高通AI研发:拓展AI研究的边界
一起了解高通 AI 研发如何持续推进从边缘到云端的创新神经信息处理系统()大会是首屈一指的机器学习会议,今年以令人印象深刻的25%录用率回归。我们很高兴同与会者直接互动,展示我们的研究成果和演示项目。我们很荣幸有17篇论文(10篇主要会议论文和7篇研讨会论文)和9个技术演示项目在此次大会上被录用,我们的演示项目占EXPO演示项目总数的45%。2025年因生成式人工智能(GenAI)的显著进步而备受
一起了解高通 AI 研发如何持续推进从边缘到云端的创新

您应当了解的情况:
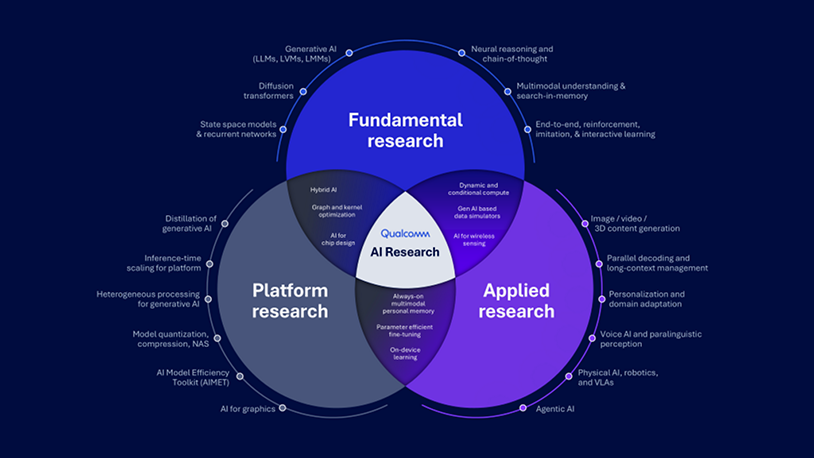
- 在高通AI研发 (Qualcomm AI Research),我们一直在推进AI的技术发展,使其各种核心功能 – 包括感知、推理和行动 – 能够广泛覆盖各种设备。
- 在一年一度的 NeurIPS 大会上,我们展示了前沿语言、视觉、多模态推理和基础机器学习(ML)研究方面的领导地位。
- 我们通过实际操作演示、研讨会和专题演讲,重点呈现创新的AI应用与技术,包括高效的生成式人工智能模型、低功耗计算机视觉、以及节能型神经网络。
神经信息处理系统(NeurIPS)大会是首屈一指的机器学习会议,今年以令人印象深刻的25%录用率回归。我们很高兴同与会者直接互动,展示我们的研究成果和演示项目。我们很荣幸有17篇论文(10篇主要会议论文和7篇研讨会论文)和9个技术演示项目在此次大会上被录用,我们的演示项目占EXPO演示项目总数的45%。
2025年因生成式人工智能(GenAI)的显著进步而备受瞩目,而高通技术公司正引领这一技术向边缘设备与云端的全面拓展。我们的Qualcomm AI Research致力于推动AI/机器学习的界限,并将这些创新成果转化为现实世界的应用场景。
用突破性的想法推进人工智能
在类似NeurIPS这样的著名学术会议上,具有突破性的论文是与更广泛的社区分享创新成果和有影响力的AI研究项目的重要渠道。我想重点推出一些得到录用的论文和正在推动机器学习边界拓展的关键主题。
在NeurIPS上,我们的团队展出了语言、多模态推理、图像/视频生成和机器学习基础方面等一系列不同的主题。这些研究方向共同反映了一个目标:确保AI系统更加高效、更值得信赖,并能够应对复杂的现实世界挑战。从速度更快的大模型到稳健的多模态搜索,从生成视觉的基准到循环神经网络(RNN)的理论进展,我们的工作涵盖了现代AI研究的多个领域。
下一代大语言模型
大模型(LLM)正在迅速演进并日益普及;因此我们一直在努力实现速度更快、效率更高、可靠性更强的大模型,并在各类设备上进行部署。OmniDraft:用于本地推测解码的跨词汇在线自适应起草器重新构想了推测性解码技术:通过引入可实时适配任意目标模型的通用生成器,实现技术突破。这一创新技术为本地AI实现了更快的响应、更低的成本和更大的灵活性,而实验表明速度提高了两倍。
在提升效率的基础上, KeyDiff:针对资源受限环境中的长上下文大语言模型推理、并基于键相似度的KV缓存收回解决了长时间对话占用大量内存的挑战。KeyDiff仅保留最独特的信息片段,而不是依赖于开销更高的注意力评分,从而确保各个模型能够处理更长的提示符词,以更快的速度运行,并使用更少的内存,同时几乎不会降低准确性。
面向大模型的扩散模型有望实现更快的生成速度,而我们的团队正在探索针对这种范式的上下文学习。掩码可能具有干扰性:论扩散语言模型中的上下文理解为训练目标如何影响归纳偏差提供了全新的见解。我们的研究结果表明,使用非自回归损失训练的扩散模型的表现与自回归模型相当,同时能够更快地进行推理。但是,这类模型仍然表现出近因偏差以及从最初到后续令牌符号从左到右进行处理的偏好,尽管这种偏好并不那么强烈,这表明扩散模型继承了一些归纳偏差,尽管它们的训练方法并不相同。
为了加强推理,直链思维,摒弃花哨:面向高效多跳检索增强生成的结构化推理重复使用常见的推理模式,并增加一个能够判定在何时收集到足够信息的智能“停止器”,从而推出了一种结构化的多跳推理方法,能够提供速度更快、成本更低、可靠性更强的复杂答案。
最后,分析和改进思维链可监控性研究了为何用于检测推理轨迹中偏见或有害内容的监控器常常失效。我们将信息缺口和诱导误差确定为关键问题,并提出了两种新的训练策略,其中一项策略奖励更清晰的推理痕迹,而另一项策略使用信息论将输出与推理结合起来,这两者都显著提高了监测的准确性和弹性。
总之,这些面向下一代大模型的AI研究论文展示了各种提高性能、效率、推理和可信度的技术。
多模态AI
AI系统越来越需要理解和连接文本、图像和视频并建立关联,而我们的工作推动了这一前沿领域的发展。广义对比学习(GCL):更好地搜索文本和图像推出了一种训练方法,允许各种模型在多种模态范围内实施一次性对比,从而实现更加通用的检索功能,同时无需专门的数据集。通过训练各种模型同时对齐文本和图像,广义对比学习为AI提供了一种更为通用的“检索能力”,使其能在各类不同内容间高效检索。
在此基础上,多模态大语言模型是否可以提供实时分步任务指导?通过高通交互式烹饪数据集 (Qualcomm Interactive Cooking dataset) 探索了交互式辅助功能,该数据集包含人们在遵照食谱进行烹饪过程中进行制作和纠正错误的视频。利用该数据集,我们测试了当前的多模态模型,并引入了一个旨在提供直播、流媒体指导的系统,这是向可以实时指导用户的AI迈出的第一步。
为了提高模型的感知能力和可信度,视觉语言模型中的注意力引导对齐针对视觉语言系统中的 “幻觉现象” 展开研究,并指出:图像区域和文本之间的不良对齐是根本原因,从而解决了视觉语言系统中的幻觉。我们的框架使用先进的分割工具引导人们注意正确的图像区域,从而产生更准确和更可信的描述。
为自动驾驶提炼多模态大语言模型将多模态方法扩展到自动驾驶中,提出了将多模态大模型的知识提炼成一种更轻便视觉性规划器的框架。该系统在保持效率的同时受益于更广泛的推理能力,在罕见的长尾场景中将轨迹误差减少了44%,并在主流基准测试中实现了最先进的性能。
最后,利用概率建模实现跨域强大端对端自动驾驶推出了一种框架,该框架制定了对自我和周围车辆信息进行编码的令牌联合概率分布情况。该框架基于高斯过程实现实例化,以通过涉及不同驾驶场景的相应轨迹学习基本token,从而能够实现对于新领域的强大适应性,并且在没有额外推理成本的情况下显著优于直接微调。
总的来说,这些AI研究论文展示了多模态AI改善搜索、引导、感知和自主决策的方式。
图像和视频生成
生成视觉和感知仍然是AI领域中最为困难的挑战之一,而我们的论文正直面这些问题。多人测试台:提高多人图像生成的标准提供了第一个用于评估模型如何能够创建多人逼真图像的专门基准,而其中每个人都有不同的面孔、姿势和动作。凭借数以千计的不同面孔和提示符,加上衡量身份、行动和对齐的指标,该基准为推进多人物图像生成设定了新标准。
为了推进生成式方法发展,快捷模型改进训练推出了一种统一的训练框架,解决了各种快捷模型的关键挑战,例如频率偏差和引导不一致。通过调节网络的当前噪声水平和期望的步长,快捷模型可以预测单个正推计算中的多个时间步长,从而显著加快生成过程。通过动态控制、小波损失和双EMA策略等创新技术,我们的框架使快捷模型重新获得竞争力,在一步和多步采样中提供更清晰、更可靠的图像生成。
ODG:更加智能的自动驾驶汽车三维场景理解将生成式视觉扩展到自动驾驶领域,提出了一种将驾驶场景分为静态和动态部分,从而更有效地捕捉建筑物等静止结构和汽车或行人等移动物体的双高斯方法。其结果是形成更清晰、更快速、更准确的三维预测,让自动驾驶系统对前方道路有更加清晰的认识。
总之,这些AI研究论文通过设定新基准、改进生成式训练和实现更智能的场景理解,推进了视觉AI的发展。
机器学习的基础
除了应用之外,我们的工作还加强了对于基础机器学习的研究,我们从理论的角度探索基本的限制条件或功能,以了解AI/机器学习的优点和缺点。基于最优传输的非交换性共形预测解决了存在测试数据与训练数据不同的分布移位问题。通过利用最优运输,我们的论文展示了如何在不确切知道数据如何变化的情况下估计和纠正不确定性,这使得模型在复杂的实际场景中,预测结果更具可靠性。
重新审视循环神经网络中的双线性状态转移重新思考了传统上被视为循环神经网络的递归神经网络的作用。通过重新审视双线性操作(其中输入和隐藏状态以相乘方式交互),我们已表明隐藏单元是主动的计算参与者。我们认为,隐藏单元天然适合需要跟踪演进状态的各项任务。通过我们的工作,甚至描绘出了有关复杂性的层次结构,将各种流行模型(例如:Mamba)置于更为简单的一端,从而为循环神经网络的实际思维方式提供了一个全新视角。
最后,延迟NMS攻击:这是真实世界还是只是幻想?研究了长期以来对计算机视觉系统中延迟攻击的担忧。使用我们的EVADE评估框架,我们证明了这些攻击在现实条件下几乎不会影响性能:性能下降不会跨模型传递,保持在可接受的范围内,并且很容易进行防御。简而言之,虽然它们在理论层面上看起来令人担忧,但NMS延迟攻击并不是现实世界的威胁。
综上,这些 AI 研究论文共同推动了机器学习(ML)基础领域的发展:它们让预测结果更鲁棒,为循环神经网络(RNN)研究提供了全新理论见解,并厘清了对抗性攻击(adversarial attacks)的真实风险。
我们的论文强调了AI未来的广阔愿景:速度更快、效率更高、能够在各种模态下进行推理、基于可信赖的感知、并建立在坚实理论基础上的系统。我们的工作解决了从长上下文记忆到多模态搜索,从生成式视觉基准到分布转移的挑战,从而有助于构建不仅强大而且实用可靠的AI。
总之,这些AI研究论文实现了更为稳健的预测,为循环神经网络 (RNN) 提供了全新理论见解,并澄清了对抗性攻击的真正风险,从而加固了机器学习的基础。
有关前沿领域的EXPO讲座和研讨会
我们的讲座《嵌入式AI的最新发展》探讨了现实世界的互动如何给AI系统带来独特挑战,因为AI系统天然需要对物理世界和/或其居民具有深刻的理解。该讲座深入讨论嵌入式AI,重点关注基于多模态大语言模型的最新进展,解释了端到端训练如何实现将现实世界常识的关键方面灌输到模型中,从而开启了诸如通才机器人控制和现实世界视觉交互(例如:能看能听的聊天机器人)等新颖应用。
我们的研讨会《大规模真实世界物理AI系统》涵盖了该领域领导者在物理AI工业研究中的最新研究和最佳实践。研讨会还探讨了物理 AI 方向的前沿技术,例如基于 VLA 的基础模型、AI 数据飞轮(AI data flywheel)以及跨具身学习(cross-embodiment learning)。
生成式AI正在从离线、单模态模型演变为在现实世界中感知、决策和行动的交互式智能体系统。我们的另一次研讨会《AI助理在野外:代理、自适应、和记忆增强部署》探讨了我们如何建立不仅具有高效性和响应性,而且能够随时间推移、在个人记忆的基础上进行积累、回忆和自适应的生成式智能体。该生成式智能体旨在汇集来自生成式建模、代理学习、高效模型设计和记忆系统的观点,以缩小实验室规模原型和现实世界部署之间的差距。
先进技术展示描绘了未来的景象
对我们来说,在一个互动环境中提供实时、真实的演示,以补充我们的前沿研究出版物具有很高的重要性。我们展示了自身对于AI的研究,包括本地生成式AI、全栈AI优化、全新AI应用、和高效AI推理方面的示例。我们的EXPO演示项目,可分类为平台优化、图像生成和高级推理:
平台优化演示
- 移动视频扩散转换器:用于文本/图像到视频生成的扩散转换器(DiTs)由于对数千个视频令牌的二次注意力而需要巨大的内存和计算成本。我们演示了首个在移动设备(例如:手机和笔记本电脑)中的低功耗NPU上运行的扩散转换器。通过全栈AI优化,我们的实现在搭载第5代骁龙8至尊版平台的手机上,利用高通Hexagon NPU在8秒内生成了分辨率为1024x640的48帧视频。
- 用于AI加速器的分解大语言模型:大语言模型推理通常分为两个不同的阶段:预填充和解码。预填充阶段是计算边界,而解码阶段是存储边界。该演示项目展示了高通Cloud AI 100 Ultra卡上的分解服务,这是一种节能型AI推理加速器,可以在第一令牌(TTFT)和整体吞吐量方面提供显著改进。
- 采用本地验证的并行生成:直接在本地有效生成和验证大语言模型的多个响应是一项主要挑战。我们的方案利用了多流执行图和并行大语言模型生成,在一个统一框架内为联合生成和验证实现了测试时间缩放的优势,从而解决了这一问题。通过在搭载第5代骁龙8至尊版平台的手机上运行,这种方法减少了内存迁移,最大限度地减少了延迟,并优化了高质量响应的选择。其结果是更有效、更安全、更具个性化的本地大语言模型推理,从而使先进的AI功能更接近日常使用。
- 利用异构计算的AI模型进行高效激光雷达处理:AI模型的高效处理具有挑战性。本演示项目展示了在骁龙平台上运行的激光雷达模型如何执行异构计算。激光雷达处理,特别是三维稀疏卷积(SpConv3D)网络,在高通Adreno GPU上运行,而区域提议网络(RPN)则在Hexagon NPU上执行。这种在各种专用平台之间进行的任务划分减少了本地推断延迟,并最大限度地提高了整体效率。
图像生成演示
- 通过文本和参考图像生成多人合影:基于参考的多人图像生成正在成为个性化、合成数据创建和基准生成模型的重要功能。现有模型往往不能保留身份或保持空间保真度,这限制了它们对现实世界场景的适用性,如社交内容创建或训练视觉系统。为应对这些挑战,我们的演示项目展示了一种可以在上下文中生成所有参与者高质量图像的最先进系统。
- SwiftEdit:通过移动设备上的一步扩散实现快速文本引导图像编辑:由于涉及成本高昂的多步反演和采样过程,现有的文本引导图像编辑方法无法满足现实世界和本地应用程序所需要的速度需求。我们的演示项目展示了本公司的一步扩散图像编辑模型SwiftEdit,该模型在文本提示符的基础上,以交互方式编辑用户的源图像。
多模态和推理演示
- 用于视频监控的多模态AI取证搜索:视频监控通常需要在多个摄像头上筛选数小时的镜头,以找到特定目标或事件。为了应对这一挑战,我们引入了多模态 AI 取证搜索框架ForeSea,可结合文本和图像支持丰富的多模式查询,并返回带有时间戳的关键事件。在本公司全新AI Forensic QA基准测试的基础上,ForeSea取得了显著的提升,与强大的基准模型相比,准确率提高了8.6%,交并比提高了6.9%。
- 有关端侧内容审核的软提示:当收到有害提示时,大模型有时会生成不安全或有毒输出。通过我们提出的TV DiSP框架,我们展示了第一个使用高效软提示提炼的安全对齐大语言模型无缝本地集成。通过此项设计,可确保移动设备能够运行配备了学习软提示的量化大语言模型,以实时审核有害内容,同时最低限度地增加推理成本。结果是安全性提高了15%以上,证明了先进的安全对齐技术在端侧 AI 中既能落地实用,又能保持轻量化特性。
- 通过多模态端到端决策转换器网络和视觉语言动作(VLA)模型进行推理:涉及弱势道路使用者和道路上其他参与者的复杂自动驾驶用例可能具有挑战性,特别是对于模块化AI方法。该演示项目展示了用于路径规划场景的边缘集成端到端视觉语言动作模型所具有的实时输出和可视化功能。利用原始多模态传感器输入(包括视觉和语音数据),视觉语言动作模型可以实时处理信息,生成安全、可解释且可重复的驾驶轨迹。
在我们的展位提供更多的演示和讲座
除了我们的EXPO演示项目外,我们举办了有关各种研究主题的其他演示项目,分类为:高效大模型和推理,多模态AI,视觉内容生成,汽车AI,计算机视觉,扩展现实AI,云端AI等。
例如,高效大模型和推理演示包括:在手机上以每秒超过200个令牌的速度运行一个3B参数模型,利用动态预算来减少推理令牌,以及具有验证功能的并行推理。我们的生成式和多模态AI演示包括具有负面提示符、能够以30倍的速度提供高保真图像的一步文本到图像扩散模型,用于边缘部署的紧凑语言视觉模型,以及通过智能眼镜提供的个性化健身辅助。
我们的计算机视觉演示包括手机上的开放词汇目标检测,下一代用户界面的人类行为分析,高质量的交通场景模拟,以及在搭载骁龙平台的设备上的三维高斯泼溅。
在高通技术公司,我们率先实现了突破性研究,并将其影响扩展到各种设备和行业,使我们的愿景能够推动无处不在的智能计算。高通AI研发与公司其他部门密切合作,将尖端的AI技术无缝集成到我们的产品中。这一合作加速了从实验室研究到现实应用的转变,通过创新的AI解决方案丰富了我们的生活。
在所发布内容中表达的观点仅为原作者的个人观点,并不代表高通技术公司或其子公司(以下简称为“高通技术公司”)的观点。所提供的内容仅供参考之用,而并不意味着高通技术公司或任何其他方的赞同或表述。本网站同样可以提供非高通技术公司网站和资源的链接或参考。高通技术公司对于可能通过本网站引用、访问、或链接的任何非高通技术公司网站或第三方资源并没有做出任何类型的任何声明、保证、或其他承诺。
骁龙和高通品牌产品均为高通技术公司和/或其子公司的产品。高通专利由高通公司授权。高通AI研究院是高通技术公司的一项倡议。
关于作者
法提赫·波里克利,高通技术公司技术副总裁

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

{kind=link}
所有评论(0)