
别只盯着deepseek了,这个大模型本地化部署成本仅deepseek的1/3
很多企业或者个人都想在本地部署一套大模型来满足一些特殊场景的需求,在过去,因为deepseek表现出的卓越性能,使得其成为大部分企业或者个人本地化部署的首选。此外,由于deepseek对外完全开源,也就是我们部署到本地无需给deepseek公司支付任何费用,甚至使用deepseek进行任何商业行为,deepseek公司也不会来管你。这就给特别多人带来一个很大的误区,以为可以使用很低的成本就可以部署

很多企业或者个人都想在本地部署一套大模型来满足一些特殊场景的需求,在过去,因为deepseek表现出的卓越性能,使得其成为大部分企业或者个人本地化部署的首选。
此外,由于deepseek对外完全开源,也就是我们部署到本地无需给deepseek公司支付任何费用,甚至使用deepseek进行任何商业行为,deepseek公司也不会来管你。
这就给特别多人带来一个很大的误区,以为可以使用很低的成本就可以部署deepseek到本地,其实不然。

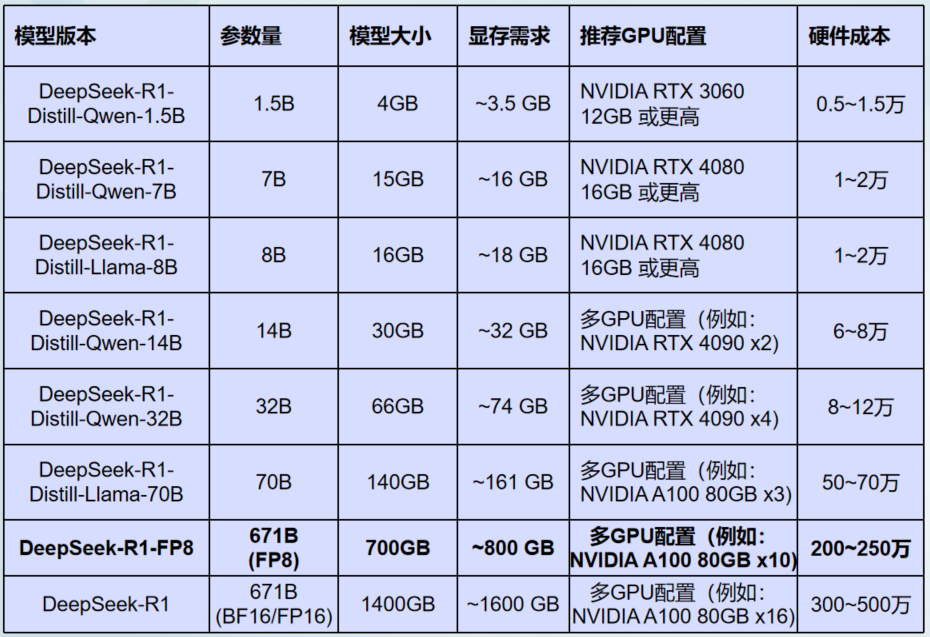
deepseek在社区有不同的蒸馏版本,其部署时对硬件要求各不一样,我们常常见到的deepseek r1满血版本即671B版本,真正要实现本地化部署,其硬件成本需求往往要超过百万。
下面这个表就是deepseek不同版本的硬件需求以及对应的大致成本。
其实,我们在大模型本地化部署时,可以不只盯着deepseek,下面我们就来聊聊五一节前阿里重磅发布的Qwen3系列开源大模型。
首先,我们可以通过通义官方发表的这张长图来了解Qwen3大模型的能力。


Qwen3采用的是创新的MOE(混合专家)架构,融合了推理和非推理能力,在推理、工具调用、指令遵循和多语言能力等方面都表现优异。
跟deepseek的深度思考能力有所不同,deepseek关闭深度思考其实就从R1变成了V3,而Qwen3则模型本身并没有改变。
这种架构的大模型在国内,Qwen3可以算首发。
本次Qwen3发布带来了从0.6B到235B不同系列共计8个版本的大模型,其中两款适合复杂任务的MOE架构的Qwen3-30B-A3B和Qwen3-235B-A22B性能表现均相当优秀。
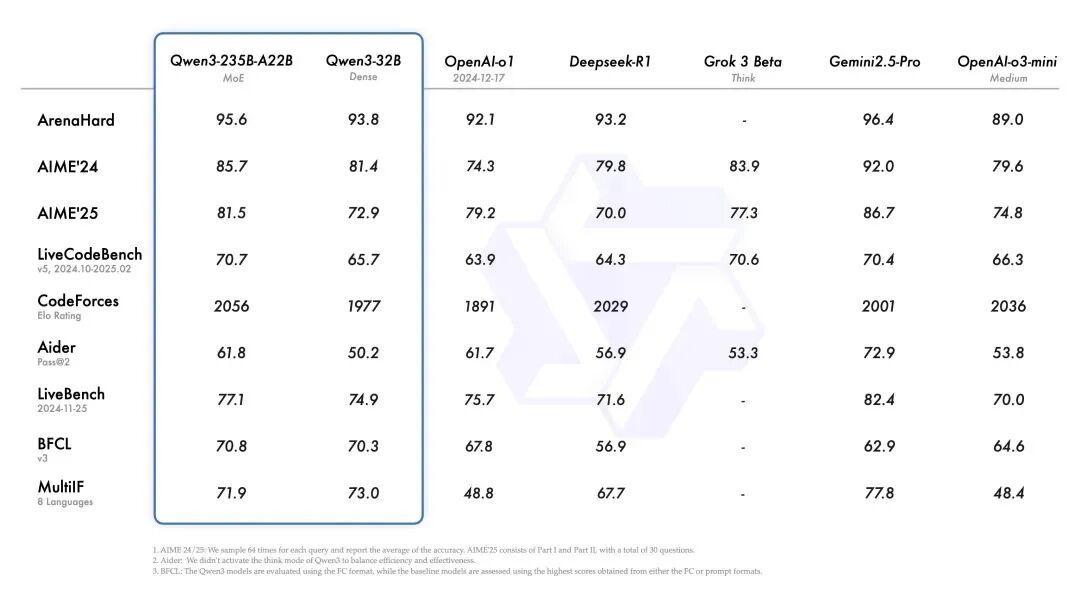
非常值得一提的是,整体性能与deepseek不相上下的同时,其对硬件需求却比deepseek低很多。
旗舰模型Qwen3-235B-A22B其部署成本仅为deepseek R1的35%,最低只需要4张H20就可以正常运行,部署量化后的版本仅需8张4090卡或者2张H20卡即可。
比Qwen3-235B-A22B稍逊一筹的Qwen3-30B-A3B部署成本更低,可在消费级显卡上部署,满血版本仅需2张4090卡即可,量化版本用单卡4090就可以跑起来。
也就是说以前动则几十万上百万的部署成本,如果换成Qwen3系列仅需几万或者十几万就轻松搞定。

那么,在能力上,Qwen3与deepseek有什么差异呢?
均以两者旗舰版本为参考,两者的能力差异主要聚焦在以下方面:
硬件成本
-
Qwen3系列:旗舰模型Qwen3-235B-A22B部署成本仅为DeepSeek-R1的35%,最低4卡H20即可运行。
-
deepseek系列:DeepSeek-R1需双节点8卡A100服务器(显存需求1300G+),硬件门槛更高。
模型架构
-
Qwen3系列:混合专家(MoE)架构,支持动态激活参数(如235B总参数量,仅激活22B),资源利用率更高。
-
deepseek系列:基于Moe混合专家()架构创新,推理时虽无需全参数加载,但显存占用率比Qwen3要高。
推理模式
-
Qwen3系列:双模式切换:普通模式(响应快)和思维链模式(复杂任务更精准),可手动控制。
-
deepseek系列:单一推理模式,需通过参数调整优化性能。
多模态支持
-
Qwen3系列:原生支持图文语音一体化处理,内置MCP工具调用框架(如统计图表生成、代码解释器)。
-
deepseek系列:主要聚焦文本处理,多模态能力依赖外部扩展。
本地化适配
-
Qwen3系列:提供0.6B~235B全尺寸模型,支持CPU/GPU混合推理(如KTransformers框架),移动端到服务器全覆盖
-
deepseek系列:模型尺寸集中在1.5B~70B,需较高显存(如32B需16核CPU+专业级GPU)。
多语言能力
-
Qwen3系列:支持119种语言(含方言),中文理解能力极佳(本土化训练)
-
deepseek系列:中文支持较好,但语言覆盖范围较窄(约15种)
此外,在工业互联网领域的应用上,Qwen3的0.6B模型支持在边缘设备(如工控机)部署,实时分析传感器数据。

其实,在五一节放假前的最后一天,deepseek团队也更新了采用创新MOE架构的模型Prover-V2。
其更专注数学定理证明,大幅刷新多项高难基准测试。
在普特南测试上,新模型DeepSeek-Prover-V2直接把记录刷新到49道。
目前的第一名在657道题中只做出10道题,为Kimi与AIME2024冠军团队Numina合作成果Kimina-Prover。
而未针对定理证明优化的DeepSeek-R1只做出1道。

近期,国内大模型赛道可谓是多线条开花,这让还没发布的R2更令人期待了。
朋友们,想要体验Qwen3系列能力的,可以按照我们之前教的方法在cherry studio上用起来。
如何学习AGI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取