一夜之间全上新:DeepSeek、智谱、MiniMax打响AI新战役
2026开年,中国三大头部玩家几乎同时在Agent能力超长上下文架构效率三大最前沿方向取得突破。这不再是单纯的参数规模竞赛,而是真正围绕实用落地场景的系统性技术升级。对于开发者而言,现在是中国模型最值得深度接入的窗口期:性价比、开源程度、API稳定性、社区生态都在快速赶超。你已经开始在生产环境中使用GLM-5、DeepSeek V系列或MiniMax了吗?欢迎在评论区分享你的实际体验与benchm
中国AI大模型领域近期迎来密集重磅更新,智谱AI的GLM-5、DeepSeek的超长上下文突破以及MiniMax的M2.5内测,共同勾勒出2026年中国基础模型竞赛的激烈图景。这些进展不仅在技术指标上持续逼近甚至局部超越国际一线模型,更在Agent智能体能力、长上下文处理效率和架构创新上展现出鲜明中国特色。
本文将从技术角度深度剖析这些最新动态,并结合实际应用场景与性能对比,帮助开发者与研究者更好地理解当前中国大模型的真实水平与未来方向。
智谱AI GLM-5:从“Pony Alpha”到公开登顶的Agent王者
2月11日晚,智谱AI官方正式确认:此前在OpenRouter全球热度榜长期霸榜的神秘模型“Pony Alpha”正是新一代基座模型GLM-5。目前该模型已正式在chat.z.ai平台上线供公众体验。
早在2月6日,OpenRouter悄然上线这款匿名模型,其超强编码能力、超长上下文窗口以及针对智能体工作流的深度优化迅速引爆海外开发者社区。OpenRouter官方将其定义为“前沿基础模型”,在编程、智能体任务、复杂推理和角色扮演四大维度表现出色,尤其强调“极高的工具调用准确率”——这正是当前AI Agent落地最关键的瓶颈之一。
借助极高的工具调用稳定性,开发者可以通过Claude Code等框架调用GLM-5,实现连续数小时的复杂项目自主开发,例如完整前端/后端系统迭代、算法竞赛题库刷题、甚至多文件大型代码仓库重构等场景。
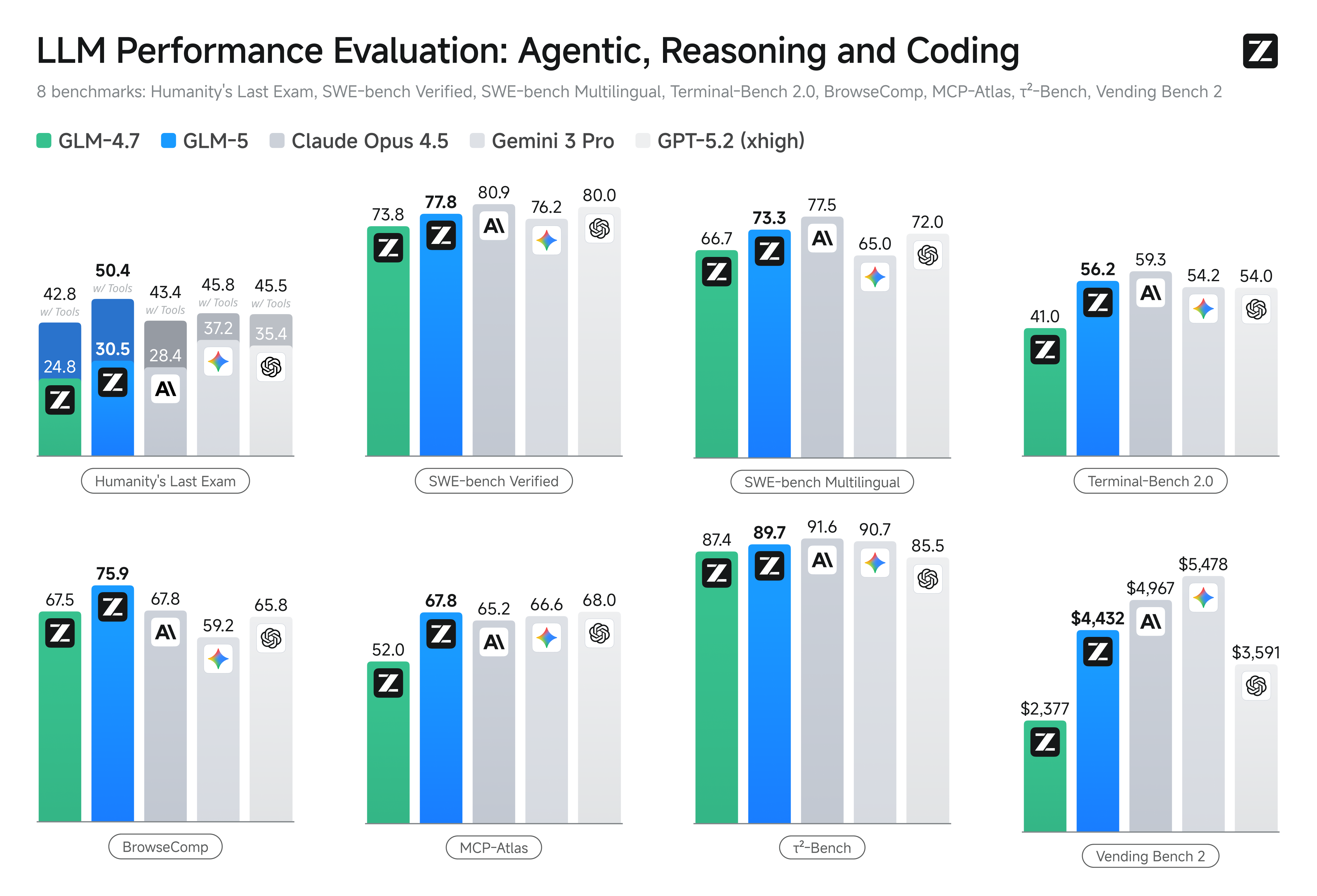
智谱在2026年1月8日港交所挂牌上市当天,首席科学家唐杰教授内部信中明确表示:公司将从2026年起全面回归基础模型研究,并成立前沿创新实验室X-Lab,重点聚焦三大方向:新型模型架构、下一代学习范式、模型持续进化机制。这标志着智谱从“应用驱动”向“技术原生驱动”的战略转型。
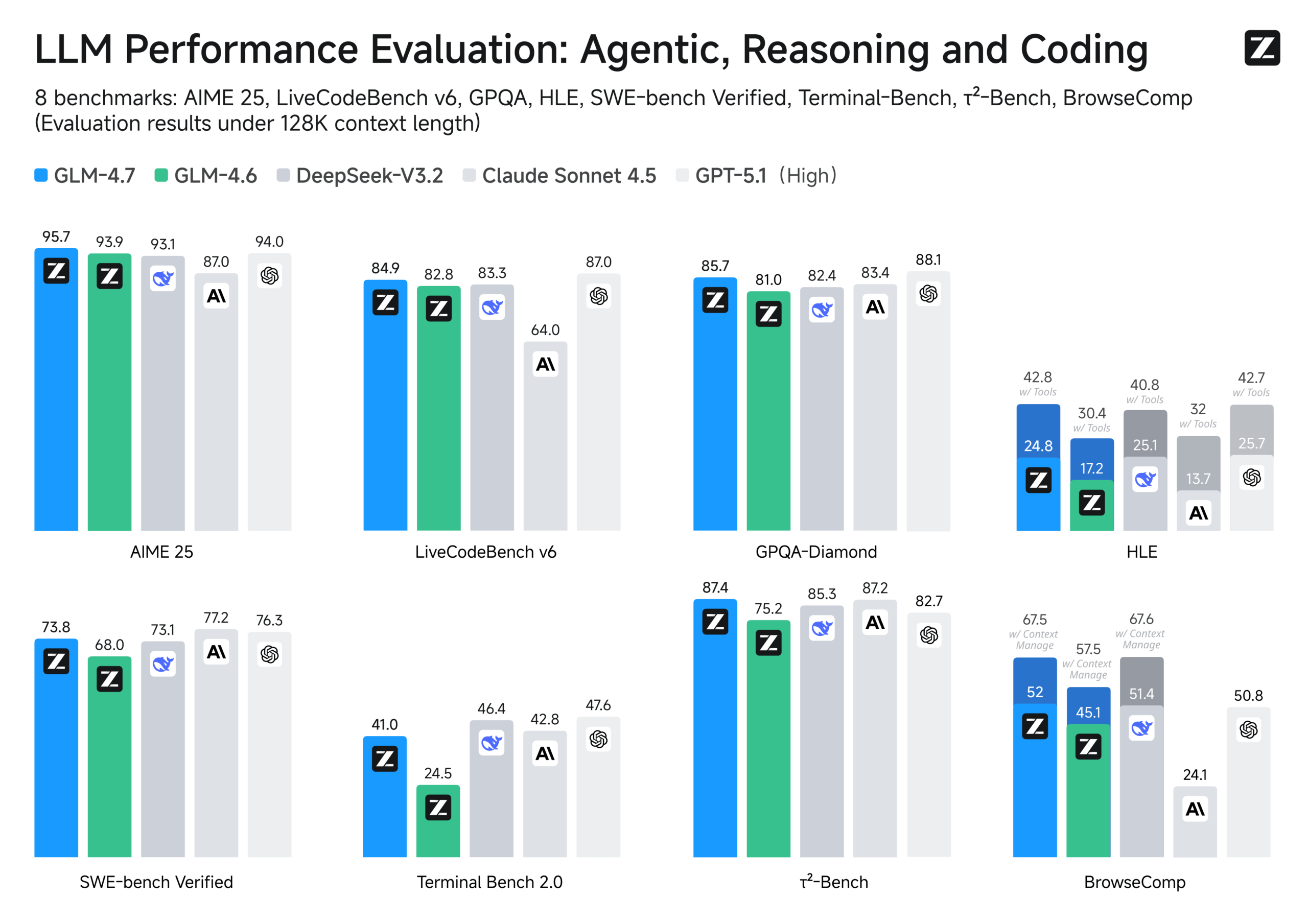
Zhipu AI challenges Western rivals with low-cost GLM-4.7
从公开评测看,GLM-5在Agentic、Reasoning、Coding三大类基准上已展现出极强竞争力,尤其在工具调用场景下多次超越Claude系列和Gemini最新版本。
DeepSeek V系列:百万Token上下文 + 创新架构双轮驱动
DeepSeek近期迎来多轮升级,最引人注目的是网页端与APP端已支持最高1M Token上下文长度(用户实测反馈),较2025年8月的DeepSeek V3.1(128K)提升近8倍。
目前全球能稳定支持百万级上下文的模型仍屈指可数,主要集中在谷歌Gemini系列和Anthropic Claude Opus最新版本。DeepSeek此举大幅降低了企业级长文档处理、代码仓库整体分析、法律/医学文献深度阅读等场景的门槛。
DeepSeek V系列核心定位是“追求极致综合性能的基础模型”。其技术路线以高效MoE(Mixture-of-Experts)架构为核心:
- 2024年12月发布的V3奠定强大性能基座
- 2025年迭代V3.1强化推理与Agent能力
- 2025年12月推出正式版V3.2,并同步发布专注高难度数学/学术的V3.2-Speciale
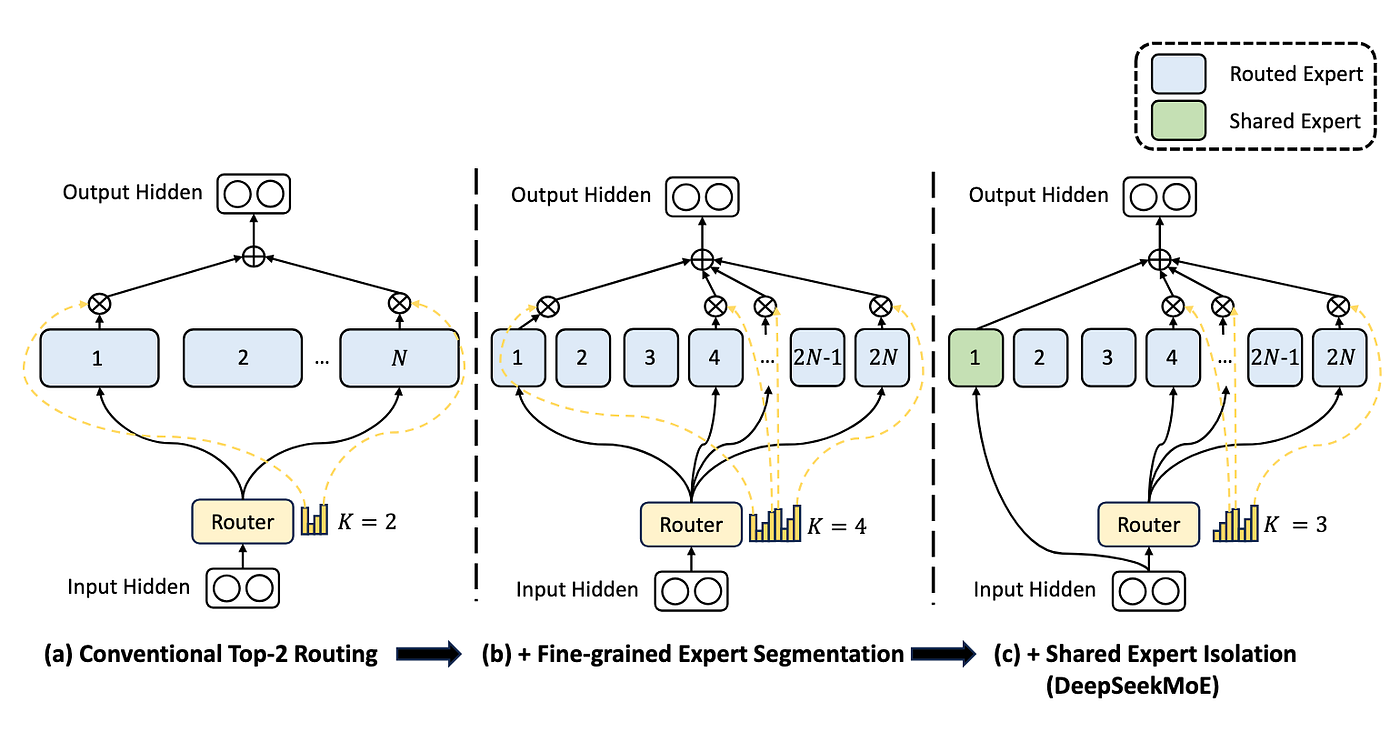
2026年初DeepSeek团队连续发表两篇重要论文,公开两项关键创新:
- mHC(Manifold-constrained Hyper-Connection):优化深层Transformer的信息流动路径,使训练更稳定、可扩展,在不增加算力前提下显著提升性能。
- Engram(条件记忆模块):将静态知识存储与动态计算解耦,使用廉价DRAM存放实体知识,把昂贵HBM专注于推理计算,大幅降低长上下文推理的内存与成本。
科技媒体The Information爆料,DeepSeek计划在2026年2月中旬(农历新年期间)推出旗舰模型DeepSeek V4,重点强化写代码能力,有望成为2026年上半年最强开源/半开源编码模型之一。

🇨🇳 China & new AI model 🤖 DeepSeek V4: The upcoming AI flagship with revolutionary coding capabilities 🚀
MiniMax M2.5:Agent产品线内测中的下一代旗舰
同一天,MiniMax也传出重磅消息:M2.5模型即将正式公开,目前已在海外MiniMax Agent产品中进行封闭内测。
MiniMax长期专注Agent场景,其产品设计理念强调“模型即工具调用执行器”。M2.5预计将在工具调用稳定性、多模态理解、长时序任务规划等方面进一步升级,值得持续关注。
结语:中国大模型已进入“质变”窗口期
2026开年,中国三大头部玩家几乎同时在Agent能力、超长上下文、架构效率三大最前沿方向取得突破。这不再是单纯的参数规模竞赛,而是真正围绕实用落地场景的系统性技术升级。
对于开发者而言,现在是中国模型最值得深度接入的窗口期:性价比、开源程度、API稳定性、社区生态都在快速赶超。
你已经开始在生产环境中使用GLM-5、DeepSeek V系列或MiniMax了吗?欢迎在评论区分享你的实际体验与benchmark对比,我们共同见证这一轮中国AI的爆发式进化。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)