RoboBrain 2.5:视野中的深度,思维中的时间
26年1月来自北京智源的论文“RoboBrain 2.5: Depth in Sight, Time in Mind”。RoboBrain 2.5,是一款具身人工智能基础模型,它通过在高质量时空监督数据上进行大量训练,显著提升通用感知、空间推理和时间建模能力。RoboBrain 2.5 在其前代产品的基础上进行两项功能升级。具体而言,它实现了精确的 3D 空间推理,从基于 2D 像素的相对定位转向
26年1月来自北京智源的论文“RoboBrain 2.5: Depth in Sight, Time in Mind”。
RoboBrain 2.5,是一款具身人工智能基础模型,它通过在高质量时空监督数据上进行大量训练,显著提升通用感知、空间推理和时间建模能力。RoboBrain 2.5 在其前代产品的基础上进行两项功能升级。具体而言,它实现了精确的 3D 空间推理,从基于 2D 像素的相对定位转向基于深度感知的坐标预测和绝对度量约束理解,从而在物理约束下生成完整的 3D 操作轨迹,并将其表示为有序的关键点序列。为了进一步提升空间精度,该模型还建立密集时间值估计功能,能够跨不同视角提供密集的、步-觉察的进度预测和执行状态理解,并为下游学习生成稳定的反馈信号。这些升级共同推动该框架向更具物理基础和执行感知能力的具身智能发展,从而能够处理复杂、精细的操作。
如图所示RoboBrain 2.5的新特征:上图:基于深度感知定位、度量测量和物理约束下的完整操作轨迹生成,实现精确的 3D 空间推理。下图:基于跨视角和任务的状态转换,进行步长感知进度/退步预测的密集时间值估计;雷达图总结在 2D/3D 空间和时间基准测试中的性能提升。
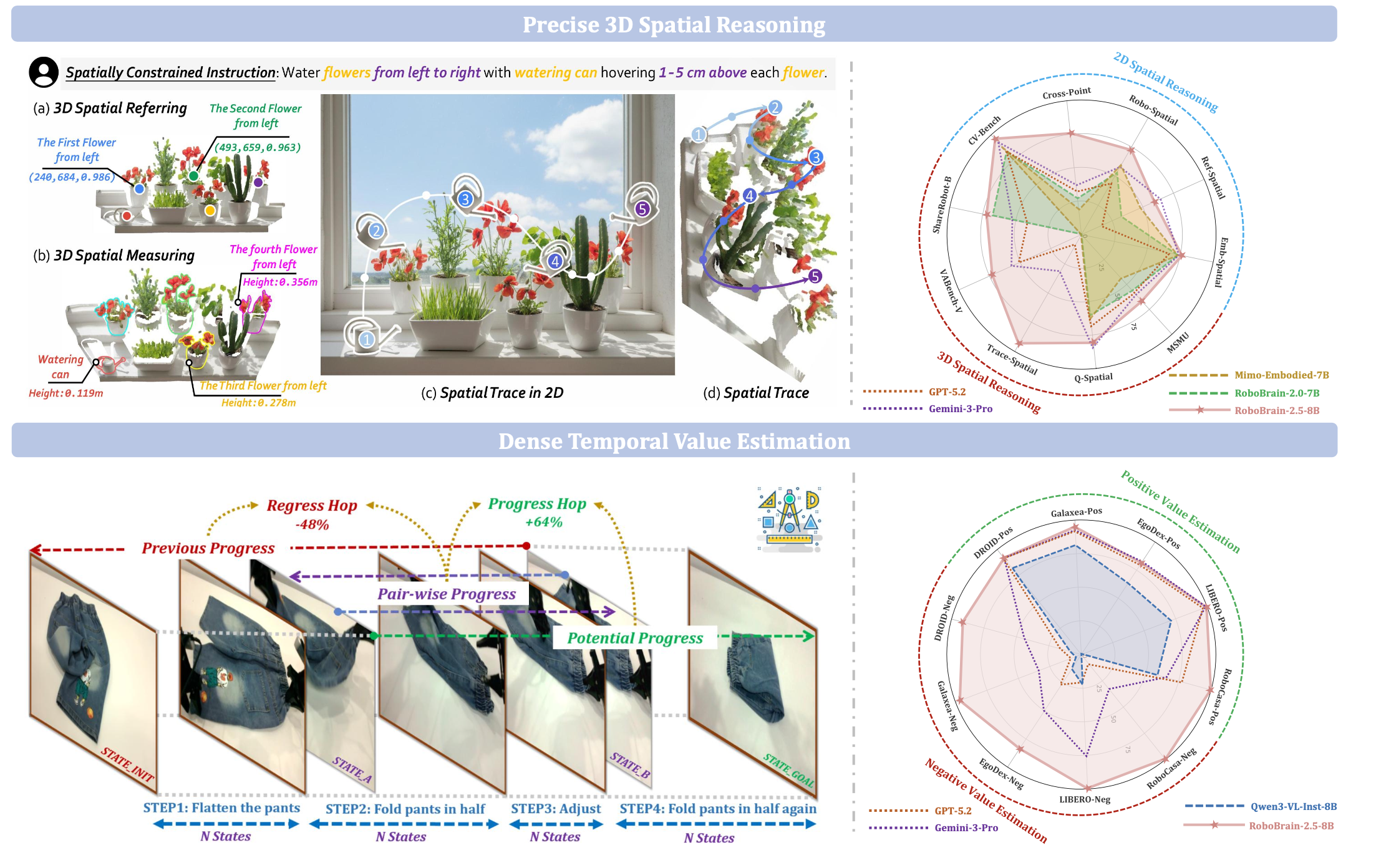
精确三维空间推理
为了使具身智体能够有效地与物理世界交互,它们必须准确地解读空间信息并做出相应的反应。这需要对物体位置、物体间关系以及视觉观察中获得的精确度量数据有深刻的理解。为了满足这些基本需求,引入一个精确三维空间推理框架。
三维空间参照、测量与追踪
具身机器人通常需要根据日益复杂且空间受限的指令执行动作[1, 10, 11, 34, 68, 70, 71, 85],例如上图所示的“用喷壶从左到右给花朵浇水,每朵花上方1-5厘米处悬停”。然而,目前数据匮乏的视觉-语言-动作(VLA)模型难以胜任此类任务。在这种情况下,生成一个三维位置序列(称为三维空间轨迹)将大有裨益,它可以作为直观的桥梁,帮助机器人理解三维空间中的指令执行过程,并指导其生成实际的动作轨迹。然而,这项替代任务(即三维空间追踪)本身就极具挑战性,因为它需要在复杂的三维场景中进行多步骤、基于度量的推理。具体而言,每个推理步骤都需要两个关键组成部分:(1) 三维空间参照,用于解析空间关系并精确定位轨迹生成过程中涉及的物体(例如,识别花朵及其从左到右的顺序并定位它们)。(2) 三维空间测量,用于理解与所捕获场景中的轨迹相关的绝对真实世界度量量(例如,量化每朵花的实际高度以及其上方 1-5 厘米的高度)。为此,为 RoboBrain 2.5 配备这三项关键功能,使其能够在空间约束下直接从单目图像预测基于度量的输出,从而与三维物理世界进行直接交互。
密集时间值估计
有效执行长时域操作任务需要的不仅仅是最终的成功信号;它还需要连续、细粒度的反馈来引导智体经历复杂的中间状态[3, 15, 52, 54, 80]。为了克服稀疏反馈的局限性,引入密集时间值估计(Dense Temporal Value Estimation),这是一种基于视觉的机制,它提供实时、步-觉察的进度评估作为时间值反馈,从而实现鲁棒的闭环控制和高效的强化学习。
逐跳(Hop)进度构建
方法的核心是将值估计表述为任务进度;因此,模型作为一个视觉语言估计器,旨在从视觉输入中推断细粒度的实时进度。为了保证在不同实现方式和任务族中的泛化能力,实现一个三阶段的数据整理流程,以处理不同的数据来源。
多视角进度融合
为了减轻误差累积并确保一致的准确性,融合来自三个互补视角的密集时间值估计:增量预测、前向锚定预测和后向锚定预测。
双向一致性检查
虽然通过平均进行多视角融合可以作为基线方法,但将其直接应用于在线强化学习 (RL) 会面临分布外 (OOD) 幻觉的风险。由于数据覆盖范围的固有局限性,训练集不可能涵盖状态空间的每个角落。在强化学习过程中,策略不可避免地会探索未见过的区域,而密集的时间值估计可能会产生虚假的高信号,导致“奖励作弊”。为了解决这些问题,提出一种双向一致性检查策略,该策略利用一致性作为可靠性的代理(proxy)。这种设计的动机源于以下观察:在分布外观测下,前向预测 Φ∗_F 和后向预测 Φ∗_B 往往会显著发散,而在熟悉的状态下,它们则保持一致。
如图所示,RoboBrain 2.5 基于一个多样化且庞大的数据集进行训练,旨在增强其在具身环境下的空间理解、时间建模和因果推理能力。具体而言,构建一个包含约 1240 万个高质量样本的统一语料库,并将其分为三个核心领域:(1)用于鲁棒语义感知的通用 MLLM 数据;(2)涵盖从二维感知到度量感知三维追踪的空间推理数据;以及(3)用于分层规划和密集值估计的时间预测数据。这种混合模式巧妙地平衡大规模网络知识和细粒度的物理世界交互,从而弥合高层推理和底层控制之间的鸿沟。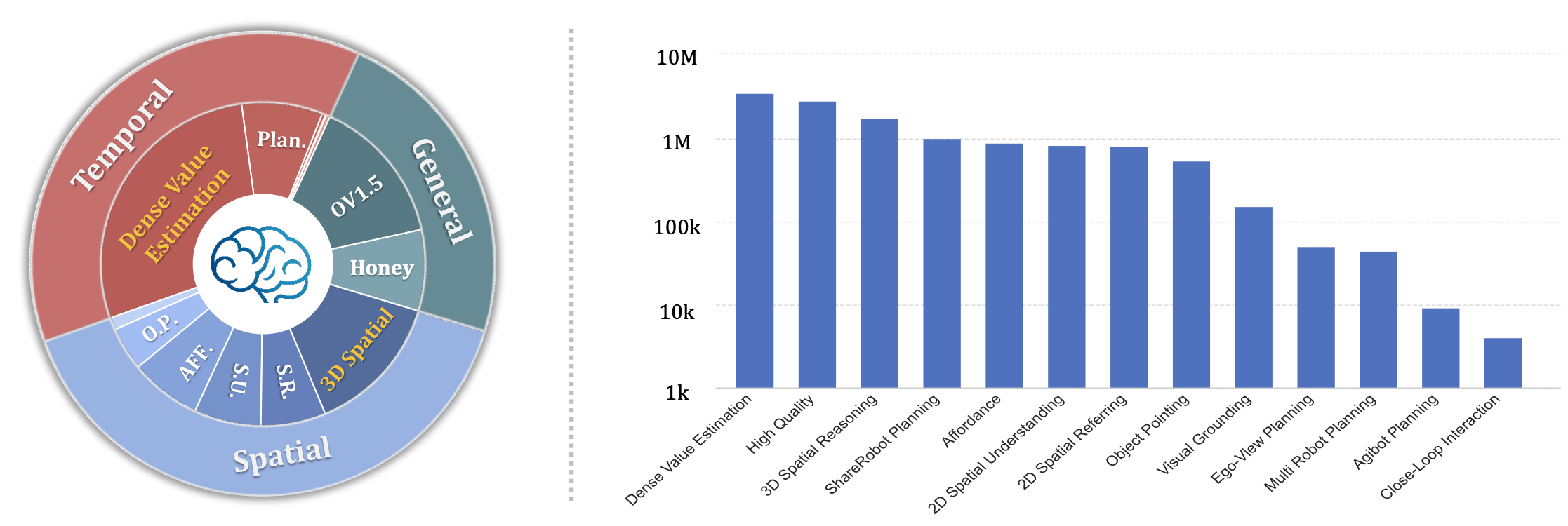
通用多模态语言模型 (MLLM) 数据
高质量通用数据。为了构建稳健的通用视觉感知和推理基础,RoboBrain 2.5 的通用训练数据集包含约 283 万个高质量样本。这些样本主要来源于两个最先进的开源数据集:Honey-Data-1M [82] 和 LLaVA-Onevision-1.5-Instruct-Data [5],并经过蒸馏。(1) Honey-Data-1M 数据处理。用 Honey-Data-1M [82] 作为关键数据源,它提供一系列旨在增强多模态理解的多样化视觉语言指令。为了使响应风格符合具身智体对简洁直接执行命令的要求,截断其中大量的思维链 (CoT) 推理组件,仅保留最终答案,以简化直接指令执行的监督信号。(2) LLaVA-Onevision 数据蒸馏。进一步整合 LLaVA-Onevision-1.5-Instruct-Data [5],这是一个涵盖多种视觉任务(包括 OCR、数学和通用 VQA)的综合数据集。为了专注于视觉能力,首先过滤掉所有纯文本样本。为了解决数据不平衡问题,对每个基于视觉的子类应用平衡采样。此外,为了优化训练效率和上下文窗口利用率,采用一种样本打包策略,将较短的训练样本连接起来。这使得序列长度分布更加均匀,主要集中在 2048 到 8192 个标记的范围内。(3) 去重和合并。鉴于这两个存储库的数据源存在重叠,进行严格的去重处理,以防止冗余和数据泄露。基于图像相似性和问答文本相似性对合并后的数据集进行筛选。最终整理的数据集包含 283 万个独特的、高质量的多模态指令跟随样本。
空间推理数据
视觉落地。视觉定位数据集旨在通过精确的对象级定位来增强多模态理解,并利用 LVIS [27] 的大量标注。精心挑选来自 LVIS 的 15.2 万张高分辨率图像,确保涵盖各种对象类别和复杂的视觉场景。每个对象标注都被转换为标准化的边框坐标 (x1, y1, x2, y2),分别代表左上角和右下角,从而实现一致的空间参考。为了促进丰富的视觉对话,生成 8.6 万个对话序列,每个序列包含多轮问答对,逐步探索视觉关系、属性推理和上下文理解。该数据集在对象类别之间保持均衡分布,同时保留了遮挡、视角变化和罕见实例等具有挑战性的情况,以支持稳健的视觉定位。
对象指向。对象指向数据集旨在使 RoboBrain 2.5 能够通过在图像中指向来识别指定对象的位置。利用 Pixmo-Points [22] 数据集作为数据源,该数据集包含 22.3 万张图像上的 230 万个点标注。然而,由于物体实例重复密集(例如,书架上的书),直接使用 Pixmo-Points 数据进行 RoboBrain 2.5 训练面临挑战。为了解决这个问题,实施一个两步过滤过程:(1)为了简化训练,舍弃标注点超过十个的标注;(2)用 GPT-4o [31] 作为场景分析器,仅选择室内相关的物体,例如厨具、家具和装饰品,排除无关的或室外场景。该过程为 6.4 万张图像生成了 19 万个问答对,减少了杂乱度,使数据更适合具身认知环境。为了构建用于指向任务的问答对,构建 28 个人工设计的模板,例如“指出图像中所有 {label} 的实例”。或者“请帮我在图像中找到{label},并指出它们的位置。”这里,{label}指的是标注中的物体类别。模板是随机选择的,以确保语言多样性并提高模型在指认任务中的泛化能力。对于物体指认任务,采用来自RoboPoint [78] 的物体指认数据集,该数据集包含28.8万张图像上的34.7万个问答标注。为了解决过多的点可能阻碍训练收敛的问题,每个问题随机抽取最多10个点。此外,所有坐标都被转换为归一化值,以更好地支持RoboBrain 2.5的训练。
Affordance。affordance数据集侧重于理解物体的功能和用于放置的空间空余区域。对于物体affordance识别,使用来自PACO-LVIS [63] 的部件级标注,该数据集涵盖4.6万张图像上的75个物体类别和200个部件类别。提取整个物体及其功能部件的边框和分割掩码。这些标注被转换为边框坐标 (x1, y1, x2, y2),作为affordance预测任务的真实标签。用 GPT-4o [31] 构建问题,以查询物体的功能和部件用途,例如,“手提包的哪个部分可以用来抓握?”(针对手提包的提手)。对于整体物体affordance,问题避免直接提及物体名称,例如,“哪个设备可以用来移动以控制屏幕上的光标?”(针对鼠标,一种计算机设备)。这一自动化过程生成了 56.1 万个问答对。对于空间affordance学习,引入来自 RoboPoint [78] 的区域参考数据集。该数据集包含 27 万张图像、32 万个问答对和 14 个空间关系标签。每个标注都被转换为一组归一化坐标 [(x1, y1), (x2, y2), …],并且真实标签点被重采样到每个答案最多 10 个点以进行优化。该数据集使 RoboBrain 2.5 能够推理真实世界环境中物体放置的空间affordance。
空间理解。为了增强 RoboBrain 2.5 的空间推理能力,提出包含 82.6 万个样本的空间理解数据集。该数据集强调以物体为中心的空间属性(例如,位置、方向)和物体间关系(例如,距离、方向),涵盖定性和定量两方面。它涵盖了 31 个不同的空间概念,远超以往数据集通常包含的约 15 个概念。部分采用 RefSpatial [85] 流程,通过自动化的基于模板和 LLM 的生成方式构建 2D 网络图像和 3D 视频数据集:(1)2D 网络图像旨在提供涵盖各种室内外场景的核心空间概念和深度感知。为了弥合这些领域之间的尺度和类别差异,使用大规模的 OpenImage [38] 数据集。由于直接从二维图像进行三维推理具有挑战性,将其转换为伪三维场景图。具体来说,在将 170 万张图像过滤到 46.6 万张后,首先使用 RAM [83] 进行物体类别预测,并使用 GroundingDINO [49] 进行二维边框检测。然后,用 Qwen2.5-VL [62] 和一种启发式方法,根据二维边框生成从粗略(例如,“杯子”)到精细(例如,“从左边数第三个杯子”)的分层描述。这使得在杂乱环境中也能进行明确的空间指称,并能同时捕捉粗略和精细的空间信息。接下来,用 UniDepth V2 [60] 和 WildeCamera [87] 获取深度信息和相机内参,从而实现三维点云重建。最后,结合 GroundingDINO [49] 中的对象框和 SAM 2.1 [64] 中的掩码,每个场景图都包含对象标签、二维框、实例掩码和对象级点云,从而生成轴对齐的三维框。对象描述作为节点,空间关系构成边。问答对通过模板和 LLM(例如 QwQ [74])生成,其中包括从分层描述中提取的对象位置问题。(2) 扫描数据集整合来自五个原始数据集的多模态三维场景理解数据:MMScan [50]、3RScan [76]、ScanQA [6]、SQA3D [51] 和 SpaceR [58]。通过严格的数据处理进行基于模板的问题过滤,以确保任务相关性,执行多阶段质量筛选(例如一致性检查、异常值去除),并将所有格式标准化为统一的表示形式。这种数据整理方法能够实现更精细、更可靠的环境感知,支持从物体定位到3D场景中复杂空间推理等各种任务。(3) 3D具身视频专注于室内环境中的精细空间理解。利用CA-1M [39] 数据集,从200万帧中筛选出10万帧高质量帧。与2D相比,精确的3D边框能够构建更丰富的场景图,展现更多样化的空间关系,从而生成更多定量问答对(例如,大小、距离)。
空间指称。在增强基础3D空间理解能力之后,引入包含80.2万个样本的空间指称数据集[85],将这些能力扩展到物理世界的交互。与以往视觉定位或物体指向数据集(通常处理模糊或多个指称对象)不同,该数据集针对单个明确的目标,这与需要精确物体识别和定位的机器人应用(例如精确拾取和放置)相契合。遵循 RefSpatial [85] 的构建流程,对于位置数据,用分层描述,从基于二维网络图像(OpenImage [38])和三维具身视频(CA-1M [39])构建的场景图中采样描述点对。对于位置数据,利用完全标注的三维数据集生成自上而下的占用图,该图编码了物体的位置、方向和度量空间关系(例如,“椅子右侧 10 厘米”),从而实现精确的空间指称。
3D空间推理(RoboBrain 2.5新增功能)。为了使模型具备强大的3D空间推理能力,以完成诸如3D空间参照、测量和追踪等任务,引入3D空间推理数据集,其中包含174万个样本(808万个问答对)。与侧重于定性、与度量无关的空间概念(例如,左、远、内)的空间理解数据集不同,该数据集基于度量,并支持以适当的单位(例如,厘米、英寸、米)灵活输出。遵循TraceSpatial [86] 的构建流程,提出一种数据管道,该管道逐步集成3D扫描和视频源,以执行3D空间参照、测量和追踪。(1) 3D扫描数据集旨在使模型具备针对室内场景的、基于度量的空间推理能力。因此,利用标注丰富的 CA-1M [39] 和 ScanNet [21] 数据集。经过细粒度滤波后(类似于空间理解部分),构建具有更多样化空间关系的伪 3D 场景图,这得益于与 2D 方法相比更精确的 3D 边框。此外,生成 3D 占用图,其中编码位置、方向和度量距离(例如,“玩具右侧 35 厘米”),以便生成精确的以物体为中心的空间轨迹。(2) 操作视频提供与桌面环境中实际操作一致的空间轨迹。虽然 3D 扫描能够实现以物体为中心的追踪,但它们缺乏适用于机器人的物理上合理的操作。因此,收集真实的(例如,AgiBot-Beta [19]、DROID [36])和模拟的(例如,RoboTwin 2.0 [17])桌面视频。通过严格的数据清洗流程,例如验证有效的相机位姿、连贯的任务流程和清晰的轨迹,将 AgiBot-Beta 的数据集从 16.7 万个样本减少到 5.9 万个样本,将 DROID 的数据集从 11.6 万个样本减少到 2.4 万个样本。进一步利用 Qwen3-VL [62] 将这些任务分解为子目标,从而实现对三种机器人配置的单臂/双臂机器人进行精确的多步空间追踪。
时间预测数据
自我视角规划。通过对包含 5 万个自动生成样本的 EgoPlan-IT [18] 数据集进行部分处理,构建自我视角规划数据集。对于每个选定的任务实例,从先前的动作中提取多个帧来表示任务进度,并提取一个帧来捕捉当前视角。为了增强语言多样性,用多个提示模板来描述任务目标、视频上下文和当前观察结果。每个问题都包含正确的下一步动作,以及最多三个从反例中随机抽取的干扰动作。这种设置支持使用多样化的视觉和文本输入进行多模态指令调整,旨在提高以自我为中心的任务规划性能。
ShareRobot 规划。ShareRobot 数据集 [33] 是一个大规模、细粒度的机器人操作资源,提供专为任务规划量身定制的多维标注。其规划组件提供与单个视频帧对齐的详细底层指令,有效地将高层任务描述转换为结构化且可执行的子任务。每个数据实例都包含精确的规划注释,以支持准确且一致的任务执行。该数据集包含来自 51,000 个实例的 100 万个问答对,涵盖 12 种机器人形态的 102 个不同场景和 107 个原子任务,这些任务根据 Open-X-Embodiment 分类法 [59] 进行筛选。所有规划数据均由人类专家按照 RoboVQA [65] 格式进行精心标注,使模型能够学习基于各种真实世界场景的稳健多步骤规划策略。ShareRobot 的规模、质量和多样性有助于提高模型在复杂具身环境中执行细粒度推理和任务分解的能力。
Agibot 规划。AgiBot 规划数据集是一个基于 AgiBot-World [12] 数据集构建的大规模机器人任务规划数据集,包含 19 个操作任务的 9,148 个问答对和 109,378 张第一人称视角图像。每个样本包含 4-17 个连续帧,以多模态对话格式记录任务进展。AgiBot-Planning 提供分步规划指令,将高层目标转化为可执行的子任务。每个数据点包含当前目标、历史步骤和所需的后续操作。该数据集涵盖了从家庭冰箱操作到超市购物等各种场景,并涉及不同的环境。精心设计的标注采用标准化的对话格式,使模型能够从各种真实世界情境中学习。通过连续的视觉序列和精细的动作计划,AgiBot-Planning 增强了 RoboBrain 2.5 在复杂具身场景中执行长时程任务规划和空间推理的能力。
多机器人规划。多机器人规划数据集基于 RoboOS [68, 69] 构建,模拟家庭、超市和餐厅三种环境下的协作任务场景。每个样本均使用结构化模板生成,这些模板指定了详细的场景图、机器人规格和相关工具列表。针对每种场景,设计高层次、长远的协作任务目标,这些目标需要场景中多个机器人之间的协调,并生成相应的流程图,将任务分解为子任务,并提供详细的推理解释。基于这些分解,进一步生成特定于智体的机器人工具计划,将高层次的任务目标转化为每个子任务的精确的低层次观察-动作对。具体而言,在三个环境中定义 1659 种多机器人协作任务,并使用 DeepSeek-V3 [46] 生成了 44142 个样本。
闭环交互。闭环交互数据集旨在促进高级具身推理 [84],其包含大量合成的观察-思考-动作 (OTA) 轨迹,这些轨迹结合第一人称视觉观察和结构化思维tokens。该数据集涵盖120种不同的室内环境,包括厨房、浴室、卧室和客厅,包含超过4000个交互式物体和容器。该数据集在AI2Thor [37]模拟器中构建,采用基于具身推理器[81]的严谨多阶段流程,包括:(1) 从受限模板中构建任务指令,以确保场景适用性;(2) 从编码功能关系的物体关联图中提取关键动作序列;以及 (3) 策略性地融入搜索动作,以模拟真实的探索过程。为了增强推理深度,GPT-4o [31] 生成了详细的思维过程——涵盖上下文分析、空间推理、自我反思、任务规划和验证——这些过程在观察和行动之间无缝衔接,形成连贯的推理链,引导模型完成复杂的、长周期的交互式任务。
密集值估计(RoboBrain 2.5 新功能)。为了增强密集时间值估计器的泛化能力,构建一个包含约 3500 万个值估计样本的综合数据集,这些样本源自超过 2700 万帧原始数据,然后下采样至 350 万个样本用于最终训练。遵循多巴胺(Dopamine)-奖励[67]流程,该语料库精心聚合自三个互补领域,并经过策略性平衡,以弥合物理现实与语义理解之间的差距:(1)真实世界机器人数据,构成训练集的大部分(约 60%),整合 AgiBot-World[12]、DROID[36] 和 RoboBrain-X[25] 等各种数据集,以使模型能够适应不同环境下的物理交互动态;(2)仿真数据(约 13%),包含 LIBERO[47]、RoboCasa[55] 和 RoboTwin[17] 等基准测试,通过高质量、无遮挡的标签来增强指令遵循能力;(3)以人为中心的数据(约 26%),利用 EgoDex[30] 的大规模数据来获取与机器人形态无关的通用物体可供性先验知识。至关重要的是,这种异质混合模型涵盖广泛的实例,从单臂工业机器人(例如 Franka Emika Panda)到复杂的双手人形机器人(例如 AGIBot-A2D),从而避免模型过拟合特定运动学特征,并确保模型专注于物体状态的变化。
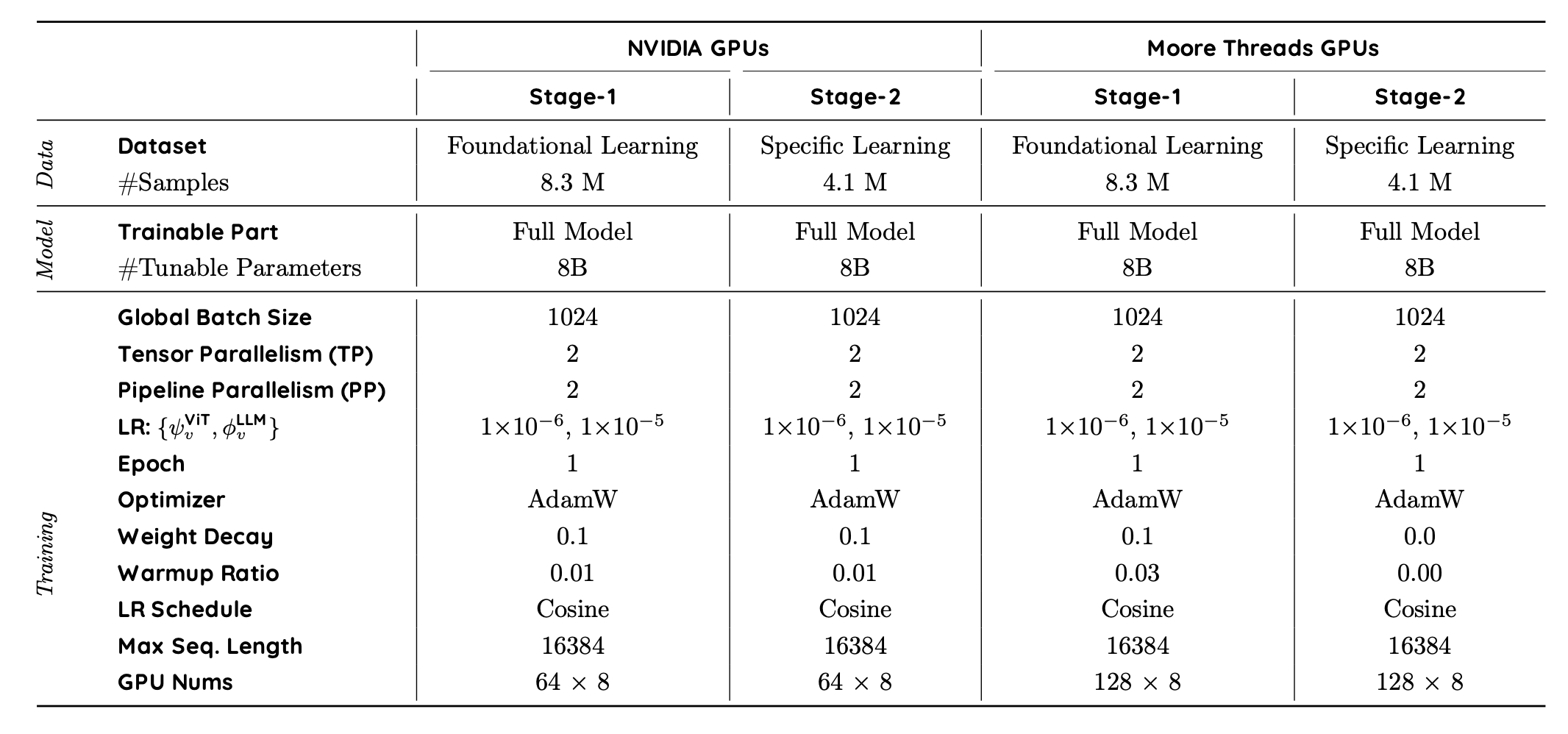
与 RoboBrain 2.0 [72] 类似,RoboBrain 2.5 通过渐进式的双阶段训练策略实现具身认知能力(空间理解、时间建模),如表所示。从稳健的视觉语言基础出发,逐步引入递增的具身认知监督,使模型能够从静态感知演化为动态推理,并在真实环境中进行可执行的规划。具体而言,训练流程分为两个不同的阶段:(1)基础时空学习,建立广泛的视觉语义、二维空间基础和开环规划能力;(2)特定时空增强,在定量三维空间推理和密集时间值估计方面对模型进行微调,以确保精确的、度量感知的物理交互。
第一阶段:基础时空学习
在第一阶段,专注于构建一个强大的“通用大脑”,使其能够理解多模态指令、将物体定位在二维空间中,并掌握高级规划逻辑。用包含 830 万个样本的完整模型,这些样本包括通用 MLLM 数据集、空间推理数据集(不包括度量三维点/轨迹)和时间预测数据集(规划和成对比较)。为了确保模型在这个异构语料库上稳定收敛,采用标准的下一个token预测损失。本阶段的主要目标有三方面:(1)通用视觉感知:利用高质量的通用数据(例如 Honey-Data-1M)来维持和增强模型的通用视觉语言能力。这确保模型能够保持对开放世界语义、复杂用户查询和多样化视觉场景的强大理解,从而为特定的具身任务奠定灵活的基础。 (2)二维空间感知与定性三维理解:除了标准的二维视觉感知和affordance检测之外,此阶段还整合来自三维空间推理数据集的基于文本的问答。这使得模型能够理解复杂的空间关系(例如空间关系、占用情况)和定性三维概念,而无需进行精确的度量坐标回归。(3)规划与时间逻辑:整合多种规划数据集来训练模型进行逻辑任务分解。此外,引入一个源自密集值估计数据集的时间值比较任务。模型不再预测绝对值,而是学习按时间顺序排列关键帧(即识别哪个帧代表后续状态),从而初步了解任务进度和状态演变。此阶段生成的模型精通一般感知、逻辑规划和定性时空推理,为细粒度训练提供了坚实的初始基础。
第二阶段:特定时空增强
为了弥合语义理解与物理执行之间的差距,第二阶段引入了特定时空增强,重点在于精确的定量推理。该阶段利用约 410 万个样本,旨在实现新引入的度量三维空间推理和密集值估计功能。(1) 度量感知三维追踪。引入专注于点和轨迹生成的特定三维数据,以使模型从定性理解过渡到定量感知。这使得模型能够预测绝对三维坐标、深度感知轨迹和度量距离(例如,以厘米为单位),这些对于精确操作任务至关重要。(2) 密集值估计。从成对比较过渡到显式跳跃(Hop)预测。该模型经过训练,能够逐帧预测连续的进度值(跳跃值),从而作为鲁棒的价值函数(Critic)发挥作用,为策略排序和错误恢复提供细粒度的闭环反馈。(3) 防遗忘策略。为了防止在学习这些专门的度量任务时出现通用能力的灾难性遗忘,采用一种数据回放策略。随机抽取第一阶段数据的15%,并将其与第二阶段的特定数据混合。这确保模型在掌握三维具身环境的细粒度物理技能的同时,仍能保持其对话、二维定位和逻辑规划能力。
在 RoboBrain 2.5 的训练过程中,基于 RoboBrain 2.0 [33, 72] 中建立的基础架构,进一步强化并系统化了核心训练流程。整个系统采用多维混合并行策略,结合分布式数据加载优化和针对多模态长序列训练深度优化的内存预分配机制。这些改进显著提升了硬件利用率和整体训练吞吐量。
在数据方面,实现基于 Megatron-Energon [40] 框架,并进行大量自主优化。这种设计实现了统一的格式表示,并支持对包括文本、单幅图像、多幅图像和视频样本在内的异构模态进行在线混合训练。同时,严格保持数据集内部样本的顺序,以满足指令对齐和时间一致性的要求。通过采用定制的 WebDataset [4] 样本格式,系统实现了对多种数据类型的兼容性,同时大幅降低了离线预处理开销,并提高了数据流程的灵活性和可扩展性。
混合并行
多模态大型模型在模型架构和计算特性方面都表现出显著的异构性[48]。视觉组件通常由一个相对轻量级的基于ViT的编码器(带有适配器模块)构成,而语言组件则主要由大规模的纯解码器架构构成。尽管视觉编码器的参数占用较少,但当使用大量视觉或视频样本进行训练时,其计算成本仍然不容忽视。
为了解决这种架构异构性问题,用在智源内部分布式框架FlagScale[20]中积累的异构训练经验,并采用了一种非均衡的流水线并行策略[56]。具体而言,将ViT模块放置在模型的前端,并相应地减少分配给第一流水线阶段的语言层数量。这种设计平衡流水线各阶段的计算负载,缓解流水线气泡问题,并提高整体流水线效率。
动态预分配内存
在RoboBrain 2.5的训练中,不同样本的序列长度差异很大。结合 PyTorch 默认的 CUDA 缓存内存分配器,这种动态形状的工作负载通常会导致严重的 GPU 内存碎片化,在极端情况下甚至会导致内存不足 (OOM) 错误。一种常见的解决方法是在每次迭代之前调用 torch.cuda.empty_cache() [61];然而,这种方法会破坏内存重用,并显著降低训练性能。
为了解决这个问题,对 CUDA 的内存分配和重用行为进行深入分析,并提出一种基于双数据流的动态统一填充策略。
• 在训练开始之前,收集训练集中观察的最大序列长度;
• 在第一次训练迭代中,所有样本都被填充到该最大长度,从而在初始化期间实现一次性内存预分配;
• 在后续迭代中,张量重用预分配的内存,有效地抑制内存碎片化;
• 仅当视觉token长度超过当前最大值时,系统才会触发完整的缓存清理,并将样本重新填充到新的最大长度。
该策略在内存效率和训练性能之间取得有效的平衡,在大规模多模态长序列训练场景中兼顾稳定性和高吞吐量。
跨加速器训练和推理
利用 FlagScale 在异构加速器集群上的分布式训练能力,结合 VLM 特定的内核和通信优化,成功地在由非 NVIDIA 加速器组成的千台设备集群上完成 RoboBrain 2.5 的端到端训练。由此产生的损失收敛行为与在 NVIDIA 平台上观察到的情况非常接近,最终收敛差距控制在 0.62% 以内。
此外,训练好的检查点可以无缝迁移到基于 NVIDIA 的平台进行下游评估。在一系列主流基准测试中,最终性能与在 NVIDIA 硬件上原生训练的模型高度一致。 RoboBrain 2.5 案例研究表明,FlagOS/FlagScale 的跨加速器训练和推理能力已经成熟到可靠、实用且可用于大规模多模态模型训练的生产就绪水平。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献210条内容
已为社区贡献210条内容

所有评论(0)