OpenClaw 实战#05-4:第四层工程拆解Workspace / Memory
OpenClaw框架中的Workspace/Memory层是工程化Agent系统的关键分水岭。其核心价值不在于增强LLM记忆力,而是为系统提供"可恢复、可审计、可演进"的持久化支撑。Workspace作为系统级持久化容器,完整保存Session状态、执行记录、Tool调用痕迹等5类关键数据;Memory则是Runtime按需提取的状态子集,需进行裁剪压缩以控制成本。这种设计解决
目录
二、我一开始的误解:Memory ≈ 给 LLM 用的上下文?
四、先把概念钉死:Workspace ≠ Memory(工程语义别搞混)
1️⃣ Workspace:系统级持久化容器(存所有“家底”)
2️⃣ Memory:被 Runtime 使用的状态子集(用什么拿什么)
五、为什么 OpenClaw 要把 Workspace 单独拎成一层?
1️⃣ Runtime 是短命的,Workspace 是长命的
六、Workspace 里通常会存什么?(工程级拆解,直接参考落地)
5️⃣ Skill / Policy 绑定信息(版本兼容的关键)
七、Memory 为什么必须是“可裁剪的”?(新手最容易踩的坑)
2️⃣ Runtime 对 Memory 的真实操作方式(OpenClaw 工程实践)
八、Workspace 设计中最容易踩的 3 个坑(避坑指南)
——Workspace / Memory:为什么它不是“聊天记录”,而是系统的持久化骨架
在前几篇里,我们已经把 OpenClaw 的三层核心结构拆得明明白白,没有一句玄学:
-
第一层:消息入口 —— 系统如何被触发(谁来调用、用什么方式调用)
-
第二层:Gateway —— 触发如何被治理(控制平面,管权限、限流、路由)
-
第三层:Agent Runtime —— 一次执行如何被安全跑完(执行平面,管隔离、调度、异常兜底)
到这里,很多做Agent开发的同学都会陷入一个错觉:
“好像已经差不多了,Agent 能跑、Tool 能用、策略也有了,部署上就能落地。”
但我敢说,只要你真正把 Agent 放进长期运行的生产级工程系统,不用半个月,所有问题一定会集中爆在这一层:
Workspace / Memory
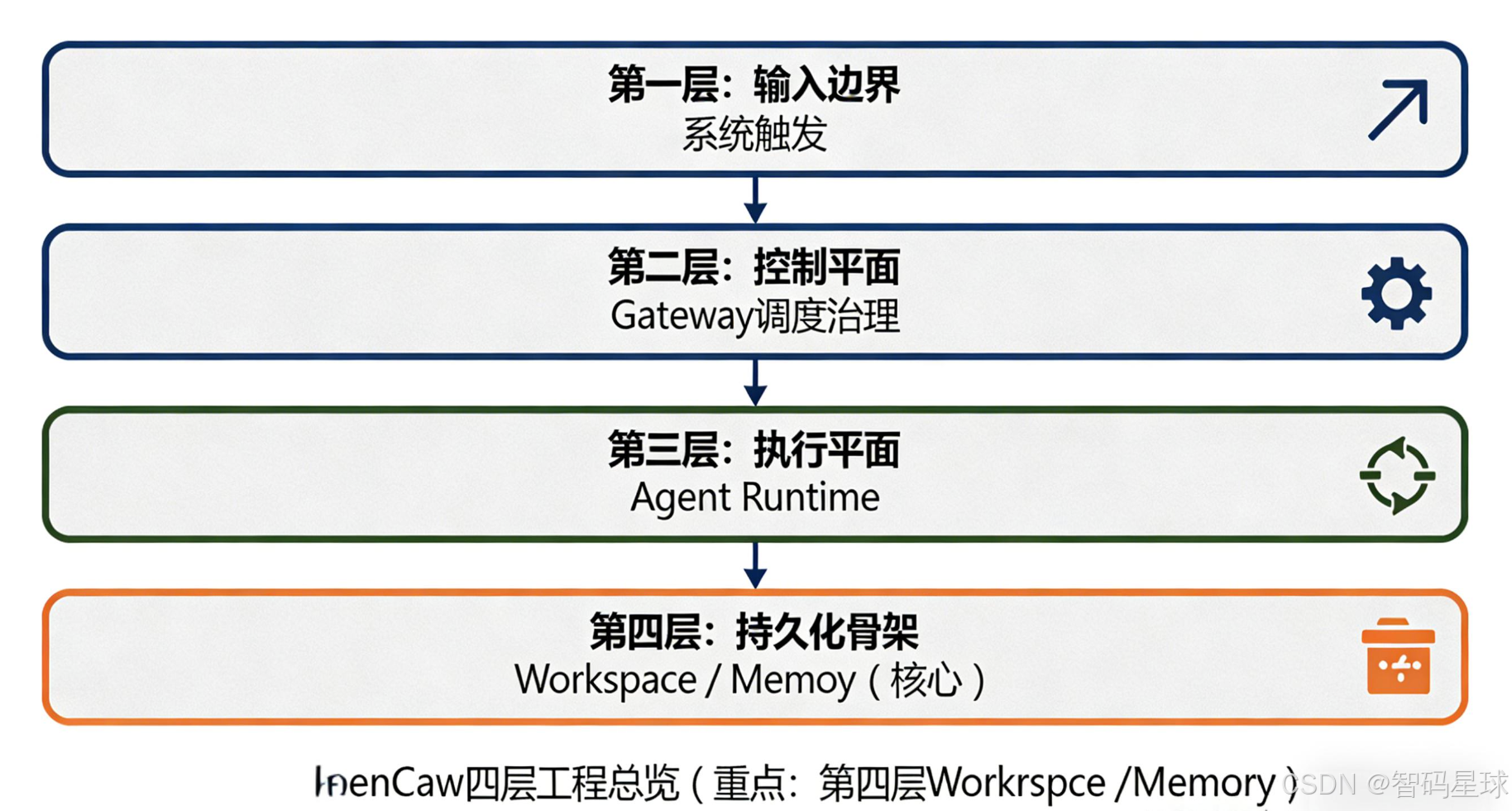
一、先给一句工程级结论(非常重要,记死)
在 OpenClaw 里,关于Workspace / Memory,我只说一句实在话:
Workspace / Memory 的本质不是“让 Agent 记住更多”,而是为系统提供一个“可恢复、可审计、可演进”的持久化骨架。
这句话你要是听不进去,把它理解成“聊天记录”“长期记忆”,甚至“LLM上下文缓存”,那后期一定会踩大坑——要么系统崩在重启后,要么出问题无法复盘,要么升级后旧数据拖垮新系统。
二、我一开始的误解:Memory ≈ 给 LLM 用的上下文?
这不是我一个人的误区,是行业里80%做Agent开发的同学,都会踩的坑——毕竟很多Agent框架讲Memory,核心就围着“LLM”转。
很多框架聊Memory,关注点永远是这三点:
-
记住用户的偏好(比如用户喜欢简洁回复)
-
记住历史对话内容(避免重复提问)
-
让下次回答更“聪明”(贴合用户习惯)
但 OpenClaw 的 Workspace / Memory,关注点根本不在这里。它不关心LLM“记不记得”,只关心系统“稳不稳、可不可管”——这就是Demo开发和工程开发的核心区别。
三、工程系统真正关心的 3 个问题(无关LLM,只关运维)
脱离Demo,站在生产工程视角,Memory(以及Workspace)首先要回答的不是“Agent聪不聪明”,而是这三个实打实的运维问题——答不上来,系统就不敢长期跑。
1️⃣ 系统挂了,能不能恢复?
生产环境里,没有永远不挂的服务,常见场景比比皆是:
-
Runtime 执行到一半中断(比如资源耗尽被Kill)
-
服务进程重启(部署升级、机器重启)
-
Gateway 迁移(集群扩容、节点切换)
核心问题:**中断前的执行状态、已完成的操作、未处理的任务,还能不能完整找回来?**能不能接着跑,而不是从头再来?
2️⃣ 出问题时,能不能复盘?
生产系统最怕“出问题查不到原因”,Agent执行尤其如此——毕竟它是动态调用Tool、执行策略的,出问题可能是Tool报错,可能是Policy生效异常,也可能是Runtime调度问题。
核心问题:有没有完整的执行痕迹? 比如:
-
这个Tool是谁触发的?触发时的权限、参数是什么?
-
当时的系统状态、策略配置是什么?为什么会走这个执行分支?
-
Policy是否生效?如果没生效,是配置问题还是执行问题?
3️⃣ 系统升级后,旧状态还认不认?
Agent系统不是一成不变的,后期一定会迭代升级:
-
Skill升级(新增功能、修改执行逻辑)
-
Policy升级(调整权限、限流规则、路由策略)
-
Runtime行为升级(优化隔离机制、异常处理逻辑)
核心问题:升级前的旧状态、旧数据,会不会和新系统不兼容? 会不会导致新系统启动失败、执行异常,把新系统拖死?
这三个问题,才是 Workspace / Memory 在 OpenClaw 里的核心使命——和LLM的“记忆力”无关,只和系统的“可运维性”强相关。
四、先把概念钉死:Workspace ≠ Memory(工程语义别搞混)
在OpenClaw的工程设计里,这两个词经常一起出现,甚至在配置里会关联,但它们的职责完全不同——搞混了,后期设计和运维都会乱。
1️⃣ Workspace:系统级持久化容器(存所有“家底”)
不用搞复杂定义,用工程人的话来说,你可以把 Workspace 理解为:
“Agent 系统的工程工作目录”
它是系统级的、长期存在的,负责承载所有需要持久化的状态和数据,相当于系统的“家底”,只要系统在,它就一直在(除非手动清理过期数据)。具体包括:
-
Session 状态(当前会话的配置、状态、关联用户)
-
Run 的执行结果(每一次Agent执行的完整记录,成功/失败/中断)
-
Tool 的调用痕迹(参数、返回值、错误信息、调用时间)
-
中间产物(执行过程中生成的临时数据、计算结果、中间文件)
-
Skill / Policy 绑定信息(当前Session、Run 绑定的Skill版本、Policy版本)
2️⃣ Memory:被 Runtime 使用的状态子集(用什么拿什么)
Memory 不是独立存在的,它只是 Workspace 中的一部分,是“按需提取”的子集——核心特点是“为Runtime服务、为执行服务”,具体来说:
-
会被装配进 Runtime 上下文(供Runtime调度、执行时使用)
-
会参与 LLM 推理(仅提取和当前执行相关的部分,不是全量)
-
会被裁剪、压缩、摘要(避免冗余,控制成本和执行效率)
一句话总结,好记不混淆:
Workspace 是“存什么”(系统的全部家底),Memory 是“用什么”(Runtime执行时,从家底里拿出来用的那部分)。
五、为什么 OpenClaw 要把 Workspace 单独拎成一层?
原因很简单,简单到很多框架都忽略了,但却是生产级系统的刚需——分离“短命的执行”和“长命的状态”。
1️⃣ Runtime 是短命的,Workspace 是长命的
在 OpenClaw 的设计里,有一个明确的边界:
-
Run 是一次性执行(一次Agent调用,执行完就结束)
-
Runtime 不保证长期存在(执行完就释放资源,异常时会被销毁,重启后就清零)
但 Workspace 完全相反:
-
跨 Run(多次执行的状态,都存在同一个Workspace里)
-
跨进程(即使进程重启、迁移,Workspace的数据也能被读取)
-
跨版本(系统升级后,旧版本的Workspace数据能被新版本兼容读取)
说白了,Workspace 就是系统的“时间轴”——记录着系统从启动到现在的所有关键状态,不管执行层怎么变,只要时间轴还在,系统就能稳定运行、追溯历史。
2️⃣ 不持久化,工程系统一定会变成“不可运维”
很多新手做Agent系统,只关注“能跑通”,把所有状态都存在Runtime内存里——这在Demo里没问题,但在生产环境里,就是灾难。
如果你只依赖 Runtime 内存,一定会遇到这三个无解问题:
-
出问题无法复现(内存清零,没有任何痕迹,查不到原因)
-
重启就是“失忆”(进程一重启,所有执行状态、历史记录全丢,用户体验崩了)
-
Debug 全靠猜(没有持久化数据,只能靠日志瞎猜,效率极低)
老师傅一句话总结,记好:
凡是靠“现在还记得”的系统,都不配叫工程系统——工程系统要的是“即使忘了,也能找回来”。
六、Workspace 里通常会存什么?(工程级拆解,直接参考落地)
结合 OpenClaw 的整体架构,以及我实际落地的经验,一个成熟的 Workspace 至少包含以下5类数据——少一类,后期都可能出问题,直接给大家拆透,不用自己瞎猜。
1️⃣ Session 状态快照(核心中的核心)
Session 是用户和系统交互的入口,它的状态快照必须持久化,否则会话中断后无法恢复。具体包含:
-
当前 session id(唯一标识,关联所有相关操作)
-
最近一次交互(交互时间、交互内容、触发方式)
-
当前状态(空闲 / 执行中 / 挂起 / 异常)
-
关联配置(当前Session绑定的用户、权限、Policy、Skill集合)
核心用途:恢复执行、判断是否可并发(避免同一Session同时执行多个Run)、防止重复Run。
2️⃣ Run 级执行记录(审计和复盘的关键)
这是 Workspace 里极其重要的一块数据——所有Agent执行的“总账”,没有它,出问题就无法追责、无法优化。通常包括:
-
Run id(唯一标识,和Session id关联)
-
触发来源(哪个入口触发、触发人、触发时间,是手动调用还是cron调度、CLI调用)
-
使用的 Agent 规格(Agent版本、配置参数、隔离级别)
-
执行时间(开始时间、结束时间/中断时间,耗时)
-
执行结果(成功 / 失败 / 中断,失败/中断原因)
核心用途:审计(谁在什么时间做了什么操作)、追责(出问题是谁的配置/操作问题)、工程分析(统计执行成功率、耗时,优化系统)。
3️⃣ Tool 调用痕迹(排查执行异常的核心)
很多人会忽略这一点——只存Tool的执行结果,不存调用痕迹,后期排查Tool相关的异常时,会寸步难行。真正的工程级设计,要存的是“全链路痕迹”,不是只有“结果”:
-
调用参数(传入Tool的所有参数,包括隐式参数、上下文参数)
-
返回值(Tool返回的完整结果,包括正常返回和异常返回)
-
错误信息(如果调用失败,完整的错误栈、错误码、错误描述)
-
Policy 命中情况(是否命中限流、权限控制,命中的Policy规则是什么)
核心用途:解释“系统为什么会做这一步”,排查Tool调用异常、Policy生效异常——比如用户问“为什么Tool没返回结果”,查这里就能一目了然。
4️⃣ 中间产物与派生数据(避免重复计算,支撑恢复执行)
Agent执行过程中,会产生很多中间数据——这些数据不一定需要给LLM用(不一定进Memory),但必须进入Workspace,原因很简单:避免重复计算,支撑恢复执行。
常见的中间产物包括:
-
扫描结果(比如文件扫描、接口扫描的中间数据)
-
计算中间值(比如多步骤执行中的临时计算结果)
-
已生成但未使用的数据(比如生成的临时文件、未提交的接口请求参数)
重点提醒:这些内容不一定进入Memory(不需要给LLM推理用),但必须进入Workspace——否则执行中断后,需要重新计算这些数据,耗时耗资源,甚至无法恢复。
5️⃣ Skill / Policy 绑定信息(版本兼容的关键)
这是很多系统会忽略的点,也是系统升级后出现兼容问题的核心原因——你必须知道,每一条数据、每一次执行,都是在哪个版本的Skill、Policy下产生的。
具体要存的信息:
-
该执行/数据对应的 Skill 版本(包括依赖的子Skill版本)
-
该执行/数据对应的 Policy 版本(包括权限、限流、路由等所有规则版本)
-
版本关联关系(哪个Session、哪个Run,绑定了哪个版本的Skill/Policy)
核心用途:系统升级后,旧数据能被正确解析——比如Skill升级后,旧版本的执行结果,能对应到旧版本的Skill逻辑,不会因为新版本Skill的逻辑变化,导致旧数据失效、系统报错。否则,系统一升级,旧数据就会变成“定时炸弹”。
七、Memory 为什么必须是“可裁剪的”?(新手最容易踩的坑)
聊完Workspace,再回到Memory——新手最容易犯的一个错误,就是“贪多”:
“既然是记忆,那就多存一点,存得越多,Agent越聪明。”
这是典型的Demo思维,不是工程思维——在生产环境里,这种想法一定会导致系统失控。
1️⃣ 工程事实只有一个:
Memory 如果不敢删,系统一定会失控。
原因很现实,没有半点玄学,全是工程里的实际问题:
-
token 成本:存得越多,传给LLM的上下文越长,token消耗越高,执行效率越低——长期运行,成本会翻倍。
-
行为漂移:冗余的历史数据会干扰LLM的推理,导致Agent行为偏离预期(比如记住了无关的历史,执行了错误的操作)。
-
历史噪音:过时的状态、无效的记录,会增加Runtime的处理成本,甚至导致Runtime解析异常,拖慢整个系统。
2️⃣ Runtime 对 Memory 的真实操作方式(OpenClaw 工程实践)
在 OpenClaw 的设计中,Runtime 不会把Workspace里的所有数据都放进Memory——它对Memory只做三件事,每一件都围绕“工程效率”和“系统稳定”:
-
选择性装配:不是Workspace里的所有数据都给LLM、给Runtime用,只提取“当前执行必须的部分”——比如当前Run需要的Tool调用记录、Session状态,无关的历史数据一律不装。
-
摘要与压缩:对于必须保留的长历史数据(比如多次交互记录),不会直接存储原始内容,而是做结构化摘要——比如把10条交互记录,摘要成1条核心信息,既保留关键内容,又控制体积。
-
阶段性淘汰:按照“有用性”淘汰旧状态——比如执行完成后,只保留“执行结果”相关的部分,中间的临时状态全部淘汰;或者超过一定时间的历史数据,自动淘汰,只留“对后续执行有价值的部分”。
最后再强调一句:Memory 是运行时视角的状态投影,是“按需提取、按需裁剪”的,不是历史档案——历史档案,交给Workspace来存就好。
八、Workspace 设计中最容易踩的 3 个坑(避坑指南)
结合我落地OpenClaw的经验,这3个坑,新手几乎必踩,老师傅也偶尔翻车——记好,能少走很多弯路。
坑 1:Workspace = 日志
绝对不行,两者的定位天差地别。
日志是“只写不改”的流水账,核心用途是“追溯历史、排查异常”,不能支撑状态恢复、不能支撑版本兼容;而 Workspace 是“动态的状态模型”,既要存数据,还要支撑状态变更、执行恢复、版本关联——它是“活的”,日志是“死的”。
举个例子:日志能记录“某个Run执行失败”,但Workspace能恢复这个Run的状态,让它接着执行——日志做不到这一点。
坑 2:Memory = 全历史对话
绝对不行,这叫“上下文垃圾场”。
全历史对话里,有大量无关信息、过时信息——把这些都放进Memory,只会增加token成本、导致行为漂移,对当前执行没有任何价值。
正确的做法:Memory 只放“当前执行必须的状态和数据”,无关的历史对话,交给Workspace存储,不需要进入Memory。
坑 3:版本演进不考虑兼容
这是最隐蔽、最致命的坑——很多人设计Workspace时,不考虑版本问题,认为“存数据就行”,但系统一定会升级,Skill、Policy、Runtime都会变。
如果Workspace没有版本意识,不记录每一条数据对应的Skill/Policy版本,那么系统升级后,旧数据就无法被新系统正确解析——要么报错,要么执行异常,最后只能删数据,得不偿失。
避坑关键:从设计初期,就给Workspace加上“版本关联”,每一条数据、每一次执行,都绑定对应的版本信息。
九、这一层和前后两层是如何配合的?(放回架构,看懂全局)
把Workspace / Memory 放回OpenClaw的四层架构里,不用复杂的流程图,一句话就能看懂它和前后两层的配合——逻辑清晰,不用记复杂的调用关系。
-
Gateway(第二层,控制平面):决定 Run 是否发生(管入口、权限、调度),同时会把Run的触发信息、Policy配置,同步到Workspace,供后续审计和恢复。
-
Agent Runtime(第三层,执行平面):决定 Run 如何执行(管隔离、Tool调用、异常处理),执行过程中,会从Workspace提取需要的状态(装配成Memory),执行完成后,再把执行记录、中间产物,回写到Workspace。
-
Workspace / Memory(第四层,持久化层):不参与执行,不参与调度,只负责“存状态、供恢复、供审计”——决定系统是否“活得久、活得稳”,是否可运维、可演进。
最后用一句话串起来,好记不混淆:
Gateway 管入口,Runtime 管执行,Workspace 管时间。
十、小结:这一层为什么是“工程分水岭”
很多Agent系统,Demo做得很炫,功能很全,测试环境跑得飞起,但一放到生产环境,就不敢跑一个月——不是LLM不行,不是Tool不行,而是没有一个真正站得住的持久化骨架。
很多人做Agent,只关注“能不能跑通一次执行”,却忽略了“能不能长期稳定运行”——这就是Demo开发和工程开发的核心区别,而Workspace / Memory,就是这个区别的“分水岭”。
OpenClaw 把 Workspace / Memory 明确拆成独立一层,本质上不是多此一举,而是在告诉你一个工程真相:
Agent 不是一次对话,不是一个Demo,而是一段可以被回放、被升级、被审计的系统行为——而Workspace / Memory,就是支撑这段行为的核心骨架。
下一篇:从“状态”走向“能力边界”
拆解完OpenClaw的四层系统层(入口、Gateway、Runtime、Workspace/Memory),接下来,我们就要跳出“系统层”,进入能力层了。
👉 Skill:能力声明与能力实现,为什么必须分离?
这一篇,我们会聊透OpenClaw的能力层核心——为什么Skill要分“声明”和“实现”,分离之后,能解决工程落地中的哪些痛点,以及如何设计可复用、可升级的Skill。
如果你已经把前四层吃透,你已经站在一个远超大多数从业者的高度,看懂了Agent系统的底层逻辑——它从来不是“对话工具”,而是可运维、可演进的生产级系统。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)