在Windows个人电脑上通过Ollama在本地部署AI大模型(部署qwen3、使用CherryStudio和AingDesk与AI大模型交互、解决Ollama中AI大模型只能同时处理一个请求的问题)
在Windows个人电脑上通过Ollama在本地部署AI大模型(部署qwen3、使用CherryStudio和AingDesk与AI大模型交互、解决Ollama中AI大模型只能同时处理一个请求的问题)
文章目录
0. 为什么要在本地部署AI大模型
| 考虑维度 | 实际意义 |
|---|---|
| 数据安全与隐私 | 数据完全在本地闭环处理,无需上传至第三方云端服务器 |
| 响应速度与体验 | 模型推理在本地硬件上直接完成,消除了网络传输延迟 |
| 深度定制与集成 | 拥有模型权重,允许利用私有数据进行微调,并修改底层代码 |
| 成本控制与效益 | 一次性硬件投入后,内部使用边际成本趋近于零,无按Token计费的压力 |
| 内容自主与审查 | 摆脱第三方API不透明的黑盒敏感词过滤机制(AI 大模型输出到一半时突然撤回消息) |
1. Ollama
1.1 Ollama是什么
Ollama 是一个“本地运行大模型”的工具,可以在你的电脑/服务器上下载、运行和管理各种开源大语言模型,并提供统一命令行和 HTTP API,像用本地版的“ChatGPT 服务”一样方便
1.2 下载Ollama
1.2.1 通过Ollama官网下载
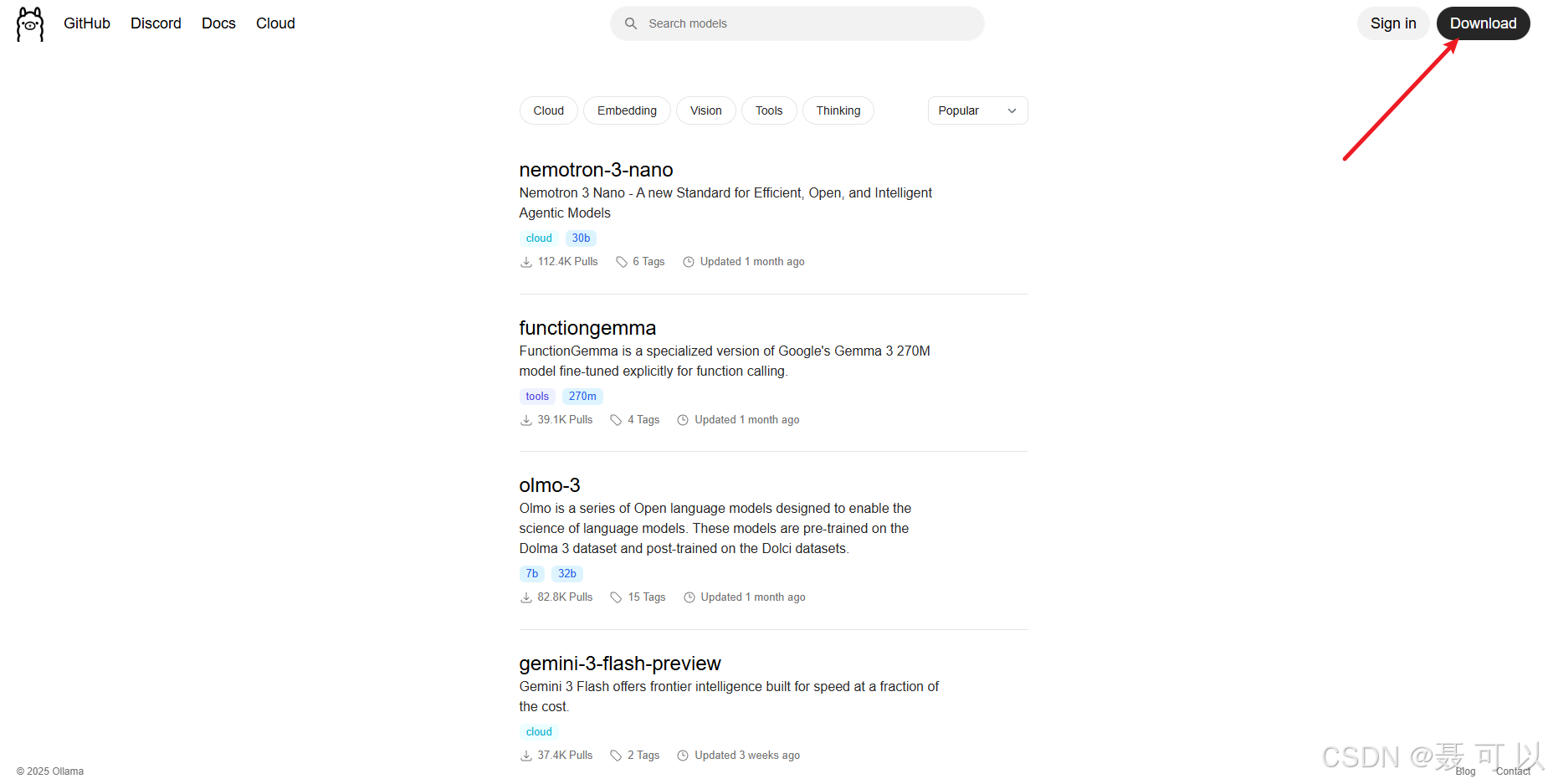
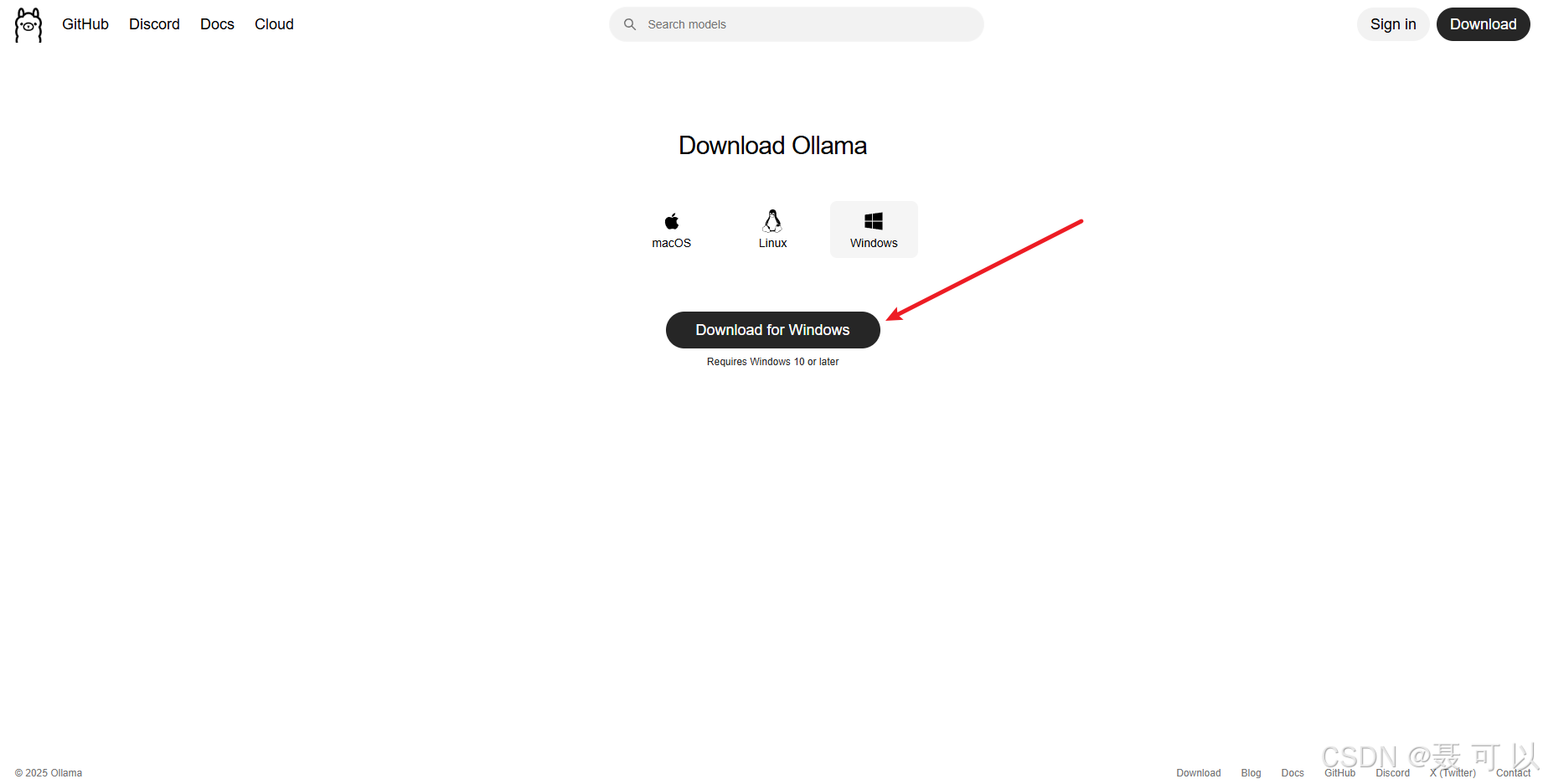
下载地址:https://ollama.com/
https://ollama.com/
1.2.2 通过GitHub下载
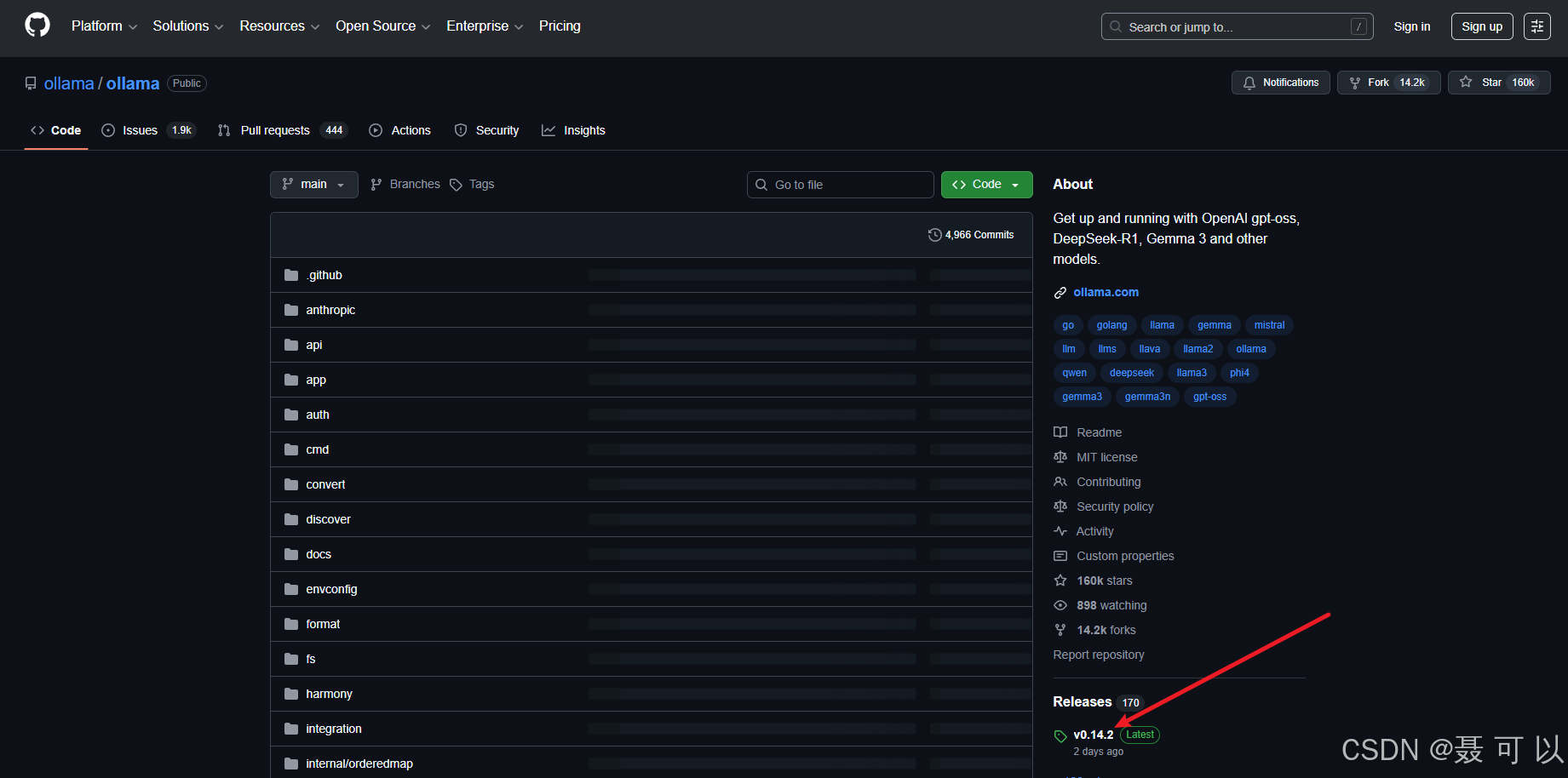
下载地址:https://github.com/ollama/ollama/
https://github.com/ollama/ollama/
如果无法正常访问 GitHub,可以参考我的另一篇博文:GitHub的使用技巧(加速访问GitHub、查看GitHub的热门项目、查看GitHub推荐的项目、Fork、Issue、快速找到项目的安装包、GitHub的各种快捷键)
1.2.3 通过第三方下载(推荐)
通过第三方下载的 Ollama 可能不是最新版,但不影响我们正常使用,后续我们也可以手动将Ollama升级到最新版
下载地址:https://www.onlinedown.net/soft/10133234.htm
https://www.onlinedown.net/soft/10133234.htm
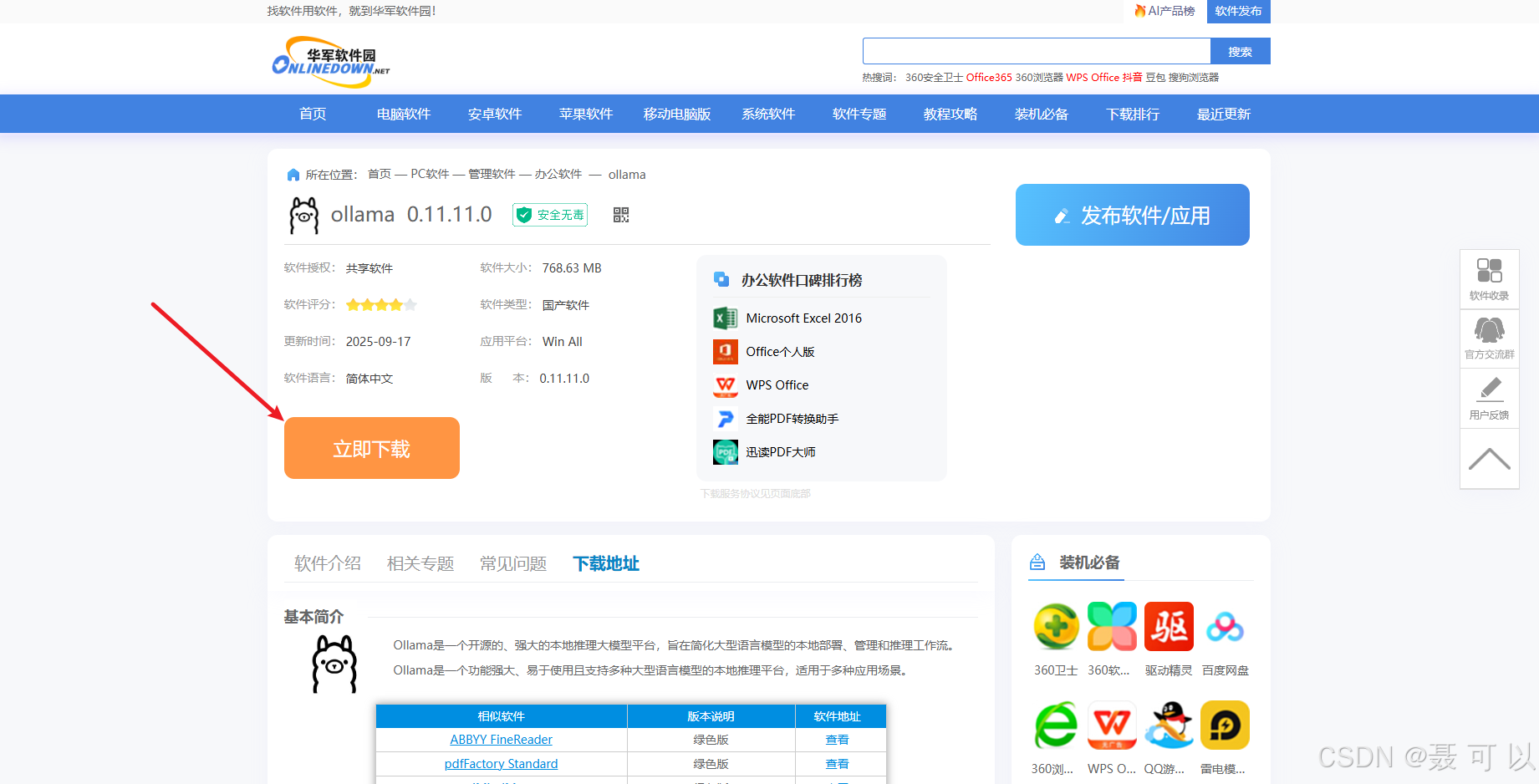
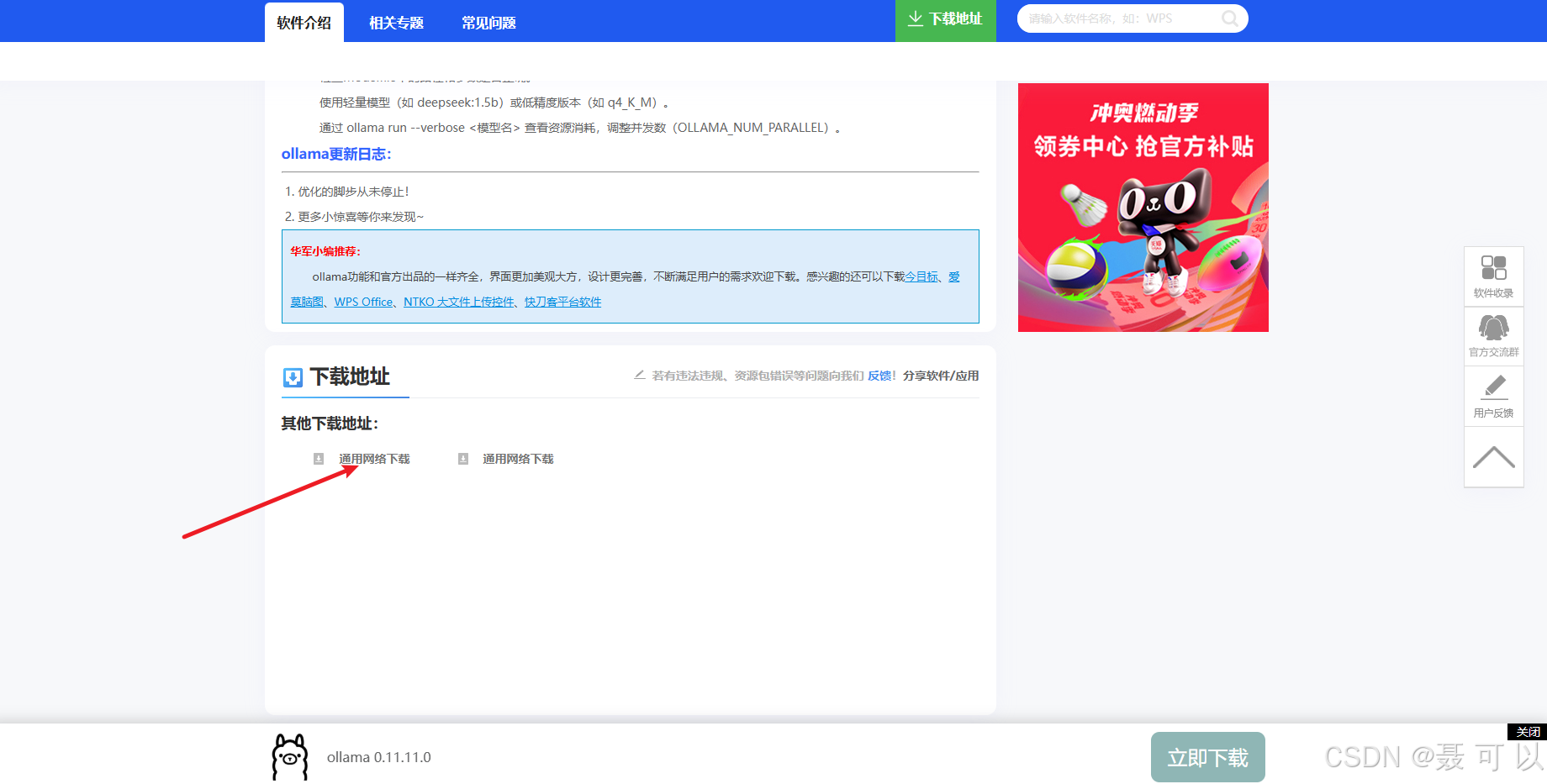
1.2.4 通过联想电脑管家下载
没想到吧,联想电脑管家还能干这事ψ(*`ー´)ψ
联想电脑管家的下载地址:https://guanjia.lenovo.com.cn/
https://guanjia.lenovo.com.cn/
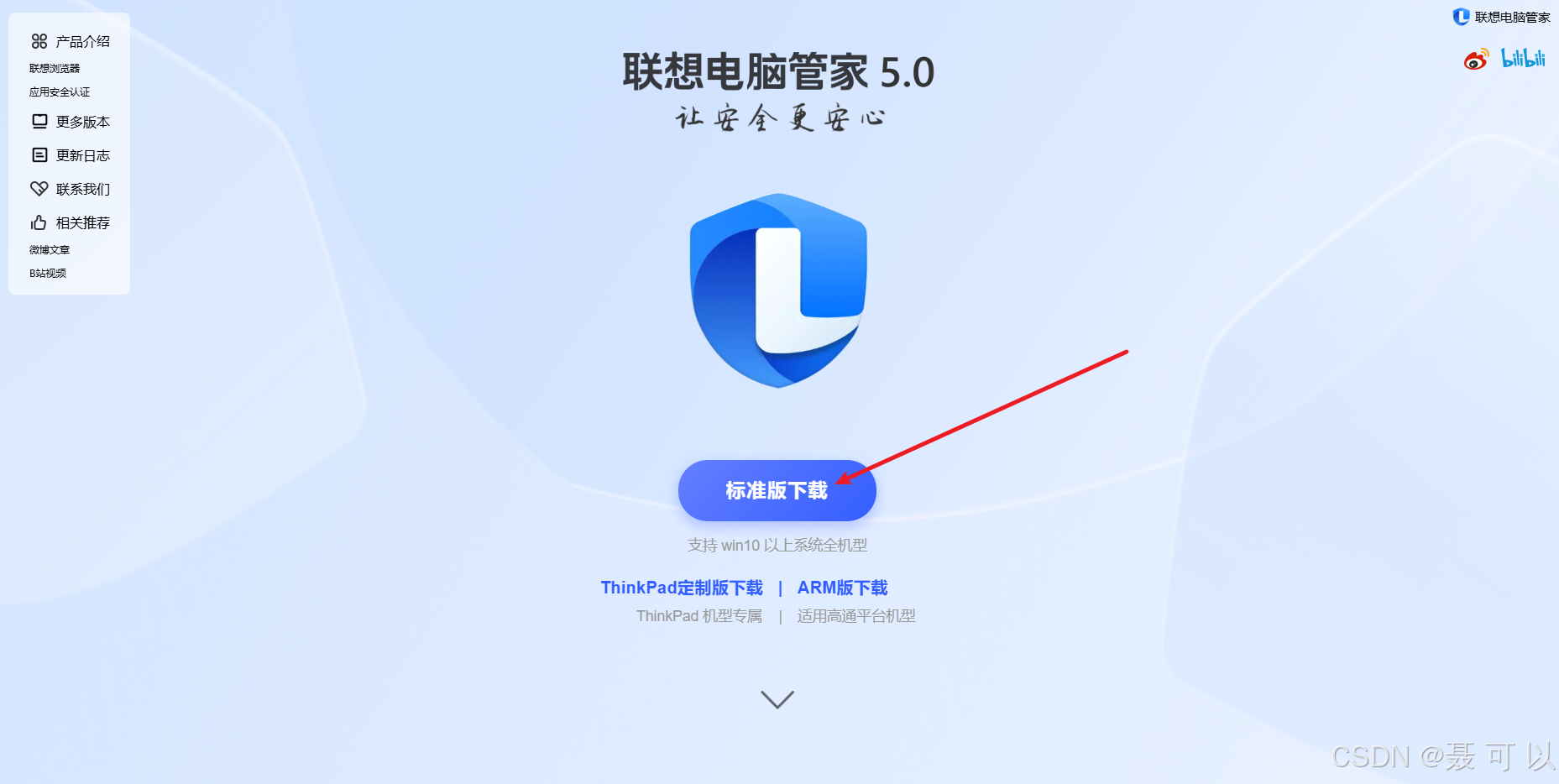
成功安装联想电脑管家后,打开联想应用商店
搜索 Ollama 关键字,点击安装按钮就可以下载了(由于我的电脑上已经安装过 Ollama,所以显示的是打开按钮)
Ollama
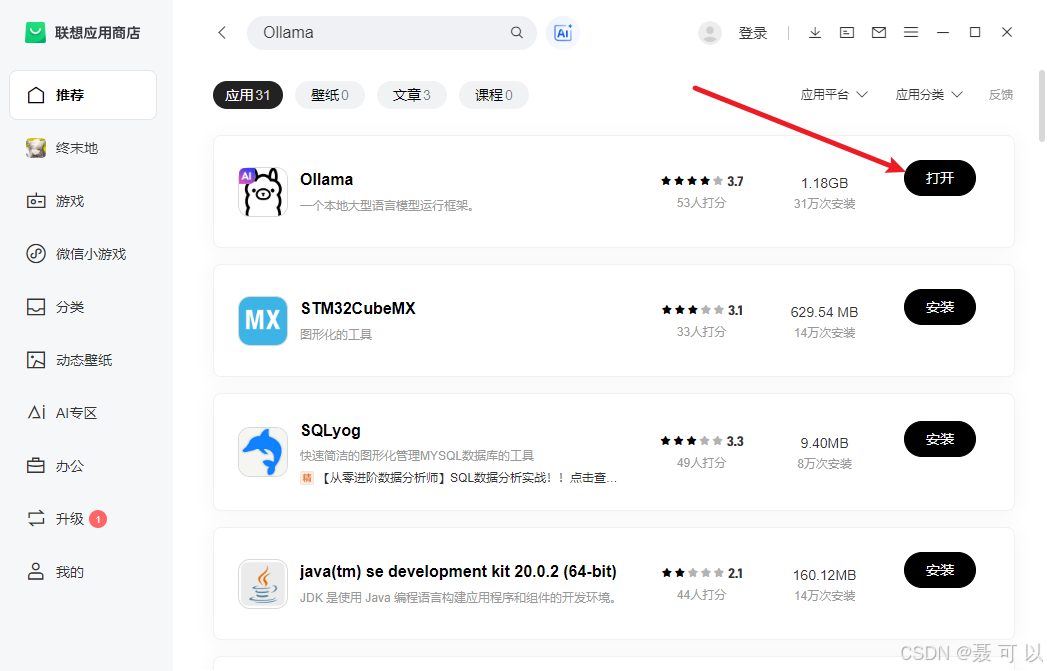
1.3 安装Ollama
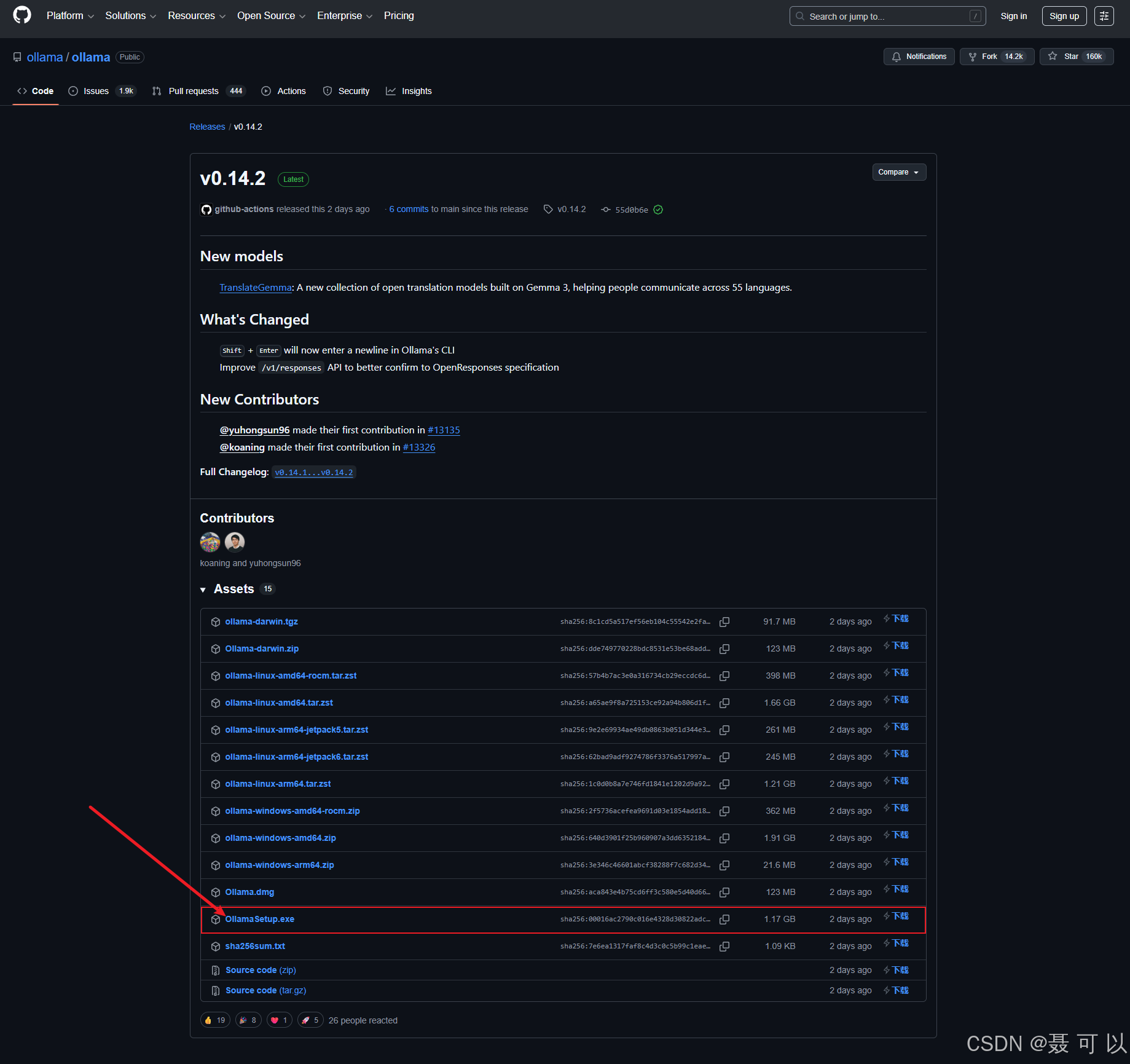
双击 OllamaSetup.exe 文件安装 Ollama,一路点击下一步就好了(默认安装在 C 盘,不可更改)
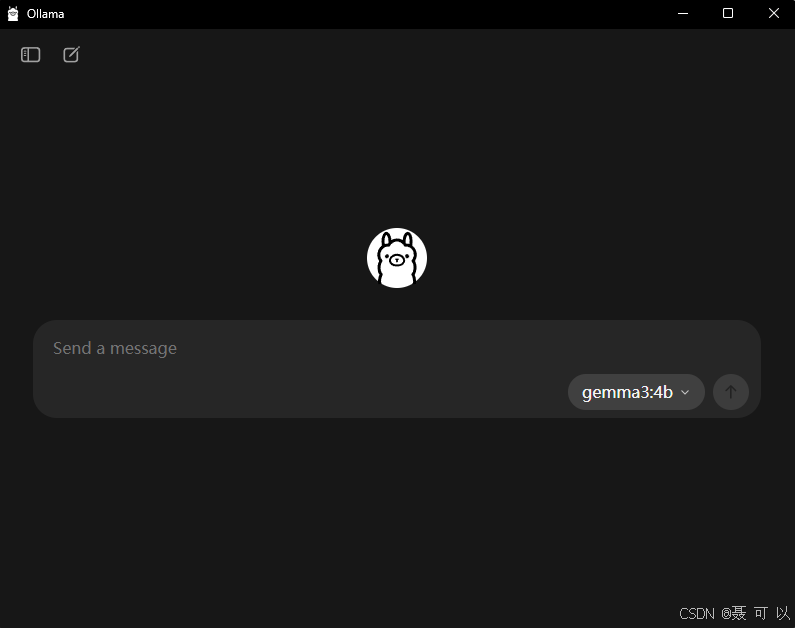
安装成功之后,会自动打开 Ollama 软件
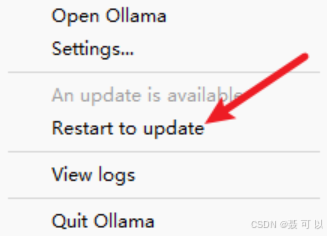
1.4 更新Ollama(可选)
在任务栏中鼠标右键 Ollama 的图标,点击 Restart to update 选项
2. 下载AI大模型
2.1 更改AI大模型的保存路径
使用 Ollama 下载大模型时,大模型默认会保存在 C 盘,我们需要更改大模型的保存路径
点击 Ollama 左上角的图标
点击 Settings 选项
更改大模型的保存位置
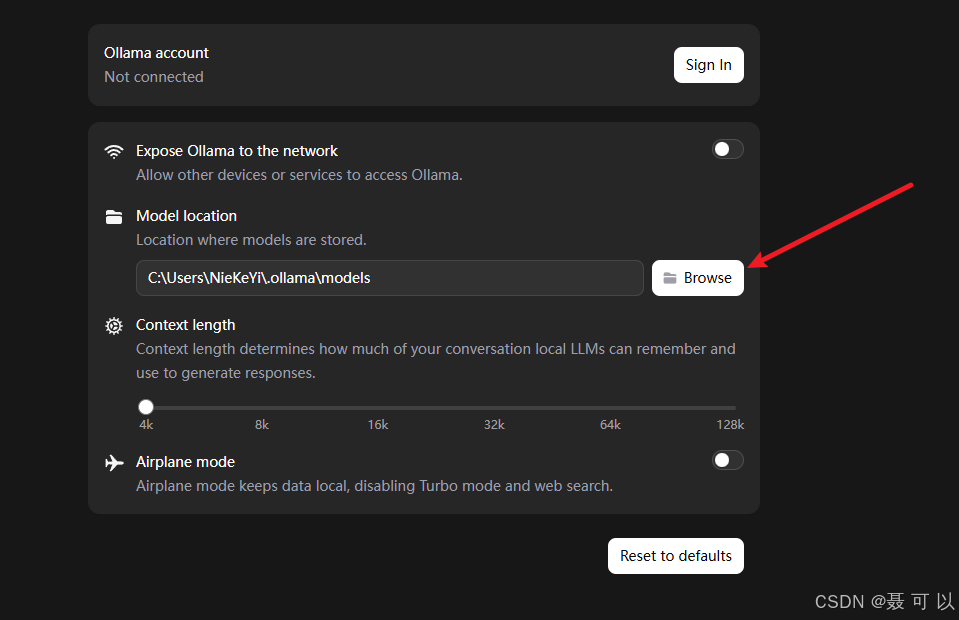
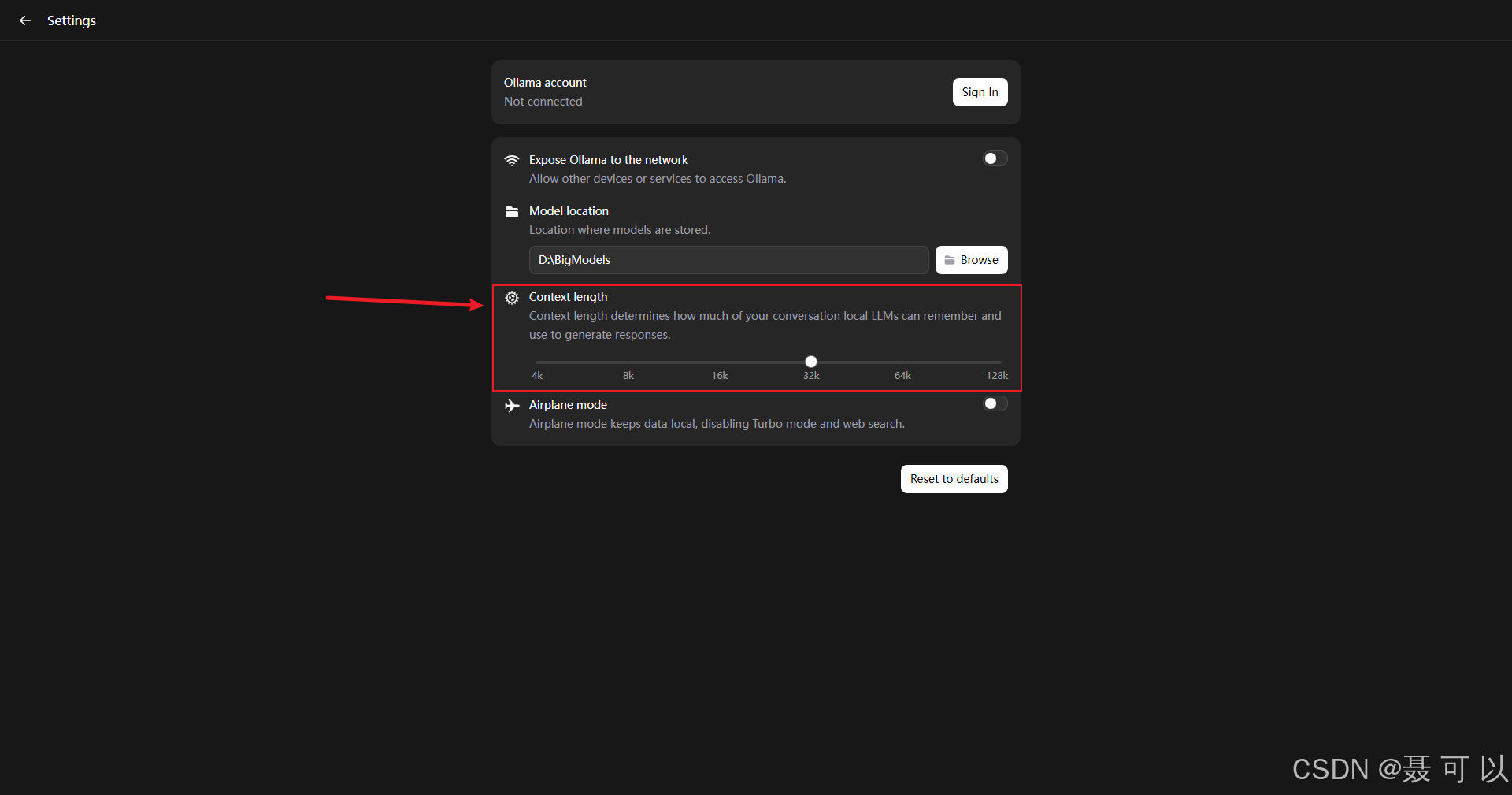
2.2 Ollama设置界面中各个配置项的含义
以下是使用微信翻译的 Ollama 设置界面
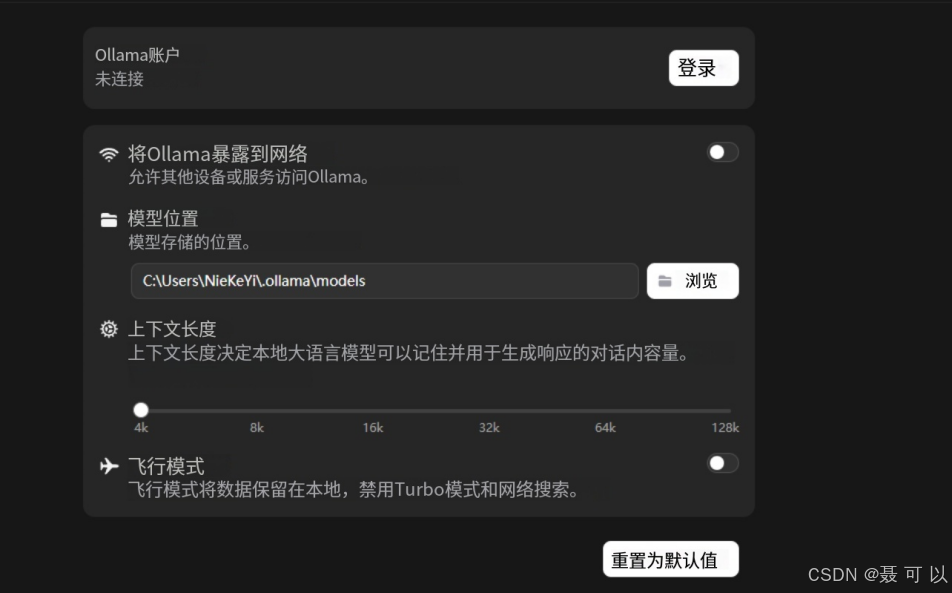
上下文长度越大,大模型能够记住你说过的内容就越多,使用体验也会更好,当然,上下文长度越大,大模型的处理速度和吐字速度也会变慢,可根据机器的硬件配置调整上下文的长度
2.3 下载AI大模型(以qwen3:4b为例)
本次演示所使用的电脑的硬件配置如下:
- CPU:Intel® Core™ i5-14600KF
- 内存:32G
- 显卡:16G
2.3.1 在大模型广场找到qwen3:4b大模型
大模型广场:https://ollama.com/
https://ollama.com/
搜索 qwen3 关键字
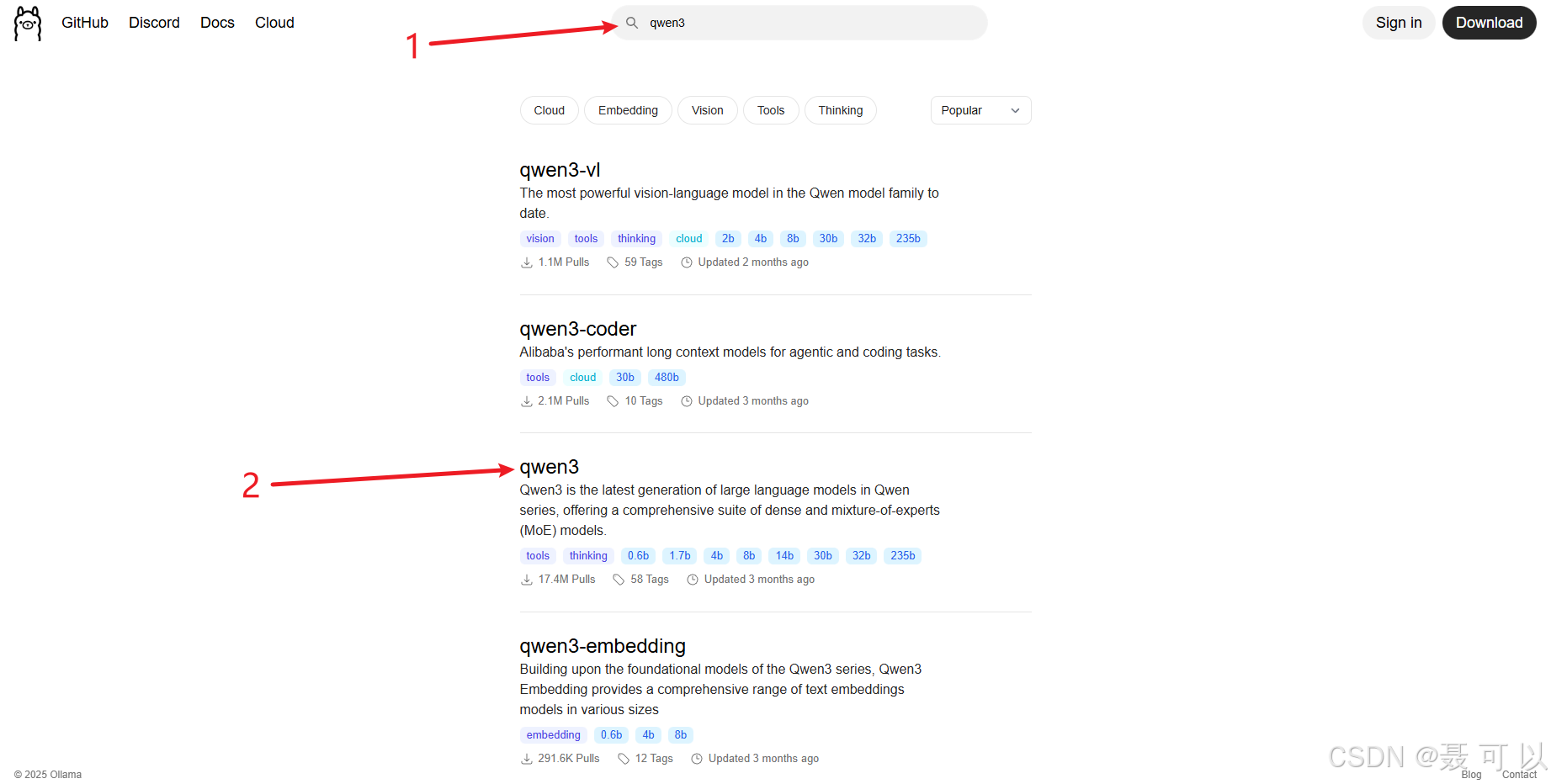
不同参数的 qwen3 模型对硬件的要求如下
| 模型名称 | 模型大小 | 上下文长度 | 输入类型 | 推荐硬件配置 |
|---|---|---|---|---|
| qwen3:latest | 5.2GB | 40K | 文本 | NVIDIA RTX 3060 / 3070 或更高(12GB 显存);支持推理部署于消费级 GPU |
| qwen3:0.6b | 523MB | 40K | 文本 | Intel i5 + 16GB 内存 或 树莓派 4B(轻量级任务);适合边缘设备 |
| qwen3:1.7b | 1.4GB | 40K | 文本 | NVIDIA GTX 1660 / RTX 3050(6GB 显存);可本地运行小规模任务 |
| qwen3:4b | 2.5GB | 256K | 文本 | NVIDIA RTX 3080 / 4070(10GB+ 显存);适合长文本处理 |
| qwen3:8b | 5.2GB | 40K | 文本 | NVIDIA RTX 3090 / 4080(24GB 显存);推荐用于高性能推理 |
| qwen3:14b | 9.3GB | 40K | 文本 | NVIDIA A6000 / RTX 4090(48GB 显存);需专业级显卡支持 |
| qwen3:30b | 19GB | 256K | 文本 | 双卡或多卡 NVIDIA A100 / H100;适合科研与企业级应用 |
| qwen3:32b | 20GB | 40K | 文本 | 多卡 A100 / H100 集群;需分布式推理架构支持 |
| qwen3:235b | 142GB | 256K | 文本 | 超大规模集群(如 8x A100/H100);仅限云平台或超算中心部署 |
我们下载参数为 4b 的模型
复制代码
ollama run qwen3:4b
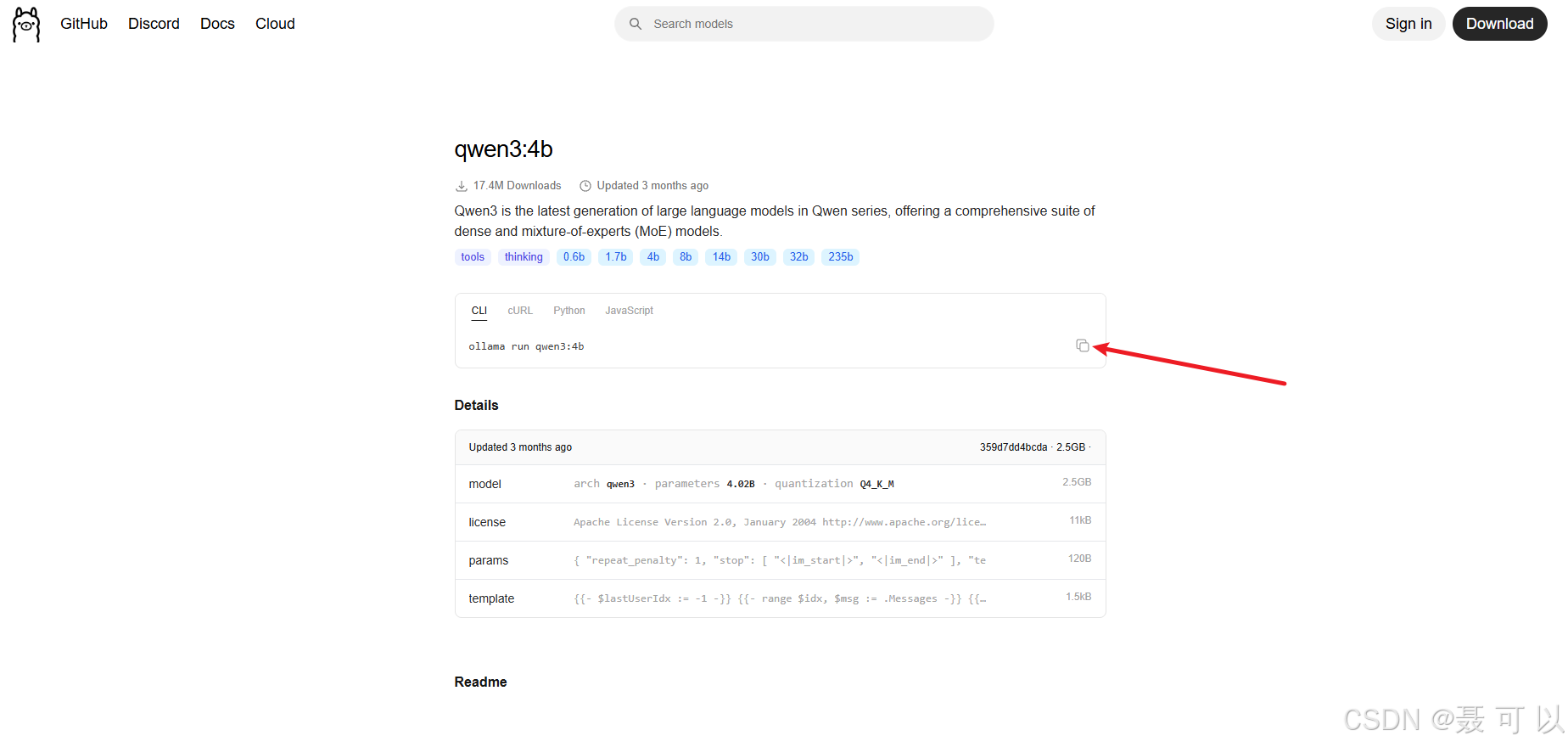
2.3.2 下载qwen3:4b大模型
按下 win + r 快捷键,输入 cmd 指令打开命令行窗口,在命令行窗口中输入我们刚才复制的代码
ollama run qwen3:4b
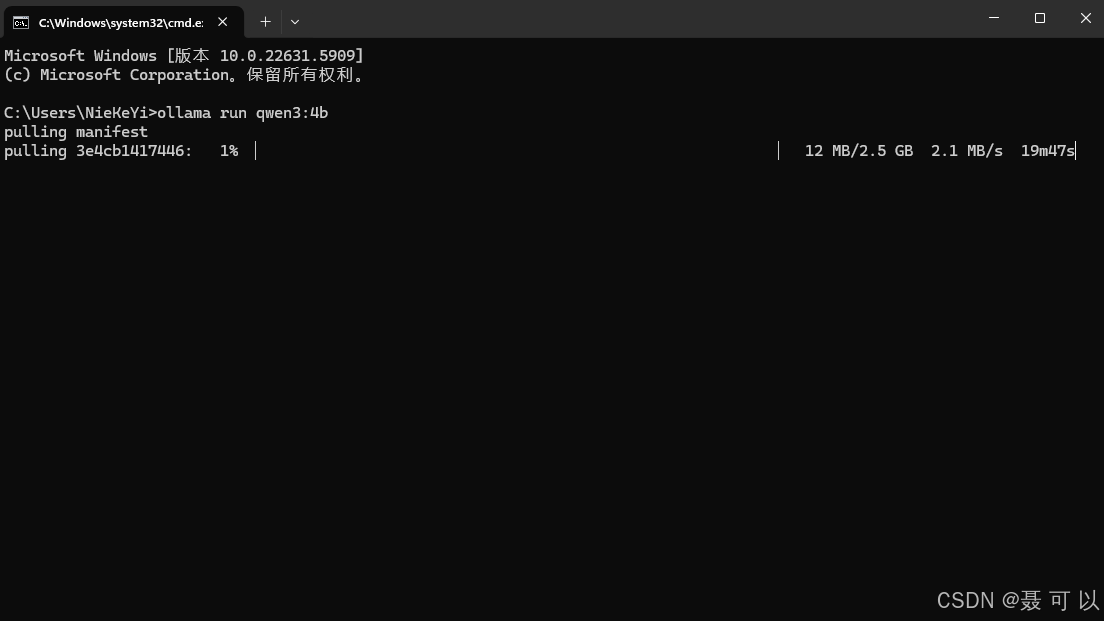
2.4 验证AI大模型在本地是否部署成功
下载成功后,如果终端出现 Send a message (/? for help) 提示信息,说明大模型在本地部署成功了

我们可以在终端中与大模型进行交互,第一次提问时大模型的回复速度可能较慢,后面大模型的回复速度会快很多

2.5 修改AI大模型的上下文长度
我们打开 Ollama 的界面,点击 Settings 按钮
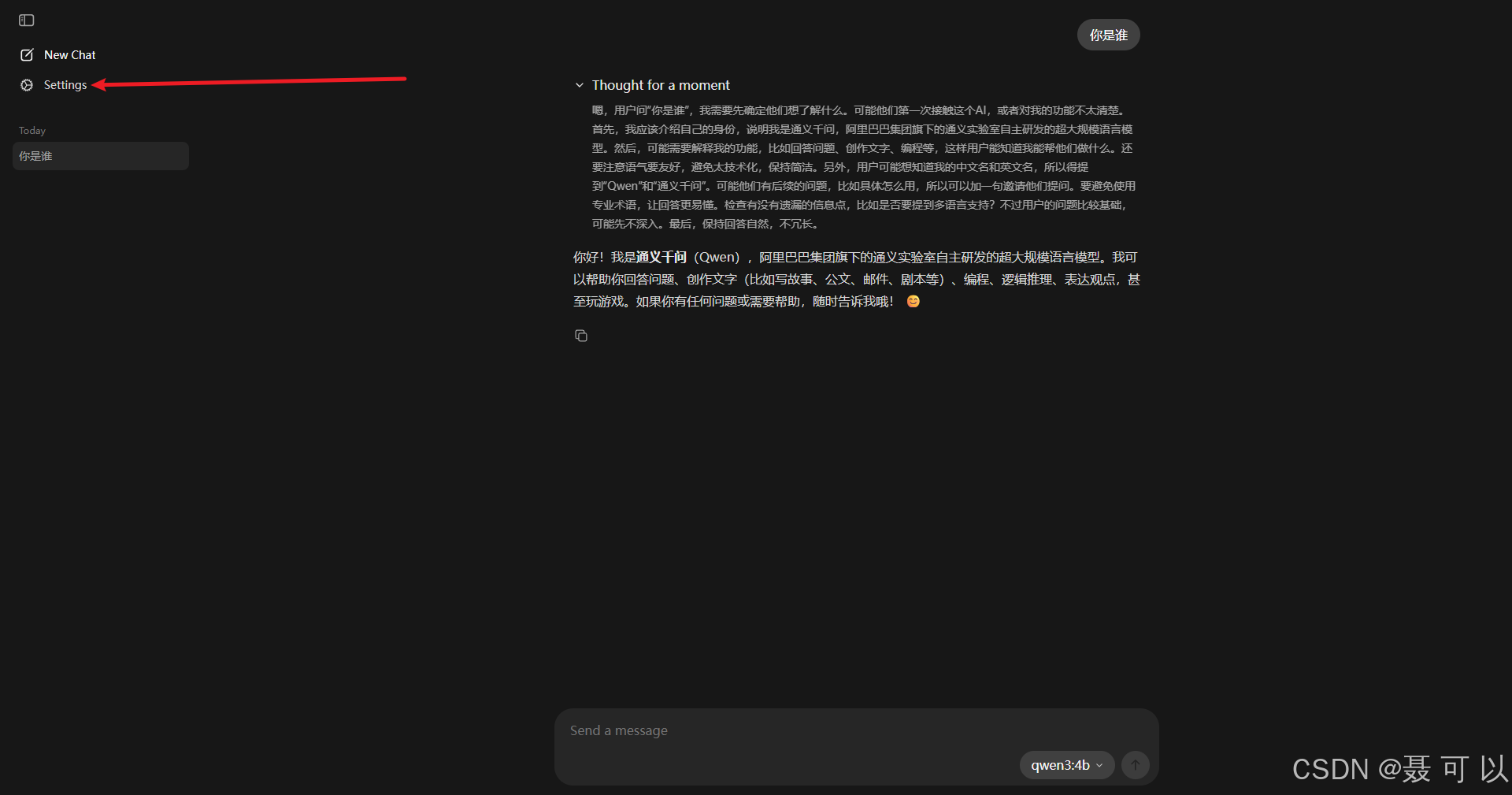
即使你的对话没有任何记录,在机器硬件配置有限的情况下,上下文长度变大,大模型的处理速度也会下降
根据大模型的吐字速度灵活调整上下文长度,在机器配置有限的情况下,上下文长度越长,大模型的处理速度(吐字速度)越慢
3. 下载与AI大模型交互的软件
一直在 cmd 命令窗口里面与大模型交互,很不方便,我们可以借助一些软件来实现聊天对话框的效果
3.1 Cherry Studio社区版(个人使用免费,商用需授权)
3.1.1 下载
下载地址:https://www.cherry-ai.com/
https://www.cherry-ai.com/
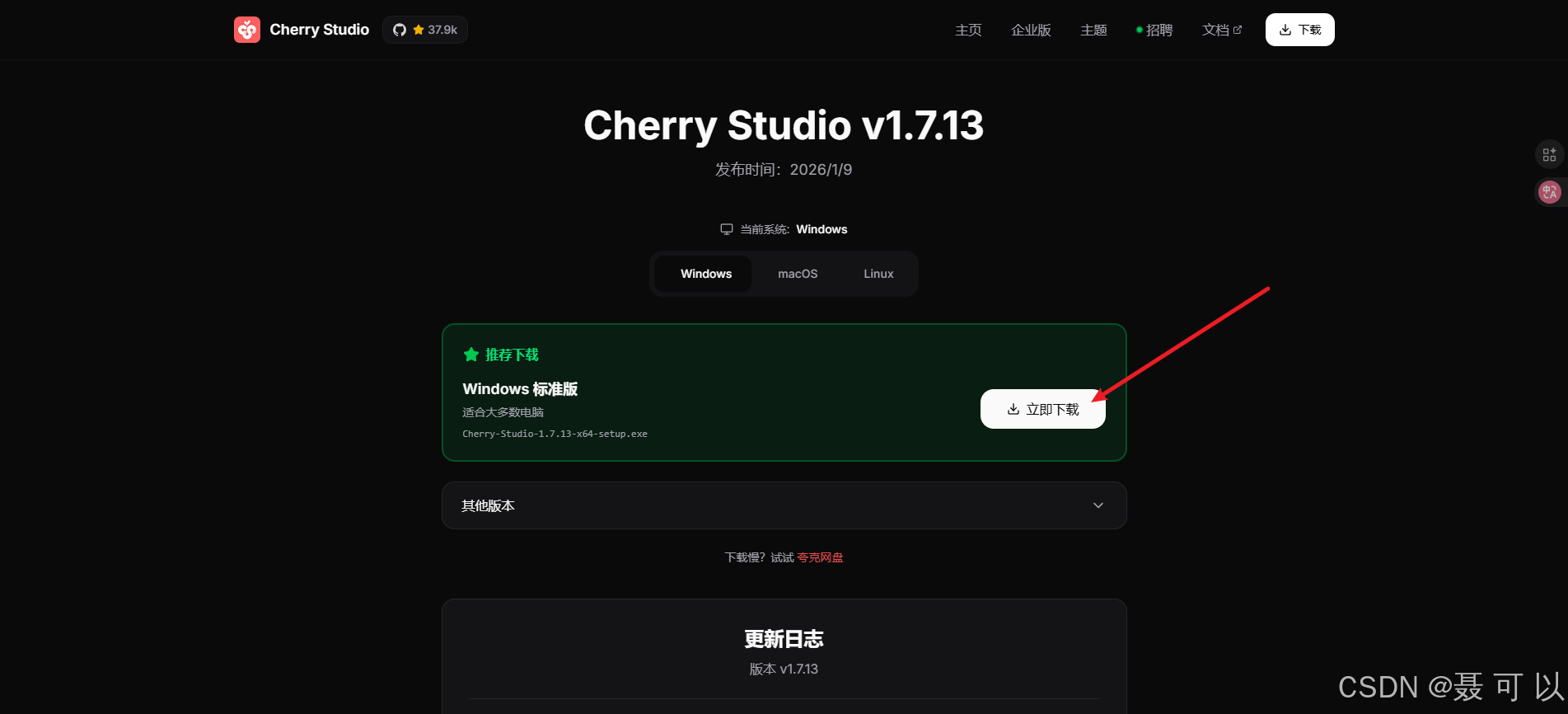
3.1.2 安装
双击 Cherry Studio 安装包,一路点击下一步即可
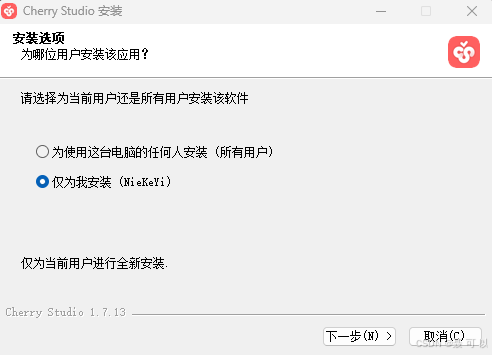
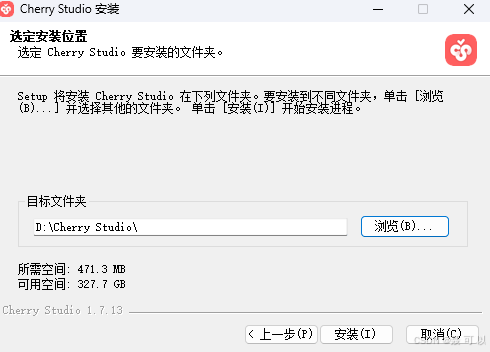
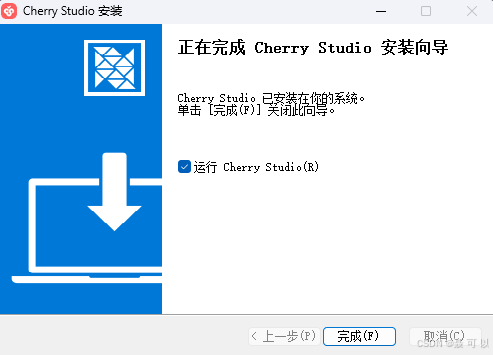
看到以下界面说明 Cherry Studio 安装成功了
3.2 AingDesk(个人使用和商用均免费)
3.2.1 下载
3.2.1.1 通过GitHub下载
下载地址:https://github.com/aingdesk/AingDesk
https://github.com/aingdesk/AingDesk
如果无法正常访问 GitHub,可以参考我的另一篇博文:GitHub的使用技巧(加速访问GitHub、查看GitHub的热门项目、查看GitHub推荐的项目、Fork、Issue、快速找到项目的安装包、GitHub的各种快捷键)
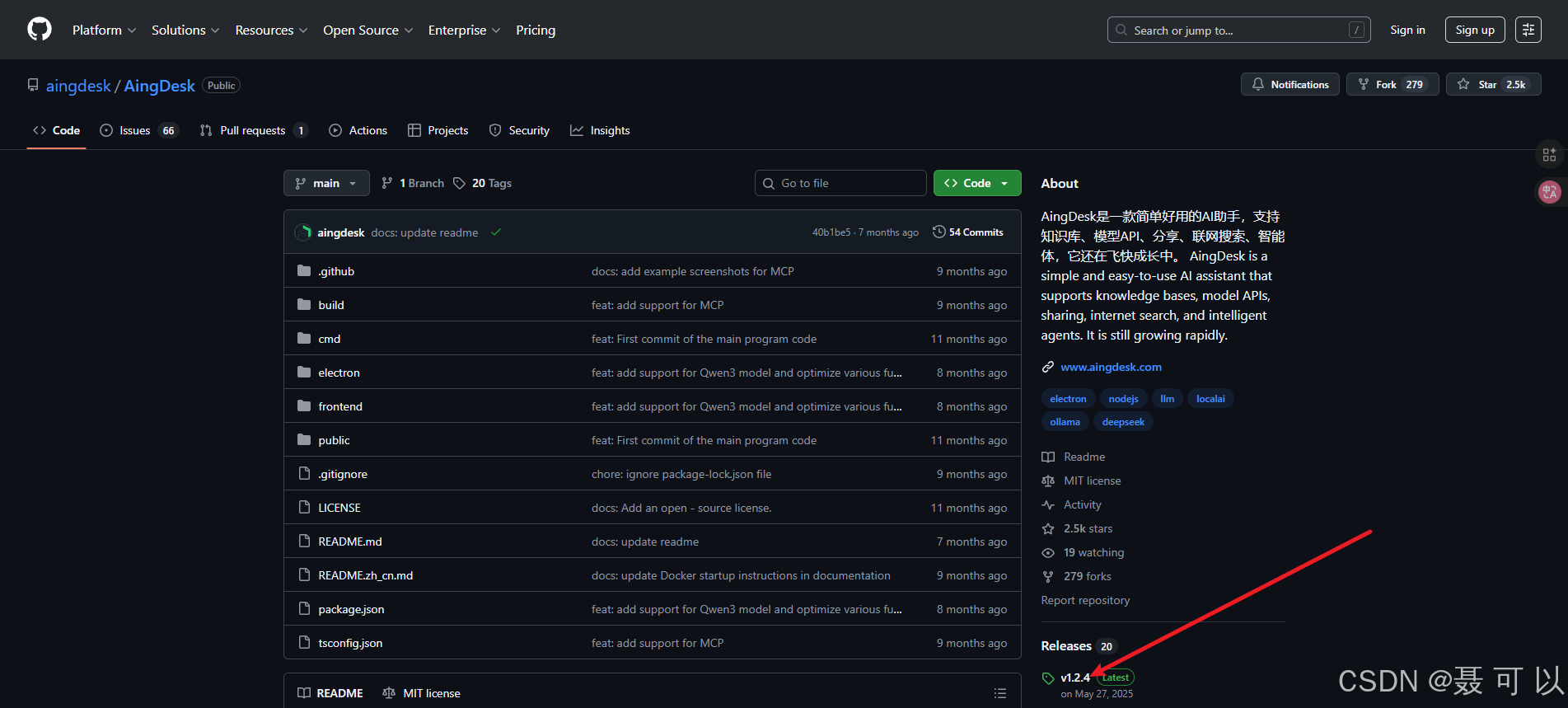
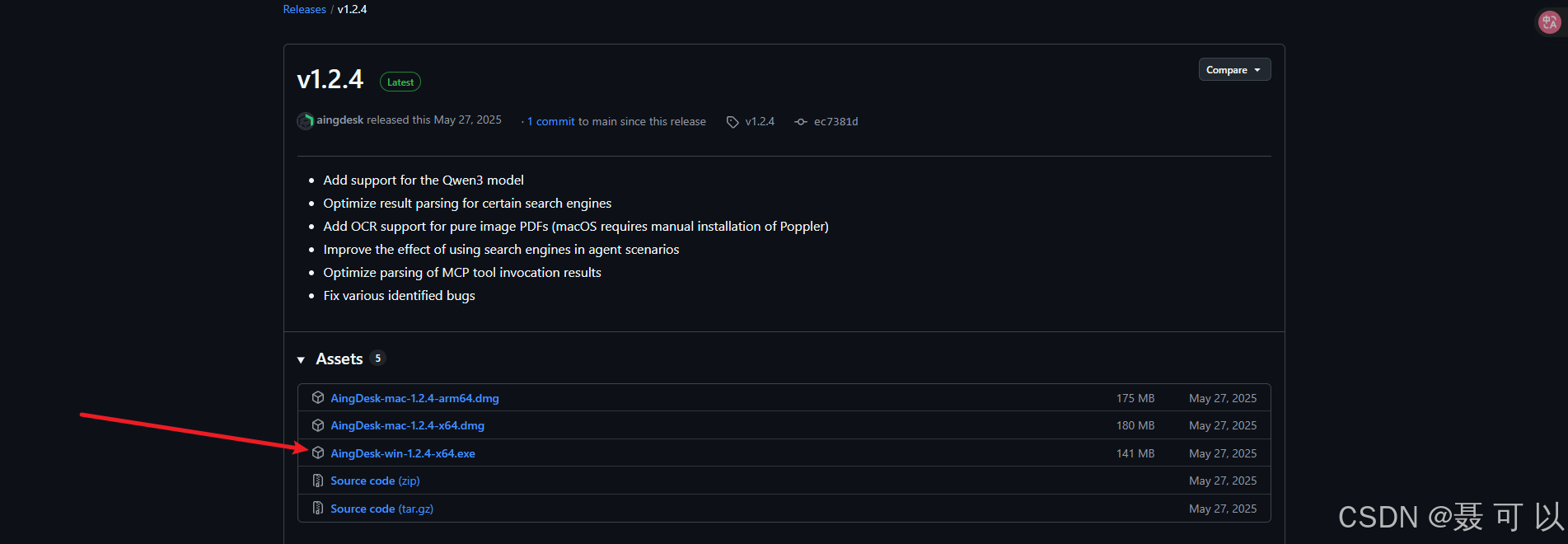
3.2.1.2 通过腾讯CNB下载
下载地址:https://cnb.cool/aingdesk/AingDesk/-/releases
https://cnb.cool/aingdesk/AingDesk/-/releases
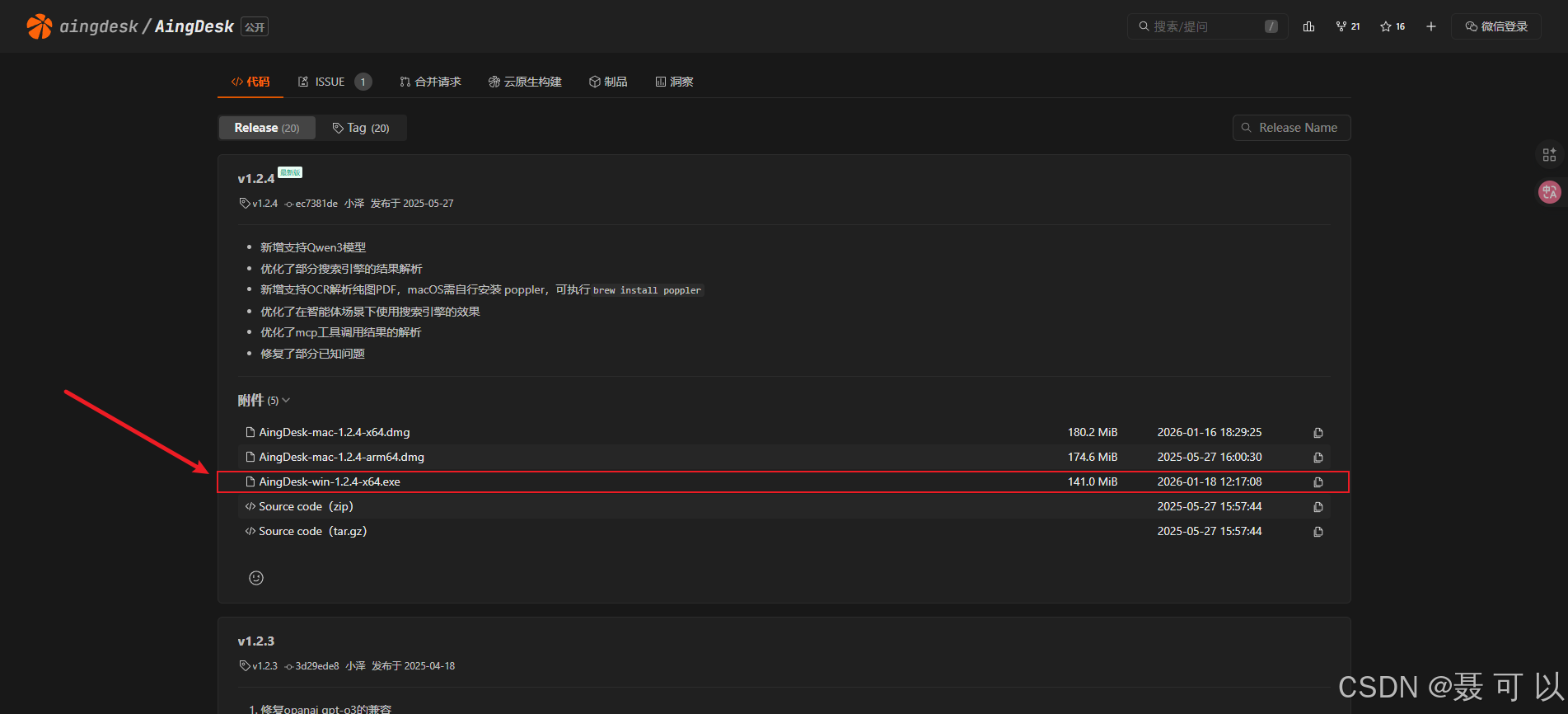
3.2.2 安装
双击 AingDesk-win-1.2.4-x64.exe 文件,一路点击下一步就可以了

看到以下界面说明 AingDesk 安装成功了

4. 使用软件与AI大模型进行交互
4.1 使用Ollama与AI大模型进行交互
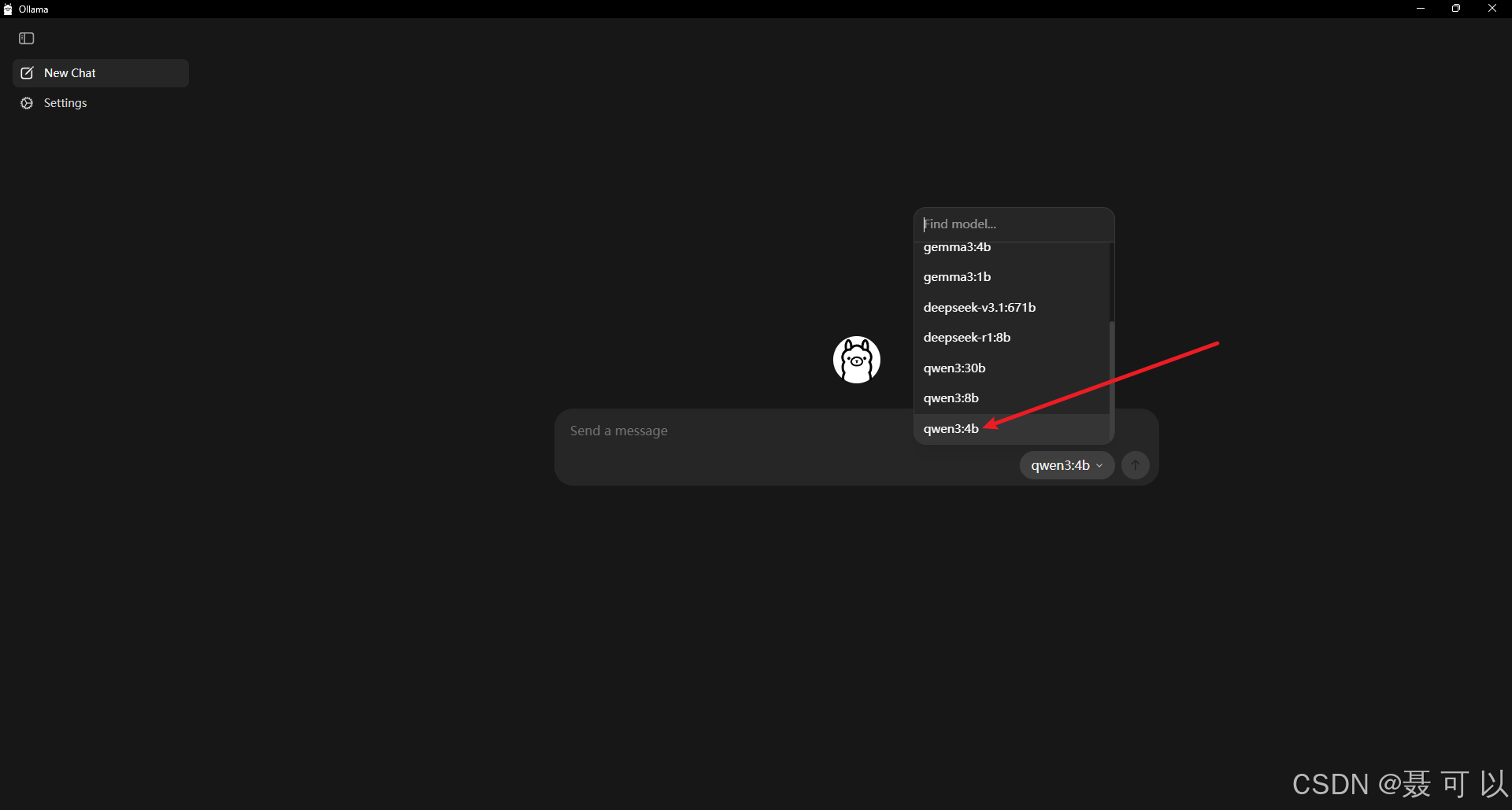
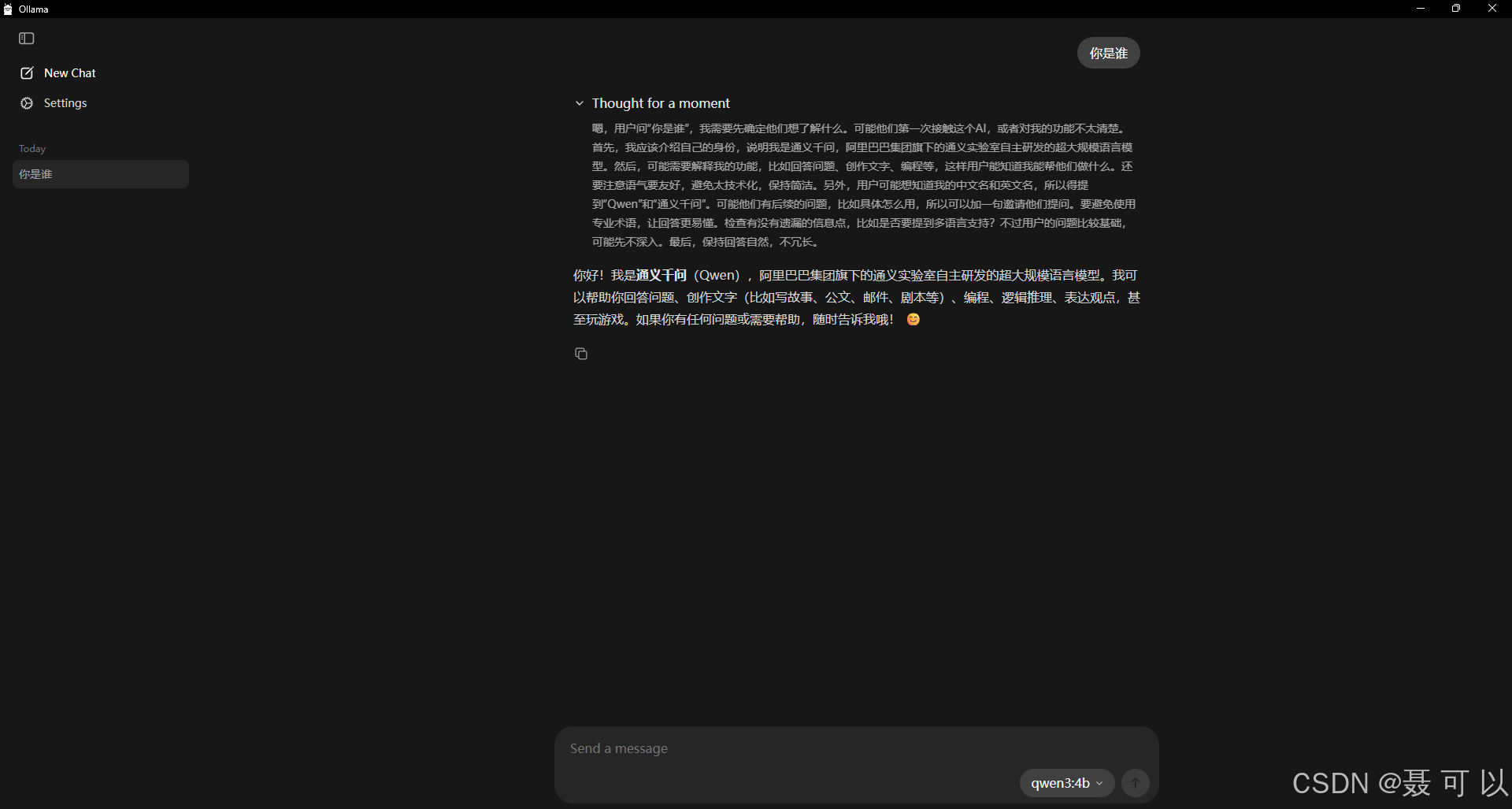
在 Ollama 中也与 AI 大模型进行交互
选择我们下载好的 qwen3:4b 模型
4.2 使用Cherry Studio与AI大模型进行交互
4.2.1 添加本地AI大模型
点击右上角的设置图标
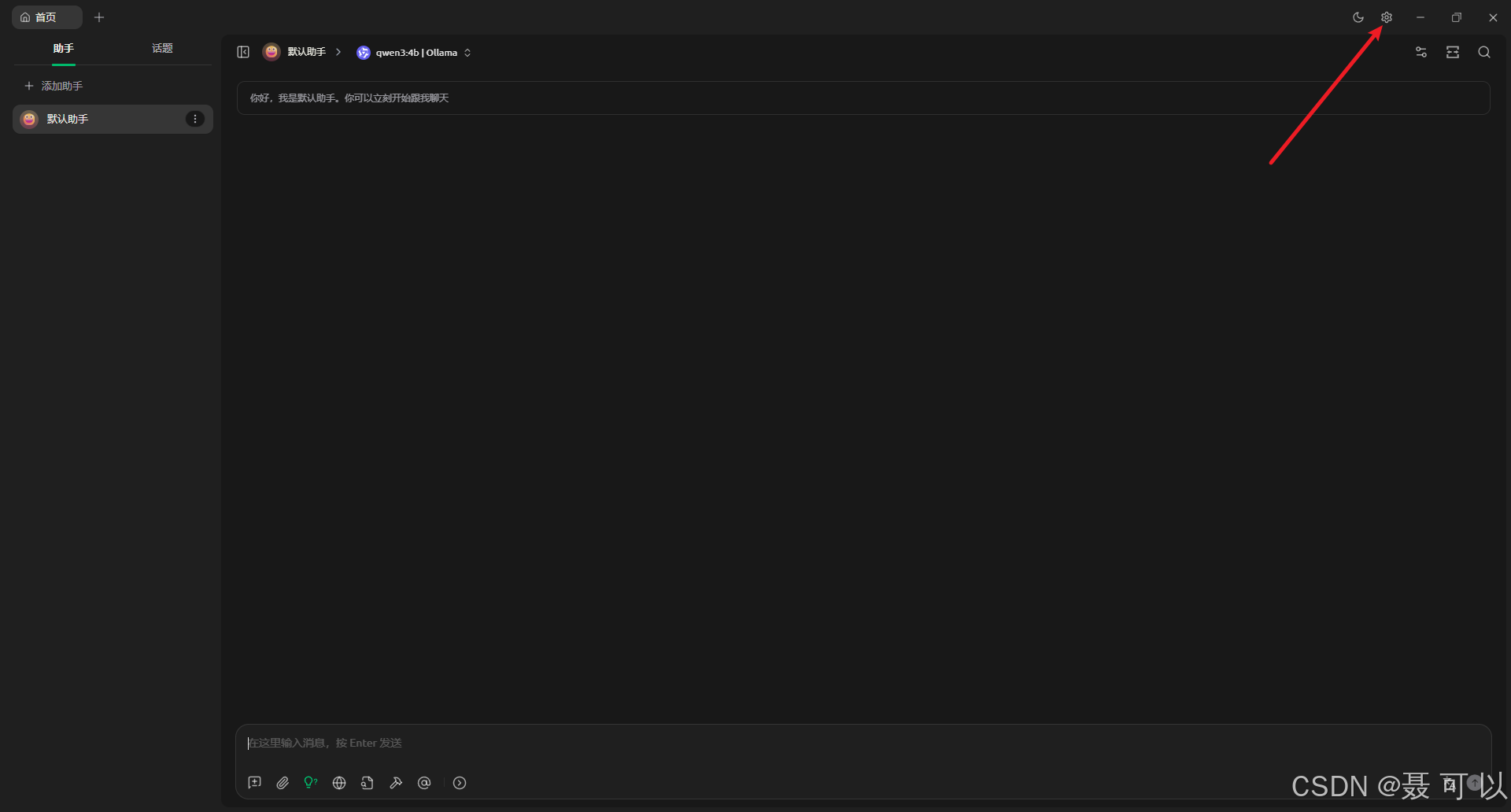
搜索 Ollama 关键字
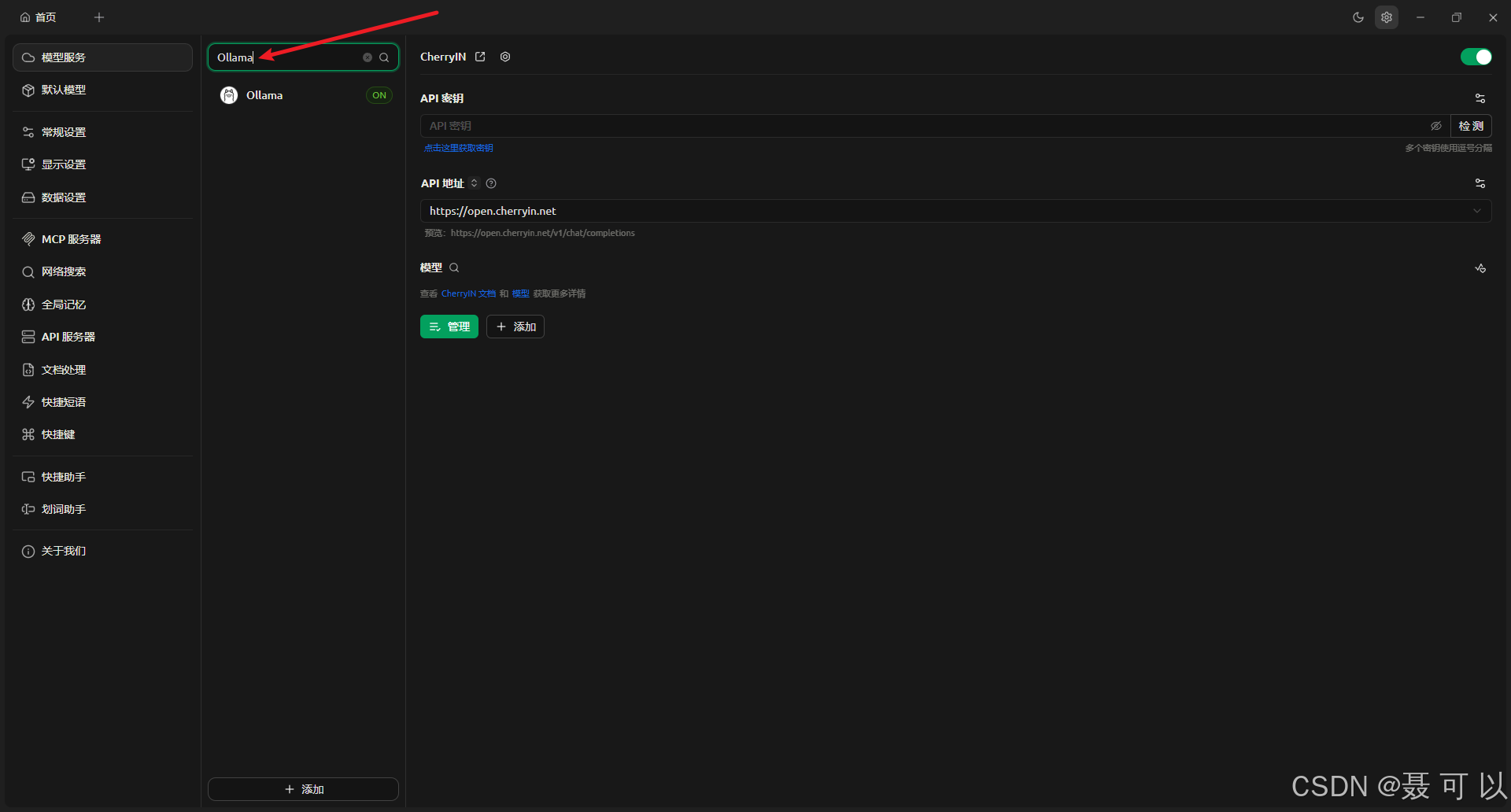
点击 Ollama 选项,再点击添加按钮
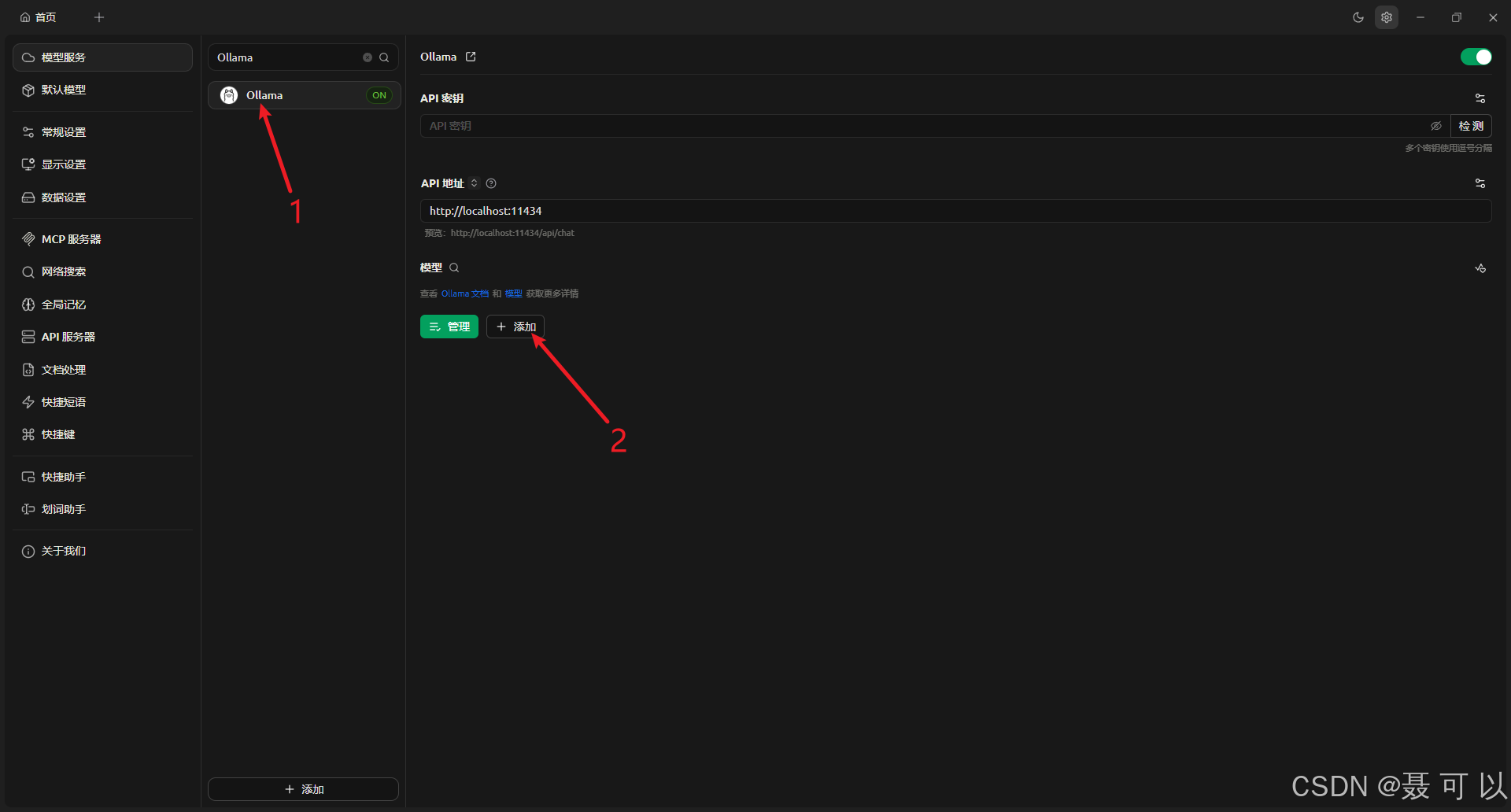
输入模型 ID 后会自动填写模型名称和分组名称
qwen3:4b
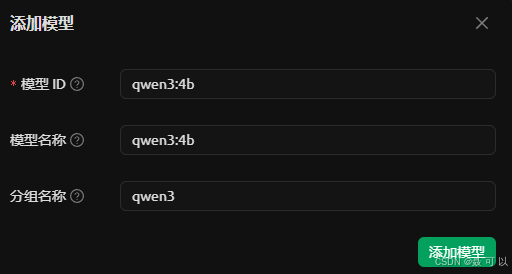
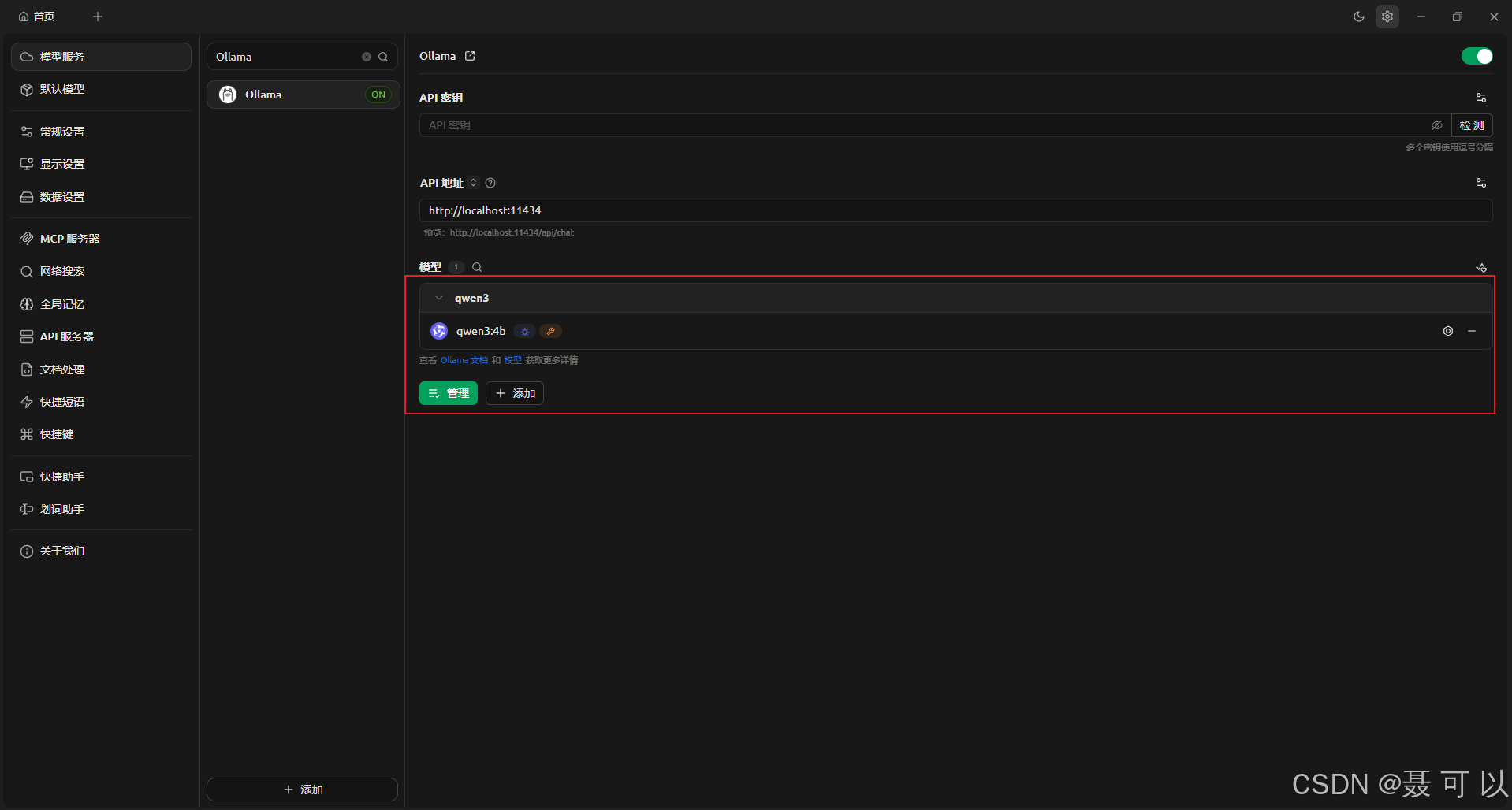
添加成功后点击左上角的首页,再点击某个对话,将对话中的模型切换为 qwen3:4b 模型,切换成功后就可以正常对话了
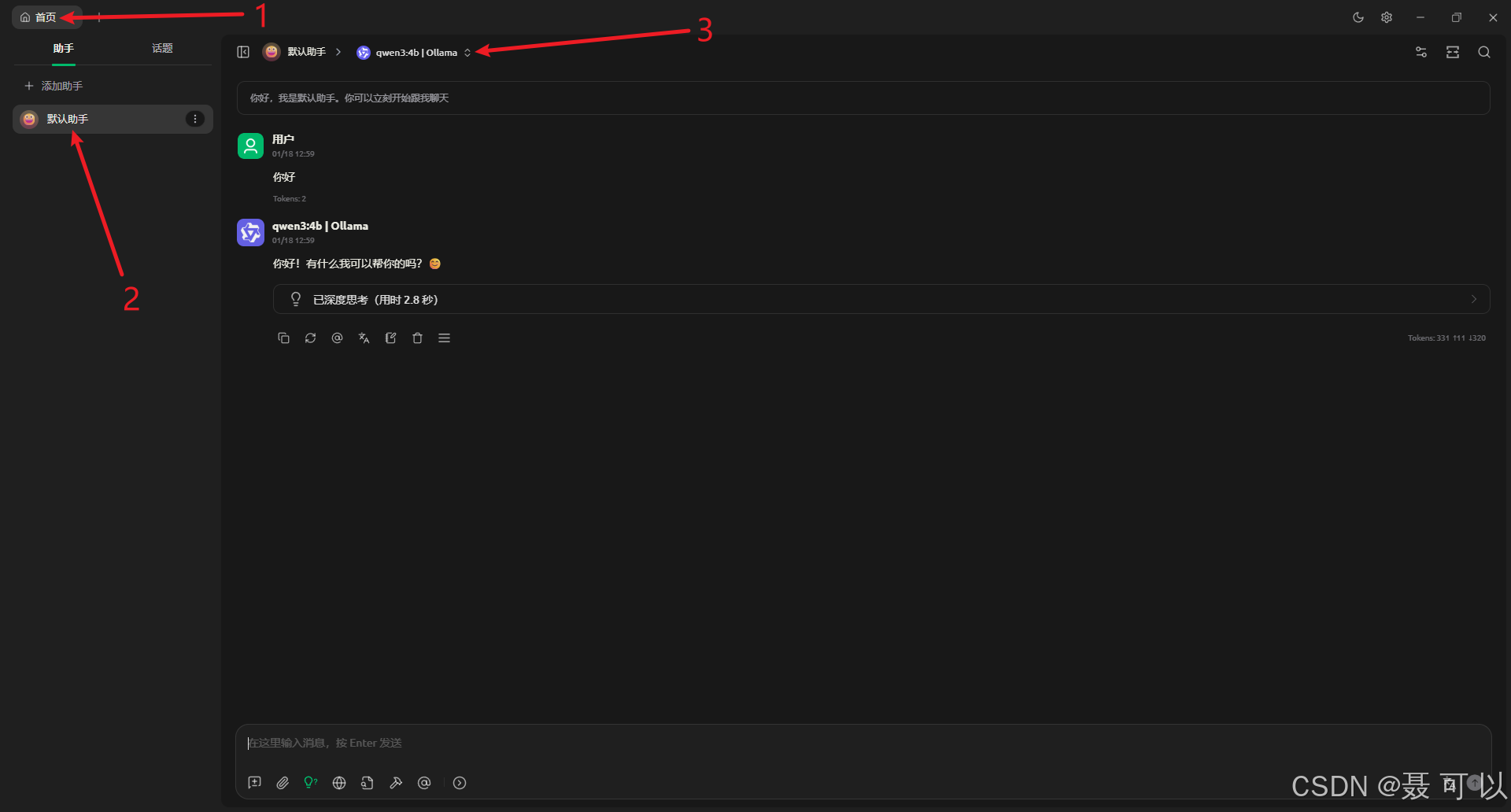
4.2.2 设置AI大模型上下文的长度
点击对话记录右边的三个小点
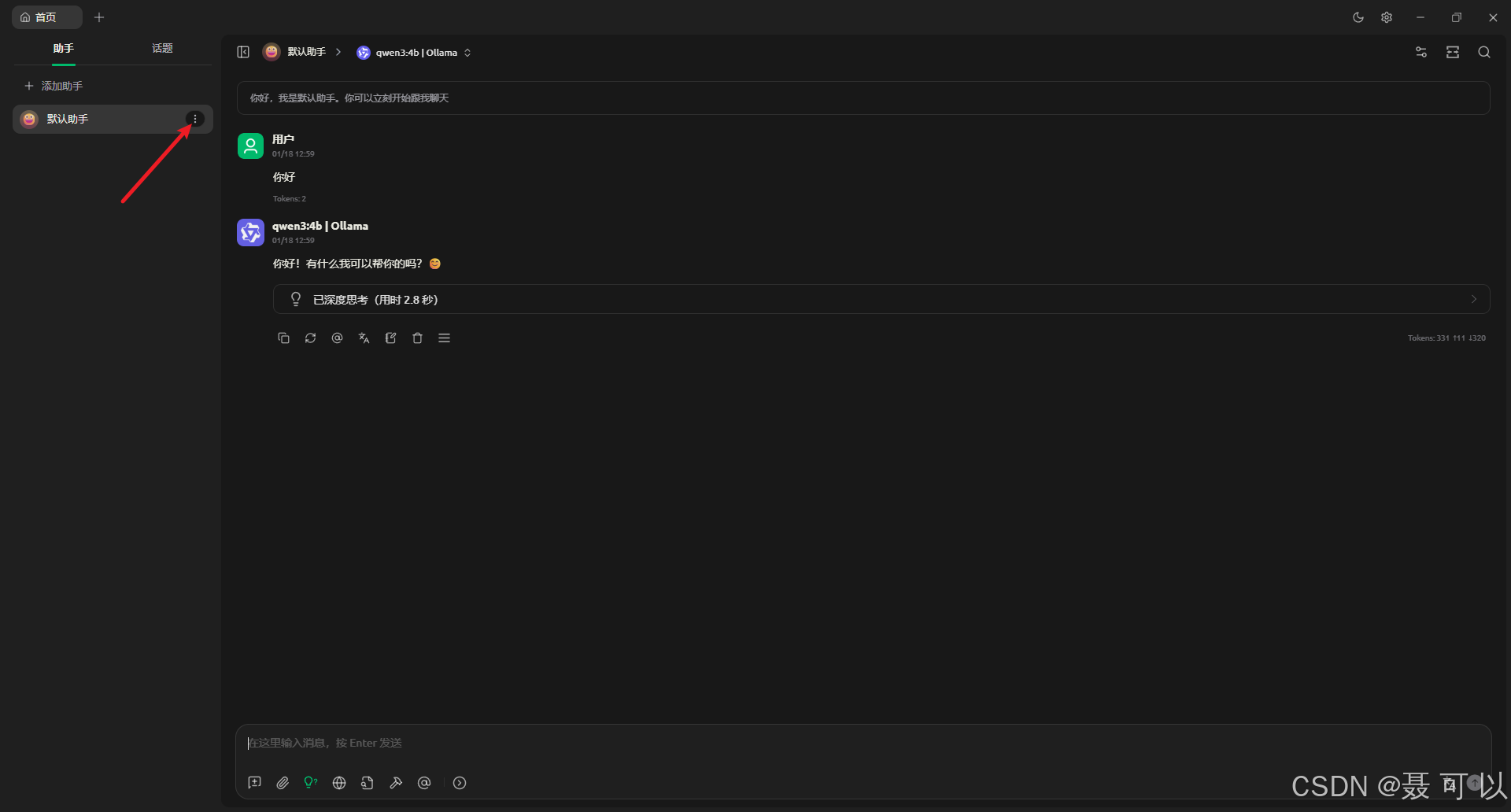
将上下文数设置为不限(之所以设置为不限,是因为我们要靠 Ollama 来限制上下文数量,而不是靠 Cherry Studio 来限制上下文数量)
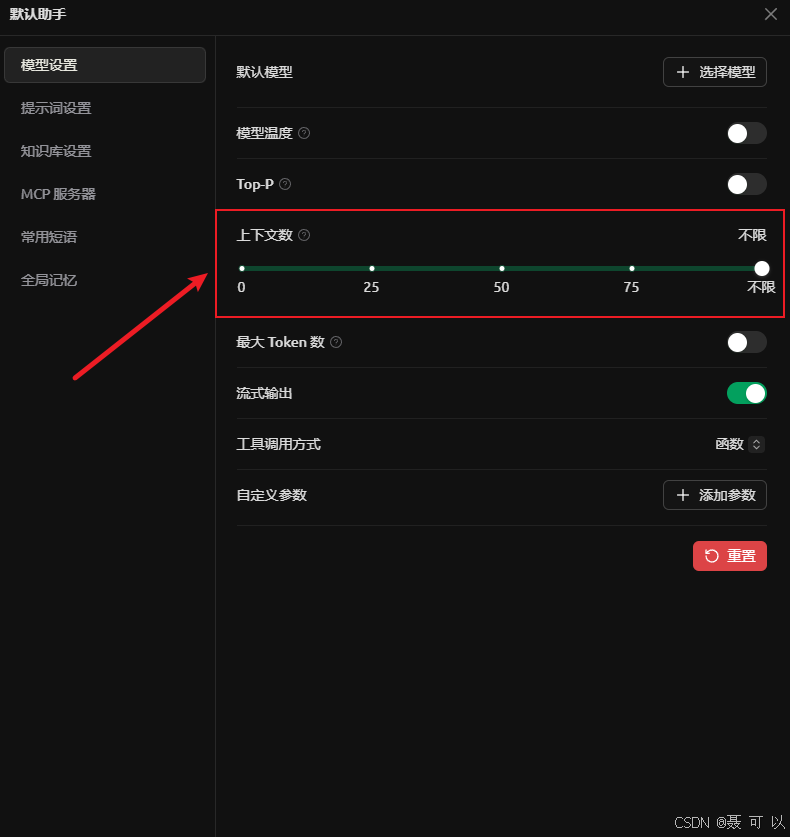
接着我们打开 Ollama 的界面,点击 Settings 按钮
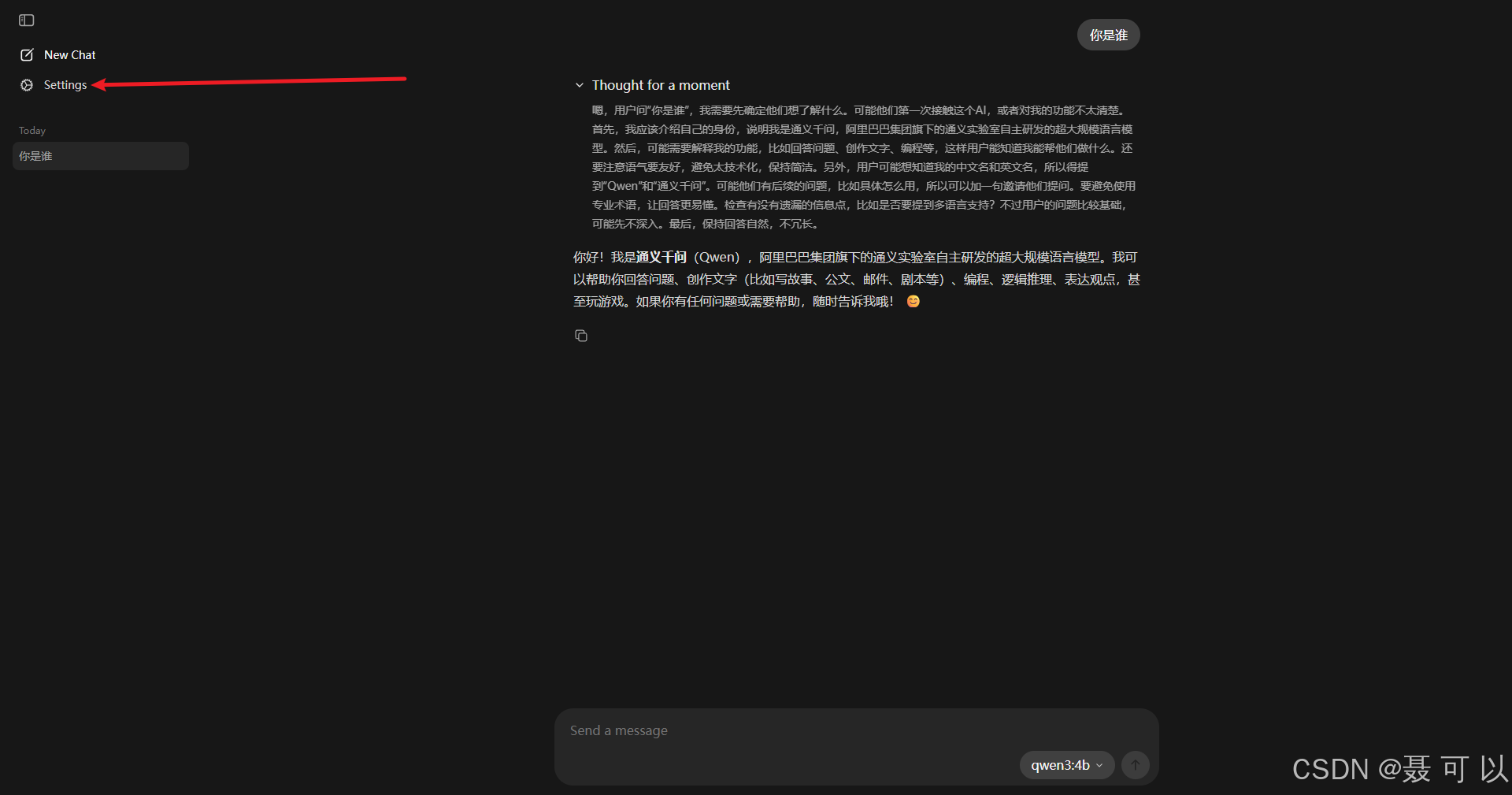
即使你的对话没有任何记录,在机器硬件配置有限的情况下,上下文长度变大,大模型的处理速度也会下降
根据大模型的吐字速度灵活调整上下文长度,在机器配置有限的情况下,上下文长度越长,大模型的处理速度(吐字速度越慢)越慢
4.3 使用AingDesk与AI大模型进行交互
使用本地模型
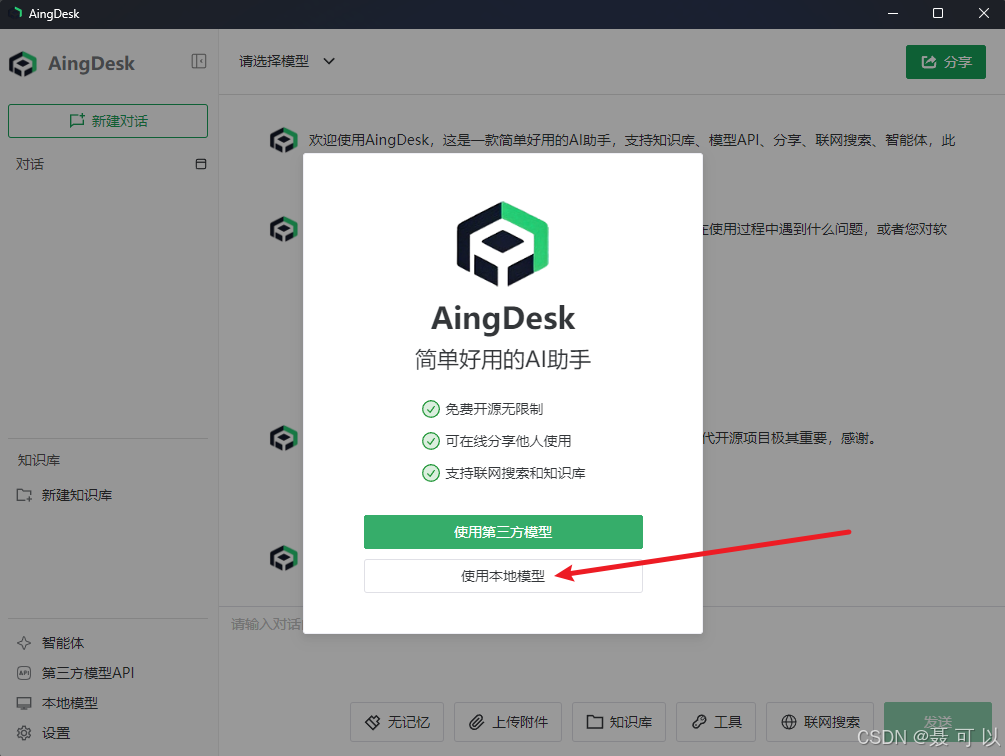
查看已安装的模型
选择我们安装好的 qwen:3b 模型
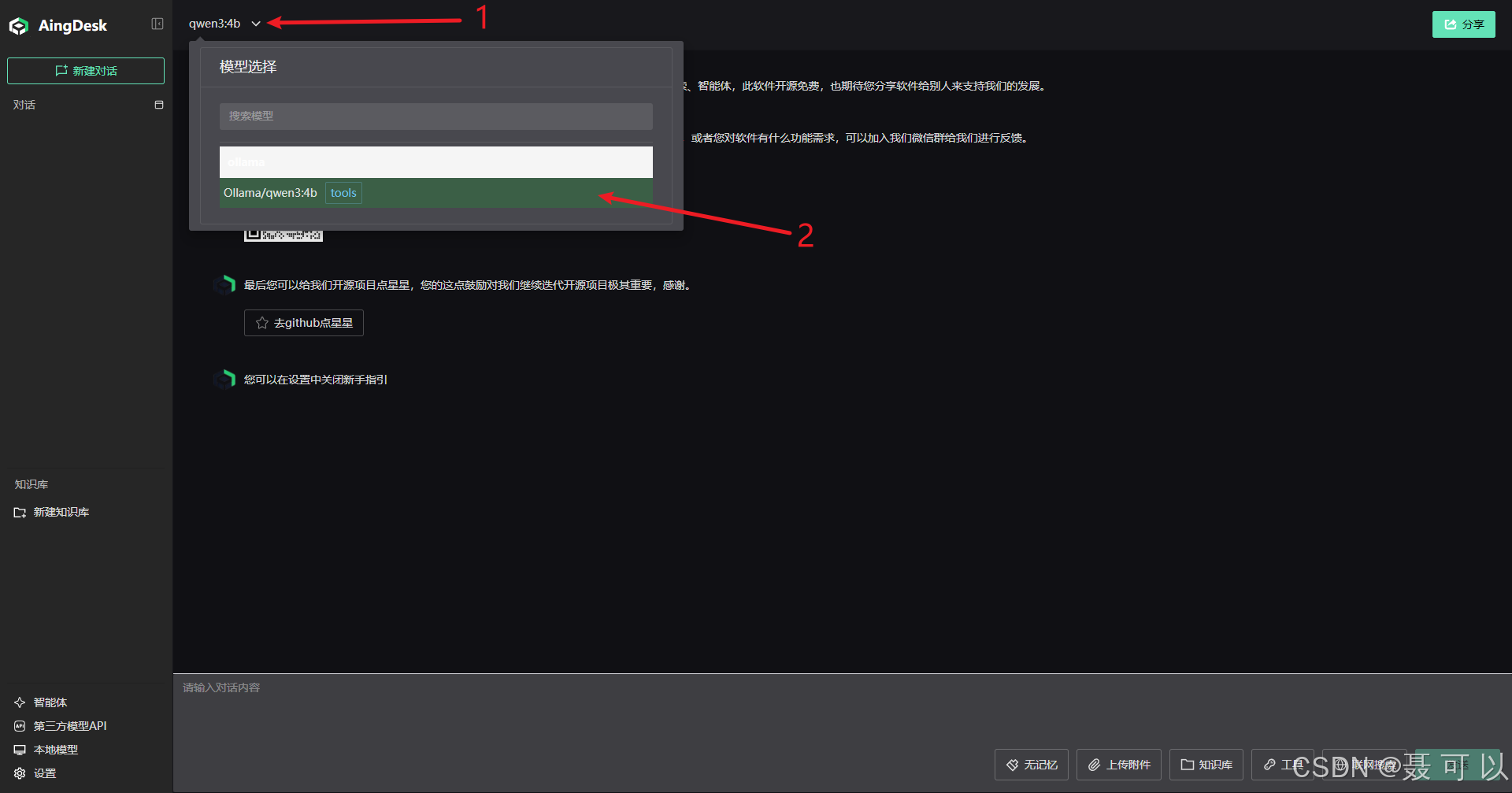
在下方的输入框中输入提问内容
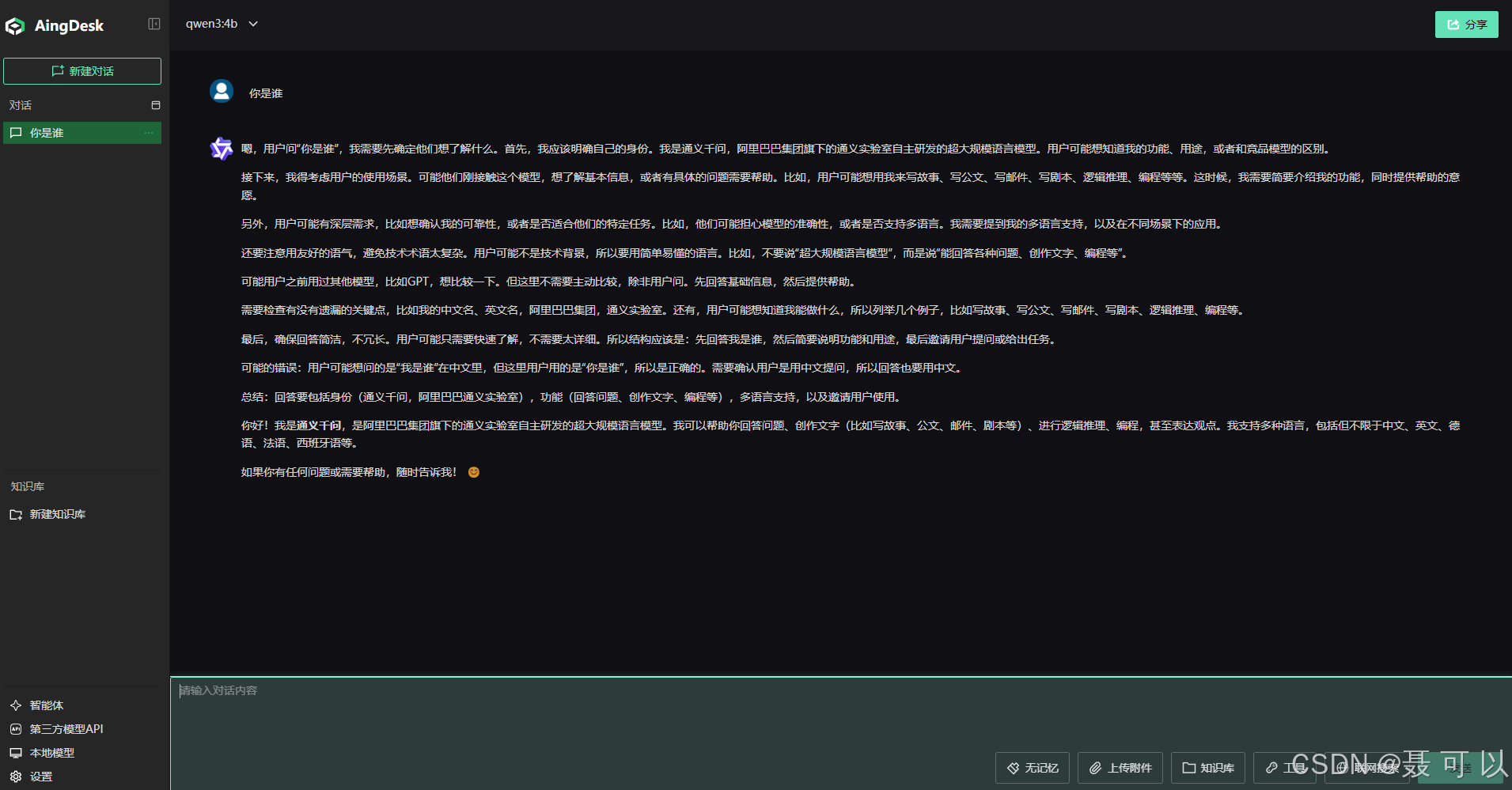
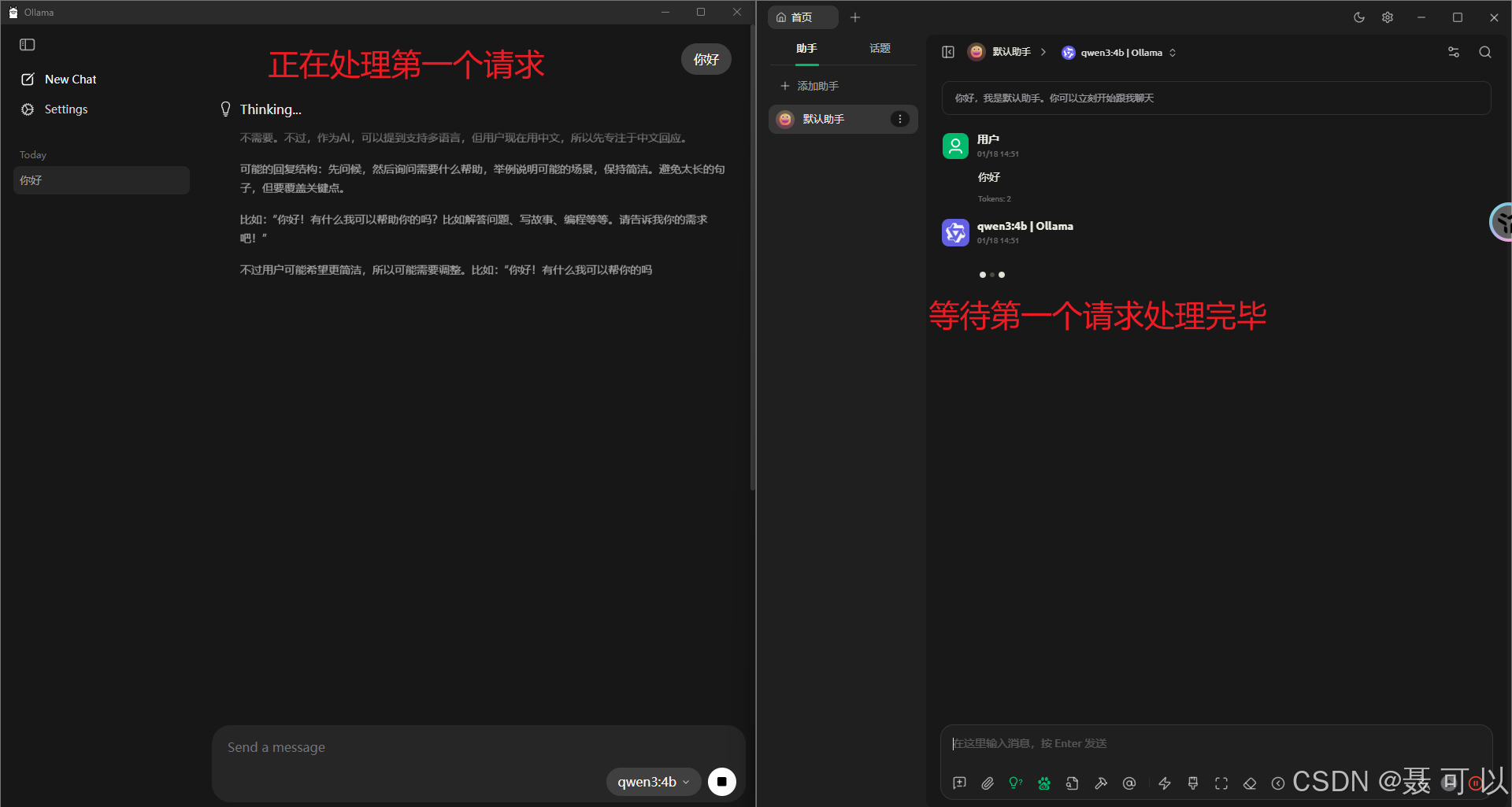
5. 解决ollama中AI大模型只能同时处理一个请求的问题
默认情况下,如果同时打开两个聊天窗口,ollama 需要处理完第一个请求之后才能处理第二个请求
5.1 添加OLLAMA_NUM_PARALLEL系统环境变量
我们可以通过添加 OLLAMA_NUM_PARALLEL 系统环境变量来设置 ollama 支持的请求并发数
按下 win + i 快捷键,搜索环境变量关键字,点击编辑系统环境变量
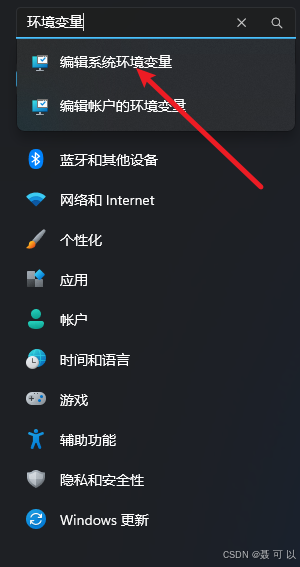
点击环境变量
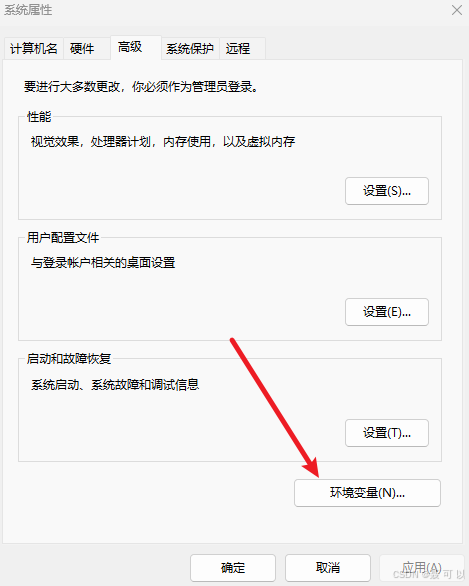
点击新建
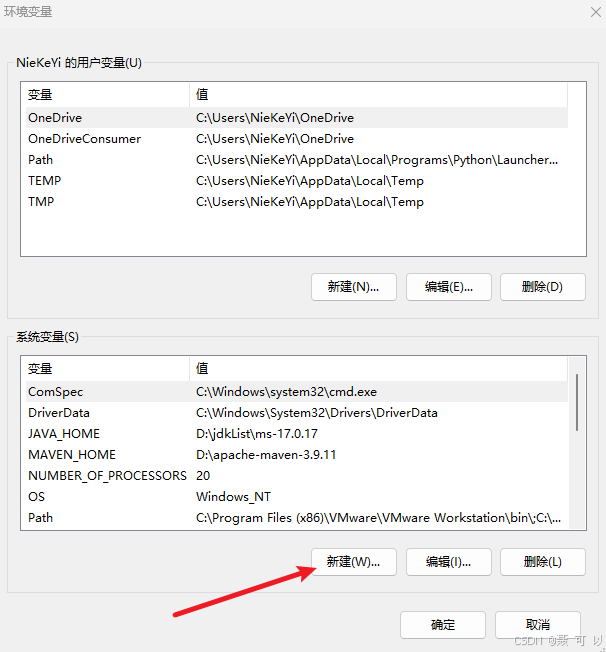
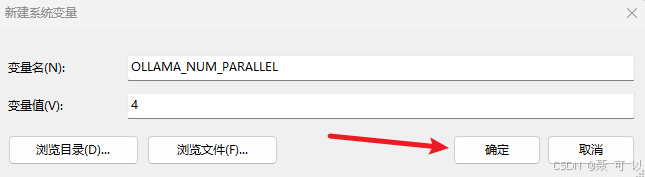
变量名称为 OLLAMA_NUM_PARALLEL,变量的值为并发数
OLLAMA_NUM_PARALLEL
添加完 OLLAMA_NUM_PARALLEL 环境变量后,点击打开的窗口的所有确定按钮,保存更改
5.2 重启ollama
在任务栏中鼠标右键 Ollama 图标,暂时关闭 Ollama
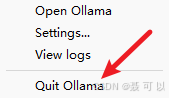
再次打开 Ollama,可以发现 Ollama 已经支持同时处理多个请求了
6. 本地部署AI大模型时可能遇到的问题
6.1 AI大模型的处理速度(吐字速度)十分慢
如果大模型的吐字速度十分慢,大概率是因为上下文长度太长了,在机器硬件配置有限的情况下,可以适当减小上下文的长度
我们打开 Ollama 的界面,点击 Settings 按钮
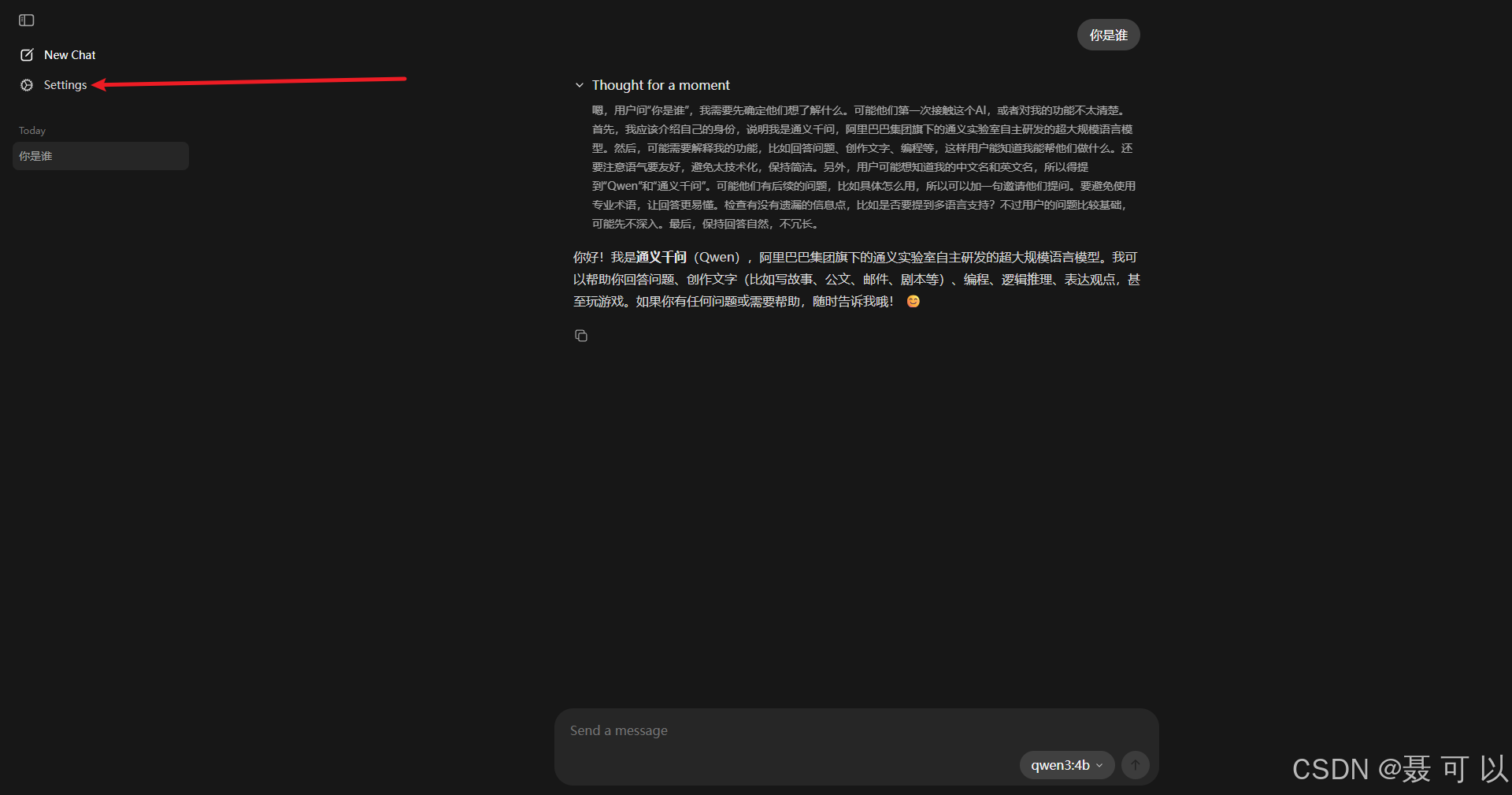
即使你的对话没有任何记录,在机器硬件配置有限的情况下,上下文长度变大,大模型的处理速度也会下降
根据大模型的吐字速度灵活调整上下文长度,在机器配置有限的情况下,上下文长度越长,大模型的处理速度(吐字速度)越慢
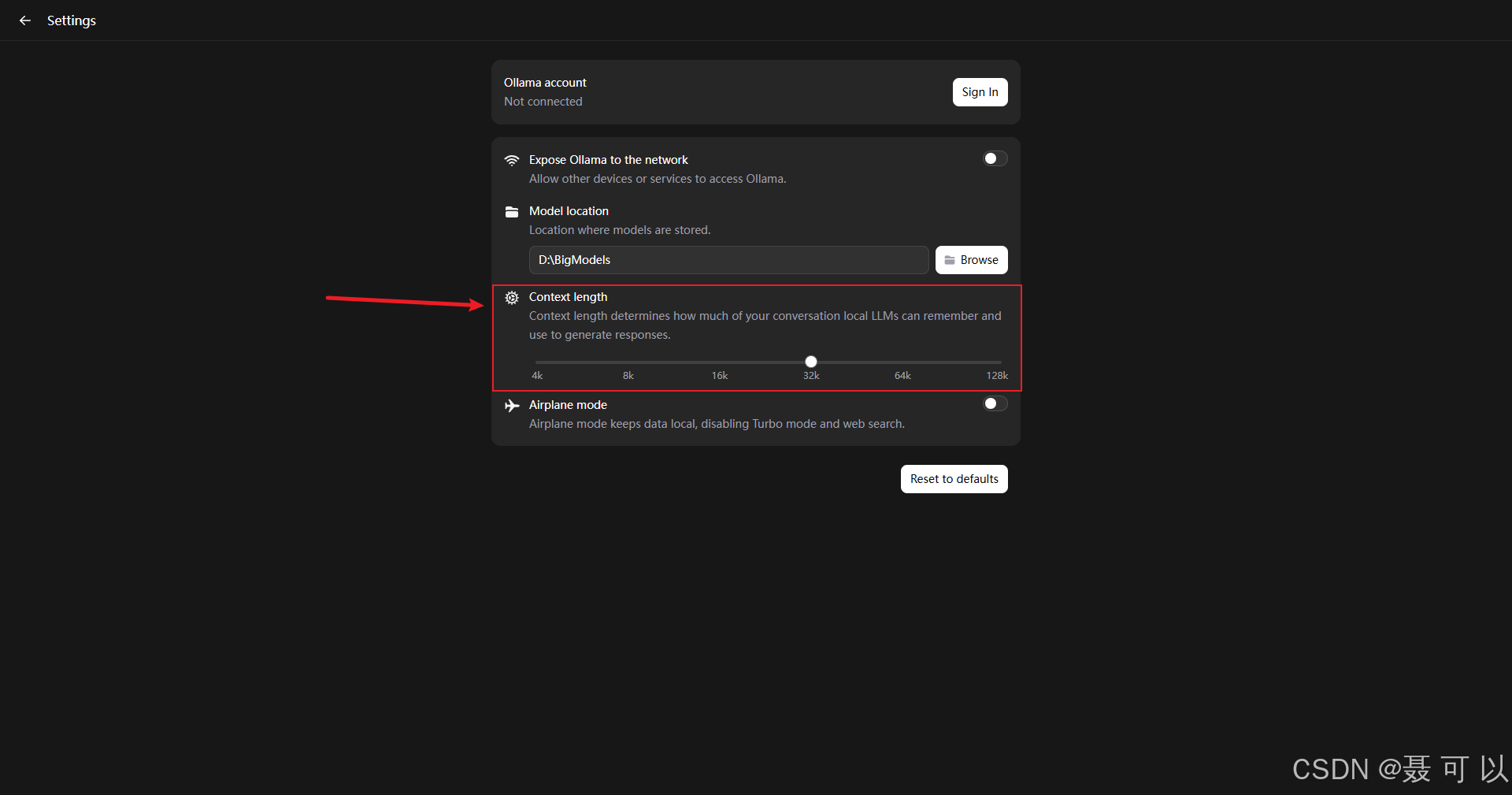
6.2 使用Cherry Studio与AI大模型交互时报错(model requires more system memory)
6.2.1 问题呈现
如果在使用 Cherry Studio 与 AI 大模型交互时报错
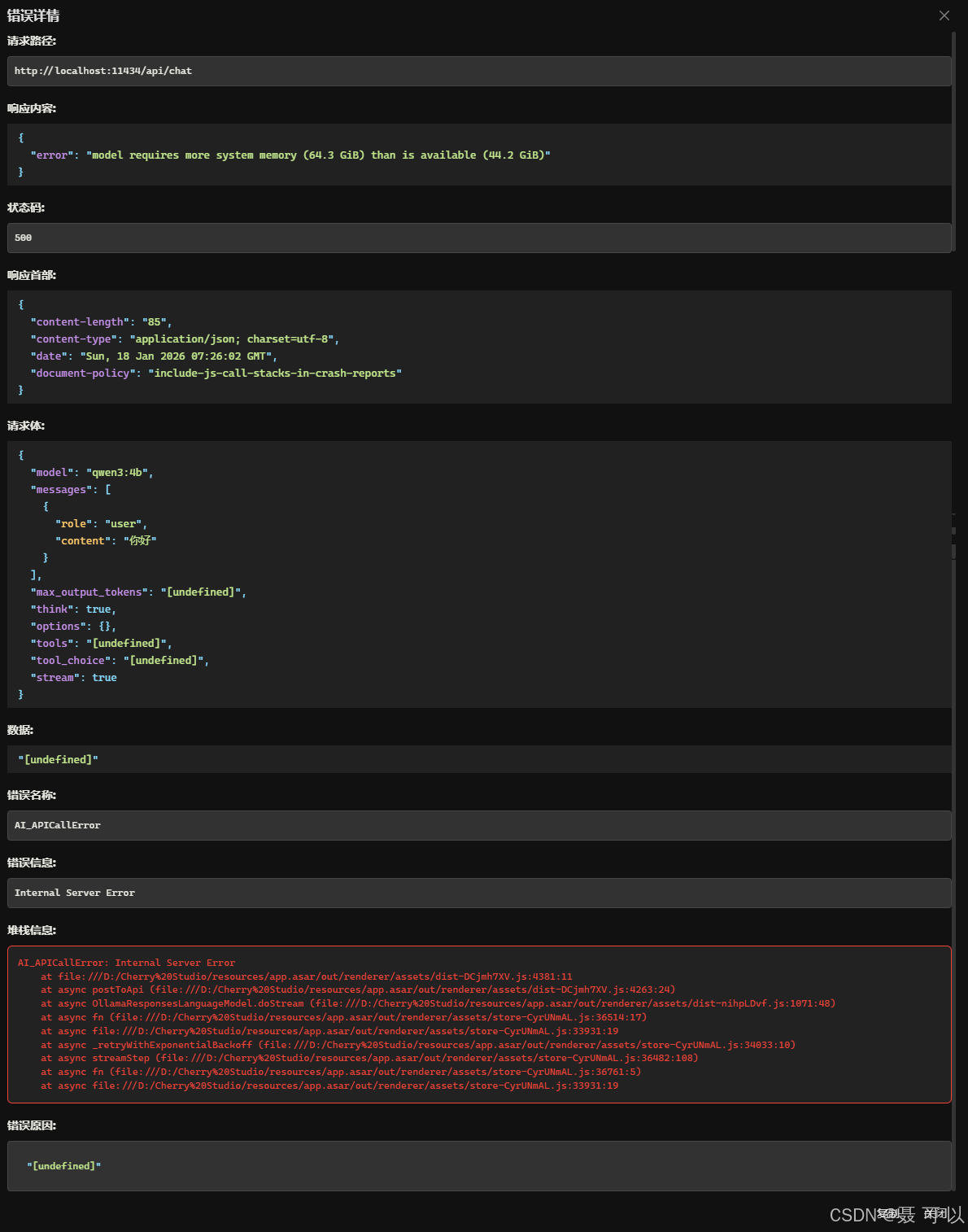
点开错误详情后发现相应内容为
“error”: “model requires more system memory (64.3 GiB) than is available (44.2 GiB)”
6.2.2 解决方法
之所以出现这个问题,是因为 Ollama 支持的请求并发数设置得太大了,或者 AI 大模型上下文长度太大了,机器拉不动
要解决这个问题,我们需要调整 Ollama 支持的请求并发数或调整 AI 大模型的上下文长度:
- 调整 AI 大模型的上下文长度:参考本文的 AI大模型的吐字速度十分慢 章节
- 调整 Ollama 支持的请求并发数:参考本文的 解决ollama只能同时处理一个请求的问题 章节
7. 如何停止正在运行的AI大模型
默认情况下,如果 4 分钟内不再向 AI 大模型发送任何请求,Ollama 为了节省资源,会自动把 AI 大模型从内存(显存)中卸载掉,只要一直在跟 AI 大模型对话,这个时间就会一直重置
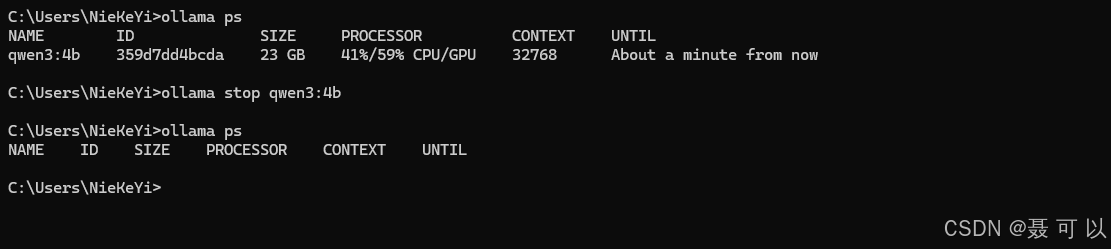
按下 win + r 快捷键,输入 cmd 指令打开命令行窗口,在命令行窗口中 ollama ps 指令
ollama ps

| 字段 | 含义 |
|---|---|
| NAME | 当前正在运行的模型名称(这里是 Qwen3 的 4B 版本) |
| ID | 模型实例的唯一标识哈希值,用于区分不同的会话实例 |
| SIZE | 这个模型当前占用的显存(或内存)大小。如果看到 20多 GB,说明模型很大或者被加载到了显存中 |
| PROCESSOR | 显示模型的计算资源分配情况。目前模型正在混合使用 CPU 和 GPU,大约 36% 的负载在 CPU 上,64% 的负载在 GPU 上。这通常是好事,说明你的 GPU 正在承担主要工作 |
| CONTEXT | 上下文窗口大小,即模型能"记住"的最多 Token(词元)数量。32768 表示 32k 的上下文长度 |
| UNTIL | 自动卸载倒计时。这表示如果你在接下来的 4 分钟内不再向这个模型发送任何请求,Ollama 为了节省资源,会自动把它从内存(显存)中卸载掉。只要你在跟它对话,这个时间就会一直重置 |
按下 win + r 快捷键,输入 cmd 指令打开命令行窗口,在命令行窗口中 ollama stop qwen3:4b 指令停止正在运行的 AI 大模型,其中 qwen3:4b 为 AI 大模型的名称
ollama stop qwen3:4b
8. 参考视频

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 42
42 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)