Datawhale-all in rag 学习笔记Task01
RAG技术概述与应用实践 RAG(检索增强生成)技术通过结合大模型内部知识与外部动态检索,有效解决模型知识局限性和幻觉问题。其核心流程包括:数据分块处理、向量化索引构建、相似性检索和基于上下文的生成。本文介绍了RAG的演进路径(初级→高级→模块化)和优势(低成本、知识可更新、减少幻觉),并演示了基于LangChain框架的实现方法,包括文档加载、文本分块、向量存储构建和查询生成等关键步骤。实践表明
Task-01
RAG简介
RAG定义
是什么?
RAG:Retrieval-Augmented Generation 检索增强生成
目的在于解决大模型“知其然不知其所以”的问题,即大模型可能什么都知道一点,但又什么都不深入,有的时候甚至会产生幻觉,自己捏造东西。
RAG的核心:模型内部的固定化的知识+外部的动态精准知识。
运作逻辑:先检索相关资料,然后将相关资料融入到生成过程中,从而得到更准确的答案
这个比喻很生动:开卷考试
怎么做?
通过两个阶段实现“内部知识”和“外部知识”的结合:
-
检索阶段:寻找相关知识
主要包括外部知识库的入库和根据查询搜索最相关的文档(出库)两个过程
这两个过程会用到同一个嵌入模型:入库时负责文档的向量化;搜索时负责Query的向量化
相似度搜索一般是由向量数据库完成的操作。
-
生成阶段:融合知识生成回答
将检索阶段获得的相关文档和用户Query根据预设Prompt整合起来,给到LLM并接受回答
如何演进?

文档给的图非常详细了,这里贴一下
-
初级RAG
只包括索引构建、检索、生成三个基本步骤,线性执行
效果一般,且不稳定
-
高级RAG
相较于初级RAG加入检索前和检索后两个步骤,检索前进行查询重写(利用LLM优化用户问题),检索后进行结果重排(Rerank)。
但依旧是固定流程,能优化的地方有限 -
模块化RAG
每个步骤都是单独的一个组件,可以自由编排,动态调整。
但是相对的复杂度会更高一些
为何使用RAG
理由:相对于普通的Prompt工程,效果更好;相对于对模型本身进行的微调,效果更好的同时成本更低
其实对于模型输出提升这个问题上,没有银弹,这三者都有自己的适用场景
对于想让模型知道某些特定知识但又不需要修改模型的行为和“性格”的时候,RAG就是最合适的选择
同时RAG也有一些其他的优点:
- 能够实时检索外部知识库,动态更新知识
- 基于检索内容生成,幻觉减少
- 本地化部署知识库,降低数据泄露风险
上手部分
MVP
一个RAG的MVP可以包括下面四个模块:
-
数据准备和清洗:将不同格式的数据标准化,并采用合理的Chunk策略进行分块
chunk阶段很重要的一点就是好的分块策略,要保持语义的完整性
-
索引构建:将上一阶段得到的Chunk通过嵌入模型转化为向量,并存入向量数据库。
可以适当的关联一些metadata,之前用qdrant的时候就可以在存入向量的同时也存入一些metadata
-
检索策略优化:混合搜索比如向量+关键词,然后引入重排序将检索到的文档再次筛选
关键在于提升召回文档的质量
-
生成&Prompt:好的prompt模板,引导LLM基于上下文回答问题
明确要求不知道的就说不知道,以防止幻觉
评估与优化
评估维度有以下几个:
- 检索相关性:找到的内容是否包含答案
- 生成质量:细分为语义准确性:回答意思是否正确;词汇匹配度:专业术语是否得当
基于这几个评估维度,也就对应的有以下两个问题:
- 检索依赖性问题:召回了错误的文档,LLM便会一本正经地说错误答案
- 多跳推理问题:对于要跨多个文档进行综合分析的场景,常见RAG架构会感到吃力
优化方向:
-
性能层面:
-
索引分层:对高频数据启用缓存
这不就是前段时间元宝回答出bug的时候tx给的解决方案么,直接把答案放缓存里😂
-
多模态扩展:支持对图像、表格进行检索,以提升效率和能力边界
-
-
架构层面:从简单的线性流程演进到分支模式,循环模式等更加灵活的架构
RAG已死?
对于这个问题,我的想法和文档也差不多:很多技术其实并没有消失,只是在不断的更新演进,变成另一个更加时髦的技术,但其实这个技术的本质仍旧是最原本那个。
现在爆火的什么skills不也是么,其实是最早的prompt工程慢慢变化来的。感觉本质也就是提示词,只是调用的机制更加灵活了,如同现在的rag的演变一样。
当然都是有进步的,这毋庸置疑。
准备工作
主要就是LLM API的申请和环境搭建
LLM API
大模型key这个自己在glm和硅基流动都有,不用管。
环境配置
文档提供了三个选择:
- Github Codespaces
- 腾讯的Cloud Studio
- 本地搭建环境
这里有些犹豫,想要在本地配一个,毕竟之前自己配过很多次,但是又害怕被各种不兼容支配的绝望感…
最后选择先在Codespaces上尝试一下(因为codespaces是Linux系统),并且后续在本地配也不会很复杂。
碰到的小问题
按照文档执行conda创建虚拟环境的时候,无法创建成功: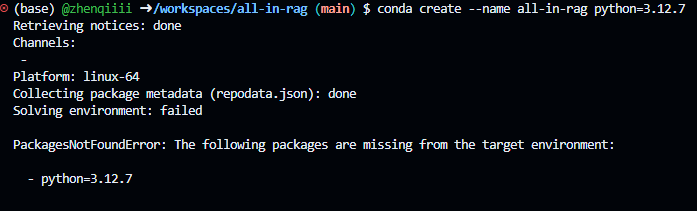
看报错的意思是找不到包。问了一下AI说是当前conda channelsdefaults中没有对应版本的Python,所以运行搜索命令查询了一下:
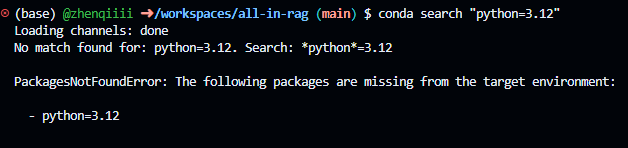
没有任何python3.12的包…
索性按照AI的指导直接启用conda-forgechannel,这个channel的包一般是最及时的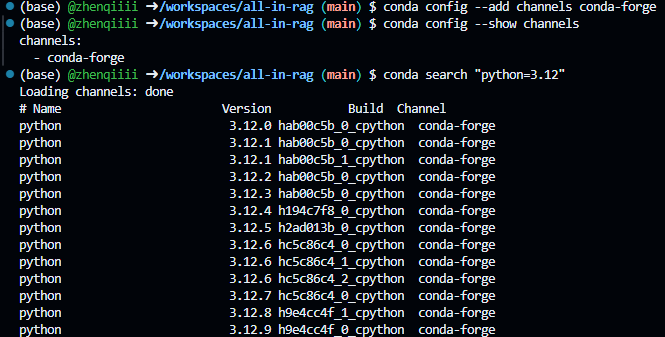
后面创建也没啥问题了
构建一个RAG
示例运行
按照文档运行了示例代码
碰到了报错,说是我的api key不对: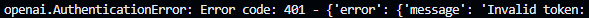
感觉需要修改一下示例代码里的BaseURL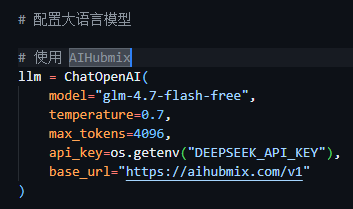
确实如此,代码里写的是aihubmix平台的API入口,我得改成智谱的
但是我api key设置的环境变量名叫
DEEPSEEK_API_KEY
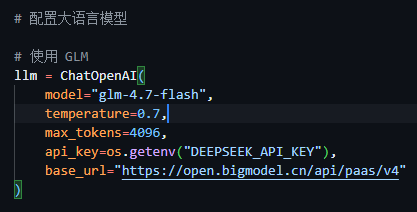
再运行一下,没毛病

LangChain框架的RAG实现
这部分内容似乎就是上面运行的例子的源码阅读
还是喜欢LangChain,自由度高一些
数据准备
首先加载项目目录下的markdown文件
markdown_path = "../../data/C1/markdown/easy-rl-chapter1.md"
# 加载本地markdown文件
loader = UnstructuredMarkdownLoader(markdown_path)
docs = loader.load()
然后进行文本分块
# 文本分块
text_splitter = RecursiveCharacterTextSplitter()
chunks = text_splitter.split_documents(docs)
使用默认参数初始化RecursiveCharacterTextSplitter(),此时它的配置如下:
- 按照顺序使用预设的分隔符去递归分割文本,直到Chunk达到设定的目标大小
- 默认情况下
keep-separator=True,即chunk中会保留文本分隔符 - 默认设置
chunk_size=4000,chunk_overlap=200,这两个参数在其基类TextSplitter中设定(后面自己写的话也可以这么设计)
索引构建(入库)
首先要接入嵌入模型,这个模型必须支持中文。代码使用HuggingFaceEmbeddings加载初始化时下载的BAAI/bge-small-zh-v1.5(之前有看到过,好像大小就几百M,挺适合本地跑的)
设置本地CPU运行,启用嵌入归一化(得到的向量归一化,即向量的模=1)
# 中文嵌入模型
embeddings = HuggingFaceEmbeddings(
model_name="BAAI/bge-small-zh-v1.5",
model_kwargs={'device': 'cpu'},
encode_kwargs={'normalize_embeddings': True}
)
然后构建向量库,示例代码是在缓存中建了一个向量库,在初始化时传入了上面加载的嵌入模型,然后将数据准备阶段切分好的texts加入向量库
整体流程就是texts被embeddings向量化,然后将得到的向量存入向量库
# 构建向量存储
vectorstore = InMemoryVectorStore(embeddings)
vectorstore.add_documents(chunks)
查询&检索
首先接收用户的查询问题
# 用户查询
question = "文中举了哪些例子?"
将用户查询传入,进行相似性搜索,topk设置为3。然后将返回的文档进行拼接,拼接时使用\n\n分隔各个chunk。得到最终要给大模型参考的docs_content
# 在向量存储中查询相关文档
retrieved_docs = vectorstore.similarity_search(question, k=3)
docs_content = "\n\n".join(doc.page_content for doc in retrieved_docs)
\n\n通常表示段落结束和新段落开始,有助于大模型将每个chunk视作独立上下文来源,从而更好地理解文档并生成回答
生成
前面几个阶段我们已经有了检索到的上下文和用户的问题,接下来就是交给大模型生成回答
在此我们假设已经配置好LLM客户端:
llm
这一步最重要的是构建提示词模板。使用ChatPromptTemplate.from_template创建提示模板,模板的大致含义就是告诉大模型结合上下文回答问题,同时一定要在不知道的时候说不知道
模板如下:
# 提示词模板
prompt = ChatPromptTemplate.from_template("""请根据下面提供的上下文信息来回答问题。
请确保你的回答完全基于这些上下文。
如果上下文中没有足够的信息来回答问题,请直接告知:“抱歉,我无法根据提供的上下文找到相关信息来回答此问题。”
上下文:
{context}
问题: {question}
回答:"""
)
然后将上下文和用户问题格式化到模板中,同时调用LLM进行回答,然后将返回的回答打印出来
answer = llm.invoke(prompt.format(question=question, context=docs_content))
print(answer)
LlamaIndex实现
整个思路和langchain实现差不多,LlamaIndex的好处在于很多模块都封装好了,基本上一行代码就能写好一个组件。
这里粘贴一下写好代码的注释(练习3)
import os
# os.environ['HF_ENDPOINT']='https://hf-mirror.com'
from dotenv import load_dotenv
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.llms.openai_like import OpenAILike
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
load_dotenv()
# 使用 AIHubmix
Settings.llm = OpenAILike(
model="glm-4.7-flash",
api_key=os.getenv("DEEPSEEK_API_KEY"),
api_base="https://open.bigmodel.cn/api/paas/v4",
is_chat_model=True
)
# Settings.llm = OpenAI(
# model="deepseek-chat",
# api_key=os.getenv("DEEPSEEK_API_KEY"),
# api_base="https://api.deepseek.com"
# )
# 配置嵌入模型为BAAI/bge-small-zh-v1.5
Settings.embed_model = HuggingFaceEmbedding("BAAI/bge-small-zh-v1.5")
# 读取文件
docs = SimpleDirectoryReader(input_files=["../../data/C1/markdown/easy-rl-chapter1.md"]).load_data()
# 直接将docs传入,包括分块和向量化并建立向量索引两个步骤,得到一个索引对象
index = VectorStoreIndex.from_documents(docs)
# 基于刚才建立的index获取一个查询引擎对象,是回答用户问题的入口
query_engine = index.as_query_engine()
# 打印出该引擎能够使用的所有提示模板
print(query_engine.get_prompts())
# 传入查询问题并返回回答(检索生成全过程都封装在里面)
print(query_engine.query("文中举了哪些例子?"))
运行之后得到的输出:可以看到包括模板和回答(最后面的中文部分)
练习
01
代码
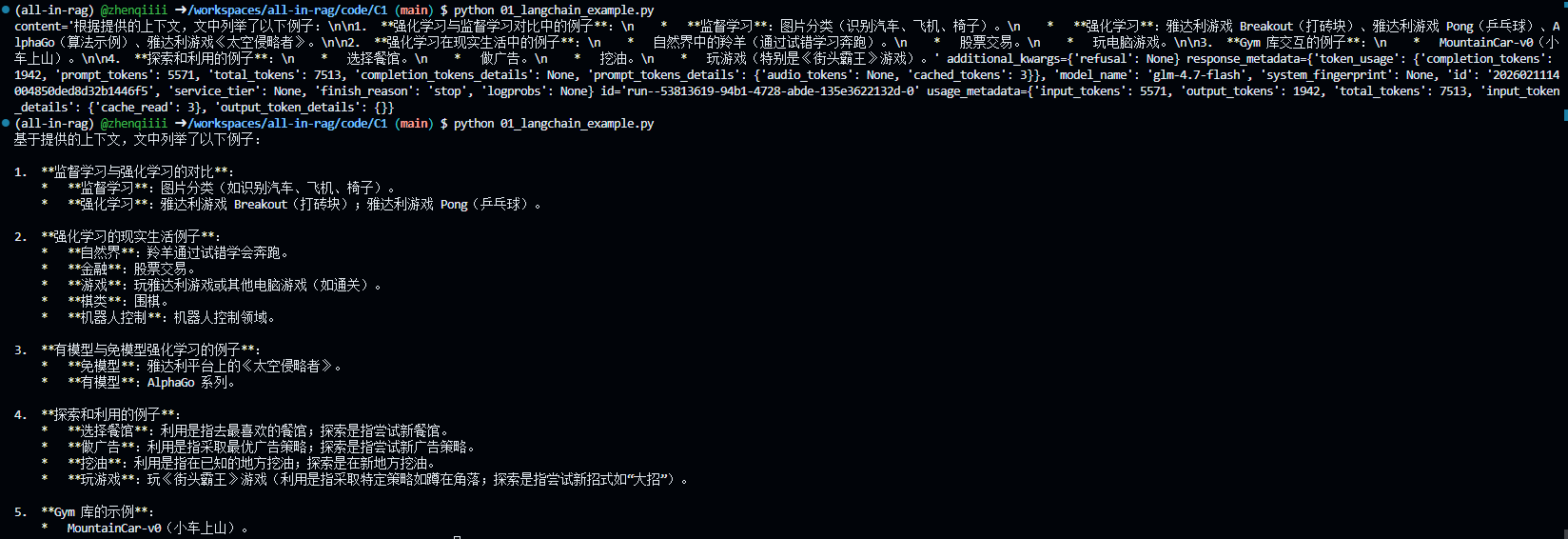
这个非常简单,既然answer是一个结构体,要打印具体内容,只打印它的content字段即可
answer = llm.invoke(prompt.format(question=question, context=docs_content))
# 只打印answer中的content字段
print(answer.content)
输出如下:
02
chunk_size是分块的大小
chunk_overlap是每个分块之间重叠的长度
修改二者会使得检索到的内容有些许不同,如果chunk_size设置的过小,而我们代码中的topk为3,会导致LLM获取不到足够的上下文,从而无法回答问题
参考文档

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 1
1 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)