AI大模型-Ollama默认提供的API端口
Ollama默认提供的API端口(通常是11434)及常见问题排查
Ollama 服务架构与进程模型
在Windows上,Ollama不是单个进程。当启动它时:
-
桌面应用 (
Ollama.exe):作为用户界面和服务管理器。它默认开机启动,在后台运行。这个进程本身不监听11434端口。 -
后台服务进程 (
ollama serve):桌面应用会自动唤醒一个真正的服务进程。可以在任务管理器里找到它。正是这个ollama.exe的子进程在监听0.0.0.0:11434。 -
模型运行进程:当执行
ollama run时,会启动一个独立的进程加载模型。API请求最终由这个进程处理。
为什么理解这个很重要?
当发现端口无响应时,问题可能出在“服务进程”没有正常启动,而不是桌面应用没打开。
验证服务进程是否存在:
# 在PowerShell中,查找真正服务的进程
Get-CimInstance Win32_Process | Where-Object { $_.CommandLine -like "*ollama*" } | Select-Object ProcessId, CommandLine 网络连接的本质 -
网络连接的本质 - localhost vs 127.0.0.1 vs 0.0.0.0
在浏览器或脚本里输入 http://localhost:11434,系统会将其解析为IP地址 127.0.0.1。这是一个特殊的回环地址,数据包根本不离开网卡,直接在操作系统内部流转。
关键细节:Ollama服务默认绑定在 0.0.0.0:11434。这意味着它监听所有网络接口的11434端口,包括物理网卡、虚拟网卡和回环地址。
如何进行底层连通性测试?
按顺序执行以下命令,进行逐层诊断:
| 测试命令 | 测试目的 | 预期成功输出 | 若失败则意味着 |
|---|---|---|---|
ping 127.0.0.1 |
测试操作系统TCP/IP协议栈是否正常。 | 来自 127.0.0.1 的回复。 | 系统网络核心故障,极其罕见。 |
telnet 127.0.0.1 11434 |
测试端口层面的TCP连接。 | 新窗口闪烁或保持空白(连接已建立)。 | 1. Ollama服务未运行 2. 端口被其他程序占用 3. 防火墙拦截 |
curl http://127.0.0.1:11434 |
测试HTTP层面的GET请求。 | {"Ollama":"service is running"} |
服务已运行但HTTP层面有问题(较少见)。 |
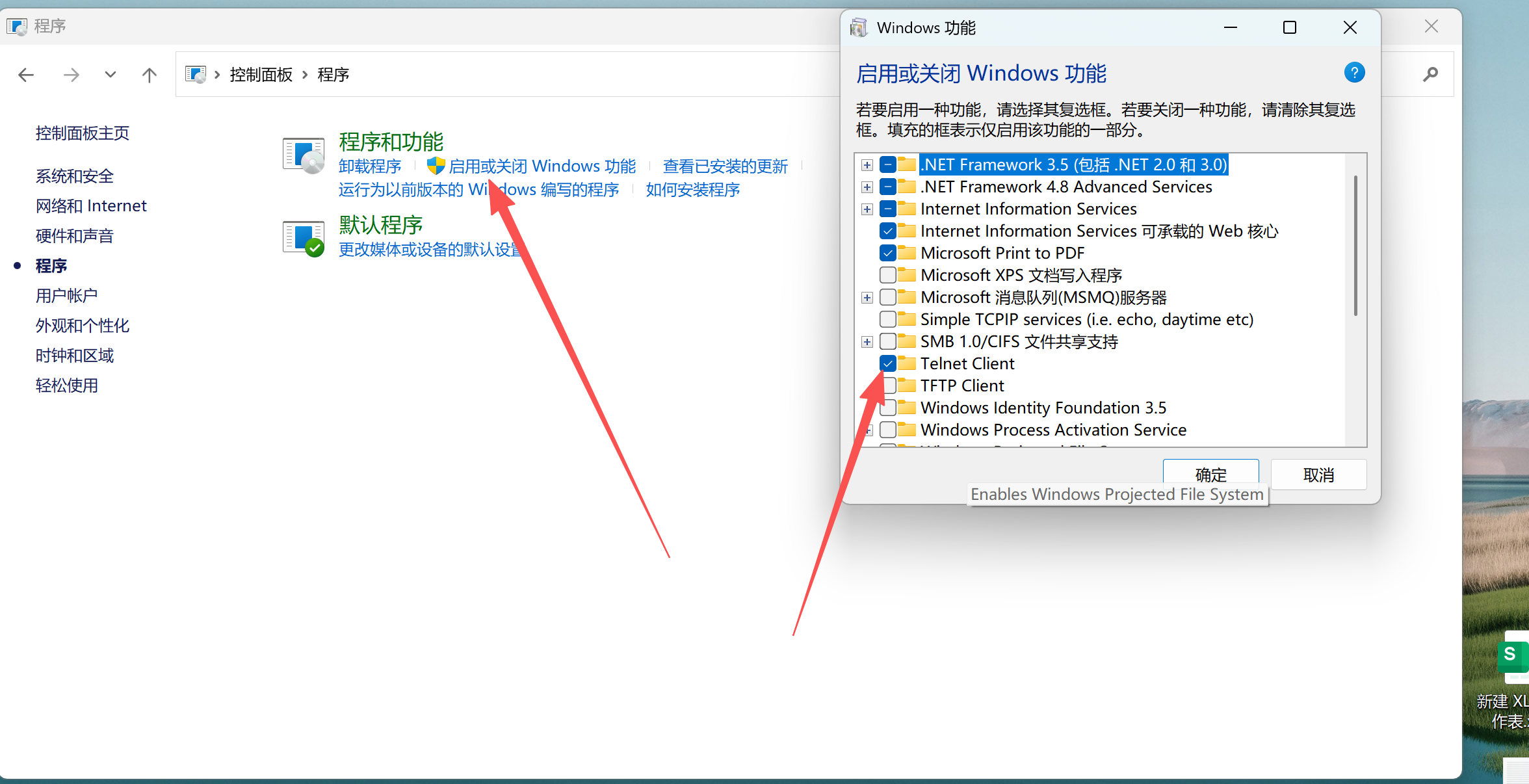
注意:Windows默认没有
telnet客户端。启用方法如下图:
在代码中建立稳定连接的最佳实践
基于HTTP的请求在长连接或流式传输时不稳定,这里提供生产环境级的Python连接代码,重点解决超时、重试和流式读取问题。
python
import requests
import json
import time
class OllamaClient:
def __init__(self, host="http://127.0.0.1:11434", timeout=60):
self.base_url = host
self.timeout = timeout
self.session = requests.Session() # 使用Session保持连接,提升性能
# 配置重试策略(对于不稳定的网络或服务启动期很有用)
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
retry_strategy = Retry(
total=3,
backoff_factor=1,
status_forcelist=[429, 500, 502, 503, 504]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
self.session.mount("http://", adapter)
self.session.mount("https://", adapter)
def generate_with_robust_streaming(self, model, prompt):
"""健壮的流式生成方法,正确处理各种中断情况。"""
url = f"{self.base_url}/api/generate"
payload = {
"model": model,
"prompt": prompt,
"stream": True,
"options": {"num_predict": 500}
}
full_response = ""
print("AI: ", end="", flush=True)
try:
# 设置更长的超时,特别是对于首次加载模型的请求
with self.session.post(url, json=payload, stream=True, timeout=300) as response:
response.raise_for_status()
# **关键:手动迭代处理流式响应**
for raw_line in response.iter_lines():
if not raw_line:
continue # 跳过空行
try:
line_json = json.loads(raw_line.decode('utf-8'))
except json.JSONDecodeError as e:
print(f"\n[警告] 解析JSON行失败: {e}, 原始行: {raw_line[:50]}...")
continue
# 检查流结束标志
if line_json.get("done", False):
# 可以在这里获取性能统计信息
stats = line_json.get("metrics", {})
print(f"\n[生成完成] 耗时: {stats.get('total_duration', 0)/1e9:.2f}秒")
break
# 累积响应文本
chunk = line_json.get("response", "")
if chunk:
print(chunk, end="", flush=True)
full_response += chunk
except requests.exceptions.Timeout:
print("\n[错误] 请求超时。模型可能正在加载或生成过长文本。")
return None
except requests.exceptions.ConnectionError as e:
print(f"\n[错误] 连接失败。请确认Ollama服务正在运行。详细信息: {e}")
# 可以在这里添加自动启动服务的逻辑(如果需要)
return None
except Exception as e:
print(f"\n[未预料错误] {type(e).__name__}: {e}")
return None
return full_response
# 使用示例
if __name__ == "__main__":
client = OllamaClient()
# 测试一个中等长度的生成任务
response = client.generate_with_robust_streaming("qwen2.5:3b", "详细解释TCP三次握手的过程。")
if response:
print(f"\n最终回复长度: {len(response)} 字符")高级调试与抓包分析
当常规方法都无法定位问题时,需要成为“网络侦探”。
1. 查看端口监听详情:
# 查看11434端口被哪个进程精确监听
netstat -ano | findstr :11434 | findstr LISTENING
# 输出示例:TCP 0.0.0.0:11434 0.0.0.0:0 LISTENING 12345
# 记下PID(例如12345),然后在任务管理器中查看对应进程。2. 使用网络抓包工具(终极武器):
安装 Wireshark。捕获 loopback 或 Adapter for loopback traffic 接口的数据。
-
过滤器设置:
tcp.port == 11434 -
这时将看到原始的TCP数据包。找到HTTP请求,查看完整的请求头和响应头。一个常见的错误是
Content-Type头不正确,Ollama要求application/json。
3. 检查Ollama服务日志:
Ollama服务进程的输出通常不可见。但可以通过命令提示符手动启动服务来查看实时日志:
cd "C:\Program Files\Ollama"
ollama serve保持这个窗口打开,所有内部错误和请求日志都会打印在这里。这是诊断模型加载失败等问题的最直接方法。
-
用
telnet和curl成功验证端口,并运行上面的健壮Python脚本。 -
Agent开发:将
OllamaClient类封装到Agent框架中。流式处理对于实现Agent的“思考-输出”过程至关重要。 -
任何时候遇到连接问题:按照 连通性测试 -> 进程检查 -> 日志分析 -> 抓包 的四层漏斗进行排查。
记住,localhost:11434 不是一个魔法字符串,它是一个由特定进程提供的、基于TCP/IP协议的网络服务。理解这一点,你就拥有了彻底驾驭它的能力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)