这8个工具能让你 24 小时内,一个人活成一支 AI 技术团队
它能把代码转译成框架无关的中间表示,让你可以用 PyTorch 写代码,然后在 TensorFlow 的后端上运行,或者反之。这通常是因为“数据漂移”(Data Drift),带清都亡了,你的模型还在搞反清复明那一套。做 AI 开发的时候,好不容易找到一篇绝佳论文,代码是 PyTorch 写的,而基础设施全套是 TensorFlow。两周前训练出一个准确率 95% 的模型,今天想复现,却死活想不起
收藏工具是很多开发者的习惯。在 GitHub 上点 Star,然后放进收藏夹吃灰,好像这样就能自动拥有了这种能力
没错,就跟减肥健身一样,收藏了=做过了,吓吓身上的肥肉。
当大多数人还在手动写 CRUD、用肉眼盯着模型训练、在繁杂的项目文档中溺水时,极少数大聪明就开始用工具构建了自动化体系。
如果在 24 小时内部署好这8个工具,就会彻底告别低效的体力劳动。
Ivy
解决痛点:深度学习框架的生殖隔离

做 AI 开发的时候,好不容易找到一篇绝佳论文,代码是 PyTorch 写的,而基础设施全套是 TensorFlow。重写模型需要一周,放弃又不甘心。
这时候 Ivy 就能派上用场了,它是一个机器学习框架的转换器(Transpiler)。它能把代码转译成框架无关的中间表示,让你可以用 PyTorch 写代码,然后在 TensorFlow 的后端上运行,或者反之。它打破了框架之间的壁垒,让复用开源模型变得不再痛苦。
安装方式:
pip install ivyMLflow
解决痛点:实验过程的失忆
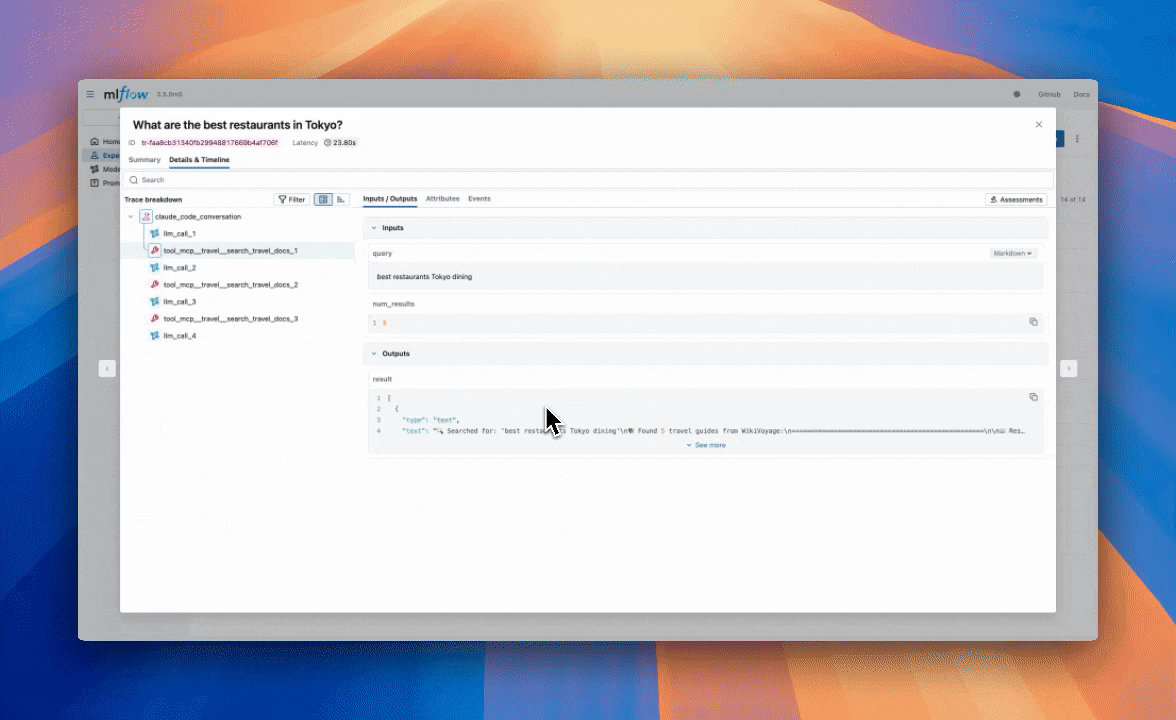
两周前训练出一个准确率 95% 的模型,今天想复现,却死活想不起当时的参数是 0.01 还是 0.001。老祖宗说的好,好记性不如烂笔头。
MLflow 就是全自动烂笔头,它能记住所有东西。它不干涉怎么写模型,只负责记录。它会追踪每一次实验的代码版本、数据哈希、超参数设置和最终指标。当项目变得复杂时,它是保证实验可追溯、模型可复现的基础设施。
安装方式:
pip install mlflowEvidently
解决痛点:模型上线后的数据漂移
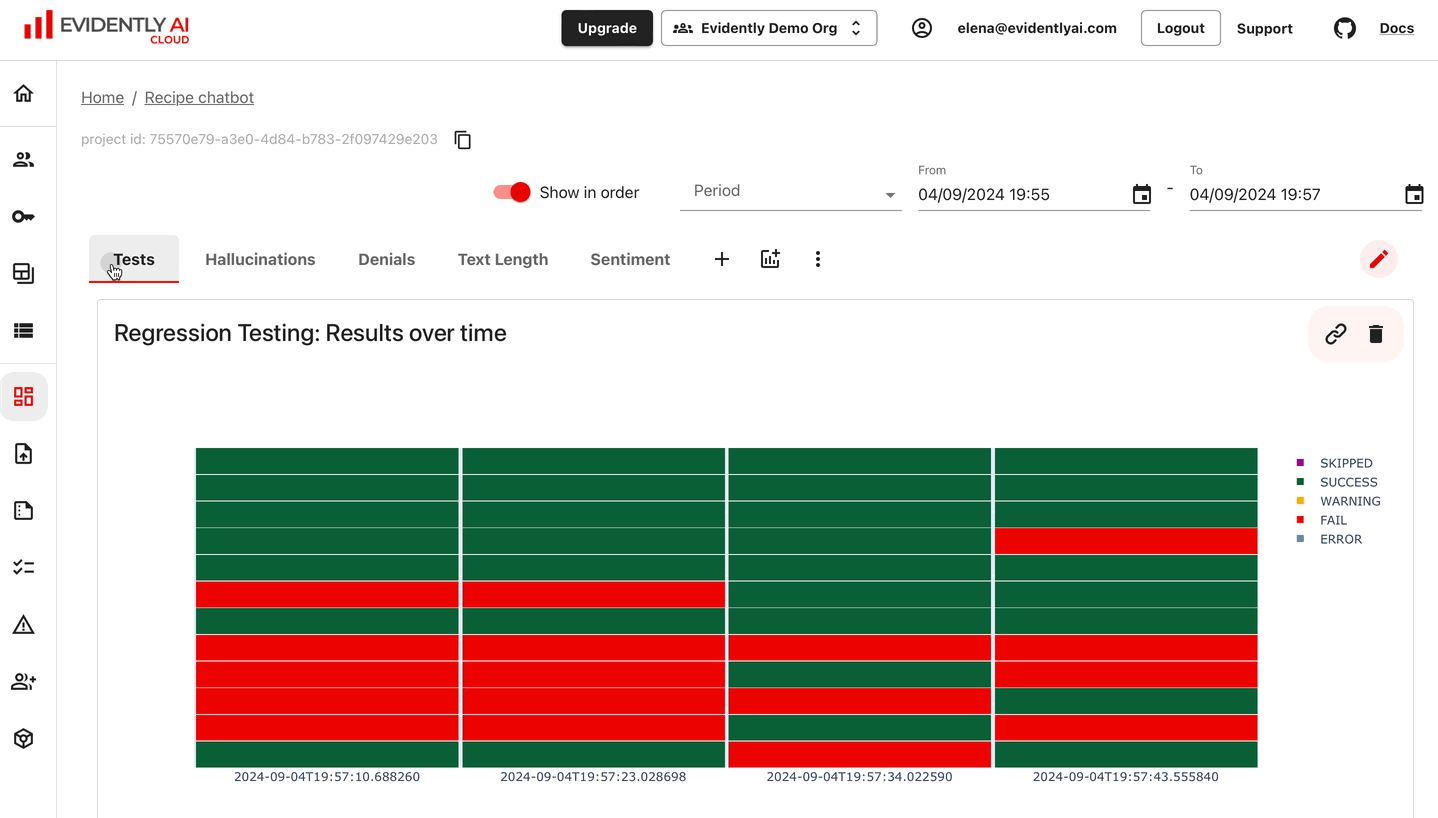
模型在训练集上准确率 99%,上线一个月后效果却莫名其妙下降。这通常是因为“数据漂移”(Data Drift),带清都亡了,你的模型还在搞反清复明那一套。
Evidently 专门用来监控这种现象。它不看 CPU 内存,只看数据。它通过对比训练数据和线上实时数据的分布差异,生成直观的报告。一旦发现输入特征发生偏移,或者模型预测倾向出现异常,它能立刻发出警报。这是防止 AI 系统在生产环境中撒谎的必要工具。
安装方式:
pip install evidentlyPrefect
解决痛点:脆弱的 Crontab 和胶水代码
很多数据流水线最初只是几个 Python 脚本,用 Crontab 定时跑。一旦任务失败、依赖卡死或者需要重试,维护成本就直线上升。
Prefect 是现代化的流程编排工具。它接管调度、日志、重试和通知。原本需要写满 try-except 的脏活,现在只需要一个装饰器。让数据流转像瑞士钟表一样精准,而不是像摇摇欲坠的积木。
Huly Platform
解决痛点:项目管理工具的割裂
Linear 追任务,Slack 聊需求,Notion 记文档。每天在三个网页间切换 500 次,你的注意力就是这样被撕碎的。
Huly 是一个开源的一体化平台,把项目管理、即时通讯和知识库整合在一起。它基于 Node.js 构建,不仅能替代 Jira/Linear,还允许通过 AI 智能体来自动化处理任务流转。对于希望数据私有化且厌倦了 SaaS 订阅费的团队,这是一个极佳的替代方案。
安装方式:直接下载即可
但需要使用 npm 进行身份验证:
npm login --registry=https://npm.pkg.github.comOpenCode
解决痛点:被 IDE 插件锁死,AI 编程缺乏掌控感
市面上的 AI 编程助手都在试图把你锁死在他们的 IDE 里,强推闭源模型。你以为你在用 AI,其实你是被 AI 厂商圈养的数据工。
OpenCode (opencode.ai) 就不是这样,它是终端优先(Terminal-first)的 AI 编程智能体。它不依赖浏览器或特定编辑器,而是直接在终端里通过自然语言与代码库交互。
-
拒绝被宰:支持 75+ 种模型。用 Claude 3.5 写逻辑,用本地 Ollama 跑隐私数据,完全由你掌控。
-
双脑协作:Plan Agent 负责思考,Build Agent 负责执行,逻辑严密。
-
拒绝幻觉:深度集成 LSP,它能看懂代码结构,而不是瞎猜变量名。
对于习惯命令行、重视隐私且不想被大厂生态绑架的开发者,OpenCode 是目前最自由的替代方案。
安装方式:
npm i -g opencode-aiKrayin CRM
解决痛点:CRM 系统只进不出,缺乏生产力
销售人员最恨录入数据。一个只能记录不能产出的 CRM,就是企业的僵尸资产。
Krayin 引入了 AI 模块来提升效率:
-
内容生成:自动起草跟进邮件、整理会议纪要,销售只需简单修改即可发送。
-
智能补全:在详情页辅助填充客户信息,减少手动录入工作量。
-
上下文增强:在记录日志时,AI 能根据简短的关键词扩充成完整的业务记录。
对于熟悉 PHP 技术栈的团队,Krayin 是一个兼具灵活性和智能化的高性价比选择。
安装方式:需要PHP 8.1及以上版本;Node 8.11.3 LTS 及以上版本;还有 MySQL 或 MariaDB 数据库
composer create-project
# 找到根目录中的.env文件,并将APP_URL参数更改为您的域名。
# 另外,请在.env文件中配置邮件和数据库参数。
php artisan krayin-crm:installIDURAR
解决痛点:ERP 系统僵化,难以二开
中小企业需要 ERP/CRM,但市面上的 SaaS 软件要么太贵,要么功能太死板。IDURAR 基于 Node.js (MERN 栈),天生就是为了被修改和集成设计的。
它的 AI 集成策略非常务实:通过 API 连接外部 AI 服务。系统本身提供稳固的业务流程(销售、库存、发票),同时留出接口让开发者挂载自定义的 AI 逻辑。比如连接一个微调过的模型来分析销售数据,或者自动更新库存状态。这种松耦合设计非常适合开发者进行定制。
安装方式:需要创建 MongoDB 帐户和数据库集群
git clone https://github.com/idurar/idurar-erp-crm.git
cd idurar-erp-crm
cd backend
npm install把上面这些工具跑起来,就会发现技术栈挺杂的。
-
Ivy, MLflow, Prefect, Evidently:深度依赖 Python,且对版本敏感。
-
Huly, OpenCode, IDURAR:基于 Node.js,前后端依赖包复杂。
-
Krayin CRM:基于 PHP (Laravel),需要配置 Web Server 和数据库。
如果在本地电脑上混装这些环境,光是处理环境变量冲突、依赖打架就能折腾一天。
为了保持开发环境的纯净,可以使用 ServBay。
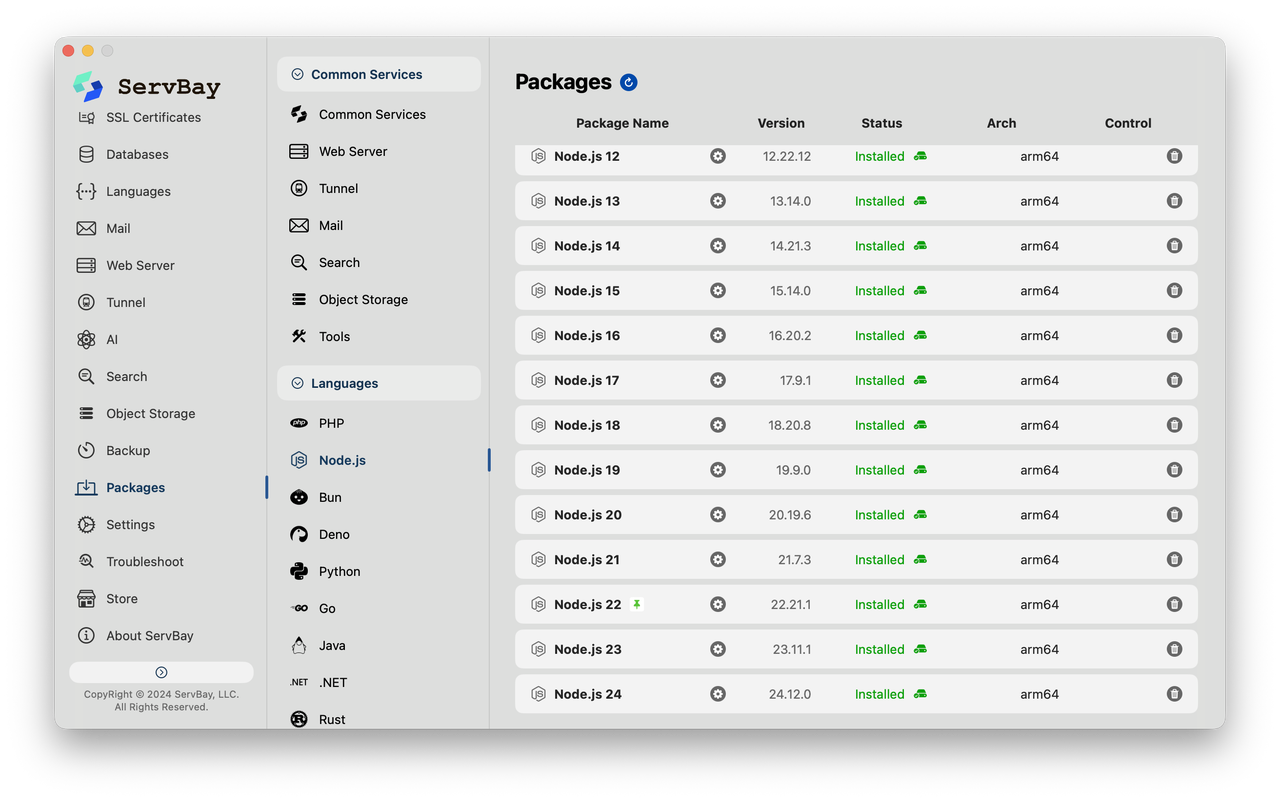
它不是虚拟机,也不需要编写 Dockerfile,主要作用就是环境隔离与快速切换。ServBay 允许在同一台机器上共存多个版本的 Python、Node.js 和 PHP。
-
想跑 Krayin?一键切换到 PHP 8.2 环境。
-
想试用 Huly?切到 Node.js 20。
-
搞深度学习?切回 Python 3.10。
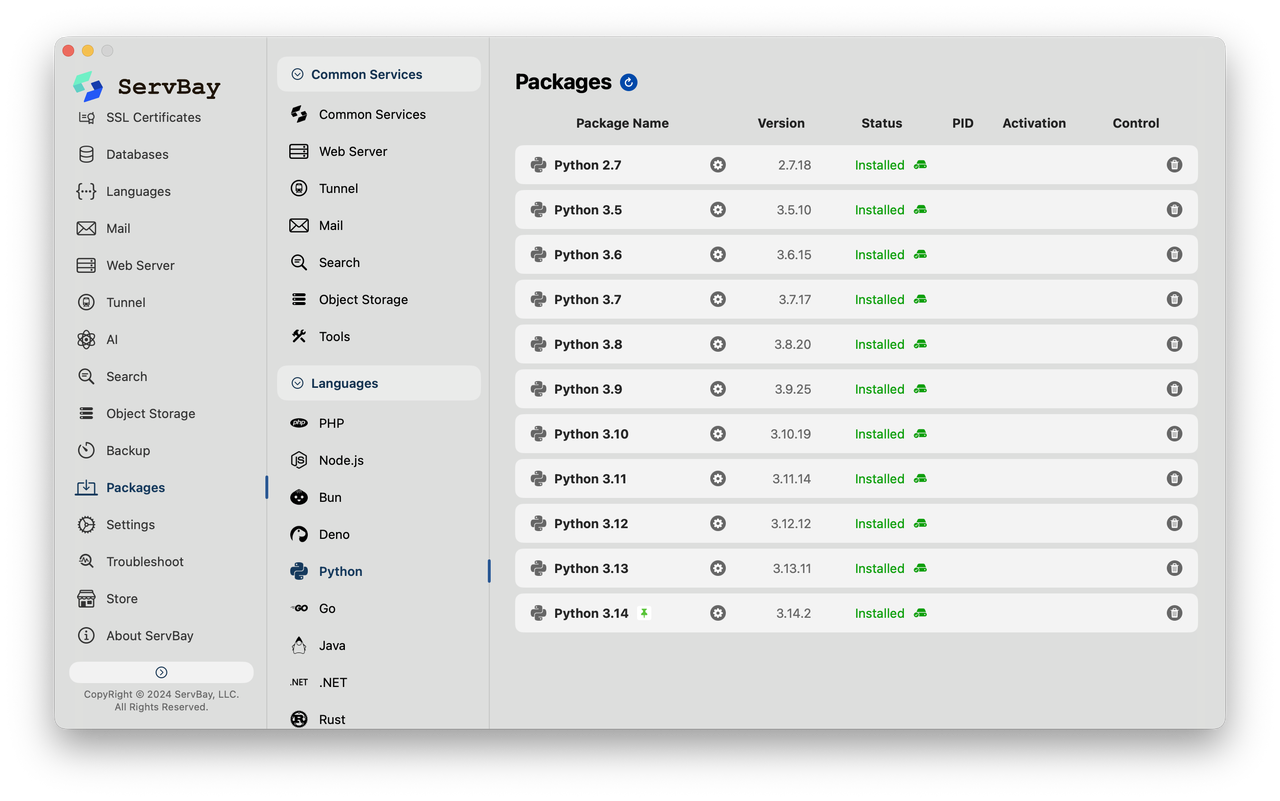
它自动处理了路径和依赖问题,让这些工具能互不干扰地运行。对于喜欢折腾各种开源项目但又不想把系统搞乱的开发者来说,这是一个非常实用的工具。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)