计算机基础·cs336-torch基础
本文总结了PyTorch张量操作、模型训练和优化器使用中的关键知识点。主要内容包括:张量连续性概念及view/transpose操作的内存共享特性;矩阵乘法(bmm/einsum)的实现方式;模型参数管理(Parameter/register_buffer区别)和初始化方法;常用张量操作函数(tril/masked_fill/scatter/gather等);训练模式切换(train/eval)注
·
torch张量性质
连续性contiguous:
- 维护内存和张量维度的一致性
view,transpose等操作不会新建内存,也就是共享存储空间(变量)。
# view
x = torch.tensor([[1., 2, 3], [4, 5, 6]])
y_view=x.view(3,2)
y_trans=x.transpose(0,1)
# same storage
x[0,0]=9
y_trans
tensor([[1., 2.],
[3., 4.],
[5., 6.]])
tensor([[9., 4.],
[2., 5.],
[3., 6.]])
view 需要连续内存;非连续张量先 .contiguous()
- transpose/permute/步长切片产生视图,共享存储但多为非连续。
- contiguous() 会复制数据,把当前逻辑顺序重排为物理连续。
# contiguous
print(y_trans.is_contiguous(),y_view.is_contiguous())
# not contiguous to contiguous
y_origin_=y_trans.contiguous().view(2,3)
y_origin_
*Rearrange维度变换
- 类似爱因斯坦乘法那样定义矩阵维度,然后进行矩阵形状的变化(不需要考虑矩阵存储的连续性)。
from einops import rearrange# 建议使用
q= rearrange(q,' ... l (h d)-> ... h l d',h=self.num_heads,d=self.d_k)
torch运算
矩阵乘法
批量乘法
- 简单来说就是忽略第一维度的乘法
x=torch.ones(2, 3, 4)# B L D
y=torch.ones(2, 3, 4)
z=torch.bmm(x,y.transpose(1,2))# bmm ignore batch size
z.shape
torch.Size([2, 3, 3])
*爱因斯坦乘法
- 为每一个维度进行命名,然后给出乘法样式(输入和输出维度,
a b c,d e f->e f g) - 维度命名只支持单字符
x=torch.ones(2, 3, 4)# B L D
y=torch.ones(2, 3, 4)
z = torch.einsum("b l d, b m d -> b l m", x, y)# 仅支持单字符标签
print(z.shape)
模型参数细节
nn.Parameter vs nn.Register_buffer:
- nn.Parameter:可训练参数,参与反向传播,优化器会更新;属于模块参数列表,会出现在 state_dict(作为参数)。
- register_buffer:非训练状态(缓冲区),不参与梯度计算与优化器更新;不在 parameters() 中,但默认也出现在 state_dict(作为缓冲区),随 to()/cuda() 迁移设备。
阶段初始化:nn.init.trunc_normal_(self.w,std=1,mean=0,a=-3,b=3)
- 使用均值为0,方差为1进行归一化,然后截断不在[a,b]范围内的初始值。
model.parameters()
- 迭代器:列表
- 用于给优化器进行训练
- 无参数名称
for p in model.parameters():
print(p.numel())
1 1 1 1 1 1
model.named_parameters()
for k,v in model.named_parameters():
print(f'layer:{k} #param:{v.numel()}')
layer:layers.0.weight #param:16
layer:layers.0.bias #param:4
layer:layers.1.weight #param:16
layer:layers.1.bias #param:4
layer:final.weight #param:4
layer:final.bias #param:1
*非常有用的一些函数
torch.tril(A,diagonal=0):保留下三角矩阵。
scores.masked_fill(mask==False,float('-inf')):将矩阵值为1/True的地方填充为指定值
- 我们得到的掩膜False值是要省略的,因此需要手动转换
mask==False。
*指定下标填充指定元素torch.scatter()
- 指定下标:
sorted_indices - 指定元素:
indices_to_remove - 维度必须一一匹配
indices_to_remove_origin.scatter_(dim=-1,index=sorted_indices,src=indices_to_remove)
获得指定下标的元素torch.gather
index=targets.unsqueeze(-1):维度必须与目标变量logits匹配
target_logits = torch.gather(logits,dim=-1,index=targets.unsqueeze(-1))
统计操作
max,sort和topk操作:返回一个元组(values,indices)
- 对于数组特定维度进行求和或排序
- 返回一个元组
(values,indices)
sorted_probs, sorted_indices = torch.sort(probs,descending=True,dim=-1)
- TOPK函数
logits_topk,indices_topk = torch.topk(logits,top_k,dim=-1)
mean和median:只返回数值
前缀和函数torch.cumsum
`cum_probs = torch.cumsum(sorted_probs,dim=-1)`
训练和测试函数
model.train() vs model.eval()
梯度
require_gradient=True,Tensor默认为Falsew.grad.data:获取梯度loss.backward():反向传播的函数,回传梯度。
x = torch.tensor([1., 2, 3])# requires_grad=False by default
w = torch.tensor([1., 1, 1], requires_grad=True) # Want gradient
y_pred=x @ w
loss = 0.5 * (y_pred - 5).pow(2)
loss.backward()
w.grad.data
优化器原理
优化器的构造和作用
- 构造:优化器会将传入的参数
optimizer = AdaGrad(model.parameters(), lr=0.01),分为组param_groups。 param_groups是一个列表,每个元素都代表一个字典,字典常见内容包括参数(model.parameters(),也是一个列表)和学习率。self.state:表示优化器自身的一些超参数,例如动量,累积梯度等信息。p.data -= lr * grad / torch.sqrt(g2 + 1e-5):手动实现梯度下降方法
class AdaGrad(torch.optim.Optimizer):
def __init__(self, params, lr: float = 0.01):
super(AdaGrad, self).__init__(params, dict(lr=lr))
def step(self):
for group in self.param_groups:
lr = group["lr"]
for p in group["params"]:
# Optimizer state
state = self.state[p]
grad = p.grad.data
# Get squared gradients g2 = sum_{i<t} g_i^2
g2 = state.get("g2", torch.zeros_like(grad))
# Update optimizer state
g2 += torch.square(grad)
state["g2"] = g2 # 每个参数对应一个新的状态
# Update parameters
p.data -= lr * grad / torch.sqrt(g2 + 1e-5)
- 自定义优化器:手动实现
step操作:关键点在于保存状态和实现梯度下降。
optimizer.zero_grad(set_to_none=True):使用优化器清空梯度,在反向传播前使用。
模型和优化器的状态:state_dict()
optimizer.state_dict()
- 包含
state和param_groups两个参数 - 每一个
param_groups都是一个列表,数量等于你传入多少个模型的参数 - 列表元素是一个字典,包含该模型对应的参数
params(只给出了注册时的下标),包括optimizer初始化时将它们捆绑在一起的学习率等参数lr,betas,eps等
from torch.optim import AdamW
optimizer = AdamW([
{'params': model1.parameters(), 'lr': 1e-3, 'weight_decay': 1e-2},
{'params': model2.parameters(), 'lr': 5e-4, 'weight_decay': 0.0},
])
optimizer.state_dict()
{'state': {},
'param_groups': [{'lr': 0.001,
'weight_decay': 0.01,
'betas': (0.9, 0.999),
'eps': 1e-08,
'amsgrad': False,
'foreach': None,
'maximize': False,
'capturable': False,
'differentiable': False,
'fused': None,
'params': [0, 1, 2, 3]},
{'lr': 0.0005,
'weight_decay': 0.0,
'betas': (0.9, 0.999),
'eps': 1e-08,
'amsgrad': False,
'foreach': None,
'maximize': False,
'capturable': False,
'differentiable': False,
'fused': None,
'params': [4, 5, 6, 7]}]}
model.state_dict
- 字典:{名称:参数张量}
- 模型的参数:名称+参数张量,保存中间缓存信息
- 用于保存
for k,v in model.state_dict().items():
print(f'layer:{k} #param:{v.numel()}')
layer:layers.0.weight #param:16
layer:layers.0.bias #param:4
layer:layers.1.weight #param:16
layer:layers.1.bias #param:4
layer:final.weight #param:4
layer:final.bias #param:1
state_dict命名原则:{模块对应的属性名}.{模块索引}.{参数对应的属性名}
- {参数对应的属性名}
class model(nn.Module):
def __init__():
self.w = ...
model.state_dict()
"w":xxx
- {模块对应的属性名}.{模块索引}.{参数对应的属性名}
class model(nn.Module):
def __init__():
self.layers = nn.ModuleList([model1,model2...])
model.state_dict()
"layers.0.w":xxx
"layers.1.w":xxx
检查点
checkpoint = {
"model": model.state_dict(),
"optimizer": optimizer.state_dict(),
}
数据类型
torch.float32:单精度/全精度,需要4个字节来存储

torch.float16:基本不用,2个字节
torch.bfloat16:2个字节
- 特点:和
torch.float32一样,指数部分精度一致,但是小数部分精度较差。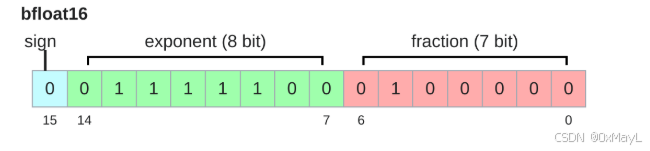
torch.bf8:
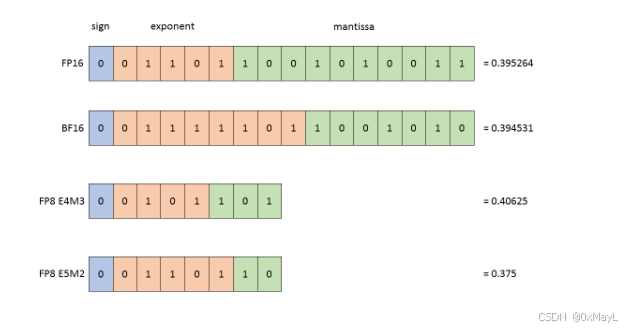
FLOP vs FLOPs vs FLOPS(FLOP/s)
- FLOP:浮点运算数量
- FLOPS=FLOP/s:每秒浮点运算数量(衡量GPU能力)
- FLOPs:需要的浮点运算能力

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)