绝对位置编码和旋转位置编码
本文对比了Transformer中的两种位置编码方法:绝对位置编码(APE)和旋转位置编码(RoPE)。APE通过为每个位置分配固定或可学习的向量,直接加到词嵌入中,但存在外推性差的问题。RoPE则通过旋转Q/K向量的方式,使注意力分数天然编码相对位置关系,更适合长文本处理。文章详细分析了两种方法的实现原理、关键特性和适用场景:APE适合固定长度的非自回归任务,而RoPE在自回归语言模型和长上下文
1. Transformer 为什么需要位置?
自注意力(self-attn)本质上只看 token 之间的相似度(Q·K),不带顺序概念。
如果不给“第几个 token”的信息:
- “猫咬狗”和“狗咬猫”会非常像
- 长文本里“前面提到的那个东西”很难定位
所以要注入“位置信息”。
2. 绝对位置编码(Absolute Positional Encoding, APE)
2.1 核心想法
给每个位置一个“身份证向量”,把它加到 token embedding 上。
第 0 位是一个向量,第 1 位是另一个向量……
2.2 两种常见实现
(A) 可学习位置向量(learned APE)
- 直接有一个表
P[pos] ∈ R^d - 输入 token embedding
E[x_t] - 最终输入:
ht=E[xt]+P[t] h_t = E[x_t] + P[t] ht=E[xt]+P[t]
优点:简单、效果常常不错
缺点:超出训练长度就没定义(或需要插值/扩展),外推差
(B) Sinusoidal(固定三角函数,经典 Transformer)
Pt,2i=sin(t/100002i/d),Pt,2i+1=cos(t/100002i/d) P_{t,2i} = \sin(t / 10000^{2i/d}),\quad P_{t,2i+1} = \cos(t / 10000^{2i/d}) Pt,2i=sin(t/100002i/d),Pt,2i+1=cos(t/100002i/d)
同样是加法:
ht=E[xt]+P[t] h_t = E[x_t] + P[t] ht=E[xt]+P[t]
优点:无需学习、理论上可到任意长(能算出来)
缺点:实践里长外推也不一定稳;而且“加法注入”会被后续层混掉一部分
2.3 APE 的一个关键性质
APE 把“位置”塞进每个 token 的表示里。注意力算
Attn(i,j)∝(xi+pi)WQ⋅(xj+pj)WK \text{Attn}(i,j)\propto (x_i + p_i)W_Q \cdot (x_j + p_j)W_K Attn(i,j)∝(xi+pi)WQ⋅(xj+pj)WK
它会出现很多交叉项(内容-位置混在一起),但并不天然强调相对距离(i-j)。
3. 旋转位置编码(RoPE, Rotary Positional Embedding)
RoPE 是现在 LLM 里非常常见的(LLaMA 系、Qwen 系、很多 VLM)。
3.1 核心直觉(大白话)
不再把位置“加进去”,而是把 Q/K 向量按位置做一个“旋转”。
位置越往后,旋转角度越大。
这样 Q·K 的相似度会自然带上“相对位移”。
你可以把每两个维度当成一个平面坐标 (x, y),在这个平面里旋转一个角度 θ。
3.2 旋转是怎么做的(最简单的二维例子)
对一个 2D 向量 v=[v1, v2],旋转角 θ: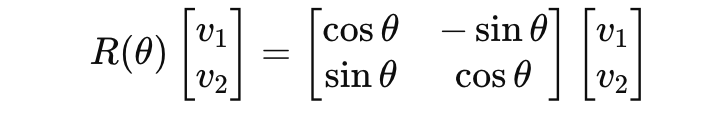
得到: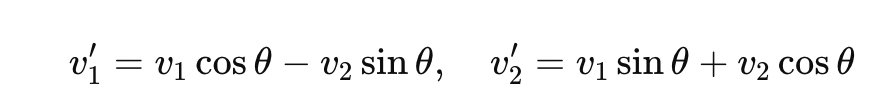
RoPE 就是把 Q 和 K 的每一对维度都做这种旋转。
3.3 θ(角度)怎么随位置变化?
每一对维度有不同频率(类似 sinusoidal 的频率分布):
θt,i=t⋅ωi,ωi=10000−2i/d \theta_{t,i} = t\cdot \omega_i,\quad \omega_i = 10000^{-2i/d} θt,i=t⋅ωi,ωi=10000−2i/d
然后对第 i 个二维子空间旋转 θ_{t,i}。
t:token 的位置索引(第几个 token)
d:模型的隐藏维度大小(或 head_dim)
i:维度编号 / 频率编号(第几对维度)
3.4 最关键性质:相对位移自然出现
RoPE 的魔法在于:
如果
qt′=R(t)qt,ks′=R(s)ks q_t' = R(t)q_t,\quad k_s' = R(s)k_s qt′=R(t)qt,ks′=R(s)ks
那么点积有这样的结构(直觉表达):
(qt′)⊤ks′;;依赖于;;(t−s) (q_t')^\top k_s' ;; \text{依赖于};; (t-s) (qt′)⊤ks′;;依赖于;;(t−s)
也就是说:注意力对分数会天然编码“相对距离”。
这就是 RoPE 被认为更适合长上下文的核心原因之一:
它不是“告诉你我在第 t 位”,而是让模型更容易学到“我和你差了多少位”。
4. APE vs RoPE:到底差在哪?
4.1 注入方式
- APE:位置向量“加”到 token embedding(进入网络前)
- RoPE:位置通过“旋转”作用在 Q/K(注意力内部)
4.2 绝对 vs 相对
- APE 更像“绝对坐标”(第 128 个 token)
- RoPE 更像“相对几何关系”(你在我前面 20 个 token)
4.3 长上下文外推
- learned APE:基本不行(长度外直接没 embedding)
- sinusoidal APE:可算但外推未必稳
- RoPE:外推更常用,但仍需要技巧(比如 NTK scaling / RoPE scaling)
4.4 和 KV cache 的适配
RoPE 特别适合自回归推理:
- 你每生成一步,只需要对新 token 的 Q/K 做对应位置的旋转
- cache 里存的 K 已经是旋转后的版本,位置一致性清晰
5. RoPE 的实现细节
5.1 典型实现套路
-
先算每个位置的
freqs = pos * inv_freq -
把 freqs “复制一份”拼成维度 d(因为每两维共用一个角度)
-
得到
cos, sin -
对 Q/K 做:
q_rot = q * cos + rotate_half(q) * sinrotate_half就是把(x,y)变成(-y,x)(对应旋转矩阵里的那项)
5.2 常见坑
- 维度配对:RoPE 要求 head_dim 是偶数
- 广播维度:cos/sin 的 shape 要能广播到
[batch, heads, seq, head_dim] - position_ids 的构造:训练和推理要一致(尤其是 KV cache 时 offset)
- scaling:长上下文要用 RoPE scaling,不然高频角度旋得太快导致失真
6. 绝对位置编码什么时候更好?RoPE 什么时候更好?
APE 更合适的场景
- 序列长度固定、不会外推
- 模型结构里你希望“位置就是一个 token-level 特征”
- 某些 encoder-only(BERT 风)模型仍常见 learned APE
RoPE 更合适的场景
- 自回归 LLM / 长上下文
- 需要更强的相对位置归纳
- 需要和 KV cache 稳定配合
7. “对比记忆法”
APE:位置是“加法特征”。
RoPE:位置是“几何变换”,作用在注意力相似度里。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)