Agent 记忆系统的标准方案为什么会失败?
摘要: 本文探讨了AI Agent记忆系统的设计挑战与解决方案。作者指出当前常见的对话历史存储和向量数据库检索存在局限性,提出了短期记忆的检查点机制(Checkpointing)和两种长期记忆架构:基于文件的自组织系统和混合图谱(Hybrid Graph)。系统通过主动处理信息、分层检索、冲突解决和智能遗忘机制,确保记忆的准确性和时效性。文章强调记忆是基础设施而非功能,建议将Agent视为操作系统
大家都明确地感受到,近几个月来我们使用的各个厂商的各种大模型给的这些编码套餐越来越大,作为一个普通人而言,我完全是用不完的,我正常也就使用了1%-2%。所以面对这些套餐里面,我一直在不停的去想有没有一种方式,是可以让整个的AI编程工具或程序能够完全的自主的跑起来,在我们定义好的这些角色里面有:产品经理、项目经理、前端开发、后端开发、自动化的测试、自动化的运维、数据分析等这些角色,通过AI agent把它们全部串起来,实现全自动化的任务。
这里面有个问题,也就是我们这篇文章里面提到的问题:记忆怎么样去处理。其实长久以来我们都知道大模型记忆他是有上下文长度限制的,不管是128k 还是 256k, 我们之前的文章里面也提到多很多方法比如:上下文压缩、工程的方法分级处理。看看下面内容对你有没有启发。
以下内容来自外网一个叫 Rohit的一名 AI 应用开发者。几个月前,我在一次关键的技术面试中失败了——面试官问我的 Agent:“用户上次提到的饮食偏好是什么?”
我的 Agent 回答:“我不确定。”
那一刻我意识到:我们正在用聊天日志假装自己有记忆。
我花了接下来的 90 天,深入研究 Agent 记忆系统,最终构建出一套可用于生产环境的记忆架构。核心洞察只有一句:
记忆是基础设施,不是功能。
为什么标准方案会失败?
1. 对话历史塞入上下文
最常见做法:把最近 10 轮对话塞进上下文。
- 问题:10 轮后上下文窗口满了,系统开始截断旧消息。
- 后果:Agent 忘记用户是素食者,推荐了牛排。
- 本质:对话历史不是记忆,只是聊天日志。
2. 向量数据库检索
进阶做法:用向量数据库存储记忆,通过语义检索。
- 问题:两周后数据库有 500 条记录。用户问“我的工作情况”,返回 12 段矛盾片段。
- 后果:Agent 幻觉出一个“既在 Google 又在 OpenAI 工作”的错误综合答案。
- 关键认知:Embedding 衡量相似性,不是真实性。向量数据库不理解时间、上下文或更新。
短期记忆:Checkpointing(检查点机制)
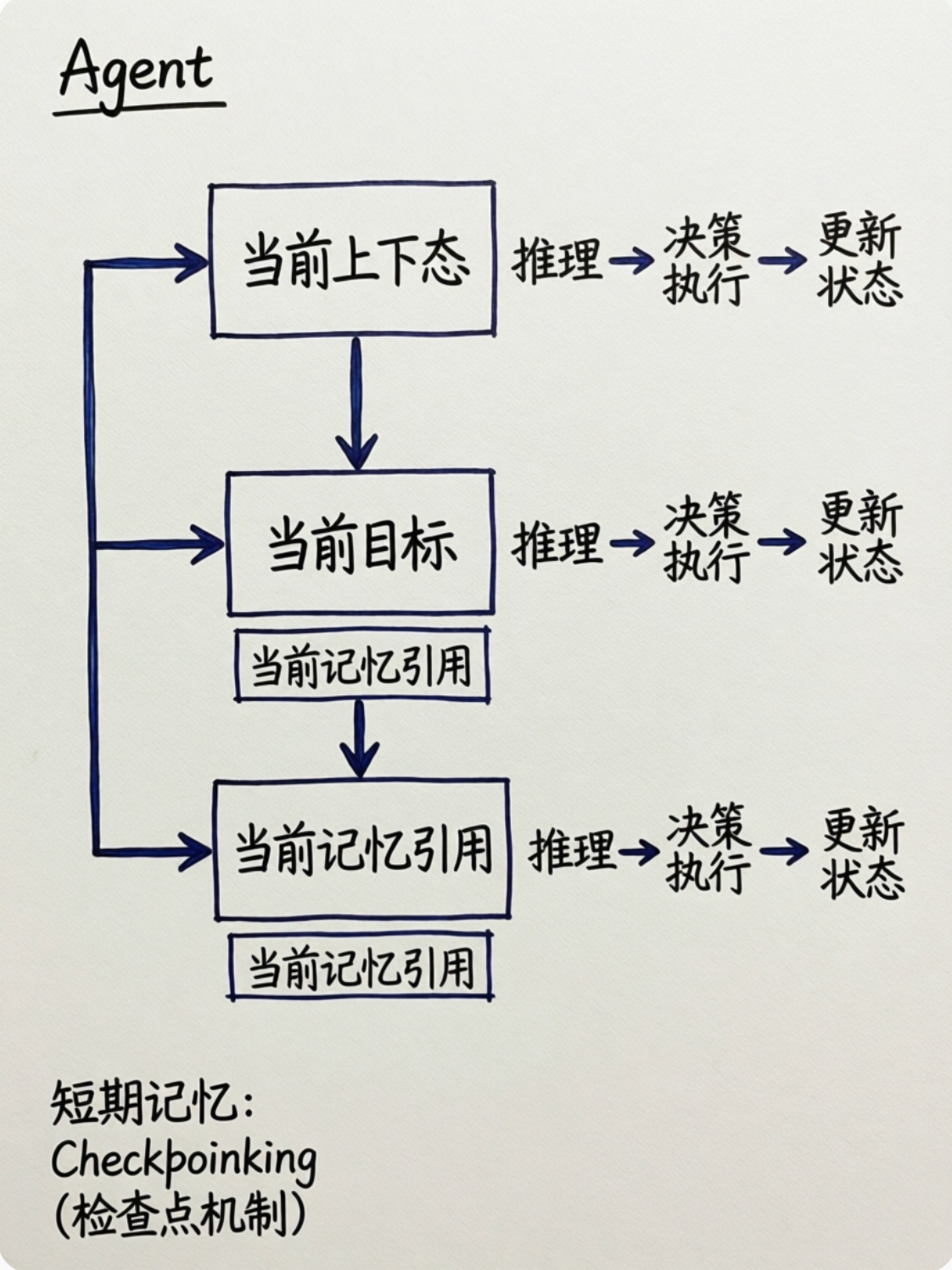
我把每个 Agent 当作一个状态机运行。
- 状态 = 当前上下文 + 当前目标 + 当前记忆引用
- 动作 = 推理 → 决策 → 执行 → 更新状态
引入 Checkpointing:
- 每次状态变更,保存完整状态快照。
- 支持:
- 确定性重放:复现任意一次对话流程
- 崩溃恢复:从最近快照重启
- 回溯调试:像时间旅行一样查看 Agent 的“思维过程”
短期记忆不是“记住刚才说了什么”,而是“记住当前任务的完整上下文”。
长期记忆架构 A:基于文件的自组织系统
设计了一个三层结构,模仿人类记忆的“编码-存储-提取”过程:
| 层级 | 类型 | 描述 |
|---|---|---|
| Resources | 原始数据 | 不可变,带时间戳(如聊天记录片段) |
| Items | 原子事实 | 提取的结构化事实(“用户偏好 Python”) |
| Categories | 演化摘要 | 动态摘要文件(work_preferences.md) |
写入时主动处理
新信息不只是归档,而是编织进现有摘要。
- 用户说:“我现在开始学 Rust。”
- 系统识别:与“偏好 Python”存在潜在冲突
- 决策:重写
work_preferences.md,将 Python 降级为“熟悉”,Rust 升级为“主用” - 自动解决矛盾
读取时分层检索
- 先拉取摘要(Categories)
- 问 LLM:“这些信息足够回答问题吗?”
- 如果不够,再下钻到 Items 和 Resources
- 避免信息过载
长期记忆架构 B:上下文图谱(Hybrid Graph)

为了处理复杂关系,我引入了混合存储结构:
- 向量存储:用于发现相似文本(“用户提过类似想法”)
- 知识图谱:用于精确的主语-谓语-宾语关系(“用户-当前雇主-OpenAI”)
冲突解决机制
用户说:“我跳槽到 OpenAI。”
- 系统检测到与“用户-当前雇主-Google”冲突
- 操作:
- 将旧关系标记为“历史”(保留时间戳)
- 创建新关系:“用户-当前雇主-OpenAI”
- 图谱中保留两条边,但标记“当前”状态
混合检索
- 向量搜索 + 图谱遍历并行运行
- 结果合并:向量提供“可能相关”,图谱提供“确定关系”
- LLM 负责最终综合
记忆必须衰减:智能遗忘
“永不遗忘”不等于“记住每个 Token”。
真正的记忆,是记住重要的。
我引入了三级衰减机制:
| 频率 | 操作 | 目的 |
|---|---|---|
| 每夜 | 合并冗余,提升高频访问项优先级 | 保持活跃记忆新鲜 |
| 每周 | 压缩旧事实为高层洞察,修剪 90 天未访问记忆 | 防止数据膨胀 |
| 每月 | 重建 Embedding,调整图谱边权重,归档冷数据 | 优化检索效率 |
推理时检索:从上下文约束反向设计
不要先检索再填充,而要从上下文窗口反向约束检索:
- 合成查询:LLM 生成多个搜索意图(“用户偏好”、“最近变更”、“职业背景”)
- 广泛搜索:并行检索候选记忆
- 评分排序:相关性 × 时间衰减权重
- 注入控制:只保留 Top 5–10 条真正有用的记忆
近期记忆往往击败六个月前的完美匹配。
五个致命错误(你可能正在犯)
- 存原始对话 → 应提取事实,而非转录
- 盲目用 Embedding → “我爱工作”和“我恨工作”嵌入相似,但语义相反
- 没有衰减 → Agent 淹没在过去,响应变慢且混乱
- 没有写入规则 → 想写就写,写的是垃圾
- 记忆当聊天历史 → 聊天历史短暂,记忆是结构化表示
核心智模型:把 Agent 当操作系统
我把 Agent 看作一个运行在 LLM 之上的操作系统:
| 组件 | 类比 | 作用 |
|---|---|---|
| RAM | 短期记忆 / Checkpoint | 当前对话的快速易失上下文 |
| 硬盘 | 长期记忆 / 图谱+向量库 | 持久化、索引化的知识存储 |
| 垃圾回收 | 衰减系统 | 定期维护,否则系统崩溃 |
记忆不是功能,是身份
一个没有记忆的 Agent,只是一个会说话的计算器。
一个有记忆的 Agent,才可能成为真正的数字伙伴。
我仍在优化这套系统,但核心原则已验证:
记忆不是你存了什么,而是你能在需要时准确想起什么。
如果你在构建 Agent,别再把聊天记录当记忆了。
从今天开始,设计你的记忆系统,就像设计数据库一样严谨。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)