代码学习 - 掩码生成与恢复
本文学习自Unist的论文实现,源码地址:https://github.com/tsinghua-fib-lab/UniST/tree/main,本内容为个人理解整理。
文章目录
前言
本文学习自Unist的论文实现,源码地址:https://github.com/tsinghua-fib-lab/UniST/tree/main,本内容为个人理解整理。
一、masking策略
1.random_masking
随机掩蔽:这种策略类似于MAE中使用的策略,其中时空补丁被随机掩蔽。其目的是捕获细粒度的时空关系。
M ∼ U [ 0 , 1 ] , E x = E x [ M < 1 − r ] , M ∈ R L ′ × H ′ × W ′ M ∼ U[0, 1], E_x = E_x [M < 1 − r ], M ∈ R^{L^′×H^′×W^′} M∼U[0,1],Ex=Ex[M<1−r],M∈RL′×H′×W′
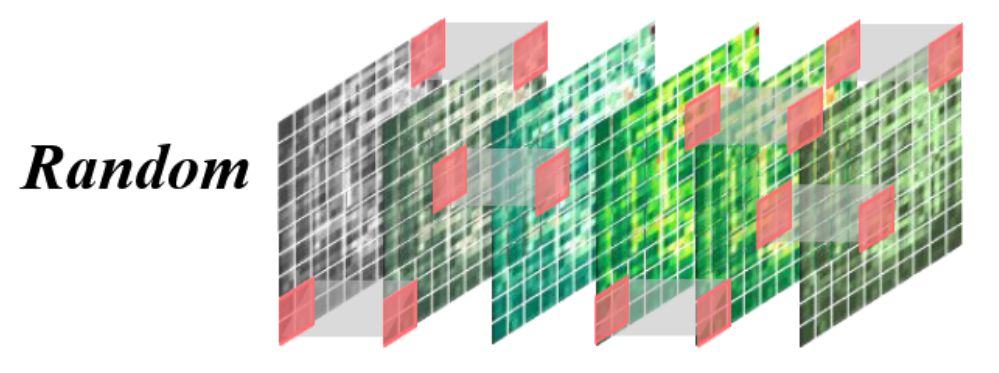
输入变量包括维度为 ( N , L , D ) (N, L, D) (N,L,D)的 x x x和掩码率 m a s k r a t i o mask_{ratio} maskratio
随机掩码策略实现:函数先根据掩码率 mask_ratio 计算保留长度 len_keep。随后为每个样本样本随机产生一个长度为L的噪声,得到形状为 ( N , L ) (N,L) (N,L)的噪声矩阵。利用 torch.argsort 函数对噪声矩阵第二维(大小为L) 进行排序,得到一个顺序位置索引 ids_shuffle ,噪声小的排前面、噪声大的排后面,这个位置索引可以看成随机产生,用于对原始数据进行随机掩码用。并再用一次 torch.argsort 函数对ids_shuffle顺序进行排序,得到位置索引ids_restore,这个用于记录ids_shuffle顺序,用于进一步还原原始数据。
设:N=1, L=8, D=1,x = [10,20,30,40,50,60,70,80],mask_ratio=0.5,所以 len_keep=4。假设随机噪声是:noise = [0.42, 0.05, 0.77, 0.33, 0.11, 0.66, 0.25, 0.90],按噪声升序排序得到 ids_shuffle:[1,4,6,3,0,5,2,7]。
前 4 个保留:ids_keep=[1,4,6,3],x_masked=[20,50,70,40],由ids_restore=argsort(ids_shuffle),得到ids_restore为[4,0,6,3,1,5,2,7]。
含义:ids_shuffle 的第 k 位来自原位置 ids_shuffle[k],ids_restore 用来把“shuffle顺序”还原到“原顺序”。先在 shuffle 顺序里造 mask:mask_shuffle = [0,0,0,0,1,1,1,1](前4保留,后4遮住)。再还原到原顺序:mask = gather(mask_shuffle, ids_restore);mask = [1,0,1,0,0,1,0,1]。
2.tube_masking
管道掩蔽。这种策略模拟了某些空间单元的数据在时间上完全丢失的场景,反映了一些传感器可能不起作用的真实情况——这是一种常见的情况。目标是提高空间外推能力。
M ∼ U [ 0 , 1 ] , E x = E x [ : , M < 1 − r ] , M ∈ R H ′ × W ′ M ∼ U[0, 1], E_x = E_x [ : , M < 1 − r ], M ∈ R^{H^′×W^′} M∼U[0,1],Ex=Ex[:,M<1−r],M∈RH′×W′
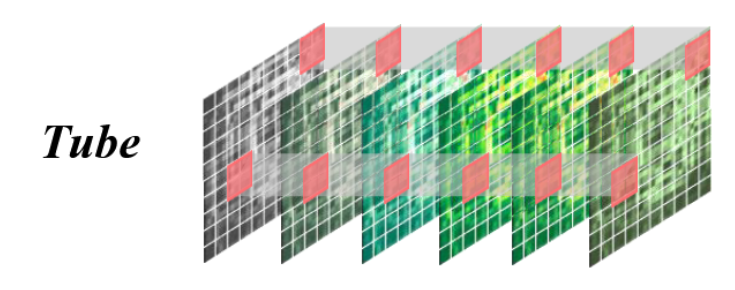
输入变量除了维度为 ( N , L , D ) (N, L, D) (N,L,D)的 x x x和掩码率 m a s k r a t i o mask_{ratio} maskratio,还有被分割后的时间块数量 T T T(这是掩码策略不同所致)。
管道掩码的处理流程与随机掩码过程大体一致,不同的部分是从原本的 L = ( T / t patch_size ∗ H / p a t c h s i z e ∗ W / p a t c h s i z e ) L=(T/t_{\text{patch\_size}}*H/patch_{size}*W/patch_{size}) L=(T/tpatch_size∗H/patchsize∗W/patchsize),将时间维度 ( T / t patch_size ) (T/t_{\text{patch\_size}}) (T/tpatch_size)拆出来,让 L = ( H / p a t c h s i z e ∗ W / p a t c h s i z e ) L=(H/patch_{size}*W/patch_{size}) L=(H/patchsize∗W/patchsize)代表纯空间,然后对 L L L 进行掩码,代码如下:
这里面如何确保reshape出来的 x 的第二个维度T就一定是原始数据代表时间维度的变量,这是由 token 的展平顺序和长度关系的前置约束决定的。TokenEmbedding 的 flatten 顺序是按时间在前,所以 (T_patch, H_patch*W_patch) 的结构是可逆的。
3.tube_block_masking
块掩蔽。管掩蔽的一个更具挑战性的变体,块掩蔽涉及在时间上完全不存在的整个空间单元块。由于上下文信息有限,重建任务变得更加复杂,目的是增强空间可转移性
M ∼ U n i f o r m ( 1 , 2 ) , E x = E x [ : , M − 1 2 H ′ : M 2 H ′ , M − 1 2 W ′ : M 2 W ′ ] . M ∼ Uniform(1, 2), E_x = E_x [ : , \frac{M −1}{2} H^′ : \frac{M}{2}H^′, \frac{M −1}{2} W^′:\frac{M}{2} W^′]. M∼Uniform(1,2),Ex=Ex[:,2M−1H′:2MH′,2M−1W′:2MW′].
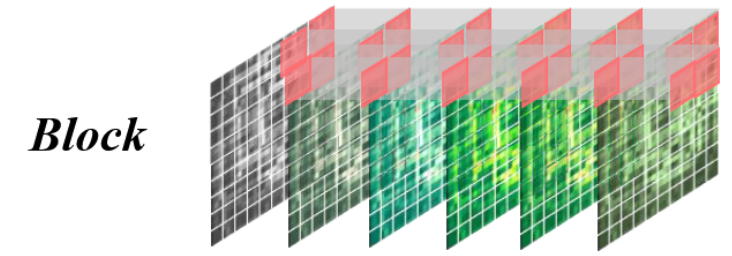
块掩码的处理流程与管道掩码处理流程类似,不同之处在于噪声的定义。这里噪声设定为一个 ( N , L ) (N,L) (N,L)的矩阵(虽然这里是一个矩阵,与管道掩码不同,但实际上效果都是一样,在做掩码处理的时候并没有说不同样本掩码位置不同,实际上不同样本掩码位置都是相同的,所以换成一个向量也能达到相同的效果),掩码率强制规定三个选择:[0.25,0.5,0.75]。noise 初始化为全 0,再按比例把某个块改成 1(或反过来),通过 argsort 实现“某块优先保留/优先遮住”:0.25:随机选 1/4 空间块设为 1,意味着这块更可能被遮(保留其余 3/4);0.75:先全 1,再把随机 1/4 设 0,意味着只保留这 1/4,遮其余 3/4;0.5:随机选一半设 1,保留另一半。
4. causal_masking
在因果掩码中,根据掩码策略不同细分为时间掩码和 f r a m e frame frame掩码。
在时间掩码中,未来的数据被屏蔽,迫使模型仅根据历史信息重建未来。目的是改进模型捕获从过去到未来的时间依赖关系的能力。
M = C o n c a t ( [ 1 ( 1 − r ) L ′ × H ′ × W ′ , 0 r L ′ × H ′ × W ′ ] ) , E x = E x [ M = 1 ] M = Concat( [1_{(1−r )L^′ ×H^′ ×W^′}, 0_{rL^′ ×H^′ ×W^′ ]}), E_x = E_x [M = 1] M=Concat([1(1−r)L′×H′×W′,0rL′×H′×W′]),Ex=Ex[M=1]
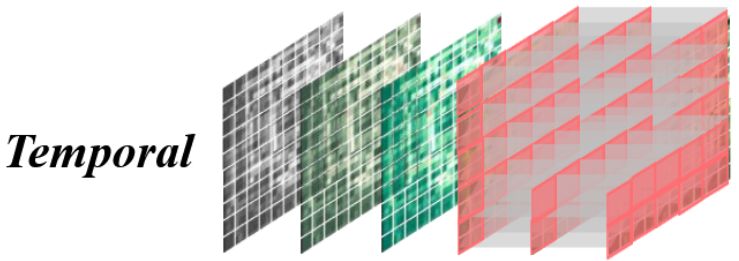
时间掩码按照时间顺序,保留前面len_keep帧,遮住后面的帧,符合因果约束。 f r a m e frame frame掩码则是在所有时间帧里面随机选len_keep帧进行遮蔽,这不是因果的,属于随机帧遮挡。但是两者都是属于对时间的掩码。
具体的实现上,对于时间掩码,噪声的选取使用torch.arange()函数返回一个有终点和起点的固定步长的排列,每个样本同一时间顺序;而 f r a m e frame frame掩码使用torch.rand()返回一个随机排序。
代码如下:
小结
可以发现,掩码实现大体的步骤都差不多,他们之间的差别主要体现在噪声的实现方式上。返回值包括
x m a s k e d x_{masked} xmasked:掩码之后的保留值。形状为 ( N , L ′ , C ) (N,L',C) (N,L′,C),主要变化发生在第二维上,从原来的总长度 L t o t a l L_{total} Ltotal 变为“保留 token 数” L ′ L' L′。
m a s k mask mask:记录掩码位置,值为1表示被遮掩,值为0表示保留。形状为 ( N , L ) (N, L) (N,L),只保留前两维,第三维被砍掉了。
i d s r e s t o r e ids_{restore} idsrestore:ids_shuffle 的逆映射,用来把“shuffle 顺序”恢复到原序列顺序(不只是“记录原始顺序”)。形状为 ( N , x ) (N,x) (N,x),x因不同掩码策略而具备不同的值。
i d s k e e p ids_{keep} idskeep:被保留 token 在原序列中的位置索引。形状跟 x m a s k e d x_{masked} xmasked类似,为 ( N , L ′ ) (N,L') (N,L′)。
二、masking_evaluate策略
xxx_masking_evaluate函数中,在采样噪声前加了 torch.manual_seed(111),让掩码可复现。xxx_masking函数中,不固定种子,每次都会随机出不同 mask(训练增强用)。其余流程和输出形状是一样的。本质差别是evaluate 版用于验证/测试时“可比较”,训练版用于“随机扰动”。
三、mask_restore
1.random_restore
适用于mask_strategy == 'random’的情况
函数的输入包含被掩码的序列 x x x;ids_restore:为ids_shuffle 的逆映射,记录被遮掩的值的位置;N, T, H, W, C;以及mask_token,一个可学习的占位向量,专门给被 mask 掉的 patch 用,被正态初始化为 [ 1 , 1 , d e c o d e r e m b e d _ d i m ] [1, 1, decoder_{embed\_dim}] [1,1,decoderembed_dim]的形状。
这一个函数用于把 encoder 的“保留 token 序列”恢复成完整长度序列,被遮掉的位置用 mask_token 补上。具体实现方式如下:
先通过 repeat 生成需要补的 mask token 数量,将 ids_restore 由 [ 1 , 1 , d e c o d e r e m b e d _ d i m ] [1, 1, decoder_{embed\_dim}] [1,1,decoderembed_dim] 变成 [ N , T ∗ H ∗ W − x . s h a p e [ 1 ] , d e c o d e r e m b e d _ d i m ] , T ∗ H ∗ W [N, T*H*W - x.shape[1],decoder_{embed\_dim}],T*H*W [N,T∗H∗W−x.shape[1],decoderembed_dim],T∗H∗W 是完整 token 数 L_full,所以这里补 L_full - L_keep 个。
然后利用cat把保留 token 和 mask token 拼起来,长度凑到 L_full。此时顺序还是“保留在前,mask 在后”,还不是原始顺序。
接着利用view(),整理成 [ N , T ∗ H ∗ W , C ] [N, T*H*W, C] [N,T∗H∗W,C]这种类似于 [ b a t c h , l e n , c h a n n e l ] [batch, len, channel] [batch,len,channel] 的标准形状。
.view(…) 是 PyTorch 的张量重塑操作,不改数据内容,只改张量形状,其中元素总数必须不变,常用命令包括x.view(a, b, c):指定新形状;x.view(a, -1, c):-1 让 PyTorch 自动推导该维度
然后用gather(),用 ids_restore 把序列“反打乱unshuffle”,还原到 token 原本的位置顺序。这一步之后,每个原始位置都回来了,其中保留位置是原特征,遮挡位置是 mask_token。
最后通过view()再整理一下数据维度。
并将其输出,可以看见通过restore之后序列 x x x维度由输入的 [ N , T ′ ∗ H ′ ∗ W ′ , C ] [N,T'*H'*W',C] [N,T′∗H′∗W′,C]变成 [ N , T ∗ H ∗ W ′ , C ] [N,T*H*W',C] [N,T∗H∗W′,C]。
2.tube_restore
适用于mask_strategy == [‘tube’,‘block’]的情况
与以上random_restore不同,tube_restore先把序列 reshape 成 [N, T, H*W, C],再沿空间维(dim=2)用 ids_restore 恢复。具体如下:
通过reshape把输入从 [ N , T ′ ∗ H ′ ∗ W ′ , C ] [N, T'*H'*W', C] [N,T′∗H′∗W′,C] 变成 [ N , T ′ , H ′ ∗ W ′ , C ] [N, T', H'*W', C] [N,T′,H′∗W′,C],按时间拆开,每个时间片有 H ′ ∗ W ′ H'*W' H′∗W′ 个保留空间 token。
接着再是补 mask token 的数量,形状为 [ N , T , H ∗ W , C ] [N, T, H*W, C] [N,T,H∗W,C]
然后就是cat拼接、gather还原顺序、view整理形式的流水线操作。要注意cat和gather都是在dim=2的维度上执行的。
3.causal_restore
适用于mask_strategy == [‘frame’,‘temporal’]的情况
与以上在“全token维”或“空间维”恢复不同,causal_restore在“时间维”恢复。
大致与tube_restore相似,只是从空间维变成时间维。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)