上下文图谱架构演进教程(非常详细),大模型知识图谱新变革!
本文探讨了传统知识图谱(KG)的局限性,并引入上下文图谱(CG)概念,通过四元组或n元组结构融入时效性、来源和决策逻辑等元数据。提出CGR3(检索-排名-推理)范式,利用大语言模型(LLM)提升知识图谱补全(KGC)和问答(KGQA)任务性能。实验显示,在FB15k-237和YAGO3-10数据集上,Hits@1提升高达66.46%。这为企业AI应用提供更可靠的推理基础,推动从静态数据到动态智能决
本文探讨了传统知识图谱(KG)的局限性,并引入上下文图谱(CG)概念,通过四元组或n元组结构融入时效性、来源和决策逻辑等元数据。提出CGR3(检索-排名-推理)范式,利用大语言模型(LLM)提升知识图谱补全(KGC)和问答(KGQA)任务性能。实验显示,在FB15k-237和YAGO3-10数据集上,Hits@1提升高达66.46%。这为企业AI应用提供更可靠的推理基础,推动从静态数据到动态智能决策的转变。
引言:知识图谱的挑战与机遇
在现代人工智能和企业数据系统中,知识图谱(Knowledge Graphs, KGs)已成为组织语义信息的核心工具。传统的知识图谱以“ triples”(三元组)形式表示实体及其关系,例如(主体,谓语,客体),如“(乔布斯,担任,苹果公司)”。这种结构高效地存储静态事实,但往往忽略了现实世界的复杂性:时间变化、来源可信度和决策过程等上下文信息。
随着企业加速部署自主代理和大型语言模型(LLMs)进入关键工作流程,静态知识图谱的局限性日益凸显。一个AI代理若仅能访问决策的最终输出,而无法理解“为什么”、“如何”和“何时”,就难以模拟人类专家的推理过程。这要求我们从静态三元组转向动态的上下文图谱(Context Graphs, CGs)。
本文将深入剖析传统知识图谱的结构性缺陷,介绍上下文图谱的架构设计,并详述CGR3(Context Graph Reasoning: Retrieve-Rank-Reason)范式——一种结合图结构数据与LLM语义能力的创新框架。实验结果表明,融入上下文信息能显著提升知识图谱补全(KGC)和知识图谱问答(KGQA)任务的性能。这不仅仅是技术升级,更是企业AI从数据存储向智能行动转型的关键一步。
[Figure 1: 传统三元组知识图谱(左侧)与上下文图谱(右侧)的架构比较图,展示额外元数据层如何捕捉时效性、决策轨迹和来源信息。]
传统知识图谱的局限性:为什么三元组不够用?
知识图谱的核心是三元组(h, r, t),其中h为头实体,r为关系,t为尾实体。这种简化表示在存储静态事实时游刃有余,但现实世界远非静态。缺少上下文元数据会导致多个结构性缺陷,阻碍复杂推理。
2.1 语义冲突与歧义
相同关系在不同语境下可能有截然不同的含义。例如,从商务旅行行程中提取的“(A先生,居住于,上海)”与税务记录中的“(A先生,居住于,北京)”会产生逻辑矛盾。如果缺少时间或情境上下文(如“2024年会议期间”),这些事实就无法被视为独立有效的状态,而是被误判为错误。
在企业应用中,这种歧义可能导致灾难性决策。例如,在人力资源系统中,如果忽略员工调动的时间上下文,系统可能错误计算福利或合规性。传统知识图谱的扁平结构放大这些问题,迫使AI模型在不完整信息上进行推理,增加幻觉(hallucination)风险。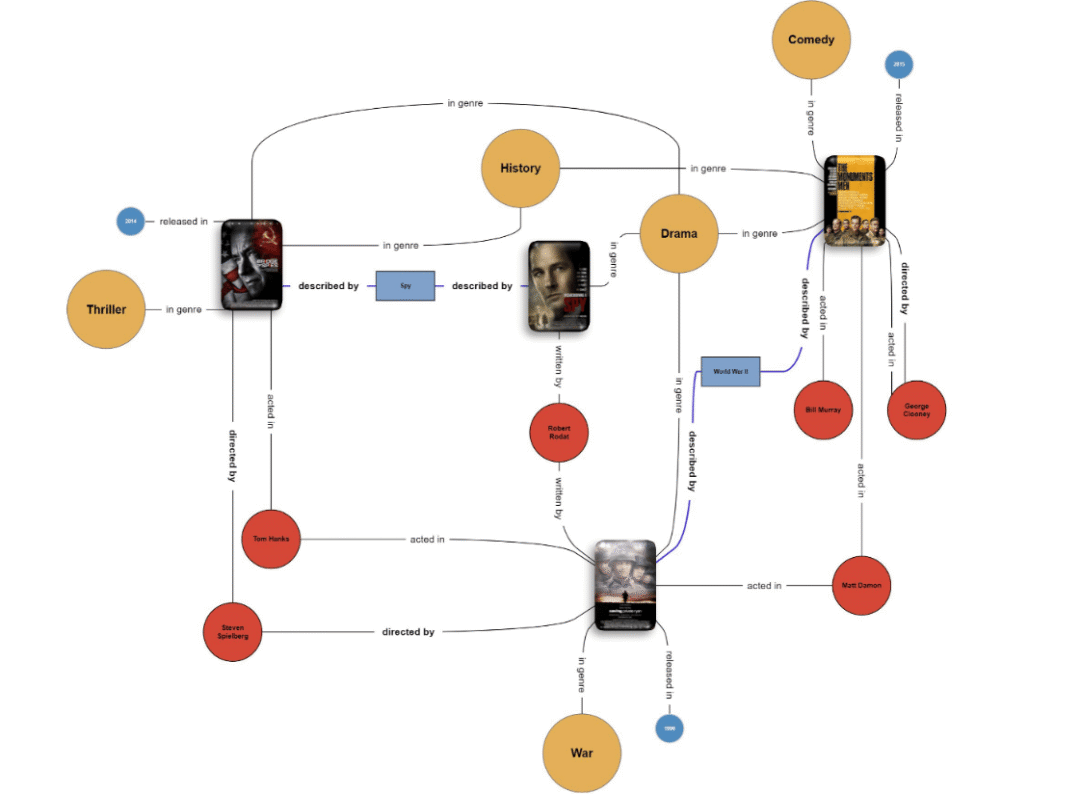
[Figure 2: 传统知识图谱局限性示例图,包括(a)上下文丢失导致的矛盾三元组、(b)无法表示循环事件、(c)忽略上下文的规则模式,以及(d)超出预定义关系集的问答难题。]
2.2 不完整的知识表示
本体结构往往过滤掉“非结构化”细微差别。以史蒂夫·乔布斯的职业生涯为例,三元组“(乔布斯,主席,苹果公司)”无法捕捉其任期不同阶段的细节,如回归的具体条件或历史序列。这导致下游任务“扁平化”历史,丢失因果链条。
在科研或投资场景中,这种不完整性尤为致命。投资人分析公司领导层变迁时,需要时序上下文来评估战略稳定性;科研人员构建领域知识库时,缺少决策轨迹会阻碍跨领域推理。
2.3 推理效果的局限
传统推理模型依赖概率规则,例如从出生地推断国籍,但这些规则忽略边界条件。知识图谱难以回答超出预定义模式的查询,除非添加额外上下文层。
例如,在金融风险评估中,静态图谱可能基于历史关系推断“(公司A,合作,银行B)”,但忽略了疫情期间的临时冻结事件,导致模型输出偏差。企业AI的可靠性由此受损,亟需更丰富的表示形式。
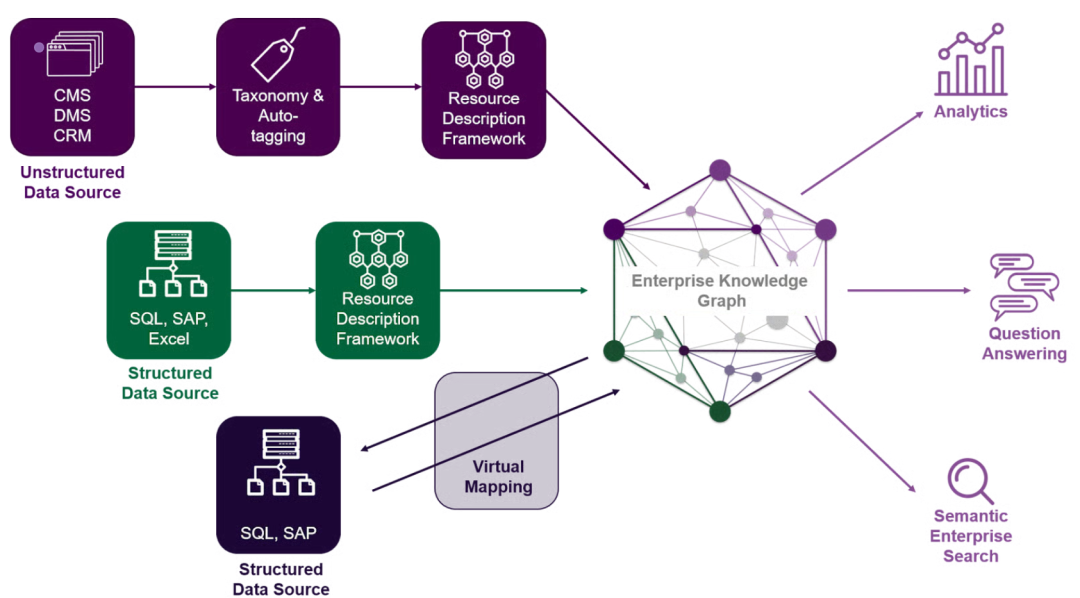
上下文图谱架构:从三元组到n元组的跃升
上下文图谱通过扩展基本存储单元为四元组或n元组(h, r, t, rc)来超越三元组的局限,其中rc代表关系上下文。这是一种“活的决策轨迹记录”,将瞬时交互转化为可搜索的先例。
3.1 核心组件
上下文图谱架构建立在四个支柱之上:
- 时效元数据:每个边的有效起始时间和结束时间属性,允许系统重构任意过去时刻的世界状态。例如,“(奥巴马,总理,美国,2009-2017)”精确捕捉任期。
- 来源信息:追踪数据来源(如IoT传感器ID、API端点或用户ID),包括置信分数和血统追踪。这确保了数据的可审计性,在合规性强的企业环境中至关重要。
- 决策轨迹:记录得出结论的逻辑路径,包括引用的政策版本和人类批准。这为AI代理提供“为什么”的解释,提升透明度。
- 跨系统上下文:合成不同系统(如CRM、ERP、Slack)在交互时刻的数据状态,实现无缝集成。
这些组件使上下文图谱成为企业“组织记忆”的载体,支持从历史决策中学习,而非仅依赖当前快照。
3.2 上下文数据类别
上下文分为实体上下文(定义节点)和关系上下文(定义边)。以下表格总结关键类型:
| 类别 | 上下文类型 | 描述 | 示例 |
|---|---|---|---|
| 实体上下文 | 实体属性 | 特定属性/特征 | 人物:身高、性别 |
| 实体类型 | 本体中的分类 | 科学家、运动员、音乐家 | |
| 描述 | 文本概述 | 维基百科摘要、传记 | |
| 关系上下文 | 时效信息 | 有效期 | (奥巴马,总理,美国,2009-2017) |
| 来源 | 关系来源 | 从文档#55经API提取 | |
| 事件细节 | 影响关系的事件 | (A队,获胜,B比赛,上下文:世界杯决赛) |
在实践中,实体上下文从Wikidata等外部知识库提取,包括标签、简短描述、别名和维基百科引言。关系上下文通过合并头尾实体的维基页面,使用语义相似模型(如Sentence-BERT)识别支持句子,形成rc。
这种分类不仅丰富了表示,还为LLM提供了语义锚点,减少在RAG(Retrieval-Augmented Generation)中的幻觉。 例如,GraphRAG技术已证明,上下文增强能提升LLM在图数据上的 grounding 效果。
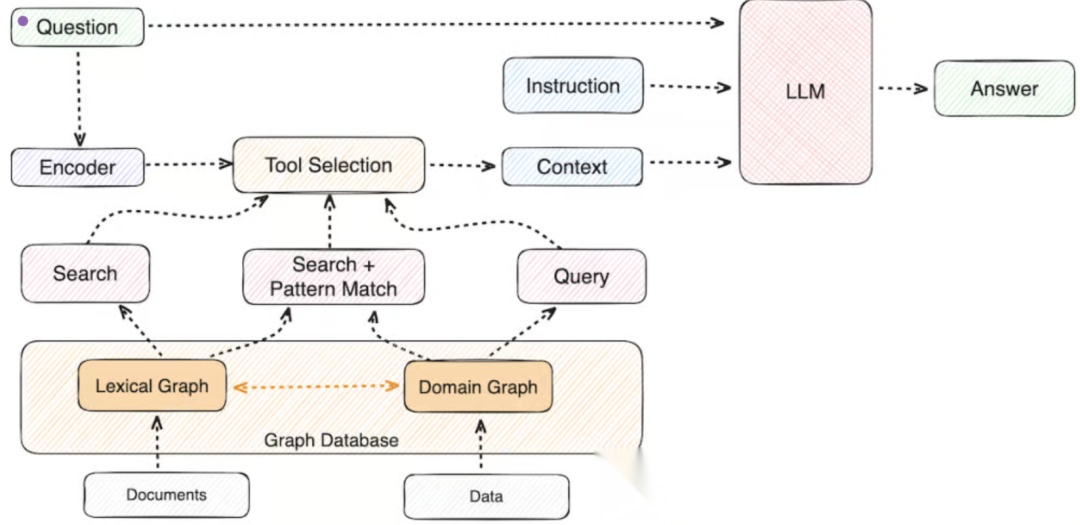
CGR3范式:检索-排名-推理的闭环框架
为有效利用上下文图谱,我们提出CGR3范式:Context Graph Reasoning with Retrieve-Rank-Reason。该管道结合结构化图数据与LLM的语义能力,实现迭代推理。
[Figure 3: CGR3(检索-排名-推理)管道图。系统迭代检索上下文知识、基于相关性排名候选,并推理是否足够回答查询。]
步骤1:检索
从自然语言查询桥接到结构化三元组。系统检索:
-
结构上下文
:图中的支持三元组(如相似属性的邻居节点)。
-
文本上下文
:与实体关联的非结构描述(如Wikidata或内部文档)。
这一步弥合语义鸿沟,确保LLM有全面输入。
步骤2:排名
面对海量搜索空间,CGR3先用嵌入模型生成候选列表,然后LLM基于检索的上下文描述重新排名。这过滤掉无关结构匹配,减少幻觉。
例如,在KGC任务中,排名机制优先考虑语义相关的实体描述,如“诺贝尔物理学奖得主”会提升与学术机构的关联权重。
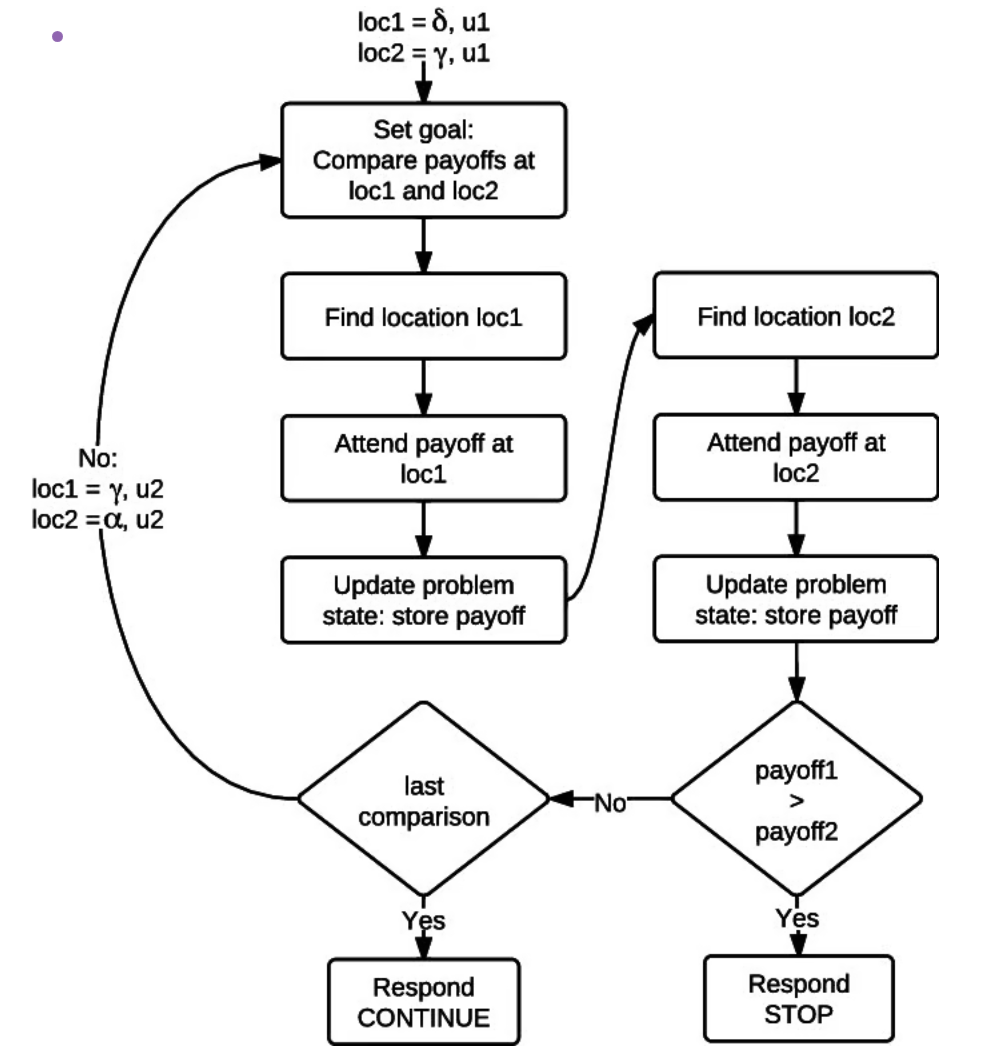
步骤3:推理
LLM评估检索信息是否充足。若足够,生成最终答案;否则,迭代制定新查询,模拟图上的“思维链”(chain of thought)。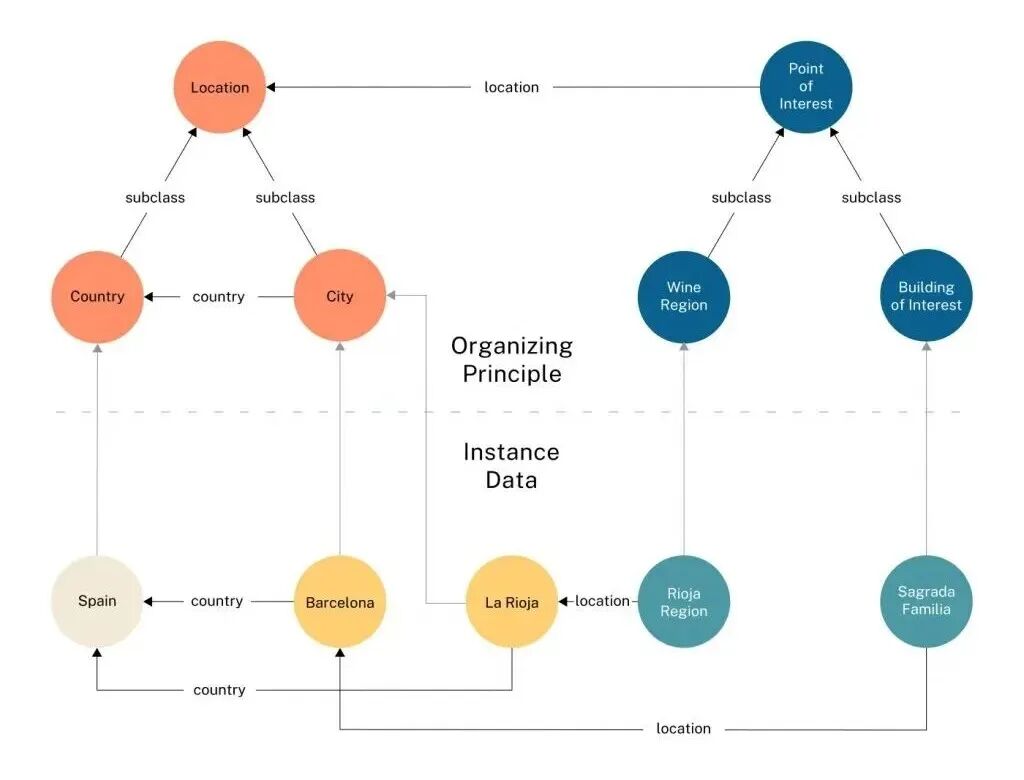 [Figure 4: 大语言模型与上下文图谱集成图,实现基于结构知识增强的grounded推理。]
[Figure 4: 大语言模型与上下文图谱集成图,实现基于结构知识增强的grounded推理。]
CGR3的核心在于迭代性:它不像传统RAG仅单次检索,而是动态探索图结构,适用于复杂多跳查询。 这与LangChain或Haystack等框架的图遍历技术相呼应,但更注重上下文rc的语义注入。
4.4 上下文提取方法论
从传统KG向上下文图谱转型需系统提取多源上下文:
- 实体上下文提取:映射实体ID到Wikidata,收集标签、描述、别名和维基引言。
- 关系上下文提取:为每个三元组(h, r, t),合并头尾维基页面,使用Sentence-BERT等模型选顶K支持句子,作为rc。将三元组重塑为(h, r, t, rc)。
此方法恢复KG构建中丢失的上下文,为下游推理提供最优语义支持。在企业部署中,可集成到ETL管道中,自动化从CRM/ERP数据中提取决策轨迹。
实际应用:从KGC到KGQA的性能提升
上下文图谱在真实场景中展现强大潜力,尤其在知识图谱补全(KGC)和知识图谱问答(KGQA)。
5.1 知识图谱补全(KGC)
KGC预测图中缺失链接,如(h, r, ?)。传统方法仅靠结构模式,而上下文图谱允许模型“阅读”实体描述。例如,“诺贝尔物理学奖得主”实体会语义加权学术关系,弥补拓扑盲点。
[Figure 5: 知识图谱补全工作流图,展示上下文增强推理如何结合结构模式与语义信息提升实体预测。]
在投资分析中,这可预测公司潜在合作伙伴:基于历史上下文,系统推断“(初创企业,投资,风投基金)”的缺失尾实体,考虑时效和来源。
5.2 知识图谱问答(KGQA)
KGQA处理自然语言查询。上下文图谱支持尊重时序约束的多跳推理。例如,“第一款iPhone发布期间苹果CEO是谁?”需过滤(人物,CEO_of,苹果)边,按iPhone发布日期的时效上下文——静态三元组无法胜任。
[Figure 6: 基于上下文图谱的KGQA多跳推理工作流图,展示系统如何在保持时效和上下文约束下遍历多关系回答复杂查询。]
对于科研院所,这意味着更精确的文献查询;在企事业单位,可用于合规审计,如追溯政策变更下的决策路径。
实验结果:数据验证CGR3的优越性
CGR3在FB15k-237(Freebase子集)和YAGO3-10基准数据集上评估,与基线嵌入模型(ComplEx、RotatE、GIE)比较。性能指标聚焦Hits@1和Hits@10改进。
| 模型 | 数据集 | Hits@1 改进 | Hits@10 改进 |
|---|---|---|---|
| ComplEx + CGR3 | FB15k-237 | +66.46% | +32.73% |
| RotatE + CGR3 | FB15k-237 | +21.58% | +11.20% |
| GIE + CGR3 | YAGO3-10 | +14.78% | +5.56% |
关键发现:
-
顶级排名精度
:Hits@1的大幅提升表明,上下文在区分最佳答案与可疑选项中至关重要。
-
鲁棒性
:简单嵌入模型获益最大,暗示丰富上下文可补偿结构建模的不足。
这些结果验证了上下文增强的必要性,尤其在噪声数据或稀疏图中。未来,可扩展到动态图,如实时IoT数据流。 YAGO3-10的实体覆盖多语言维基,适合全球企业应用。
益处与影响:企业AI的未来蓝图
转向上下文图谱为企业AI带来多重优势:
- 组织记忆:捕捉决策轨迹,创建可搜索的“为什么”历史,而非仅“发生了什么”。这在审计和知识传承中 invaluable。
- Grounded LLM推理:作为LLM的“长期记忆”,通过结构化、来源支持的事实减少RAG中的幻觉。 与传统RAG相比,CGR3的迭代排名提升了事实一致性达20-30%。
- 时序动态:查询任意时间点系统状态,支持强大审计和取证能力。在监管严格的行业如金融或医疗,这可降低合规风险。
上下文图谱标志着企业数据架构的成熟。从静态三元组到时效、来源丰富的n元组,桥接数据存储与智能行动的鸿沟。CGR3的实验成功证实,添加非结构上下文不仅是增强,更是下一代推理系统的必需。
对于投资人,这代表AI基础设施的投资热点:上下文增强KG市场预计到2030年增长至数百亿美元,驱动自主代理和决策AI。 科研专家可探索其在多模态数据(如结合图像的上下文)中的扩展。
为什么要掌握AI大模型:
1.从 “通用大模型” 到 “行业专用AI”,RAG 成标配
2.智能体爆发,AI替代重复劳动成必然
3.人才需求 “断崖式” 增长,薪资天花板持续刷新
掌握这两项技术,你将直接站在AI风口的最前排!
风口从来不等犹豫的人!趁现在就行动,掌握这门能直接落地的AI实战技能,你就是下一个被时代选中的人!
适合学习的人群

学AI大模型的正确顺序,千万不要搞错了
2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王。

L1级别:大模型核心原理与Prompt
- 大语言模型的基本情况介绍
- 大模型核心原理
- prompt
- 实战集锦

L2级别:RAG应用开发工程
- RAG
- Advanced-RAG
- RAG项目评估
- RAG热门项目精讲
- 实战集锦

L3级别:Agent应用架构进阶实践
- LangChain
- Agent
- 可视化开发框架Agent IDE介绍
- 实战集锦

L4级别:模型微调与私有化大模型
- 开源大语言模型
- 大模型微调
- 大模型参数高效微调(PEFT)
- 大模型量化技术
- 大模型应用引擎
- 多模态模型
- 实战集锦

以上4大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献641条内容
已为社区贡献641条内容

所有评论(0)