大模型张量并行和序列并行介绍
本文分析了Transformer模型训练中的张量并行(TP)和序列并行(SP)技术。TP通过切分权重矩阵减少模型和激活显存,每层激活显存降至$sbh(10+24/tp+5as/h)$,需4次AllReduce通信。SP结合TP进一步减少LayerNorm和Dropout的激活显存,通过AllGather和ReduceScatter实现序列维度的并行。DeepSpeed-Ulysses采用All2A
以Transformer为例,介绍大模型训练过程中常用的张量并行(TP)和序列并行(SP)技术,推导在不同并行策略下的显存大小和通信量。
Transformer结构
单层Transformer由一个Attention模块和一个MLP模块组成
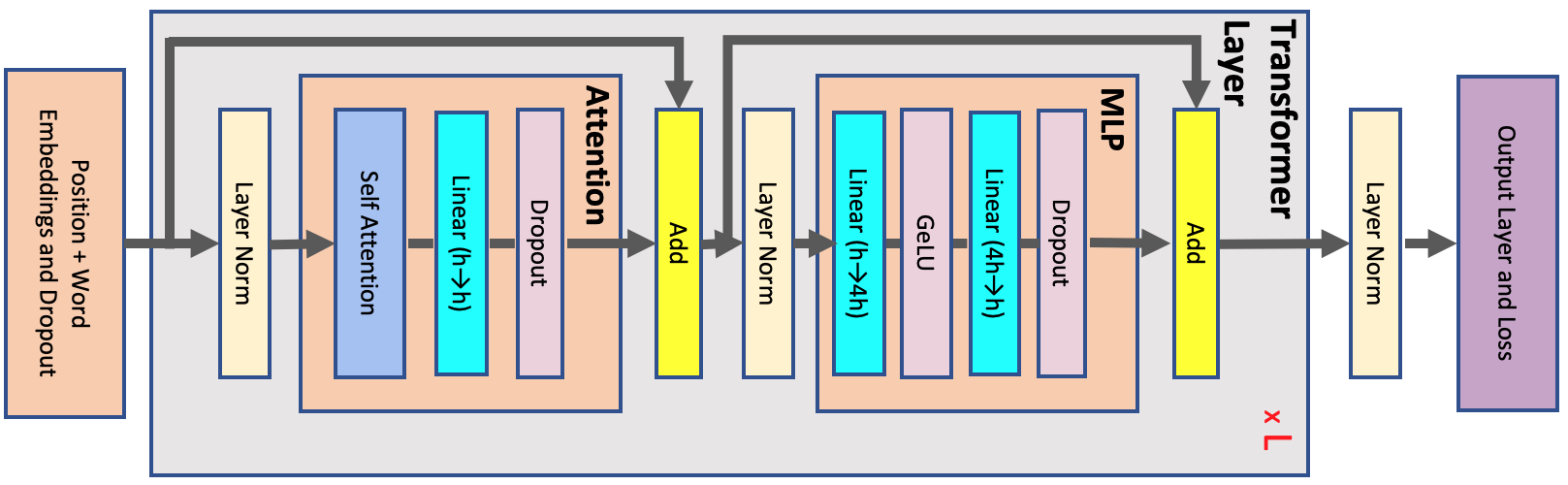
假设数据类型为fp16,输入shape为(s, b, h),b为head数量,分析激活内存:
LayerNorm:一共2层,每层的输入占 2 s b h 2sbh 2sbh,共 4 s b h 4sbh 4sbhMLP:第一层的输入 2 s b h 2sbh 2sbh,第二层的输入 8 s b h 8sbh 8sbh; G e L U GeLU GeLU的输出 8 s b h 8sbh 8sbh, D r o p o u t Dropout Dropout的mask为 s b h sbh sbh,一共是 19 s b h 19sbh 19sbhSelfAttention:初始输入 2 s b h 2sbh 2sbh, q , k , v q,k,v q,k,v占用 6 s b h 6sbh 6sbh, S o f t m a x Softmax Softmax的输出 2 a s 2 b 2as^2b 2as2b, D r o p o u t Dropout Dropout的mask和输出 3 a s 2 b 3as^2b 3as2b,输出 L i n e a r Linear Linear层的输入 2 s b h 2sbh 2sbh,最后一个 D r o p o u t Dropout Dropout的mask为 s b h sbh sbh。一共是 11 s b h + 5 a s 2 b 11sbh+5as^2b 11sbh+5as2b
A c t i v a t i o n s m e m o r y p e r l a y e r = s b h ( 34 + 5 a s h ) Activations\ memory\ per\ layer = sbh(34 + 5\frac{as}{h}) Activations memory per layer=sbh(34+5has)
张量和序列并行
Tensor Parallelism
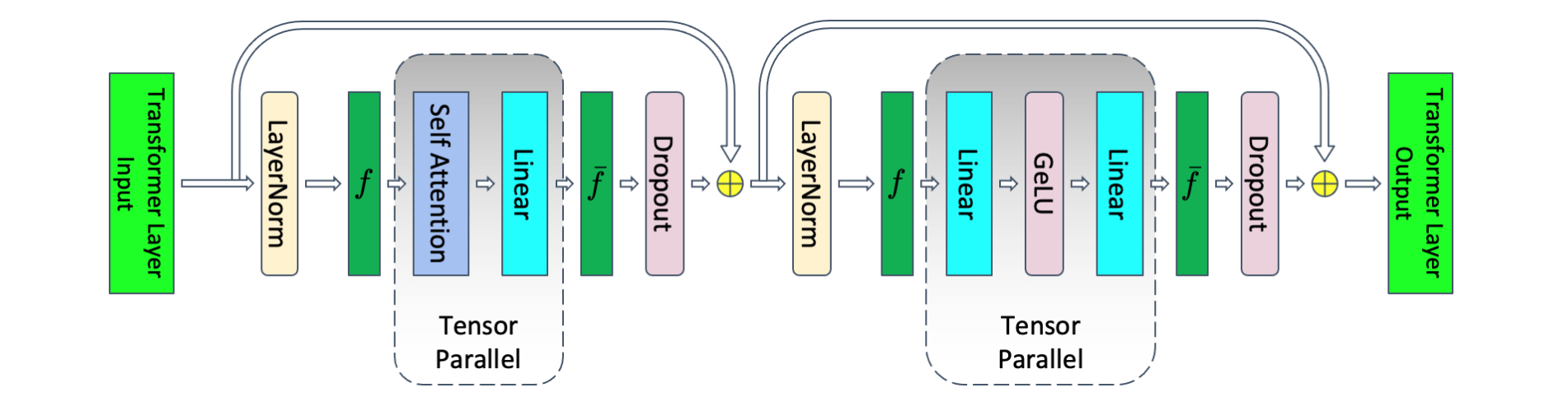
当单卡放不下单个模型时,可以使用张量并行。megatron论文中Transformer中张量并行的流程图:
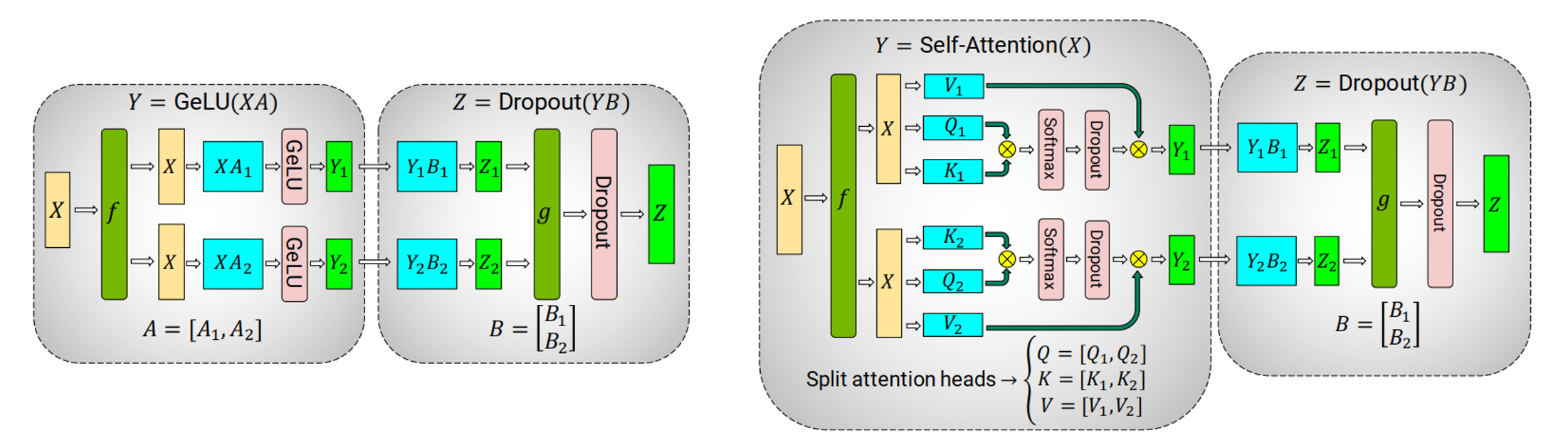
forward过程中, f f f不做任何操作, g g g表示AllReduce;backward过程中, g g g不做任何操作, f f f表示AllReduce
**MLP:**先沿着列切分第一个线性层的权重,再沿着行切分第二个线性层的权重
**Attention:**先沿着列切分 q , k , v q,k,v q,k,v投影线性层,各自计算selfattention;再沿着行切分输出线性层
通信量分析:前向2次AllReduce,反向2次AllReduce
张量并行同时减少了模型大小和激活值,开启后激活值显存占用为
A c t i v a t i o n s m e m o r y p e r l a y e r = s b h ( 10 + 24 t p + 5 a s h ) Activations\ memory\ per\ layer = sbh(10 + \frac{24}{tp} + 5\frac{as}{h}) Activations memory per layer=sbh(10+tp24+5has)
Tensor and Sequence Parallelism
序列并行可用于减少LayerNorm和Dropout模块的激活值,通常与张量并行结合使用
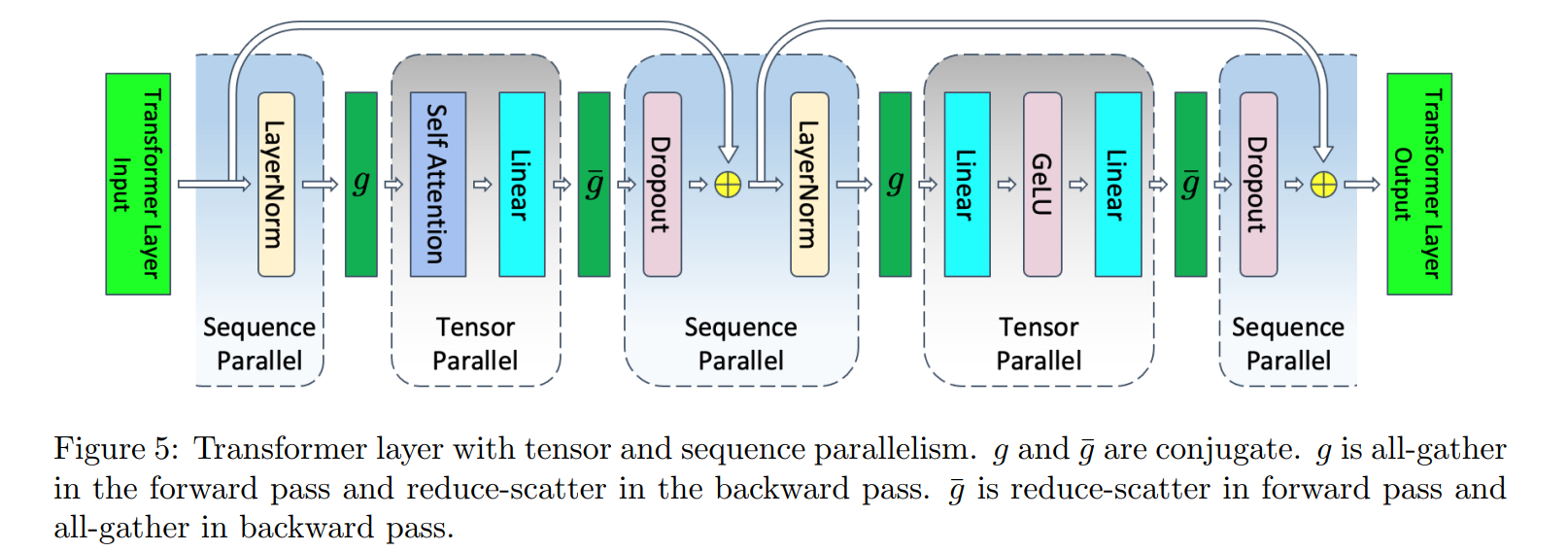
沿着(s, b, h)中s方向切分过的数据,输入到LayerNorm和Dropout层计算
在输入Attention和MLP前,进行AllGather,沿着sp聚合;输入LayerNorm和Dropout前,进行ReduceScatter,沿着sp切分
通信量分析:forward2次AllGather,2次ReduceScatter;反向2次AllGather,2次ReduceScatter
SP并行减少了LayerNorm和Dropout层的激活值,激活值分析:
A c t i v a t i o n s m e m o r y p e r l a y e r = s b h ( 10 s p + 24 t p + 5 a s h ) Activations\ memory\ per\ layer = sbh(\frac{10}{sp} + \frac{24}{tp} + 5\frac{as}{h}) Activations memory per layer=sbh(sp10+tp24+5has)
Ulysses-SP
DeepSpeed-Ulysses 是一种高效的长序列并行技术,通过All2All重排将序列维度并行转为多头并行,无需切分模型权重
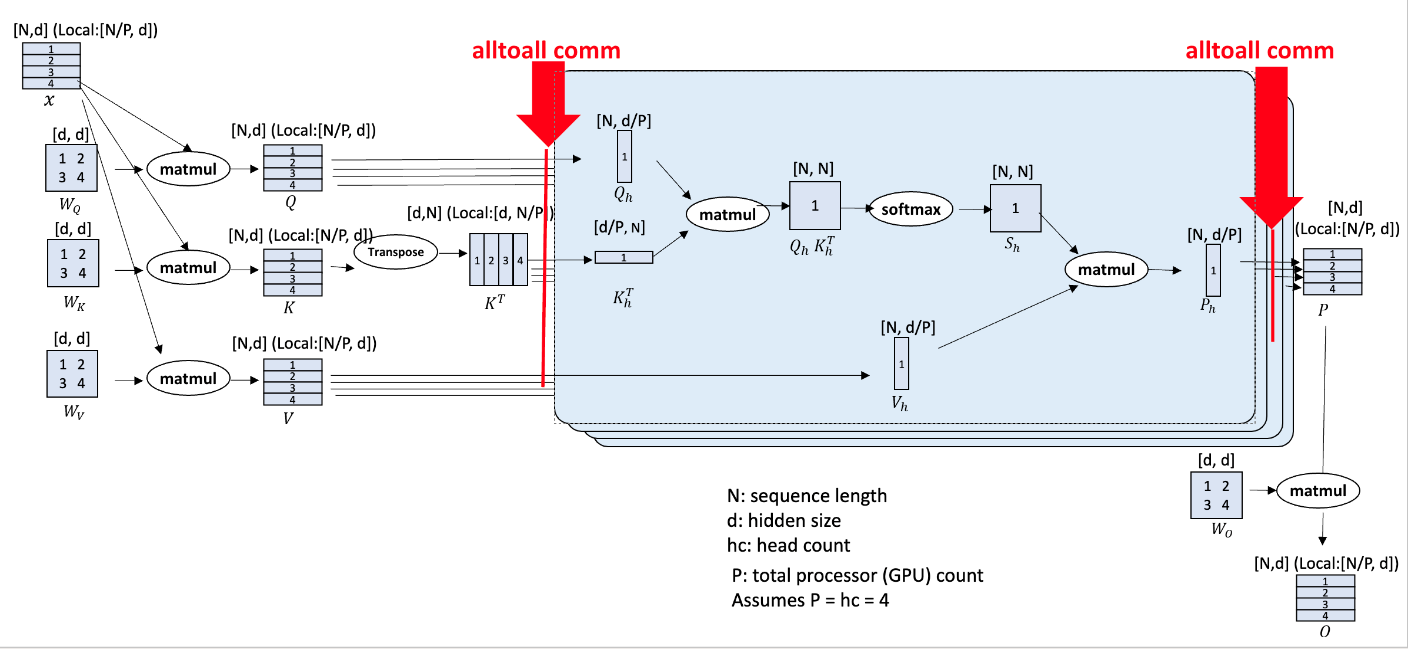
通信量分析:前向和反向分别做4次All2All;单次All2All的通信量为 N d / P Nd/P Nd/P
Ulysses vs. TP-SP
从Attention模块来看:
- Megatron通过TP,显式地把 W q , W k , W v Wq, Wk, Wv Wq,Wk,Wv切分开,每张卡上计算所有seq的部分head的结果。
- Ulysses通过
all2All,在每张卡完整保存 W q , W k , W v Wq, Wk, Wv Wq,Wk,Wv的前提下,让每张卡上计算所有seq的部分head的结果。
- Megatron Tp-Sp:4
AllGather+ 4ReduceScatter,总通讯量为8Nd - DeepSpeed Ulysses:8
All2All,总通讯量为8Nd/P,可以增加卡数来降低通信量
参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)