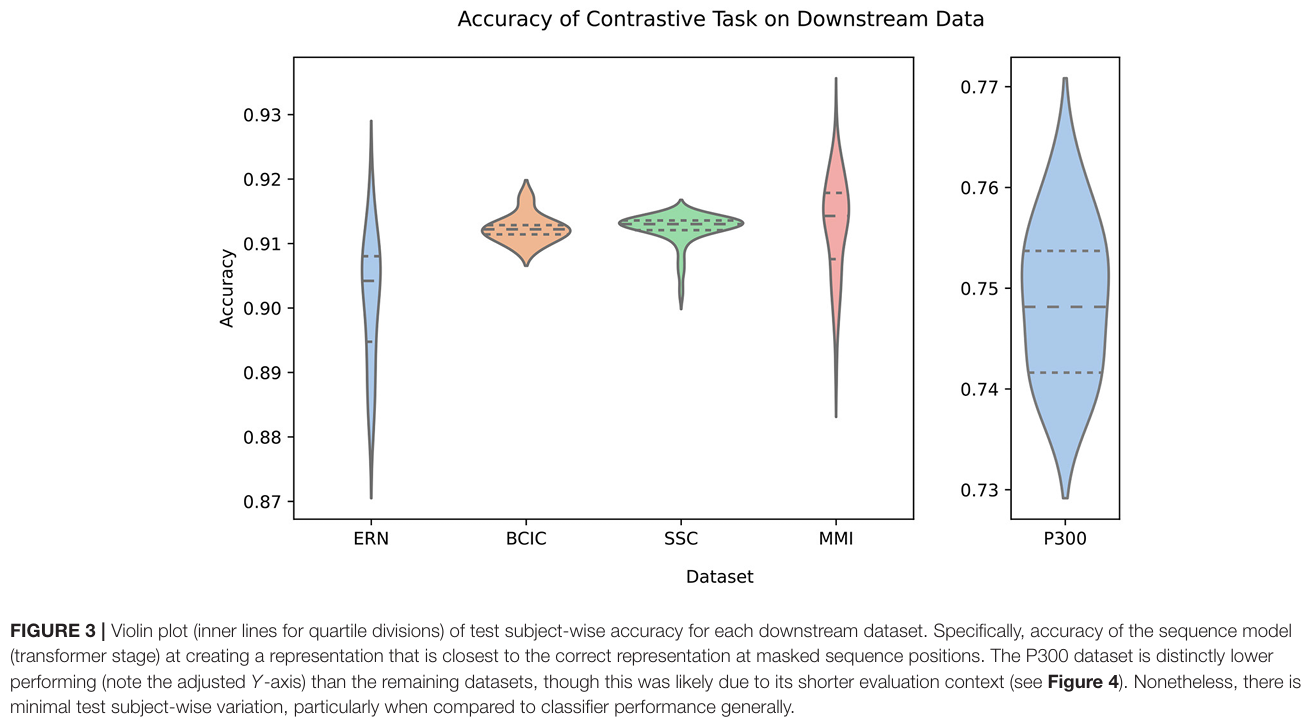
在未见过的新数据集、新被试、新设备上,作者挑了 5 个典型范式,覆盖 MI、ERP(P300/ERN)、睡眠分期(SSC):
- MMI(MI 二分类 L/R):160Hz,64ch,105 subjects,5 folds
- BCIC(MI 四分类 L/R/F/T):250Hz,22ch,9 subjects,9 folds(基本 LOSO)
- ERN(错误相关负波 二分类):200Hz,56ch,26 subjects(另有 10 个 held-out test subjects),4 folds
- P300(P300 speller 二分类):2048Hz,64ch,9 subjects,9 folds
- SSC(Sleep staging 五分类):100Hz,2ch,83 subjects,10 folds
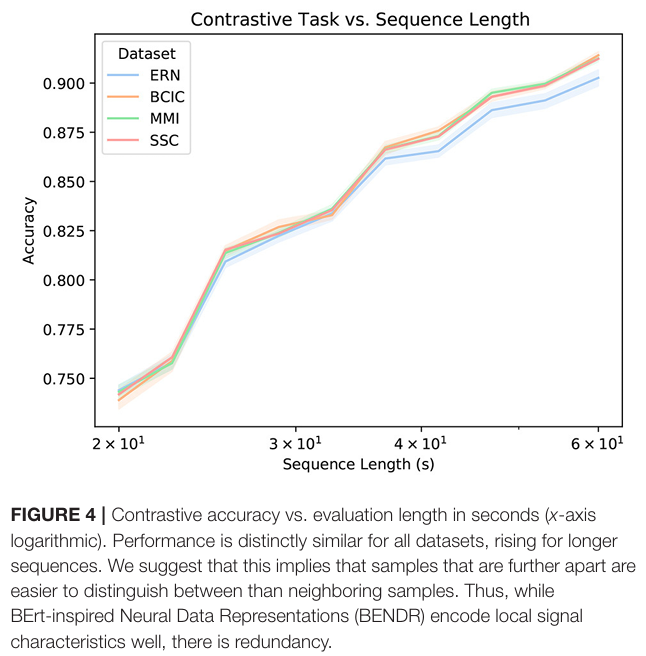
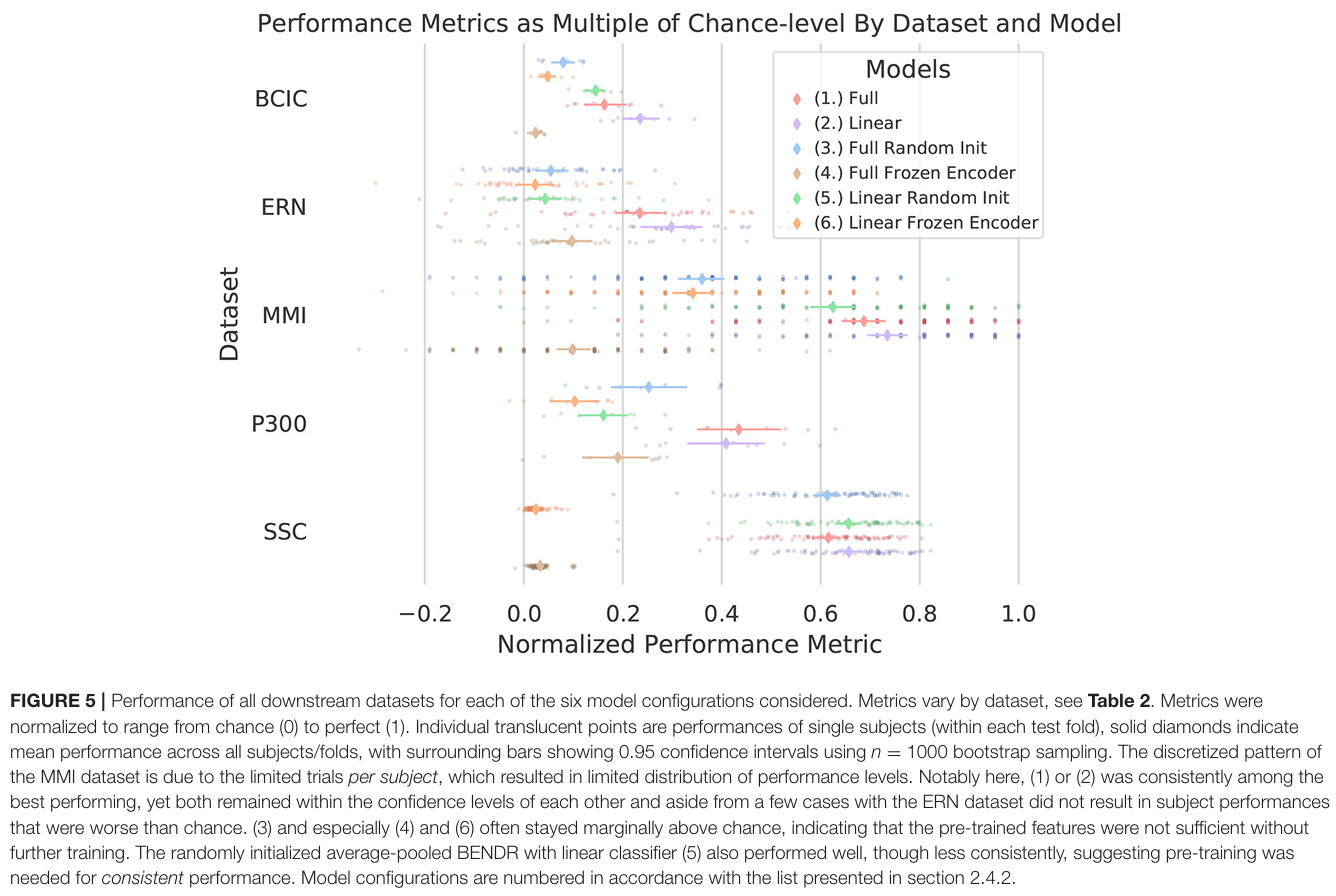
总结
BENDR证明,通过借鉴NLP的BERT技术,用掩码对比学习从大规模无标注EEG数据中学习通用神经表示,可以有效解决脑机接口中的跨任务泛化难题,为深度学习在脑科学中的应用开辟了新路径,为之后脑电大模型研究奠定了基础。
代码开源链接。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 15
15 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)