【OpenClaw 本地实战 Ep.1】抛弃 Ollama?转向 LM Studio!Windows 下用 NVIDIA 显卡搭建 OpenClaw 本地极速推理服务
摘要:本教程介绍在Windows11环境下使用LMStudio替代Ollama搭建OpenClaw本地推理服务的方法。通过三步配置(开启CUDA加速、启动无界面服务、建立OpenAI兼容接口),可充分发挥NVIDIA显卡(如RTX3090)的算力优势。文章详细演示了LMStudio的GPU加速设置和后台服务开启流程,为后续OpenClaw对接奠定基础。该方案解决了Windows平台下Ollama无
【OpenClaw 本地实战 Ep.1】抛弃 Ollama?转向 LM Studio!Windows 下用 NVIDIA 显卡搭建 OpenClaw 本地极速推理服务
摘要:
OpenClaw 本地化部署第一弹。
解决 Windows 11 下 Ollama 无法稳定调用 CUDA 的痛点,手把手教你用 LM Studio + RTX 3090 (或其他 NVIDIA 显卡) 开启 GPU Offload 和 无界面后台服务,搭建完美的 OpenAI 兼容接口。
标签:
NVIDIA 显卡 本地部署 LM Studio CUDA加速 OpenClaw Windows开发
写在前面:为什么要开启这个系列?
在 Windows 11 环境下折腾本地 AI Agent(智能体)时,很多开发者都会遇到一个经典困境:“大脑”跟不上“手脚”。
我们希望用 OpenClaw 这样强大的框架来编排任务,但在底层推理后端上,常用的 Ollama 在 Windows(特别是配合最新的 Intel Ultra CPU + NVIDIA 显卡时)经常出现 GPU 调度失灵的问题——明明插着一张 RTX 3090 24GB,它却非要用 CPU 跑,推理速度慢得像蜗牛。
为了解决这个问题,我摸索出了一套 “LM Studio + OpenClaw” 的黄金组合。
本系列将分四篇文章,从零开始带你搭建一套 满血版 的本地 AI 开发环境。
🚀 本系列规划:
-
👉 Ep.1(本文):基础设施搭建 —— 用 LM Studio 满血释放 NVIDIA 显卡算力
-
Ep.2:强强联合 —— 修改 OpenClaw 配置连接本地服务
-
Ep.3:突破瓶颈 —— 强制解锁 32k 上下文,解决 Context Window 报错
-
Ep.4:终极提效 —— 固定 Token 实现浏览器无缝重连
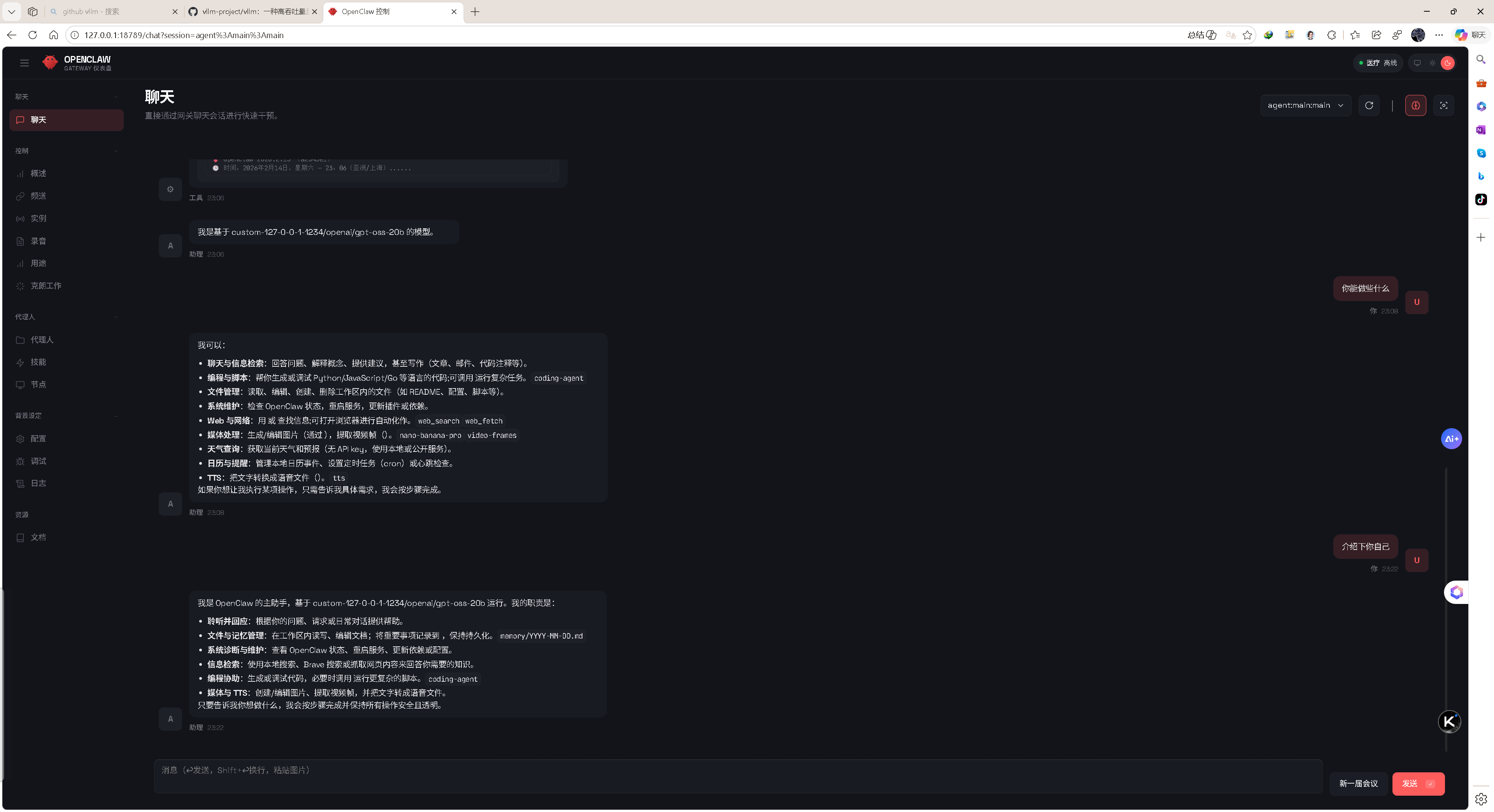
图1:LM Studio + OpenClaw” 黄金组合的本地服务启动成功。
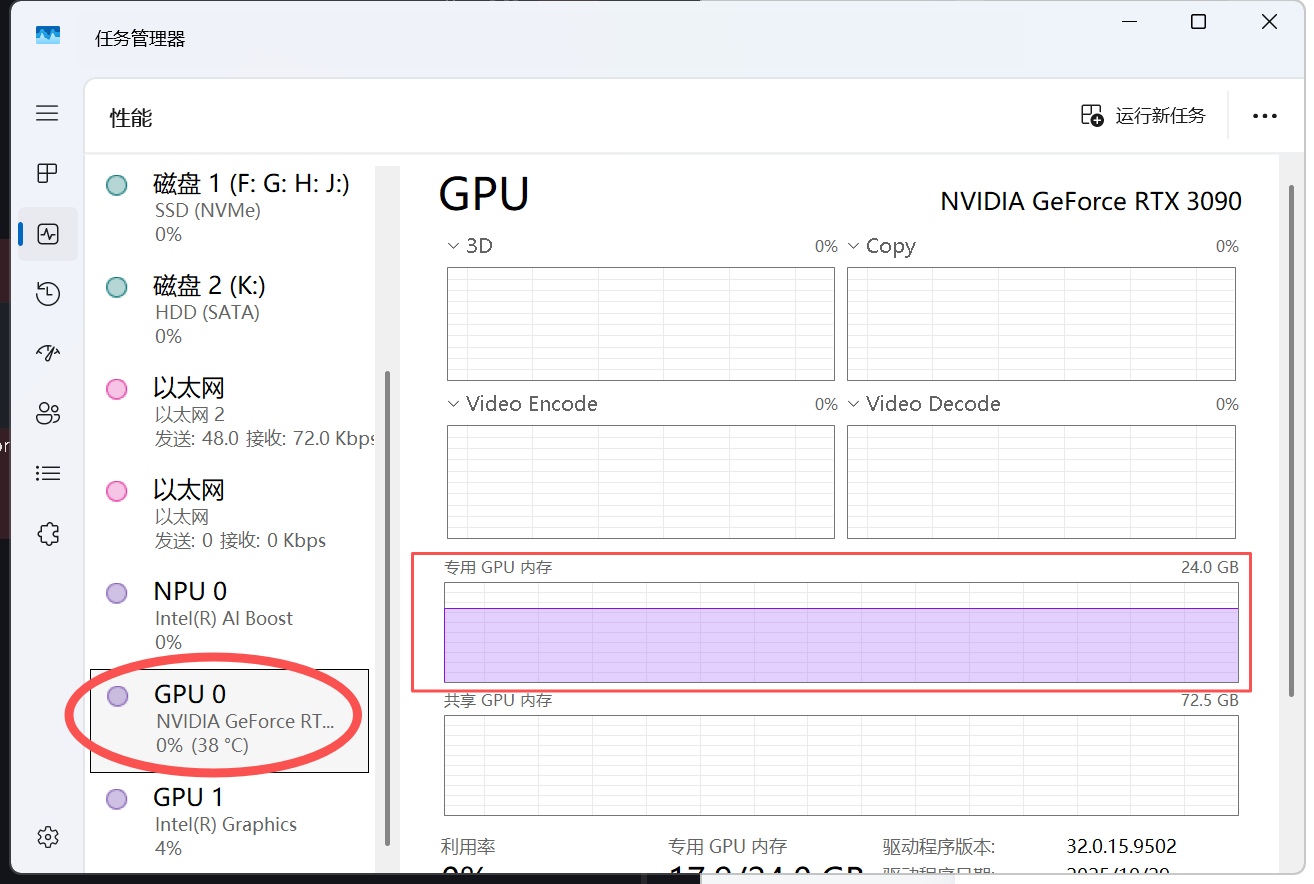
图2:LM Studio + OpenClaw” 的黄金组合 充分利用了 NVIDIA 显卡进行推理。
一、 硬件准备:NVIDIA 显卡是关键
想要本地 AI 跑得快,显存(VRAM)是第一生产力。
以下是我的测试环境,本教程适用于所有支持 CUDA 的 NVIDIA 显卡(如 RTX 3060/4060/4090 等)。
-
CPU: Intel Core Ultra 9 285K
-
GPU: NVIDIA GeForce RTX 3090 (24GB VRAM)
-
软件: LM Studio (0.4.2 或更高版本)
二、 核心配置:三步榨干显卡算力
第一步:开启 CUDA 硬件加速 (GPU Offload)
这是性能起飞的关键!很多新手只是下载了模型,却忘了把模型“装进”显卡里。
-
选中并加载一个模型,例如
openai/gpt-oss-20b。 -
打开 LM Studio 右侧侧边栏(左下角)的 Settings (齿轮图标)。
-
进入 Hardware 选项卡。
-
GPUs:确保识别并选中了你的 NVIDIA 显卡(如下方截图中的 RTX 3090)。
-
GPU detected with CUDA:务必勾选 ON。
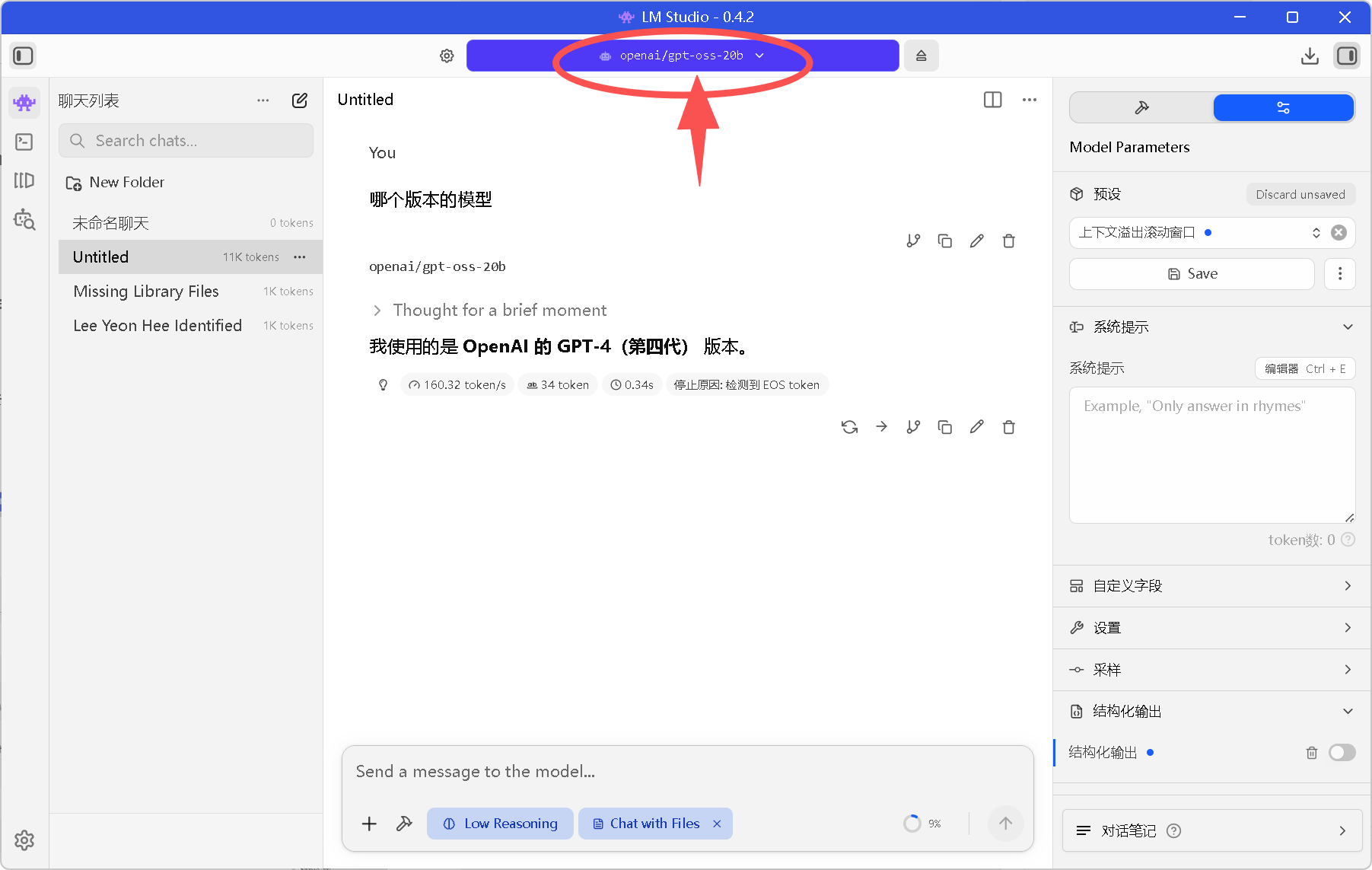
图3:LM Studio 启动成功,模型加载已就绪。
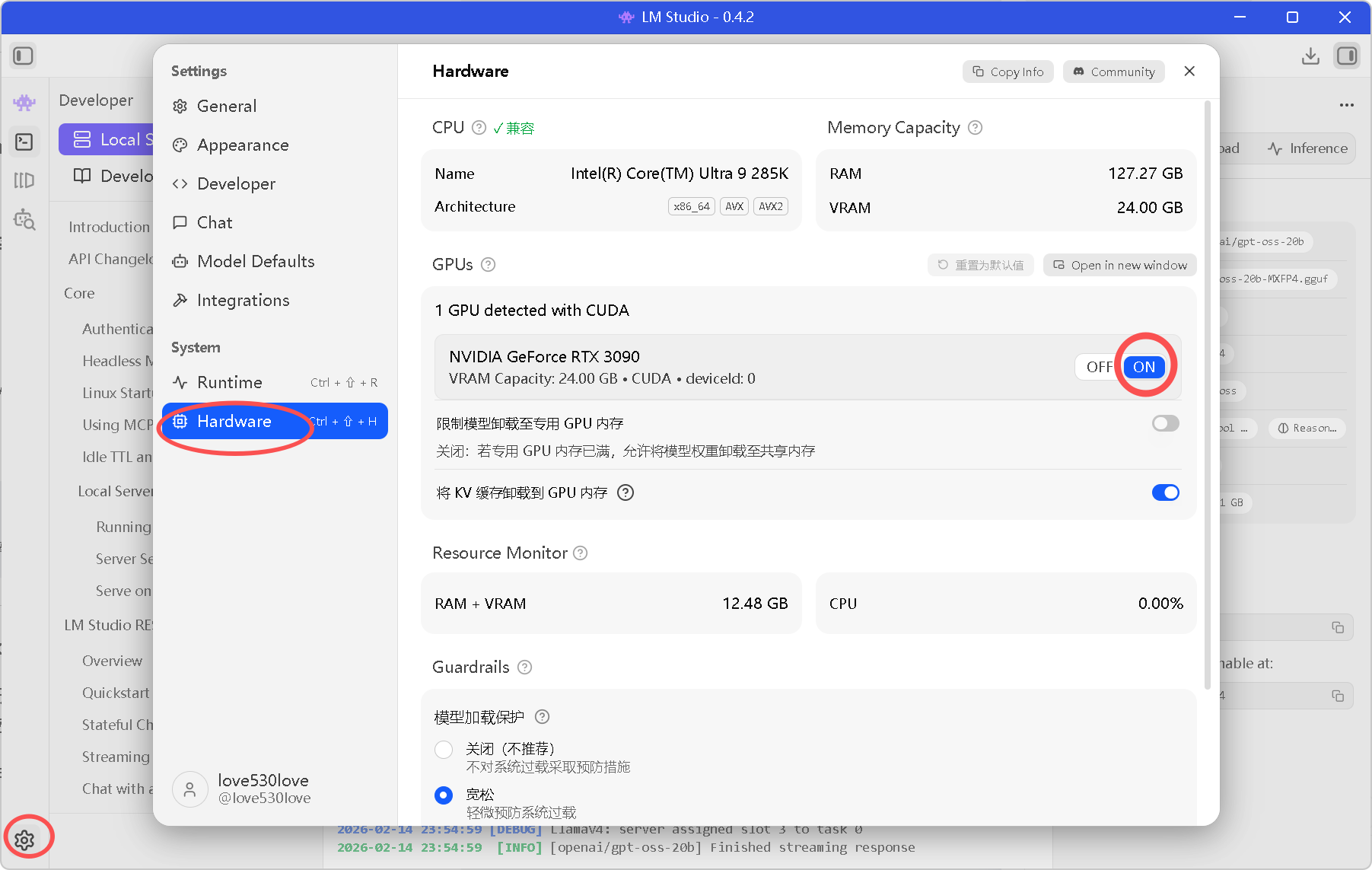
图4:LM Studio 成功识别 RTX 3090,显存容量 24GB,CUDA 加速已开启。
第二步:开启后台无界面服务 (Headless Mode)
这是让 LM Studio 成为合格“服务器”的关键设置。开启此选项后,LM Studio 可以更稳定地作为后台服务运行,哪怕你不打开聊天窗口,它也能响应 OpenClaw 的请求。
-
在 Settings 菜单中,点击 Developer 选项卡。
-
找到 “本地 LLM 服务(无界面)” 区域。
-
勾选 “启用本地 LLM 服务”。
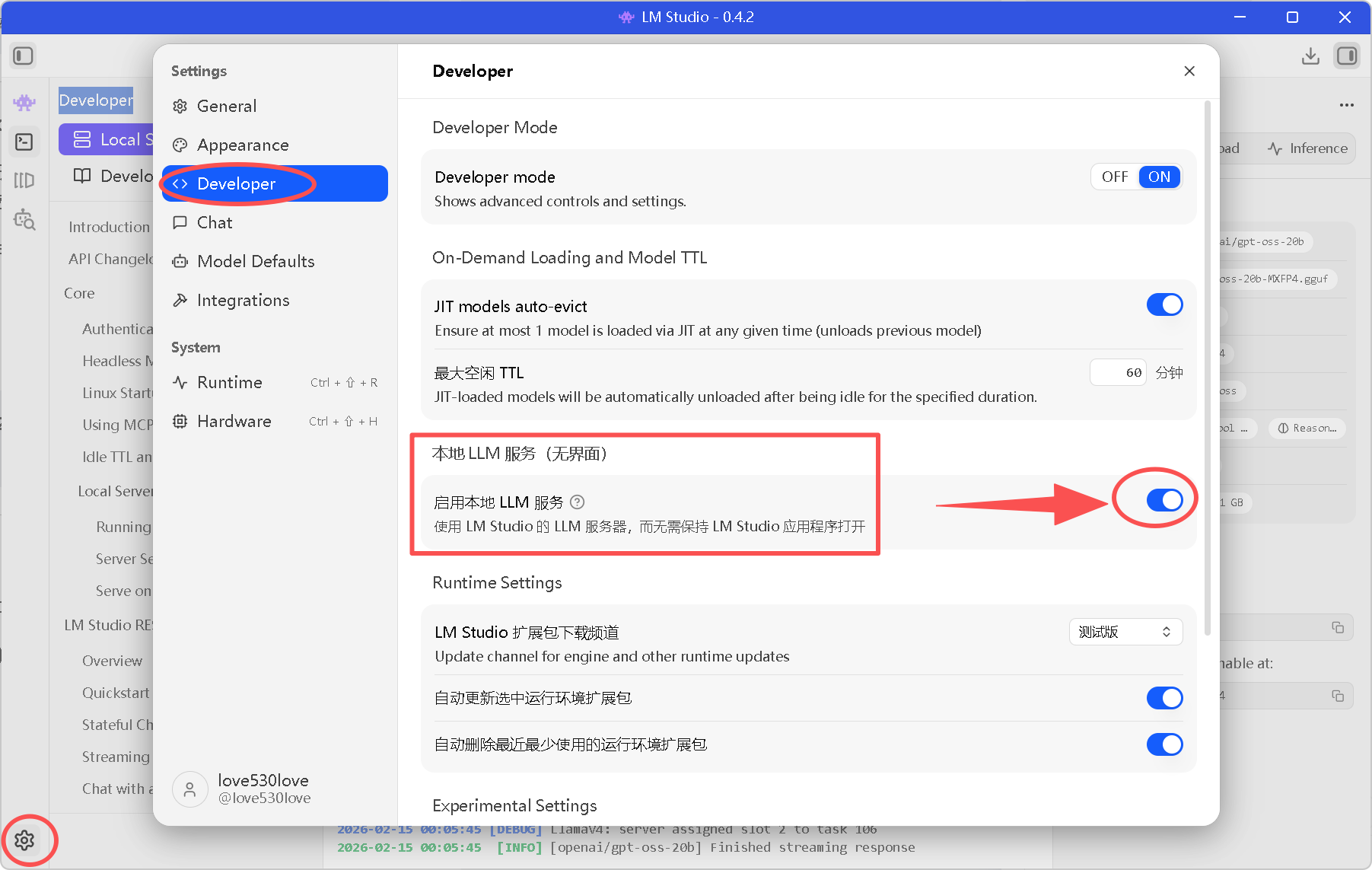
图5:开启无界面服务模式,确保后台推理的稳定性。
第三步:启动 OpenAI 兼容接口
OpenClaw 默认是为 OpenAI 设计的,我们需要让 LM Studio 伪装成 OpenAI。
-
点击左侧侧边栏的 Developer / Server (<->) 图标。
-
Server Settings:
-
Port:保持默认 1234。
-
CORS:建议开启(防止跨域报错)。
-
-
点击蓝色的 Start Server 按钮。
-
关键检查:
-
确保顶部的状态显示为绿色的 Status: Running。
-
记下右侧的 API Model Identifier(例如
openai/gpt-oss-20b),我们在下一篇配置 OpenClaw 时必须用到它。
-
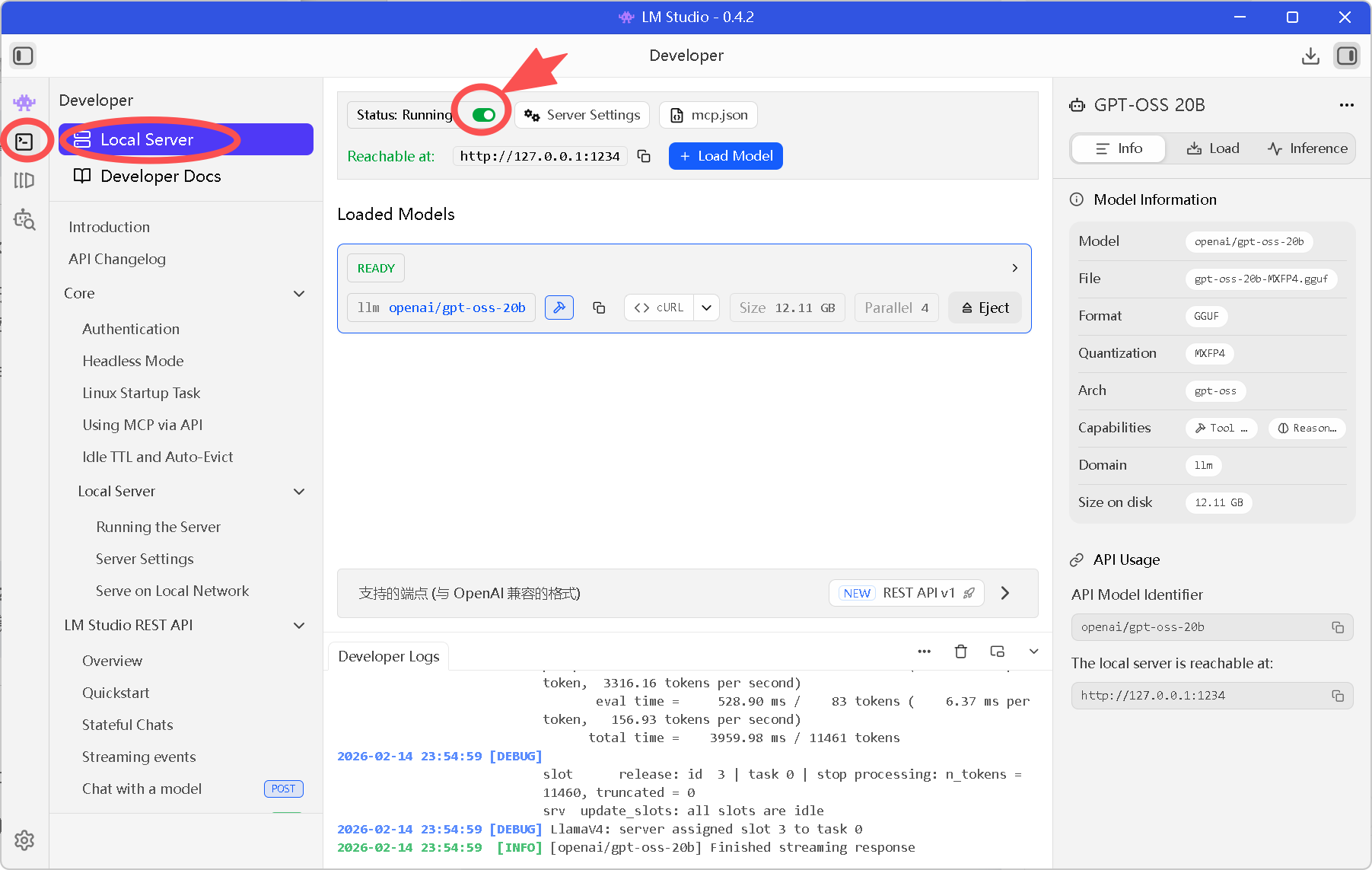
图6:本地服务启动成功,监听在 1234 端口,模型无界面本地服务已就绪。
三、 效果验证
至此,你的本地电脑已经变成了一个“私有版 OpenAI 服务器主机”。
-
你可以在 LM Studio 的 Server Logs 窗口看到实时的请求日志。
-
在 RTX 3090 的加持下,推理速度(Speed)应该非常快,几乎没有延迟。
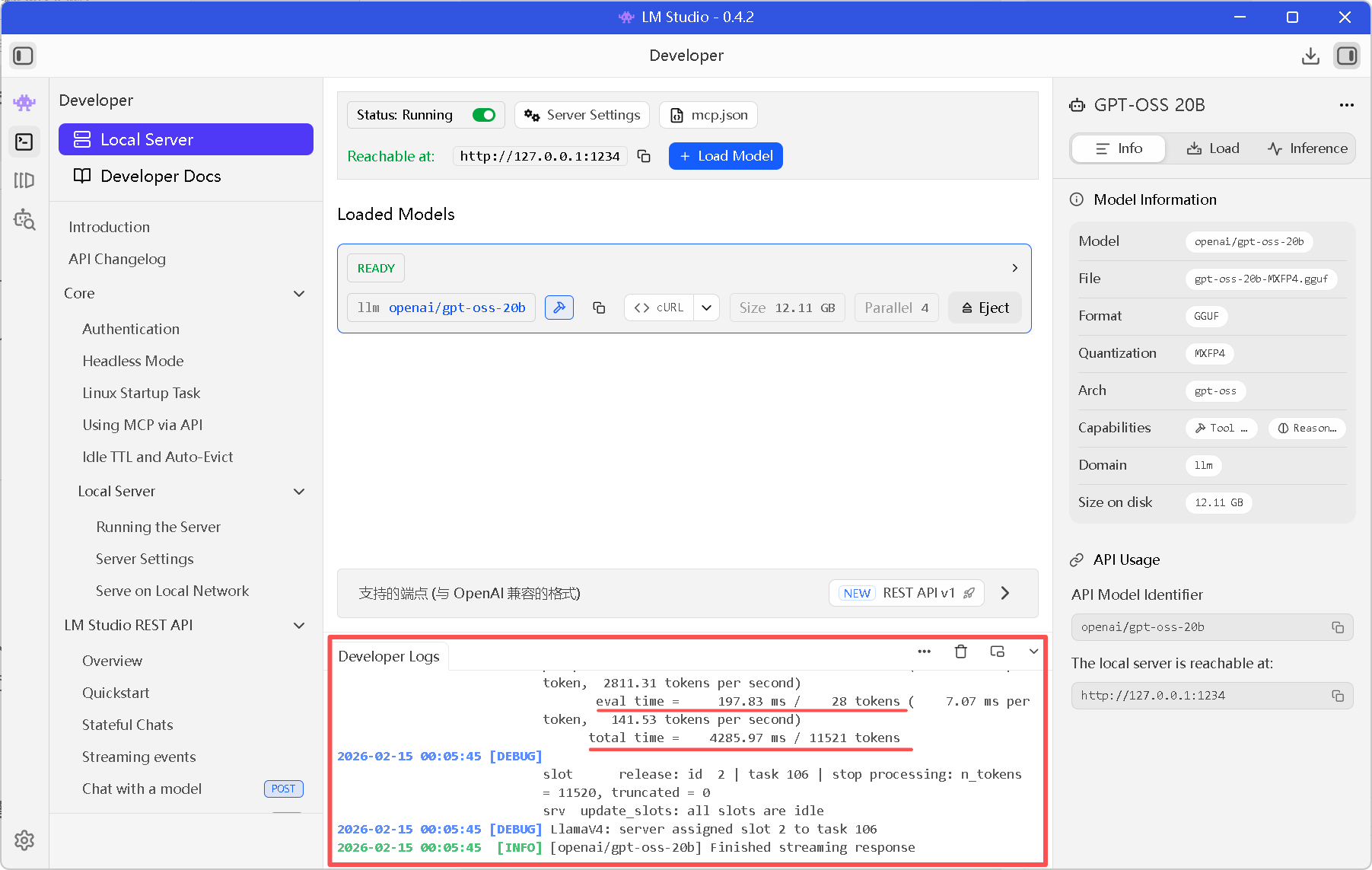
图7:在 OpenClaw 推理时,可以在erver Logs 窗口这里查看运行日志。
四、 下一步计划
现在,“大脑”(LM Studio + RTX 3090)已经就位,而且提供了标准的接口 。
http://127.0.0.1:1234/v1你可以重启 LM Studio 后 在 LM Studio 的聊天界面测试一下,体验那如丝般顺滑的生成速度。
但是,仅仅有一个服务端是不够的。
我们还需要一个强大的“大脑指挥官”——OpenClaw,来连接这个服务,并让它具备写代码、读文件、个人助理等能力。
在下一篇文章中,我将不再通过枯燥的代码修改,而是展示如何利用 OpenClaw 自带的 交互式设置向导 (Setup Wizard),像安装游戏一样,几步操作就完成与本地 LM Studio 的对接。
下一篇预告: 👉 《【OpenClaw 本地实战 Ep.2】零代码对接:使用交互式向导快速连接本地 LM Studio 用 CUDA GPU 推理》
(剧透:你将看到那个超酷的 🦞 OPENCLAW 🦞 启动画面!)
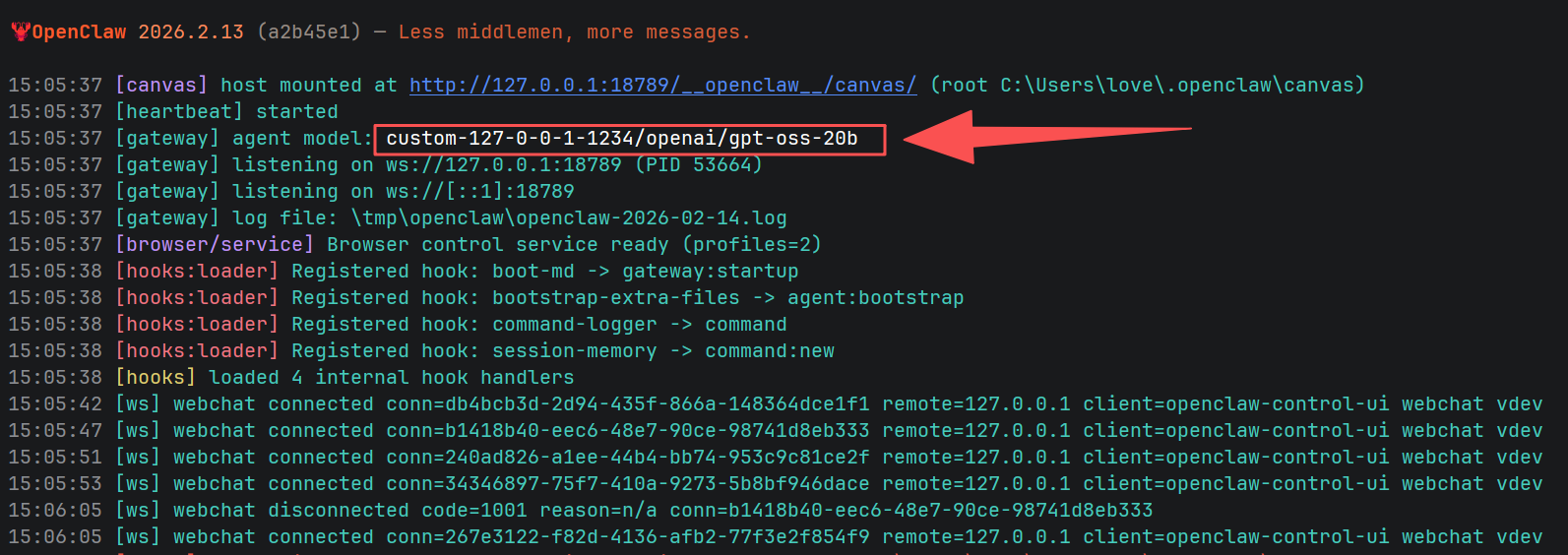
图8:OpenClaw 启动成功,监听在 1234 端口,LM Studio 模型 openai/gpt-oss-20b 已就绪。
(本文截图均为作者实测环境)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献83条内容
已为社区贡献83条内容

所有评论(0)