【Datawhale组队学习202602】Hello-Agents task02 智能体发展史
本文探讨了智能体的演进历程,从符号主义时代的早期智能体到现代基于大语言模型的智能体。文章首先介绍了物理符号系统假说和专家系统的工作原理,分析了符号主义智能体在知识获取和灵活性方面的局限性。随后阐述了马文·明斯基的心智社会理论,以及联结主义学习范式如何通过神经网络解决符号主义的瓶颈问题。最后对比了不同时代智能体技术的差异,并通过"智能代码审查助手"的案例展示了智能体技术的演进过程
系列文章目录
- task00 环境配置+前言
- task01 初识智能体
- task02 智能体发展史
- task03 大语言模型基础
- task04 智能体经典范式构建
- task05 基于低代码平台的智能体搭建
- task06 框架应用开发实战
文章目录
前言
一、智能体的演进阶梯
只有深刻理解现代智能体为何呈现出如今的形态,以及其核心设计思想的由来,才能更好的理解现代智能体。
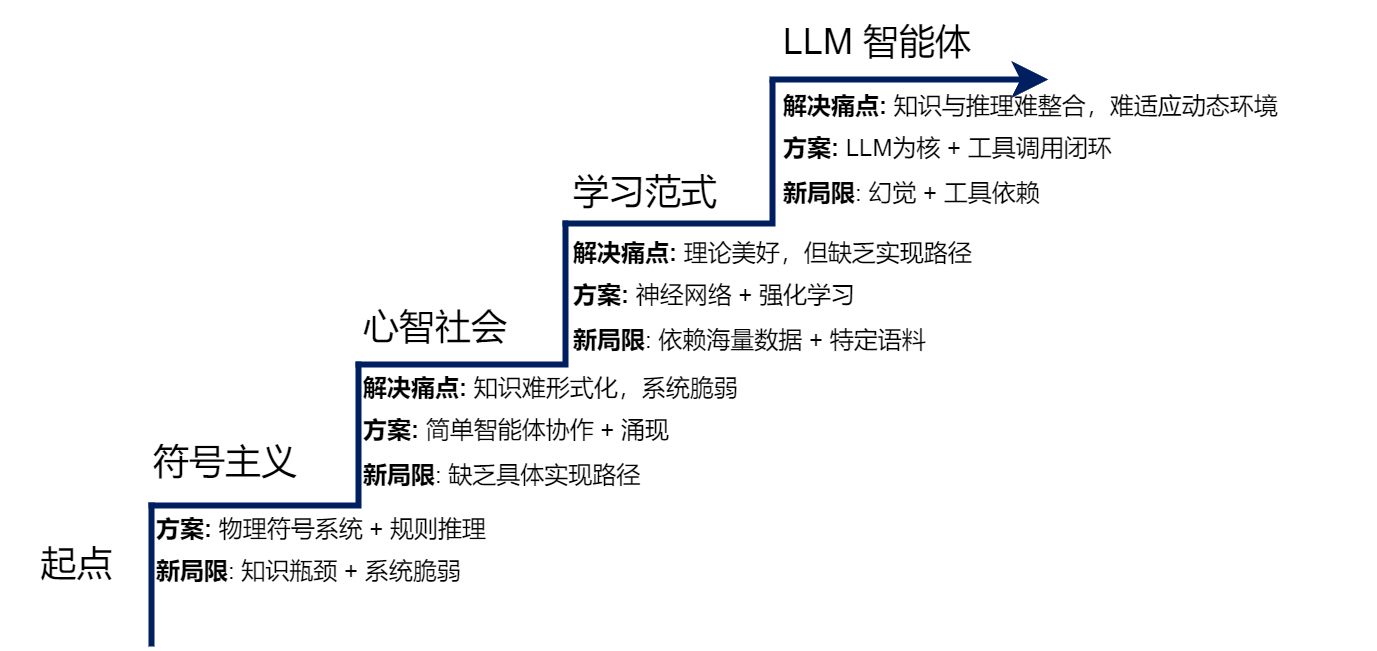
- 演进方向:每一个新范式的出现,都是为了解决上一代范式的核心“痛点”或根本局限。而新的解决方案在带来能力飞跃的同时,也引入了新的、在当时难以克服的“局限”,而这又为下一代范式的诞生埋下了伏笔。
二、 基于符号与逻辑的早期智能体
人工智能领域的早期探索,深受数理逻辑和计算机科学基本原理的影响。
- 符号主义(Symbolicism),也被称为“逻辑AI”或“传统AI”。
- 核心思想:智能行为的核心是基于一套明确规则对符号进行操作。
- 因此,一个智能体可以被视为一个物理符号系统:它通过内部的符号来表示外部世界,并通过逻辑推理来规划行动。这个时代的智能体,其“智慧”完全来源于设计者 预先编码的知识库和推理规则。
2.1 物理符号系统假说
符号主义时代的理论根据,是1976年由艾伦·纽厄尔(Allen Newell)和赫伯特·西蒙(Herbert A. Simon)共同提出的物理符号系统假说(PhysicalSymbol SystemHypothesis, PSSH)。
- 该假说包含两个核心论断:
- 充分性论断:任何一个物理符号系统,都具备产生通用智能行为的充分手段。
- 必要性论断:任何一个能够展现通用智能行为的系统,其本质必然是一个物理符号系统。
2.2 专家系统
在物理符号系统假说的直接影响下,专家系统(Expert System)成为符号主义时代最重要、最成功的应用成果。
-
专家系统的核心目标,是模拟人类专家在特定领域内解决问题的能力。它通过将专家的知识和经验编码成计算机程序,使其能够在面对相似问题时,给出媲美甚至超越人类专家的结论或建议。
-
典型专家系统的核心部分构成:
- 知识库
- 推理机
- 用户界面
-
专家系统的“智能”主要源于其两大核心组件:知识库和推理机。
-
知识库(Knowledge Base):专家系统的知识存储中心,存放领域专家的知识和经验。知识表示(Knowledge Representation)是构建知识库的关键。在专家系统中,最常用的一种知识表示方法是产生式规则(Production Rules),即一系列“IF-THEN”形式的条件语句。例如:IF 病人有发烧症状 AND 咳嗽 THEN 可能患有呼吸道感染。这些规则将特定情境(IF部分,条件)与相应的结论或行动(THEN部分,结论)关联起来。一个复杂的专家系统可能包含成百上千条这样的规则,共同构成一个庞大的知识网络。
-
推理机(Inference Engine):推理机是专家系统的核心计算引擎。它是一个通用的程序,其任务是根据用户提供的事实,在知识库中寻找并应用相关的规则,从而推导出新的结论。推理机的工作方式主要有两种:
正向链(Forward Chaining):从已知事实出发,不断匹配规则的IF部分,触发THEN部分的结论,并将新结论加入事实库,直到最终推导出目标或无新规则可匹配。这是一种“数据驱动”的推理方式。
反向链(Backward Chaining):从一个假设的目标(比如“病人是否患有肺炎”)出发,寻找能够推导出该目标的规则,然后将该规则的IF部分作为新的子目标,如此递归下去,直到所有子目标都能被已知事实所证明。这是一种“目标驱动”的推理方式。
三、 马文·明斯基的心智社会
四、 学习范式的演进与现代智能体
如果智能无法被完全设计,那么它是否可以被学习出来?
- 作为对符号主义局限性的直接回应,联结主义(Connectionism) 在20世纪80年代重新兴起。
- 联结主义是一种自下而上的方法,其灵感来源于对生物大脑神经网络结构的模仿[8]。它的核心思想可以概括为以下几点:
知识的分布式表示:知识并非以明确的符号或规则形式存储在某个知识库中,而是以连接权重的形式,分布式地存储在大量简单的处理单元(即人工神经元)的连接之间。整个网络的连接模式本身就构成了知识。
简单的处理单元:每个神经元只执行非常简单的计算,如接收来自其他神经元的加权输入,通过一个激活函数进行处理,然后将结果输出给下一个神经元。
通过学习调整权重:系统的智能并非来自于设计者预先编写的复杂程序,而是来自于“学习”过程。系统通过接触大量样本,根据某种学习算法(如反向传播算法)自动、迭代地调整神经元之间的连接权重,从而使得整个网络的输出逐渐接近期望的目标。
4.1 从符号到联结
习题
- 物理符号系统假说是符号主义时代的理论基石。请分析:
- 该假说的"充分性论断"和"必要性论断"分别是什么含义?
- 结合本章内容,说明符号主义智能体在实践中遇到的哪些问题对该假说的"充分性"提出了挑战?
- 大语言模型驱动的智能体是否符合物理符号系统假说?
答:
- 充分性论断说明了
- 遇到问题有知识瓶颈,常识性知识无法显式规则,图像、声音等无法学习,不够灵活自主,存储和计算需求量爆炸。
- 符合又不符合,最不符合的就是大模型内部深度神经网络的黑盒机制。
专家系统MYCIN[2]在医疗诊断领域取得了显著成功,但最终并未大规模应用于临床实践。请思考:
提示:可以从技术、伦理、法律、用户接受度等多个角度分析
除了本章提到的"知识获取瓶颈"和"脆弱性",还有哪些因素可能阻碍了专家系统在医疗等高风险领域的应用?
如果让现在的你设计一个医疗诊断智能体,你会如何设计系统来克服MYCIN的局限?
在哪些垂直领域中,基于规则的专家系统至今仍然是比深度学习更好的选择?请举例说明。
在2.2节中,我们实现了一个简化版的ELIZA聊天机器人。请在此基础上进行扩展实践:
提示:这是一道动手实践题,建议实际编写代码
为ELIZA添加3-5条新的规则,使其能够处理更多样化的对话场景(如谈论工作、学习、爱好等)
实现一个简单的"上下文记忆"功能:让ELIZA能够记住用户在对话中提到的关键信息(如姓名、年龄、职业),并在后续对话中引用
对比你扩展后的ELIZA与ChatGPT,列举至少3个维度上存在的本质差异
为什么基于规则的方法在处理开放域对话时会遇到"组合爆炸"问题并且难以扩展维护?能否使用数学的方法来说明?
马文·明斯基在"心智社会"理论[7]中提出了一个革命性的观点:智能源于大量简单智能体的协作,而非单一的完美系统。
在图2.6"搭建积木塔"的例子中,如果 GRASP 智能体突然失效了,整个系统会发生什么?这种去中心化架构的优势和劣势是什么?
将"心智社会"理论与现在的一些多智能体系统(如CAMEL-Workforce、MetaGPT、CrewAI)进行对比,它们之间存在哪些关联和不同之处?
马文·明斯基认为智能体可以是"无心"的简单过程,然而现在的大语言模型和智能体往往都拥有强大的推理能力。这是否意味着"心智社会"理论在大语言模型时代不再适用了?
强化学习与监督学习是两种不同的学习范式。请分析:
用AlphaGo的例子说明强化学习的"试错学习"机制是如何工作的
为什么强化学习特别适合序贯决策问题?它与监督学习在数据需求上有什么本质区别?
现在我们需要训练一个会玩超级马里奥游戏的智能体。如果分别使用监督学习和强化学习,各需要什么数据?哪种方法对于这个任务来说更合适?
在大语言模型的训练过程中,强化学习起到了什么关键性的作用?
预训练-微调范式是现代人工智能领域的重要突破。请深入思考:
为什么说预训练解决了符号主义时代的"知识获取瓶颈"问题?它们在知识表示方式上有什么本质区别?
预训练模型的知识绝大部分来自互联网数据,这可能带来哪些问题?如何缓解以上问题?
你认为"预训练-微调"范式是否可能会被某种新范式取代?或者它会长期存在?
假设你要设计一个"智能代码审查助手",它能够自动审查代码提交(Pull Request),概括代码的实现逻辑、检查代码质量、发现潜在BUG、提出改进建议。
如果在符号主义时代(1980年代)设计这个系统,你会如何实现?会遇到什么困难?
如果在没有大语言模型的深度学习时代(2015年左右),你会如何实现?
在当前的大语言模型和智能体的时代,你会如何设计这个智能体的架构?它应该包含哪些模块(参考图2.10)?
对比这三个时代的方案,说明智能体技术的演进如何使这个任务从"几乎不可能"变为"可行"
总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)