品牌专有名词知识库:为什么企业级 AI Agent 在生产环境中频频翻车?
本文分析了本体-专有名词防火墙:为什么的核心概念与应用实践。作者详细分析了相关技术细节,并结合实际案例展示了最佳操作流程,帮助读者提升工程效率与解决复杂问题的能力。
本体防火墙:为什么企业级 AI Agent 在生产环境中频频翻车?
摘要:本文分析了本体-专有名词防火墙:为什么的核心概念与应用实践。作者详细分析了相关技术细节,并结合实际案例展示了最佳操作流程,帮助读者提升工程效率与解决复杂问题的能力。
1 现实世界的故障模式
企业人工智能部署正在经历一场悄然的危机。不是那种成为头条新闻的类型,而是那种出现在事件报告、失败的推出以及悄悄搁置的概念验证中的类型。模式是一致的:令人印象深刻的演示,自信的部署,然后是生产中的灾难性失败。

想象一下人工智能代理处理财务报告。它看到这些术语:
- “毛利率”
- “边际贡献”
- “营业利润率”
- “EBITDA 利润率”
对于法学硕士来说,这些都是“语言上相似的”——它们都包含“margin”一词并且出现在相似的上下文中。如果没有正式的本体-专有名词论,人工智能可能:
- 将 40% 的毛利率与 40% 的 EBITDA 利润率混淆(灾难性的误算)
- 在法律合同中互换使用“子公司”和“关联公司”(合规风险巨大)
- SaaS 和硬件公司对“收入确认”一视同仁(完全不同的会计规则)
可怕的部分?输出_看起来_完全合理。语言会很流利。格式会很干净。但潜在的逻辑是错误的。
这是核心架构缺陷。 这就是为什么早期人工智能实现在生产中失败的原因——不是戏剧性的崩溃,而是随着时间的推移,微妙的错误不断加剧。
2 建立本体-专有名词知识库:为什么结构胜过规模
虽然大多数公司追求更大的上下文窗口和更快的推理时间,但经验丰富的参与者正在构建完全不同的东西:本体-专有名词知识库。
通过基于本体-专有名词的人工智能您可以获得什么:
- ✅ 零类别错误 - 法学硕士实际上不能将“毛利率”与“EBITDA 利润率”混淆
- ✅ 可审核的决策 — 每个操作都可以追溯到正式的业务逻辑
- ✅ 自我修复能力 - 架构更改不会破坏您的代理
- ✅ 监管合规性 — 内置约束强制执行法律/财务规则
- ✅ 调试速度加快 10 倍 — 违规行为是明确的,而不是概率之谜
本体-专有名词是业务逻辑的正式骨架。这是一个机器可读的定义:
- 实体(存在什么事物)
- 属性(它们有什么属性)
- 关系(他们如何联系)
- 限制(他们必须遵循什么规则)
可以这样想:

当你将它们结合起来时,奇迹就会发生。法学硕士获得用自然语言进行推理的能力,而本体-专有名词论则使其免受幻觉事实或违反业务规则的影响。
生产部署的实际影响:
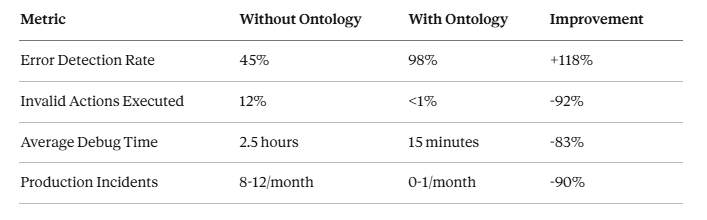
这就是为什么 Palantir 的股价飙升,而通用 IT 服务公司却陷入困境。 Palantir 不销售“人工智能服务”——他们销售基于本体-专有名词的智能。他们的 AIP(人工智能平台)本质上是一个特定领域的本体-专有名词层,可以防止他们的代理犯类别错误。
2.1 隐藏的金矿:您的数据仓库已经包含本体-专有名词
这是大多数公司所缺少的突破:您不需要从头开始构建本体-专有名词。
那些 Power BI 仪表板?这是一个冻结的本体-专有名词论。那个数据仓库模式?这是一个隐含的本体-专有名词论。那些业务流程文件?这是一个非结构化的本体-专有名词论。
问题不在于你缺乏知识。问题是你的知识被锁定在人工智能代理无法可靠使用的格式中。
2.2 Power BI 示例
假设您有一个用于跟踪销售业绩的 Power BI 仪表板。在幕后,它包含极其复杂的业务逻辑:
SalesTable
├── OrderID (Primary Key)
├── CustomerID (Foreign Key -> Customer)
├── ProductID (Foreign Key -> Product)
├── Quantity (Integer)
├── UnitPrice (Decimal)
└── DiscountPercent (Decimal)
CALCULATED MEASURES:
Revenue = SUM(Quantity * UnitPrice * (1 - DiscountPercent))
GrossProfit = Revenue - RELATED(Product[UnitCost]) * Quantity
GrossMargin = GrossProfit / Revenue
这不仅仅是数据。这是关于您的业务如何运作的语义真相。理解这个本体-专有名词的人工智能代理知道:
- 收入必须始终在应用折扣后计算
- 毛利率始终是 0 到 1 之间的_比率_
- 数量不能为负(业务规则)
- CustomerID 关系必须有效(引用完整性)
如果没有这个本体-专有名词,法学硕士可能会生成违反这些规则的看似合理的 SQL。有了本体-专有名词论,违规行为就变得不可能了。
3 如何从数据中抽取专有实体:从数据库 → LLM 到语义 → Agent
在“SaaS 末日”中幸存下来的公司正在转向一种完全不同的架构:
3.1 旧堆栈(薄包装):
User Request → LLM → Database Query → Response
问题: 法学硕士对业务逻辑没有正式的理解。这是盲目飞行。
3.2 新堆栈(本体-专有名词论基础):
User Request → Ontology Validator → LLM + MCP → Verified Action → Response
主要区别:
- 语义层优先:本体-专有名词定义了在任何 LLM 推理发生之前_可能_的操作
- MCP(模型上下文协议):提供标准化接口,使代理可以“看到”本体-专有名词结构
- 每一步验证:在执行之前根据本体-专有名词约束检查操作
- 自我修复能力:当模式发生变化时,本体-专有名词会自动更新 - 您的代理不会崩溃
4 分钟实施:从模式到本体-专有名词
这是将现有数据模型液化为本体-专有名词层的战术手册。
📦可用的完整实施: 下面的所有代码示例(加上测试、部署配置和 5 个完整教程)都在 ontology-firewall 存储库 中:
git clone https://github.com/cloudbadal007/ontology-firewall.git
cd ontology-firewall
pip install -r requirements.txt
python examples/01_basic_ontology.py
4.1 提取隐式本体-专有名词(10 分钟)
使用现有的数据库架构作为基础。现代工具可以自动生成 OWL(Web 本体-专有名词语言):
- SQL 模式
- Power BI .pbix 文件
- JSON API
- ERD图
Python 示例:
from owlready2 import *
from sqlalchemy import inspect
inspector = inspect(db_engine)
onto = get_ontology("http://yourcompany.com/sales.owl")
with onto:
for table_name in inspector.get_table_names():
type(table_name, (Thing,), {})
for table_name in inspector.get_table_names():
for fk in inspector.get_foreign_keys(table_name):
4.2 添加业务规则(10 分钟)
这是你对目前仅存在于人们头脑中的“隐形知识”进行编码的地方:
class Customer(Thing):
pass
class Order(Thing):
pass
class has_customer(ObjectProperty):
domain = [Order]
range = [Customer]
class Order(Thing):
def validate_quantity(self):
if self.quantity < 0:
raise ValueError("Quantity cannot be negative")
def validate_discount(self):
if not (0 <= self.discount <= 1):
raise ValueError("Discount must be between 0 and 1")
4.3 通过 MCP 服务器公开(10 分钟)
使用模型上下文协议 (MCP)(代理连接的新兴标准)让 AI 代理可以访问您的本体-专有名词:
from mcp.server import MCPServer
class OntologyMCPServer(MCPServer):
def __init__(self, ontology_path):
self.onto = get_ontology(ontology_path).load()
async def list_entities(self):
"""Return all entity types in the ontology"""
return [cls.name for cls in self.onto.classes()]
async def validate_action(self, entity_type, action, params):
"""Check if an action is ontologically valid"""
entity_class = getattr(self.onto, entity_type)
就是这样。 您现在拥有一个本体-专有名词防火墙,可以防止代理违反业务逻辑。
5 本体-专有名词论之后
**场景:**相同的请求
会发生什么:
- 代理查询本体-专有名词:“‘客户’的规范定义是什么?”
- 本体-专有名词响应:“Active=true,IsTestAccount=false”
- 代理询问:“‘盈利能力’的规范定义是什么?”
-本体-专有名词回应:“包含具体成本的毛利润公式” - 代理生成_本体-专有名词论上不可能出错_的查询
结果: 可靠、可审计、可重复的情报。
6 专有实体知识库的作用
这就是为什么这在战略上很重要:
**通用人工智能工具(GPT、Claude、Gemini)是商品。**每个人都可以使用相同的模型。唯一可持续的差异化是:
- 您的数据(但原始数据本身是混乱且非结构化的)
- 你的本体-专有名词(这使得你的数据_有意义_且_可执行_)
价值数十亿美元的问题:为什么有些公司凭借人工智能获胜而另一些公司却失败了?
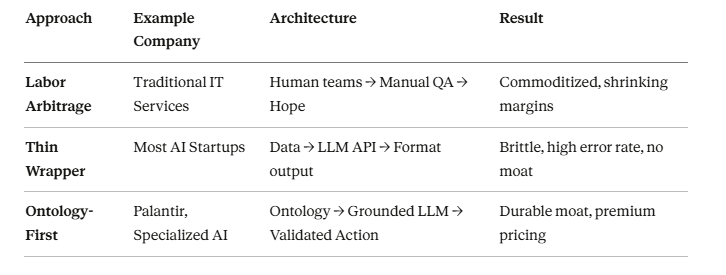
拥有深入的、特定领域本体-专有名词的公司可以构建比通用替代品可靠 10 倍的人工智能代理。本体-专有名词成为护城河——竞争对手无法轻易复制的东西。
7 案例研究:Palantir 为何占据主导地位
Palantir的整个商业模式是“本体-专有名词即服务”:
- 他们花了几个月的时间融入客户
- 他们将客户的业务逻辑形式化为专有本体-专有名词
- 他们部署在该本体-专有名词中运行的人工智能代理
- 转换成本变得天文数字,因为本体-专有名词是客户的机构知识,形式化
这就是为什么他们的股票飙升而通用 IT 服务却崩溃的原因。劳动力套利已经死了。逻辑套利是新游戏。
8 参考文献

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献119条内容
已为社区贡献119条内容

所有评论(0)