单查秒回,一联就跪!多表关联的慢SQL该如何优化
你有没有遇到过这种情况:单表查询嗖嗖快,一旦多表关联(JOIN)就卡成狗,甚至直接超时?这其实不是因为“数据太多”,而是因为 JOIN 背后的执行路径被无限放大。结果就是,系统资源被白白浪费,查询时间呈指数级增长,业务也跟着“躺平”。今天我们就从 MySQL 执行计划(EXPLAIN)入手,带你一眼看穿哪些 JOIN 会“炸库”,以及如何快速“灭火”。
目录
四、Using join buffer:索引 JOIN 失败的信号
你有没有遇到过这种情况:单表查询嗖嗖快,一旦多表关联(JOIN)就卡成狗,甚至直接超时?这其实不是因为“数据太多”,而是因为 JOIN 背后的执行路径被无限放大。结果就是,系统资源被白白浪费,查询时间呈指数级增长,业务也跟着“躺平”。

今天我们就从 MySQL 执行计划(EXPLAIN)入手,带你一眼看穿哪些 JOIN 会“炸库”,以及如何快速“灭火”。
一、慢 JOIN SQL 的本质是什么?
MySQL 多表 JOIN 的本质是嵌套循环(Nested Loop Join)
一旦某个表被“低效地重复访问”,性能就会呈指数级下降。因此,所有慢 JOIN SQL 的执行计划,本质都暴露了同一个问题:
某个表被反复扫描,却没有走索引!
二、最致命特征:被驱动表 type = ALL
多表join本质就是再做for循环判断,可抽象为:
for(order表行 oRow : order表){
for(u表的行 uRow : user表){
if(uRow.id = oRow.user_id){
return oRow;
}
}
}此处的 order表就是驱动表,user表就是被驱动表,样例SQL:
SELECT *
FROM orders o
left JOIN user u ON o.user_id = u.id
WHERE o.create_time >= '2024-01-01' and o.create_time <= '2024-02-01';问题前提:
-
orders.user_id有值 -
user.id没有索引
执行计划:
+----+-------------+-------+------------+-------+------------------------+------------------------+---------+------+------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+------------------------+------------------------+---------+------+------+----------+--------------------------------------------+
| 1 | SIMPLE | o | NULL | range | idx_orders_create_time | idx_orders_create_time | 6 | NULL | 1 | 100.00 | Using index condition |
| 1 | SIMPLE | u | NULL | ALL | NULL | NULL | NULL | NULL | 662 | 100.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+-------+------------------------+------------------------+---------+------+------+----------+--------------------------------------------+
2 rows in set, 1 warning (0.00 sec) 其中user表每次join都会被全表扫描
优化方式:
给被驱动表的连接字段建索引:
CREATE INDEX idx_user_id ON user(id);三、相关子查询:DEPENDENT SUBQUERY
执行计划的selectType中出现DEPENDENT SUBQUERY,代表子查询 依赖外层表,无法物化。即外层返回 N 行,子查询执行 N 次。样例SQL:
SELECT *
FROM user u
WHERE (
SELECT COUNT(*)
FROM orders o
WHERE o.user_id = u.id
) > 5;执行计划:
+----+--------------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+--------------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
| 1 | PRIMARY | u | NULL | ALL | NULL | NULL | NULL | NULL | 662 | 100.00 | Using where |
| 2 | DEPENDENT SUBQUERY | o | NULL | ALL | NULL | NULL | NULL | NULL | 437625 | 10.00 | Using where |
+----+--------------------+-------+------------+------+---------------+------+---------+------+--------+----------+-------------+
2 rows in set, 2 warnings (0.00 sec) 在 MySQL 8.0 中,大部分 EXISTS 相关子查询已经可以被优化为 MATERIALIZED 或半连接,只有在“无法去相关”的情况下,才会出现 DEPENDENT SUBQUERY。
优化写法(改写为 GROUP BY + HAVING):
SELECT u.*
FROM user u
JOIN (
SELECT user_id
FROM orders
GROUP BY user_id
HAVING COUNT(*) > 5
) o ON o.user_id = u.id;
-- 同时添加索引
CREATE INDEX idx_orders_user_id ON orders(user_id);-
orders 只扫描 1 次
-
在子查询里完成聚合
-
外层 JOIN 用等值关联,可走索引
四、Using join buffer:索引 JOIN 失败的信号
如果执行计划的Extra中出现了 Using join buffer (Block Nested Loop) ,8.0较高版本中为hash join,则说明:
-
JOIN 条件无法使用索引
-
MySQL 使用 JOIN Buffer + 块嵌套循环
SQL样例:
SELECT o.*
FROM orders o
JOIN user u ON o.user_id = u.id
WHERE u.status = 'ACTIVE';问题前提:
-
连接条件均有索引
-
但是连接条件的字段类型不一样,例如varchar与int比较,导致了隐式类型转换,无法直接使用索引进行等值匹配,而是会调用函数来计算结果
执行计划:
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+--------------------------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+--------------------------------------------+
| 1 | SIMPLE | u | NULL | ALL | PRIMARY | NULL | NULL | NULL | 100113 | 10.00 | Using where |
| 1 | SIMPLE | o | NULL | ALL | NULL | NULL | NULL | NULL | 435000 | 10.00 | Using where; Using join buffer (hash join) |
+----+-------------+-------+------------+------+---------------+------+---------+------+--------+----------+--------------------------------------------+
2 rows in set, 2 warnings (0.00 sec) 优化方式:
修改连接条件、或更改字段类型
五、如何优化?
多表 JOIN 的慢 SQL,很多时候并不是因为数据量本身过大,而是由于 JOIN 路径设计不合理,导致表被低效、重复地访问。
在 EXPLAIN 中看到的各类“危险信号”,很多情况下都是在提示:某些 JOIN 条件没有有效利用索引,触发了不必要的多次扫描。
如何一键识别并优化这类慢 SQL?
DBdoctor提供的SQL审核功能,内置多条 JOIN 关联规则,自动识别:
-
多表关联,关联字段类型不一致
-
多表关联,被驱动表的访问路径需要走索引
-
表关联可能存在笛卡尔积
-
表连接数量限制
-
多表关联,关联字段charset不同,可能导致索引失效
-
...
SQL审核结果样例:
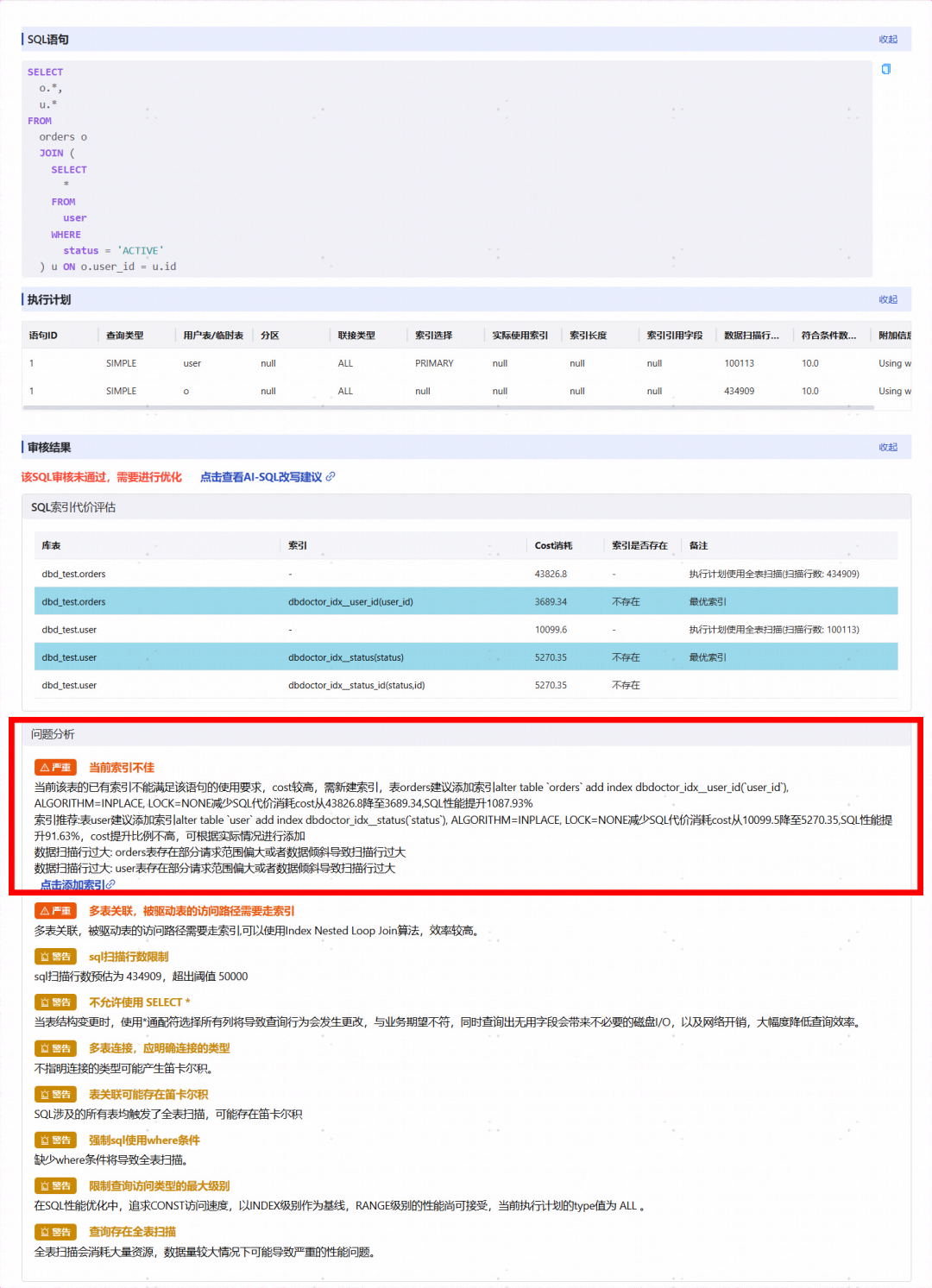
点击DBdoctor的 AI-SQL改写功能,还可以在不改变语义的情况下,对SQL进行优化改写,进一步提升SQL性能。
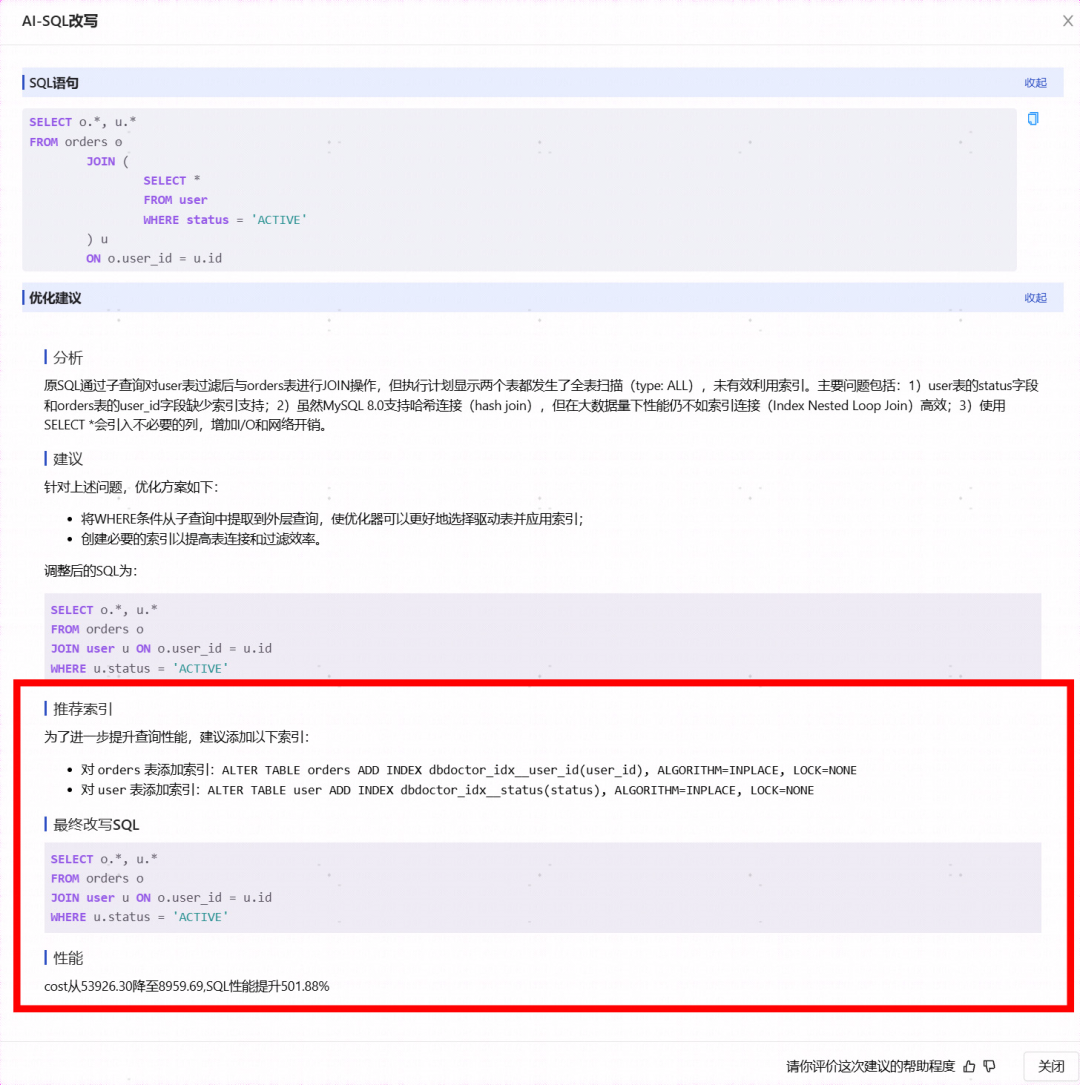
DBdoctor 通过精准解析 SQL 与执行计划,快速定位 JOIN 性能瓶颈,同时结合专家优化经验、外置Cost优化器以及大模型,为慢 SQL 提供精准优化建议,让查询性能瞬间提升。欢迎下载体验,让 SQL 优化从此省心!
_________________________________________________
DBdoctor免*费下载地址:https://www.dbdoctor.cn/?utm=02
点击下方添加小助手微信,官方技术支持服务+加入技术交流群+赠送高阶License

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)