调优不抓瞎!Milvus检索可视化,让RAG调试告别黑盒凭感觉
摘要 RAG(检索增强生成)作为大模型落地的核心方案,解决了知识时效性和事实性问题,但调试过程存在"黑盒"困境。开发者无法直观感知高维向量空间的语义分布,导致调优效率低下。GitHub项目Project_Golem通过3D可视化技术破解这一难题,但原架构仅适用于小规模演示。本文提出基于Milvus 2.6.8的改造方案,解决了实时性、可扩展性和工程化三大痛点,实现了百万级文档的
RAG作为大模型落地的核心方案,完美解决了知识时效性、事实性的痛点,却始终被“调试黑盒”所困扰。开发者调优时只能看到冰冷的相似度分数和召回文档列表,却无从知晓文档在向量空间的实际分布,更搞不懂核心文档漏召、无关文档误召的根本原因。选不对embedding模型?文本切块大小不合理?索引算法参数设置有问题?这些疑问始终没有直观答案,让RAG调优全凭经验“瞎猜”,效率低下还难见成效。
而GitHub上的Project_Golem项目,为破解这一难题提供了全新思路,它将高维向量空间通过可视化技术转化为可感知的3D界面,让RAG的检索轨迹和语义分布一目了然。但原版Project_Golem仅适用于小规模技术演示,面对生产级的海量数据、实时更新需求时力不从心。为此,我们结合Milvus 2.6.8版本的强大能力对其进行改造升级,解决了原架构的技术瓶颈,让这套可视化方案具备了实时性、可扩展性和工程化能力,真正让RAG调优有迹可循、有据可依,从此告别“抓瞎式”调参。
一、RAG调试的黑盒困境,到底难在哪?
想要理解Project_Golem的价值,首先要搞懂RAG调试黑盒的本质问题:向量空间的高维性导致人类无法直观感知。我们将文本转化为768或1536维的向量后,这些向量会在高维空间中自然形成聚类,语义相似的文本向量会紧密聚集,语义无关的则会相互远离。但高维空间无法被人类直接观察,开发者能获取的有效信息仅有两个,一是查询向量与文档向量的余弦相似度分数,二是最终被召回的文档列表,这就直接导致了三大调优难题。
当召回效果差时,开发者根本无法判断问题根源,是embedding模型在文本向量化过程中出现了语义丢失,让原本相关的内容无法被正确表征,还是检索策略出了问题,比如索引算法选择不当、参数设置不合理,导致检索效率和准确性大打折扣。这种根源的模糊性,让调优变成了“无头苍蝇乱撞”,只能不断更换模型、调整参数反复测试,耗费大量时间却收效甚微。
当出现文档漏召时,目标文档的向量在高维空间中处于什么位置始终是个谜,开发者不知道它是否与查询向量属于同一聚类,也不清楚是聚类本身出现了偏差,还是检索范围设置过窄,让本该被召回的文档被排除在外。更无从判断,是否是文本切块时将完整的语义信息拆分,导致单个切块的向量无法准确代表原文档的核心含义,最终被检索系统忽略。
当发生无关文档误召时,同样无法解释背后的原因,为什么语义无关的文档向量会与查询向量产生较高的相似度。是文本拆分时混入了无关信息,让切块向量出现了“语义偏差”,还是向量空间的分布本身存在问题,不同语义的聚类出现了重叠,让检索系统无法准确区分。看不到高维空间的实际情况,就无法找到问题的核心,调优也就只能停留在表面。
简单来说,因为看不到高维向量空间的分布过程和检索轨迹,开发者始终处于“只知结果,不知原因”的状态,无法针对性地解决问题,这也是RAG调优效率低下的核心症结。而Project_Golem的出现,正是为了打破这个黑盒,它的核心逻辑其实并不复杂,通过UMAP算法将768或1536维的高维向量降维至3维,再利用Three.js完成3D空间渲染,让所有文档向量都以节点的形式呈现在3D界面中。
在这个3D界面里,语义相似的节点会自然聚集形成簇,不同类别的文档还能通过不同颜色进行区分,高维空间的语义分布变得直观可见。在线检索阶段,当用户发起查询时,系统会先在高维空间计算余弦相似度完成检索,再根据返回的文档索引,在3D界面中“点亮”对应的节点,检索结果的空间位置、与查询向量的关联程度都能一目了然。开发者终于能看到RAG检索的“全过程”,而不只是最终的结果。
但必须承认的是,原版的Project_Golem设计更偏向技术验证和小规模演示,其架构存在明显的局限性,当文档量达到10万、100万级的生产级规模时,各种问题会集中暴露,主要体现在静态数据、内存性能、工程能力三个方面,根本无法满足实际业务需求。
在数据处理上,原版架构属于典型的静态数据模式,无法支持在线业务的增量更新需求。新增文档后,开发者需要重新生成完整的npy向量文件,并重跑全量UMAP降维,再更新JSON坐标文件,整个过程繁琐且耗时。仅仅是10万条文档的UMAP单核计算,就需要5-10分钟,若是百万级文档,耗时会呈指数级增长。这就意味着,这套方案只能对接固定的静态文档,无法应用在资讯更新、产品手册迭代、用户对话记录等需要实时更新数据的业务场景中,实用性大打折扣。
在性能表现上,原版架构存在严重的内存与性能瓶颈,暴力搜索的方式效率极低。以768维float32向量为例,10万条向量会占用305MB内存,100万条直接达到3GB,对服务器内存资源形成巨大消耗。而原版架构采用NumPy暴力搜索的方式进行检索,时间复杂度为O(n),随着数据量的增加,检索延迟会急剧上升,单次查询在百万条数据下的延迟会超过1秒,远达不到在线服务毫秒级响应的核心要求,根本无法支撑高并发的业务场景。
在工程能力上,原版架构的设计过于简单,与实际生产需求脱节。它没有集成HNSW、IVF等主流的ANN近邻索引算法,检索效率和准确性难以保证,也不支持标量过滤、多租户隔离、混合检索等生产环境必需的特性。在实际业务中,开发者往往需要按照文档类别、发布时间、权限等级等标量条件过滤检索结果,而原版架构只能做纯向量检索,无法实现这些个性化、精细化的检索需求,难以落地到实际的生产系统中。
二、Milvus+Project_Golem,破解原架构三大痛点
原版Project_Golem的根本问题,在于数据流的断裂和底层支撑的缺失,新增文档→重生成npy→重跑UMAP→更新JSON,整个链路串行且耗时,没有实现检索与可视化的解耦,也缺乏生产级的向量数据库做底层支撑。而Milvus作为国内主流的云原生向量数据库,尤其是2.6.8版本引入的Streaming Node特性,恰好精准解决了原版架构的三大痛点,同时为可视化方案提供了工程化、规模化的底层能力,让RAG检索可视化真正具备了落地生产的可能。
针对原版架构无法支持实时更新的痛点,Milvus 2.6.8的Streaming Node特性带来了颠覆性的解决方案。它无需依赖Kafka、Pulsar等外部消息队列,就能实现实时数据注入、增量索引更新,新增文档后,写入即可查询,检索索引会自动实时更新,彻底摆脱了全量重跑的困境。这一特性完美适配了在线业务的增量更新需求,无论是资讯的实时发布、产品手册的迭代更新,还是用户对话记录的持续积累,都能被快速纳入检索系统,且不会对现有系统的运行造成任何影响,让可视化方案真正能对接动态的业务数据。
同时,Milvus实现了可视化层与检索层的完全解耦,让两个模块能够各司其职、独立迭代。在改造后的架构中,检索层由Milvus全权负责,包括高维向量的实时检索、索引优化、数据管理等核心工作,依托Milvus成熟的索引算法和高性能的检索能力,实现毫秒级的实时响应;可视化层则仅需根据Milvus返回的文档索引,在3D界面中完成节点点亮、轨迹绘制等可视化工作,无需参与复杂的检索计算。两层互不干扰,各自可以根据业务需求进行优化迭代,既提升了系统的整体稳定性,也让后续的功能扩展变得更加便捷。
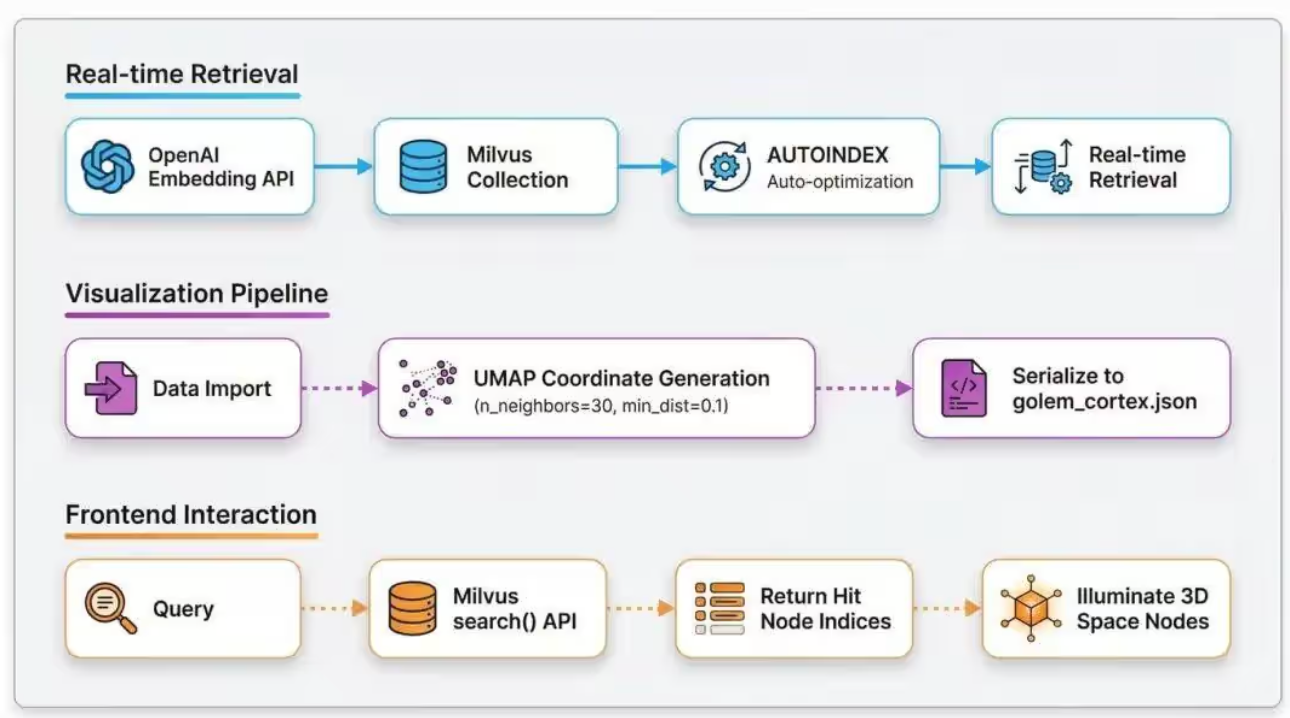
改造后的方案,依然保留了原版Project_Golem的双路核心逻辑,同时将检索层全面替换为Milvus,让整个方案具备了生产级的能力,两条路径的设计各有侧重、相互配合,共同实现RAG检索的可视化与高效化。
检索路径的核心目标是实现毫秒级实时响应,完全依托Milvus的高性能能力搭建。当用户发起查询时,首先通过OpenAI embedding生成查询向量,随后将查询向量写入Milvus Collection,Milvus的AUTOINDEX特性会自动根据数据特征优化索引,选择最适合的索引算法和参数,最后通过实时余弦相似度检索,快速返回相关的文档索引,整个过程在毫秒级完成,完全满足在线服务的响应要求。相较于原版的暴力搜索,Milvus的检索路径在效率和准确性上都实现了质的飞跃。
可视化路径目前主要适配小规模演示场景,在保留原版核心逻辑的基础上进行了优化。数据导入时,通过UMAP算法生成3D坐标,设置n_neighbors=30、min_dist=0.1的参数,让语义聚类更加合理,随后将3D坐标固化到golem_cortex.json文件中,当检索路径返回文档索引后,前端根据索引在3D界面中点亮对应的节点,同时根据相似度分数调整节点亮度,让检索结果的直观性进一步提升。
当然,当前的混合架构主要适配1万条以内的演示场景,而要让这套方案真正落地生产,支持百万级文档的动态更新,还需要实现增量可视化,我们通过三个关键步骤,就能解决这一问题,让方案的规模化扩展成为可能。
第一步是设置合理的触发机制,避免频繁的计算消耗。系统会监听Milvus Collection的插入事件,当累计新增文档超过1000条时,才会触发UMAP增量更新,这样既保证了可视化数据的及时性,又不会因为单次新增少量文档而反复计算,有效节省了计算资源。
第二步是采用增量降维的方式,大幅降低计算耗时。不再重跑全量UMAP fit,而是使用UMAP的transform()方法,将新生成的向量直接映射到已有的3D空间中,保持原有空间的语义分布不变,仅添加新的节点,这一方式能将百万级文档的更新耗时从数小时缩短至数分钟,效率提升数十倍。
第三步是实现前端的实时同步,提升用户体验。通过WebSocket技术,将更新后的JSON坐标片段向前端进行推送,前端接收到数据后,动态添加新的节点,无需刷新整个3D界面,既保证了可视化的实时性,又让用户的操作体验更加流畅。
此外,Milvus 2.6.8的混合检索能力,也就是向量+全文+标量过滤的组合检索方式,还为可视化方案预留了丰富的扩展空间。后续我们可以在3D界面中叠加关键词高亮、类别过滤、时间筛选等交互功能,比如开发者可以通过筛选功能,只查看某一类别、某一时间段的文档节点,也可以通过关键词高亮,快速定位包含特定关键词的节点,让RAG调试的维度更加丰富,开发者能更加精准地找到问题所在。
三、实战落地!Milvus+Project_Golem完整部署教程
改造后的Project_Golem已开源至GitHub,项目仓库地址为https://github.com/yinmin2020/Project_Golem_Milvus,整个方案基于Docker+Python搭建,零基础也能快速上手。我们以Milvus官方文档为数据集,一步步实现RAG检索的3D可视化,让大家能直观感受这套方案的实际效果,整个部署过程分为准备条件、部署Milvus、核心代码实现、下载数据集、启动项目、可视化交互六大步骤,操作简单且可复制。
(一)准备条件
在开始部署前,需要确保本地环境满足以下要求:Docker版本不低于20.10,Docker Compose版本不低于2.0;Python版本不低于3.11,保证代码的正常运行;拥有有效的OpenAI API Key,用于生成文本向量;准备好数据集,本次实战使用Milvus官方文档的markdown文件,也可以替换为自己的业务文档。
(二)部署Milvus
首先下载Milvus 2.6.8的docker-compose.yml文件,在终端中执行命令:wget https://github.com/milvus-io/milvus/releases/download/v2.6.8/milvus-standalone-docker-compose.yml -O docker-compose.yml,将文件下载到本地指定目录。
随后启动Milvus服务,执行命令:docker-compose up -d,启动过程中请检查端口映射为19530:19530,这是Milvus的默认通信端口,确保端口未被占用。
服务启动后,验证是否成功运行,执行命令:docker ps | grep milvus,若成功启动,终端会显示3个运行中的容器,分别是milvus-standalone、milvus-etcd、milvus-minio,缺少任何一个都表示启动失败,需要检查环境配置和命令执行情况。
(三)核心代码实现
改造后的核心代码主要分为两部分,分别是适配Milvus的ingest.py和负责前端可视化的GolemServer.py,两者相互配合,完成数据处理、向量存储、检索服务和可视化展示的全流程。
ingest.py的核心作用是加载本地markdown文档、进行文本切块、生成向量、降维得到3D坐标、将数据存储到Milvus并生成可视化所需的JSON文件。它支持最多8个文档类别,超出部分会循环使用颜色,方便在3D界面中区分不同类别的文档。代码中可配置Milvus连接地址、集合名称、数据文件夹、OpenAI嵌入模型等参数,适配不同的业务需求。
具体执行流程为:首先加载指定文件夹下的所有markdown文件,将文件夹的相对路径作为文档类别;随后使用RecursiveCharacterTextSplitter进行文本切块,设置chunk_size=800、chunk_overlap=50,在保证语义完整的同时,避免切块过大或过小;接着通过OpenAI的text-embedding-3-small模型生成1536维的向量,采用批量生成的方式提升效率;然后通过UMAP算法将高维向量降维至3维,得到每个切块的3D坐标;再通过KNN算法找到每个节点的邻近节点,构建节点间的关联;最后将3D坐标等可视化数据保存到golem_cortex.json,将向量、文本、类别等数据插入Milvus,并创建AUTOINDEX索引,提升检索效率。
GolemServer.py基于Flask搭建,是连接Milvus和前端可视化界面的桥梁,主要负责提供前端页面访问、接收查询请求、调用OpenAI生成查询向量、通过Milvus进行检索、返回检索结果等功能。
代码中会先检查可视化所需的JSON文件和前端页面文件是否存在,验证OpenAI API Key是否有效,检查Milvus中的集合是否存在,确保系统运行的前置条件全部满足;随后设置路由,根路由提供前端index.html页面的访问,/query路由接收前端的POST查询请求;当接收到查询请求后,调用OpenAI生成查询向量,通过Milvus进行余弦相似度检索,返回前50个相关结果的索引和相似度分数,供前端进行可视化展示。
(四)下载数据集存放指定目录
本次实战使用Milvus官方文档作为数据集,下载地址为https://github.com/milvus-io/milvus-docs/tree/v2.6.x/site/en,将下载后的markdown文件全部存放至项目根目录的data文件夹中,若没有data文件夹,可执行mkdir -p data命令创建。如果使用自己的业务文档,只需将markdown格式的文档放入data文件夹即可,支持扁平结构和嵌套结构,嵌套结构的文档会以子文件夹名称作为类别。
(五)启动项目
项目启动分为两步,首先执行文本向量化并映射到3D空间,在项目根目录终端中执行命令:python ingest.py,该命令会执行上述ingest.py的所有流程,完成数据处理、向量存储和可视化文件生成,执行成功后,终端会提示“CORTEX GENERATED SUCCESSFULLY”,并显示存储到Milvus的节点数量和JSON文件的保存路径。
随后启动前端服务,执行命令:python GolemServer.py,执行成功后,终端会提示“SYSTEM ONLINE: http://localhost:8000”,表示服务已成功启动,此时在浏览器中访问该地址,即可进入3D可视化界面。
(六)可视化交互演示
改造后的可视化界面具备丰富的交互功能,支持鼠标左键拖动旋转摄像机、右键拖动平移视角、滚轮缩放,在搜索框中输入查询内容并按下回车,即可发起检索。前端接收检索结果后,会根据相似度分数映射节点亮度,相似度越高,节点亮度越亮,同时保持节点原颜色不变,以维持类别簇的视觉连续性;还会绘制从查询点到命中节点的半透明连线,摄像机也会平滑聚焦到激活簇所在区域,让开发者能快速定位检索结果的空间位置。
我们通过两个实际案例,直观感受可视化界面的调试效果。案例一为领域内匹配,在搜索框中查询:“Milvus支持哪些索引类型?”,可视化界面会出现明显的反馈,3D空间中标记为“INDEXES”类别的红色簇中,约15个节点亮度显著增强,达到原有亮度的2-3倍,这些命中节点正是index_types.md、hnsw_index.md、ivf_index.md等文档的文本切块,前端会绘制从查询向量位置到这些节点的半透明连线,镜头也会平滑聚焦到红色簇区域,开发者能清晰看到,检索系统准确命中了与索引类型相关的文档,且这些文档在向量空间中形成了紧密的聚类,说明embedding模型的向量化效果良好,检索策略设置合理。
案例二为领域外查询的拒绝表现,在搜索框中查询:“KFC优惠套餐多少钱?”,这一问题与Milvus无关,属于领域外查询,此时可视化界面的反馈也十分明显,空间中所有节点保持原色,仅有微弱的尺寸波动,波动幅度小于1.1倍,没有节点出现明显的亮度增强;命中节点分散在多个不同颜色的簇中,无明显的聚集模式,说明这些命中只是偶然的低相似度匹配;摄像机也未触发聚焦行为,因为相似度分数未达到阈值0.5。开发者能通过这些可视化反馈明确判断,该查询为领域外内容,检索系统的“拒绝”表现合理,无需进行调优。
四、可视化调优,让RAG开发告别凭感觉
Project_Golem结合Milvus的改造升级,本质上是一个实验性但极具参考意义的项目,它的核心价值并非只是简单实现了RAG检索的3D可视化,更是为行业解决RAG可解释性问题提供了全新的技术思路,让RAG调优从“凭经验、看结果、瞎调参”的黑盒操作,变成了“看过程、找根源、精准调”的可视化操作,这是RAG开发领域的一次重要探索。
在这套可视化方案出现之前,RAG调优始终处于一种“盲人摸象”的状态,开发者只能根据最终的召回结果不断试错,调优过程缺乏科学的依据和明确的方向。比如发现漏召问题后,只能不断更换embedding模型、调整文本切块大小、修改索引参数,逐一测试排查,不仅耗费大量的时间和精力,还很难找到问题的根本原因,往往是解决了一个问题,又出现了新的问题。
而在这套Milvus+Project_Golem的可视化方案之后,开发者能通过3D可视化界面,完成三个核心调优动作,让调优过程有迹可循、精准高效。首先是观察语义空间结构,判断embedding模型的向量化效果。开发者能直观看到不同文档在3D空间中的聚类情况,如果语义相似的文档形成了紧密、合理的聚类,说明embedding模型的向量化效果良好;如果语义相似的文档分散在不同的簇中,或者语义无关的文档聚集在一起,说明embedding模型选择不当,需要更换模型或调整模型参数,让向量化结果更贴合业务需求。
其次是定位检索策略问题,精准分析漏召、误召的原因。针对漏召问题,开发者能在3D空间中找到目标文档的节点,查看它是否与查询向量的聚类相邻,若目标节点与查询聚类距离较远,说明需要调整检索范围或索引参数;若目标节点处于查询聚类中却未被召回,说明文本切块可能存在问题,需要调整切块大小或重叠度,让切块能准确代表原文档的语义。针对误召问题,开发者能查看误召节点的空间位置,若误召节点与查询聚类存在重叠,说明需要优化向量空间分布,更换更合适的embedding模型;若误召节点与查询聚类距离较远却被召回,说明索引算法或参数设置不合理,需要调整索引策略,提升检索的准确性。
最后是验证调优效果,让调优成果可量化、可可视化。在对embedding模型、文本切块、检索策略进行调优后,开发者能在3D可视化界面中直观看到向量空间的变化,比如原本分散的语义聚类变得紧密,原本重叠的聚类变得清晰;也能看到检索轨迹的优化,比如漏召的节点能被成功点亮,误召的节点大幅减少。这些可视化的变化,让调优效果不再是抽象的“感觉变好”,而是具体、可量化的“实际优化”,开发者能明确判断调优措施是否有效,是否需要进一步调整,让调优过程形成闭环。
当然,这套Milvus+Project_Golem的可视化方案目前仍处于不断迭代优化的阶段,未来还有很大的扩展空间。比如结合Milvus的混合检索能力,在3D界面中增加标量过滤、全文检索的交互功能,让开发者能更加精细化地调试;比如引入实时的性能监控数据,将检索延迟、召回率、准确率等指标与可视化界面结合,让调优不仅能看语义分布,还能看性能表现;比如支持多模型对比,在同一个3D空间中展示不同embedding模型的向量化结果,让开发者能直观对比不同模型的效果,快速选择最适合的模型。
RAG作为大模型落地的核心技术,其可解释性和调优效率的提升,对于大模型在各行业的规模化落地至关重要。而Milvus+Project_Golem的可视化方案,为解决RAG调试黑盒问题提供了切实可行的技术路径,它将高维的向量空间转化为可感知、可交互的3D界面,让RAG调优从“凭感觉”变成“看数据、看过程”。
相信随着向量数据库的不断发展,Milvus等产品会持续推出更多高性能、高扩展性的特性,也随着可解释性技术的持续迭代,RAG可视化调试方案会不断完善,功能会更加丰富,性能会更加稳定。未来,RAG调试的黑盒问题会被彻底解决,开发者能更加高效、精准地进行RAG开发和调优,让大模型在金融、电商、医疗、教育等各个行业的落地更加高效、更加稳定,释放出更大的技术价值和商业价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)