小白程序员必备:手把手教你用PyTorch构建Transformer大模型(收藏版)
本文详细介绍了如何使用PyTorch从零开始构建完整的Transformer模型。内容涵盖了位置编码、多头注意力、前馈网络、编码器层、解码器层等关键组件的实现,并提供了完整的模型结构和训练示例。文章还讨论了模型的应用场景和性能优化技巧,适合想要学习大模型的小白程序员参考和收藏。
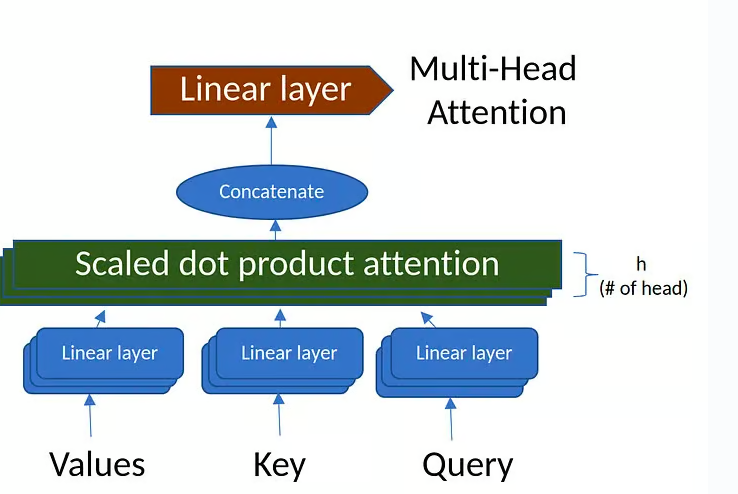
以下是使用PyTorch构建完整Transformer模型的实现方案:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
import copy
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=5000):
super(PositionalEncoding, self).__init__()
pe = torch.zeros(max_len, d_model)
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, x):
return x + self.pe[:, :x.size(1)]
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super(MultiHeadAttention, self).__init__()
self.d_model = d_model
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, Q, K, V, mask=None):
batch_size = Q.size(0)
# 线性变换并分割多头
Q = self.W_q(Q).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(K).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(V).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)
# 计算注意力分数
scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(self.d_k)
# 应用掩码
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 计算注意力权重
attn = F.softmax(scores, dim=-1)
attn = self.dropout(attn)
# 应用注意力权重到value上
output = torch.matmul(attn, V)
# 合并多头并线性变换
output = output.transpose(1, 2).contiguous().view(batch_size, -1, self.d_model)
return self.W_o(output)
class PositionWiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionWiseFeedForward, self).__init__()
self.fc1 = nn.Linear(d_model, d_ff)
self.fc2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.fc2(self.dropout(F.relu(self.fc1(x))))
class EncoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(EncoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask):
# 自注意力子层
attn_output = self.self_attn(x, x, x, mask)
x = self.norm1(x + self.dropout(attn_output))
# 前馈网络子层
ff_output = self.feed_forward(x)
x = self.norm2(x + self.dropout(ff_output))
return x
class DecoderLayer(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super(DecoderLayer, self).__init__()
self.self_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.cross_attn = MultiHeadAttention(d_model, num_heads, dropout)
self.feed_forward = PositionWiseFeedForward(d_model, d_ff, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, enc_output, src_mask, tgt_mask):
# 自注意力子层
attn_output = self.self_attn(x, x, x, tgt_mask)
x = self.norm1(x + self.dropout(attn_output))
# 编码器-解码器注意力子层
attn_output = self.cross_attn(x, enc_output, enc_output, src_mask)
x = self.norm2(x + self.dropout(attn_output))
# 前馈网络子层
ff_output = self.feed_forward(x)
x = self.norm3(x + self.dropout(ff_output))
return x
class Transformer(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512, num_heads=8,
num_layers=6, d_ff=2048, max_seq_length=100, dropout=0.1):
super(Transformer, self).__init__()
self.encoder_embedding = nn.Embedding(src_vocab_size, d_model)
self.decoder_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.positional_encoding = PositionalEncoding(d_model, max_seq_length)
self.encoder_layers = nn.ModuleList([EncoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
self.decoder_layers = nn.ModuleList([DecoderLayer(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)])
self.fc = nn.Linear(d_model, tgt_vocab_size)
self.dropout = nn.Dropout(dropout)
def generate_mask(self, src, tgt):
src_mask = (src != 0).unsqueeze(1).unsqueeze(2)
tgt_mask = (tgt != 0).unsqueeze(1).unsqueeze(3)
seq_length = tgt.size(1)
nopeak_mask = (1 - torch.triu(torch.ones(1, seq_length, seq_length), diagonal=1)).bool()
tgt_mask = tgt_mask & nopeak_mask
return src_mask, tgt_mask
def forward(self, src, tgt):
src_mask, tgt_mask = self.generate_mask(src, tgt)
# 编码器
src_embedded = self.dropout(self.positional_encoding(self.encoder_embedding(src)))
enc_output = src_embedded
for enc_layer in self.encoder_layers:
enc_output = enc_layer(enc_output, src_mask)
# 解码器
tgt_embedded = self.dropout(self.positional_encoding(self.decoder_embedding(tgt)))
dec_output = tgt_embedded
for dec_layer in self.decoder_layers:
dec_output = dec_layer(dec_output, enc_output, src_mask, tgt_mask)
output = self.fc(dec_output)
return output
第二个训练示例
def train_transformer():
# 超参数配置
src_vocab_size = 5000
tgt_vocab_size = 5000
d_model = 512
num_heads = 8
num_layers = 6
d_ff = 2048
max_seq_length = 100
dropout = 0.1
batch_size = 64
num_epochs = 100
learning_rate = 0.0001
# 初始化模型
model = Transformer(src_vocab_size, tgt_vocab_size, d_model, num_heads,
num_layers, d_ff, max_seq_length, dropout)
# 损失函数和优化器
criterion = nn.CrossEntropyLoss(ignore_index=0)
optimizer = optim.Adam(model.parameters(), lr=learning_rate, betas=(0.9, 0.98), eps=1e-9)
# 生成随机训练数据
src_data = torch.randint(1, src_vocab_size, (batch_size, max_seq_length))
tgt_data = torch.randint(1, tgt_vocab_size, (batch_size, max_seq_length))
# 训练循环
model.train()
for epoch in range(num_epochs):
optimizer.zero_grad()
# 前向传播
output = model(src_data, tgt_data[:, :-1])
# 计算损失
loss = criterion(output.contiguous().view(-1, tgt_vocab_size),
tgt_data[:, 1:].contiguous().view(-1))
# 反向传播和优化
loss.backward()
optimizer.step()
print(f'Epoch: {epoch+1}, Loss: {loss.item()}')
# 验证
model.eval()
val_src = torch.randint(1, src_vocab_size, (batch_size, max_seq_length))
val_tgt = torch.randint(1, tgt_vocab_size, (batch_size, max_seq_length))
with torch.no_grad():
val_output = model(val_src, val_tgt[:, :-1])
val_loss = criterion(val_output.contiguous().view(-1, tgt_vocab_size),
val_tgt[:, 1:].contiguous().view(-1))
print(f'Validation Loss: {val_loss.item()}')
if __name__ == '__main__':
train_transformer()
关键组件说明:
- 位置编码(PositionalEncoding):
- 使用正弦和余弦函数生成位置信息
- 允许模型感知序列中token的位置
- 多头注意力(MultiHeadAttention):
- 将输入分割成多个头并行计算注意力
- 每个头学习不同的注意力模式
- 最后将多头输出合并
- 前馈网络(PositionWiseFeedForward):
- 包含两个全连接层和ReLU激活
- 对每个位置独立进行非线性变换
- 编码器层(EncoderLayer):
- 包含自注意力子层和前馈网络子层
- 每个子层后接残差连接和层归一化
- 解码器层(DecoderLayer):
- 包含自注意力、编码器-解码器注意力和前馈网络
- 使用掩码防止未来信息泄露
- 完整Transformer模型:
- 包含嵌入层、位置编码和Transformer核心结构
- 支持源序列和目标序列的编码解码
- 输出层将解码结果映射回词汇表空间
训练流程建议:
- 准备数据集并构建词汇表
- 创建数据加载器处理批次数据
- 定义损失函数(交叉熵损失)和优化器(Adam)
- 实现训练循环和验证循环
- 添加学习率调度和早停机制
应用场景:
- 机器翻译(源语言到目标语言)
- 文本生成(给定前缀生成后续文本)
- 序列标注任务(如命名实体识别)
- 文本摘要(生成原文的简洁摘要)
性能优化技巧:
- 使用混合精度训练加速计算
- 实现梯度累积支持更大批次
- 添加标签平滑提升泛化能力
- 使用学习率预热策略稳定训练
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
【附赠一节免费的直播讲座,技术大佬带你学习大模型的相关知识、学习思路、就业前景以及怎么结合当前的工作发展方向等,欢迎大家~】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献603条内容
已为社区贡献603条内容

所有评论(0)