Agentic RAG 框架实战教程(非常详细),让大模型自己决定怎么检索!
讲道理,2026 年了,大家还在用那套老掉牙的 RAG 方法——要么就是一股脑把检索到的文档全塞给模型,要么就是提前写好流程让模型按部就班地执行。这就好比你去图书馆找资料,要么馆员直接给你扔一堆书(管你需不需要),要么给你一张固定的找书流程图(第一步去A区,第二步去B区...)。

研究背景
“
RAG 遇到瓶颈,该让模型自己做主了
讲道理,2026 年了,大家还在用那套老掉牙的 RAG 方法——要么就是一股脑把检索到的文档全塞给模型,要么就是提前写好流程让模型按部就班地执行。这就好比你去图书馆找资料,要么馆员直接给你扔一堆书(管你需不需要),要么给你一张固定的找书流程图(第一步去A区,第二步去B区…)。
但现在的大模型,像 GPT-5、Claude Opus 这些,推理能力和工具使用能力都已经这么强了,为啥还要被这种"死板"的 RAG 系统限制住?模型明明可以根据问题灵活调整检索策略,但传统 RAG 就是不给这个机会。
这篇论文的作者团队(来自中国科技大学和 Metastone Technology)就看不下去了,直接提出了 A-RAG(Agentic RAG) 框架。核心思路就一句话:把检索的决策权交还给模型,让它像个真正的 Agent 一样自主探索知识库。
他们做了个对比实验,结果发现即使是最简单的 Agentic RAG(只给模型一个嵌入搜索工具),性能也能吊打传统方法。在 HotpotQA、MuSiQue 这些多跳问答数据集上,A-RAG 的准确率比传统方法高出 10-20 个百分点,而且用的检索 token 还更少!
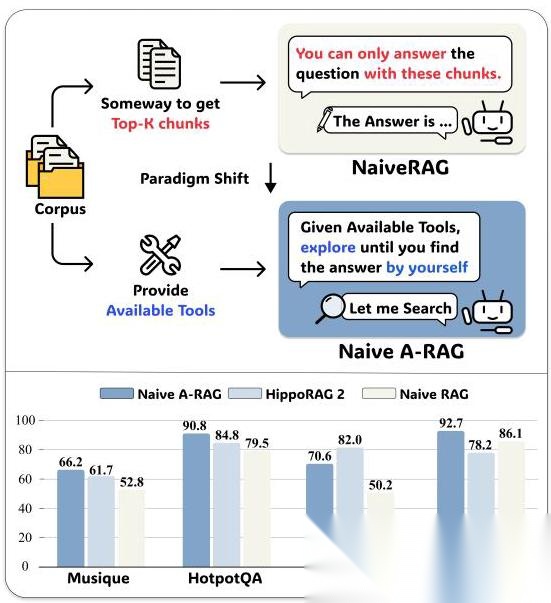
看这个图就明白了,左边是传统 RAG(“你只能用这些文档回答”),右边是 A-RAG(“给你工具,自己探索去”),性能差距一目了然。
相关工作
“
三大 RAG 流派,只有 A-RAG 是真 Agent
作者把现有的 RAG 方法分成了三大流派,并且定义了"真正的 Agentic 系统"必须满足三个原则:
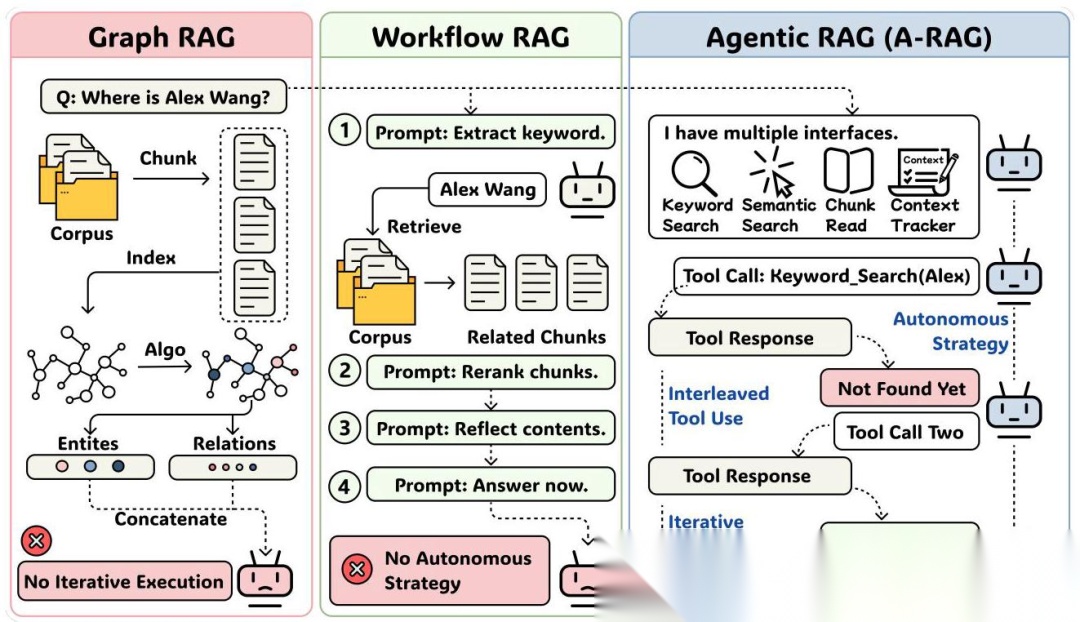
1. Basic RAG / Graph RAG
这类方法的核心是"算法决定一切"。比如微软的 GraphRAG 会构建知识图谱,RAPTOR 搞递归摘要树,HippoRAG 模仿海马体记忆机制。听起来很高级,但问题是:检索策略在设计阶段就定死了,模型只能被动接受检索结果,没法根据任务特点灵活调整。
就好比你去餐厅,菜单都是厨师提前定好的,你只能从里面选,想吃点特别的?对不起,没有。
2. Workflow RAG
这类方法看起来像 Agent 了,比如 FLARE(置信度低时触发检索)、IRCoT(推理和检索交替进行)、MA-RAG(多智能体协作)。但本质上还是"按流程办事",模型虽然能多轮交互,但每一步该做什么都是预先定义好的。
这就像你去图书馆,馆员给了你一张详细的找书流程图:“先去历史区找关键词,再去文学区找相关书籍,最后去工具书区核对信息”。流程是灵活了,但还是不够自主。
3. A-RAG(真正的 Agentic RAG)
A-RAG 的核心理念是:给模型提供分层检索工具,让它自己决定怎么用。就像给你一个图书馆的完整权限——你可以用关键词索引快速定位,可以用语义搜索找相关内容,还可以直接调阅完整文档。什么时候用哪个工具、检索多少轮、什么时候停止,全由模型自己判断。
作者总结了三个"真 Agent"的标准:
- 自主策略(Autonomous Strategy):模型能根据任务特点选择不同的检索策略
- 迭代执行(Iterative Execution):可以多轮检索,不断补充信息
- 交错工具使用(Interleaved Tool Use):推理和工具调用可以灵活穿插
只有 A-RAG 三个都满足,其他方法都有缺陷。
核心方法
“
三层检索接口,让模型"随心所欲"
A-RAG 的设计非常简洁,核心就是提供三个不同粒度的检索工具: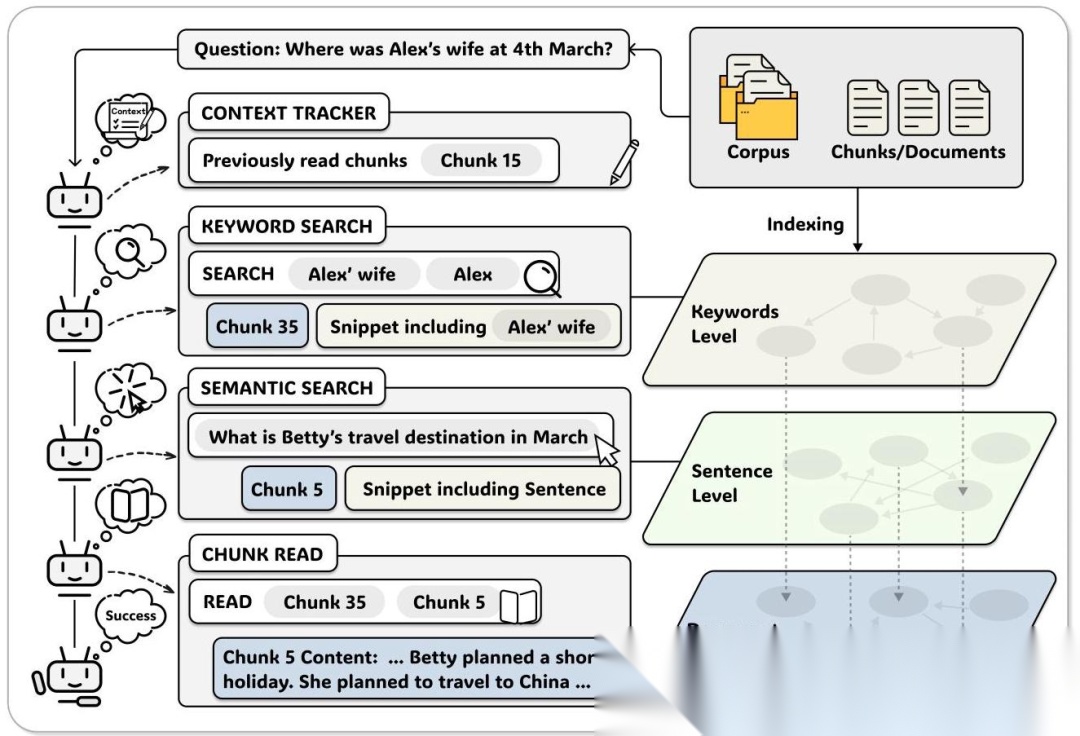
1. 关键词搜索(Keyword Search)
这个工具做精确匹配,适合找特定实体或术语。比如你要找"Alex Wang",关键词搜索就能快速定位包含这个名字的文档块。
相关性得分的计算公式是:
其中 是关键词 在文档块 中出现的次数, 是关键词的字符长度(越长的关键词权重越高,因为更具体)。
返回结果不是完整文档,而是包含关键词的句子片段(snippet),让模型快速判断是否相关。
2. 语义搜索(Semantic Search)
这个工具做语义匹配,适合找相关但不完全一致的内容。比如你问"Alex 的妻子 3 月去了哪里",关键词搜索可能找不到(因为文档里写的是"Betty 计划去中国旅行"),但语义搜索能通过向量相似度找到相关句子。
相似度计算公式是经典的余弦相似度:
同样返回 snippet,不是完整文档。
3. 文档块读取(Chunk Read)
前两个工具返回的都是"预览",如果模型觉得某个文档块值得深入了解,就可以用这个工具读取完整内容。模型还可以读取相邻文档块,补充上下文信息。
索引构建:轻量且高效
整个索引构建过程非常简单:
- 把语料库切成 1000 token 左右的文档块(chunk)
- 每个块再拆成句子,用预训练的 sentence encoder 生成向量
- 关键词层面不预先建索引,直接在查询时做文本匹配
这样做的好处是索引成本低,而且避免了 Graph RAG 那种复杂的知识图谱构建过程。
Agent 循环设计:简单但有效
作者特意用了最简单的 ReAct 框架(推理-行动交替),每轮只调用一个工具,观察结果后再决定下一步。这样做是为了排除复杂设计的干扰,纯粹看接口设计的效果。
还有个小细节很聪明:他们加了个 Context Tracker,记录哪些文档块已经读过了。如果模型想重复读取,系统直接返回"这个块你已经读过了",避免浪费 token。
实验效果
“
全面碾压,而且更省 token
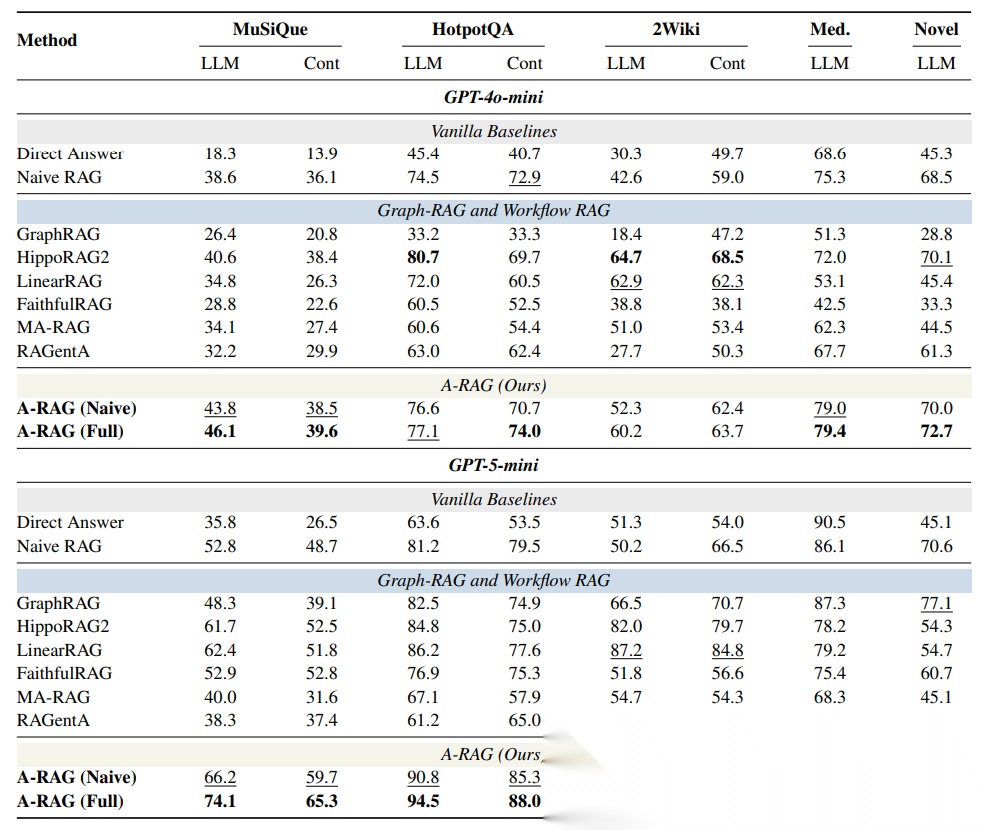
作者在四个多跳问答数据集上做了测试,用 GPT-4o-mini 和 GPT-5-mini 作为骨干模型,结果非常炸裂:
主要发现
- 传统 Naive RAG 依然是个强基线
在统一评测设置下(用 GPT-5-mini 做评判、用 Qwen3-Embedding 做检索),简单的 Naive RAG 表现居然还不错。很多 Graph RAG 和 Workflow RAG 方法都没能稳定超过它。 - 即使是 Naive A-RAG 也能碾压传统方法
A-RAG (Naive) 只配了一个语义搜索工具,但在多个数据集上都超过了 GraphRAG、HippoRAG2、LinearRAG 这些复杂方法。而且用 GPT-5-mini 后优势更明显,说明模型越强,Agentic 范式的优势越大。 - 完整版 A-RAG 全面领先
- 在 GPT-4o-mini 上,A-RAG (Full) 在 5 个数据集中的 3 个拿到最佳成绩
- 在 GPT-5-mini 上,A-RAG (Full) 全部数据集第一
- MuSiQue 数据集上,准确率从 Naive RAG 的 52.8% 提升到 74.1%,提升了 21 个百分点!
更高效的 token 使用
更神奇的是,A-RAG 不仅准确率高,用的 token 还更少。对比数据:
- Naive RAG 平均检索 5000+ token
- A-RAG (Naive) 检索了 20000-50000+ token(因为没有分层接口,只能反复检索完整文档)
- A-RAG (Full) 只检索 2000-7000 token,比传统方法更少,但效果更好
这证明了分层接口的威力:模型可以先看 snippet 判断相关性,只对真正需要的文档深入阅读,避免了无效信息的干扰。
消融实验:三个工具缺一不可
作者分别去掉了关键词搜索、语义搜索和文档块读取,发现:
- 去掉任何一个工具都会导致性能下降
- 去掉文档块读取(直接返回完整文档)性能也会下降,说明"先看 snippet 再决定是否深入"的设计很关键
测试时计算扩展性
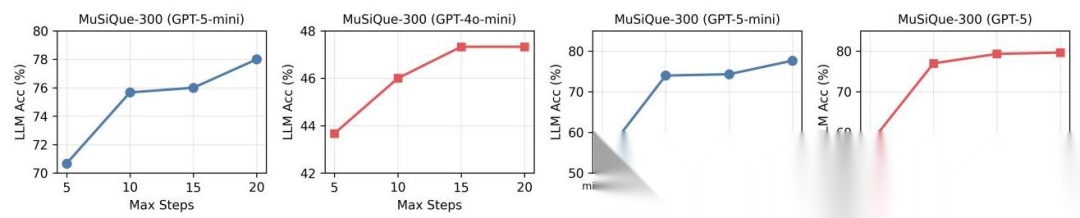
作者还测试了增加推理步数和推理努力程度的效果:
- 从 5 步增加到 20 步,GPT-5-mini 提升 8%,GPT-4o-mini 只提升 4%(说明强模型更能利用长探索)
- 推理努力从 minimal 到 high,性能提升 25%
这说明 A-RAG 能很好地利用测试时计算资源,是个很有前景的扩展方向。
失败案例分析
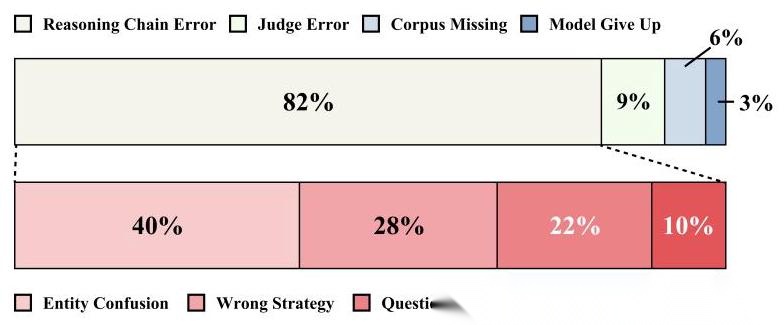 作者手动分析了 100 个错误案例,发现主要问题是:
作者手动分析了 100 个错误案例,发现主要问题是:
- 实体混淆(最常见):模型把相似实体搞混了
- 检索策略错误:选错了工具或检索时机
- 问题理解错误:没理解问题的真实意图
这些问题其实是模型推理能力的限制,而不是框架设计的问题。
论文总结
“
把决策权还给模型,才是 RAG 的未来
一句话概括:A-RAG 通过设计分层检索接口(关键词、语义、文档块三个粒度),让大模型像真正的 Agent 一样自主探索知识库,在多跳问答任务上全面超越传统 RAG 方法,而且更省 token、更能利用测试时计算资源。
作者的核心洞察很简单:与其设计复杂的检索算法,不如设计好用的检索接口,让模型自己决定怎么检索。就像给程序员提供好的 API 比写死的脚本更有用一样。
这个工作的意义在于,它指明了 RAG 的一个新方向:不要再纠结于"怎么设计更好的检索流程",而是应该思考"怎么给模型提供更灵活的检索工具"。随着大模型推理能力和工具使用能力的提升,Agentic RAG 的优势会越来越明显。
代码和评测套件已经开源,地址在:https://github.com/Ayanami0730/arag
核心代码如下:
"""Base agent implementation for ARAG."""import jsonfrom typing import Any, Dict, List, Optionalimport tiktokenfrom arag.core.context import AgentContextfrom arag.core.llm import LLMClientfrom arag.tools.registry import ToolRegistryclass BaseAgent: """Base agent with tool calling capabilities.""" def __init__( self, llm_client: LLMClient, tools: ToolRegistry, system_prompt: str = None, max_loops: int = 10, max_token_budget: int = 128000, verbose: bool = False, ): self.llm = llm_client self.tools = tools self.system_prompt = system_prompt or "You are a helpful assistant." self.max_loops = max_loops self.max_token_budget = max_token_budget self.verbose = verbose self.tokenizer = tiktoken.encoding_for_model("gpt-4o") def _calculate_message_tokens(self, messages: List[Dict[str, Any]]) -> int: total = len(self.tokenizer.encode(self.system_prompt)) for msg in messages: content = msg.get("content", "") if content: total += len(self.tokenizer.encode(str(content))) return total def _force_final_answer(self, messages: List[Dict[str, Any]], context: AgentContext, total_cost: float, reason: str) -> tuple: """Force the model to give a final answer when limits are reached.""" force_prompt = ( "You have reached the limit. " "You MUST now provide a final answer based on the information you have gathered so far. " "Do NOT call any more tools. Synthesize the available information and respond directly." ) messages.append({"role": "user", "content": force_prompt}) try: response = self.llm.chat(messages=messages, tools=None, temperature=0.0) total_cost += response["cost"] final_answer = response["message"].get("content", "") if self.verbose: print(f"Forced answer: {final_answer[:200]}...") print(f"Total cost: ${total_cost:.6f}") except Exception as e: if self.verbose: print(f"Error getting forced answer: {e}") final_answer = f"Error: {reason} and failed to generate final answer." return final_answer, total_cost def run(self, query: str) -> Dict[str, Any]: context = AgentContext() messages = [ {"role": "system", "content": self.system_prompt}, {"role": "user", "content": query}, ] trajectory = [] total_cost = 0.0 loop_count = 0 tool_schemas = self.tools.get_all_schemas() if self.verbose: print(f"\n{'='*60}") print(f"Question: {query}") print(f"{'='*60}\n") for loop_idx in range(self.max_loops): loop_count = loop_idx + 1 current_tokens = self._calculate_message_tokens(messages) if current_tokens > self.max_token_budget: if self.verbose: print(f"Token budget exceeded ({current_tokens} > {self.max_token_budget}), forcing answer...") final_answer, total_cost = self._force_final_answer( messages, context, total_cost, "Token budget exceeded" ) return { "answer": final_answer, "trajectory": trajectory, "total_cost": total_cost, "loops": loop_count, "token_budget_exceeded": True, **context.get_summary() } if self.verbose: print(f"Loop {loop_count}/{self.max_loops} (Tokens: {current_tokens}/{self.max_token_budget})") try: response = self.llm.chat(messages=messages, tools=tool_schemas) except Exception as e: if self.verbose: print(f"LLM error: {e}") break total_cost += response["cost"] message = response["message"] messages.append(message) if self.verbose and message.get("content"): print(f"Assistant: {message['content'][:200]}...") tool_calls = message.get("tool_calls") if not tool_calls: # No tool calls - agent is done final_answer = message.get("content", "") return { "answer": final_answer, "trajectory": trajectory, "total_cost": total_cost, "loops": loop_count, **context.get_summary() } # Execute tool calls for tc in tool_calls: func_name = tc["function"]["name"] try: func_args = json.loads(tc["function"]["arguments"]) except json.JSONDecodeError: func_args = {} if self.verbose: print(f"Tool: {func_name}") print(f" Args: {func_args}") try: tool_result, tool_log = self.tools.execute(func_name, context, **func_args) except Exception as e: tool_result = f"Error executing tool: {str(e)}" tool_log = {"retrieved_tokens": 0, "error": str(e)} if self.verbose: output_preview = tool_result[:300] + "..."if len(tool_result) > 300 else tool_result print(f" Result: {output_preview}") if tool_log.get("retrieved_tokens", 0) > 0: print(f" Tokens: {tool_log['retrieved_tokens']}") print() messages.append({ "role": "tool", "tool_call_id": tc["id"], "content": tool_result, }) # Record trajectory (same format as original A-RAG) traj_entry = { "loop": loop_count, "tool_name": func_name, "arguments": func_args, "tool_result": tool_result, **tool_log # includes retrieved_tokens, chunks_found, etc. } trajectory.append(traj_entry) # Max loops reached - force final answer if self.verbose: print(f"Max loops reached ({self.max_loops}), forcing answer...") final_answer, total_cost = self._force_final_answer( messages, context, total_cost, "Maximum loops exceeded" ) return { "answer": final_answer, "trajectory": trajectory, "total_cost": total_cost, "loops": loop_count, "max_loops_exceeded": True, **context.get_summary() }
这份代码实现了一个典型的 ReAct(Reasoning and Acting)循环架构,是当前 Agent 开发的最底层逻辑。它通过一个 for 循环让模型在“思考”与“行动”之间往复,核心控制力体现在对边界条件的严苛把控:代码引入了 tiktoken 实时监测 Token 消耗,并设定了 max_loops 硬性上限,防止 Agent 在复杂任务中陷入无限死循环或高昂的成本黑洞。
其运行精髓在于动态调度与兜底机制。在每一轮循环中,模型根据当前上下文决定是直接输出答案还是调用 ToolRegistry 中的工具;若触发工具调用,系统会自动执行函数并将结果喂回上下文。最亮眼的设计是 _force_final_answer 方法——当循环或预算触顶时,它会发送一条“最后通牒”式指令,强迫模型停止折腾并基于现有碎片信息整合出最终结论,确保了工程化应用中的系统稳定性与确定性。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献654条内容
已为社区贡献654条内容

所有评论(0)