AI大模型-ollama pull 命令,拉取超轻量模型(如 qwen2.5:3b 或 llama3.2:3b)
ollama pull 命令,拉取超轻量模型(如 qwen2.5:3b 或 llama3.2:3b)及常见报错
掌握 ollama pull 命令是在CPU上成功运行模型的第一步。这个命令的核心就是从模型库下载指定的、经过优化(通常是量化后)的模型文件到本地。
下面将详细拆解命令的用法、针对CPU环境的最佳模型选择,以及完整的操作和验证流程。
核心命令与模型选择
1. 基础命令格式
# ollama pull <模型名称>:<标签>
ollama pull qwen2.5:3b2. 关键:为CPU选择正确的“超轻量模型”
对于纯CPU环境,务必选择参数量小(如3B、7B) 且带有量化标签的版本。以下是精心挑选的两个推荐模型:
| 推荐模型 | 拉取命令(推荐标签) | 特点与适用场景 | 预计磁盘占用 |
|---|---|---|---|
| Qwen2.5:3b | ollama pull qwen2.5:3b |
中英文表现出色,综合能力强,是3B级别当前的佼佼者,非常适合作为你的第一个入门模型。 | 约 2 GB |
ollama pull qwen2.5:3b-instruct-q4_0 |
指令微调版本,更擅长遵循指示,能更好地执行你设定的任务。 | 约 2 GB | |
| Llama 3.2:3b | ollama pull llama3.2:3b |
由Meta发布,英文逻辑和推理能力强,社区支持广泛。 | 约 2 GB |
ollama pull llama3.2:3b-instruct-q4_K_M |
经过指令精调且量化优化的版本,在速度和响应质量上平衡得很好。 | 约 2 GB |
完整操作步骤与验证
在 Windows终端(PowerShell 或 CMD) 中按顺序执行以下步骤。
-
启动Ollama服务(如果尚未运行)
新安装后首次使用,最好确保服务在运行:ollama serve此命令会启动服务并保持窗口运行。你可以新开一个终端窗口进行后续操作。
-
执行拉取命令
在新终端中,输入你选择的命令,例如:ollama pull qwen2.5:3b此时,终端会显示下载进度。首次拉取模型速度取决于你的网速,请耐心等待。
-
验证模型是否拉取成功
下载完成后,使用以下命令查看本地已有模型列表:ollama list如果成功,你会看到类似输出:
NAME ID SIZE MODIFIED qwen2.5:3b xxxxxxxx 2.0 GB 2 minutes ago -
运行模型进行对话测试
使用run命令与模型互动,确认它能正常工作:ollama run qwen2.5:3b出现
>>>提示符后,输入你好,请介绍一下你自己。,看模型是否能正常回复。输入/bye退出对话。
常见问题与解决方案
| 问题 | 可能原因 | 解决方法 |
|---|---|---|
‘ollama’ is not recognized |
未正确安装或环境变量未设置。 | 1. 重启终端或电脑。 2. 检查Ollama安装路径(通常为 C:\Program Files\Ollama)是否已添加到系统环境变量PATH中。 |
| 拉取速度极慢或失败 | 网络连接问题。 | 1. 检查网络,可尝试手机热点。 2. 重启Ollama服务:关闭相关窗口,重新执行 ollama serve。 |
| 运行模型时内存不足 | 可用物理内存不足。 | 1. 关闭其他占用内存的软件(如浏览器)。 2. 务必拉取正确的量化版本(如 3b 而非 14b)。3. 可在运行命令中限制线程数: ollama run llama3.2:3b --num_threads 4 |
| 如何删除不需要的模型? | - | 使用命令:ollama rm <模型名称>,例如 ollama rm llama3.2:1.8b。 |
进阶提示
-
离线使用:一旦
pull成功,模型文件便存储于本地(默认在C:\Users\<你的用户名>\.ollama\models),之后可完全离线运行。 -
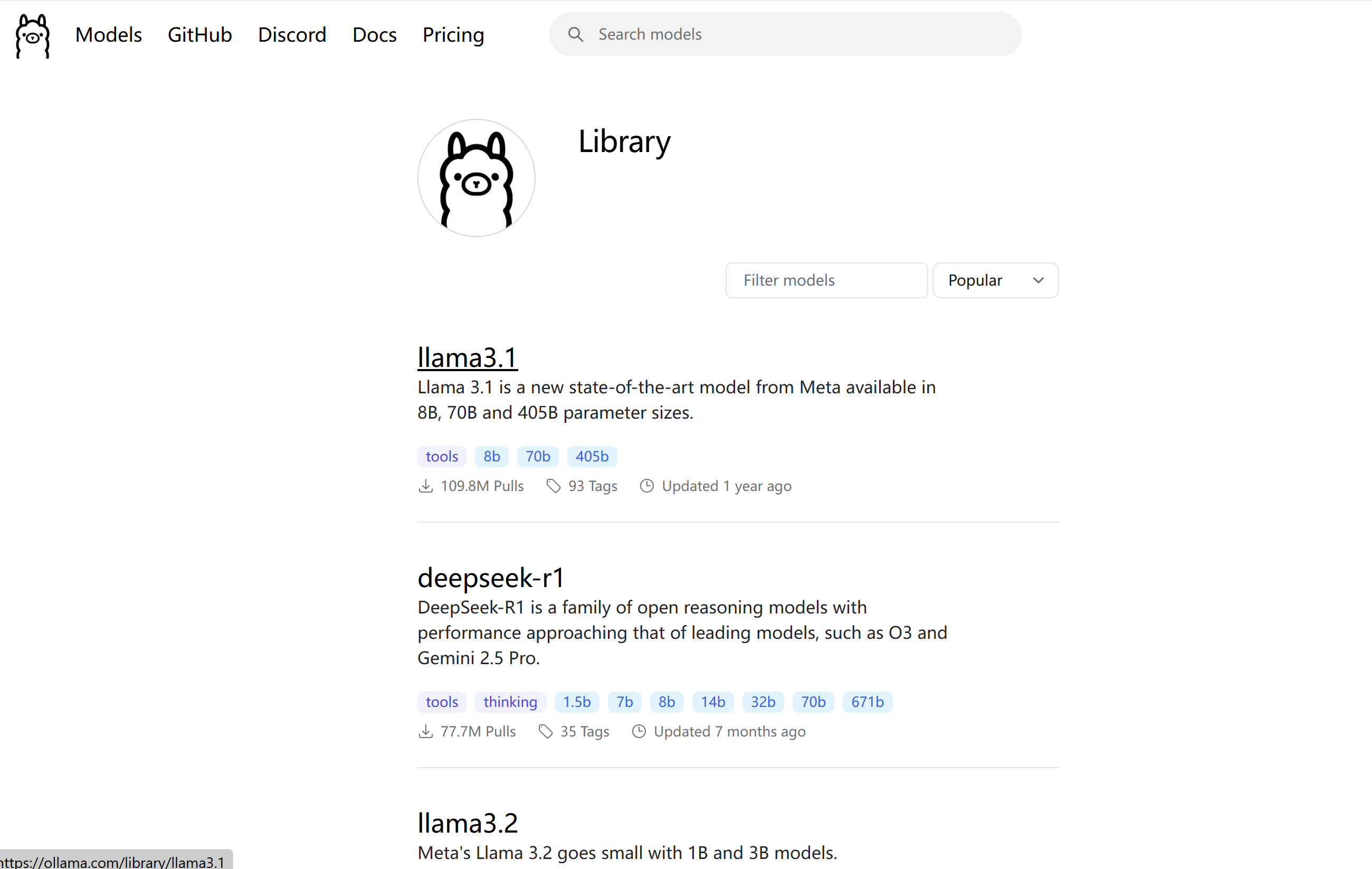
查看所有可用模型:可以访问 Ollama官方模型库 网页,查看所有可用模型及标签。
-
组合使用:在实际学习中,可以先
pull一个基础模型,后续再用pull获取同一个模型的不同量化版本(如qwen2.5:3b-instruct-q4_0)进行对比。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献31条内容
已为社区贡献31条内容

所有评论(0)