RAG routing全面总结
由于LlamaIndex的集成和配置相对复杂,且可能与LangChain的Chroma实例不直接兼容,为了避免过度冗余和增加复杂性,我将LlamaIndex的代码块注释掉,并用文字说明其概念。核心思想是LlamaIndex的RouterQueryEngine利用LLM选择最佳的QueryEngineTool,每个工具封装一个知识库的查询逻辑,与LangChain的Function Calling方
属于RAG pipeline的第二个阶段,目的是 根据question查到正确的数据源 ,实际是一个分类任务。首先要根据用户问题做意图识别:
1.基于规则的方法 :使用预先定义的关键词或模式来判断意图。 根据领域知识,列出与各类意图相关的关键词集合,匹配用户 query 中出现的词来分类。 此方法实现简单直接,对已知意图效果好。缺点是对未包含的表达方式鲁棒性差,需人工维护规则库。
-例子:如果用户 query 中包含“ 报销”“费用” 等关键词,判定为 报销流程查询 ;如果包含 “销售”“技巧” 等词,判定为 保险产品销售技巧 。
2.基于机器学习的方法 :收集大量的意图识别的样本, 对预训练的模型(如BERT)继续微调。 相比规则方法,ML 模型对同义表达更鲁棒,能捕获上下文语义特征。缺点是需要标注数据进行训练。
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import classification_report
from sentence_transformers import SentenceTransformer
# 1. 准备训练数据
# 示例文本和对应的类别标签
training_queries = [
"手机屏幕坏了怎么修?", "我的笔记本电脑充不进电", "如何更新设备的固件?", "产品规格在哪里查看?", "智能手表如何配对手机?",
"订单号ORD987654321的物流信息", "我的包裹什么时候能到?", "订单状态显示待发货是什么意思?", "我能取消订单吗?", "付款失败了怎么办?",
"退货流程是怎样的?", "换货需要支付运费吗?", "退款一般需要几天才能到账?", "我买错了东西能退吗?", "退换货的有效期是多久?"
]
labels = [
"product_support", "product_support", "product_support", "product_support", "product_support",
"order_inquiry", "order_inquiry", "order_inquiry", "order_inquiry", "order_inquiry",
"return_exchange_policy", "return_exchange_policy", "return_exchange_policy", "return_exchange_policy", "return_exchange_policy"
]
label_map = {
"product_support": 0,
"order_inquiry": 1,
"return_exchange_policy": 2
}
reverse_label_map = {v: k for k, v in label_map.items()}
numeric_labels = [label_map[l] for l in labels]
# 2. 初始化Sentence Transformer模型进行嵌入
# 使用一个轻量级的预训练模型
embedding_model = SentenceTransformer('all-MiniLM-L6-v2')
# 3. 生成查询的嵌入
print("正在生成训练数据的嵌入...")
query_embeddings = embedding_model.encode(training_queries)
print("嵌入生成完成。")
# 4. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(
query_embeddings, numeric_labels, test_size=0.2, random_state=42
)
# 5. 训练一个分类器(这里使用支持向量机 SVM)
print("正在训练分类器...")
classifier = SVC(kernel='linear', probability=True) # probability=True 允许预测概率
classifier.fit(X_train, y_train)
print("分类器训练完成。")
# 6. 评估分类器(可选)
y_pred = classifier.predict(X_test)
print("n分类器评估报告:")
print(classification_report(y_test, y_pred, target_names=label_map.keys()))
# 7. 定义路由函数
def route_with_classifier(question: str):
query_embedding = embedding_model.encode([question])
predicted_label_idx = classifier.predict(query_embedding)[0]
predicted_label = reverse_label_map[predicted_label_idx]
# 获取预测概率 (如果需要)
probabilities = classifier.predict_proba(query_embedding)[0]
confidence = probabilities[predicted_label_idx]
print(f"分类器预测类别: {predicted_label} (置信度: {confidence:.2f})")
return predicted_label, confidence
# 8. 集成到RAG流程中
def run_classifier_routed_rag(question: str):
print(f"n--- 独立分类模型路由器处理查询: '{question}' ---")
predicted_category, confidence = route_with_classifier(question)
# 根据预测类别选择对应的检索器
selected_retriever = None
if predicted_category == "product_support":
selected_retriever = product_retriever
elif predicted_category == "order_inquiry":
selected_retriever = order_retriever
elif predicted_category == "return_exchange_policy":
selected_retriever = return_exchange_retriever
else:
print("未识别的查询类别,无法进行检索。")
return "抱歉,我无法理解您的问题类型,请尝试更具体地描述。"
# 执行检索
print(f"正在从 '{predicted_category}' 知识库检索...")
retrieved_docs = selected_retriever.invoke(question)
context = "n".join([d.page_content for d in retrieved_docs])
print(f"检索到以下上下文:n{context}")
# 使用LLM生成答案
prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个友好的客服助手,请根据提供的上下文回答用户问题。如果上下文不包含足够的信息,请告知用户你无法回答。"),
("user", "上下文: {context}nn问题: {question}")
])
rag_chain = prompt_template | llm
response = rag_chain.invoke({"context": context, "question": question})
final_answer = response.content
print(f"最终回答: {final_answer}")
return final_answer
# 测试
run_classifier_routed_rag("我的手机无法开机怎么办?")
run_classifier_routed_rag("我的订单ORD123456789发货了吗?")
run_classifier_routed_rag("我买的衣服不合适,可以退货吗?")
run_classifier_routed_rag("你们最近有什么促销活动?") # 这个查询可能不会被正确分类,因为训练数据中没有类似内容
此外还有Zero Shot Classification ,其是 NLP 的一类 task,其中 model 在一组 labeled data 上训练后,能够对来自以前未见过的类的新示例进行分类。在这里,我们的 router 可以利用 zero-shot classification 的 model 为一段 text 分配一个 label,这个 label 是 router 预先定义的标签集。Haystack 的 ZeroShotTextRouter 就是利用的 Hugging Face 的 zero shot 分类模型来实现的 routing。
3.Logical routing:
(1)LLM Function Calling
from langchain_core.tools import tool
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableLambda
from langchain.agents import create_tool_calling_agent, AgentExecutor
# 定义每个知识库的检索器
product_retriever = product_db.as_retriever()
order_retriever = order_db.as_retriever()
return_exchange_retriever = return_exchange_db.as_retriever()
# 定义工具,每个工具代表一个知识库的检索功能
@tool
def get_product_support_info(query: str) -> str:
"""
当你需要回答关于产品功能、使用方法、故障排除、技术规格等产品相关问题时,使用此工具。
例如:'手机怎么开机?', '耳机连接不上蓝牙怎么办?', '笔记本电池续航多久?'
"""
docs = product_retriever.invoke(query)
return "n".join([d.page_content for d in docs])
@tool
def get_order_inquiry_info(query: str) -> str:
"""
当你需要回答关于订单状态、物流信息、支付问题、收货地址修改等订单相关问题时,使用此工具。
例如:'我的订单发货了吗?', '物流信息在哪里看?', '支付失败了怎么办?'
"""
docs = order_retriever.invoke(query)
return "n".join([d.page_content for d in docs])
@tool
def get_return_exchange_policy_info(query: str) -> str:
"""
当你需要回答关于退货流程、退款时间、换货条件、运费承担等退换货政策相关问题时,使用此工具。
例如:'怎么申请退货?', '退款多久能到账?', '非质量问题退货运费谁承担?'
"""
docs = return_exchange_retriever.invoke(query)
return "n".join([d.page_content for d in docs])
# 将所有工具放入一个列表中
tools = [get_product_support_info, get_order_inquiry_info, get_return_exchange_policy_info]
# 创建一个 Agent,让LLM根据用户问题选择并调用工具
# 注意:这里我们只用Agent来做路由决策和工具调用,实际的RAG生成部分可以单独构建
agent_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个智能客服助手,根据用户问题选择最合适的工具来获取信息。"),
("user", "{input}"),
("placeholder", "{agent_scratchpad}") # 代理的思考过程
])
agent = create_tool_calling_agent(llm, tools, agent_prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 封装一个 RAG 链
def run_llm_routed_rag(question: str):
print(f"n--- LLM Function Calling 路由器处理查询: '{question}' ---")
# 让 Agent 执行,它会选择工具并返回结果
response = agent_executor.invoke({"input": question})
# AgentExecutor的输出中包含了最终的答案
final_answer = response["output"]
print(f"最终回答: {final_answer}")
return final_answer
# 测试
run_llm_routed_rag("我的手机无法开机怎么办?")
run_llm_routed_rag("我的订单ORD123456789发货了吗?")
run_llm_routed_rag("我买的衣服不合适,可以退货吗?")
run_llm_routed_rag("你们的产品都有哪些颜色?") # LLM可能会选择产品知识库,但可能找不到确切答案,或泛化回答
(2)基于特征工程的方法 : 通过精心设计的Prompt直接让大模型判断意图类别。 可以提供若干意图类别描述,让模型选择最适合的类别。此方法不需要额外训练数据,在零样本或少样本场景下效果好。
from langchain_openai import ChatOpenAI
from langchain_core.runnables import RunnableLambda
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 前置工作:创建llm
llm = ChatOpenAI(
temperature=0.01,
model="glm-4",
openai_api_key="你的API KEY",
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
# 第一步:通过大模型进行对问题的语义分析,将结果返回出来
system = """根据用户的问题,将其分类为:'python代码问题'、'java代码问题'、'js代码问题'。如果无法分类,则直接回答不知道。
问题:{question}
输出格式直接返回选项内容
"""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
router = prompt | llm | StrOutputParser()
question = """为什么下面这段代码报错,错误信息是System.out.printIn找不到
public class HelloWorld {
public static void main(String[] args) {
System.out.printIn("Hello World");
}
}
"""
response = router.invoke({"question": question})
print(response)
# 第二步:根据返回结果,进行router选择,这里是将前面第一步也串联起来
def route_fun(result):
if "python代码问题" in result:
return "由python文档库查询"
elif "java代码问题" in result:
return "由java文档库查询"
elif "js代码问题" in result:
return "由js文档库查询"
else:
return "无法识别"
final_chain = router | RunnableLambda(route_fun)
print(final_chain.invoke({"question": question}))
4.Semantic routing
(1)基于向量相似度的路由器
这种方法不需要显式训练一个分类器,而是通过计算用户查询与各个类别代表性嵌入的相似度来决定路由。
from collections import defaultdict
from sklearn.metrics.pairwise import cosine_similarity
# 1. 为每个类别创建代表性查询的嵌入
# 我们可以使用之前用于训练分类器的查询,或者额外准备一些代表性查询
category_queries = defaultdict(list)
category_queries["product_support"].extend([
"产品功能介绍", "如何使用设备", "设备故障排除", "技术参数咨询", "软件更新问题"
])
category_queries["order_inquiry"].extend([
"订单状态查询", "物流信息跟踪", "支付问题", "修改收货地址", "取消订单"
])
category_queries["return_exchange_policy"].extend([
"退货流程", "退款政策", "换货条件", "运费承担", "售后服务"
])
# 2. 生成每个类别的平均嵌入作为类别向量
category_embeddings = {}
for category, queries in category_queries.items():
embeddings_list = embedding_model.encode(queries)
category_embeddings[category] = np.mean(embeddings_list, axis=0)
# 3. 定义路由函数
def route_with_vector_similarity(question: str):
query_embedding = embedding_model.encode([question])[0]
similarities = {}
for category, cat_embedding in category_embeddings.items():
# 计算余弦相似度
similarity = cosine_similarity([query_embedding], [cat_embedding])[0][0]
similarities[category] = similarity
# 选择相似度最高的类别
predicted_category = max(similarities, key=similarities.get)
max_similarity = similarities[predicted_category]
print(f"向量相似度预测类别: {predicted_category} (相似度: {max_similarity:.2f})")
return predicted_category, max_similarity
# 4. 集成到RAG流程中
def run_vector_routed_rag(question: str):
print(f"n--- 向量相似度路由器处理查询: '{question}' ---")
predicted_category, similarity = route_with_vector_similarity(question)
# 根据预测类别选择对应的检索器
selected_retriever = None
if predicted_category == "product_support":
selected_retriever = product_retriever
elif predicted_category == "order_inquiry":
selected_retriever = order_retriever
elif predicted_category == "return_exchange_policy":
selected_retriever = return_exchange_retriever
else:
print("未识别的查询类别,无法进行检索。")
return "抱歉,我无法理解您的问题类型,请尝试更具体地描述。"
# 执行检索
print(f"正在从 '{predicted_category}' 知识库检索...")
retrieved_docs = selected_retriever.invoke(question)
context = "n".join([d.page_content for d in retrieved_docs])
print(f"检索到以下上下文:n{context}")
# 使用LLM生成答案
prompt_template = ChatPromptTemplate.from_messages([
("system", "你是一个友好的客服助手,请根据提供的上下文回答用户问题。如果上下文不包含足够的信息,请告知用户你无法回答。"),
("user", "上下文: {context}nn问题: {question}")
])
rag_chain = prompt_template | llm
response = rag_chain.invoke({"context": context, "question": question})
final_answer = response.content
print(f"最终回答: {final_answer}")
return final_answer
# 测试
run_vector_routed_rag("手机黑屏了怎么办?")
run_vector_routed_rag("我的包裹到哪了?")
run_vector_routed_rag("怎么退换货?")
run_vector_routed_rag("你们的产品都有哪些型号?")
(2)可以为每个意图都设定一个prompt,然后进行判定
from langchain.utils.math import cosine_similarity
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnableLambda, RunnablePassthrough
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Two prompts
physics_template = """You are a very smart physics professor. \
You are great at answering questions about physics in a concise and easy to understand manner. \
When you don't know the answer to a question you admit that you don't know.
Here is a question:
{query}"""
math_template = """You are a very good mathematician. You are great at answering math questions. \
You are so good because you are able to break down hard problems into their component parts, \
answer the component parts, and then put them together to answer the broader question.
Here is a question:
{query}"""
# Embed prompts
embeddings = OpenAIEmbeddings()
prompt_templates = [physics_template, math_template]
prompt_embeddings = embeddings.embed_documents(prompt_templates)
# Route question to prompt
def prompt_router(input):
# Embed question
query_embedding = embeddings.embed_query(input["query"])
# Compute similarity
similarity = cosine_similarity([query_embedding], prompt_embeddings)[0]
most_similar = prompt_templates[similarity.argmax()]
# Chosen prompt
print("Using MATH" if most_similar == math_template else "Using PHYSICS")
return PromptTemplate.from_template(most_similar)
chain = (
{"query": RunnablePassthrough()}
| RunnableLambda(prompt_router)
| ChatOpenAI()
| StrOutputParser()
)
print(chain.invoke("What's a black hole"))
- RunnableBranch routing
from langchain_core.runnables import RunnableBranch, RunnableLambda
from langchain_core.output_parsers import StrOutputParser
# 定义一个简单的LLM分类器,直接输出类别名称
classifier_llm_prompt = ChatPromptTemplate.from_messages([
("system", """根据用户的问题,将其归类为以下之一:
'product_support': 关于产品功能、使用方法、故障排除、技术规格等。
'order_inquiry': 关于订单状态、物流信息、支付问题、收货地址修改等。
'return_exchange_policy': 关于退货流程、退款时间、换货条件、运费承担等。
如果问题不属于上述任何类别,请回答 'general_inquiry'。
只输出类别名称,不要输出其他任何内容。
"""),
("user", "{question}")
])
# 这是一个简化的分类器,直接使用LLM进行判断
llm_classifier = classifier_llm_prompt | llm | StrOutputParser()
# 定义每个类别的RAG链
def create_rag_chain(retriever):
prompt = ChatPromptTemplate.from_messages([
("system", "你是智能客服助手,请根据提供的上下文回答用户问题。如果上下文不包含足够信息,请告知用户。"),
("user", "上下文: {context}nn问题: {question}")
])
# 这里的RunnableLambda只是为了从retriever.invoke()的List[Document]中提取page_content
return (
{"context": retriever | RunnableLambda(lambda docs: "n".join([d.page_content for d in docs])), "question": RunnableLambda(lambda x: x["question"])}
| prompt
| llm
| StrOutputParser()
)
product_rag_chain = create_rag_chain(product_retriever)
order_rag_chain = create_rag_chain(order_retriever)
return_exchange_rag_chain = create_rag_chain(return_exchange_retriever)
# 定义一个通用RAG链,用于无法分类的查询(或指向一个通用知识库)
general_rag_chain_prompt = ChatPromptTemplate.from_messages([
("system", "你是一个通用的智能客服,请友好地回答用户问题。如果无法回答,请建议用户联系人工客服。"),
("user", "{question}")
])
general_rag_chain = general_rag_chain_prompt | llm | StrOutputParser()
# 使用 RunnableBranch 进行路由
# LLM分类器输出的类别名称作为判断条件
routing_chain = RunnableBranch(
(RunnableLambda(lambda x: llm_classifier.invoke({"question": x["question"]}) == "product_support"), product_rag_chain),
(RunnableLambda(lambda x: llm_classifier.invoke({"question": x["question"]}) == "order_inquiry"), order_rag_chain),
(RunnableLambda(lambda x: llm_classifier.invoke({"question": x["question"]}) == "return_exchange_policy"), return_exchange_rag_chain),
general_rag_chain # 默认分支
)
def run_lcel_routed_rag(question: str):
print(f"n--- LCEL RunnableBranch 路由器处理查询: '{question}' ---")
response = routing_chain.invoke({"question": question})
print(f"最终回答: {response}")
return response
run_lcel_routed_rag("我的耳机没有声音了,怎么回事?")
run_lcel_routed_rag("我的订单什么时候能收到?")
run_lcel_routed_rag("我想退货,流程是什么?")
run_lcel_routed_rag("今天天气怎么样?") # 会进入 general_inquiry
6.LlamaIndex RouterQueryEngine
由于LlamaIndex的集成和配置相对复杂,且可能与LangChain的Chroma实例不直接兼容,为了避免过度冗余和增加复杂性,我将LlamaIndex的代码块注释掉,并用文字说明其概念。核心思想是LlamaIndex的RouterQueryEngine利用LLM选择最佳的QueryEngineTool,每个工具封装一个知识库的查询逻辑,与LangChain的Function Calling方式异曲同工。
# from llama_index.core import VectorStoreIndex, SimpleDirectoryReader
# from llama_index.core.tools import QueryEngineTool, ToolMetadata
# from llama_index.core.selectors import LLMSingleSelector
# from llama_index.core.query_engine import RouterQueryEngine
# from llama_index.llms.openai import OpenAI
# from llama_index.embeddings.openai import OpenAIEmbedding
# # 假设您已经设置了LlamaIndex的ServiceContext
# # from llama_index.core import ServiceContext
# # llm = OpenAI(model="gpt-3.5-turbo")
# # embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# # service_context = ServiceContext.from_defaults(llm=llm, embed_model=embed_model)
# # 为了简化,这里我们直接使用之前LangChain创建的 Chroma DBs 作为 LlamaIndex 的 VectorStore
# from llama_index.vector_stores.chroma import ChromaVectorStore
# from llama_index.core import StorageContext
# from llama_index.core import VectorStoreIndex
# # LlamaIndex需要自己的LLM和Embeddings配置
# # 如果你使用LangChain的LLM和Embeddings,需要进行适配
# # 或者直接使用LlamaIndex原生的OpenAI设置
# from llama_index.llms.openai import OpenAI
# from llama_index.embeddings.openai import OpenAIEmbedding
# from llama_index.core import Settings
# Settings.llm = OpenAI(model="gpt-3.5-turbo")
# Settings.embed_model = OpenAIEmbedding(model="text-embedding-ada-002")
# # 假设我们从 LangChain 的 Chroma 数据库加载,需要重新构建 LlamaIndex 的 Index
# # 这里为了演示,我们直接用简化的方式创建 LlamaIndex 的 VectorStoreIndex
# # 实际应用中,您会从文件加载并构建 LlamaIndex 的 Index
# from llama_index.core import SimpleDirectoryReader
# # Helper function to create LlamaIndex VectorStoreIndex from text list
# def create_llama_index(docs, index_name):
# # LlamaIndex 喜欢从文件读取,这里我们模拟一下
# # 实际生产中您会加载真正的文档
# temp_dir = f"./temp_llama_docs/{index_name}"
# os.makedirs(temp_dir, exist_ok=True)
# for i, doc_content in enumerate(docs):
# with open(os.path.join(temp_dir, f"doc_{i}.txt"), "w", encoding="utf-8") as f:
# f.write(doc_content)
#
# reader = SimpleDirectoryReader(input_dir=temp_dir)
# documents = reader.load_data()
# index = VectorStoreIndex.from_documents(documents)
# return index
# product_li_index = create_llama_index(product_docs, "product_li_index")
# order_li_index = create_llama_index(order_docs, "order_li_index")
# return_exchange_li_index = create_llama_index(return_exchange_docs, "return_exchange_li_index")
# # 创建QueryEngineTool
# product_query_engine_tool = QueryEngineTool(
# query_engine=product_li_index.as_query_engine(),
# metadata=ToolMetadata(
# name="product_support_tool",
# description="当你需要回答关于产品功能、使用方法、故障排除、技术规格等产品相关问题时,使用此工具。"
# )
# )
# order_query_engine_tool = QueryEngineTool(
# query_engine=order_li_index.as_query_engine(),
# metadata=ToolMetadata(
# name="order_inquiry_tool",
# description="当你需要回答关于订单状态、物流信息、支付问题、收货地址修改等订单相关问题时,使用此工具。"
# )
# )
# return_exchange_query_engine_tool = QueryEngineTool(
# query_engine=return_exchange_li_index.as_query_engine(),
# metadata=ToolMetadata(
# name="return_exchange_policy_tool",
# description="当你需要回答关于退货流程、退款时间、换货条件、运费承担等退换货政策相关问题时,使用此工具。"
# )
# )
# # 创建RouterQueryEngine
# query_engine_tools = [
# product_query_engine_tool,
# order_query_engine_tool,
# return_exchange_query_engine_tool
# ]
# router_query_engine = RouterQueryEngine(
# selector=LLMSingleSelector.from_defaults(),
# query_engine_tools=query_engine_tools
# )
# def run_llama_routed_rag(question: str):
# print(f"n--- LlamaIndex RouterQueryEngine 路由器处理查询: '{question}' ---")
# response = router_query_engine.query(question)
# print(f"最终回答: {response}")
# return response
# # 测试
# run_llama_routed_rag("我的手机相机模糊了,怎么解决?")
# run_llama_routed_rag("我的订单状态显示已完成,但没收到货怎么办?")
# run_llama_routed_rag("我买的衣服大小不合适,可以换货吗?")
- LLM Completion Router
利用 LLM 的 Chat Completion 的功能,以对话的形式要求 LLM 从 prompt 中提供的一组单词或 topics 中选择一个来作为 routing 的结果。这种思路也是 LlamaIndex 的 LLM Selector router 的工作思路,如下图的示例程序所示: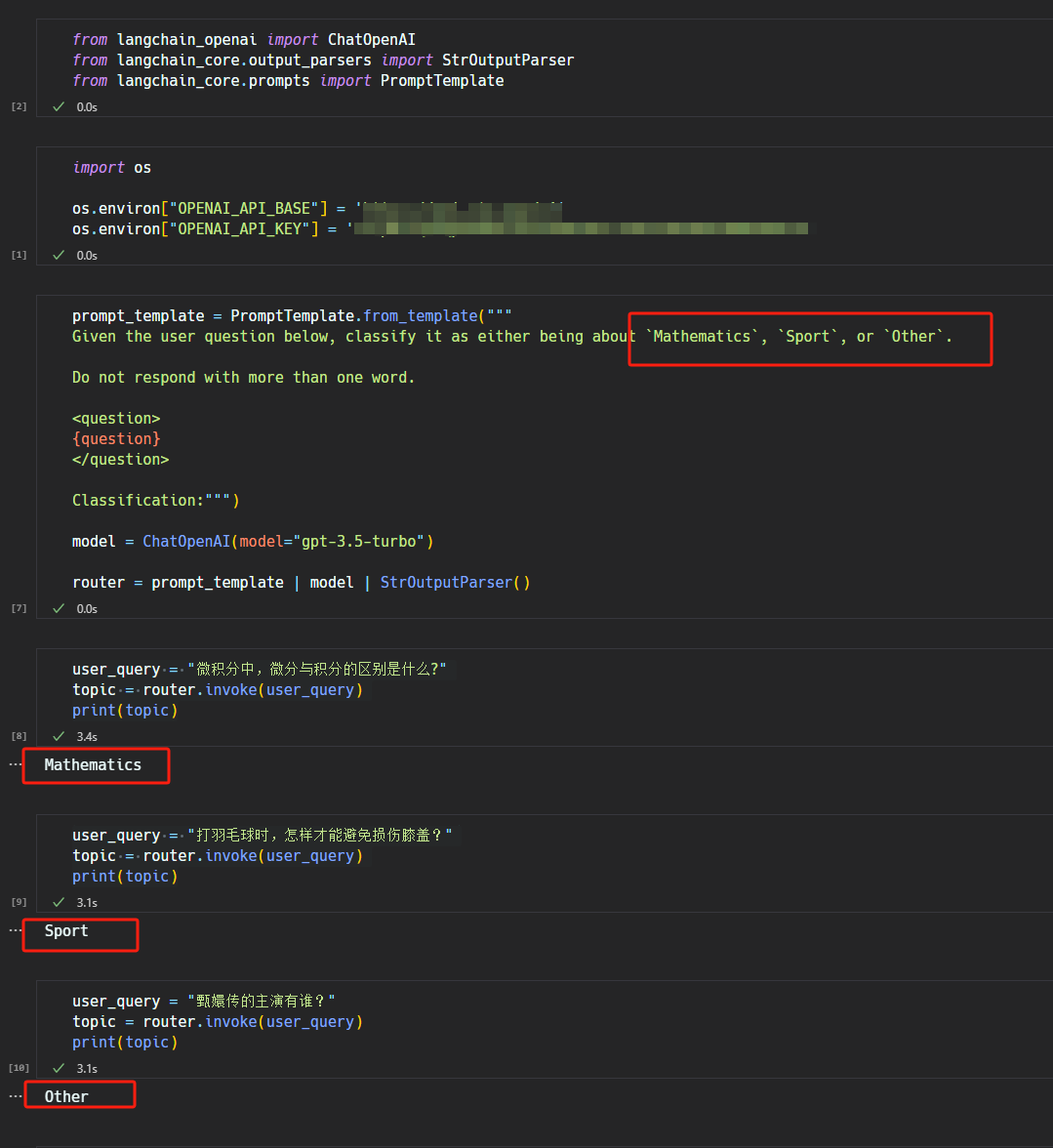
- Haystack Router
(1)Haystack 的 ZeroShotTextRouter 利用的 Hugging Face 的 zero shot 分类模型来实现的 routing。
(2)Haystack 的 TextClassificationRouter 利用了 python 的 langdetect 库实现的检索文本的语言,该库本身使用朴素贝叶斯算法来检测语言种类。
(3) Haystack 的 ConditionalRouter 和 FileTypeRouter。会针对变量进行逻辑检查,比如字符串长度、文件名以及值的比较等,用于处理如何路由查询。它们与编程中常用的 if/else 条件非常相似。其属于 Logical Routers
二,路由到不同场景
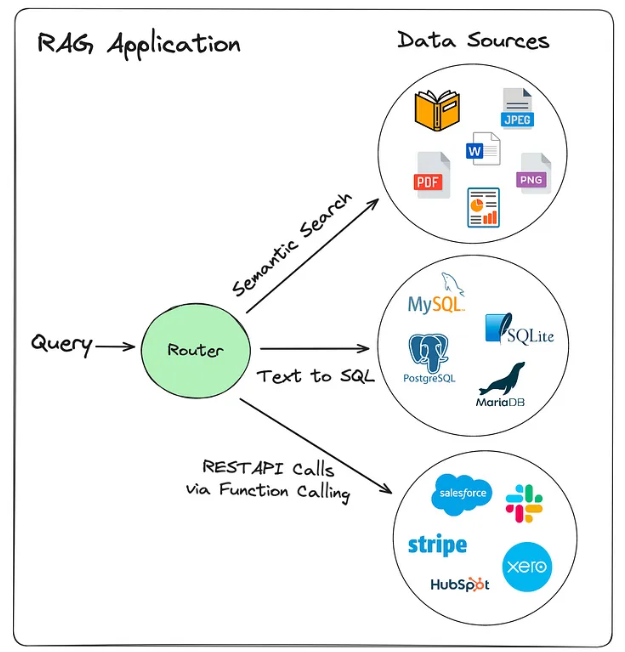
1,路由到 data source
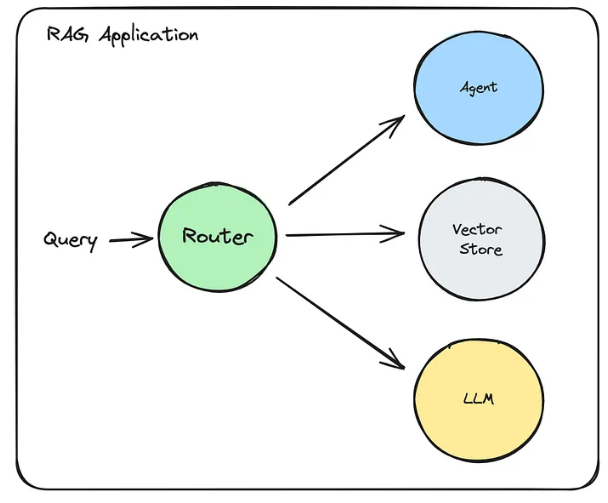
2.路由到不同的 component
还可以根据问题的性质,将 query 路由到不同的组件类型,比如可能交给 Agent 处理、Vector Store 处理或者直接由 LLM 处理
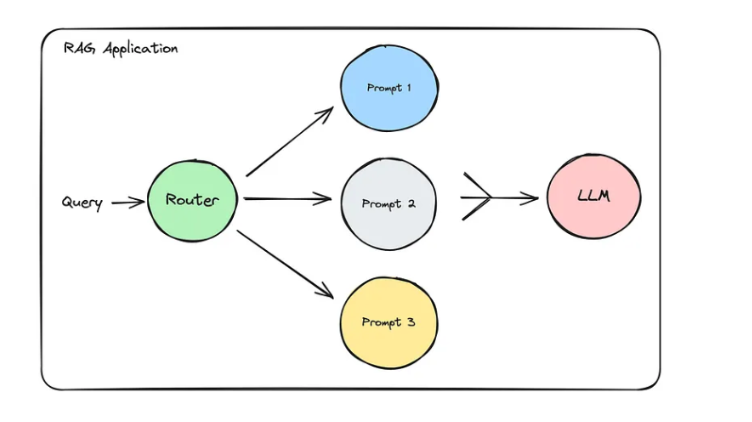
3.路由到不同的 prompt template
三,优化方向
构建一个生产级的语义路由RAG系统,还需要考虑更多高级问题:
1.多跳路由 (Multi-hop Routing):
某些复杂查询可能需要从多个知识库中获取信息,或需要分解为多个子问题。例如:“查询产品A的库存,如果库存不足,再查找替代产品B的推荐。”
这需要更智能的代理(Agent)能力,能够进行规划、执行多步骤任务,并在不同工具之间切换。
2.置信度与回退机制:
路由器不可能总是100%准确。当路由器对分类结果的置信度较低时(例如,分类器预测概率低于某个阈值,或LLM表示不确定),应该有回退机制。
常见策略:
导向一个通用知识库。
向用户澄清问题。
上报给人工客服。
同时查询多个可能性最高的知识库,然后让LLM综合判断。
3.动态知识源管理:
在企业环境中,知识库是不断变化的。如何动态地添加、更新或移除知识源,并相应地更新路由器的配置或训练数据,是一个重要考量。
对于基于向量相似度的路由器,这相对容易,只需更新类别嵌入。
对于基于分类器的路由器,可能需要周期性地重新训练模型。
对于基于LLM的路由器,可能需要更新工具的描述或LLM的上下文。
4.性能优化:
路由器的速度:
路由决策必须足够快,不能成为整个RAG系统的瓶颈。轻量级分类器或高效的向量相似度搜索是关键。
嵌入模型的选择:选择在准确性和速度之间取得平衡的嵌入模型。大型模型提供更好的语义理解,但推理速度慢。
缓存策略:缓存常见的查询结果或路由决策,减少重复计算。
并行处理:如果可能,并行执行某些步骤(例如,同时向多个知识库发送检索请求)。
5.评估与监控:
路由准确性:如何衡量路由器将查询导向正确知识库的比例?需要建立标注数据集进行评估。
端到端RAG性能:语义路由是否真正提高了最终生成答案的质量、相关性和准确性?需要通过A/B测试、用户满意度调查、人工评估等方式进行衡量。
错误分析:定期分析路由器误判的案例,以改进模型或规则。
延迟监控:监测从用户提问到获得答案的整体延迟。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)