LMDeploy重磅更新:从支撑模型到被模型反哺,推理引擎迈入协同进化时代!
近期,上海人工智能实验室(上海AI实验室)大模型推理部署工具 LMDeploy 迎来重磅更新——v0.12+ 版本正式发布,进一步为社区带来更流畅、更可靠、更强大的大模型服务体验。本次更新不仅涵盖多项功能升级与性能优化,也进一步展示了推理引擎与模型能力协同演进的可能性。亮点速览:深度参与并支撑 1T Moe 科学大模型的全周期研发首次实现了模型“反哺”算子生成的闭环尝试量化推理能力全面增强,正式拥
近期,上海人工智能实验室(上海AI实验室)大模型推理部署工具 LMDeploy 迎来重磅更新——v0.12+ 版本正式发布,进一步为社区带来更流畅、更可靠、更强大的大模型服务体验。
本次更新不仅涵盖多项功能升级与性能优化,也进一步展示了推理引擎与模型能力协同演进的可能性。
亮点速览:
-
深度参与并支撑 1T Moe 科学大模型 Intern-S1-Pro 的全周期研发
-
首次实现了模型“反哺”算子生成的闭环尝试
-
量化推理能力全面增强,正式拥抱 LLM-Compressor 生态
GitHub 主页:
https://github.com/InternLM/lmdeploy
官方文档:
https://lmdeploy.readthedocs.io/
深度赋能:支撑 Intern-S1-Pro 全周期研发
2 月 4 日,上海AI实验室开源书生 1T Moe 科学多模态大模型 Intern-S1-Pro,通过创新底层架构设计与万亿参数超大规模训练策略,Intern-S1-Pro 核心科学能力实现了质的跃升。作为书生系列模型的核心推理基础设施,LMDeploy 深度参与模型从研发到落地的完整周期,为其稳定运行与性能释放提供了关键技术支撑与可靠保障。
在模型架构预研阶段,LMDeploy 率先实现创新分组路由机制,有效解决了专家并行中的计算负载不均衡问题,将系统整体吞吐量提升至新高度。
在有监督微调阶段,LMDeploy 凭借出色的扩展能力,成功支撑了千卡级集群规模评测任务,大幅提高了硬件利用率。
在强化学习训练阶段,LMDeploy 与 XTuner V1 训练引擎协同构建了多模态多任务的异步强化学习训练框架。该框架采用 FP8 混合精度进行推理与训练,通过 Partial Rollout(部分采样) 机制大幅提升了 RL 训练效率,同时引入 Rollout Routing Replay 方法,有效解决了训练与推理阶段的路由不一致问题,显著增强了训练过程的稳定性,为万亿参数模型的长时间、高强度连续训练提供了高可靠的工程保障。
关键突破:模型自动生成算子,“反哺”推理引擎
在 LMDeploy 为 Intern-S1-Pro 提供底层能力支撑的同时,Intern-S1-Pro 也实现了对 LMDeploy 的“能力反哺”。在研发迭代过程中,团队使用 Intern-S1-Pro 驱动基于进化计算的自研智能体,通过与真实硬件的多轮交互和反馈进化(进化迭代趋势见图1),成功生成了 DeepSeek 模型 MoE 层中前向路由模块的高性能 Triton 算子(GitHub Pull Request:https://github.com/InternLM/lmdeploy/pull/4345)。
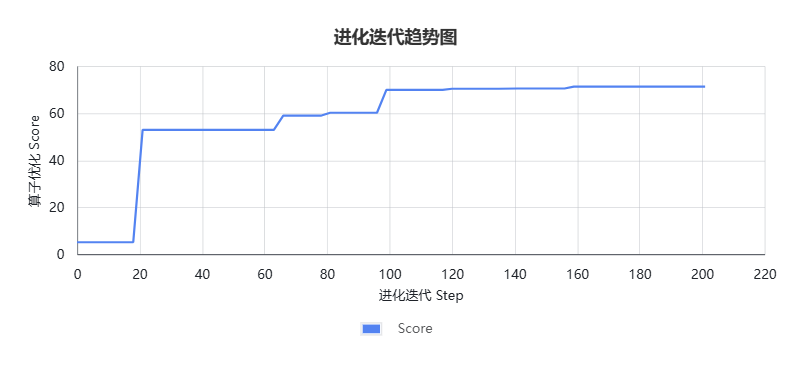
图1
在技术上,Intern-S1-Pro 将路由模块中原本繁杂的操作(包括 Sigmoid 激活、Bias 加法、Reshape、Top-K 路由选择和 Masking 等)进行了深度的算子融合(Operator Fusion),显著减少了显存带宽占用和内核启动开销,从而提高了计算效率。
在算子级隔离测试中,由 Intern-S1-Pro 自动生成的算子实现了超过 30% 的性能提升(性能数据详见下表1)。该前向路由模块已应用于 DeepSeek 系列模型,并在 DeepSeek-v3.2 实际推理场景的端到端评测中同样得到验证:自动生成的 Triton 算子带来了系统级吞吐量提升(性能数据详见下表2)。
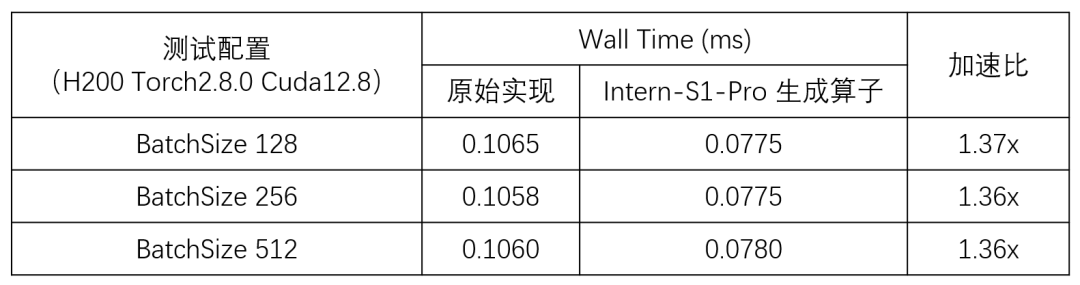
表1
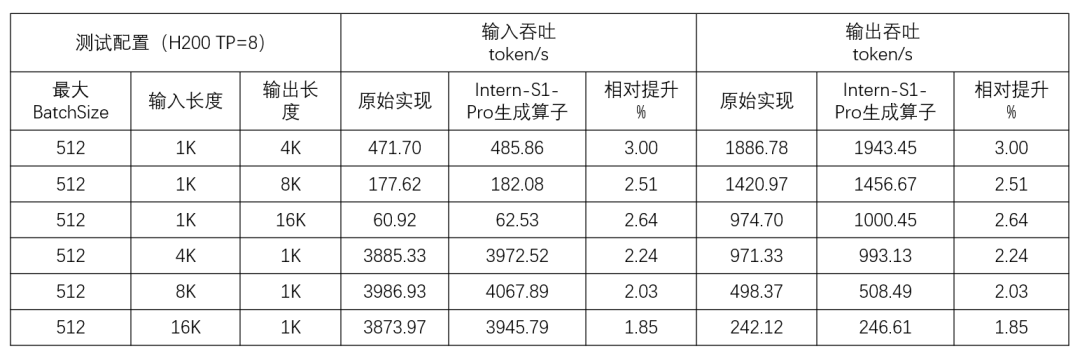
表2
强强联合:TurboMind 正式支持 LLM-Compressor
广受大家喜爱的 TurboMind 引擎现已正式支持 vLLM-Project 推出的 LLM-Compressor 量化模型推理,实现了两者优势的强强联合:在保持模型精度的同时,量化技术与推理优化的结合显著提升了推理速度;同时,量化后的模型大幅降低了内存占用,让更多开发者能够在消费级硬件上运行大模型;此外,部署体验也更加简便,无需复杂配置,即开即用即可享受量化模型带来的高性能优势。
算子开发一直存在门槛高、投入大、研发周期长等行业问题,LMDeploy v0.12+ 的发布,展现了大模型驱动算子自动生成在加速推理引擎演进中的重要价值。通过大模型自动生成并优化底层算子,不仅可以显著提升推理效率,也能减少工程师手动调优成本,使团队将更多资源投入到新功能研发与多硬件适配。随着算子生成能力持续进化,主流芯片将更快、更广泛地应用于大模型计算场景,进一步推动模型与硬件协同创新的生态发展。
在一系列技术突破的基础上,书生大模型工具链研发团队将持续开源 LMDeploy 相关工作,希望为学术界与工业界提供高效、稳定、可扩展的推理部署解决方案。目前 LMDeploy 已和 DeepLink 团队、沐曦开展紧密合作,利用 Intern-S1-Pro 的算子生成能力,结合 DLCompiler(深度学习编译器)与芯片厂商原生语言开发能力,共同推动 LMDeploy 成为国产芯片生态中稳定易用的大模型基础设施。
未来,在研究范式创新及模型能力提升的基础上,上海AI实验室将持续推进书生大模型及其全链条工具体系的开源,支持免费商用,同时提供线上开放服务,与各界共同拥抱更广阔的开源生态,共促大模型产业繁荣。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 9
9 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)