【硬核万字长文】从 BERT 到 DeepSeek:大模型架构演进、预训练全流程与 RLHF 深度解析(附 PPT 原理图解与面经)
导语 / 引言 随着 ChatGPT 和 DeepSeek 的爆火,自然语言处理(NLP)进入了“大炼模型”的时代。很多同学的知识储备还停留在跑通 BERT 分类任务的阶段,面对当今动辄千亿参数、采用 MoE 架构和强化学习(RLHF)的 SOTA 大模型时往往一头雾水。 本文基于实战经验与最新的《大模型》课程 PPT 全套核心理论,采用逆向工程思维,带你深度拆解:
-
架构演进:从 Transformer 到 DeepSeek(RoPE、MLA、MoE 等黑科技)。
-
预训练血肉:大模型是如何通过海量数据和 Scaling Law “炼”成的。
-
灵魂注入:彻底讲透 SFT 与 RLHF(PPO 算法)的数学本质。
目录 (Table of Contents)
一、 架构的分野:从 Encoder 到 Decoder-Only
2.1 归一化升级:LayerNorm $\rightarrow$ RMSNorm
2.2 激活函数演进:ReLU/GELU $\rightarrow$ SwiGLU
2.3 革命性的位置编码:绝对位置 $\rightarrow$ RoPE (旋转位置编码)
2.4 显存刺客的克星:MHA $\rightarrow$ MLA (多头潜在注意力)
2.5 算力分配艺术:Dense FFN $\rightarrow$ DeepSeekMoE (混合专家模型)
3.1 缩放定律 (Scaling Law):大力出奇迹的物理学
3.2 模型的数据口粮:数据清洗与 Tokenization
3.3 核心任务:Next Token Prediction 与涌现能力
4.1 阶段二:SFT (指令微调 / Supervised Fine-Tuning)
4.2 阶段三:RLHF (人类反馈强化学习) —— 对齐价值观
一、 架构的分野:从 Encoder 到 Decoder-Only
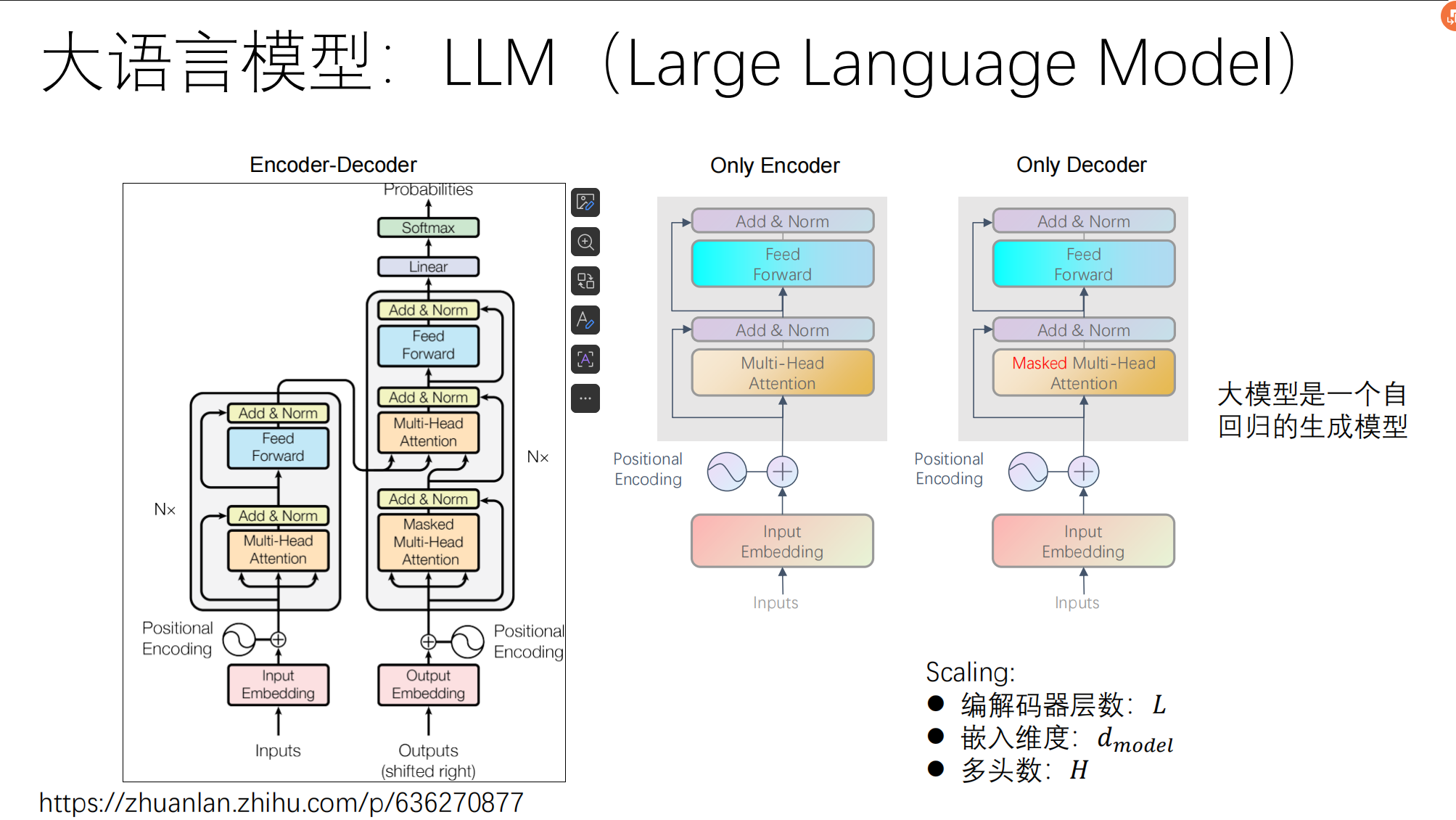
在深度学习框架中,Transformer 家族走向了不同的分支:
-
Only Encoder (BERT 代表):拥有双向注意力(能同时看到上下文),非常适合做“理解”任务(如情感分类、实体识别)。但由于其训练目标是“完形填空”,在生成(Generation)连续长文本时效率极低。
-
Only Decoder (GPT、DeepSeek 代表):采用掩码注意力(Masked Attention),严格遵守“只能看前文,不能看后文”的单向逻辑。
-
绝对优势:完美契合自回归生成(Autoregressive)的需求——像成语接龙一样,根据前置 Token 预测下一个 Token。事实证明,基于 Decoder 架构在算力和数据不断放大的情况下,能产生强大的涌现能力(Emergent Abilities)。
-
二、 内核大换血:DeepSeek 架构深度解密
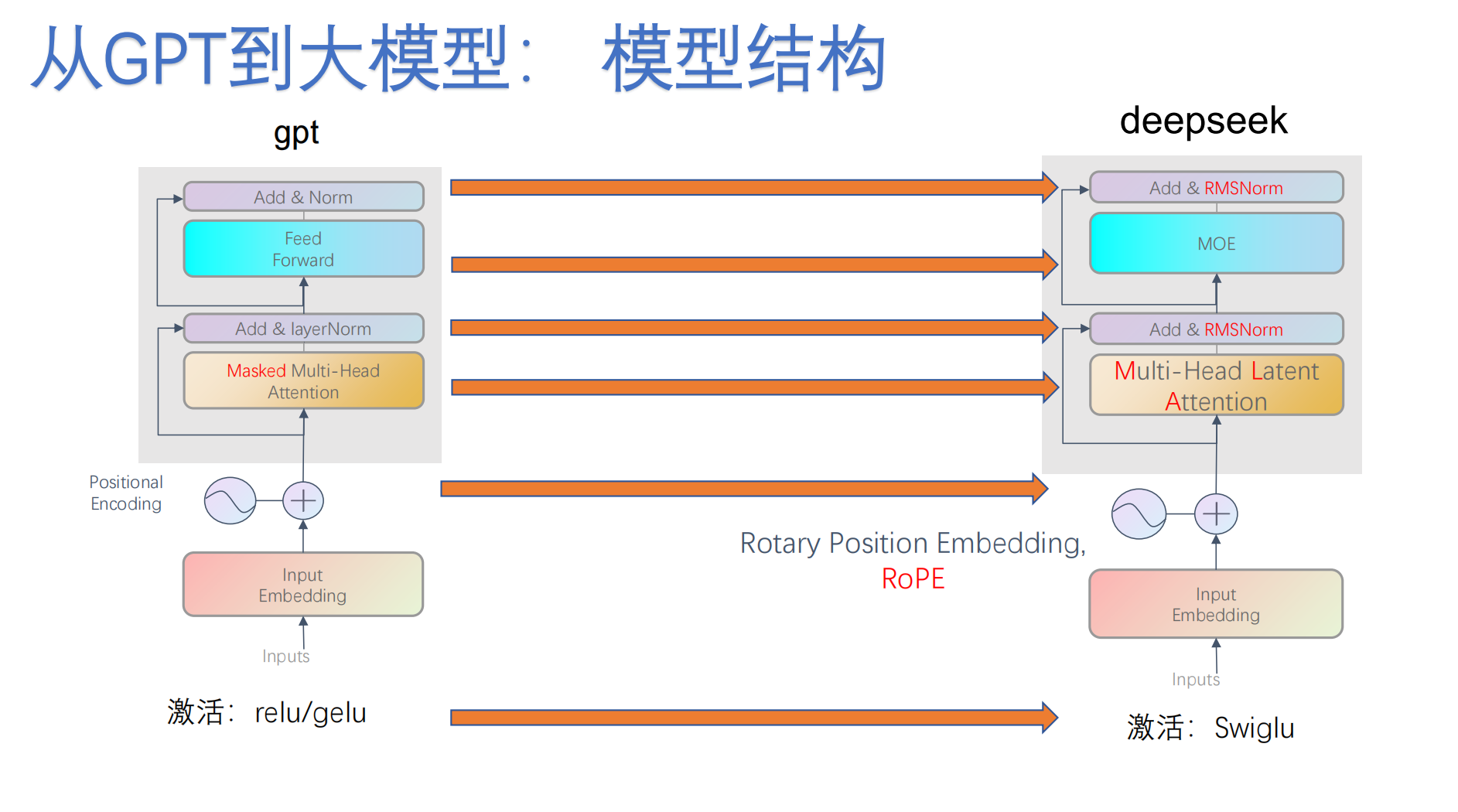
对比了传统 GPT 与最新大模型(如 DeepSeek)在内部组件上的全方位升级,这是算法岗面试的重灾区:
2.1 归一化升级:LayerNorm --> RMSNorm
传统模型使用 Add & LayerNorm,而新一代模型普遍改用 RMSNorm (Root Mean Square Layer Normalization)。
-
原理:移除了 LayerNorm 中的均值计算(Mean-centering),只计算均方根。
-
收益:在保持模型收敛效果几乎不变的前提下,减少了计算开销,提升了前向传播速度。
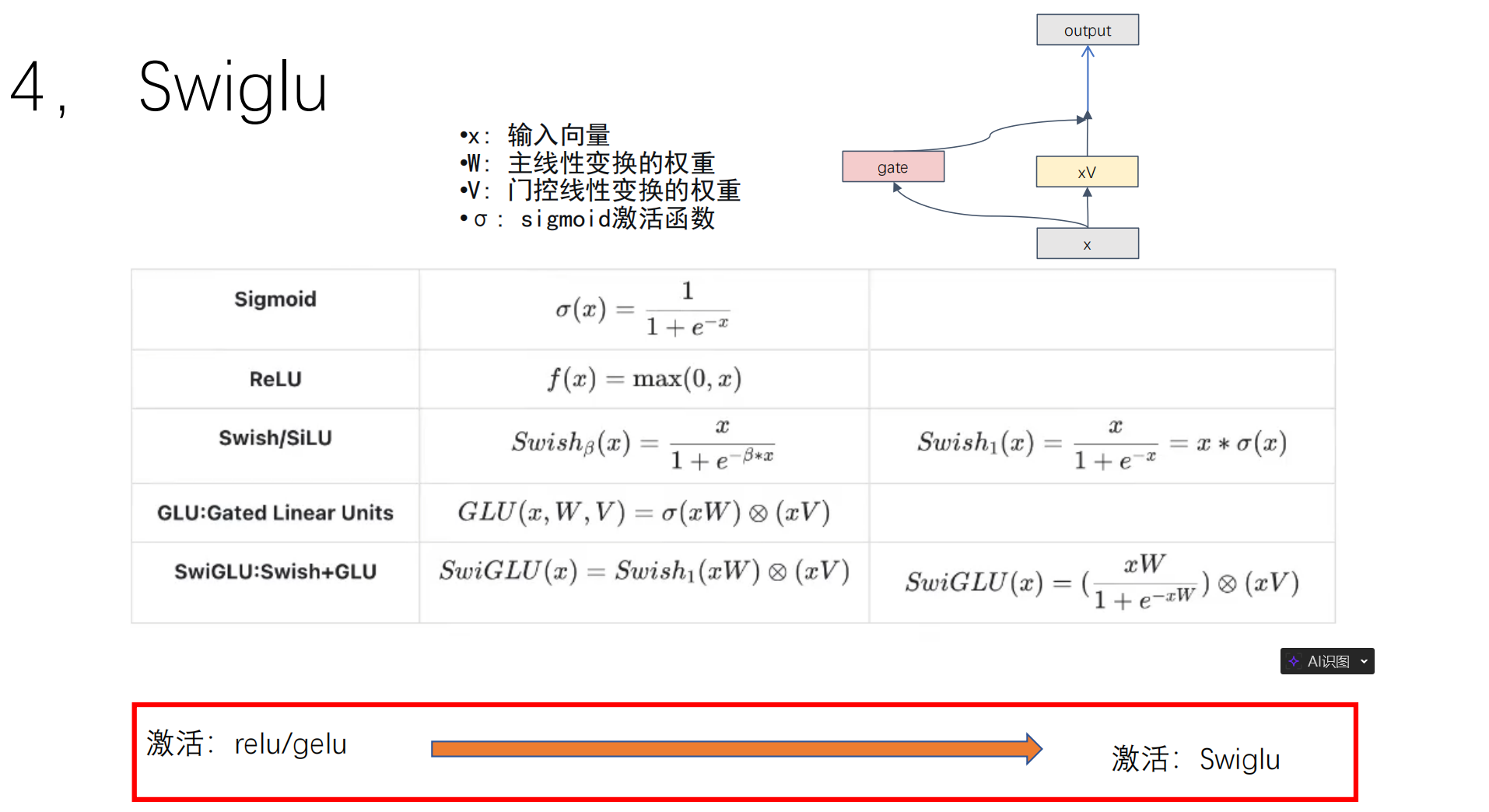
2.2 激活函数演进:ReLU/GELU --> SwiGLU
-
SwiGLU 引入了门控机制(Gated Linear Unit),结合了 Swish 激活函数。虽然这会让该层的参数量增加,但大量实验表明,SwiGLU 能显著提升大模型的性能和收敛稳定性。
-
2.3 革命性的位置编码:绝对位置 --> RoPE (旋转位置编码)
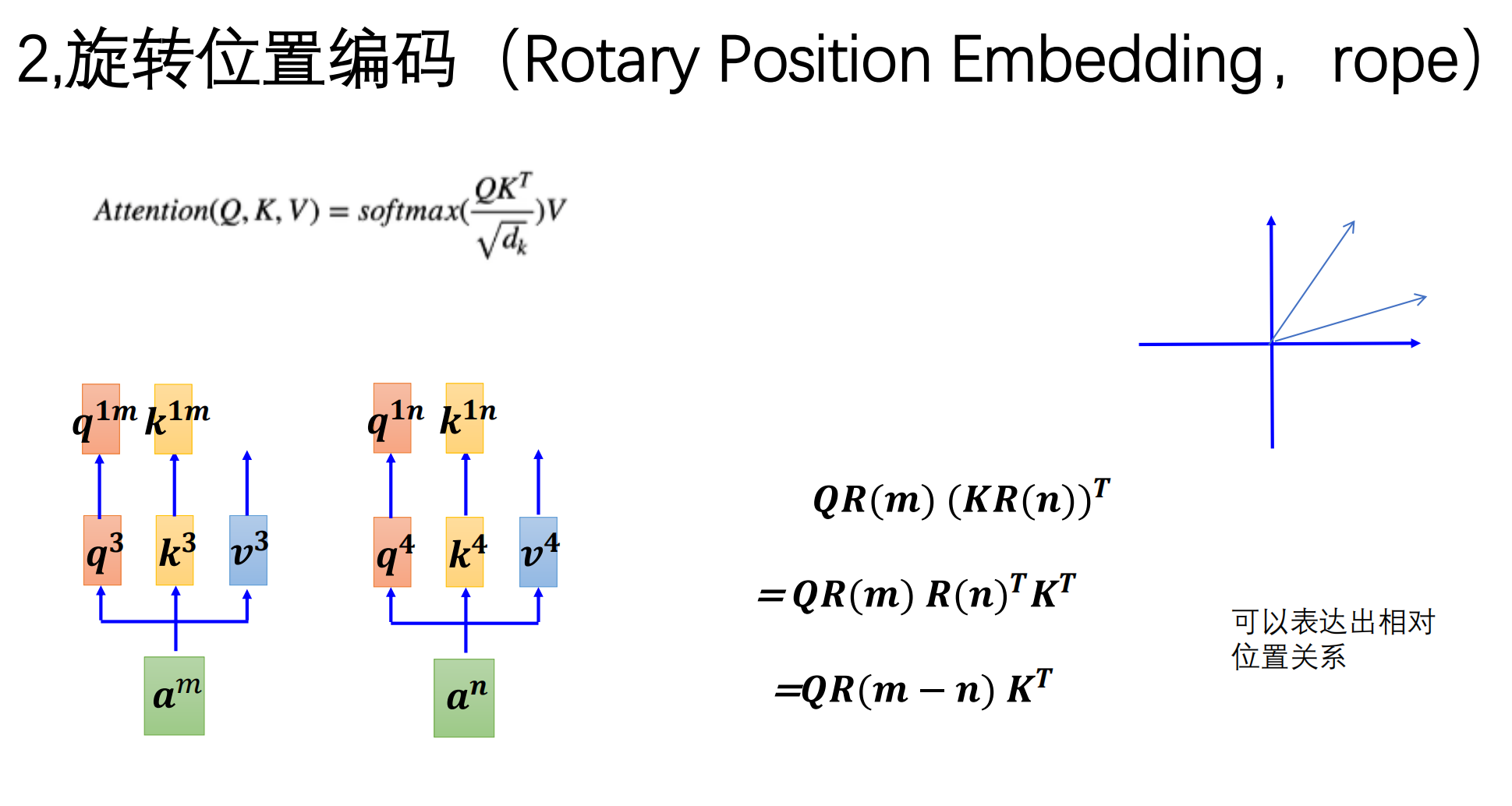
RoPE (Rotary Position Embedding) 是目前 Llama 和 DeepSeek 等顶尖模型标配的位置编码技术。
1. 为什么要换掉“绝对位置编码”?
-
死记硬背问题:早期的绝对位置编码(如 BERT)是给每个位置分配一个固定的 ID 向量。模型只记住了“第 1 个词”和“第 500 个词”是什么。
-
外推性极差:如果模型训练时只见过 512 个词,当你给它一个 1000 词的文本时,它完全不知道第 513 个词的位置信息该怎么处理,因为它没学过那个 ID。
2. RoPE 的核心直觉:时钟与旋转角度
-
把向量当成指针:想象每个词向量都是一个罗盘上的指针。
-
旋转代表位置:我们在处理第 n个词时,就把它的向量旋转 n*
的角度。
-
第 1 个词旋转
-
第 2 个词旋转 2
-
...以此类推。
-
3. 数学上的“神来之笔”:相对位置的转化 模型在计算注意力时,会计算词 m 和词 n 的点积。在 RoPE 下,神奇的事情发生了: 词 m 旋转了 m*,词 n 旋转了 n*
。当它们相乘时,绝对的角度(位置)会抵消,剩下的结果只取决于 (m-n)*
。
-
结论:虽然我们给模型输入的是绝对旋转角度,但模型最终感知到的是两个词之间的相对距离。
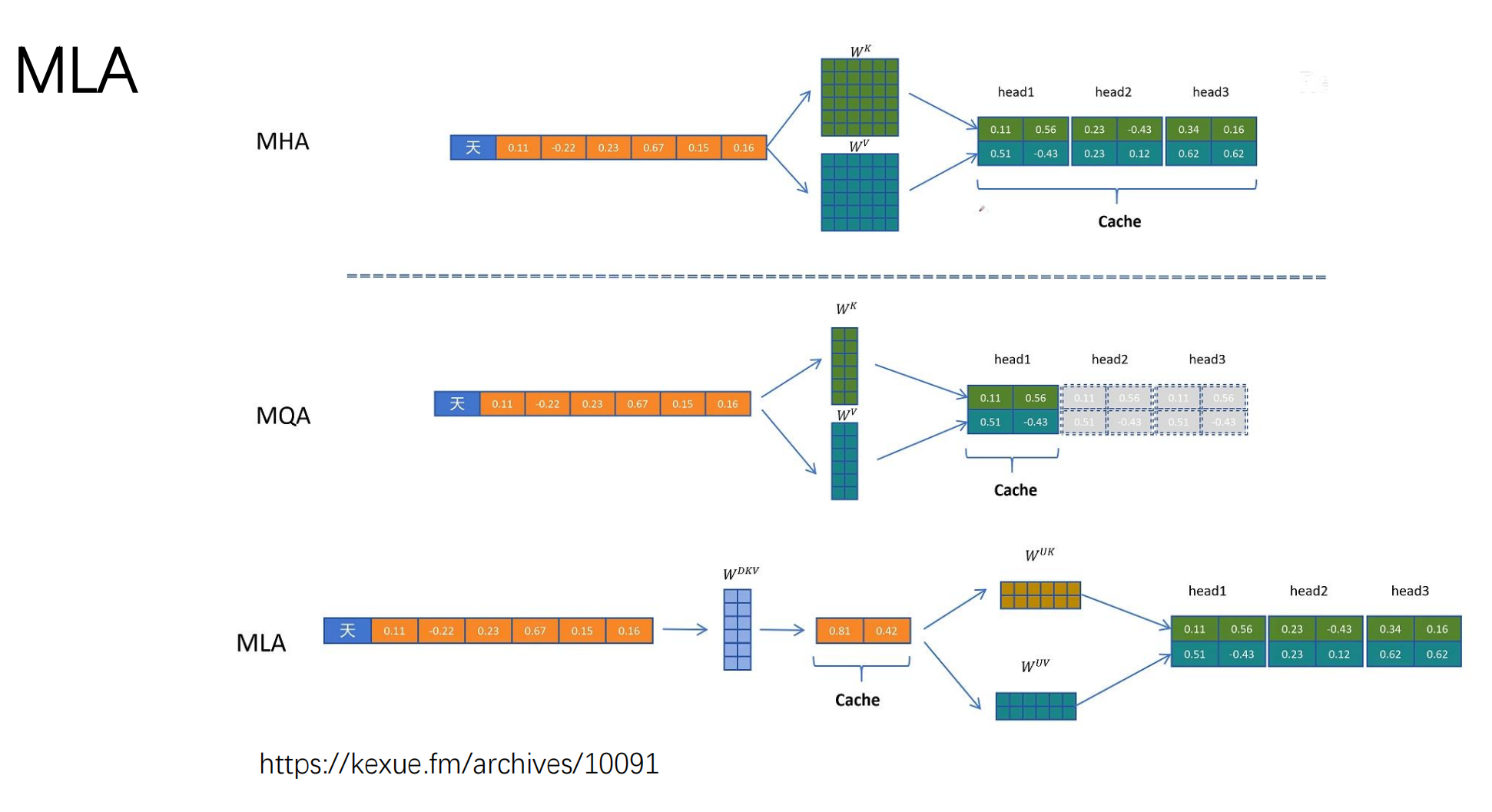
2.4 显存刺客的克星:MHA --> MLA (多头潜在注意力)
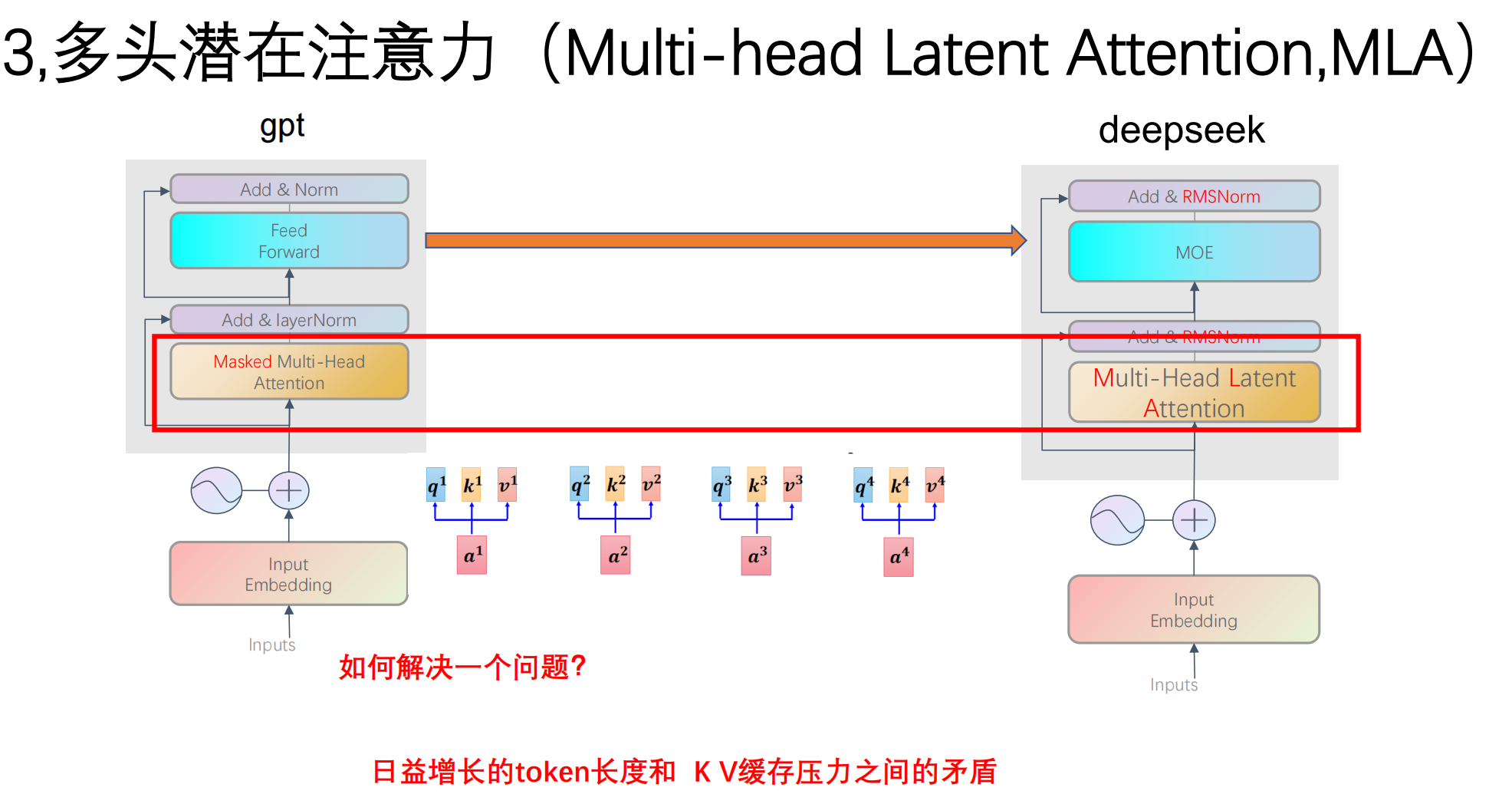
长对话推理中,最大的瓶颈是 KV Cache(键值缓存) 导致的显存爆炸。
-
DeepSeek 的 MLA:引入低秩压缩技术,将高维的 KV 矩阵压缩为一个低维的潜在向量 (Latent Vector)。
-
-
工程收益:极大降低了推理显存占用,从而可以成倍地提高
Batch Size(单卡同时服务更多用户),是 DeepSeek 降低 API 成本的核心技术。 -

2.5 算力分配艺术:Dense FFN --> DeepSeekMoE (混合专家模型)
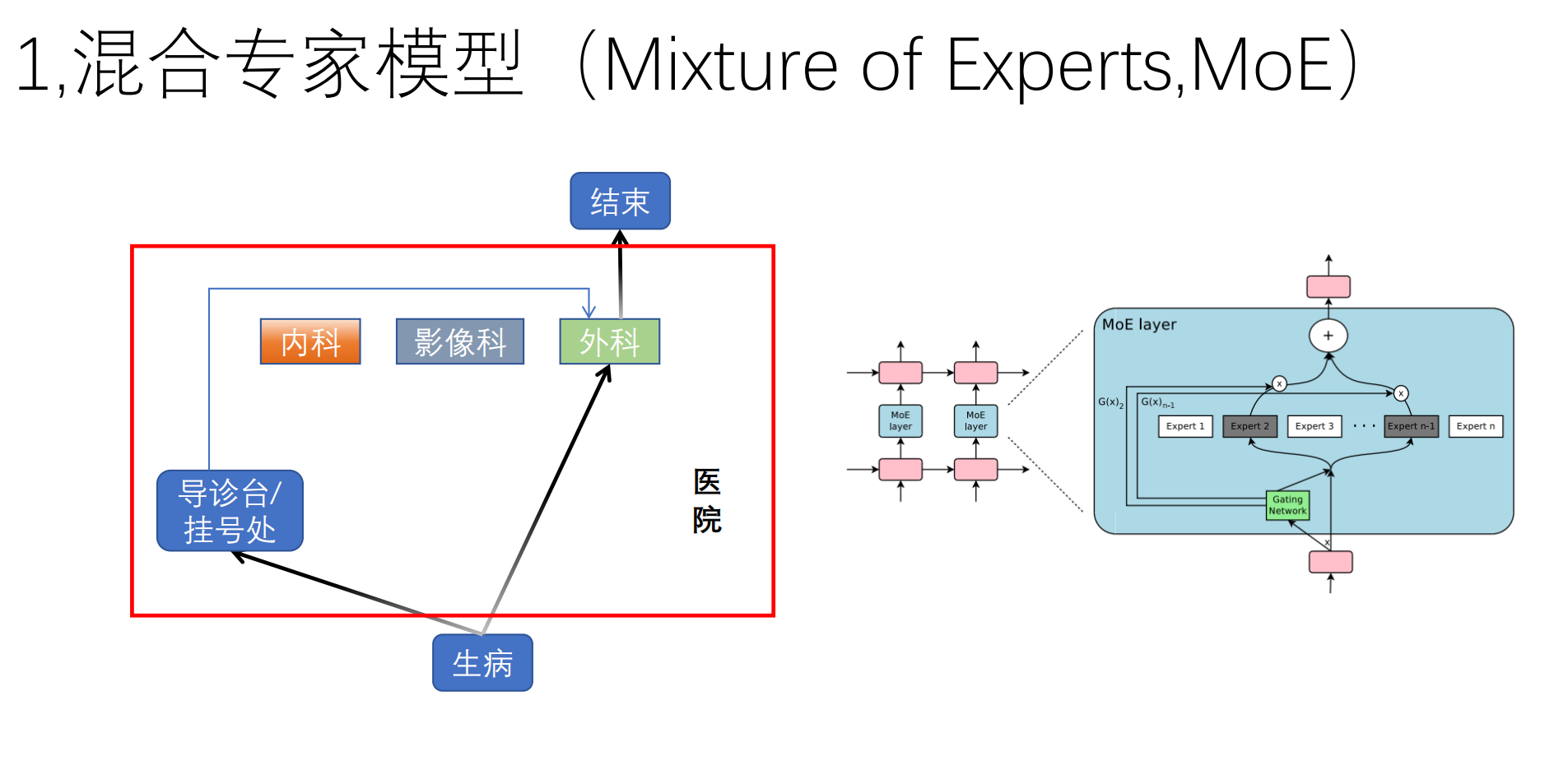
-
MoE(混合专家模型):将庞大的网络拆分成多个“专家”。借助 Router(路由) 动态激活最合适的几个专家(如只激活 8/64)。
-
DeepSeek 的独创:
-
细粒度 (Fine-Grained):大专家拆碎,路由组合更灵活。
-
共享专家 (Shared Experts):剥离出永远激活的专家处理标点、基础语法等“通用知识”,让其他专家专心钻研复杂知识,彻底避免了“专家坍塌”。
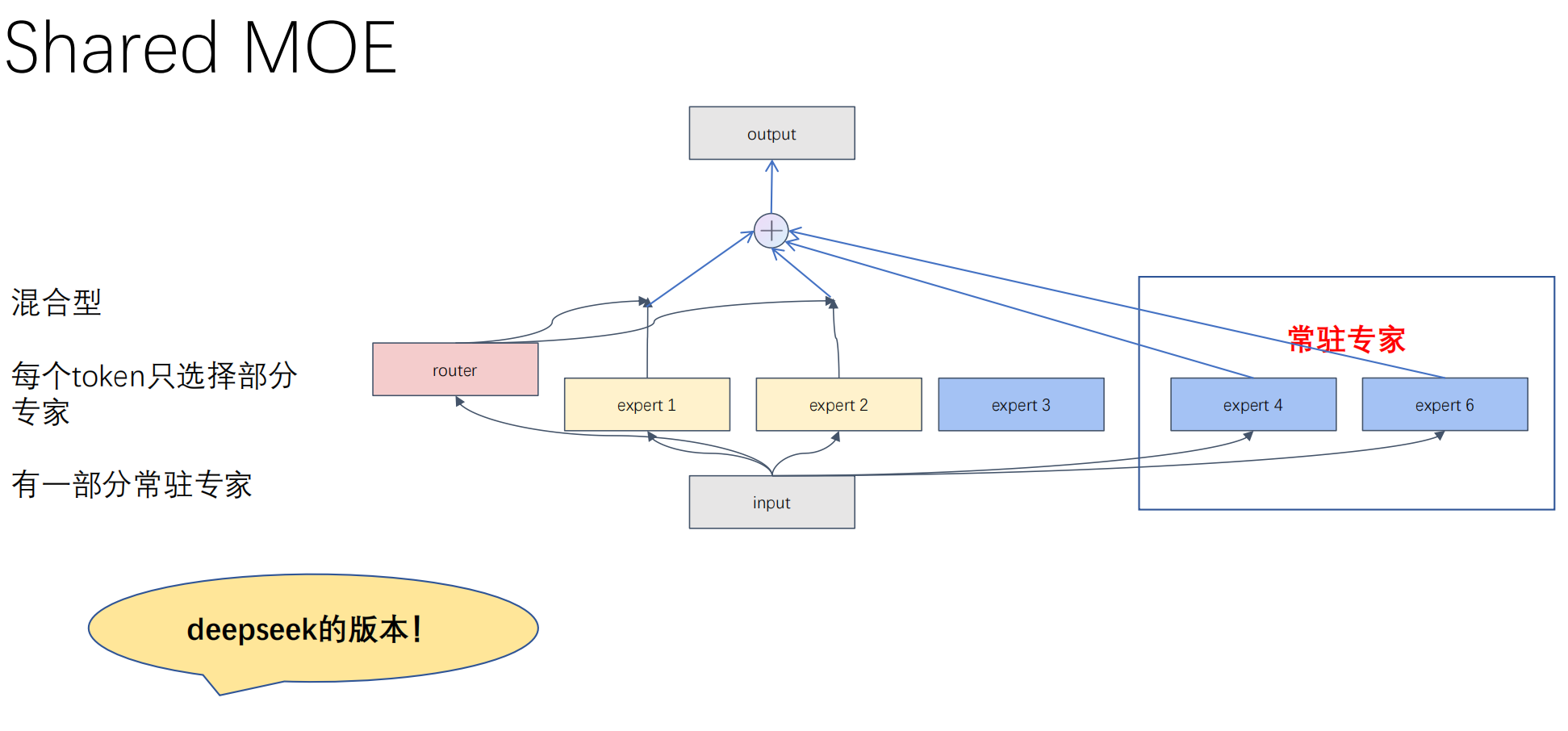
-
三、 大模型的“血肉”:预训练与 GPT 的演进
在进入微调之前,模型必须先经历漫长的预训练(Pre-training)阶段,这就好比让一个婴儿在图书馆里阅读千万本书籍。
3.1 缩放定律 (Scaling Law):大力出奇迹的物理学
OpenAI 在研发 GPT 系列时发现了一个残酷但有效的真理:Scaling Law。
-
核心规律:模型的 Loss(错误率)与计算量(Compute)、数据集大小(Data Size)、参数量(Parameters)呈极其稳定的幂律关系。
-
启示:只要这三个要素按比例放大,模型的智力就会无上限地提升。这也是为什么从 GPT-1 到 GPT-3,参数量从 1.17 亿飙升到了 1750 亿。
3.2 模型的数据口粮:数据清洗与 Tokenization
大模型无法直接吃进原始文本,必须经过严格的预处理:
-
数据清洗与去重:从 Common Crawl 等网页抓取的数据包含大量垃圾信息。必须经过启发式过滤、MinHash 去重,以保证数据的纯净度
-
Tokenization(分词):
-
现代大模型普遍采用 BPE (Byte Pair Encoding) 或 WordPiece 算法。
-
它不是按词汇表死板切分,而是基于统计频率,将常用词(如 "apple")保留为一个 Token,生僻词切分为词根词缀。这不仅压缩了上下文长度,还完美解决了 OOV(未登录词)问题。
-
3.3 核心任务:Next Token Prediction 与涌现能力

在整个预训练阶段,大模型只做一道题:猜下一个词(Next Token Prediction)。
-
自监督学习:不需要人工打标签。给模型看“床前明月”,让它预测“光”;预测错了就通过交叉熵损失(Cross Entropy Loss)计算梯度并反向传播更新参数。
-
涌现能力 (Emergent Abilities):当模型阅读了数万亿个 Token 后,奇迹发生了。为了极高的准确率预测下一个词,模型“被迫”学会了语法、逻辑、甚至世界知识。这被称为In-Context Learning(上下文学习)能力的涌现。
四、 注入灵魂:大模型的微调与价值观对齐
经历完预训练的模型,虽然博学,但只是一个“无情的文档续写机”。为了让它变成像 ChatGPT 一样的智能助手,必须进行 SFT 和 RLHF。
4.1 阶段二:SFT (指令微调 / Supervised Fine-Tuning)

-
操作:构造数万条高质量的人工问答数据,手把手教模型。
-
目的:通过监督学习,让模型学会“问答的格式”和“遵循指令(Instruction Following)”。
4.2 阶段三:RLHF (人类反馈强化学习) —— 对齐价值观

如果模型给出了两个都符合语法逻辑的答案,如何判断哪个更礼貌、更安全?这就需要 RLHF 出场。
第一步:训练 Reward Model(奖励模型) 给模型同一个 Prompt,生成 A 和 B 两个回答。人类标注员进行排序(Selected vs Rejected)。用这些偏好数据训练一个 Reward Model 替人类打分。
第二步:PPO 算法 (近端策略优化) 核心推导
PPT 第 40 页给出了强化学习的核心公式:
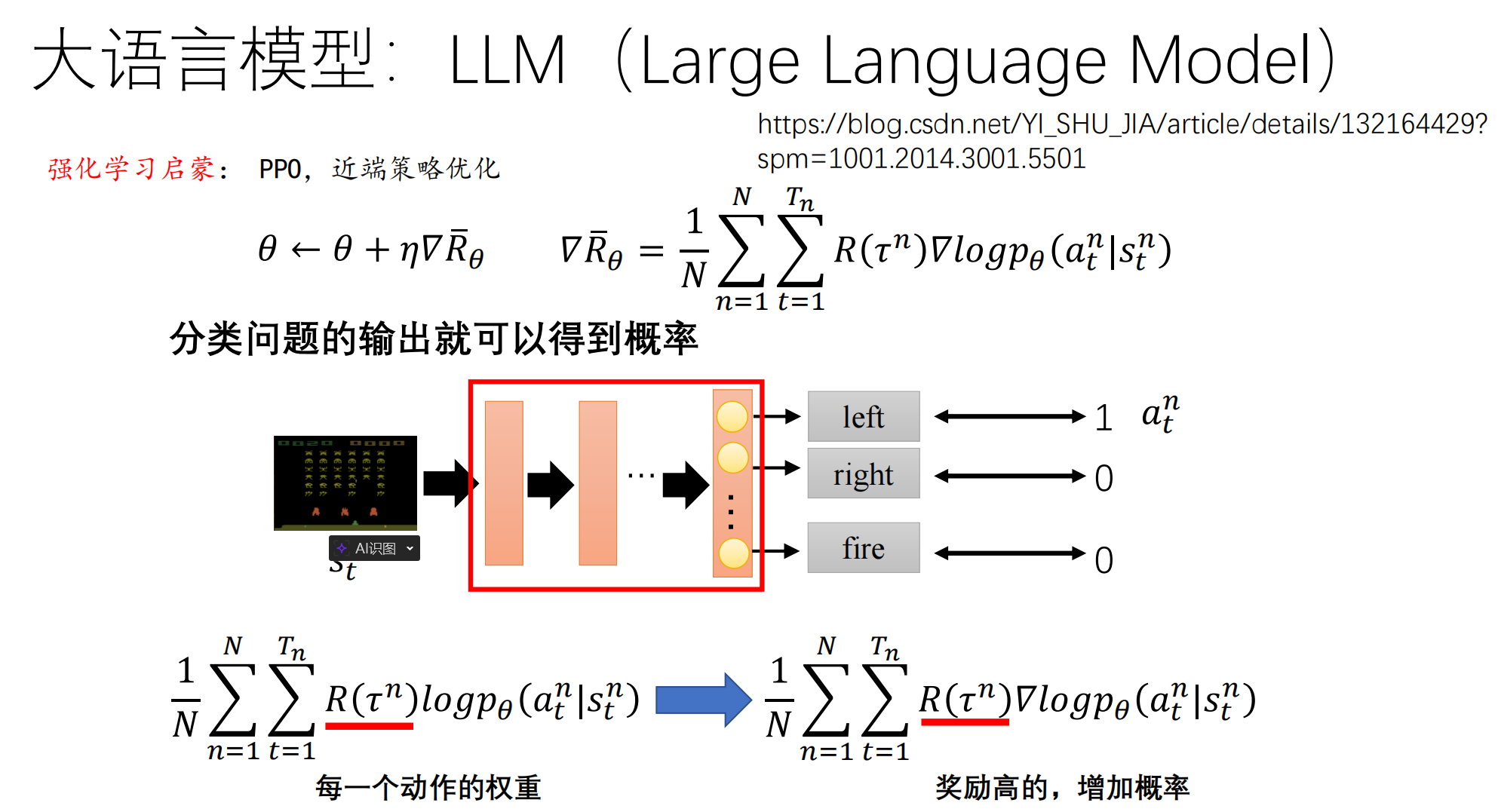
这是最难懂的部分。如果 SFT 是“老师教学生”,那么 PPO (Proximal Policy Optimization) 就是“教练训狗”。
1. 核心公式拆解
-
:代表模型在当前状态 s 下,生成词 a 的概率(取对数是为了计算方便)。
-
:梯度的方向。这代表“如果我想让这个词出现的概率变大,模型参数
-
:这是奖励分。如果整句话说得好,R 就是正的高分;说得差,R 就是负分。
2. 直观逻辑:奖优罚劣
-
情况 A(高分回答):当 R 是正数时,公式就是在增加这些 Token 出现的概率。
-
情况 B(低分回答):当 R 是负数时,公式就是在降低这些 Token 出现的概率。
-
总结:模型通过不断地试错,拿高分的路径被不断强化,拿低分的路径被抑制。
3. “训狗”类比与 KL 散度约束
想象你在训练一只狗。
-
Policy Gradient(策略梯度):狗做对了给骨头(
),它下次就会多做;做错了拍脑袋(
),它下次就少做。
-
PPO 的“近端”意义:训练时,你不能为了让狗学会新动作,就把它打得连主人的脸都忘了。决定了每次模型更新的幅度不会太大
-
KL 散度约束:这就是那根“牵引绳”。它限制了模型更新的幅度。如果新模型
相比旧模型
改变太大(KL 散度过高),系统就会强行拉回来。这保证了模型在学习“礼貌”的同时,不会把预训练学到的“知识”给丢了。
五、 代码实战:模型推理的底层陷阱
理论必须落地于代码。在深度学习实战中,加载模型进行推理时,有两个致命陷阱:
model = AutoModelForSequenceClassification.from_pretrained('./best_model')
model.eval() # 【关键操作 1】
with torch.no_grad(): # 【关键操作 2】
outputs = model(**inputs)
logits = outputs.logits
predictions = torch.argmax(logits, dim=-1)
-
为什么要
model.eval()? 如果不加这一行,Dropout 层会继续随机丢弃神经元,BatchNorm 会继续计算当前单一数据的均值方差,导致同样的输入每次预测出的概率都会微小跳动,结果极不稳定。 -
为什么要
torch.no_grad()? 在推理阶段,我们不需要反向传播更新参数。告诉 PyTorch 停止构建计算图,可以瞬间节省 50% 以上的显存,并大幅提升推理速度。
六、 高频面试题总结 (FAQ)
Q1:为什么 Transformer 推理时很吃显存?
答: 因为它是自回归生成的,需要保存历史上下文中所有 Token 的 Key 和 Value 矩阵(即 KV Cache),避免重复计算。随着文本长度增加,KV Cache 显存占用呈线性增长。DeepSeek 采用 MLA 机制,将 KV 矩阵压缩为 Latent Vector(浅向量),大幅缓解了这一问题。
Q2:简单解释一下 DeepSeek 的 MoE 是如何防止专家坍塌的?
答: 传统 MoE 在训练时,Router 可能会将所有 Token 倾向性地分配给少数几个“碰巧前期学得好”的专家。DeepSeekMoE 一方面采用了更细粒度(Fine-Grained)的切分扩大选择面,另一方面设置了“共享专家(Shared Experts)”专门处理标点、语法等高频共性知识,让细粒度专家被迫在特定专业领域进行竞争,从而有效防止了坍塌。
Q3:简述大模型 Pre-training 和 SFT 阶段的区别?
答: Pre-training 是利用海量无标注数据做 Next Token Prediction,目的是让模型掌握人类语言的规律和世界知识,此时模型是发散的;SFT 是利用高质量人工编写的 Prompt-Response 对进行微调,目的是规范模型的输出格式,让它从“续写机器”变成“听从指令的问答助手”。
作者寄语:从
import torch搭建简单的分类器,到深入理解从数据清洗、Scaling Law 到手撕 PPO 公式的全链路,大语言模型的学习曲线虽然陡峭,但只要抓住“算力瓶颈(MLA/MoE)”和“人类对齐(RLHF)”这两条主线,就能一通百通。祝大家在考研复试和秋招中乘风破浪!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 43
43 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)