【大模型智能体】代理式人工智能:大型语言模型智能体的架构、分类与评估
摘要:人工智能正从生成式模型向代理式AI演进,系统能够自主感知、推理与行动。本文系统研究了大型语言模型智能体的架构演进,提出统一分类法将其分解为感知、大脑、规划、行动等六大模块。通过分析从单循环代理到多代理系统的技术发展,揭示了工具使用、协作机制及评估方法的关键特征。研究指出行动幻觉、无限循环等风险,并为构建稳健自主系统提供了技术路线。该框架为理解智能体在软件工程、科学发现等领域的应用奠定了基础。
Agentic Artificial Intelligence (AI): Architectures, Taxonomies, and Evaluation of Large Language Model Agents
代理式人工智能:大型语言模型智能体的架构、分类与评估
摘要
人工智能正从仅生成文本的模型,迈向代理式人工智能的新阶段——系统能够作为自主实体进行感知、推理、规划与行动。大型语言模型不再仅仅充当被动的知识引擎,而是成为结合记忆、工具使用和环境反馈以追求长期目标的认知控制器。这一转变已支撑起软件工程、科学发现和网络导航等领域复杂工作流的自动化,然而从简单的单循环代理到分层多代理系统等新兴设计的多样化,使得技术版图难以清晰把握。
本文系统研究了各类架构,并提出一种统一分类法,将智能体分解为感知、大脑、规划、行动、工具使用与协作六大模块。借助这一框架,我们描述了从线性推理流程到原生推理时模型的发展,以及从固定API调用向模型上下文协议(MCP)和原生计算机使用等开放标准的演进。同时,我们对智能体的运行环境进行了归类,涵盖数字操作系统、具身机器人及其他专业领域,并梳理了当前评估实践。最后,我们指出行动幻觉、无限循环和提示注入等开放挑战,并展望未来研究方向,以构建更稳健可靠的自洽系统。
关键词:能动型人工智能、大语言模型、自主智能体、多智能体系统、认知架构、工具使用、规划。
智能体AI将人工智能系统的角色从对话伙伴转变为能够端到端执行任务的主动协作者。本文研究了让大语言模型在软件工程、科学发现和机器人领域运行复杂工作流的架构,阐释了该领域如何从单智能体循环向有组织的多智能体系统演进。我们同时指出了关键风险,包括操作中的提示注入与幻觉问题,并为构建稳健、安全、高效且适用于开放现实世界环境的自主系统提供了切实可行的路线图。
1.引言
人工智能领域正从专注于将输入映射至静态输出的“生成式人工智能”,转向“智能体人工智能”——这类系统旨在通过感知、推理和行动,主动改变其环境状态。这一转变的驱动因素已不再仅限于提示工程。
前沿模型家族如今展现出更强大的原生推理能力,包括在专用推理模型中提供可配置的推理时间预算,这实际改变了规划器和控制器的构建方式[29, 31]。与此同时,通用型基础模型(如OpenAI GPT 5系列、Google Gemini 3 Pro及Claude 4.5系列)日益支持结构化工具调用与多模态交互,但其基础对话形态仍采用逐轮处理模式,无法在长周期任务中维持可靠的任务状态或权限连续性[97–99]。
自主智能体的概念在计算机科学领域有着悠久的学术渊源。经典研究[6]将智能体视为具有情境自主性的封装实体,其构建基础是符号逻辑与手写规则。基于现代大语言模型的智能体与符号系统及强化学习智能体均存在重要差异:当代智能体不再依赖固定的符号表征或通过与环境反复交互习得的任务特定策略,而是依托基础模型中编码的概率化世界知识,能够以极少的任务特定训练实现对新任务的泛化,并常常达成零样本迁移[7]。实践中,这种特性使得智能体能够在开放领域内运行,其应用范围涵盖从修复大型软件仓库中的代码缺陷[8]到设计融合假设生成、代码执行与结果解析的科学研究工作流[9]。
智能体系统的设计动机源于某些工作流无法在单次模型调用的上下文窗口、可靠性范围或工具权限内完成。然而,工程上的应对方案并非简单地增强智能体的自主性。一个重要的实践转向是可控编排,即由开发者明确定义状态转换规则与安全护栏,而模型负责填充局部决策。这一趋势体现在基于图的编排框架与状态机设计中,此类系统优先考虑可调试性、检查点设置和人工审核机制,常被称为流程工程[32, 33]。这些编排选择直接关联到系统的可靠性与安全性,因为控制器决定了可行的操作集合、智能体的循环条件,以及验证与升级干预的发生节点。
部署具身人工智能也会带来静态大语言模型所不具备的风险。一旦模型能够执行修改文件、运行代码或操作桌面界面等行动,幻觉就可能转化为具体的故障而不仅仅是错误的文本。安全威胁也随之扩大,因为智能体必须处理非受信内容并据此采取行动。间接提示注入就是一个核心案例:恶意指令被嵌入网页、文档或工具输出中,随后被遵循指令的智能体执行[139]。新的交互模式(例如原生计算机操作——智能体通过截屏配合鼠标键盘动作操作用户界面[37, 38])进一步放大了这些风险。与此同时,工具集成在基础设施层正日益标准化。模型上下文协议为智能体提供了暴露工具和资源的通用方式,减少了连接器架构的碎片化,并支持在协议边界实施允许列表和审计日志等治理模式[34, 35]。
现有关于基于大语言模型的智能体与智能体化AI的调查主要采取以下四种互补视角:(i) 对基于大语言模型的自主智能体及其应用的广泛综述 [18, 63];(ii) 超越大语言模型、侧重于概念与定义的智能体化AI论述 [5];(iii) 聚焦于工具使用、规划与反馈学习等方法论的研究综述 [17, 24];(iv) 近期主要从方法论角度描述大语言模型智能体的文献回顾 [22]。相比之下,本次调查明确以架构与工程实践为核心:我们从基于POMDP的形式化智能体控制循环出发,围绕实际系统如何构建、部署与评估来组织文献,涵盖推理时思考、可控编排与标准化工具连接等具体方面。
具体而言,我们的主要贡献包括:
• 聚焦统一架构的分类体系。我们提出一种统一分类法,将基于大语言模型的智能体分解为六个模块化维度:核心组件(感知、记忆、行动、画像)、认知架构(规划、反思)、学习、多智能体系统、环境与评估。这种“架构优先”视角将各组件与底层控制循环相连接,并对以往主要按应用领域 [18, 63] 或按工具使用、规划、反馈学习等范式 [17] 进行归类的研究综述形成补充。
• 工程与系统视角。除高层次方法论外,我们重点探讨影响实际部署系统的具体设计选择:记忆后端与保留策略、人机界面与计算机使用行为、从JSON风格函数调用到代码即行动的演进、MCP等标准化连接层,以及强制执行类型化状态与显式状态转移的编排控制器。相较于以方法论为中心的综述 [22],我们更关注如何将这些模块集成为稳健、可监控的智能体系统。
• 从自主循环到可控图结构。我们对多智能体系统进行了统一论述,将经典多智能体系统理念与现代基于大语言模型的框架相联系。我们描述了链式、星型、网状及显式工作流图等交互模式,并在同一框架下分析了包括CAMEL、AutoGen、MetaGPT、LangGraph、Swarm和MAKER在内的多种系统。这拓展了早期多智能体调查往往孤立讨论协作机制的研究思路 [81, 82]。
• 环境、评估与安全的整体性视图。我们直接基于架构空间,运用成本、延迟、准确性、安全性与稳定性的CLASSic维度进行系统评估。我们将分层规划、代码执行、图控制器、计算机使用行为等架构选择,与具体失效模式(包括行动幻觉、无限循环、提示注入等)相关联。同时,我们总结了面向企业的基准测试与部署实践中的经验教训 [4, 75, 114]。
2.背景与定义
本节概述了智能体概念的演进脉络,基于数学决策框架对智能体定义进行形式化描述,并提出构成现代智能体系统的整体分类体系。
2.1 从符号与强化学习智能体到基于大语言模型的智能体
“智能体”这一概念在计算机科学发展史中经历了重大演变。早期研究集中于符号智能体,如奠基性文献[6]所述,这类系统依赖预定义规则、形式逻辑和固定约束在封闭环境中运行。此类系统在其设计范围内通常稳健,但一旦面对超出编程规则的情况则显得脆弱。随着研究推进,焦点逐渐转向强化学习智能体,其策略通过与环境的反复交互及显式的试错过程习得。这类智能体在特定控制任务上表现优异,但通常缺乏开放式推理或灵活自然语言交互所需的泛化能力,且每项新任务都需要大量数据及精细的样本效率优化[15]。
基于大型语言模型的现代智能体可被视为第三种范式。这些智能体不再依赖硬编码规则或狭义定义的奖励函数,而是使用预训练的大语言模型作为通用认知控制器。在此视角下,大语言模型充当可被外部记忆模块与执行模块增强的推理引擎[16],设计重点也从策略训练转向提示设计、工具集成与流程编排。这使得智能体能够将从海量互联网语料中学到的语义知识迁移至面向具体行动的任务中[17]。实践中,此类智能体常能以零样本方式泛化至包含软件开发和机器人技术的新环境,实现纯符号系统或标准强化学习智能体单独无法达成的行为。
2.2 形式化定义:主体控制回路
尽管具体架构存在差异,学界对于如何描述基于大语言模型的智能体的基本数学结构正形成日益增长的共识。与其仅将智能体视作一种策略,将其视为在部分可观测马尔可夫决策过程框架内运行的动态控制系统更为有益。我们将智能体系统A表述为一个元组:
A = ⟨ S , O , M , T , π ⟩ , \mathcal{A}=\langle\mathcal{S},\mathcal{O},\mathcal{M},\mathcal{T},\pi\rangle, A=⟨S,O,M,T,π⟩,
其中S为状态空间,O为观测空间,M为内部记忆空间,T为动作或工具空间,π为策略。
在每个离散时间步长t,系统会执行一系列相互关联的函数循环。
2.2.1 感知函数(Φ)
智能体无法获取完整的环境状态St ∈ S,而是通过感知函数Φ接收部分观测值Ot,该函数可能包含多模态编码器(例如视觉模型如CLIP)或基于文本的封装器:
O t = Φ ( S t ) w i t h O t ⊂ S t . O_t=\Phi(S_t)\quad\mathrm{with}\quad O_t\subset S_t. Ot=Φ(St)withOt⊂St.
2.2.2 记忆更新机制 (μ)
与无状态的强化学习智能体不同,基于大语言模型的智能体维护一个可变的内部状态 M t M_t Mt。该状态由函数μ更新,该函数整合了新的观测 O t O_t Ot、先前的推理轨迹 Z t − 1 Z_{t−1} Zt−1以及执行反馈 E t − 1 E_{t−1} Et−1:
M t = μ ( M t − 1 , O t , Z t − 1 , E t − 1 ) . M_t=\mu(M_{t-1},O_t,Z_{t-1},E_{t-1}). Mt=μ(Mt−1,Ot,Zt−1,Et−1).
此次更新步骤融合了检索增强生成(RAG)方法[16],其中μ参数负责从智能体的长期记忆中筛选相关信息并注入当前上下文。
2.2.3 认知规划 (Ψ)
Agentic AI的一个界定性特征在于执行任何外部行动前所产生的潜在推理步骤Zt(即思考或计划)。我们将其建模为由大语言模型θ参数化的概率推断过程。
Z t ∼ P θ ( Z t ∣ M t , O t ) . Z_t\sim P_\theta(Z_t\mid M_t,O_t). Zt∼Pθ(Zt∣Mt,Ot).
变量Zt既可以表示一个简单的思维链,也可以表示一个更具结构性的层次化计划。在诸如RAP [19]这类先进架构中,规划阶段被实现为对潜在未来轨迹的递归树搜索。
2.2.4 行动策略(π)与执行
最后,智能体从工具空间T中选择并执行动作At。策略π直接以推理轨迹为条件,从而将行动显式地锚定在内部计划中:
A t ∼ π θ ( A t ∣ Z t , M t ) . A_t\sim\pi_\theta(A_t\mid Z_t,M_t). At∼πθ(At∣Zt,Mt).
随后环境通过状态转移 S t + 1 ← Env ( S t , A t ) S_{t+1} \leftarrow \text{Env}(S_t, A_t) St+1←Env(St,At)对此动作作出反应,并产生反馈 E t E_t Et。该反馈回流至下一个感知与记忆更新步骤,从而闭合控制回路 [20]。
3.分类法
3.1 智能体人工智能生态系统的整体分类学
图1展示了代理式人工智能生态系统的高层概览及其架构随时间的演化路径。该领域通过六个相互关联的维度进行扩展,实现了从单一模型内的个体能力,到协调多个代理并包含明确评估与安全机制的系统演进。
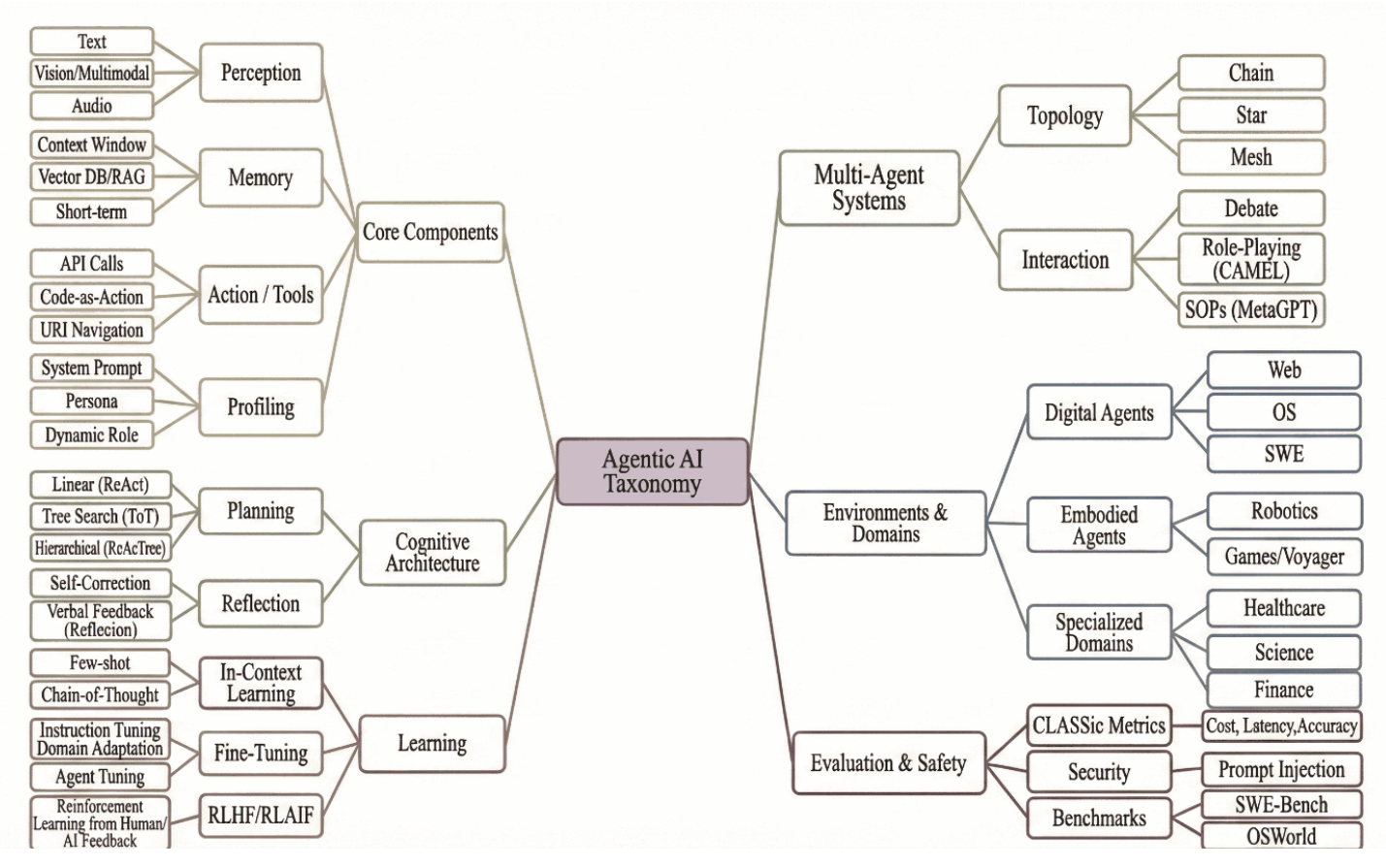
图1:具身智能体生态系统分类图谱。该图将现有文献归纳为六个核心维度:基础组件、认知架构、学习机制、多智能体系统、运行环境及评估体系。这些维度共同勾勒出该领域从基于文本的简单循环系统,向能在开放环境中运作的复杂层级化系统演进的发展轨迹。
核心组件
智能体一切功能的根基在于其与世界的交互界面。感知系统已从仅处理原始文本发展为兼容视觉、多模态及音频输入,使智能体能解读复杂的图形用户界面。记忆机制从短暂的上下文窗口转向由向量数据库与检索增强生成(RAG)技术支撑的持久化存储,从而支持长时程的信息连续性。基于同样的演进逻辑,行动接口也从固定的API调用发展为更灵活的代码即行动模式与直接URI导航。画像系统通过系统提示与动态角色定义来完成该层级构建,它确立智能体的身份标识,确保其在不同任务中行为模式保持一贯性。
认知架构维度描述了智能体的推理机制。早期系统依赖于线性规划循环,如ReAct。为处理更复杂问题,近期研究采用了分层结构,例如使用树搜索方法的"思维树"(Tree of Thoughts),以及如ReAcTree所采用的递归分解方法。为提高可靠性,这些规划器辅以反思机制,包括自我校正及言语反馈方法(如Reflexion),使智能体能够在行动前对计划进行批判性评估与优化。
学习维度捕捉智能体如何随时间获取并提升能力。在频谱的一端是在线上下文学习方法,例如少样本提示和思维链,这些方法具有临时性并完全在提示中完成。另一端则是通过微调实现的永久权重更新,包括指令微调和智能体专项微调。在此基础上,对齐技术(如RLHF和RLAIF)利用人类或其他模型的反馈来调整智能体行为,正日益广泛地应用于现实场景中的决策塑造。
随着任务需求超出单一模型的处理能力,分类体系拓展至多智能体系统。这一维度区分了多种交互模式:既包括从对抗性辩论到协作式角色扮演(如CAMEL),也涵盖基于标准操作流程的结构化工作流(如MetaGPT)。同时该维度突出了不同的通信拓扑结构——智能体可按链式结构组织以实现顺序处理,可采用中央协调器主导的星型配置,亦可通过网状集群实现更去中心化的协同运作。
智能体的定义也取决于其运行环境。分类体系将其划分为:在网络浏览器、操作系统或软件工程工具内运作的数字智能体;机器人学和《Voyager》等游戏中的具身智能体;以及涵盖医疗健康、科学和金融等领域的专业领域智能体。每类环境都具有独特的约束条件和功能可供性,这反过来对感知、记忆和行为设计提出了特定要求。
评估与安全
最后一个维度涉及智能体系统的评估与安全保障。评估框架已超越单一的准确率指标,目前采用成本、延迟、准确度、安全性和稳定性的CLASSic综合指标体系。安全研究尤其侧重于防范提示注入等威胁。与此同时,SWE-Bench(软件工程基准)和OSWorld(操作系统控制基准)等标准化测试集为追踪不同系统架构的进展提供了统一的参照基准。
我们以此分类体系作为本文后续内容的组织结构。它使我们能够深入分析每个维度——从单智能体认知架构到多智能体协同模式,以及现实场景部署所需遵循的评估与安全实践。
4.智能体人工智能统一架构
我们将自主智能体的架构视为一种认知管道,通过核心决策过程将感知转化为行动。如图2所示的反馈循环,该系统将模块化资源与随时间运行的推理引擎相集成。根据图1的分类体系,我们将此管道划分为三个层次:i) 核心组件层——提供感知、记忆、行动与画像的交互接口;ii) 认知架构层——执行规划与反思;iii) 学习层——描述智能体如何习得并完善其能力。
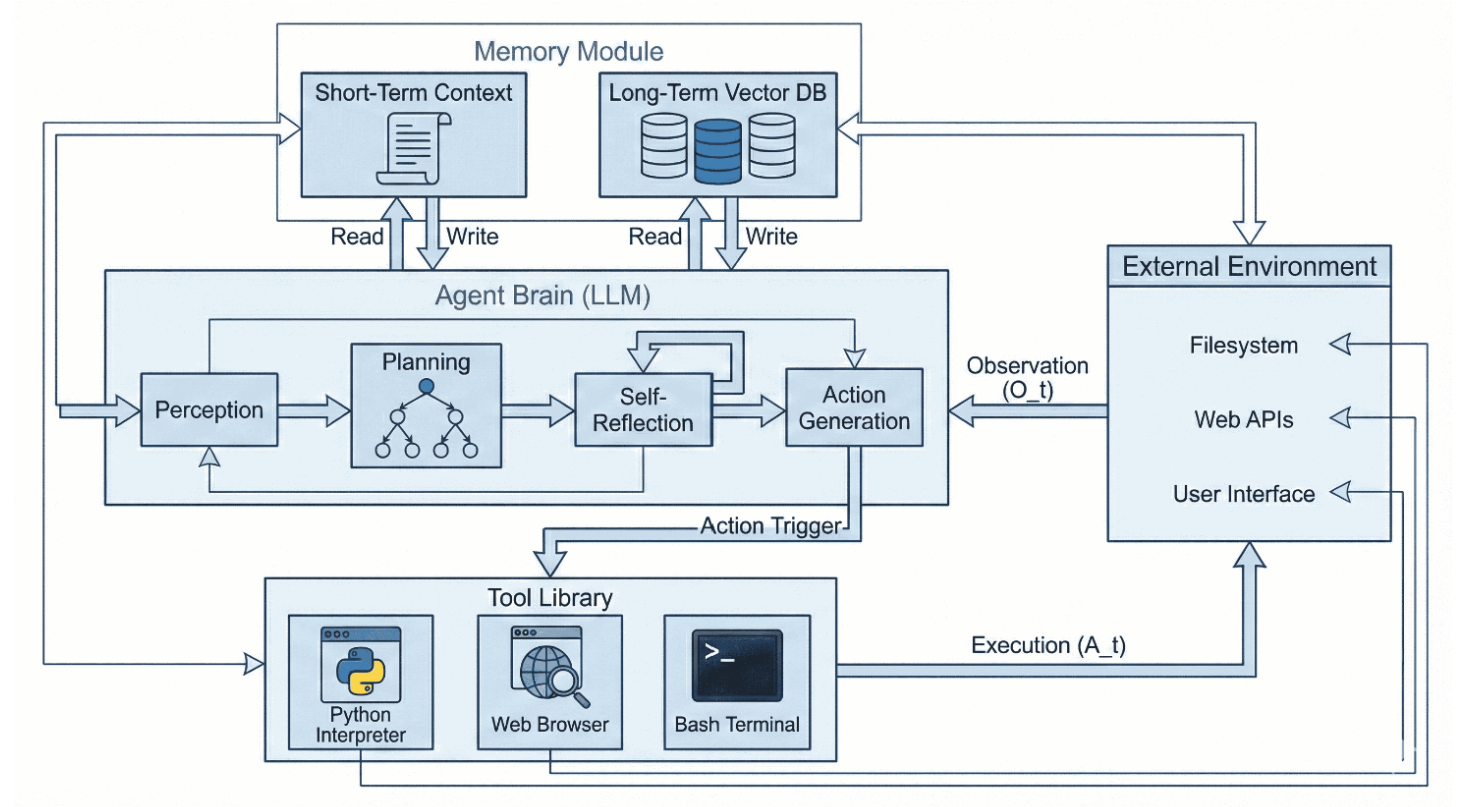
图2:智能体人工智能的统一架构。该系统呈现为改进型部分可观测马尔可夫决策过程循环。中心的智能体大脑通过分层规划与自我反思,将每次观测( O t O_t Ot)转化为推理轨迹( Z t Z_t Zt)。顶部的双流记忆模块支持上下文检索,而底部的工具库则执行基于代码的动作( A t A_t At),这些动作会改变右侧的外部环境。
4.1 核心组件
现代智能体架构由模块化组件构成,通过认知过程进行协调。基于基础结构层[21]与构建分类法[22],我们将智能体A的核心组件表述为一个元组。
A = ⟨ Φ , M , T , P ⟩ , A=\langle\Phi,M,T,P\rangle, A=⟨Φ,M,T,P⟩,
其中Φ代表感知,M代表记忆,T是行动与工具的集合,P代表画像分析。
4.1.1 感知
感知(Φ)是智能体与其环境交互的接口。早期的智能体(如ReAct)完全在文本域中运作。相比之下,近期的系统利用多模态大语言模型(MLLMs),将推理过程建立在更高维度的感官输入之上。
面向数字与具身环境的跨模态语义理解
现代感知模块已突破纯文本输入范畴,支持界面层语义理解(屏幕截图、触控坐标及混合DOM+视觉信息)与具身感知(视频、音频及三维几何数据)。WebVoyager与AppAgent在浏览器与移动应用中分别展示了基于截图驱动与坐标控制的交互模式,但二者均暴露出持续的语义理解瓶颈:将高层用户意图映射至精确界面元素时,微小控件与动态布局易导致定位漂移或误触生成[91, 92, 108]。针对时序动态场景,Magma将感知能力扩展至连续视频流以支持机器人操控任务[156]。除视觉模态外,AudioGPT集成语音/音频理解能力实现语音优先交互[93];而3D-LLM通过注入点云表征以保留二维投影中损失的空间可供性信息[94]。表1系统梳理了代表性架构设计、语义理解机制及其主要失效模式。
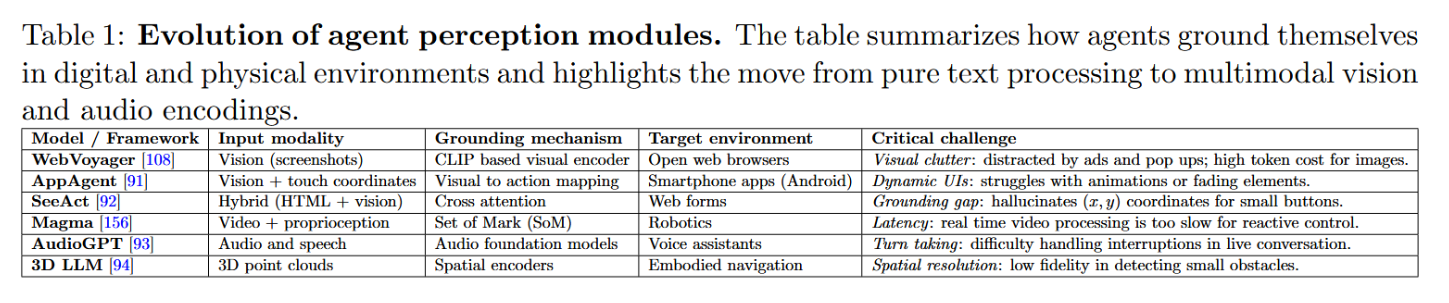
表1:智能体感知模块的演进历程。该表格总结了智能体如何在数字与物理环境中实现自我定位,并着重呈现了从纯文本处理到多模态视觉与音频编码的技术发展路径。
4.1.2 记忆
为实现持久智能体而非单次会话的行为,系统需要具备在时间维度上保存状态并支持行为一致性的机制。记忆组件不仅能满足这些需求,还超越了简单的向量检索功能,它包含结构化存储、保持策略,以及用于信息摘要与删除的显式处理机制。
记忆作为检索、结构与留存策略
智能体在成本与注意力约束下如何管理工作上下文是核心系统决策:长上下文提示会因无关历史而难以扩展,因此检索增强生成技术对于聚焦任务相关状态仍然至关重要[16]。MemoryBank研究表明,通过结构化检索与自我剪枝,分层摘要的表现可优于原始日志提示[61];而当单次提示不足时,Chain-of-Agents能将超长上下文分配到协同工作的多个智能体间处理[78]。为实现长程连贯性,Generative Agents维护带时间戳的记忆流[59],而ACAN式对齐机制能实现超越基础相似性检索的回忆效果[60]。留存策略(总结/遗忘/剪枝)可防止记忆无限增长:MemInsight将情景轨迹压缩为语义“洞见”[76],MemAgent则将记忆管理视为跨会话的习得决策过程[77]。当状态天然具备结构时,ChatDB通过SQL实现高精度符号记忆[62],而MemGPT则在显式控制器下形式化了短上下文与外部存储间的分页机制[102]。表2从结构、检索与留存策略维度对比了这些设计方案。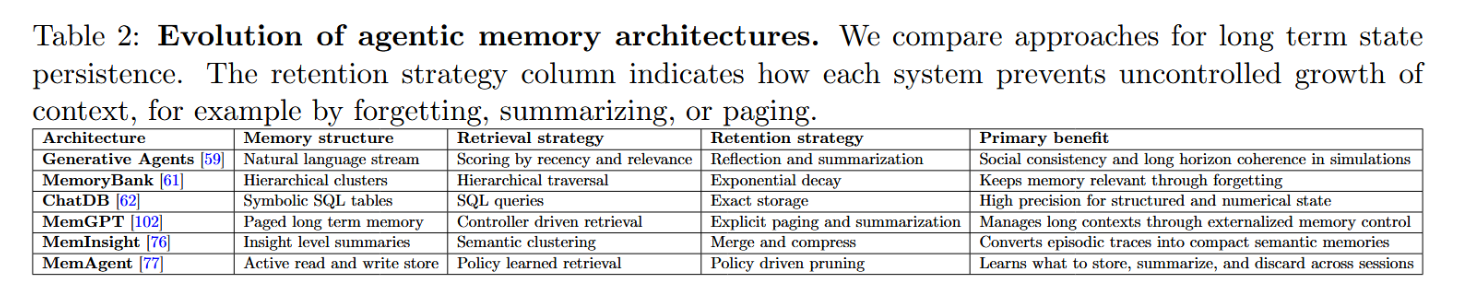
表2:智能体记忆架构演进。我们比较了长期状态持久化的实现方法。"保持策略"列展示了各系统如何防止上下文无限扩展,例如通过遗忘、摘要或分页机制实现。
4.1.3 行动与工具
虽然认知架构(下文详述)提供了推理蓝图,但行动组件使智能体能够实际改变其环境。 该模块将规划层产生的语义意图转化为具体操作。随着时间推移,可能的行动空间已从固定、预定义的函数调用发展为更灵活的代码执行和界面级导航。为清晰起见,我们将这些机制归纳为四大主要范式:API调用、代码即行动、智能体计算机界面,以及具身视觉语言行动。
从受限API到代码、接口与具身控制
智能体行动空间已从受限API/函数调用扩展至可执行程序、用户界面级控制及连续具身策略。以API为中心的系统如Toolformer和Gorilla通过结构化调用强调安全性与工具选择,但通常需要脆弱的模式提示及跨步骤的临时状态传递[52, 57]。在基础设施层,MCP标准化了工具发现与调用机制,使控制器能在权限白名单、身份验证和审计日志等治理边界内连接持续演进的工具目录[34, 35]。
与此同时,“代码即行动”范式将可执行脚本作为控制接口——支持变量和控制流,且更适配代码密集型的预训练数据分布——CodeAct与Voyager的可复用技能库即为例证[3, 64]。针对长周期数字任务,经过定制的智能体计算机接口(如SWE-agent)通过提供简化的、适配智能体的命令行界面/集成开发环境,降低了上下文负载[8]。最后,计算机使用操作(屏幕截图+鼠标/键盘)支持通用图形界面操作,但会引入延迟与更广泛的注入风险[36, 38];而具身视觉语言动作系统则朝着机器人领域的直接感知-运动控制方向推进[118]。表3总结了这些范式及其权衡关系。

表3:具身智能体行动空间的演进。该表格对比了智能体执行任务的主要方式。近期的生产系统增加了用于通用图形用户界面控制的计算机操作行为,同时包含代码执行和受限的工具调用。
4.1.4 用户画像
记忆赋予智能体经验的连续性,而画像则赋予其稳定的性格特征。该模块定义了智能体的身份、角色及隐性约束[23]。在实际应用中,画像对应塑造行为的系统提示或角色设定,例如:“你是一名资深Python工程师,编写清晰且经过充分测试的代码。”此类画像能缩小搜索空间并提升行为对齐度。一个强调安全性的智能体画像,自然会比优先考虑速度的智能体更倾向于选择更安全的方案。更先进的设计支持动态角色切换,例如当任务从起草阶段转入修订阶段时,智能体可从写作者角色转换为编辑者角色。
4.2 认知架构
认知架构是智能体的决策核心:它将目标分解为动作序列 At 并监控执行过程中的不一致性和失败。与依赖人工编写规则和显式环境模型的经典符号规划器不同,基于LLM的智能体利用概率性世界知识来提出计划,并在反馈下进行修正。根据我们的分类法,我们通过规划(轨迹如何构建)与反思(轨迹如何评估与改进)来描述这一层。
4.2.1 规划
一个基础的智能体范式是ReAct [1],其将中间推理与环境交互交错进行,这与纯粹隐式的思维链提示 [25] 形成对比。ReAct执行轨迹 τ = { o 1 , z 1 , a 1 , o 2 , z 2 , a 2 , . . . } τ = \{o1, z1, a1, o2, z2, a2, . . . \} τ={o1,z1,a1,o2,z2,a2,...},其中推理依据 z t z_t zt 决定行动 a t a_t at 及后续观察,这提升了事实依据性,但仍易受短视和错误传播的影响(例如,早期错误可能导致无益的循环)。
为减少思维盲目性,诸多方法会引入显式分支与搜索。"思维树"将中间思维视作搜索节点,并通过广度/深度优先策略探索备选路径[26]。LATS进一步将智能体规划与蒙特卡洛树搜索相结合,利用模型同时担任提案生成器和评估器,从而可在执行不可逆工具调用前对候选方案进行筛选[127]。
最新趋势显示,前沿推理模型在推断时将部分搜索过程内化。OpenAI的o1系列强调通过增加测试时的“思考”来提升性能[28, 29],这与测试时计算规模化的研究[31]及后续发布的o3[30]等方向一致。这并未消除外部规划模块,而是改变了其角色:现代系统日益将可控的推断时推理预算,与强制执行安全性、状态持久性和工具权限的外部控制器相结合。
随着任务复杂度增加,扁平规划器仍面临语境与模块性限制,这推动了层级分解方法的发展。ReAcTree通过显式控制流将长程规划分配至递归子智能体[2],而GoalAct采用双层架构,包含全局里程碑规划器与局部执行器[27]。这些设计提升了可解释性与故障隔离能力,但在大规模或高噪声环境中可能增加令牌消耗与延迟成本。
为在无需额外标注的情况下提升效率,测试时优化方法利用从智能体轨迹中提取的信号来改进行为(例如RISE与测试时自我改进)[49, 50]。前瞻性架构进一步将内部决策过程与面向用户的输出分离,以限定交互延迟[51]。表4将这些方法与提示搜索、层级结构以及推理时计算扩展进行了对比定位。
4.2.2 反思
反思机制使智能体能够基于自身行为轨迹进行批判与调整,将稀疏的成功/失败信号转化为可操作的指导。一种常见模式是语言强化:Reflexion 系统以自然语言形式存储对失败的批判性分析,并依据这些经验调整后续尝试的策略,而非直接更新模型权重[44]。互补地,自我修正协议在输出前应用批判性评估。Self-Refine 系统实现了生成-批判-修订的迭代循环[65];而 CRITIC 方法则通过要求工具交互式验证(例如使用解释器或搜索工具)来减少纯粹的内部确认循环,以此作为接受修订的前提[155]。
反思在工具故障(超时、模式不匹配、重复重试)情况下尤为重要。PALADIN通过在大规模故障轨迹数据集上训练恢复行为,能够进行故障诊断并执行修正后的重试,从而减少循环式故障的发生[58]。Expel能够从历史错误(例如安全机制或回滚启发式策略)中提取可复用的规则,并将其应用于新任务,同时支持单次任务内的修复和跨任务泛化[74]。
4.3 学习范式
学习维度描述了智能体能力如何随时间提升,涵盖瞬时上下文适应、永久权重更新以及可执行技能的非参数积累。早期智能体主要依赖上下文学习(提示中的示例与启发式方法),虽易于部署但效果短暂,且随着提示增长成本日益升高。这催生了智能体调优方法,即通过轨迹数据将有效行为内化至权重中:Agent-FLAN与FireAct基于智能体运行轨迹对模型进行微调,其中FireAct研究表明,“热”试错轨迹能超越纯提示方法,通过将长提示中的任务逻辑压缩为紧凑参数并降低推理成本[67, 158]。然而,有效的调优必须避免过度拟合表面形式,而非鲁棒的推理模式。
除监督微调外,可扩展的监督机制仍是发展瓶颈。RLAIF采用人工智能反馈生成偏好标签[159],使得如AgentRM与AgentPRM等过程级奖励模型能够在不依赖大量人工标注的情况下提供密集的逐步指导[68, 69]。这些信号支持在测试时对候选轨迹进行搜索与筛选,从而与人工设计的启发式方法形成互补。自改进流程进一步证明,智能体可通过挖掘失败案例并生成合成修正来自主提升性能,在网络智能体任务中取得显著增益[66]。最后,智能体无需权重更新亦能持续进化:Voyager维护着一个由成功代码片段构成的外部技能库,这些可执行技能可被检索与重组,从而在加速开放式学习的同时避免灾难性遗忘[64]。
5.从单智能体系统到多智能体系统
尽管单体智能体架构在独立运行时已展现出强大能力,但现实世界中的许多问题仍会超出单个模型的上下文处理范围、领域知识或认知容量。这推动了学术界向多智能体系统(MAS)的转向——在这种系统中,多个专业智能体通过协作完成工作流程。如图3所示,多智能体系统的效能很大程度上取决于其交互拓扑结构。参照[81]的分类,这些结构通常可分为三种主要模式:i) 链式或瀑布式,任务按固定顺序在智能体间传递,适用于刚性工作流;ii) 星型或中心辐射式,由中央控制器协调专业工作单元;iii) 网状或群集式,智能体以去中心化、动态化的方式交互,例如在头脑风暴场景中。
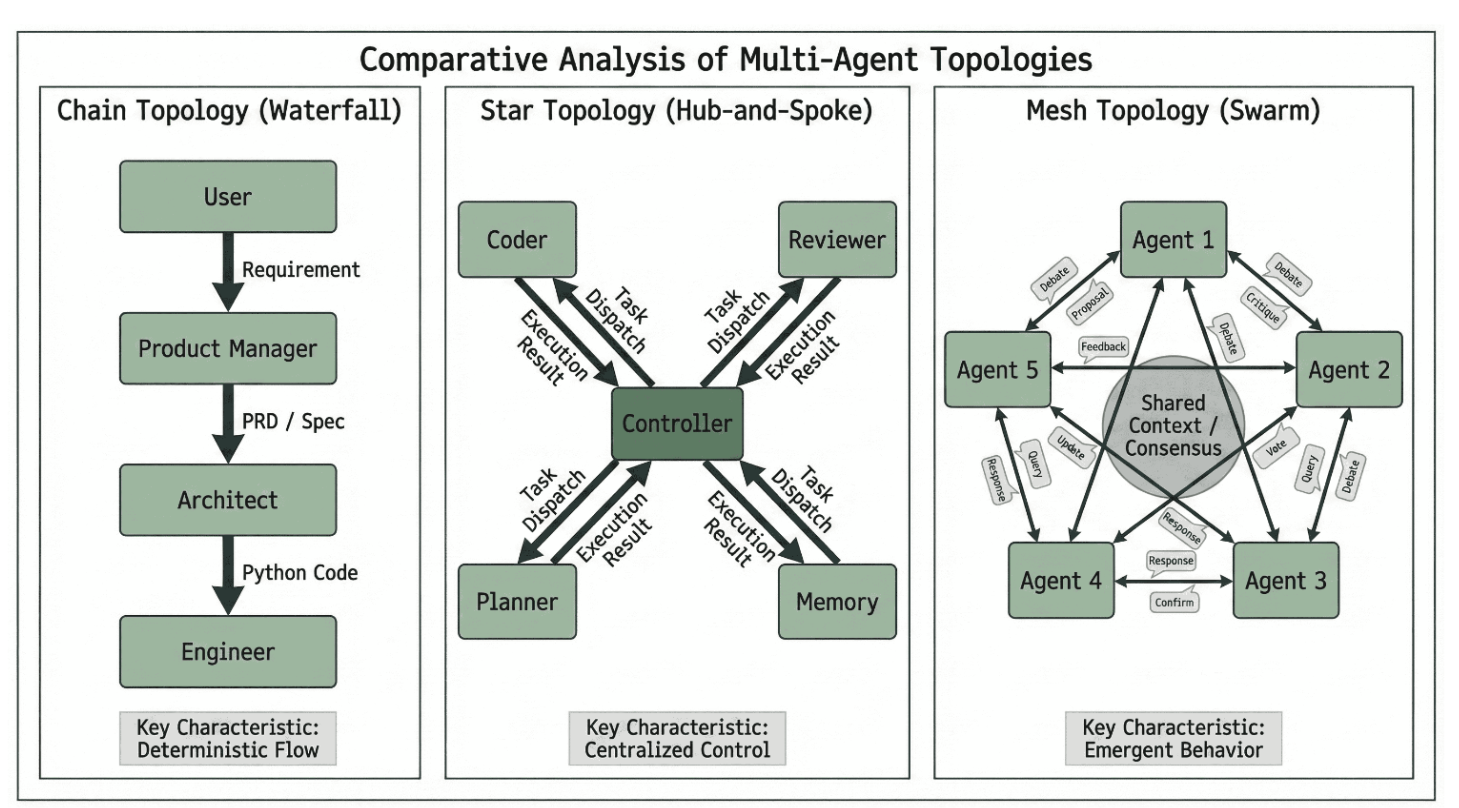
图3:多智能体系统中的通信拓扑结构。我们将协作模式归纳为三种主导架构:(左)链式拓扑,被MetaGPT用于通过顺序交接强制执行标准作业程序;(中)星型拓扑,被AutoGen采用,其中一个控制智能体向专业化工作者分发任务;(右)网状拓扑,用于"生成式智能体"等社会模拟中,以实现动态、非结构化的交互。
5.1 基于图的编排与流工程
行业的一个关键转变是从开放式的多智能体聊天循环转向显式工作流图。许多生产系统不再依赖通用管理器智能体在自由形式对话中决定后续操作,而是将工作流程建模为状态机——其中节点代表工具调用或大语言模型调用,边代表允许的状态转换。这种方法通常被称为流程工程,因为开发者负责设计控制结构,而智能体则在该结构框架内完成局部决策。
LangGraph 是一个代表性框架,它将这一理念操作化,通过将智能体执行视为具有显式状态持久化、检查点和受控循环的图遍历来实现[32]。这使得长周期行为更易于调试,也更容易与组织约束对齐,因为开发者可以在图中的特定节点插入防护节点、审批步骤和类型化状态更新。
OpenAI Swarm 提供了一个互补视角,强调轻量级智能体交接与协调专家行为的例程,其定位是可控协调模式的参考实现[33]。在实践中,这些模式符合一个更广泛的趋势:协调日益被设定为一个显式的控制器层,而大语言模型则专注于局部推理、工具参数化与恢复。基于图的设计也与安全性和评估自然衔接,因为图的边界定义了哪些操作是可能执行的,这有助于降低失控循环的发生频率与严重程度。
5.2 协作与角色扮演架构
驱动多智能体系统的核心机制是角色扮演。CAMEL框架[79]是早期具有影响力的范例,它通过引入初始提示来建立自主协作对话,具体方式是为智能体分配特定角色(例如股票交易员)并启动角色翻转式对话。CAMEL证明仅凭这些角色提示,智能体就能相互引导完成多步骤任务。然而,CAMEL采用简单的一对一网状拓扑结构,由于缺乏中央决策者,容易陷入低效循环。AutoGen[80]对这一理念进行了泛化,将智能体视为可对话实体,支持以更灵活的方式互联。开发者可以指定自定义交互图,许多实际部署采用星型拓扑结构:用户代理或管理智能体将子任务分派给工具与工作智能体,随后汇总输出结果。这种结构也支持人在回路监督,这对安全敏感应用至关重要。DyLAN[126]进一步突破了固定图结构的限制,提出动态智能体网络。它不采用静态交互模式,而是在每一步评估各智能体的贡献度,依据重要性分数选择协作伙伴。对当前任务无贡献的智能体会被静默,从而降低令牌使用量与成本,相关智能体则保持活跃。这种自适应路由机制能在复杂推理链中实现更高效、更聚焦的协作。
5.3 组织隐喻:链状拓扑结构
一类独特的多智能体系统子系统借鉴了人类企业组织的架构,通过实施标准作业程序来优化协作流程。
5.3.1 软件集群
MetaGPT [11] 通过将标准作业程序直接编码至智能体提示中,从而将这种方法形式化。通过分配产品经理、架构师和工程师等特定角色,MetaGPT 强制智能体生成标准化的交付物(如产品需求文档、API设计),这些交付物严格作为瀑布模型中下一环节智能体的输入。这实际上起到了智能体“操作系统”的作用,通过将非结构化的对话转化为严谨的工作流,有效降低了幻觉率。这一概念在ChatDev [84] 中得到了进一步例证,该框架模拟了整个软件公司的工作流程,智能体自我组织成设计、编码和测试等阶段,与单智能体编码相比,实现了30%的缺陷率降低。
5.3.2 分层验证
线性交接在上级代理出错时可能传播错误。为解决此问题,MAKER [85] 通过引入“交叉检验”阶段推进了组织隐喻。MAKER 的研究表明,通过将任务分解为细粒度步骤,并使用独立的“验证者”代理来质疑“工作者”代理的输出,系统能够执行百万步推理链且几乎无误差累积。这与 BOLAA [86] 的发现一致,该研究证明通过分配认知负荷,协调多个小型专业代理通常优于单一巨型模型。这种层级化安全机制可延伸至监督架构。OVON [88] 与良好养育框架 [89] 提出了“养育”拓扑结构,其中“审查者”代理持有专注于批判性检查与安全准则的独立系统指令。实证结果表明,在受控环境中,通过“监督者”过滤“子”代理输出可将幻觉率降低高达100%。
5.4 社会仿真与辩论:网状拓扑结构
链条结构优化效率,而网格拓扑优化创造性与多样性。在此类系统中,交互是去中心化的,使得涌现行为能够从智能体间的动态互动中产生。
5.4.1 对抗式辩论
辩证交互已被证实能提升推理表现。多智能体辩论研究[90]发现,允许多个LLM实例提出冲突答案并相互批评论证过程,能够促进向真理收敛。这种“心智社会”方法在自适应辩论[95]中得到进一步优化——智能体承担专门对抗性角色(如“魔鬼代言人”)以压力测试解决方案。近期研究将其扩展至通信博弈[96],智能体通过指称游戏对复杂分子描述达成共识。这种受限通信迫使智能体发展出精确的组合性语言,从而提升对新结构的泛化能力。
5.4.2 经济社会模拟
网格拓扑结构同样被用于复杂系统建模。TradingAgents [87] 复制了一个金融市场,其中专业智能体(风险管理者、技术交易员)就投资决策进行辩论。该研究表明,组织多样性会催生单一智能体无法模拟的涌现市场现象,例如价格发现。在更大规模上,Generative Agents [59] 展示了信息如何在模拟城镇的智能体群体中扩散。SocioVerse [103] 等近期工作将规模扩展至10,000多个智能体,以研究社会规范传播。这些"世界模型"——包括Genie 3 [104]和PAN [105]——使智能体能够在物理感知的潜在空间中模拟行动后果,然后再于现实中执行,从而弥合了内部推理与外部模拟之间的鸿沟。
表5展示了当前最先进的多智能体协作框架,对比了它们的结构刚性和冲突解决机制。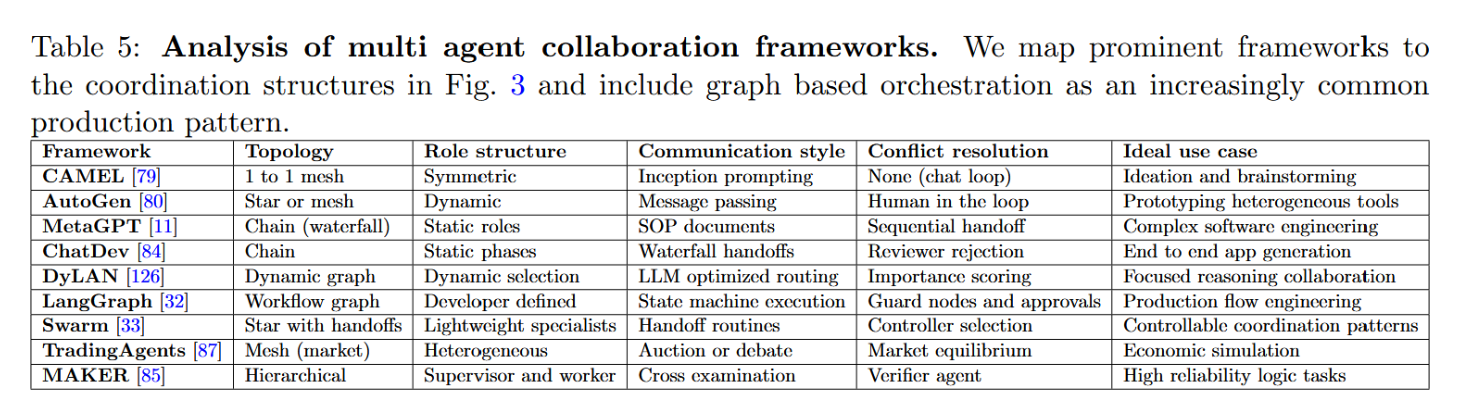
表5:多智能体协作框架分析。我们将主流框架映射至图3中的协调结构,并将基于图的编排作为日益常见的生产模式纳入分析。
6 环境与应用
智能体的定义不仅取决于其内部架构,也取决于其运作的环境。将大型语言模型的推理能力转化为可执行的行动,需要为不同领域建立专门的交互接口。我们将这些环境划分为数字领域(网络、操作系统、企业)、具身领域(机器人学)以及科学领域三大类。
6.1 数字代理:网络、操作系统与企业
现代知识工作主要在数字界面中进行,这使得网页与桌面自动化成为核心前沿领域。该领域已从被动检索转向开放环境中的主动执行。
6.1.1 网络智能体演进
网络代理的挑战性主要源于界面差异巨大且动态演变。Mind2Web和WebArena通过在功能性网站克隆(如GitLab、电商平台)上建立现实的长周期基准测试解决了这一问题[106, 107]。纯文本代理常因动态DOM变更或画布元素而失效,这推动了多模态方法的发展,例如WebVoyager利用截图推断视觉化UI结构[108]。然而,视觉代理引入了新的故障模式:环境干扰研究表明,模型可能过度关注无关的UI元素(广告、弹窗),导致操作错误,由此催生了任务感知裁剪和注意力掩码等鲁棒性增强方法[109]。
超越DOM解析的原生计算机使用
计算机使用界面通过将桌面/浏览器视为像素点与低级输入动作的组合,将这一理念推向更深层次。Anthropic为Claude开发的计算机使用工具开放了光标移动、点击、输入和屏幕状态读取功能[36, 37],降低了对脆弱的DOM提取和特定应用封装器的依赖。OpenAI的Operator系统同样基于屏幕截图和鼠标/键盘操作实现GUI控制[38]。这些能力拓展了可执行任务的范围,但也扩大了间接提示注入的攻击面,并增强了对敏感操作步骤进行沙盒隔离、权限管控和人工确认的需求。
6.1.2 从浏览器到操作系统
操作系统智能体必须管理文件、切换应用程序,并在跨多应用工作流中实现局部故障恢复。OSWorld基准测试正是对此类端到端桌面控制能力的评估,其最初研究指出,由于脆弱的语义落地和长周期错误累积,系统表现与人类性能存在巨大差距[14]。OSWorld Verified重新评估了该基准,以减少标注噪声并更好地区分语义落地错误与规划错误[100],从而显著提升了顶级系统的报告性能;例如,CoAct 1通过将计算机使用动作与代码验证-恢复动作相结合,报告了60.76%的成功率[101]。Windows Agent Arena通过聚焦Windows特有的层级结构和长周期可靠性研究[110]对此方向进行了补充,进一步强调进展既依赖于基础模型,也取决于周边控制模块(语义落地、验证、恢复),且应结合故障类别(不安全操作、重试、语义落地错误)进行报告,而非仅呈现平均成功率。
6.1.3 企业与软件工程
企业设置强调可靠性、治理机制与极长周期视野。SWE-Bench Pro将软件智能体评估扩展到仓库级任务,此类任务需要数小时的模拟工作,并揭示了上下文耗尽与搜索空间爆炸等瓶颈[13]。在商业智能领域,SQL智能体的工作展示了将复杂问题分解为多阶段查询规划的能力[111, 112]。然而实际部署不仅需要学术准确性:企业框架更强调可审计性(追踪日志)、数据治理和故障恢复能力——这些维度在AgentBench等通用基准测试中往往缺失[113, 114]。
6.2 具身智能体:机器人学与开放式游戏
具身人工智能代表了将语言锚定于物理现实的挑战,在此过程中行为会产生不可逆的后果,物理定律则规定了各种约束。该领域已从简单的指令跟随,发展为直接映射感知到运动控制的视觉-语言-行动模型。
6.2.1 游戏中的开放式学习
在挑战实体机器人之前,智能体已在开放式的游戏环境中展现出复杂行为。Voyager [64] 是具备终身学习能力的智能体典范。该智能体部署于《我的世界》环境中,能自主编写可执行的Python代码以掌握新技能(如战斗、采矿),将其存储于持久的“技能库”中,并在需要时调用这些技能以组合出复杂行为。与需要数百万次样本训练的强化学习智能体不同,Voyager通过自动课程设计探索世界,其游戏科技树进展速度比基线方法快15.3倍。这种“代码即策略”方法 [115] 证明了大语言模型能够借助编程抽象来推演长周期物理任务。
6.2.2 物理根基与可供性
将这一推理迁移至真实机器人需解决"实体化"问题——即确保智能体理解物理层面的可行性。早期方法如SayCan [116]采用大语言模型作为高层规划器,通过机器人功能可供性(例如"我能否实际拿起这个杯子?“)的学习价值函数对语义计划进行筛选。该范式已演变为端到端的视觉语言动作模型。VLA架构研究[117]收录了百余个近期模型,基于"多模态对齐”——即视觉编码器与语言标记如何直接融合为动作标记——构建了新的分类体系。
6.2.3 VLA模型
当前的前沿以Gemini Robotics 1.5 [118]等系统为代表。与Voyager的代码生成方式不同,Gemini 1.5为机器人引入了"原生思维",使其能够处理视频输入并在生成运动指令前,对任务进行内部推理(例如:“杯子是易碎的,我必须轻柔抓握”)。关键在于,它利用了跨具身学习,将一种机器人形态上学到的技能迁移到另一种形态上,这是迈向通用机器人"大脑"的关键一步。为了进一步增强鲁棒性,VLM-GroNav [119]将本体感知传感(力/扭矩反馈)与视觉相结合。通过将视觉语言模型的输出建立在物理反馈之上,机器人能够检测仅凭视觉会遗漏的危险(例如:湿滑地面),从而将导航成功率提升了50%。
6.2.4 自动驾驶
在自动驾驶这一高风险领域,智能体必须对交通规则与社会意图进行推理。Agent-Driver [120] 突破了传统黑盒神经网络的局限,引入了一个显式的推理引擎。该智能体利用交通规则的“认知记忆”与“思维链”规划器来解释其决策(例如,“因行人正进入人行横道而进行让行”),从而提升安全性与可解释性。然而,在车辆上运行这些庞大的模型在计算上是不可行的。为解决这一延迟瓶颈,DiMA [121] 提出了一个知识蒸馏框架。DiMA 将巨型多模态模型(如 GPT-4V)压缩为紧凑的、可边缘部署的模型,在保持推理逻辑的同时将参数减少 100 倍,这对于实时安全至关重要。
6.3 专业领域
虽然通用智能体备受瞩目,但许多近期影响正出现在专业垂直领域中,这些领域的智能体必须与严谨的工作流程集成,并满足安全、监管及可追溯性要求。
6.3.1 医疗保健与科学发现
在自然科学领域,智能体正从参考工具转变为研究伙伴。科学智能概述了智能体在假设生成、实验设计和分析等方面的角色[9],而全闭环系统展示了端到端的工作循环:智能体可自主提出假设、编写模拟程序代码、并在极少人工干预下解释结果[122]。研究综述还报告了其在化合物和纳米抗体发现中的应用,同时诸如ToolUniverse等平台通过管理器/编排器架构,协调对科学工具和数据库的访问[123, 124]。
在临床环境中,强调的重点是精准性、患者安全及法律问责。医疗智能体日益连接到电子健康记录系统,能够对纵向病史进行推理,并支持临床决策与行政工作流程[125,128]。《代理型医疗与心智守护》阐述了基因组学与影像学领域的工具链应用,以及通过移动传感器监测在审计追踪框架下实现治理与责任归属的主动式健康支持[129,130]。相应地,评估研究指出通用自然语言处理基准测试存在不足,呼吁建立结合病历与影像的医学专项测试,并验证其是否符合专业临床指南[131]。
6.3.2 金融、经济学与高级会话代理
在金融领域,能动型人工智能同时支持自动化与市场仿真。PyMarketSim提供了一个受控环境,使强化学习和大型语言模型智能体能够在真实订单簿中进行交易[132];金融推理研究表明,异质智能体行为能够复现流动性供给、微观结构套利及泡沫式动态等现象,这推动了基于智能体的仿真成为宏观经济研究的工具[133]。
会话式智能体以提升参与度和社交互动为优化目标,而非追求商业利润。主动式会话人工智能涵盖从反应式系统到深思型智能体的发展谱系,后者能够主动引入话题并追求长期目标(如教育、销售)[134]。共情语音代理将语音生成与情感建模相结合,使语调和节奏能适应用户状态;长期支持型智能体则旨在通过持续可靠的互动缓解用户的孤独感[135, 136]。由于实时对话对延迟高度敏感(即使亚秒级延迟也会削弱临场感),实际部署中强调采用蒸馏训练、推测解码等激进优化方案[137]。
7 评估与安全
随着智能体从封闭沙盒环境转向现实世界部署,评估方法必须超越BLEU或ROUGE等简单文本相似度指标。通过将性能指标[4]与企业部署要求[113]相结合,我们采用CLASSic框架[75],从成本、时延、准确性、安全性和稳定性这五个关键维度对该领域进行评估。
7.1 成本:效率权衡
高推理深度通常以显著的计算开销为代价[71]。如图4所示,分层架构(如ReAcTree)虽能最大化任务熟练度和推理深度,但与标准线性链或零样本提示相比,它们会导致令牌消耗呈指数级增长[70]。这种效率与智能的权衡,仍然是面向成本敏感型实时应用部署智能体时的关键瓶颈。
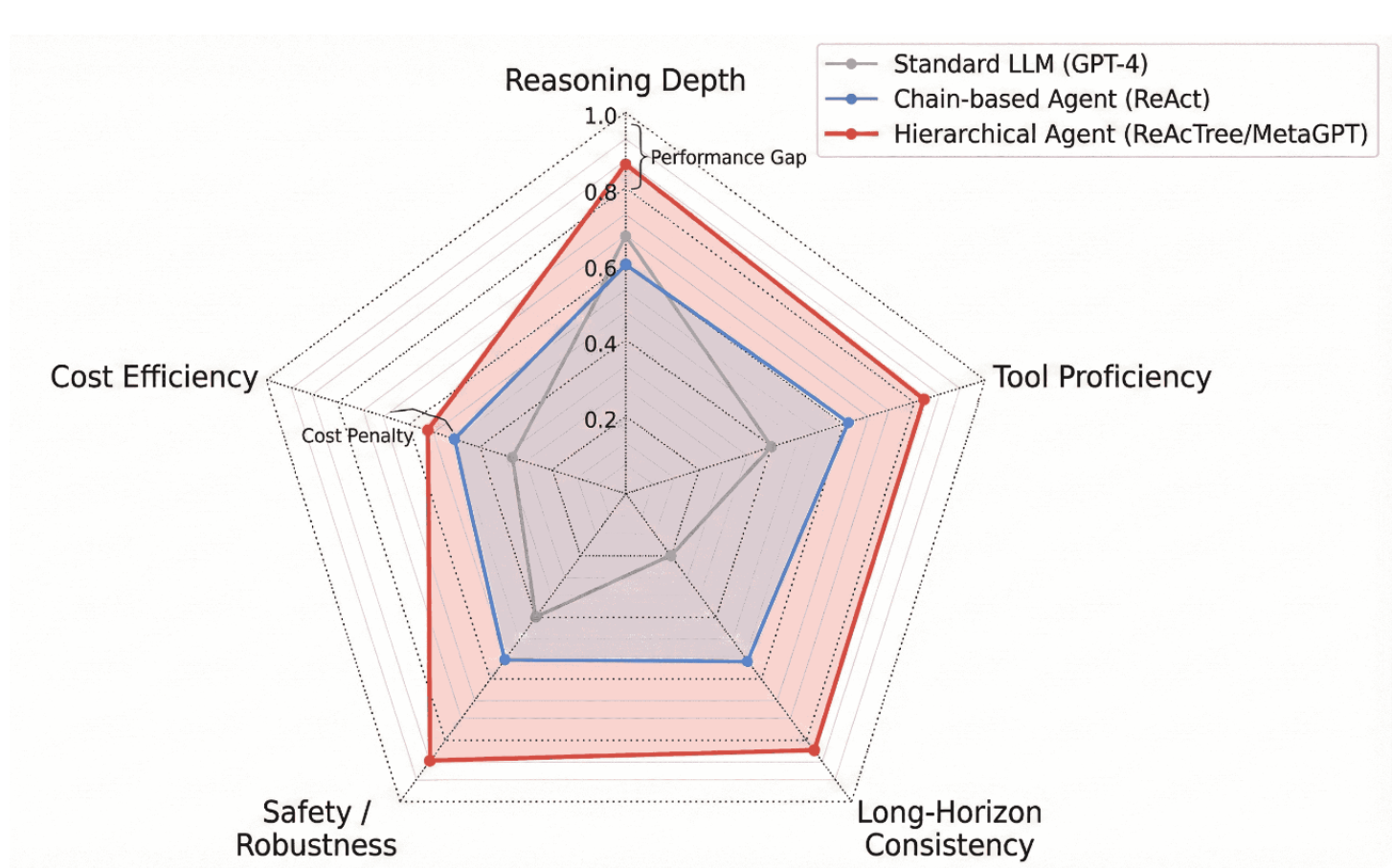
图4:多维度架构对比。我们在CLASSic维度上对架构进行比较。虽然分层智能体(红色)在推理深度与工具熟练度方面表现优异,但与标准大语言模型(灰色)相比,其产生了显著的代价惩罚与延迟。
7.2 延迟:现实世界中的约束条件
现实任务很少是瞬时完成的,因而需要进行严格的延迟评估。诸如Robotouille [138] 等异步基准测试表明,当任务涉及可变的时间延迟(例如需等待烹饪过程结束后才能执行下一步)时,智能体往往失败。研究显示,虽然同步智能体的任务成功率可达47%,但在异步环境下其性能会骤降至11%,这凸显出现有规划器严重缺乏时间感知能力。为在自动驾驶等安全关键领域缓解延迟问题(此类场景要求响应时间必须低于100毫秒),DiMA [121] 提出了知识蒸馏方法。该技术将GPT-4V等巨型多模态规划器压缩成紧凑、可部署于边缘设备的模型,在保留推理逻辑的同时将参数量减少百倍,从而在不牺牲安全逻辑的前提下解决了延迟约束。
7.3 准确性:能力差距与饱和
仅凭静态问答不足以捕捉智能体的准确性:当任务需要工具使用、状态追踪和长程恢复时,成功率可能崩溃,这既反映了基础模型的局限性,也体现了端到端架构选择(记忆、编排、 grounding 和权限控制)的影响。GAIA 在人类易于处理但需要多步分解、工具使用和验证的通用助手任务上凸显了这一差距[39]。在桌面控制领域,OSWorld Verified 减少了评估噪声,并在更可靠的协议下展现出更强的性能[100];CoAct 1 exemplifies 一种现代设计,将计算机使用操作与编码即行动相结合,在执行过程中验证和修复步骤[101]。在软件工程中,SWEbench Verified 减少了模糊性和脆弱测试[40,41],而 SWE-bench Pro 则推动向仓库规模、长程任务发展,其中上下文管理和搜索控制成为核心瓶颈[13]。针对策略约束下的工具使用,τ -bench 评估零售和航空等领域的多轮交互[43]。FrontierMath 以低污染度瞄准硬顶限数学推理,强调推理时间内的逻辑推演及验证器引导方法[42]。因此,现代智能体评估不仅日益报告平均成功率,还纳入计算预算、多次运行方差和故障严重程度分布,使准确性评估与真实任务轨迹中的 CLASSic 权衡保持一致。AgentBench 在多领域环境中评估智能体[114],而 MultiAgentBench(MARBLE)则衡量涌现的多智能体行为,如谈判效率和共识形成[82]。
7.4 安全性:信任鸿沟与提示注入
安全性是部署智能体系统的首要障碍:一旦将大型语言模型连接至可执行工具(文件I/O、代码执行、企业API),提示词注入攻击便可覆盖既定目标,使智能体转变为“困惑代理人”[139]。攻击方式既可直接通过用户输入实现,也可间接通过工具使用过程中接触的非受信内容(网页、文档、工单、工具输出)发起。在计算机使用场景等高带宽观察通道中,风险尤为突出——智能体通过解析屏幕截图并执行底层鼠标/键盘操作[37, 38]。标准化连接层(如MCP)进一步强化了对集成边界治理的需求,包括许可名单、身份验证与审计日志[34, 35]。
仅靠提示词防御是脆弱的:PromptArmor虽能降低模型遵循注入指令的可能性[140],但适应性攻击者可通过构造间接注入绕过静态防护[141]。因此,稳健的安全防护日益成为一个系统性问题:需要采用分层缓解措施,例如约束工具权限、隔离沙箱环境、对敏感操作要求显式用户确认,以及通过独立的策略/审计组件在执行前验证计划,同时辅以生产环境中的运行监控与干预机制,以限制不安全行为的影响范围[143]。
7.5 稳定性:失效模式分析
最终,“稳定性”指系统在重复运行中的方差[73]及其对微小扰动的恢复能力。在像LLM智能体这样的随机系统中,简单的“成功率”指标常常掩盖关键可靠性问题。一项针对企业级智能体的框架研究[113]指出,严格评估必须包含故障模式分析,不仅要量化智能体成功的频率,更要对其故障的严重程度进行分布分析,从而区分良性超时与灾难性数据泄露。这在受监管领域尤为重要。医疗健康应用研究[131]强调,智能体必须展现高合规稳定性,确保无论提示词表述或随机采样温度如何变化,临床决策始终与医疗指南保持一致。因此,未来的基准测试必须同时报告标准差与最坏故障场景以及平均性能,方能真实反映智能体的就绪程度。
8 挑战与未来方向
尽管智能体架构已迅速普及,该领域仍处于发展初期。虽然智能体在受控的沙箱环境中能展现卓越性能,但其在无约束现实场景中的部署仍受限于可靠性、效率与对齐性等根本缺陷。本节将综合梳理当前关键的开放挑战,并展望未来研究的可行方向。
8.1 幻觉的实际表现与错误传播
智能体式人工智能最普遍的挑战在于“行动幻觉”问题。聊天机器人回复中的事实性错误仅具误导性,但幻觉行为——例如调用不存在的API接口或删除错误文件——可能导致不可逆的系统故障。当检索组件提供无关上下文时[144],智能体常会失效,致使规划器生成有缺陷的执行步骤。此外,在ReAct等多步推理循环中,早期步骤的单一错误会向下游传播,引发“级联故障”。未来的研究必须聚焦于构建稳健的错误恢复机制,或可借鉴SelfCheckGPT[145]等技术,在执行前验证推理步骤。
8.2 无限循环与智能体瘫痪
自主智能体经常陷入重复循环,即在未调整策略的情况下持续重试失败动作。WebArena等基准测试报告显示,在长周期任务中成功率较低(常低于15%),部分原因在于智能体无法识别自身陷入局部最优状态。尽管Reflexion等架构尝试通过语言反馈缓解此问题,智能体在"适时放弃"或恰当寻求人类帮助方面仍有困难。开发能让智能体评估自身进展并中断无效循环的"元认知"模块,是一个关键的研究方向。
8.3 延迟与计算成本
从单智能体到多智能体系统的转变带来了显著的计算开销。依赖广泛辩论或树搜索的架构(例如ToT[26])需要为单个用户查询发起多次LLM推理调用,这种延迟对于实时应用而言无法接受。亟需将“系统2”思维提炼为高效的“系统1”式反射[10]。对ReWOO[146]的研究通过分离规划与执行提供了一条可行路径,但要实现智能体式AI的大规模经济可行部署,仍需进一步优化。
8.4 人机对齐与社会规范
随着智能体自主性日益增强,确保其遵循人类价值观与社会规范变得至关重要。仅以任务完成为优化目标的智能体可能出现极端行为——例如为达成"社交网络拓展"目标而向用户联系人列表发送垃圾信息。近期关于社会对齐智能体的研究[148]指出,智能体训练不仅应关注任务成功率,更需遵循社会契约与安全约束。这要求超越简单的人类反馈强化学习(RLHF),转向宪法人工智能框架,使智能体能够内在地尊重边界规范,而无需针对每个边缘情况提供明确指令。
8.5 迈向开放式学习
当前代理模型大多呈静态特性,部署后其核心能力无法持续演化。实现具备开放式自我改进能力的智能体已成为重要前沿方向。OMNI [151] 提出了能够自主生成训练课程的系统,通过探索新任务来拓展技能边界。这与Voyager [64] 的愿景相契合,共同指向这样一个未来:智能体将作为终身学习者自主运行,在无需人工干预的情况下持续获取、优化并共享新技能。
8.6 理论极限与优化
尽管取得了实证上的成功,智能体人工智能的理论边界仍未得到充分研究。OMNI [151] 指出,智能体若要实现真正的自主,必须具备内在动机函数以生成自身的学习进程,而这一特性在当前的标准大语言模型中尚不存在。此外,优化问题仍是瓶颈;TALM [150] 以及主动检索的相关研究 [144] 凸显了迭代检索带来的延迟成本。未来的架构可能需要整合内省能力 [149],以平衡昂贵的外部工具调用与更经济的内部自省之间的权衡。
9 结论
我们对智能体式人工智能生态的研究表明,核心设计问题正从“如何对模型进行提示”转向“如何编程与控制完整的智能体系统”。这一范式转换在三个维度上体现得尤为明显:
- 推理:系统架构已从ReAct等短视的单循环求解器,演进为分层与基于搜索的体系,并日益转向可在可控计算预算下于推理时内化部分搜索与回溯过程的推理模型。
- 行动:交互范式从受限的API调用扩展到以代码作为行动及计算机操作行为,使得智能体既能调用结构化工具API,也能操作任意图形界面,同时验证与恢复机制已成为首要设计需求。
- 协作:多智能体系统正从非结构化的聊天循环转向可控的工作流图与显式交接模式,通过流程工程提升可观测性、可调试性与安全性。
10.引用文献
- [1] S. Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models,” arXiv preprint arXiv:2210.03629, 2023.
- [2] J. W. Choi et al., “ReAcTree: Hierarchical LLM Agent Trees with Control Flow for Long-Horizon Task Planning,” arXiv preprint arXiv:2511.02424, 2025.
- [3] X. Wang et al., “Executable Code Actions Elicit Better LLM Agents,” International Conference on Machine Learning (ICML), 2024.
- [4] A. Khamis, M. Elshakankiri, & H. Elsayed, “Agentic AI Systems: Architecture and Evaluation Using a Frictionless Parking Scenario,” IEEE Access, vol. 13, p. 11083588, 2025.
- [5] M. Abou Ali, F. Dornaika, & J. Charafeddine, “Agentic AI: a comprehensive survey of architectures, applications, and future directions,” Artificial Intelligence Review, vol. 59, no. 1, p. 11, 2025.
- [6] N. R. Jennings, “On agent-based software engineering,” Artificial Intelligence, vol. 117, no. 2, pp. 277–296, 2000.
- [7] F. Piccialli et al., “AgentAI: A Comprehensive Survey on Autonomous Agents in Distributed AI for Industry 4.0,” Expert Systems with Applications, p. 128404, 2025.
- [8] J. Yang et al., “SWE-agent: Agent-Computer Interfaces Enable Automated Software Engineering,” arXiv preprint arXiv:2405.15793, 2024.
- [9] Y. Ren et al., “Towards Scientific Intelligence: A Survey of LLM-based Scientific Agents,” arXiv preprint arXiv:2411.13837, 2025.
- [10] Y. Li et al., “Personal LLM Agents: Insights and Survey about the Capability, Efficiency and Security,” arXiv preprint arXiv:2401.05459, 2024.
- [11] S. Hong et al., “MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework,” International Conference on Learning Representations (ICLR), 2024.
- [12] Y. Yang et al., “Navigating the Risks: A Survey of Security, Privacy, and Ethics Threats in LLMBased Agents,” arXiv preprint arXiv:2411.09523, 2024.
- [13] X. Deng et al., “SWE-Bench Pro: Can AI Agents Solve Long-Horizon Software Engineering Tasks?,” arXiv preprint arXiv:2509.16941, 2025. [14] T. Xie et al., “OSWorld: Benchmarking Multimodal Agents for Open-Ended Tasks in Real Computer Environments,” arXiv preprint arXiv:2404.07972, 2025.
- [15] L. Busoniu, R. Babuska, & B. De Schutter, “A comprehensive survey of multiagent reinforcement learning,” IEEE Transactions on Systems, Man, and Cybernetics, 2008.
- [16] G. Mialon et al., “Augmented Language Models: a Survey,” Transactions on Machine Learning Research, 2023.
- [17] P. Li et al., “A Review of Prominent Paradigms for LLM-Based Agents: Tool Use (Including RAG), Planning, and Feedback Learning,” arXiv preprint arXiv:2406.05804, 2025.
- [18] L. Wang et al., “A Survey on Large Language Model based Autonomous Agents,” Frontiers of Computer Science, vol. 18, no. 6, 2024.
- [19] S. Hao et al., “Reasoning with Language Model is Planning with World Model,” arXiv preprint arXiv:2305.14992, 2023.
- [20] A. Li et al., “Agent-oriented planning in multi-agent systems,” arXiv preprint arXiv:2410.02189, 2024.
- [21] A. Kumar, “Building Autonomous AI Agents based AI Infrastructure,” International Journal of Computer Trends and Technology, vol. 72, no. 11, pp. 116–125, 2024.
- [22] J. Luo et al., “Large language model agent: A survey on methodology, applications and challenges,” arXiv preprint arXiv:2503.21460, 2025.
- [23] Y. Cheng et al., “Exploring Large Language Model based Intelligent Agents,” arXiv preprint arXiv:2403.00000, 2024.
- [24] Y. Qu et al., “Tool Learning with Large Language Models: A Survey,” arXiv preprint arXiv:2304.08354, 2025.
- [25] J. Wei et al., “Chain-of-Thought Prompting Elicits Reasoning in Large Language Models,” Advances in Neural Information Processing Systems (NeurIPS), 2022.
- [26] S. Yao et al., “Tree of Thoughts: Deliberate Problem Solving with Large Language Models,” Advances in Neural Information Processing Systems (NeurIPS), 2024.
- [27] Y. Chen et al., “GoalAct: Enhancing LLM-Based Agents via Global Planning and Hierarchical Execution,” arXiv preprint arXiv:2410.11964, 2025.
- [28] OpenAI, “Learning to reason with LLMs,” 2024. [Online]. Available: https://openai.com/index/learning-to-reason-with-llms/
- [29] OpenAI, “o1 system card,” 2024. [Online]. Available: https://openai.com/index/openai-o1-systemcard/
- [30] OpenAI, “OpenAI o3 and o4-mini system card,” 2025. [Online]. Available: https://openai.com/index/o3-o4-mini-system-card/
- [31] C. Snell, J. Lee, K. Xu, & A. Kumar, “Scaling LLM test time compute optimally can be more effective than scaling model parameters,” arXiv preprint arXiv:2408.03314, 2024.
- [32] LangChain AI, “LangGraph: building language agents as graphs,” 2024. [Online]. Available: https://github.com/langchain-ai/langgraph
- [33] OpenAI, “Swarm,” 2024. [Online]. Available: https://github.com/openai/swarm
- [34] Anthropic, “Introducing the Model Context Protocol,” 2024. [Online]. Available: https://www.anthropic.com/news/model-context-protocol
- [35] Anthropic, “Model Context Protocol specification,” 2024. [Online]. Available: https://modelcontextprotocol.io/specification
- [36] Anthropic, “Developing a computer use model,” 2024. [Online]. Available: https://www.anthropic.com/news/developing-computer-use
- [37] Anthropic, “Computer use tool documentation,” [Online]. Available: https://platform.claude.com/docs/en/agents-and-tools/tool-use/computer-use-tool
- [38] OpenAI, “Introducing Operator,” 2025. [Online]. Available: https://openai.com/index/introducingoperator/ [39] G. Mialon et al., “GAIA: a benchmark for general AI assistants,” arXiv preprint arXiv:2311.12983, 2023.
- [40] OpenAI, “Introducing SWE bench Verified,” 2024. [Online]. Available: https://openai.com/index/introducing-swe-bench-verified/
- [41] SWE bench, “SWE bench leaderboards,” 2024. [Online]. Available: https://www.swebench.com/
- [42] Epoch AI, “FrontierMath: a benchmark for evaluating advanced mathematical reasoning in AI,” arXiv preprint arXiv:2411.04872, 2024.
- [43] J. Wu et al., “τ -bench: a benchmark for tool agent user interaction in real world domains,” arXiv preprint arXiv:2406.12045, 2024.
- [44] N. Shinn et al., “Reflexion: Language Agents with Verbal Reinforcement Learning,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [45] R. Aksitov et al., “REST Meets ReAct: Self-Improvement for Multi-Step Reasoning LLM Agent,” arXiv preprint arXiv:2312.10003, 2024.
- [46] Z. Zhou et al., “AgentCoMa: A Compositional Benchmark Mixing Commonsense and Mathematical Reasoning,” arXiv preprint arXiv:2508.19988, 2025.
- [47] H. Furuta et al., “Language Model Agents Suffer from Compositional Decision Making,” arXiv preprint arXiv:2410.15037, 2024.
- [48] Y. Sun, H. Wang, Y. Yao, & Z. Gong, “Can LLM-Reasoning Models Replace Classical Planning?,” arXiv preprint arXiv:2412.10395, 2025.
- [49] H. Qu & T. Xie, “Teaching Language Model Agents How to Self-Improve,” arXiv preprint arXiv:2410.12468, 2024.
- [50] E. Acikgoz et al., “Self-Improving LLM Agents at Test-Time,” arXiv preprint arXiv:2412.10029, 2025.
- [51] Z. Liu et al., “Proactive Conversational Agents with Inner Thoughts and Empathy,” arXiv preprint arXiv:2405.19464, 2024.
- [52] T. Schick et al., “Toolformer: Language Models Can Teach Themselves to Use Tools,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [53] D. Hendrycks et al., “Measuring Massive Multitask Language Understanding,” International Conference on Learning Representations (ICLR), 2021.
- [54] K. Cobbe et al., “Training Verifiers to Solve Math Word Problems,” arXiv preprint arXiv:2110.14168, 2021.
- [55] Z. Yang et al., “HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering,” EMNLP, 2018.
- [56] M. Shridhar et al., “ALFWorld: Aligning Text and Embodied Environments for Interactive Learning,” International Conference on Learning Representations (ICLR), 2020.
- [57] S. G. Patil, T. Zhang, X. Wang, & J. E. Gonzalez, “Gorilla: Large Language Model Connected with Massive APIs,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [58] A. Vuddanti et al., “PALADIN: Self-Correcting Language Model Agents to Cure Tool-Failure Cases,” arXiv preprint arXiv:2308.05201, 2025.
- [59] J. S. Park et al., “Generative Agents: Interactive Simulacra of Human Behavior,” Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology (UIST), 2023.
- [60] S. Hong et al., “Enhancing Memory Retrieval in Generative Agents through LLM-Trained Cross Attention Networks,” arXiv preprint arXiv:2410.15693, 2025.
- [61] W. Zhong et al., “MemoryBank: Enhancing Large Language Models with Long-Term Memory,” arXiv preprint arXiv:2305.10250, 2024.
- [62] C. Hu et al., “ChatDB: Augmenting LLMs with Databases as their Symbolic Memory,” arXiv preprint arXiv:2306.03901, 2024.
- [63] Z. Xi et al., “The Rise and Potential of Large Language Model Based Agents: A Survey,” Science China Information Sciences, vol. 68, no. 2, p. 121101, 2025.
- [64] G. Wang et al., “Voyager: An Open-Ended Embodied Agent with Large Language Models,” Transactions on Machine Learning Research (TMLR), 2024.
- [65] A. Madaan et al., “Self-Refine: Iterative Refinement with Self-Feedback,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [66] A. Patel et al., “Large language models can self-improve at web agent tasks,” arXiv preprint arXiv:2405.20309, 2024.
- [67] Z. Chen et al., “Agent-FLAN: Designing data and methods of effective agent tuning for large language models,” arXiv preprint arXiv:2403.12881, 2024.
- [68] Y. Xia et al., “AgentRM: Enhancing agent generalization with reward modeling,” arXiv preprint arXiv:2502.18407, 2025.
- [69] Z. Xi et al., “AgentPRM: Process Reward Models for LLM Agents via Step-Wise Promise and Progress,” arXiv preprint arXiv:2511.08325, 2025.
- [70] AI CERTs Team, “RE-Bench: Economic Efficiency Factors in Agent Evaluation,” AI CERTs Technical Report, 2025.
- [71] B. Cottier et al., “LLM Inference Prices Have Fallen Rapidly but Unequally Across Tasks,” Epoch AI, 2025.
- [72] T. Zhang et al., “When Hallucination Costs Millions: Benchmarking AI Agents in High-Stakes Adversarial Financial Markets,” arXiv preprint, 2025.
- [73] Scale AI Research, “Smoothing Out LLM Variance for Reliable Enterprise Evals,” Scale AI Technical Blog, 2025.
- [74] A. Zhao et al., “Expel: LLM Agents are Experiential Learners,” arXiv preprint arXiv:2308.10144, 2023.
- [75] M. Wornow et al., “Top of the CLASS: Benchmarking LLM Agents on Real-World Enterprise Tasks,” ICLR 2025 Workshop on Trustworthy LLMs, 2025.
- [76] X. Zhao et al., “MemInsight: Autonomous Memory Augmentation for LLM Agents,” arXiv preprint arXiv:2503.21760, 2025.
- [77] Z. Ma et al., “MemAgent: Reshaping Long-Context LLM with Multi-Conversation Reinforcement Learning,” arXiv preprint arXiv:2507.02259, 2025.
- [78] Y. Ge et al., “Chain-of-Agents: Large Language Models Collaborating on Long-Context Tasks,” arXiv preprint arXiv:2406.02818, 2025.
- [79] G. Li et al., “CAMEL: Communicative Agents for ’Mind’ Exploration,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [80] C. Wang et al., “AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework,” Conference on Language Modeling (COLM), 2024.
- [81] H. Tran et al., “Multi-Agent Collaboration Mechanisms: A Survey of LLMs,” arXiv preprint arXiv:2501.06322, 2025.
- [82] X. Zhu et al., “MultiAgentBench: Evaluating the Collaboration and Competition of LLM Agents,” arXiv preprint arXiv:2405.16960, 2025. [83] Y. Zhang et al., “Towards Efficient LLM Grounding for Embodied Multi-Agent Collaboration,” arXiv preprint arXiv:2405.14314, 2025.
- [84] C. Qian et al., “ChatDev: Communicative Agents for Software Development,” arXiv preprint arXiv:2307.07924, 2024.
- [85] E. Meyerson et al., “Solving a Million-Step LLM Task with Zero Errors,” arXiv preprint arXiv:2511.09030, 2025.
- [86] Z. Liu et al., “BOLAA: Benchmarking and Orchestrating LLM-Augmented Autonomous Agents,” arXiv preprint arXiv:2308.05960, 2024.
- [87] Y. Xiao, Y. Cao, H. Zhang, & W. Liu, “TradingAgents: Multi-Agent LLM Financial Trading Framework,” arXiv preprint arXiv:2409.12857, 2024.
- [88] D. Gosmar & D. A. Dahl, “Hallucination Mitigation with Agentic AI NLP-Based Frameworks,” Available at SSRN 5086241, 2025.
- [89] B. Kwartler, Y. Zhang, Z. Liu, & H. Wang, “Good Parenting is All You Need: Multi-Agentic LLM Hallucination Mitigation,” arXiv preprint arXiv:2410.14262, 2024.
- [90] Y. Du et al., “Improving Factuality and Reasoning in Language Models through Multiagent Debate,” arXiv preprint arXiv:2305.14325, 2024.
- [91] C. Zhang et al., “AppAgent: Multimodal Agents as Smartphone Users,” arXiv preprint arXiv:2312.13771, 2024.
- [92] B. Zheng et al., “GPT-4V(ision) is a Generalist Web Agent, if Grounded,” Proceedings of the 41st International Conference on Machine Learning (ICML), 2024.
- [93] R. Huang et al., “AudioGPT: Understanding and Generating Speech, Music, Sound, and Talking Head,” Proceedings of the AAAI Conference on Artificial Intelligence, vol. 38, no. 21, 2024.
- [94] Y. Hong et al., “3D-LLM: Injecting the 3D World into Large Language Models,” Advances in Neural Information Processing Systems (NeurIPS), vol. 36, 2024.
- [95] Y. Zhang et al., “Adaptive Heterogeneous Multi-Agent Debate for Large Language Models,” arXiv preprint arXiv:2410.13456, 2025.
- [96] K. M. Jablonka, P. Schwaller, A. Ortega-Guerrero, & B. Smit, “Compositional Communication with LLMs and Reasoning about Chemical Structures,” Nature Machine Intelligence, 2024.
- [97] OpenAI, “GPT-5.1 Codex Max system card,” 2025. [Online]. Available: https://openai.com/index/gpt-5-1-codex-max-system-card/
- [98] Google, “Introducing Gemini 3: Our most capable model family yet,” 2025. [Online]. Available: https://blog.google/technology/google-deepmind/gemini-3/
- [99] Anthropic, “Claude Haiku 4.5 system card,” 2025. [Online]. Available: https://assets.anthropic.com/m/37cf170ec9d01f5e/original/Claude-Haiku-4-5-System-Card.pdf
- [100] XLANG Lab, “Introducing OSWorld Verified,” 2025. [Online]. Available: https://xlang.ai/blog/osworld-verified
- [101] X. Xin et al., “CoAct 1: Computer using agents with coding as actions,” 2025. [Online]. Available: https://linxins.net/coact/
- [102] C. Xu et al., “MemGPT: Towards LLMs as operating systems,” arXiv preprint arXiv:2310.08560, 2023.
- [103] Y. Zhang et al., “SocioVerse: A World Model for Social Simulation via Multi-Agent Systems,” arXiv preprint arXiv:2410.14567, 2025.
- [104] DeepMind Team, “Genie 3: A New Frontier for World Models,” Technical Report, 2025.
- [105] Z. Zhang et al., “PAN: A World Model for General, Interactable, and Long-Horizon Agents,” arXiv preprint arXiv:2410.15678, 2025.
- [106] X. Deng et al., “Mind2Web: Towards a Generalist Agent for the Web,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [107] S. Zhou et al., “WebArena: A Realistic Web Environment for Autonomous Agents,” Advances in Neural Information Processing Systems (NeurIPS), 2023.
- [108] H. He et al., “WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models,” arXiv preprint arXiv:2401.13919, 2024. [109] K. Ma et al., “Multimodal LLM Agents are Susceptible to Environmental Distractions,” arXiv preprint arXiv:2410.14890, 2025.
- [110] R. Wu et al., “Windows Agent Arena: Evaluating Multi-Modal OS Agents at Scale,” arXiv preprint arXiv:2409.08264, 2025.
- [111] Y. Chen et al., “LLM-Powered SQL Agents for BI & Data Analytics,” arXiv preprint arXiv:2408.06259, 2025.
- [112] M. Chernyshevich et al., “Multi-hop LLM Agent for Tabular Question Answering,” arXiv preprint arXiv:2405.13678, 2025.
- [113] Y. Wang et al., “A Multi-Dimensional Framework for Evaluating Enterprise AI Agents,” arXiv preprint arXiv:2410.15890, 2025.
- [114] X. Liu et al., “AgentBench: Evaluating LLMs as Agents,” International Conference on Learning Representations (ICLR), 2024.
- [115] J. Liang et al., “Code as Policies: Language Model Programs for Embodied Control,” International Conference on Robotics and Automation (ICRA), 2023.
- [116] M. Ahn et al., “Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,” Conference on Robot Learning (CoRL), 2022.
- [117] S. Din et al., “Vision Language Action Models in Robotic Manipulation: A Systematic Review,” arXiv preprint arXiv:2408.14993, 2025.
- [118] Google DeepMind Team, “Gemini Robotics 1.5: AI Agents into the Physical World,” Technical Report, 2025.
- [119] M. Elnoor et al., “Robot Navigation Using Physically Grounded Vision-Language Models,” arXiv preprint arXiv:2407.14845, 2024.
- [120] J. Mao et al., “Agent-Driver: A Language Agent for Autonomous Driving,” arXiv preprint arXiv:2311.01135, 2024.
- [121] S. Hegde et al., “Distilling Multi-modal Large Language Models for Autonomous Driving,” arXiv preprint arXiv:2410.16234, 2025.
- [122] D. Zhou et al., “Autonomous Agents for Scientific Discovery,” arXiv preprint arXiv:2410.13567, 2025.
- [123] T. So et al., “Scientific Discoveries by LLM Agents,” Nature, 2025.
- [124] Kempner Institute et al., “ToolUniverse: Building AI Agents for Science,” arXiv preprint arXiv:2410.14678, 2025.
- [125] S. Wang et al., “A Survey of LLM-based Agents in Medicine,” arXiv preprint arXiv:2404.11585, 2025.
- [126] Z. Liu et al., “Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization,” Proceedings of the Conference on Language Modeling (COLM), 2024.
- [127] A. Zhou et al., “Language Agent Tree Search Unifies Reasoning, Acting, and Planning in Language Models,” International Conference on Machine Learning (ICML), 2024.
- [128] Nature Digital Medicine et al., “Healthcare Agent: Eliciting the Power of LLMs,” Nature Digital Medicine, 2025.
- [129] K. Yuan et al., “Agentic Large Language Models for Healthcare,” arXiv preprint arXiv:2410.15890, 2025.
- [130] ACM et al., “MindGuard: Autonomous LLM Agent for Mental Health Using Mobile Sensor Data,” ACM Proceedings, 2025.
- [131] Y. Chen et al., “Evaluating Large Language Models and Agents in Healthcare,” arXiv preprint arXiv:2409.14567, 2025.
- [132] A. Mascioli, Z. Li, H. Zhang, & Y. Wang, “A Financial Market Simulation Environment for Trading Agents,” ICAIF, 2024.
- [133] A. Lopez-Lira et al., “Can Large Language Models Trade? Testing Financial Reasoning,” arXiv preprint arXiv:2408.14234, 2025.
- [134] ACM et al., “Proactive Conversational AI: A Comprehensive Survey,” arXiv preprint arXiv:2405.13987, 2025.
- [135] IJISAE et al., “Empathetic Intelligence: LLM-Based Conversational AI Voice Agent,” IJISAE, 2024.
- [136] S. Alotaibi et al., “The Role of Conversational AI Agents in Providing Support for Isolated Individuals,” arXiv preprint arXiv:2410.14890, 2024.
- [137] RJPN et al., “Generative AI for Real-Time Conversational Agents,” arXiv preprint arXiv:2410.15234, 2024.
- [138] G. Gonzalez-Pumariega et al., “Robotouille: An Asynchronous Planning Benchmark for LLM Agents,” arXiv preprint arXiv:2502.05227, 2025.
- [139] Y. Liu et al., “Formalizing and Benchmarking Prompt Injection Attacks and Defenses,” arXiv preprint arXiv:2310.12815, 2023.
- [140] Y. Chen et al., “PromptArmor: Simple yet Effective Prompt Injection Defenses,” arXiv preprint arXiv:2507.15219, 2025.
- [141] H. Zhan et al., “Adaptive Attacks Break Defenses Against Indirect Prompt Injection,” arXiv preprint arXiv:2503.00061, 2025.
- [142] Y. Zhang et al., “Mitigating Spatial Hallucination in LLMs,” arXiv preprint arXiv:2410.13567, 2025.
- [143] AWS, “Reducing hallucinations in large language models with custom intervention using Amazon Bedrock Agents,” 2024.
- [144] Z. Jiang et al., “Active Retrieval-Augmented Generation for Knowledge-Intensive NLP,” arXiv preprint arXiv:2305.06983, 2023.
- [145] P. Manakul, A. Liusie, & M. J. F. Gales, “SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection,” Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023.
- [146] B. Xu et al., “ReWOO: Decoupling Reasoning from Observations for Efficient Augmented Language Models,” arXiv preprint arXiv:2305.18323, 2023.
- [147] Y. Zhang et al., “Personal Large Language Model Agents: A Case Study on Tailored Travel Planning,” arXiv preprint arXiv:2401.05459, 2024.
- [148] I. Gabriel et al., “Socially Aligned Agents,” arXiv preprint arXiv:2404.13789, 2024.
- [149] L. Chen et al., “Introspective Tips: Large Language Models with Self-Reflection,” arXiv preprint arXiv:2305.11598, 2023.
- [150] A. Parisi, Y. Zhao, & N. Fiedel, “TALM: Tool Augmented Language Models,” arXiv preprint arXiv:2205.12255, 2022.
- [151] J. Zhang et al., “OMNI: Open-endedness via Models of human Notions of Interestingness,” arXiv preprint arXiv:2306.01711, 2023.
- [152] Contributors, “The Ultimate Guide to Fine-Tuning LLMs from Basics,” Technical Report, 2024.
- [153] D. M. Anisuzzaman et al., “Fine-tuning large language models for specialized use cases,” Mayo Clinic Proceedings: Digital Health, vol. 3, no. 1, p. 100184, 2025.
- [154] OpenAI, “OpenAI Practical Guide to Building Agents,” 2025.
- [155] Z. Gou et al., “CRITIC: Large Language Models Can Self-Correct with Tool-Interactive Critiquing,” International Conference on Learning Representations (ICLR), 2024.
- [156] J. Yang et al., “Magma: A Foundation Model for Multimodal AI Agents,” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025.
- [157] V. Pavlyshyn, R. Gomez, & S. Li, “Time-aware Knowledge Graphs for Episodic Memory in LLM Agents,” arXiv preprint arXiv:2501.00987, 2025.
- [158] B. Chen et al., “FireAct: Toward Language Agent Fine-tuning,” International Conference on Learning Representations (ICLR), 2024.
- [159] H. Lee et al., “RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback,” arXiv preprint arXiv:2309.00267, 2024.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献29条内容
已为社区贡献29条内容

所有评论(0)