RAG,基于字号频率的内容切分算法,非常强
核心依赖逻辑:文档解析(pdfplumber/python-docx)→ 数据结构化(pandas)→ 标题识别(sklearn KMeans)→ 章节划分 → 语义切分(sentence-transformers+langchain);关键库不可替代pdfplumber(PDF精准解析)、sklearn(字号频率聚类)、langchain(语义切分)是整个流程的三大核心,缺一不可;新手优先级:先
·
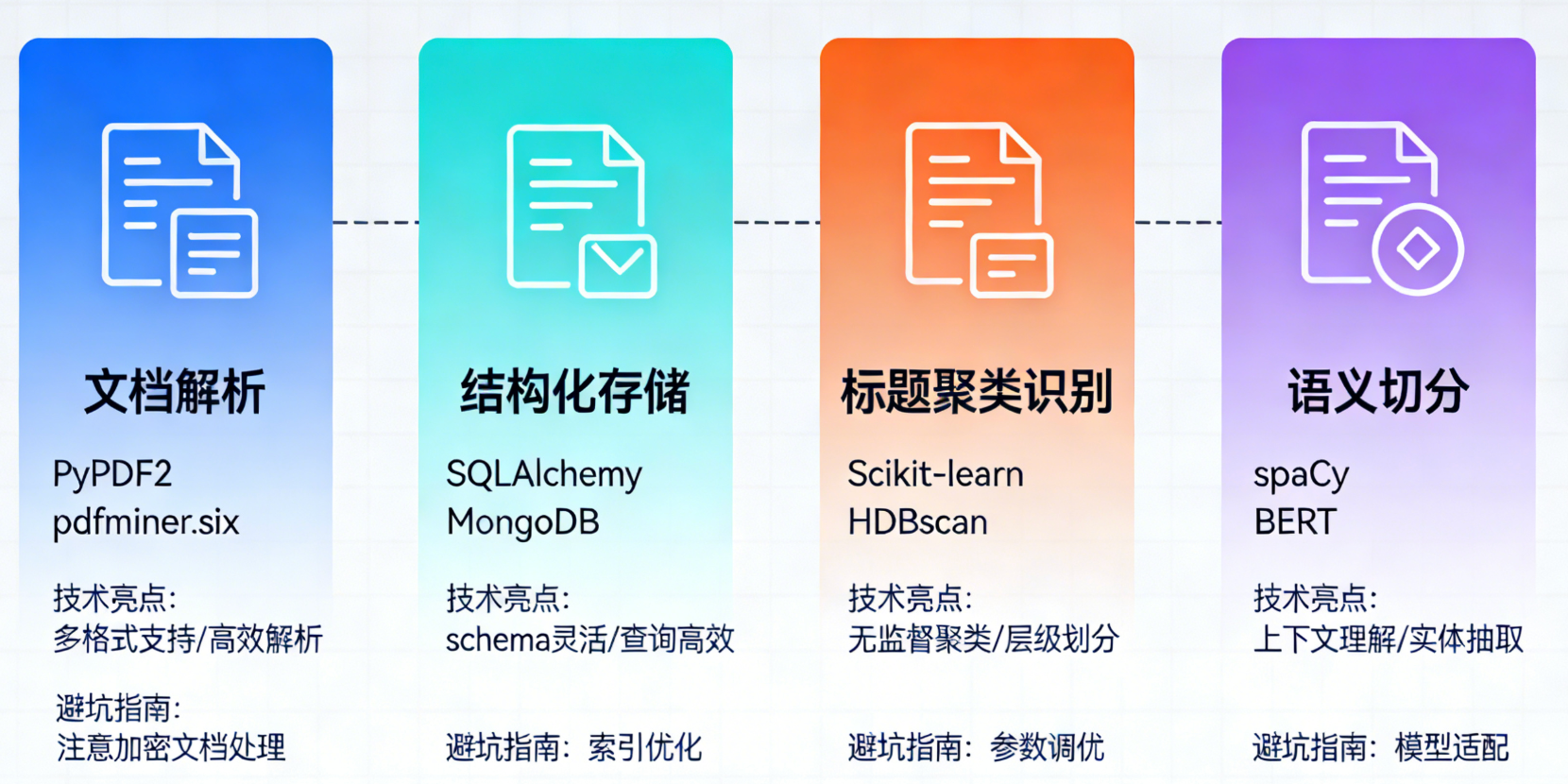
一、依赖库总览(按功能分类)
先列全代码中用到的所有库,方便你整体梳理:
| 功能模块 | 依赖库 | 核心作用 |
|---|---|---|
| 文档解析 | pdfplumber | 精准解析PDF,提取文本块+字号+粗体+位置 |
| python-docx (docx) | 解析Word(.docx),提取段落+字号+粗体 | |
| 基础数据处理 | os | 处理文件路径、识别文件后缀 |
| numpy | 数值计算(如字号均值、数组处理) | |
| pandas | 结构化数据存储、清洗、分析(核心载体) | |
| 聚类/特征处理 | scikit-learn (sklearn) | 字号频率聚类(KMeans)+ 特征归一化 |
| Embedding/语义 | sentence-transformers | 生成文本Embedding,用于语义切分 |
| RAG语义切分 | langchain | 提供SemanticChunker,按语义切分文本 |
二、逐个库详细讲解
1. 文档解析模块
(1)pdfplumber
- 核心作用:PDF解析的“瑞士军刀”,比PyPDF2、PyMuPDF更精准提取PDF的「布局信息」(文本块坐标、字号、字体、粗体),是PDF标题识别的核心依赖。
- 代码中的应用:
对应函数parse_pdf_document,核心功能:pdfplumber.open():打开PDF文件;page.extract_text_blocks():提取带坐标的文本块(x0/y0/x1/y1确定位置);page.chars:遍历每个字符,提取字号(char['size'])和粗体(char['fontname'])。
- 关键用法示例(代码片段):
import pdfplumber with pdfplumber.open("test.pdf") as pdf: page = pdf.pages[0] # 获取第1页(索引从0开始) # 提取文本块(带坐标) blocks = page.extract_text_blocks() # 返回[(x0,y0,x1,y1,text), ...] # 提取字符级字体信息 for char in page.chars: print(f"字符:{char['text']},字号:{char['size']},字体:{char['fontname']}") - 安装方式:
pip install pdfplumber(无兼容问题,Python3.7+均可)。
(2)python-docx(代码中导入为docx)
- 核心作用:专门解析Word文档(.docx格式,不支持.doc),提取段落、字号、粗体等格式信息。
- 代码中的应用:
对应函数parse_word_document,核心功能:Document():打开Word文档;doc.paragraphs:遍历所有段落;para.runs:遍历段落内的“运行块”(Word的格式最小单位),提取字号(run.font.size.pt)和粗体(run.bold)。
- 关键用法示例(代码片段):
from docx import Document doc = Document("test.docx") for para in doc.paragraphs: text = para.text.strip() if not text: continue # 提取段落的字号和粗体 for run in para.runs: font_size = run.font.size.pt if run.font.size else 12 is_bold = run.bold or False print(f"文本:{text},字号:{font_size},粗体:{is_bold}") - 安装方式:
pip install python-docx(注意:库名是python-docx,但代码中导入用import docx)。
2. 基础数据处理模块
(1)os
- 核心作用:Python内置库(无需额外安装),处理文件路径、识别文件后缀,实现“自动区分PDF/Word”。
- 代码中的应用:
对应函数auto_parse_document,核心API:os.path.splitext(file_path):拆分文件路径和后缀(如test.pdf→('test', '.pdf'));file_ext.lower():统一后缀为小写,避免.PDF/.Pdf识别错误。
- 关键用法示例:
import os file_path = "your_document.PDF" file_ext = os.path.splitext(file_path)[-1].lower() # 输出:.pdf if file_ext == '.pdf': print("是PDF文件") elif file_ext == '.docx': print("是Word文件")
(2)numpy
- 核心作用:Python数值计算基础库,处理数组、均值/极值计算,弥补Python原生列表的数值操作短板。
- 代码中的应用:
np.mean(char_fonts):计算文本块内所有字符的字号均值(避免单个字符字号误差);np.round(1):字号保留1位小数,统一格式;range(len(df))→ 结合numpy生成有序索引。
- 关键用法示例:
import numpy as np font_sizes = [12.0, 12.2, 11.8] mean_size = np.mean(font_sizes).round(1) # 输出:12.0 - 安装方式:
pip install numpy(建议安装1.21+版本,兼容性更好)。
(3)pandas
- 核心作用:结构化数据处理的核心载体,所有文本块的特征(顺序、字号、粗体、文本)都存储在DataFrame中,方便聚类、筛选、排序。
- 代码中的应用:
全程依赖,核心功能:pd.DataFrame(text_blocks):将解析后的文本块转为结构化表格;df.sort_values(by=['page', 'position']):按阅读顺序排序文本块;df.groupby('cluster').agg(...):聚类后统计各簇的字号/粗体均值,区分标题/正文;df.loc[...]:按条件筛选标题/正文块。
- 关键用法示例:
import pandas as pd # 构造DataFrame data = [{'order':0, 'font_size':24, 'is_bold':True, 'text':'第一章'}] df = pd.DataFrame(data) # 按字号分组统计 cluster_stats = df.groupby('cluster').agg({'font_size':'mean'}).round(2) - 安装方式:
pip install pandas(建议和numpy版本匹配,避免冲突)。
3. 聚类/特征处理模块
scikit-learn(代码中导入为sklearn)
- 核心作用:提供字号频率聚类的核心算法(KMeans)和特征归一化工具(MinMaxScaler),是“标题识别”的算法核心。
- 代码中的应用:
两个核心组件:
①MinMaxScaler():特征归一化- 作用:字号(12-24)、频率(0-1)、粗体(0-1)量纲不同,归一化到[0,1]避免某特征主导聚类;
- 代码:
scaler.fit_transform(df[['font_size', 'font_freq', 'bold_score']])。
②KMeans(n_clusters=3):聚类算法 - 作用:将文本块按“字号+频率+粗体”聚为3类(一级标题/二级标题/正文);
- 代码:
kmeans.fit_predict(df[['font_size_scaled', 'font_freq_scaled', 'bold_scaled']])。
- 关键用法示例:
from sklearn.cluster import KMeans from sklearn.preprocessing import MinMaxScaler import pandas as pd # 模拟特征数据 data = pd.DataFrame({ 'font_size': [24, 16, 12, 24, 16, 12], 'font_freq': [0.05, 0.1, 0.85, 0.05, 0.1, 0.85], 'bold_score': [1, 1, 0, 1, 1, 0] }) # 归一化 scaler = MinMaxScaler() data_scaled = scaler.fit_transform(data) # KMeans聚类 kmeans = KMeans(n_clusters=3, random_state=42) data['cluster'] = kmeans.fit_predict(data_scaled) print(data) # 输出聚类结果,3类分别对应一级标题/二级标题/正文 - 安装方式:
pip install scikit-learn(建议安装1.0+版本)。
4. Embedding/语义模块
sentence-transformers
- 核心作用:加载预训练的轻量级Embedding模型(如
all-MiniLM-L6-v2),将文本转为向量,用于后续的语义切分。 - 代码中的应用:
对应章节内语义切分环节,核心API:SentenceTransformer('all-MiniLM-L6-v2'):加载模型(自动下载,约80MB,轻量高效);model.encode(text):将文本转为768维向量,是语义相似度计算的基础。
- 关键用法示例:
from sentence_transformers import SentenceTransformer model = SentenceTransformer('all-MiniLM-L6-v2') # 生成文本Embedding text = "第一章 人工智能概述" embedding = model.encode(text) print(f"Embedding维度:{len(embedding)}") # 输出:384(all-MiniLM-L6-v2是384维) - 安装方式:
pip install sentence-transformers(依赖torch,安装时会自动适配,无需手动装torch)。
5. RAG语义切分模块
langchain
- 核心作用:提供
SemanticChunker(语义切分器),替代基础的字符数切分,按文本Embedding的相似度切分,保证语义完整。 - 代码中的应用:
对应章节内语义切分环节,核心API:SemanticChunker(embed_model, breakpoint_threshold_type="percentile"):初始化语义切分器;create_documents([text]):对章节正文做语义切分,返回切分后的文本块。
- 关键用法示例:
from langchain.text_splitter import SemanticChunker from sentence_transformers import SentenceTransformer embed_model = SentenceTransformer('all-MiniLM-L6-v2') # 初始化语义切分器 semantic_splitter = SemanticChunker( embed_model, breakpoint_threshold_type="percentile", breakpoint_threshold_amount=95 ) # 切分文本 text = "人工智能(AI)是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。机器学习是AI的核心,包括监督学习、无监督学习等。" chunks = semantic_splitter.create_documents([text]) for chunk in chunks: print(chunk.page_content) - 安装方式:
pip install langchain(建议安装0.1+版本)。
三、安装注意事项(避坑指南)
- 版本兼容性:
- Python版本:建议3.8-3.11(3.12+部分库可能兼容不佳);
- 核心库版本:
pandas>=1.4、scikit-learn>=1.0、langchain>=0.1。
- PDF解析特殊情况:
- 加密PDF:
pdfplumber无法解析,需先解密; - 扫描件PDF(图片):需搭配OCR工具(如
pytesseract),代码需额外扩展。
- 加密PDF:
- Word解析限制:
- 仅支持
.docx格式,.doc格式需转成.docx后再解析。
- 仅支持
- Embedding模型下载:
- 首次运行
SentenceTransformer会自动下载模型,需保证网络通畅,若下载失败可手动从HuggingFace下载。
- 首次运行
总结
- 核心依赖逻辑:文档解析(pdfplumber/python-docx)→ 数据结构化(pandas)→ 标题识别(sklearn KMeans)→ 章节划分 → 语义切分(sentence-transformers+langchain);
- 关键库不可替代:
pdfplumber(PDF精准解析)、sklearn(字号频率聚类)、langchain(语义切分)是整个流程的三大核心,缺一不可; - 新手优先级:先掌握
pandas(数据处理)和sklearn(聚类),再熟悉文档解析和语义切分,逐步拆解学习。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)