RoutIR 开源框架实战指南(非常详细),让 RAG 真正“跑”起来全攻略,收藏这一篇就够了!
约翰斯·霍普金斯大学开源的 **RoutIR**,用 200 MB 内存+几行 JSON,就能把任何学术检索模型(BM25、ColBERT、PLAID-X、Qwen3-Embedding……)包装成 **高并发 HTTP API**,动态拼装多路召回、重排序、结果融合,3-10 QPS 起步,缓存命中时“秒回”,彻底终结 RAG 流程里“离线模型上线难”的痛点。
约翰斯·霍普金斯大学开源的 RoutIR,用 200 MB 内存+几行 JSON,就能把任何学术检索模型(BM25、ColBERT、PLAID-X、Qwen3-Embedding……)包装成 高并发 HTTP API,动态拼装多路召回、重排序、结果融合,3-10 QPS 起步,缓存命中时“秒回”,彻底终结 RAG 流程里“离线模型上线难”的痛点。
| 传统痛点 | RoutIR 解法 |
|---|---|
| 学术 IR 工具(PyTerrier/Anserini)只支持离线批处理,无法嵌入动态 RAG | 提供 HTTP 服务层,即插即用 |
| 多模型组合(召回+重排+融合)要写大量胶水代码 | 一条字符串 {e1,e2}RRF>>rank1 动态拼装 |
| 高并发场景下 GPU 利用率低、延迟高 | 内置 异步批量+队列,自动把 50 ms 内请求拼 batch |
| 重复查询浪费算力 | 内存/Redis 两级缓存,默认开启 |
系统架构 1 分钟速览
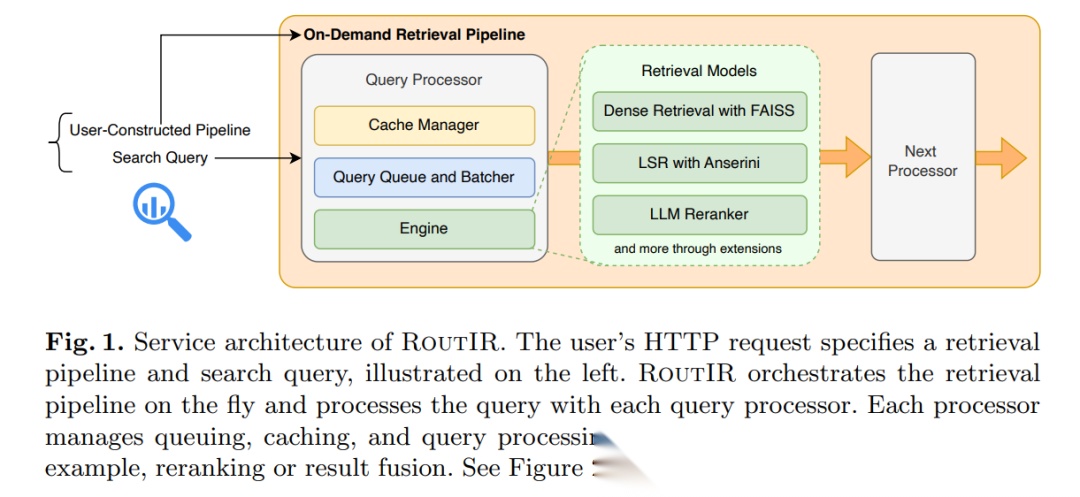
把核心抽象成 3 个乐高积木:
- Engine
真正的检索模型。官方已内置:
- 稠密向量:Qwen3-Embedding + FAISS
- 多向量:PLAID-X
- 学习稀疏:SPLADE-v3、MILCO
- 重排器:monoT5、Rank1、Qwen3-Reranker
新增模型只需继承Engine类,实现search_batch()即可。
- Processor
给 Engine 穿上“并发+缓存”外套:
- 请求先进入队列,≥batch_size 或 ≥50 ms 就整批喂给 Engine;
- 结果按 query id 原路返回,同时写缓存。
- Pipeline
用类似 Unix shell 的语法即时拼装复杂流程:
例:{qwen3-neuclir,plaidx-neuclir}RRF>>rank1
解释:两路召回并行 → RRF 融合取 Top-50 → Rank1 重排,全程异步并行,无需手写代码。
4 步把模型跑成服务
| 步骤 | 命令/配置 |
|---|---|
| ① 安装 | pip install routir |
② 写配置 config.json |
指定 Engine、索引路径、集合文件(JSONL) |
| ③ 启动 | routir config.json --port 5000 |
| ④ 调用 | curl -X POST http://ip:5000/query -d '{"service":"qwen3-neuclir","query":"马丘比丘在哪","limit":15}' |
返回示例:
{ "result": { "doc-42": 18.9, "doc-7": 18.1, ... }}
评测&实战
真实 Benchmark
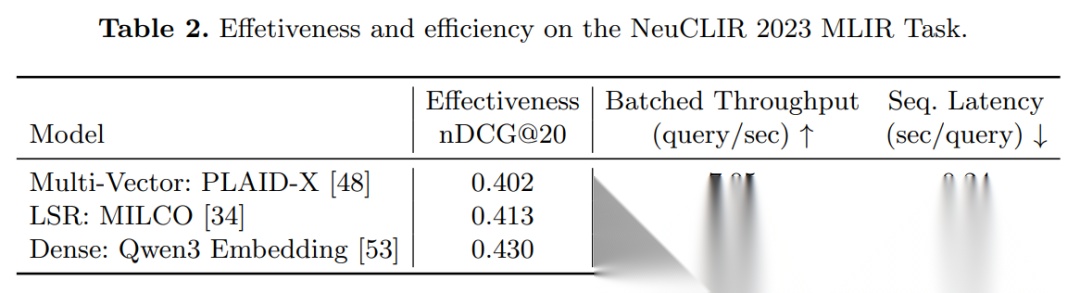
(nDCG@20 越高越好,Throughput 越大越好,NeuCLIR 多语种 1000 万文档)
| 模型 | nDCG@20 | 并发吞吐 (QPS) | 单条延迟 (s) |
|---|---|---|---|
| Qwen3-Embedding | 0.430 | 9.6 | 1.23 |
| PLAID-X | 0.402 | 7.1 | 0.24 |
| MILCO (LSR) | 0.413 | 3.3 | 2.46 |
- 全部跑在 单张 24 GB TITAN RTX;
- 开缓存后,二次查询 < 50 ms;
- 异步并发比顺序打 query 快 3-10 倍。
RAG 接入实战
GPT-Researcher 如何调用 RoutIR:
class LiveRAG_PLAIDX_Search: def __init__(self, query): self.query = query self.url = os.getenv("RETRIEVER_ENDPOINT") def search(self, max_results=5): resp = requests.post(f"{self.url}/query", json={ "service": "plaidx-liverag", "query": self.query, "limit": max_results }).json()["result"] return [{**self.get_content(doc_id), "score": score} for doc_id, score in resp.items()]
```
无需额外依赖,任何 LangGraph、AutoGen、DSPy 流程都能直接 requests.post 调用。
**与现有工具对比**
| 维度 | RoutIR | PyTerrier-RAG | ElasticSearch/Vespa |
| --- | --- | --- | --- |
| 目标场景 | 学术→原型→轻量级生产 | 学术实验 | 工业级搜索 |
| 新增模型 | 继承 Engine 即可 | 需深度集成 | 插件开发复杂 |
| 动态拼装 | 字符串即时描述 | 需要代码 | 需要 DSL/YAML |
| 缓存/并发 | 内置 | 无 | 有,但重量级 |
| 资源占用 | 200 MB 起 | 取决于底层 | GB 级 |
RoutIR 像“检索界的 LiteLLM”:让学术模型一键变成在线服务,把“写胶水代码”变成“写一句话”。 如果你正在做 RAG、Search-Agent 或者需要快速 A/B 不同召回策略,**RoutIR 值得放进你的工具箱。**
```plaintext
RoutIR: Fast Serving of Retrieval Pipelines for Retrieval-Augmented Generationhttps://arxiv.org/pdf/2601.10644https://github.com/hltcoe/routir
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献643条内容
已为社区贡献643条内容

所有评论(0)