Spring AI Alibaba 学习(三):Graph Workflow 深度解析(下篇)
本文是SpringAIAlibaba系列第四篇,深入解析DeepResearch技术及其在GraphWorkflow中的实现。文章首先介绍了DeepResearch的概念演进,从RAG到DeepSearch再到具备复杂推理能力的DeepResearch,分析了其解决企业级AI痛点的优势。重点剖析了DeepResearch四大核心模块(规划、问题演化、网页探索、报告生成)的技术架构,并通过代码示例展
📌 系列文章
- Spring AI Alibaba学习(一)—— RAG
- Spring AI Alibaba 学习(二):Agent 智能体架构深度解析
- Spring AI Alibaba 学习(三):Graph Workflow 深度解析(上篇)
- Spring AI Alibaba 学习(三):Graph Workflow 深度解析(下篇)(本文)
目录
1.2 从 RAG 到 DeepResearch 的技术演进
2.2 模块二:Question Developing(问题演化)
2.4 模块四:Report Generation(报告生成)
三、用 Graph Workflow 实现 DeepResearch
6.1 添加人工审核——基于人类的反馈机制(Human In The Loop)
📖 前言
上回说到,我们学习了 Graph Workflow 的核心概念和基础用法。上回我们一起拆解了 Graph Workflow 的三大核心组件,也理清了完整工作流的搭建思路。相信你和我一样,已经迫不及待想动手实践 —— 真正打造一套拥有类人学习能力的 Agent 工作流。当然SAA的框架的设计者也有他们预设封装好的一套DeepResearch框架,详细的介绍可以参考同站这位@Ben_Ym 作者大大的技术博客——非常高质量优秀的一篇技术博客分享:Spring AI Alibaba DeepResearch源码解读
https://blog.csdn.net/qq_34438435/article/details/157843204
本文将涵盖:
- ✅ DeepResearch 是什么?为什么这么火?
- ✅ DeepResearch 的工作原理
- ✅ 用 Graph Workflow 实现 DeepResearch
- ✅ 完整的代码实现
- ✅ 高级特性:人工介入、缓存、迭代优化
一、什么是 DeepResearch?
1.1 概念起源与演变
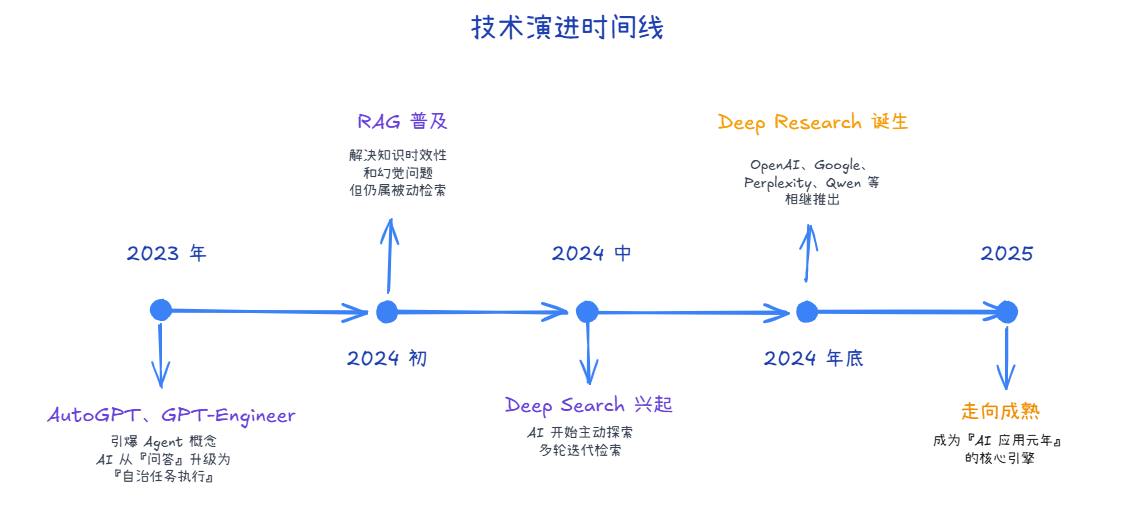
DeepResearch(深度研究)是 2024-2025 年 AI 领域最受关注的方向之一,代表着 AI Agent 从简单任务执行向复杂研究能力的跃升。它的出现并非偶然,而是 AI 技术演进的必然结果:
为什么 DeepResearch 这么火?

随着 Agent 技术的成熟,企业级需求暴露出三个核心痛点:
- 实时性:需要接入最新数据,而不是依赖模型训练时的"冻结"知识
- 可追溯性:每步决策都需要可审计的依据
- 稳定性:多轮规划 + 工具调用不能全靠长上下文推理
DeepResearch 正是为解决这些问题而生!
1.2 从 RAG 到 DeepResearch 的技术演进
第一阶段:RAG(检索增强生成)- 被动检索时代
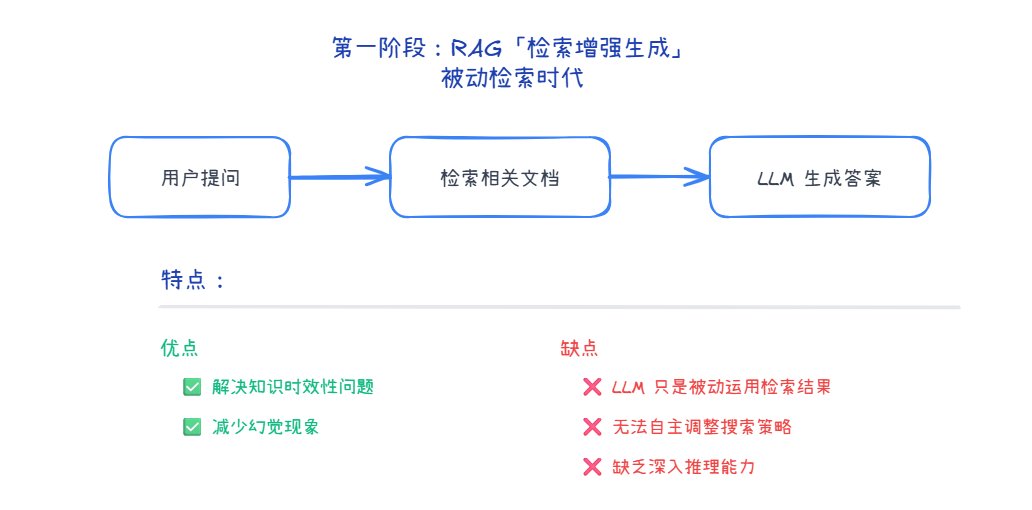
特点:
- ✅ 解决知识时效性问题
- ✅ 减少幻觉现象
- ❌ LLM 只是被动运用检索结果
- ❌ 无法自主调整搜索策略
- ❌ 缺乏深入推理能力
可以说,RAG 解决了 有信息可用”的问题,但还远没实现“会思考、会研究”,这个阶段的Agent思考力仍然非常欠缺!

第二阶段:Deep Search - 主动探索的开端
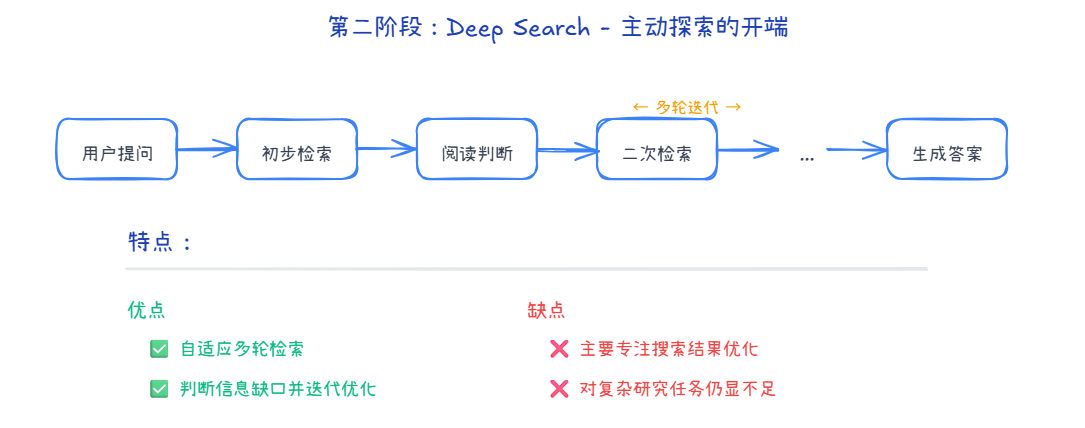
特点:
- ✅ 自适应多轮检索
- ✅ 判断信息缺口并迭代优化
- ❌ 主要专注搜索结果优化
- ❌ 具备初步的研究力了,但对复杂研究任务心有余而力不足。
第三阶段:Deep Research - 复杂推理新范式
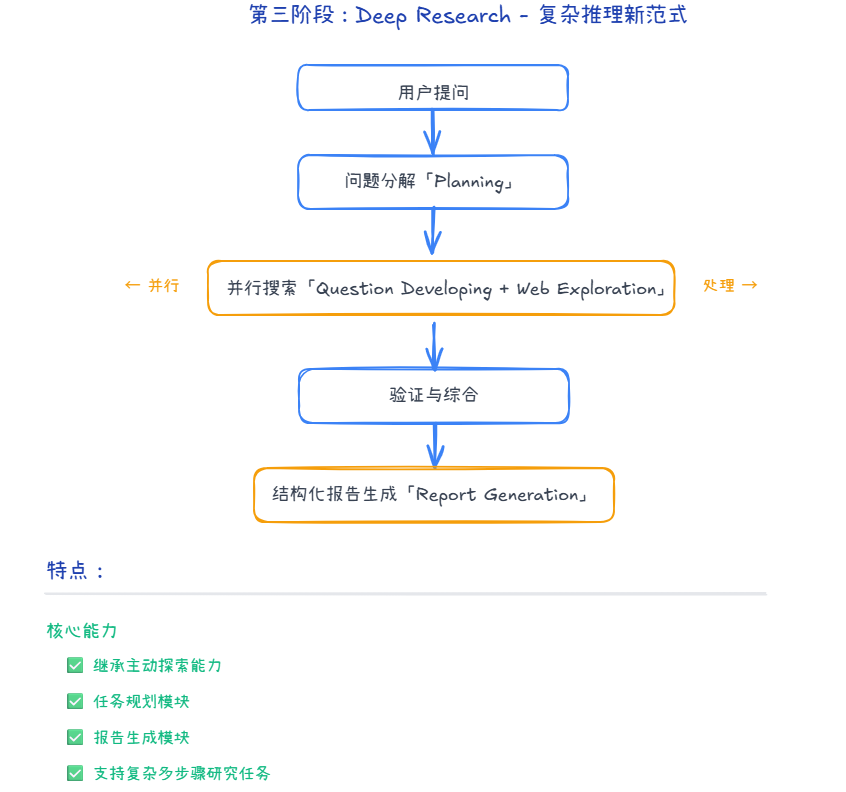
特点:
- ✅ 继承主动探索能力
- ✅ 任务规划模块
- ✅ 报告生成模块
- ✅ 支持复杂多步骤研究任务
1.2 DeepResearch vs 传统 AI
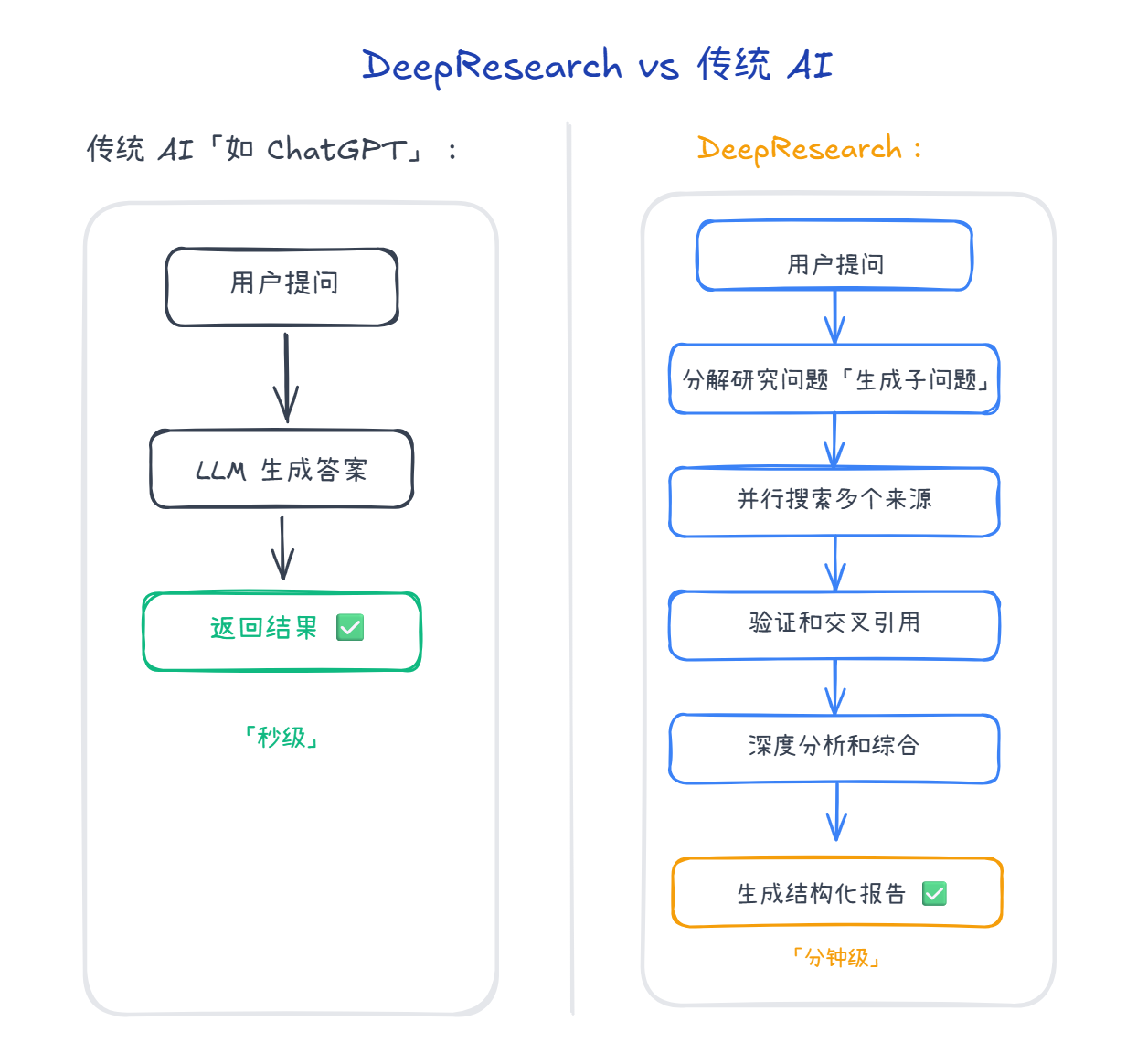
1.4 核心特点对比
| 特性 | 传统 AI | DeepResearch |
|---|---|---|
| 研究深度 | 浅层回答 | 深度研究 |
| 信息来源 | 单次调用 | 多源搜索 |
| 思考过程 | 隐藏 | 可见(透明) |
| 输出形式 | 简单回答 | 结构化报告 |
| 时间 | 秒级 | 分钟级 |
二、DeepResearch 通用架构深度解析
DeepResearch 系统由 四大核心模块 组成,每个模块都有独特的职责和技术挑战:
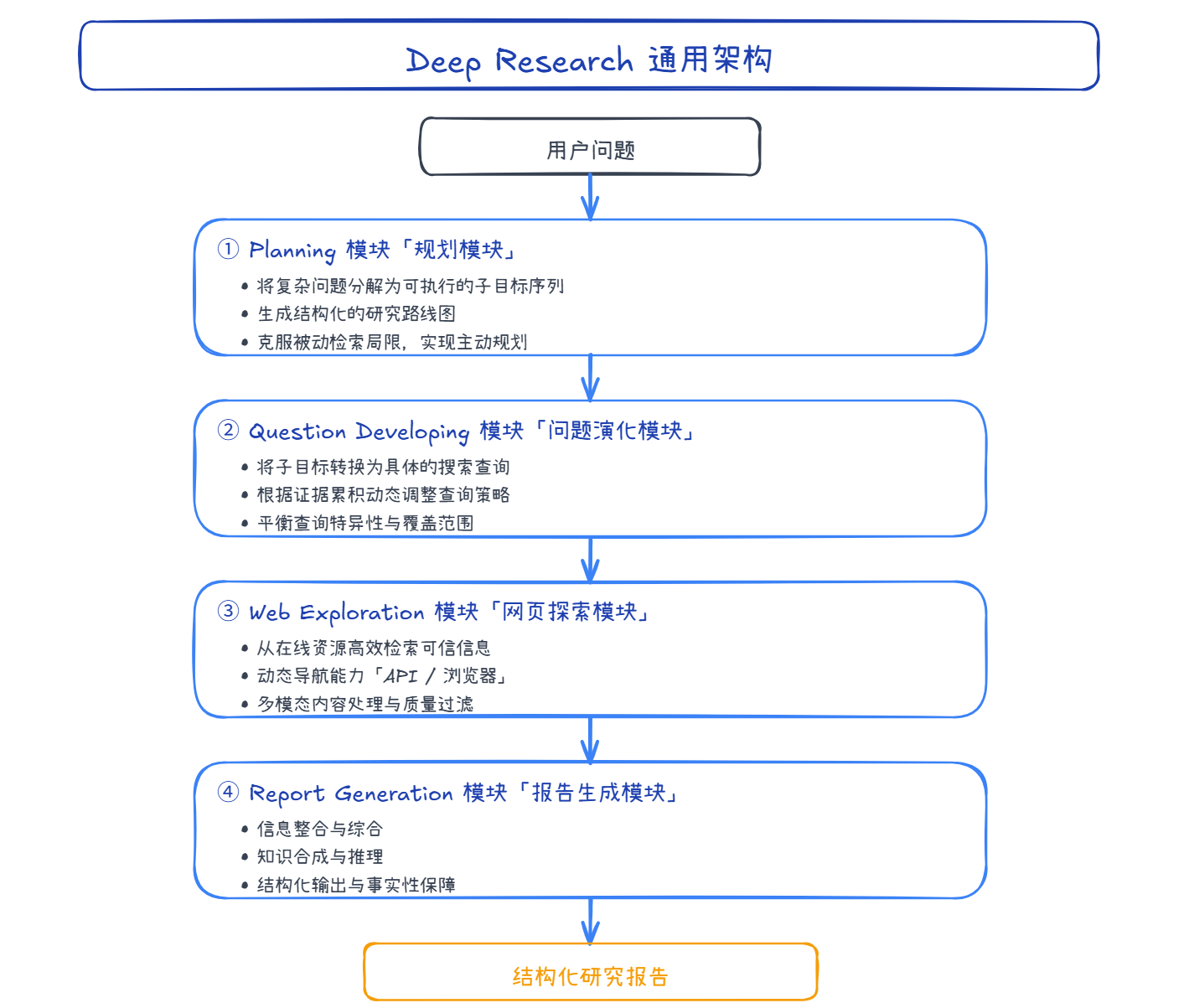
2.1 模块一:Planning(规划模块)
2.1.1 核心作用
- 将用户意图转化为可执行计划:分解为结构化子目标序列
- 提供结构化路线图:任务感知的执行路线图
- 克服被动检索局限:实现主动规划和系统化推理
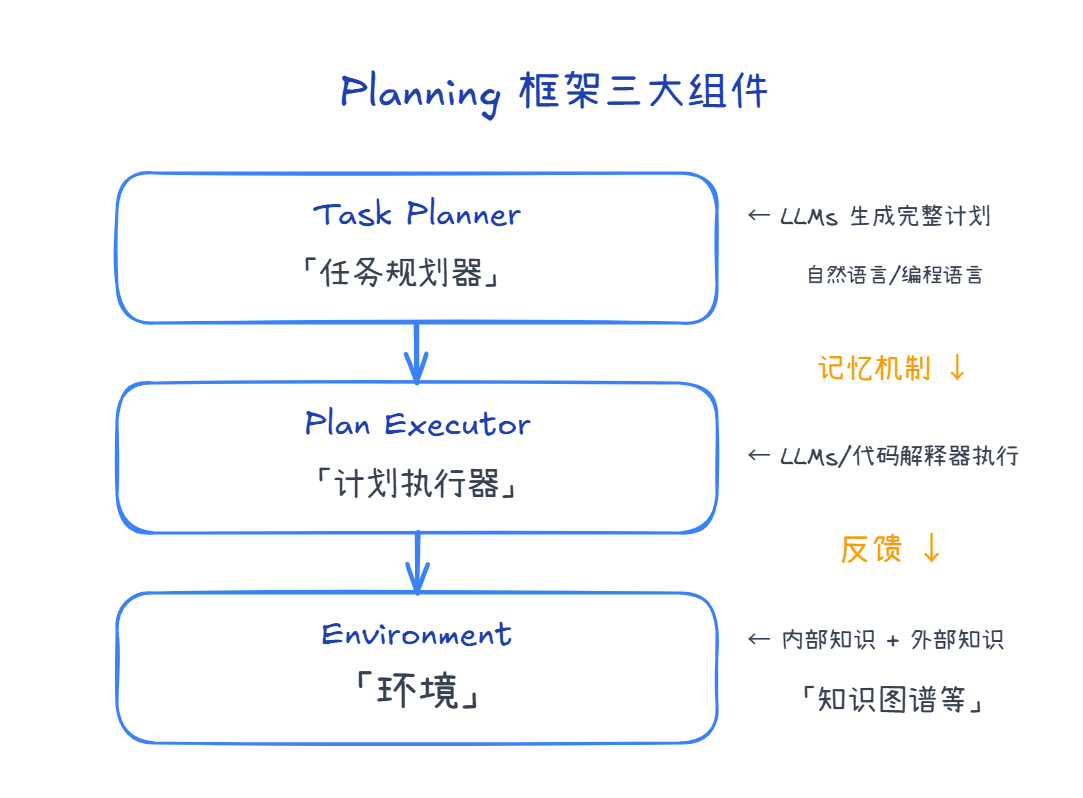
2.1.2 技术框架
2.1.3 工程策略对比
| 策略 | 描述 | 代表系统 | 适用场景 |
|---|---|---|---|
| Planning-Only | 直接根据初始提示生成计划 | Grok、Manus | 简单任务 |
| Intent-to-Planning | 先澄清意图再生成计划 | OpenAI DR | 复杂任务 |
| Unified Intent-Planning | 初步计划 + 用户交互确认 | Gemini DR | 团队协作 |
2.2 模块二:Question Developing(问题演化)
2.2.1 核心作用
- 结构化计划 → 可执行查询:将子目标转换为搜索序列
- 上下文感知:根据累积证据动态调整
- 平衡精度与覆盖:既精确又全面
2.2.2 优化方法
当前主要优化方向:
- 奖励驱动:通过奖励函数训练更好的问题生成能力
- 监督驱动:使用标注数据指导问题演化
- 强化学习:根据检索结果质量优化查询策略
2.3 模块三:Web Exploration(网页探索)
2.3.1 两种架构范式
| 方式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 基于 API | 速度快、效率高、结构化好 | 无法获取动态内容 | 结构化数据检索 |
| 基于浏览器 | 可获取动态/非结构化内容 | 延迟高、资源消耗大 | 深度交互分析 |
混合架构:未来趋势是结合两者优势
- 快速初步检索(API)
- 深层交互分析(Browser)
- 专门的证据抽取与验证模块
2.4 模块四:Report Generation(报告生成)
2.4.1 核心作用
- 信息整合:零散证据 → 结构化报告
- 知识合成:多源信息 → 新知识和结论
- 事实保障:确保准确性和可追溯性
2.4.2 两大技术方向
① 结构控制
- 基于规划的生成
- 约束引导的生成
- 结构感知的对齐
② 事实完整性
- 忠实建模:生成内容与证据一致
- 冲突解析:处理矛盾信息
- 事实评估:验证准确性
示例:BRIDGE 方法在检索与生成间插入验证层,动态决定:
- 信任内部知识
- 信任外部知识
- 拒绝回答
三、用 Graph Workflow 实现 DeepResearch
3.1 DeepResearch 的 Graph 结构
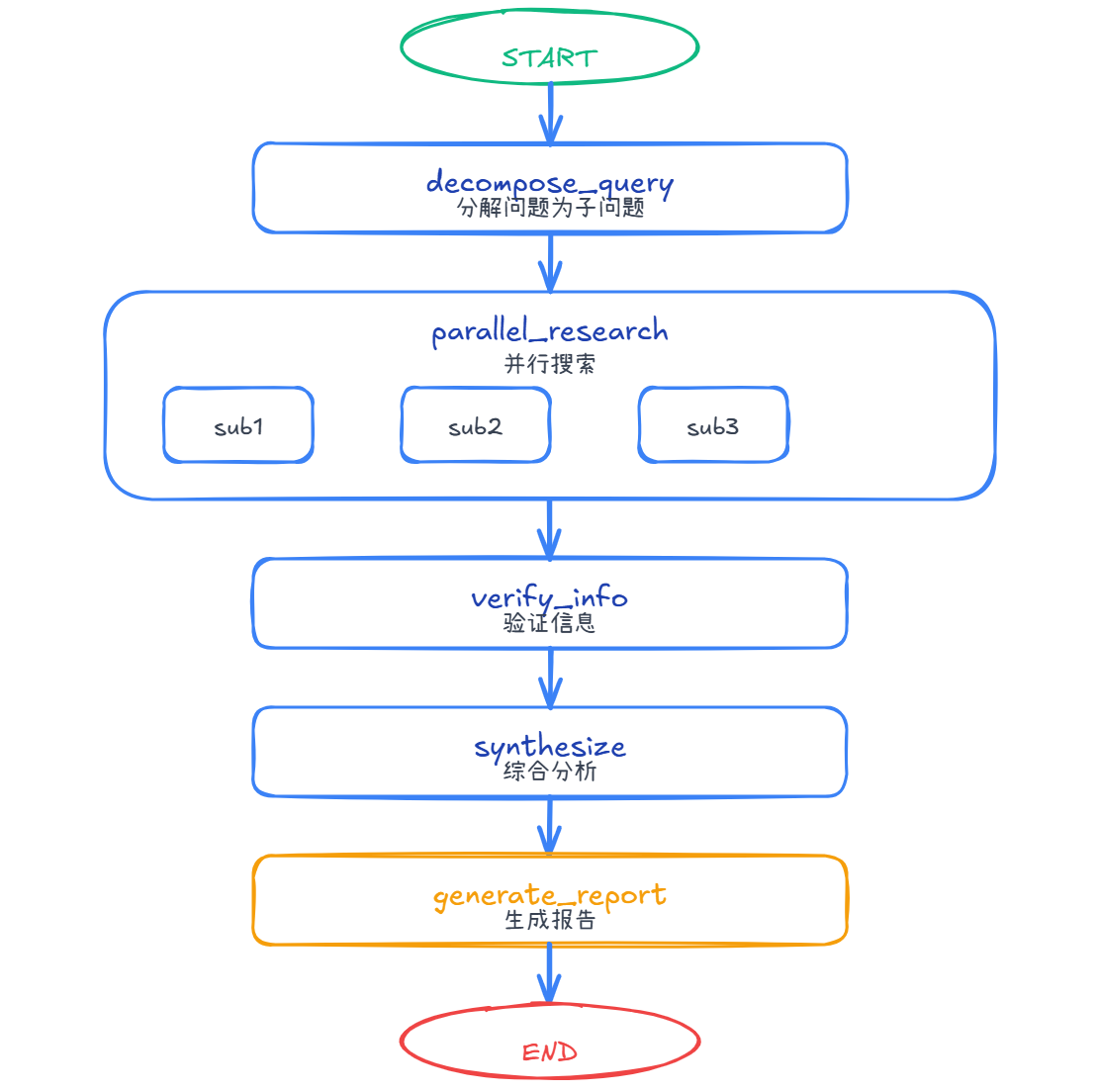
3.2 状态定义
public class DeepResearchState {
private String originalQuery; // 原始问题
private List<String> subQueries; // 子问题列表
private Map<String, ResearchResult> results; // 每个子问题的研究结果
private List<String> verifiedFacts; // 验证过的事实
private String finalReport; // 最终报告
private List<String> sources; // 信息来源
}
public class ResearchResult {
private String query;
private List<String> findings;
private List<String> sources;
private double confidence;
}
3.3 KeyStrategyFactory 配置
public static KeyStrategyFactory createKeyStrategyFactory() {
return () -> {
Map<String, KeyStrategy> strategies = new HashMap<>();
strategies.put("original_query", new ReplaceStrategy());
strategies.put("sub_queries", new ReplaceStrategy());
strategies.put("results", new ReplaceStrategy());
strategies.put("verified_facts", new AppendStrategy());
strategies.put("final_report", new ReplaceStrategy());
strategies.put("sources", new AppendStrategy());
strategies.put("messages", new AppendStrategy());
return strategies;
};
}
四、核心节点实现
4.1 节点 1: 问题分解
public class DecomposeQueryNode implements NodeAction {
private final ChatClient chatClient;
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String query = (String) state.value("original_query").orElse("");
String prompt = String.format("""
你是一个研究专家。请将以下复杂问题分解为 3-5 个可研究的子问题。
原始问题:%s
要求:
1. 子问题应该相互独立
2. 子问题应该覆盖原始问题的不同方面
3. 每个子问题都应该可以通过搜索回答
以 JSON 数组格式返回:["子问题1", "子问题2", "子问题3"]
""", query);
String response = chatClient.prompt()
.user(prompt)
.call()
.content();
// 解析子问题
List<String> subQueries = parseSubQueries(response);
log.info("分解为 {} 个子问题", subQueries.size());
return Map.of(
"sub_queries", subQueries,
"messages", List.of(" 问题分解完成")
);
}
}
4.2 节点 2: 并行研究
public class ParallelResearchNode implements NodeAction {
private final ChatClient chatClient;
private final SearchTool searchTool; // 搜索工具
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
List<String> subQueries = (List<String>) state.value("sub_queries")
.orElse(List.of());
// 并行研究每个子问题
Map<String, ResearchResult> results = new ConcurrentHashMap<>();
// 使用并行流处理
subQueries.parallelStream().forEach(subQuery -> {
try {
ResearchResult result = researchSubQuery(subQuery);
results.put(subQuery, result);
} catch (Exception e) {
log.error("研究子问题失败: {}", subQuery, e);
}
});
log.info(" 完成 {} 个子问题的研究", results.size());
return Map.of(
"results", results,
"messages", List.of(" 并行研究完成")
);
}
private ResearchResult researchSubQuery(String query) throws Exception {
// 1. 搜索相关信息
List<String> searchResults = searchTool.search(query, 5);
// 2. 使用 LLM 提取关键信息
String prompt = String.format("""
基于以下搜索结果,回答问题:%s
搜索结果:
%s
请提取关键信息,并评估可信度(0-1)。
""", query, String.join("\n", searchResults));
String response = chatClient.prompt()
.user(prompt)
.call()
.content();
// 3. 构建研究结果
ResearchResult result = new ResearchResult();
result.setQuery(query);
result.setFindings(List.of(response));
result.setSources(searchResults);
result.setConfidence(0.8);
return result;
}
}
4.3 节点 3: 信息验证
public class VerifyInformationNode implements NodeAction {
private final ChatClient chatClient;
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
Map<String, ResearchResult> results =
(Map<String, ResearchResult>) state.value("results")
.orElse(Map.of());
List<String> verifiedFacts = new ArrayList<>();
// 交叉验证信息
for (ResearchResult result : results.values()) {
String prompt = String.format("""
请验证以下信息的准确性,并提取可靠的事实:
问题:%s
发现:%s
来源数量:%d
只返回高可信度的事实,每行一个。
""",
result.getQuery(),
String.join("\n", result.getFindings()),
result.getSources().size()
);
String verified = chatClient.prompt()
.user(prompt)
.call()
.content();
verifiedFacts.addAll(Arrays.asList(verified.split("\n")));
}
log.info(" 验证了 {} 个事实", verifiedFacts.size());
return Map.of(
"verified_facts", verifiedFacts,
"messages", List.of(" 信息验证完成")
);
}
}
4.4 节点 4: 综合分析与报告生成
public class SynthesizeNode implements NodeAction {
private final ChatClient chatClient;
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
String originalQuery = (String) state.value("original_query").orElse("");
List<String> verifiedFacts = (List<String>) state.value("verified_facts")
.orElse(List.of());
Map<String, ResearchResult> results =
(Map<String, ResearchResult>) state.value("results")
.orElse(Map.of());
String prompt = String.format("""
你是一个研究分析专家。请基于以下研究结果,生成深度分析报告。
原始问题:%s
研究发现:
%s
验证的事实:
%s
要求:
1. 生成结构化的研究报告
2. 包含:执行摘要、详细分析、关键发现、结论
3. 使用 Markdown 格式
4. 引用具体来源
""",
originalQuery,
formatResults(results),
String.join("\n", verifiedFacts)
);
String report = chatClient.prompt()
.user(prompt)
.call()
.content();
// 收集所有来源
List<String> allSources = results.values().stream()
.flatMap(r -> r.getSources().stream())
.distinct()
.collect(Collectors.toList());
log.info("生成了 {} 字的研究报告", report.length());
return Map.of(
"final_report", report,
"sources", allSources,
"messages", List.of(" 综合分析完成")
);
}
}
五、构建完整的 DeepResearch Graph
public class DeepResearchGraph {
public static CompiledGraph createDeepResearchGraph(ChatModel chatModel)
throws GraphStateException {
ChatClient.Builder chatClientBuilder = ChatClient.builder(chatModel);
SearchTool searchTool = new SearchTool(); // 假设已实现
// 创建节点
var decomposeNode = node_async(
new DecomposeQueryNode(chatClientBuilder.build())
);
var researchNode = node_async(
new ParallelResearchNode(chatClientBuilder.build(), searchTool)
);
var verifyNode = node_async(
new VerifyInformationNode(chatClientBuilder.build())
);
var synthesizeNode = node_async(
new SynthesizeNode(chatClientBuilder.build())
);
// 构建 Graph
StateGraph workflow = new StateGraph(createKeyStrategyFactory())
.addNode("decompose", decomposeNode)
.addNode("research", researchNode)
.addNode("verify", verifyNode)
.addNode("synthesize", synthesizeNode);
// 添加边(顺序执行)
workflow.addEdge(START, "decompose");
workflow.addEdge("decompose", "research");
workflow.addEdge("research", "verify");
workflow.addEdge("verify", "synthesize");
workflow.addEdge("synthesize", END);
// 编译
var memory = new MemorySaver();
var config = CompileConfig.builder()
.saverConfig(SaverConfig.builder()
.register(memory)
.build())
.build();
return workflow.compile(config);
}
// 使用示例
public static void main(String[] args) throws Exception {
// 创建 ChatModel
ChatModel chatModel = DashScopeChatModel.builder()
.apiKey(System.getenv("AI_DASHSCOPE_API_KEY"))
.build();
// 创建 DeepResearch Graph
CompiledGraph deepResearch = createDeepResearchGraph(chatModel);
// 初始状态
Map<String, Object> initialState = Map.of(
"original_query", "分析 2024 年人工智能的主要发展趋势",
"messages", new ArrayList<String>()
);
var config = RunnableConfig.builder()
.threadId("research_001")
.build();
// 流式执行,观察每个阶段
System.out.println("=== 开始深度研究 ===\n");
deepResearch.stream(initialState, config)
.doOnNext(output -> {
System.out.println(" 阶段: " + output.node());
List<String> messages = (List<String>) output.state()
.data().get("messages");
if (messages != null && !messages.isEmpty()) {
System.out.println(" " + messages.get(messages.size() - 1));
}
System.out.println();
})
.blockLast();
// 获取最终报告
var finalState = deepResearch.getState(config);
String report = (String) finalState.state().data().get("final_report");
System.out.println("\n=== 研究报告 ===\n");
System.out.println(report);
}
}
六、高级特性
6.1 添加人工审核——基于人类的反馈机制(Human In The Loop)
引入Human In the Loop(人机协同反馈机制),可通过简单的人工审核,弥补RAG被动检索阶段的局限、提升输出可信度,既能进一步降低模型幻觉,也能让检索生成的结果更贴合实际需求。
// 编译时配置中断点
var config = CompileConfig.builder()
.saverConfig(SaverConfig.builder().register(memory).build())
.interruptBefore("synthesize") // 在生成报告前人工审核
.build();
CompiledGraph deepResearch = workflow.compile(config);
// 执行到中断点
deepResearch.stream(initialState, runnableConfig).blockLast();
// 人工审核研究结果
var currentState = deepResearch.getState(runnableConfig);
Map<String, ResearchResult> results =
(Map<String, ResearchResult>) currentState.state().data().get("results");
System.out.println("请审核研究结果:");
results.forEach((query, result) -> {
System.out.println("问题: " + query);
System.out.println("发现: " + result.getFindings());
});
// 审核通过后继续
deepResearch.updateState(runnableConfig, Map.of("approved", true), null);
deepResearch.stream(null, runnableConfig).blockLast();
6.2 添加迭代改进
// 添加反馈循环
workflow.addConditionalEdges("synthesize",
edge_async(state -> {
String report = (String) state.value("final_report").orElse("");
// 如果报告质量不够,重新研究
if (needsMoreResearch(report)) {
return "research"; // 回到研究阶段
}
return END;
}),
Map.of("research", "research", END, END)
);
private static boolean needsMoreResearch(String report) {
// 简单的质量检查
return report.length() < 1000 || !report.contains("结论");
}
6.3 添加缓存机制
public class CachedResearchNode implements NodeAction {
private final Map<String, ResearchResult> cache = new ConcurrentHashMap<>();
private final ParallelResearchNode delegate;
@Override
public Map<String, Object> apply(OverAllState state) throws Exception {
List<String> subQueries = (List<String>) state.value("sub_queries")
.orElse(List.of());
Map<String, ResearchResult> results = new HashMap<>();
for (String query : subQueries) {
// 检查缓存
if (cache.containsKey(query)) {
log.info(" 使用缓存结果: {}", query);
results.put(query, cache.get(query));
} else {
// 执行研究
ResearchResult result = researchSubQuery(query);
cache.put(query, result);
results.put(query, result);
}
}
return Map.of("results", results);
}
}
七、实战案例输出示例
7.1 输入
"量子计算在未来 5 年内有哪些实际的商业应用?"
7.2 执行过程
=== 开始深度研究 ===
📍 阶段: decompose
✅ 问题分解完成
子问题:
1. 量子计算的当前技术成熟度?
2. 哪些行业最有可能采用量子计算?
3. 主要的技术挑战是什么?
4. 预期的商业化时间表?
📍 阶段: research
✅ 并行研究完成
完成 4 个子问题的研究
📍 阶段: verify
✅ 信息验证完成
验证了 12 个事实
📍 阶段: synthesize
✅ 综合分析完成
生成了 2500 字的研究报告
7.3 输出报告
# 量子计算商业应用研究报告
## 执行摘要
量子计算正处于从实验室走向商业应用的关键阶段...
## 详细分析
### 1. 技术成熟度
- 当前状态:NISQ(噪声中等规模量子)时代
- 主要玩家:IBM、Google、IonQ
- 量子比特数:50-1000 范围
### 2. 潜在应用领域
- 药物发现:分子模拟
- 金融:风险建模
- 物流:路径优化
### 3. 技术挑战
- 量子退相干
- 错误率
- 可扩展性
### 4. 商业化时间表
- 2024-2025:特定领域试点
- 2026-2028:早期商业应用
- 2029+:广泛商业化
## 关键发现
1. 药物发现是最接近商业化的领域
2. 混合量子-经典算法是当前主流
3. 云量子计算降低了准入门槛
## 结论
量子计算在未来 5 年内将在特定领域实现商业价值...
## 参考来源
1. IBM Quantum Roadmap 2024
2. Nature: Quantum Computing Applications
3. McKinsey: Quantum Technology Report
八、应用场景
| 应用场景 | 输入示例 | 输出结果 | 应用价值 |
|---|---|---|---|
| 市场研究 | "分析电动汽车市场的竞争格局" | 完整的市场分析报告 | 通过深度市场调研,帮助企业了解行业竞争态势、市场规模、主要竞争对手及发展趋势,为战略决策提供数据支持。 |
| 技术调研 | "评估 Rust 语言在后端开发中的优劣" | 技术评估报告 | 对技术方案进行全面分析,涵盖性能、安全性、生态系统、学习曲线等维度,为技术选型和架构决策提供专业建议。 |
| 学术研究 | "总结近 5 年关于 Transformer 架构的研究进展" | 文献综述报告 | 系统梳理学术领域的最新研究成果,识别关键技术突破、研究热点和发展趋势,为学术探索和技术创新提供知识基础。 |
| 商业分析 | "分析 OpenAI 和 Anthropic 的竞争策略" | 竞争对手分析报告 | 深入剖析商业竞争格局,包括产品定位、市场策略、技术优势、融资情况等,为企业战略规划和投资决策提供参考。 |
九、总结与回顾
⑨.1 核心要点回顾
9.1.1 DeepResearch 技术演进
RAG(被动检索)
→ Deep Search(主动探索)
→ Deep Research(复杂推理)
9.1.2 四大核心模块
- Planning(规划):问题分解 + 路线图生成
- Question Developing(问题演化):子目标 → 搜索查询
- Web Exploration(网页探索):API + 浏览器混合架构
- Report Generation(报告生成):信息整合 + 结构化输出
9.1.3 为什么用 Graph Workflow
DeepResearch 需求 Graph Workflow 能力
─────────────────────────────────────────────
多阶段流程 ←→ 节点(Node)
并行搜索 ←→ 并行边(Parallel Edges)
条件分支 ←→ 条件边(Conditional Edges)
状态管理 ←→ State 管理
可观察性 ←→ 流式输出(Stream)
人工介入 ←→ 中断点(Interrupt)
9.1.4 实现关键点
- 问题分解(Planning)
- 并行研究(Parallel Search)
- 信息验证(Verification)
- 深度综合(Synthesis)
⑨.2 DeepResearch vs 其他架构
| 特性 | RAG | ReactAgent | DeepResearch |
|---|---|---|---|
| 核心能力 | 知识检索 | 工具调用 | 深度研究 |
| 处理时间 | 秒级 | 秒级 | 分钟级 |
| 适用场景 | 快速问答 | 任务执行 | 研究报告 |
| 可组合性 | ✅ 可作为 DR 的搜索工具 | ✅ 可作为 DR 的子节点 | ✅ 可集成 RAG 和 Agent |
参考资源
官方资源
- Spring AI Alibaba 官方文档:https://java2ai.com
- GitHub 仓库:https://github.com/alibaba/spring-ai-alibaba
- 示例代码:https://github.com/alibaba/spring-ai-alibaba/tree/main/examples
DeepResearch 深度阅读
- 腾讯技术工程:《2025必看系列:AI如何重新定义研究?万字长文讲透Deep Research》
- 详细解析 DR 的四大核心模块
- 评测方法与主流系统对比
- Dola 的混合数据源方案
💬 互动交流
如果这篇文章对你有帮助,欢迎:
- 👍 点赞支持
- 💬 评论交流
- ⭐ 收藏备用
- 🔗 分享给更多人
有任何问题或建议,欢迎在评论区留言讨论!下一节,我们将回归基础细节,去研究SAA是如何设计调用工具链路的,也就是说,我们的Agent有了脑子,真正是怎样的机制,让它从只会Chat的LLM到Agent?这些无形而又迅猛的“手”是如何来的?敬请期待下回~


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)