小白必看!轻松入门Transformer大模型,收藏这份学习笔记!
Transformer作为当前大语言模型的基础架构,其核心在于自注意力机制。本文从背景介绍出发,详细解析了注意力机制、多头注意力机制,深入剖析了Transformer的编码器与解码器结构,并阐述了其在并行处理、长距离依赖捕捉、注意力分布灵活性及可扩展性等方面的优势。通过本文,读者将能全面理解Transformer的工作原理,为深入学习大模型打下坚实基础。
- 一、Transformer 背景介绍
- 二、Transformer 核心概念
- 2.1、注意力机制(Attention)
- 2.2、多头注意力(Multi-head Attention)
- 三、Transformer 架构原理
- 3.1、模型结构
- 3.2、编码器
- 3.3、解码器
- 四、Transformer 的优势
- 4.1、并行处理能力
- 4.2、捕捉长距离依赖
- 4.3、灵活的注意力分布
- 4.4、可扩展性
一、Transformer 背景介绍
- Transformer 是一种基于自注意力机制的深度学习模型,诞生于 2017 年。目前大部分大语言模型,像 GPT 系列和 BERT 系列都是基于 Transformer 架构。
- Transformer 摒弃了之前序列处理任务中广泛使用的循环神经网络(RNN),转而使用自注意力层来直接计算序列内各元素之间的关系,从而有效捕获长距离依赖。这一创新设计不仅明显提高了处理速度,由于其并行计算的特性,也大幅度提升了模型在处理长序列数据时的效率。
- 看看这幅图你就明白 Transformer 在江湖中的地位了。
- Transformer 模型由编码器和解码器组成,每个部分均由多层重复的模块构成,其中包含自注意力层和前馈神经网络。接下来我们依次了解下这些模块。
二、Transformer 核心概念
2.1、注意力机制(Attention)
-
Transformer 是一个完全基于注意力机制构建的模型,它的核心思想就是:Attention Is All You Need(注意力是你所需要的全部),与之前依赖循环神经网络(RNN)或长短期记忆网络(LSTM)的模型不同,Transformer 通过自注意力机制来处理序列数据,这使得每个输出元素都能直接与输入序列中的所有元素相关联,从而有效捕获长距离依赖关系。
-
拿 AI大模型实战——深入理解Seq2Seq 文章讲的举例,在编码阶段结束后,会产生一个上下文向量,或者叫隐藏状态,解码器根据这个向量计算下一个词的概率。参考下图:
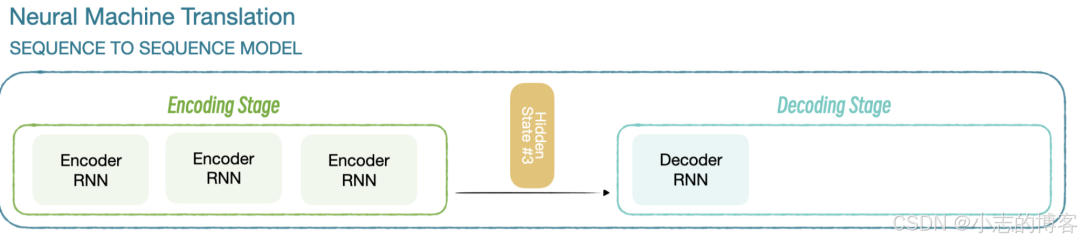
-
解码阶段参考公式:
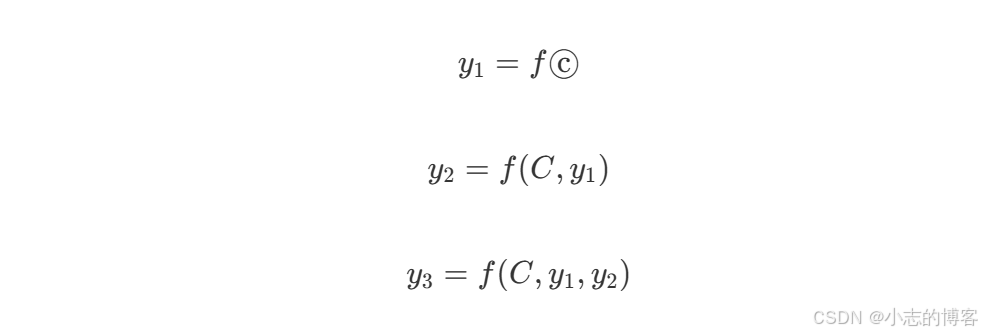
C 代表隐藏状态,解码器在不同解码阶段,仅依赖同一个隐藏状态 C。加入注意力机制后,编码器传给解码器多个隐藏状态,解码器根据不同的隐藏状态计算下一个词的概率。
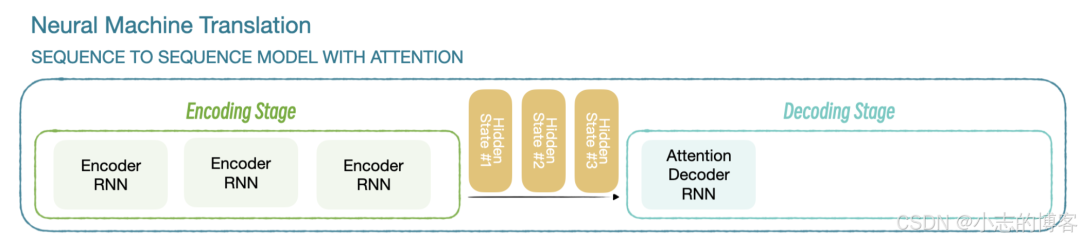
在这里插入图片描述
-
这个时候,每推测一个词之前,都会计算一下所有和这个词相关的概率,这就是注意力。我们拿 AI大模型实战——深入理解Seq2Seq 文章讲的例子说明一下。
我 喜欢 学习 机器 学习。I like studying machine learning -
在推测 machine 的时候,会先计算一下和 machine 相关的词的概率,也叫分配注意力,比如 (我,0.2)(like,0.3)(学习,0.4)(机器,0.6),这时模型就知道了下一个词和机器相关,会把注意力集中在机器上,解码阶段参考公式:
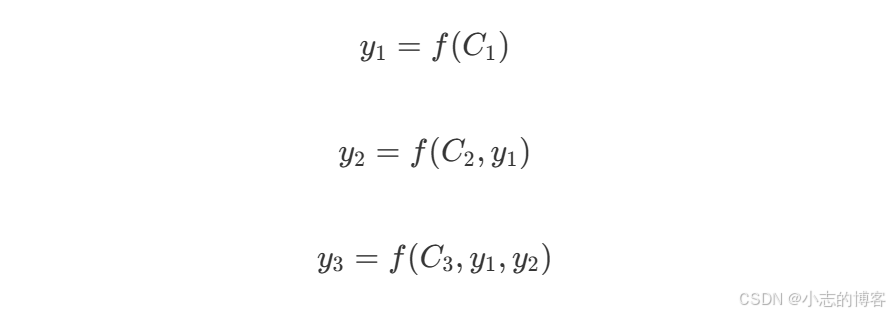
-
那这个注意力分配概率怎么来的呢?不同的论文可以有不同的做法,这里我给你讲一个通用的做法。一般分为 3 步。
2.1.1、注意力分配概率的由来
-
1、转换为查询(Query)、键(Key)和值(Value)
我们首先将输入序列中的每个词和目标词转换为三种向量表示。
查询:代表目标词的向量,用于查询与输入序列中哪些词相关。
键:代表输入序列中每个词的向量,用于被查询匹配。
值:也是代表输入序列中每个词的向量,一旦词的重要性(通过键与查询的匹配)被确定,其值向量将被用来计算最终的输出。
-
2、计算相似度
接下来,模型需要判断目标词(查询)与输入序列中每个词(键)之间的相关性。这是通过计算查询向量与每个键向量之间的点积来实现的。点积的结果越大,表示两个向量越相似,也就意味着输入中的这个词与目标词越相关。在词嵌入那节课我们讲过,具有相同意思的词,在同一个向量空间中比较接近,而点积就是衡量两个向量在方向上的一致性,正好可以用来计算向量的相似度。
-
3、 转换为注意力权重
由于点积的结果可能会非常大,为了将其转换为一个合理的概率分布,即每个词的重要性权重,我们会对点积结果应用 Softmax 函数。Softmax 能够确保所有计算出的权重加起来等于 1,每个权重的值介于 0 和 1 之间。这样,每个输入词的权重就代表了它对于目标词的相对重要性。
-
我们可以用代码来表示这个过程。
import torchimport torch.nn.functional as F# 假设我们已经有了每个词的嵌入向量,这里用简单的随机向量代替真实的词嵌入# 假设嵌入大小为 4embed_size = 4# 输入序列 "我 喜欢 学习 机器 学习" 的嵌入表示inputs = torch.rand((5, embed_size))# 假设 "machine" 的查询向量query_machine = torch.rand((1, embed_size))def attention(query, keys, values): # 计算查询和键的点积,除以根号下的嵌入维度来缩放 scores = torch.matmul(query, keys.transpose(-2, -1)) / (embed_size ** 0.5) # 应用softmax获取注意力权重 attn_weights = F.softmax(scores, dim=-1) # 计算加权和 output = torch.matmul(attn_weights, values) return output, attn_weightsoutput, attn_weights = attention(query_machine, inputs, inputs)print("Output (Attention applied):", output)print("Attention Weights:", attn_weights) -
代码输出:
Output (Attention applied): tensor([[0.4447, 0.6016, 0.7582, 0.7434]])Attention Weights: tensor([[0.1702, 0.2151, 0.1790, 0.2165, 0.2192]] -
最后两个权重 0.2165 和 0.2192 表明,machine 和结尾的两个词“机器”和“学习”最相似,也就是为计算过程赋予了注意力:要注意最后这两个词。

2.2、多头注意力(Multi-head Attention)
-
多头注意力是 Transformer 模型中的一个关键创新。它的核心思想是将注意力机制“分头”进行,即在相同的数据上并行地运行多个注意力机制,然后将它们的输出合并。这种设计允许模型在不同的表示子空间中捕获信息,从而提高了模型处理信息的能力。Transformer 默认 8 个头,其工作过程如下:
分割:对于每个输入,多头注意力首先将查询、键和值矩阵分割成多个“头”。这是通过将每个矩阵分割成较小的矩阵来实现的,每个较小的矩阵对应一个注意力“头”。假设原始矩阵的维度是 d_{model},那么每个头的矩阵维度将是 d_{model}/h ,其中 h 是头的数量。
并行注意力计算:对每个头分别计算自注意力。由于这些计算是独立的,它们可以并行执行。这样每个头都能在不同的表示子空间中捕获输入序列的信息。
拼接和线性变换:所有头的输出再被拼接起来,形成一个与原始矩阵维度相同的长矩阵。最后,通过一个线性变换调整维度,得到多头注意力的最终输出。
三、Transformer 架构原理
3.1、模型结构
- 下图出自《Attention Is All You Need》论文,大部分介绍 Transformer 的文章都会引用这张图片,接下来我将带你一步一步揭开这个架构的神秘面纱。
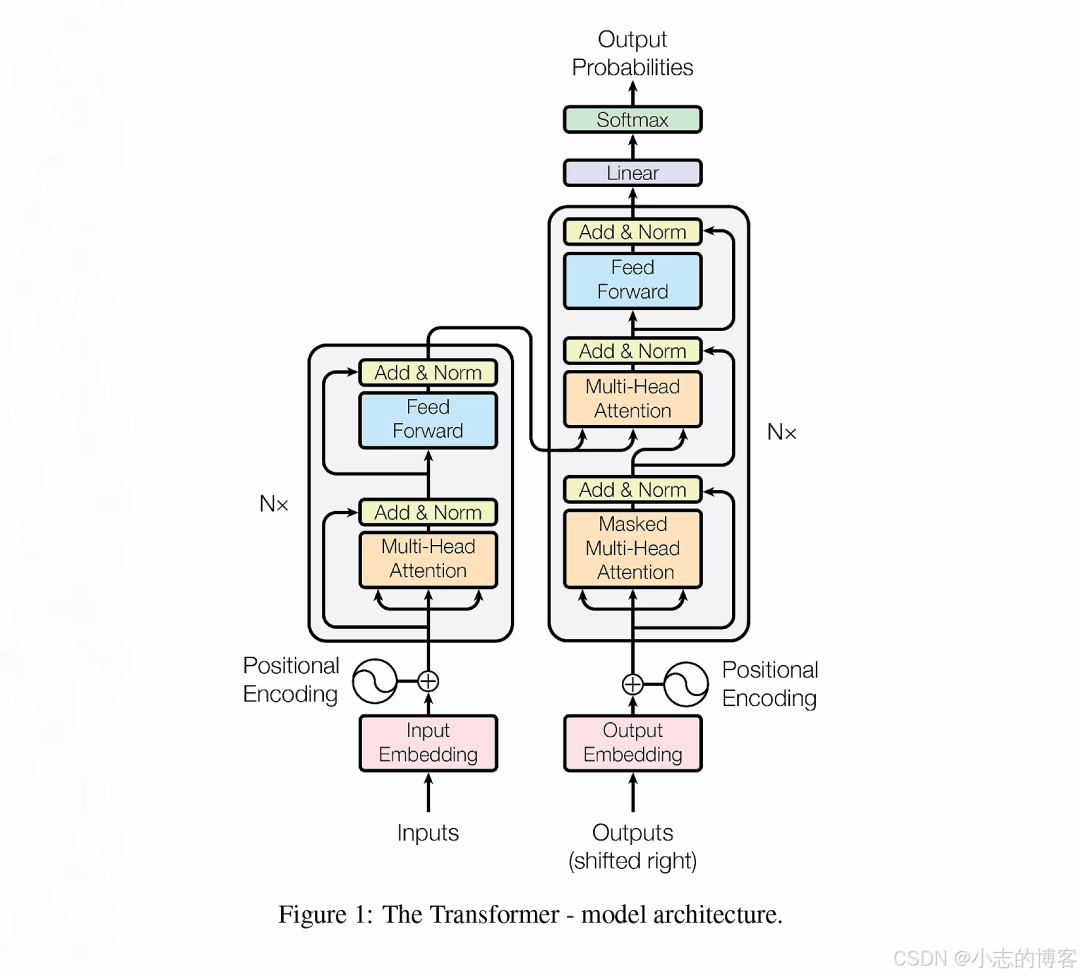
- 在 Transformer 中,编码器可以叫做编码器组,解码器也一样,叫做解码器组,就是说它们不仅仅是由一个编码器和一个解码器组成的。
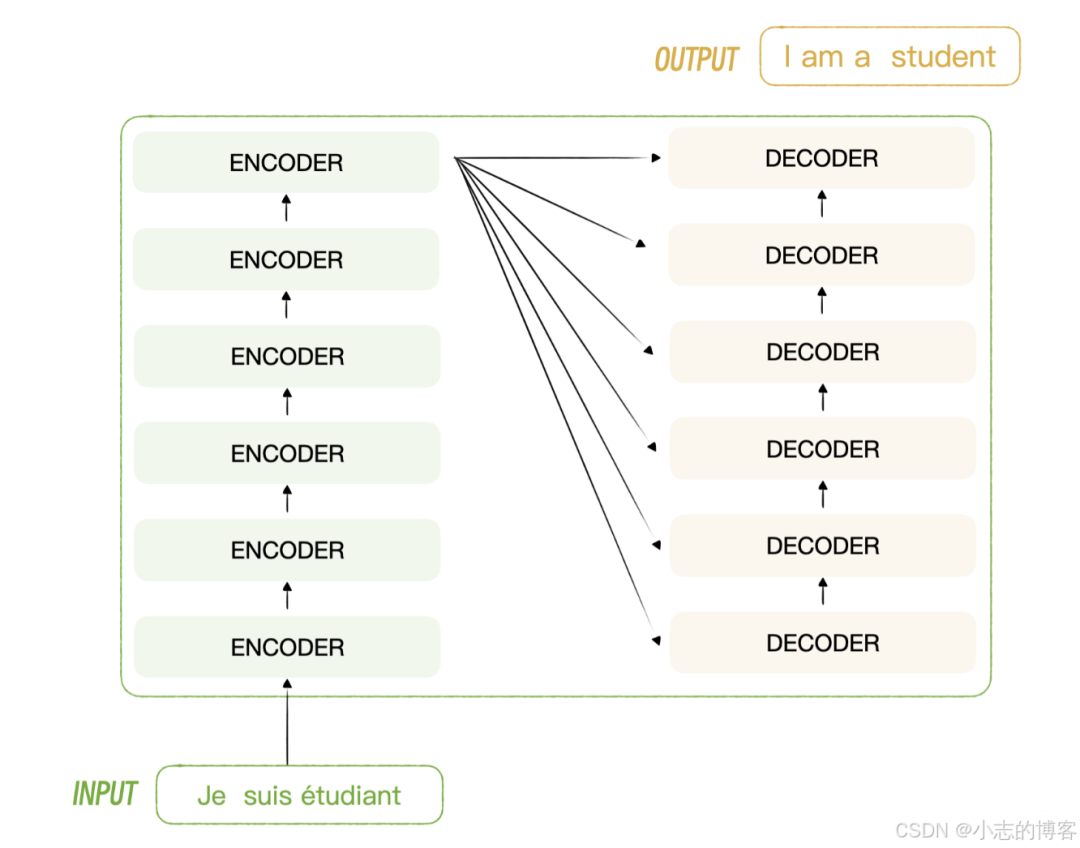
- 每一个编码器内部又分为自注意力层和前馈神经网络层,你可以看一下图示。
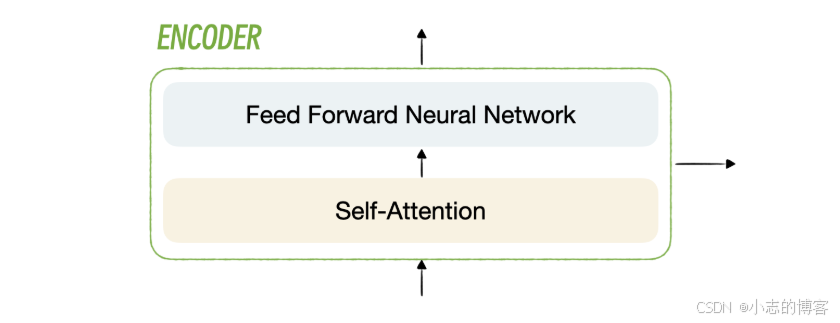
- 每一个解码器内部又分为三层:自注意力层、编码 - 解码注意力层和前馈神经网络层。
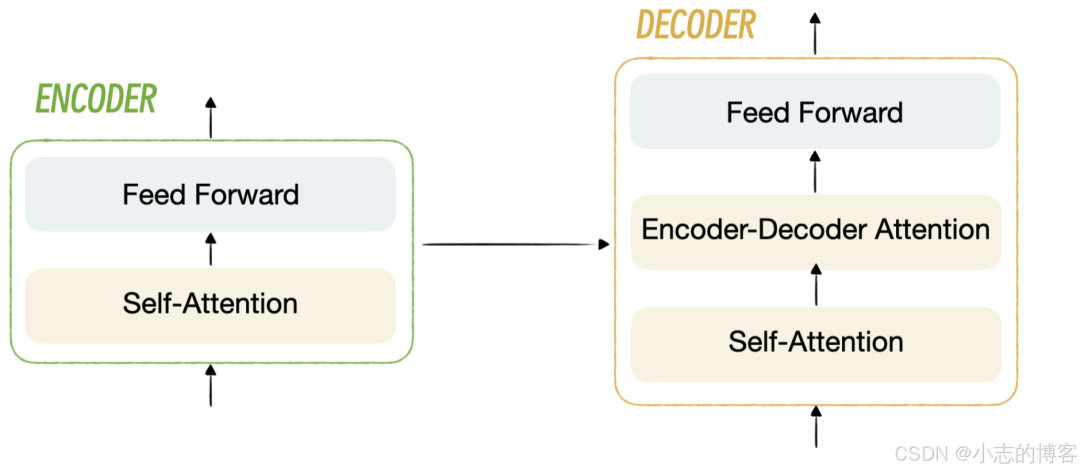
3.2、编码器
3.2.1、输入处理(编码器)
- 第一步进行词嵌入处理,在第一个编码器中,将单词向量化,然后进行位置编码,就是为每个单词添加位置信息,因为 Transformer 不像 RNN 或者 CNN,顺序处理序列,所以需要引入位置编码机制,确保模型能够记住单词的顺序。
3.2.2、自注意层处理(编码器)
- 这一层模型会计算每个输入元素与序列中其他元素的关系,使每个元素的新表示都富含整个序列的上下文信息。这意味着,通过自注意力机制,模型能够理解每个词,不仅仅在其自身的语义层面上,还包括它与句子中其他词的关系。之后数据经过 Add & Norm 操作进入前馈处理层(Feed Forward),Add & Norm 是什么意思呢?
- Add 表示残差连接,是指在自注意力层后把这一层处理过的数据和这一层的原始输入相加,这种方式允许模型在增加额外处理层的同时,保留输入信息的完整性,从而在不损失重要信息的前提下,学习到输入数据的复杂特征。具体来说,如果某一层的输入是 x,层的函数表示为 **f(x)**,那么这层的输出就是 **x + f(x)**。这样做主要是为了缓解深层网络中的梯度消失或梯度爆炸问题,使深度模型更容易训练。
- 那为什么说它可以缓解梯度消失问题呢?因为 **x + f(x),而不仅仅是f(x)**,这样在反向传播过程中,可以有多条路径,可以减轻连续连乘导致梯度减少到 0 的问题。接下来我们继续看 Norm 操作。
- Norm 表示归一化(Normalization),数据在经过 Add 操作后,对每一个样本的所有特征进行标准化,即在层内部对每个样本的所有特征计算均值和方差,并使用这些统计信息来标准化特征值。这有助于避免训练过程中的内部协变量偏移问题,即保证网络的每一层都在相似的数据分布上工作,从而提高模型训练的稳定性和速度。
- 之后数据进入前馈层,也就是前馈神经网络。
3.2.3、前馈层处理(编码器)
- 前馈全连接网络(FFN)对每个位置的表示进行独立的非线性变换,提升了模型的表达能力。通过两次线性映射和一个中间的 ReLU 激活函数,FFN 引入了必要的非线性处理,使模型能够捕捉更复杂的数据特征。这一过程对于加强模型对序列内各元素的理解至关重要,提高了模型处理各种语言任务的能力。我们通过公式来解释一下。
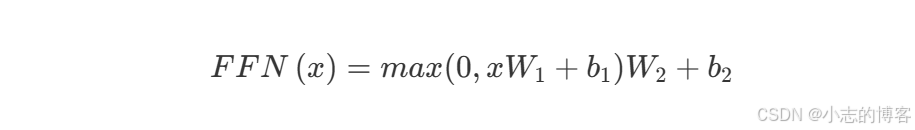
- 输入 x 就是上一层自注意力层的输出,首先通过一个线性变换,即与权重矩阵 W1 相乘并加上偏置向量 b1,这一步的计算可以表示为 xW1 + b1。权重矩阵 W1 和偏置向量 b1 是这一层的参数,它们在模型训练过程中学习得到。
- 接着,线性变换的结果通过一个 ReLU 激活函数 max(0,.)。ReLU 函数的作用是增加非线性,它定义为 max(0,z),其中 z 是输入。如果 z 为正,函数输出 z;如果 z 为负或 0,函数输出 0。这一步可以帮助模型捕捉复杂的特征,防止输出被压缩在线性空间内。
- 其次,max 函数的输出再次通过一个线性变换,即与第二个权重矩阵 W 2 相乘并加上第二个偏置向量 b2。这一步可以表示为 max(0,xW1+b1)W2+b2,其中 max(0,xW1+b1) 是第一层的输出。
- 最后,同样经过和自注意力层一样的 Add & Norm 处理,完成归一化输出。
3.3、解码器
3.3.1、自注意力层处理(解码器)
-
解码器的自注意力层设计得比较特别,与编码器的自注意力层不同,解码器的自注意力层需要处理额外的约束,即保证在生成序列的每一步仅依赖于之前的输出,而不是未来的输出。这是通过一个特定的掩蔽(masking)技术来实现的。接下来我详细解释一下解码器自注意力层的几个关键点。
1、处理序列依赖关系,解码器的自注意力层使每个输出位置可以依赖于到目前为止在目标序列中的所有先前位置。这允许模型在生成每个新词时,综合考虑已生成的序列的上下文信息。
2、掩蔽未来信息,为了确保在生成第 t 个词的时候不会使用到第 t+1 及之后的词的信息,自注意力层使用一个上三角掩蔽矩阵,在实现中通常填充为负无穷或非常大的负数。这保证了在计算 Softmax 时未来位置的贡献被归零,从而模型无法“看到”未来的输出。
3、动态调整注意力焦点,通过学习的注意力权重,模型可以动态地决定在生成每个词时应更多地关注目标序列中的哪些部分。
import torchimport torch.nn.functional as Fdef decoder_self_attention(query, key, value, mask): """ 解码器自注意力层,带掩蔽功能。 参数: - query, key, value: 形状为 (batch_size, seq_len, embed_size) 的张量 - mask: 形状为 (seq_len, seq_len) 的张量,用于防止未来标记的注意力 返回: - attention output: 形状为 (batch_size, seq_len, embed_size) 的张量 - attention weights: 形状为 (batch_size, seq_len, seq_len) 的张量 """ # 计算缩放点积注意力分数 d_k = query.size(-1) # 键向量的维度 scores = torch.matmul(query, key.transpose(-2, -1)) / torch.sqrt(torch.tensor(d_k, dtype=torch.float32)) # 应用掩蔽(将未来的标记设置为极大的负数以排除它们) scores = scores.masked_fill(mask == 0, float('-inf')) # 应用softmax获取注意力权重 attention_weights = F.softmax(scores, dim=-1) # 使用注意力权重和值向量乘积得到输出 attention_output = torch.matmul(attention_weights, value) return attention_output, attention_weights# 示例用法batch_size = 1seq_len = 5embed_size = 64query = torch.rand(batch_size, seq_len, embed_size)key = torch.rand(batch_size, seq_len, embed_size)value = torch.rand(batch_size, seq_len, embed_size)# 生成掩蔽矩阵以阻止对未来标记的注意(使用上三角矩阵掩蔽)mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()# 调用函数output, weights = decoder_self_attention(query, key, value, mask)print("输出形状:", output.shape)print("注意力权重形状:", weights.shape) -
mast 的值:
tensor([[False, True, True, True, True], [False, False, True, True, True], [False, False, False, True, True], [False, False, False, False, True], [False, False, False, False, False]]) ```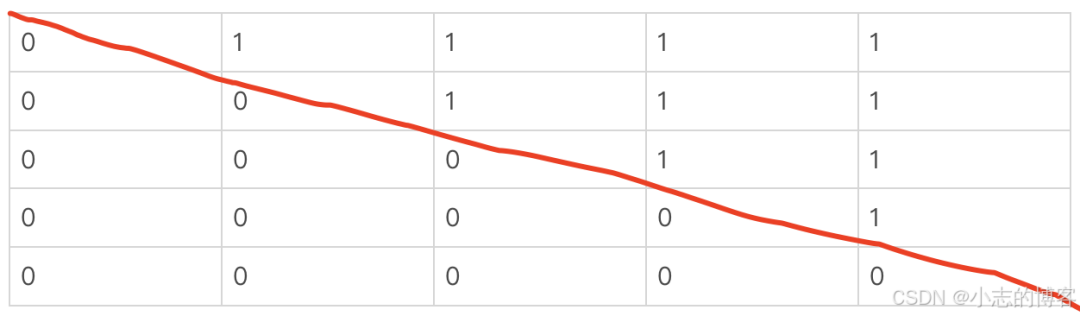 在这里插入图片描述 -
解码器中的自注意力层至关重要,因为它不仅提供了处理序列内依赖关系的能力,还确保了生成过程的自回归性质,即在生成当前词的时候,只依赖于之前已经生成的词。这种机制使 Transformer 模型非常适合各种序列生成任务,如机器翻译、文本摘要等。
-
之所以有这种机制,是因为自注意力机制允许当前位置的输出与未来位置的输入产生关联,从而导致数据泄露和信息泄露的问题。而推理阶段,是不可能读到未来信息的,这样可能会导致模型在训练和推断阶段表现不一致,以及模型预测结果的不稳定性。
3.3.2、编码 - 解码注意力层(解码器)
-
编码 - 解码注意力层(Encoder-Decoder Attention Layer)是一种特殊的注意力机制,用于在解码器中对输入序列(编码器的输出)进行注意力计算。这个注意力层有助于解码器在生成输出序列时对输入序列的信息进行有效整合和利用,注意,这个注意力层关注的是全局的注意力计算,包括编码器输出的信息序列和解码器内部的自注意力计算。
-
那它与上面讲的解码器自注意力层有什么区别呢?
1、信息来源不同:编码 - 解码注意力层用在解码器(Decoder)中,将解码器当前位置的查询向量与编码器(Encoder)的输出进行注意力计算,而解码自注意力层用于解码器自身内部,将解码器当前位置的查询向量与解码器之前生成的位置的输出进行注意力计算。
2、计算方式不同:编码 - 解码注意层计算当前解码器位置与编码器输出序列中所有位置的注意力分数。这意味着解码器在生成每个输出位置时,都可以综合考虑整个输入序列的信息。解码自注意力层计算当前解码器位置与之前所有解码器位置的输出的注意力分数。这使得解码器可以自我关注并利用先前生成的信息来生成当前位置的输出。
-
用一句话总结就是:编码 - 解码注意层关注整个编码器输出序列,将编码器的信息传递给解码器,用于帮助解码器生成目标序列,解码自注意力层关注解码器自身先前生成的位置的信息,用于帮助解码器维护上下文并生成连贯的输出序列。
3.3.3、前馈层处理(解码器)
- 前馈处理和编码器中的前馈处理类似,通过两次线性映射和一个中间的 ReLU 激活函数,生成解码器最终的输出,原理可以看我们上一节课介绍的内容。
3.3.3.1、Linear
-
在 Transformer 架构中,Linear 层就是线性层的意思,通常被用于多个子模块中,包括编码器和解码器中的不同部分。Linear 层的作用是对输入数据进行线性变换,将输入张量映射到另一个张量空间中,并且通过学习参数来实现数据的线性组合和特征变换。可以说,Linear 无处不在,也很容易理解。我简单讲解下解码器后面的 Linear 的作用。
-
解码器后面的 Linear 层通常用于将经过前馈层处理的特征表示,映射到最终的输出空间,即模型的输出词汇表的维度。这个 Linear 层的作用是将解码器前馈层的输出映射为模型最终的预测结果,例如生成下一个单词或标记的概率分布,实际上是进行降维,将前馈层的高维输出转换为词汇表的维度。你可以参考下面的示例代码:
import torchimport torch.nn as nnimport torch.nn.functional as Fclass Decoder(nn.Module): def __init__(self, d_model, vocab_size): super(Decoder, self).__init__() self.d_model = d_model self.vocab_size = vocab_size # 前馈网络(Feed Forward Network) self.feedforward = nn.Sequential( nn.Linear(d_model, 2048), nn.ReLU(), nn.Linear(2048, vocab_size) ) def forward(self, x): # x: 解码器前馈网络的输出,形状为 [batch_size, seq_len, d_model] # 将解码器前馈网络的输出通过线性层进行映射 output_logits = self.feedforward(x) # 输出形状为 [batch_size, seq_len, vocab_size] # 对输出 logits 进行 softmax 操作,得到预测概率 output_probs = F.softmax(output_logits, dim=-1) # 输出形状为 [batch_size, seq_len, vocab_size] return output_probs# 示例用法d_model = 512 # 解码器特征维度vocab_size = 10000 # 词汇表大小# 创建解码器实例decoder = Decoder(d_model, vocab_size)# 输入数据,假设解码器前馈网络的输出input_tensor = torch.randn(2, 10, d_model) # 示例输入,batch_size=2,序列长度=10# 解码器前向传播output_probs = decoder(input_tensor)# 输出预测概率,形状为 [2, 10, 10000]print(output_probs.shape) -
示例中,我们定义了一个简单的解码器(Decoder),其中包含一个前馈网络。前馈网络由两个线性层和一个 ReLU 激活函数组成,用于将解码器的特征表示 x 映射到词汇表大小的维度上。最后,对输出进行 Softmax 操作,得到预测概率。我们再看看 Softmax 函数的作用。
3.3.3.2、Softmax 函数
-
Softmax 函数作用非常大,其核心就是一句话:将一组任意实数转换成一个概率分布。在 Transformer 模型中有多处用到,比如注意力机制和多头注意力机制,通过 Softmax 函数计算注意力分数,以及在解码器最后一层,会将上面讲的 Linear 线性层输出的数据,应用 Softmax 函数进行处理。这里有两个问题需要注意。
1、为什么需要通过 Softmax 函数进行计算?意义在哪里?
2、将任意实数转化为概率分布,数据的意义将会发生变化,会不会对效果产生影响?
-
我们看一下关于问题 1 的解释。
将得分转换成概率后,模型能够更加明确地选择哪些输入的部分是最相关的。
在神经网络中,直接处理非常大或非常小的数值可能会导致数值不稳定,出现梯度消失或爆炸等问题。通过 Softmax 函数处理后,数据将被规范化到一个固定的范围,从 0 到 1 之间,可以缓解这些问题。
Softmax 函数的输出是概率分布,这使得模型的行为更加透明,可以直接解释为“有多少比例的注意力被分配到特定的输入上”。这有助于调试和优化模型,以及理解模型的决策过程。
-
我们再看一下关于问题 2 的解释。
原始的得分只表达了相对大小关系,即一个得分比另一个高,但不清楚这种差异有多大。而通过 Softmax 转换后,得到的概率值不仅反映出哪些得分较高,还具体表达了它们相对于其他选项的重要性。这种转换让模型可以做出更精确的决策。
原始得分可能因范围广泛或分布不均而难以直接操作,而概率形式的输出更标准化、更规则,适合进一步的处理和决策,如分类决策、风险评估等。
-
我们看一个简单的示例代码。
import numpy as npimport torchimport torch.nn.functional as F# 假设有一个简单的查询 (Query) 和键 (Key) 矩阵,这里使用随机数生成np.random.seed(0) # 设置随机种子以确保结果的可复现性query = np.random.rand(1, 64) # 查询向量,维度为1x64key = np.random.rand(64, 10) # 键矩阵,维度为64x10# 将numpy数组转换为torch张量query = torch.tensor(query, dtype=torch.float32)key = torch.tensor(key, dtype=torch.float32)# 计算点积注意力得分attention_scores = torch.matmul(query, key) # 结果维度为1x10# 应用Softmax函数,规范化注意力权重attention_weights = F.softmax(attention_scores, dim=-1)print("注意力得分(未规范化):", attention_scores)print("注意力权重(Softmax规范化后):", attention_weights) -
程序输出结果:
注意力得分(未规范化): tensor([[17.9834, 15.4092, 15.5016, 15.2171, 18.3008, 17.4539, 15.6339, 16.3575, 14.5159, 15.4736]])注意力权重(Softmax规范化后): tensor([[0.2786, 0.0212, 0.0233, 0.0175, 0.3826, 0.1640, 0.0266, 0.0548, 0.0087, 0.0226]]) -
Softmax 函数的具体实现:
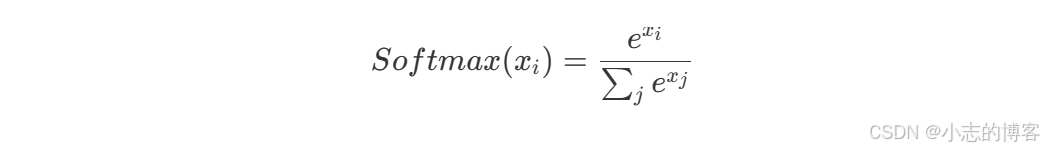
1、指数化:对输入向量的每个元素应用指数函数。这意味着每个输入值 x_i 被转换为 e^{x_i},其中 e 是自然对数的底。这一步的作用是将所有输入转化为正数,并放大了输入值之间的差异。
2、归一化:计算所有指数化值的总和 {\sum_{j}{}{e{x_j}}},然后,将每个指数化后的值除以这个总和。这一步的结果是一组和为 1 的概率值,其中每个概率值都表示原始输入值相对于其他值的重要性或贡献度。
-
代码实现如下:
import numpy as npdef softmax(x): exp_x = np.exp(x - np.max(x)) # 防止数值溢出 return exp_x / exp_x.sum()# 示例输入x = np.array([1.0, 2.0, 3.0])print("Softmax输出:", softmax(x))
四、Transformer 的优势
4.1、并行处理能力
- 与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)不同,Transformer 完全依赖于自注意力机制,消除了序列处理中的递归结构,允许模型在处理输入数据时实现高效的并行计算。这使得训练过程大大加速,特别是在使用现代 GPU 和 TPU 等硬件时。你可以回顾一下 Position Encoding 的作用,就是为序列添加位置编码,以便在并行处理完以后,进行合并。
4.2、捕捉长距离依赖
- Transformer 通过自注意力机制能够捕捉序列中的长距离依赖关系。在自然语言处理中,这意味着模型可以有效地关联文本中相隔很远的词汇,提高对上下文的理解。
4.3、灵活的注意力分布
- 多头注意力机制允许 Transformer 在同一个模型中同时学习数据的不同表示。每个头可以专注于序列的不同方面,例如一个头关注语法结构,另一个头关注语义内容。
4.4、可扩展性
- Transformer 模型可以很容易地扩展到非常大的数据集和非常深的网络结构。这一特性是通过模型的简单可堆叠的架构实现的,使其在训练非常大的模型时表现出色。
- 当然还有其他特性,比如适用性、通用性等,总的来说,Transformer 通过其独特的架构设计在效率、效果和灵活性方面提供了显著的优势,使其成为处理复杂序列数据任务的强大工具。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献638条内容
已为社区贡献638条内容

所有评论(0)