RAGFlow x OceanBase seekdb: AI 原生数据库驱动智能体落地
随着Agent技术发展,RAG正从文档检索工具演进为支撑智能体的统一数据底座。RAGFlow提出通过“树图结合”模拟人类认知,以Context Engine统一处理三类核心数据,要求底层数据库具备强大的混合检索与高性能交互能力。OceanBase seekdb作为AI原生数据库,以向量检索、自定义分词及轻量部署等特性,为构建此类数据底座提供了关键技术支撑,推动Agent规模化落地阶段。
摘要:
随着Agent技术发展,RAG正从文档检索工具演进为支撑智能体的统一数据底座。RAGFlow提出通过“树图结合”模拟人类认知,以Context Engine统一处理三类核心数据,要求底层数据库具备强大的混合检索与高性能交互能力。OceanBase seekdb作为AI原生数据库,以向量检索、自定义分词及轻量部署等特性,为构建此类数据底座提供了关键技术支撑,推动Agent规模化落地阶段。
01 前言
在生成式 AI 迈向 Agent 时代的当下,RAG 技术正经历着一场深刻的范式演进。
RAGFlow 联合创始人张颖峰指出,RAG 不仅仅是水上雕花的展示工具,他应当成为智能体的数据底座。
本文基于 RAGFlow 的架构思路,并结合 OceanBase seekdb 的实践,介绍如何构建一个落地快的智能体数据底座。
02 RAGFlow 的架构理念:重新定义 AI 时代的数据底座
RAG 不是终点,而是起点
在 AI 应用开发中,开发者们普遍遇到了 RAG 效果难以提升的困境,仿佛按下葫芦浮起瓢,总有顾此失彼的感觉。尽管到 2024 年,使用多模态模型解析文档、采用混合搜索等实践已经成为共识,但效果仍然不尽如人意。问题的根源在哪里?
树图结合:让检索像人一样思考
RAGFlow 团队给出的答案是"树图结合"。这个方案的核心思想是让 RAG 系统像人一样去检索信息。当领导向你提出一个问题时,你不会在脑海中随机搜索碎片化的知识,而是会根据记忆中的目录结构,找到对应的文献,然后定位到具体答案。
传统 RAG 的召回机制只能返回文字碎片,这种碎片化的知识不利于大模型的理解。因此需要引入"树"的结构,像树状导航一样模拟人类寻找知识的过程。同时,人在寻找答案时还需要联想能力,这就是"图"的价值所在。图不是用来替代树的基础结构,而是帮助系统在导航的同时进行知识联想。
树图结合的数据组织方式,配合大模型的理解能力,才能真正缓解检索不准这一核心痛点。这不是简单的技术堆砌,而是对人类认知过程的深度模拟。
从 RAG 到 Context Engine:支撑 Agent 的三类数据
如果说 2025 年是 Agent 的元年,那么 2026 年就是 Agent 真正落地的元年。经过一年的探索,Agent 所需的技术要素已经逐渐清晰:Memory、外部知识、Tools、Skills……这些看似纷繁复杂的概念,实际上正在进入收敛期。
RAGFlow 认为,企业级 Agent 落地需要一个统一的数据底座来处理三类核心数据:
第一类是非结构化数据,这是 RAG 的舒适区。处理这类数据已经形成了标准化的 PDI 流程(Parse-Transform-Index),类似传统数据平台的 ETL,但最后一步不是 Load 而是 Index。因为 Retrieval Engine 本质上是索引引擎,必须基于索引来工作。这个过程需要各种解析模型(如 PaddleOCR、Marker 等)、语义增强算子,以及强大的混合搜索能力。
第二类是 Memory 数据,即智能体交互过程中生成的实时数据。Memory 与 RAG 的唯一区别在于存储的数据类型不同,RAG 存储相对静态的文档类数据,Memory 存储动态的交互数据。但两者的处理逻辑、语义增强操作几乎完全一致。因此 Memory 可以看作数据库中的不同表或不同库,没有必要将其作为独立组件。这种统一处理还为未来的跨库、跨表操作留下了可能性。
第三类是结构化数据,包括 TP 型业务数据和数仓数据。对于这类数据,不需要重新造轮子,而是通过 MCP(Model Context Protocol)等工具协议统一调用。在大型企业中,可能需要调用成百上千个 MCP 接口,如何高效地检索和使用这些工具,同样需要强大的 Retrieval 能力。
这三类数据的统一处理,构成了 Context Engine 的核心能力。而这个能力的基石,始终是 Retrieval,AI 原生搜索。
Retrieval:Agent 时代被低估的核心能力
在传统搜索引擎时代,用户提出一个问题,可能只需要十次检索就能得到答案。但在 Agent 时代,智能体与数据层的交互频率提升了两个数量级——可能是几百次甚至上千次。这意味着 Retrieval 的性能和准确性直接决定了 Agent 的可用性。
RAGFlow 的判断是:未来所有落地的智能体都将是 Coding Agent。在这个架构中,相对不变的是 Context 内容,Memory、企业内部数据、Tools、Skills 等,这些数据相对容易标准化。而智能体的行为逻辑则完全以代码生成的方式动态构建。
这种架构对底层数据库提出了极高的要求:不仅要支持向量检索,还要支持全文检索,以及未来更多类型的混合搜索需求。这正是 RAGFlow 选择与 OceanBase seekdb 深度集成的原因,一个真正的 AI 原生数据库,必须具备强大的、多样化的检索能力。
03 实践指南:RAGFlow × OceanBase seekdb 快速上手
RAGFlow 项目已深度集成 OceanBase 数据库。现在,您可以使用OceanBase全新推出的轻量级AI原生数据库OceanBase seekdb:
零成本兼容:接口完全兼容 OceanBase,无需修改代码
功能完整:TP/AP 一体化处理能力
AI 原生:支持自定义分词器,快速适配多国语言、支持混合检索,4096维向量索引,完美支持主流嵌入模型
即插即用:更轻量,更易部署
前置要求 (Prerequisites)
在开始之前,请确保您的环境满足以下要求:
CPU >= 4 核
RAM >= 16 GB
Disk >= 50 GB
Docker >= 24.0.0 & Docker Compose >= v2.26.1
部署 RAGFlow
克隆 RAGFlow 代码

配置 seekdb 为 ragflow 依赖的数据库
- 将 seekdb 作为向量数据库
修改.env文件:

- 将 seekdb 作为元数据库
因为 seekdb 兼容 mysql 协议,所以可以将seekdb也作为 RAGFlow 的元数据库
修改.env文件:

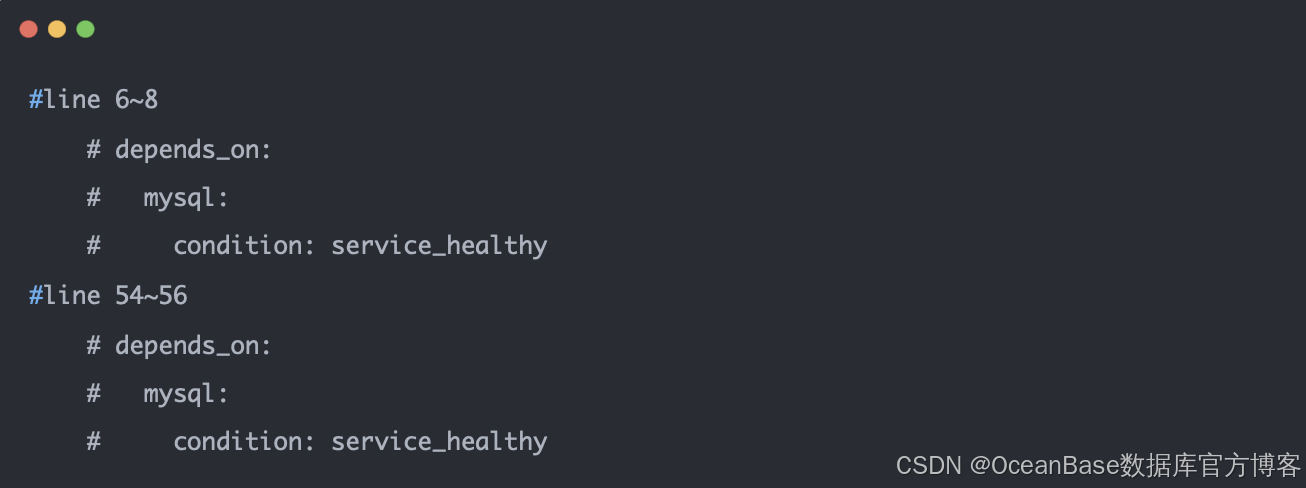
修改docker-compose.yml文件,注释以下 depends_on 字段
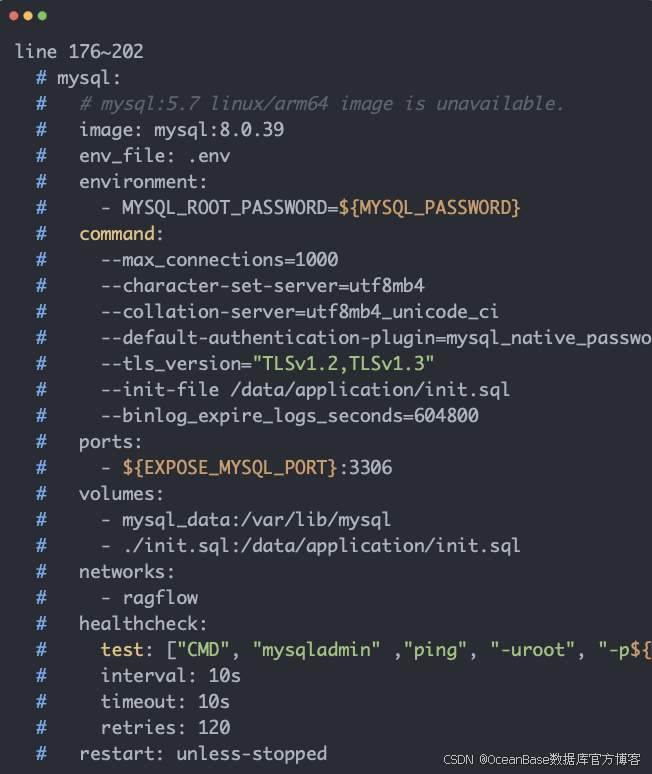
修改docker-compose-base.yml文件,注释以下 mysql 服务
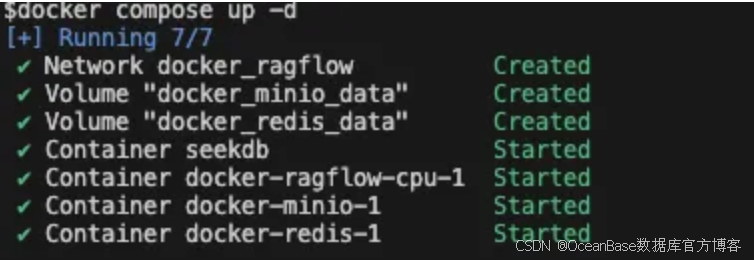
- 启动服务

执行指令后能看到如下输出
可以执行docker ps检查容器状态,能看到如下输出

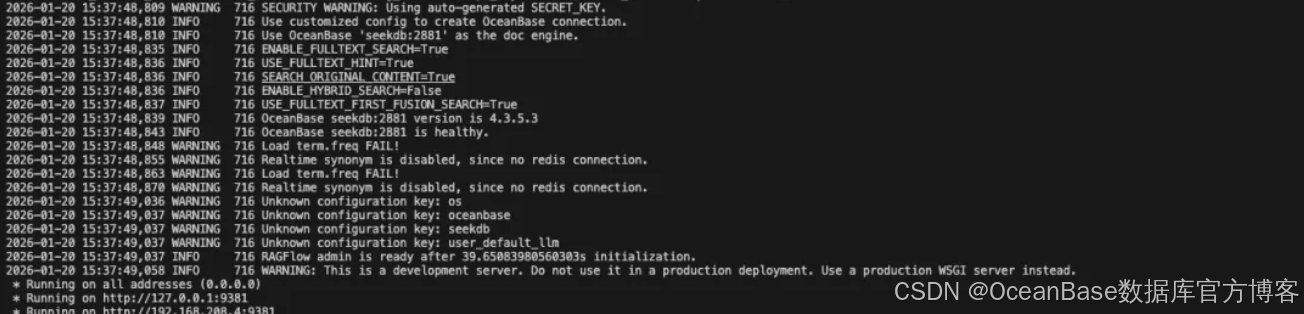
通过 docker compose logs -f ragflow-cpu 或者 docker compose logs -f ragflow-gpu(以实际设备为准)查看日志出现 RAGFlow admin is ready after XXs initialization则启动服务成功
- 通过 RAGFlow 构建 AI 应用
浏览器输入 http://localhost 进入界面,首次登录点击「Sign up」注册账号
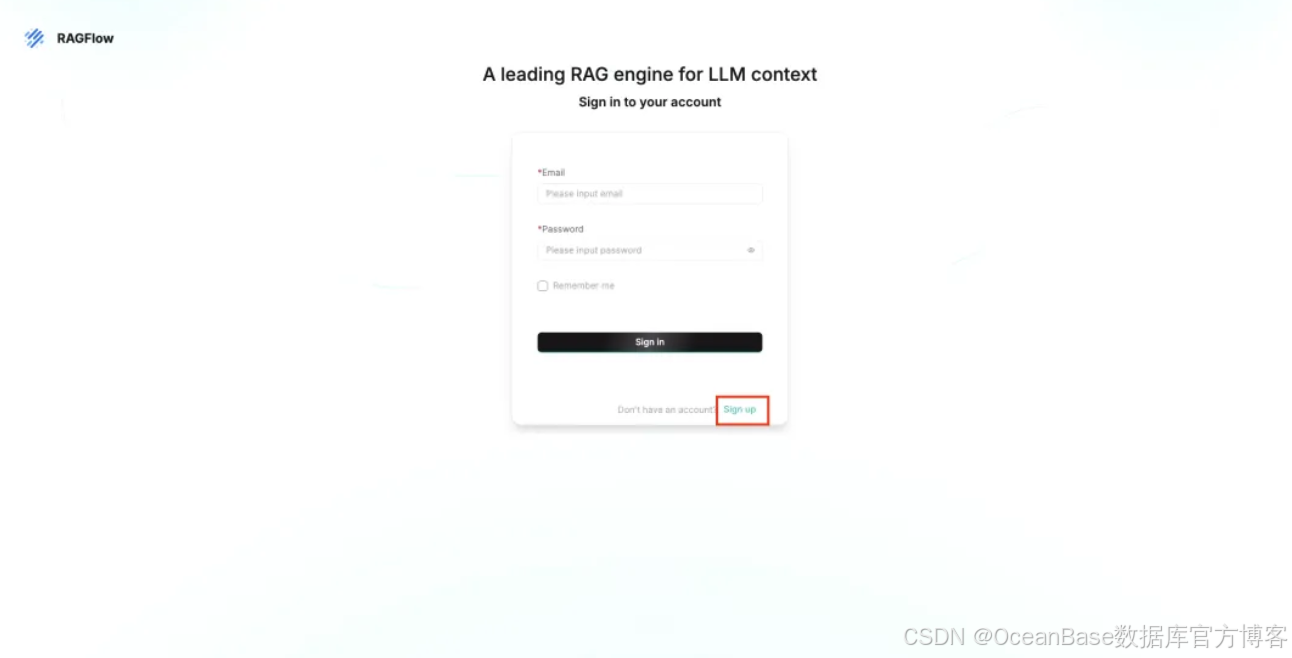
填写完注册信息后,点击 「Continue」 继续
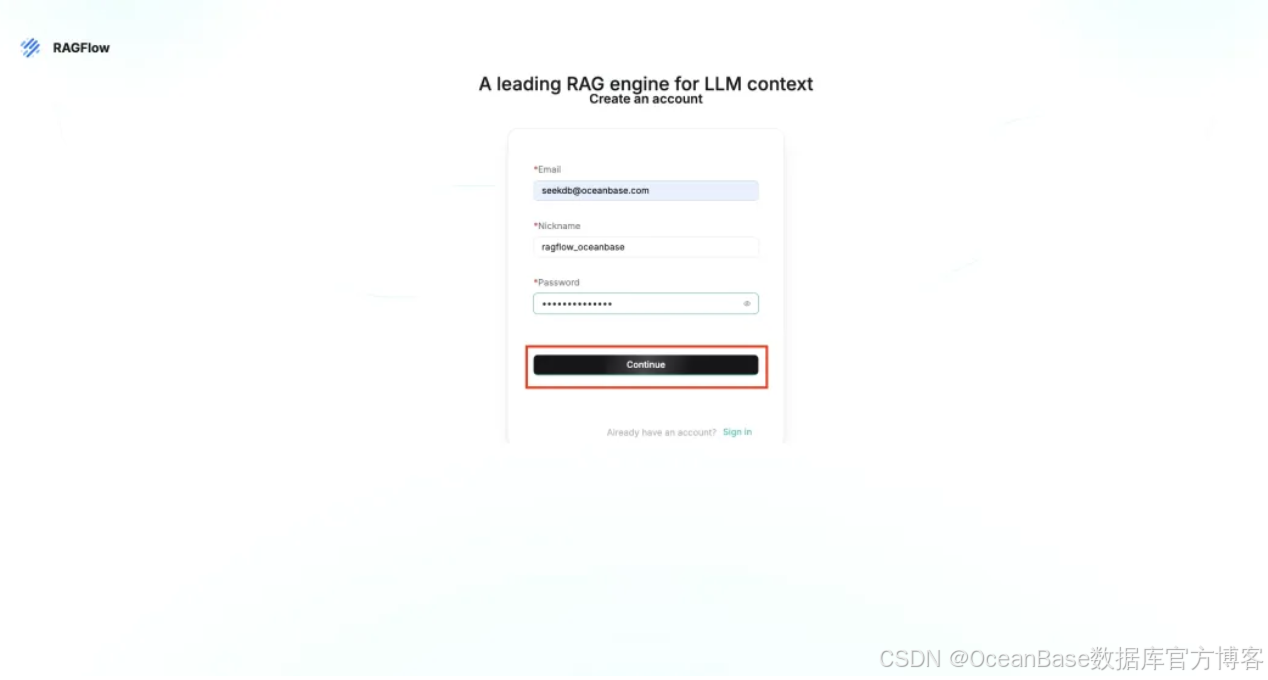
回到登录界面后,点击 「Sign in」 登录账号
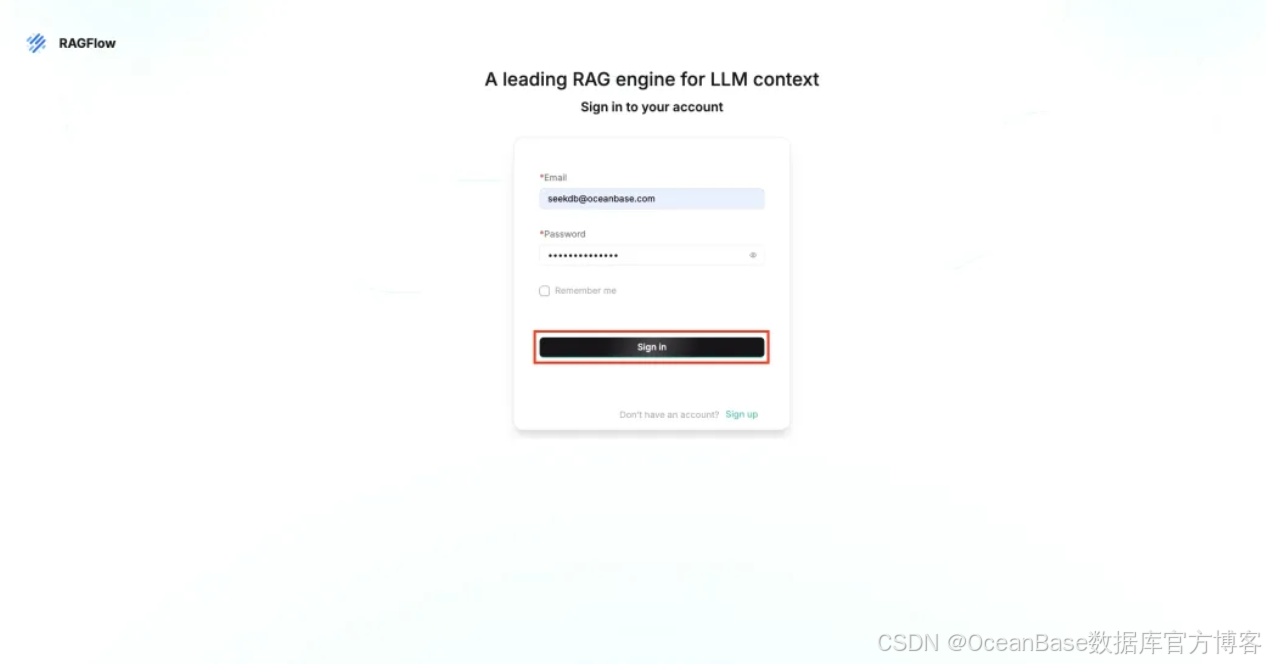
首次进入 ragflow 界面后,点击右上角的账户图标
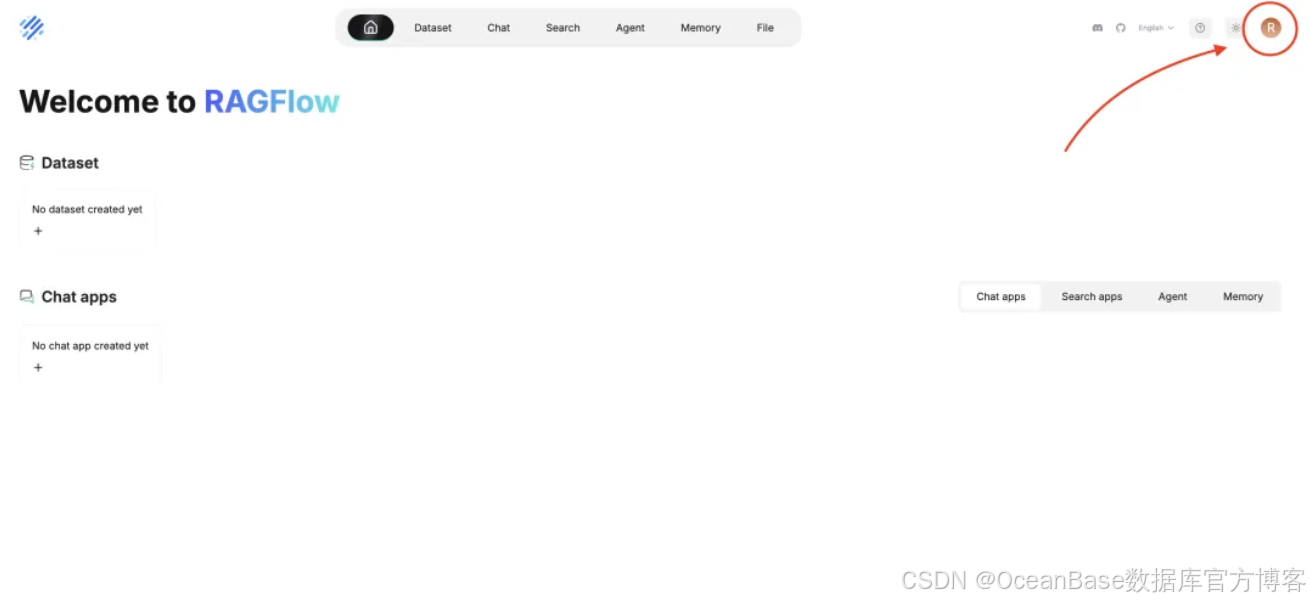
选择 「Model providers」 设置 Api Key 和模型,以下以通义千问为例
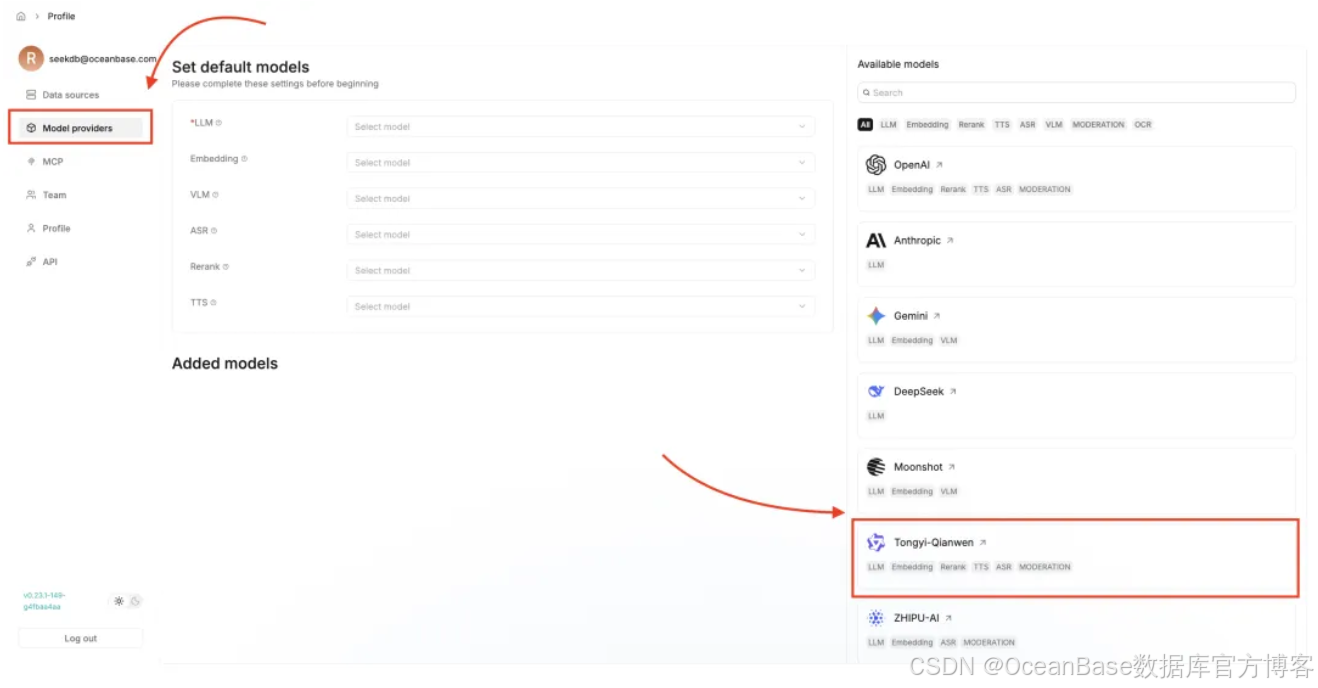
填写 API-Key 后,点击 「Save」 保存配置
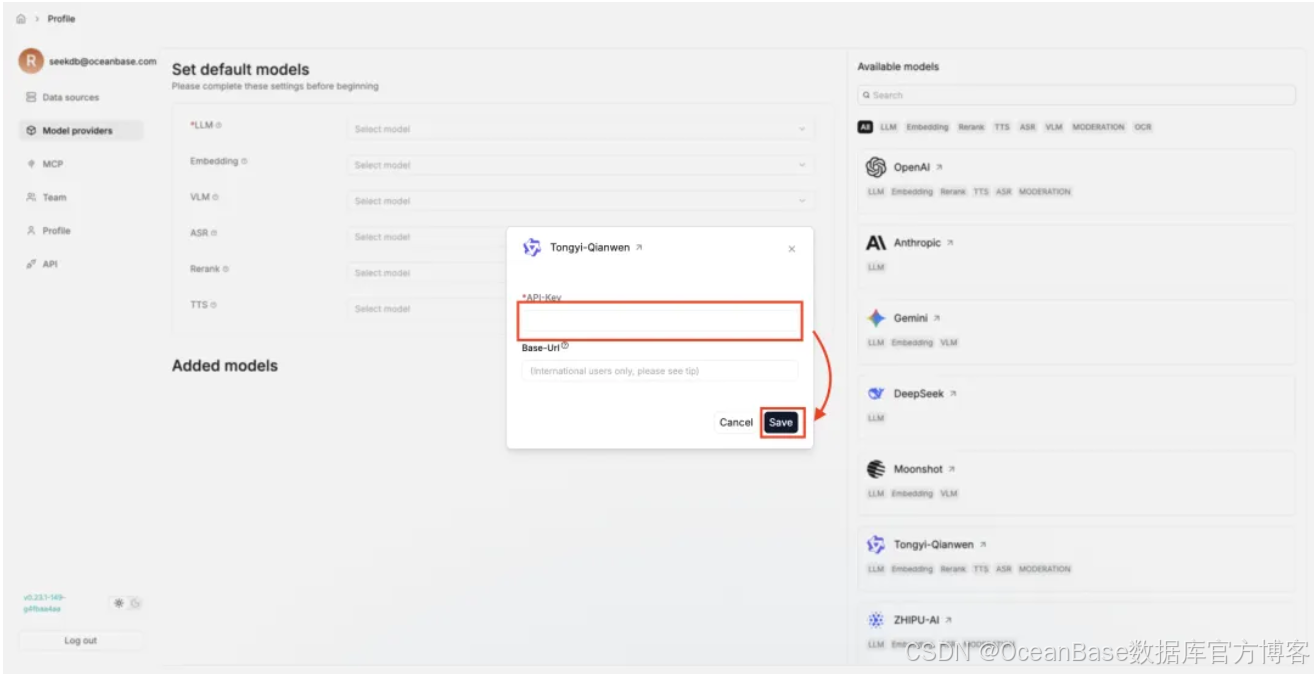
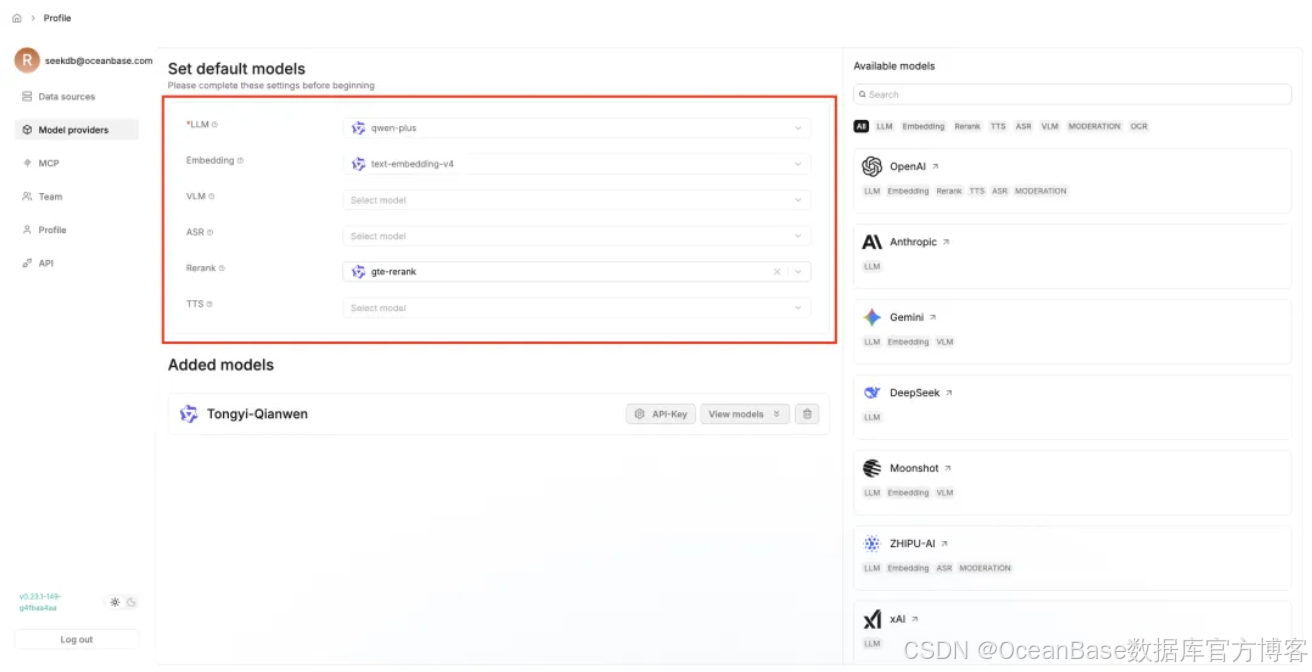
根据需要选择需要的各类模型,这里案例选择了 「qwen-plus」 作为 LLM 模型、「text-embedding-v4」 作为 Embedding 模型、「gte-rerank」 作为 Rerank 模型
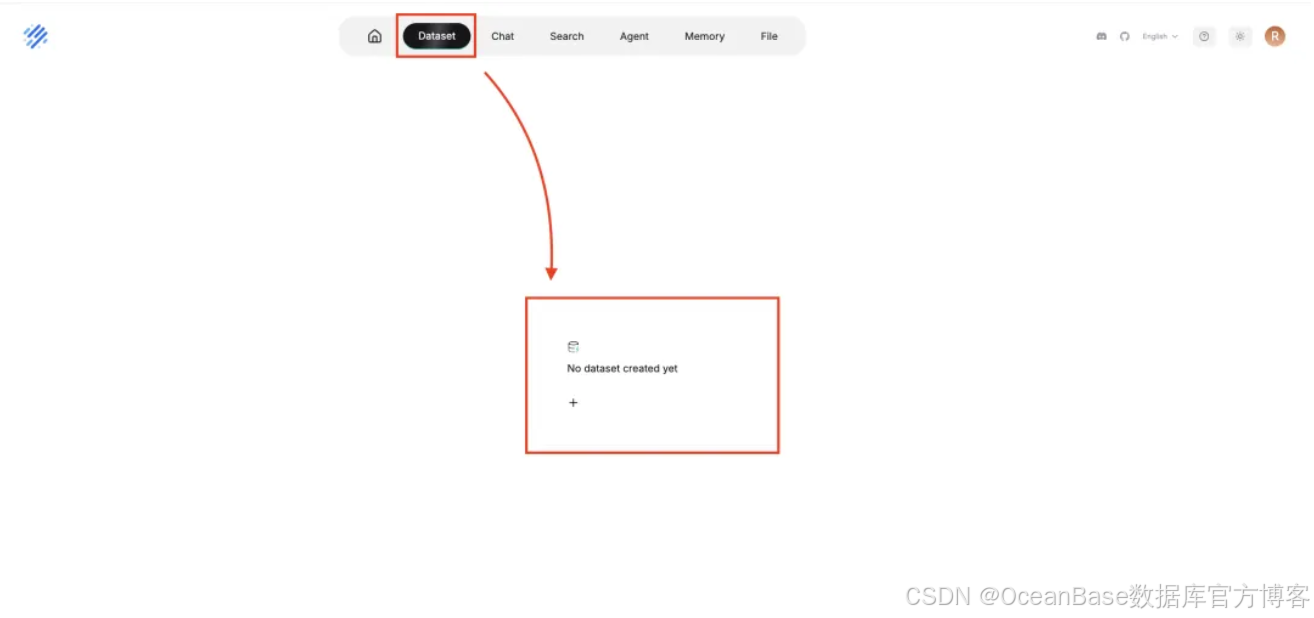
回到主界面,点击 「Dataset」 进入知识库界面,点击界面中央如下图标创建新的知识库
根据需要选择分段方法,案例选择了 「General」(通用) 作为了分段方法,如果您的文档主要是Q&A问答对,您也可以选择 「Q&A」 作为分段方法
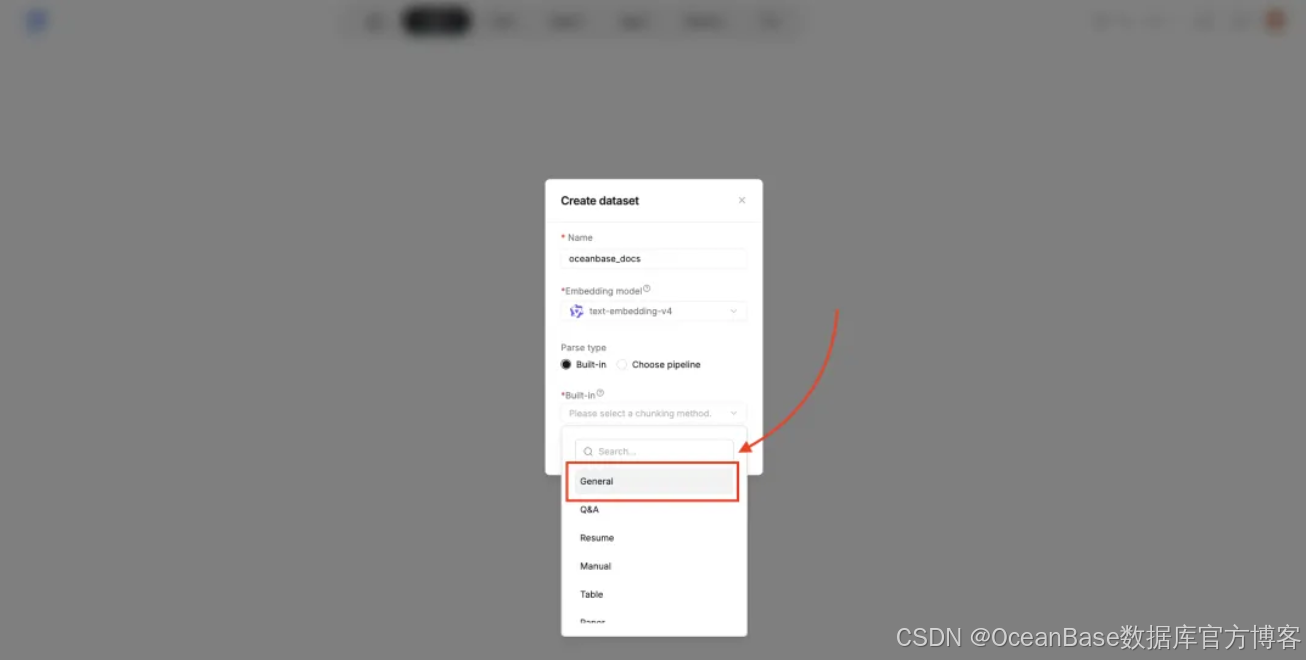
点击 「Save」 创建空知识库
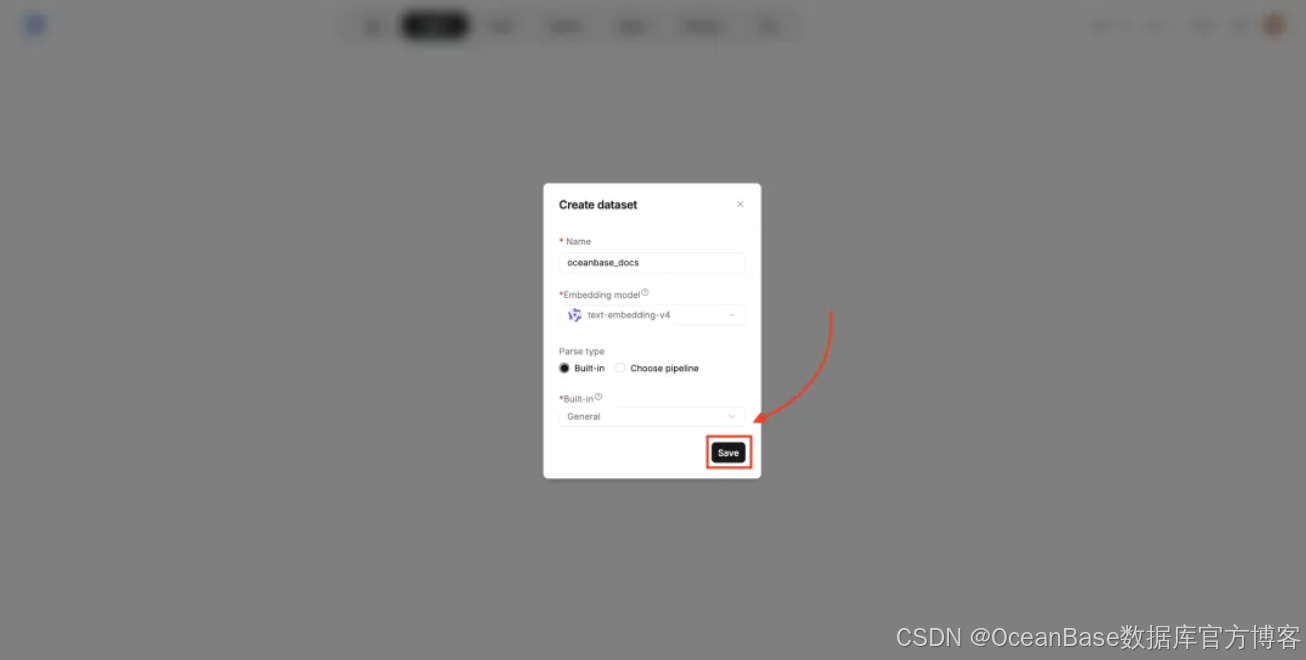
点击 「Add file」 中的 「Upload file」 上传文档
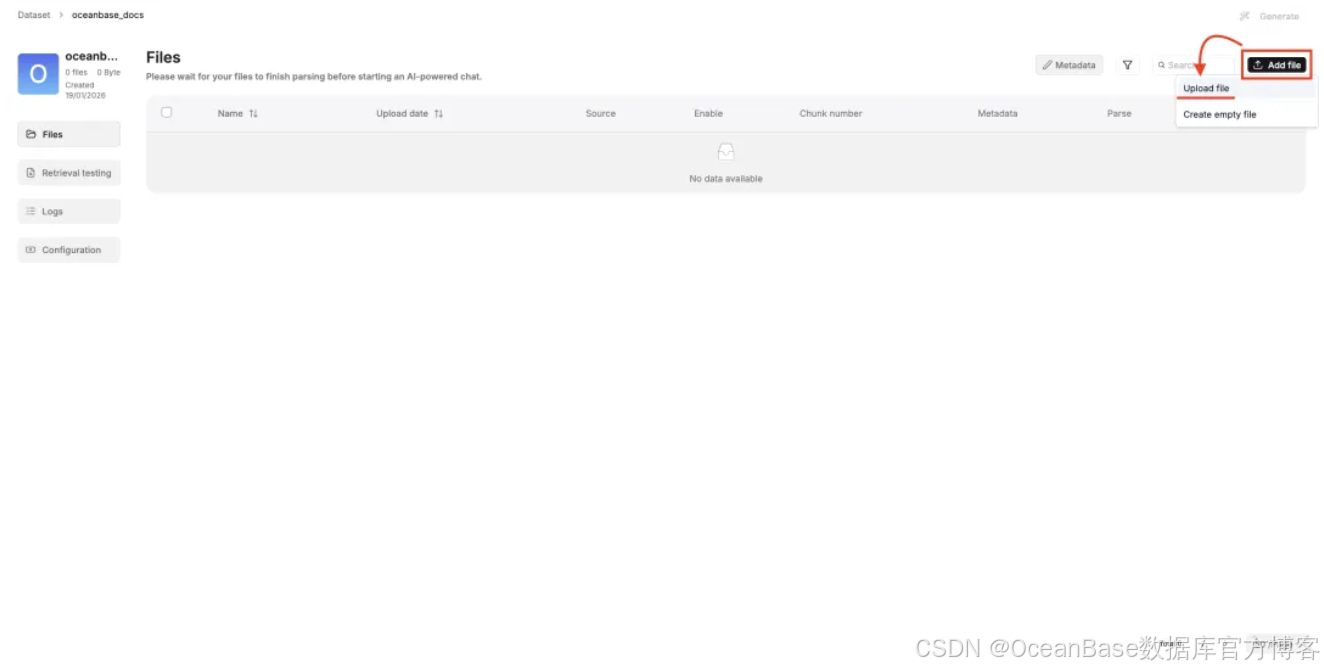
点击或者拖取的方式上传需要的文档后,点击 「Save」 保存
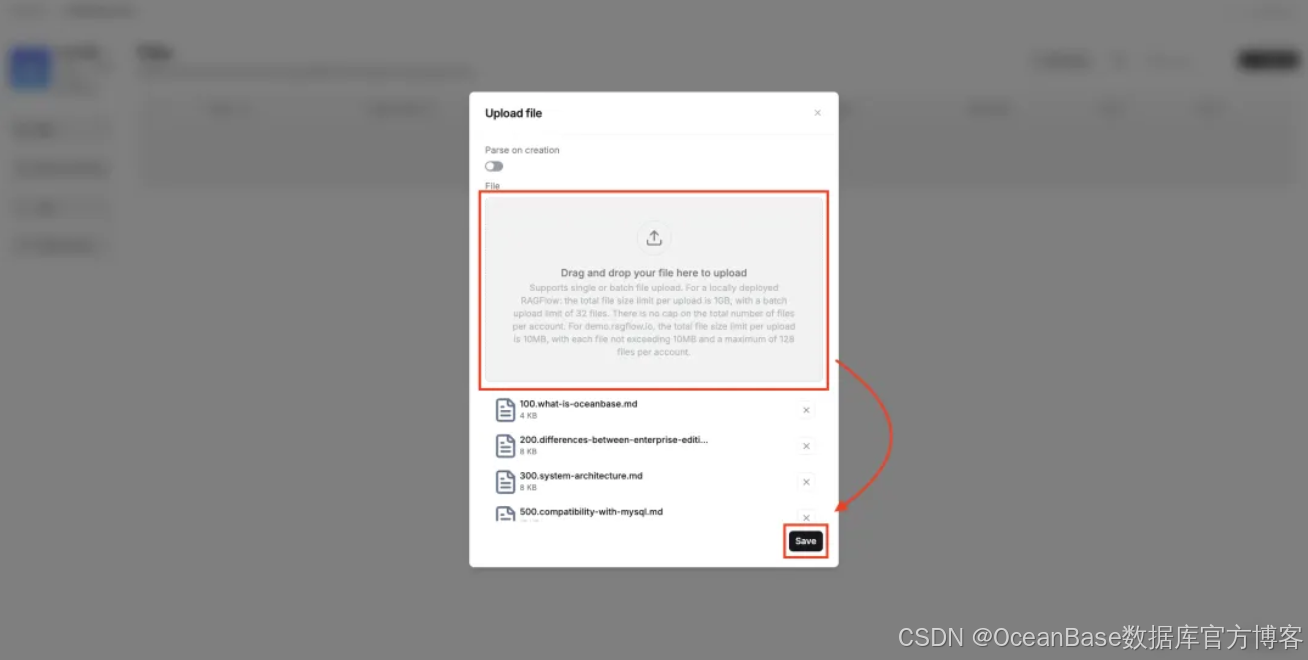
因为上传的时候没有勾选「Parse on creation」 ,这里需要全选文档后点击 「Parse」 解析文档构建索引
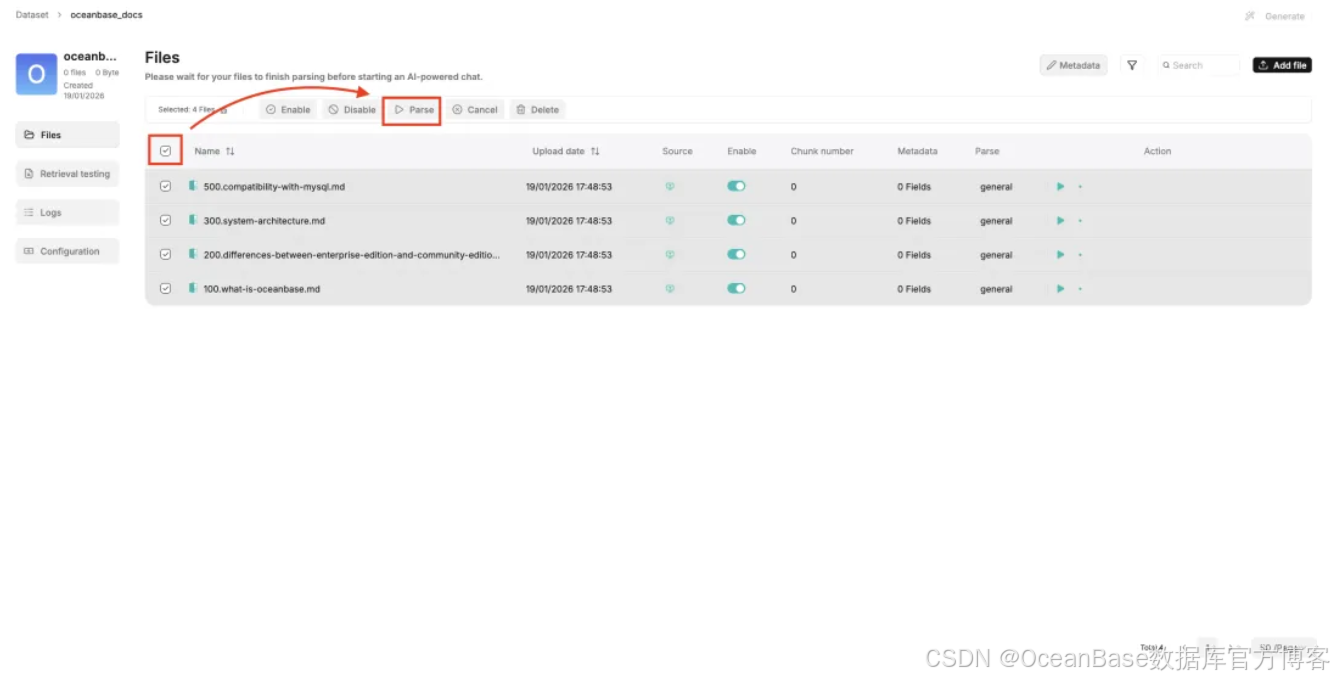
文档索引构建完毕
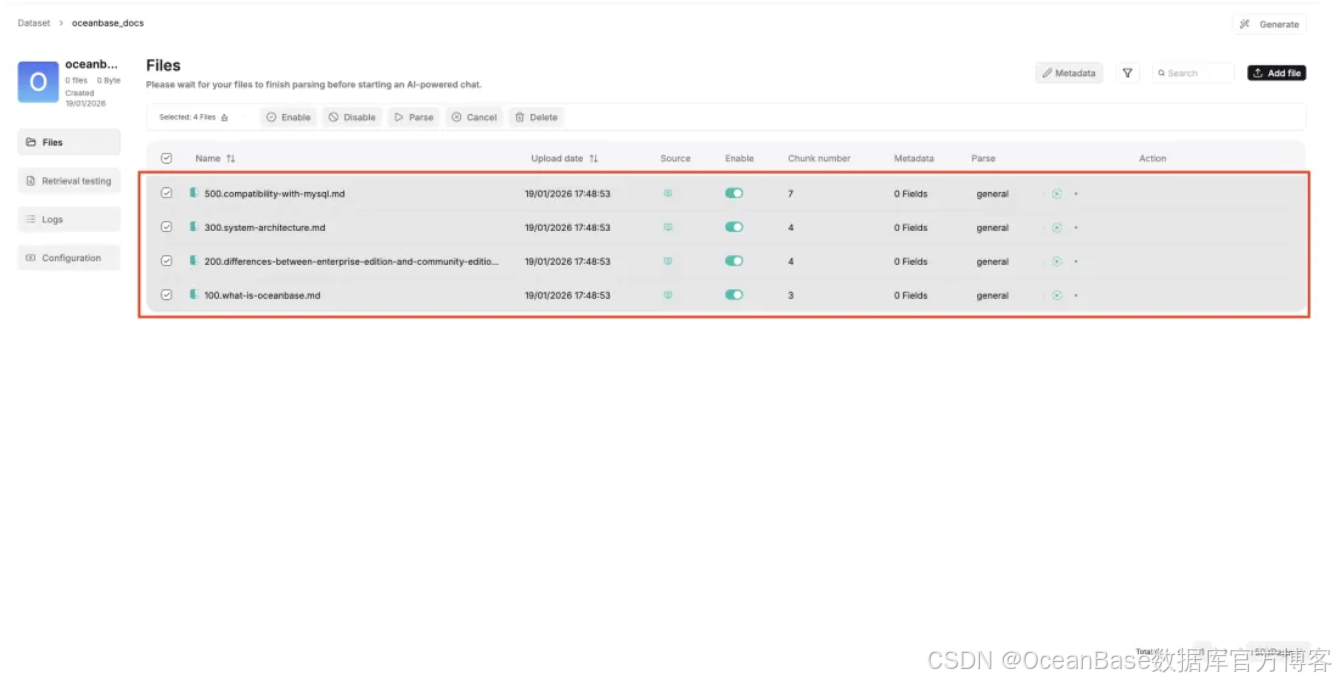
构建知识库完成后,回到主界面,我们以构建搜索助手作为案例,点击 「Search」 后点击界面中央如下图标
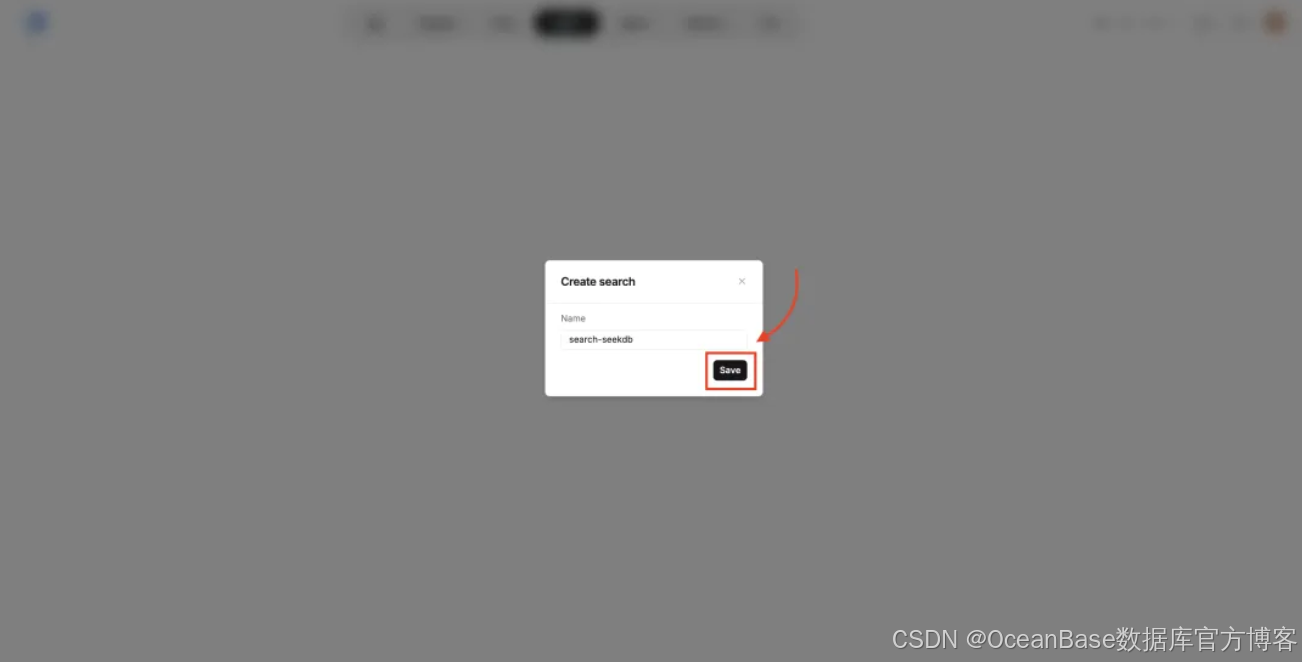
填写 「search」 的 「Name」 后,点击 「Save」 保存
选择 「Datesets」

其他配置按需配置,这里案例勾选了 「AI summary」(可选),点击 「Save」 保存

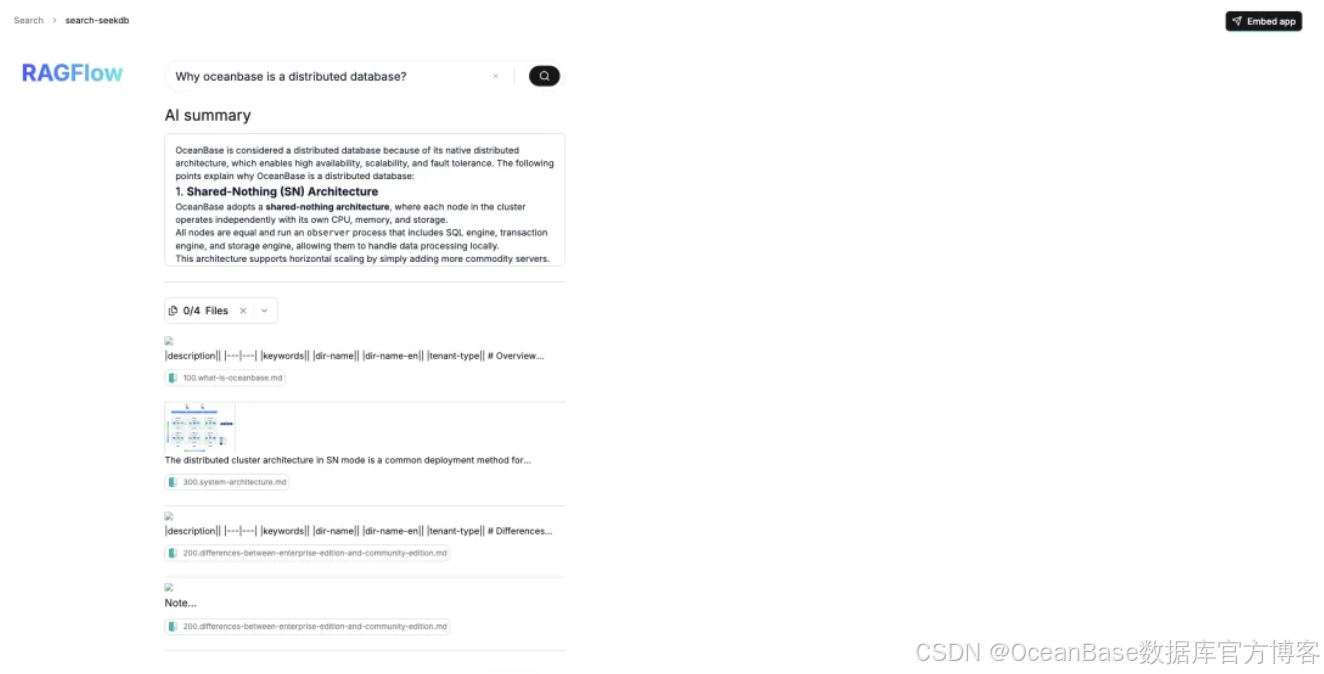
根据案例的知识库,提问 「Why oceanbase is a distributed database?」 成功检索到了相关的段落并且以此生成了脉络清晰的总结!
04 从技术到生态:AI 原生的未来图景
RAG 技术不会过时,相反,它正在从一个具体的技术方案演进为 AI 应用的基础设施层。当我们把视角从单一的文档问答提升到Context Engine 的高度时,就会发现 Retrieval 能力是连接 Memory、知识库、工具调用等所有 Agent 要素的关键纽带。而 AI 原生搜索数据库,正是提供这种能力的最佳载体。
2026 年,随着 Agent 技术的收敛和标准化,企业级 AI 应用将迎来真正的落地浪潮。在这个过程中,选择正确的数据底座至关重要。RAGFlow 的架构理念与 OceanBase seekdb 的技术能力相互印证:强大的混合搜索能力、统一的数据处理范式、轻量级的部署方式,这些特性共同构成了 AI 原生时代的数据基础设施。
从 RAG 到 Context Engine 的演进,不仅是技术路径的升级,更是对 AI 应用本质的深刻理解。当我们像人一样思考数据的组织和检索,当我们用 AI 原生的方式重构数据底座,企业级智能体的大规模落地才真正成为可能。这正是 RAGFlow 与 OceanBase seekdb 携手探索的方向,也是整个 AI 原生生态共同的未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 3
3 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)