MySQL进阶-4-SQL调优
说⼀下你了解的关于数据库优化要考虑哪⼏个层⾯的因素?介绍⼀下什么是索引?索引的作⽤是什么?索引⽤到了哪些数据结构?索引是如何的升查询效率的?什么时候应该创建索引?在哪些列上创建索引?索引越多越好吗?为什么?如何查看索引是否⽣效?知道执⾏计划(Explain)吗?它的作⽤是什么?执⾏计划结果中各列的含义了解吗?执⾏计划的type列的含义是什么?包含哪些内容?说说你熟悉的?如果type开中显⽰cons
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
(⾯试题)
-
说⼀下你了解的关于数据库优化要考虑哪⼏个层⾯的因素?
配置内存,缓冲区大小,索引,范式,日志 -
介绍⼀下什么是索引?
相当于目录,便于高速检索数据结构,通过这个数据结构组织数据 -
索引的作⽤是什么?
-
索引⽤到了哪些数据结构?
B+树,还有哈希的索引,但不支持范围查询 -
索引是如何的升查询效率的?
-
什么时候应该创建索引?
数据量比较多的时候,查询频繁的列 -
在哪些列上创建索引?
order by那些 -
索引越多越好吗?为什么?
每次创建一个都有索引树,都会占有磁盘,每次修改也要修改索引树,还要修改数据库,成本高,修改效率低了,但是查询效率还是高 -
如何查看索引是否⽣效?
-
知道执⾏计划(Explain)吗?它的作⽤是什么?
-
执⾏计划结果中各列的含义了解吗?
分析使用了索引吗,索引效率怎么样 -
执⾏计划的type列的含义是什么?包含哪些内容?说说你熟悉的?
-
如果type开中显⽰const意味什么?
-
如果Extra列中显⽰using index 意味什么?
-
谈谈如何使⽤ EXPLAIN 命令来分析查询执⾏计划?并举例说明如何根据执⾏计划进⾏优化?
-
什么是索引覆盖?
-
什么是回表查询?
-
如何避免全表扫描?
-
知道索引合并(优化)吗?
MySQL内部的优化机制,,,,就是各个查询索引树获取主键,最后取交集并集 -
什么是索引下推?
-
说⼀下索引失效的场景?
-
什么是最左匹配原则?
-
select count(*) 与 select count(1) 的区别?
1. 概述
• 优化涉及多个级别的配置、调优和性能评估。根据⾃⼰的职位(开发⼈员或DBA),可以在单个SQL 语句、整个应⽤程序、单个数据库服务器或多个联⽹数据库服务器的级别进⾏优化。
• 在数据库软件级别影响性能在有⼏个重要因素,例如表结构、查询语句和数据库配置。软件级别的因素会导致硬件级别的CPU和I/O操作。在优化数据库性能时,⾸先要学习软件级别的规则,当您成为专家时,就可以考虑如CPU周期和I/O层⾯的操作。但在真实的企业中,通常数据库遇到瓶颈⾸先考虑换⼀个⾼性能的存储设置,⽐如把机械硬盘换成SSD,再考虑软件层⾯,最后考虑操作系统层⾯的优化。
关于数据库级别的优化⼀般有⼏个重要的因素:
◦ 表结构是否正确:⽐如列是否指定了正确的数据类型。
◦ 表的类型是否正确:⽐如对于频繁更新的应⽤程序通常有很多表,表中有少量的列;对于数据分析的应⽤程序通常有少量的表,表中有很多列。
◦ 是否为适应的列建⽴索引来提升查询效率。
◦ 是否为每个表选择了适当的存储引擎,并利⽤了不同存储引擎的优点。
◦ 每个表是否选择了适当的⾏格式,⽐如归档数据可以选⽤压缩格式来减少空间提升I/O效率
◦ ⽤于缓存的内存⼤⼩是否合适,等等等等…
2. 优化索引
2.1 观看查询性能
我们知道InnoDB存储引擎使⽤B+树作为索引默认的数据结构来组织数据,为频繁查询的列建⽴索引可以有效的提升查询效率,那么如何利⽤索引编写出⾼效的SQL查询语句?以及如何分析某个查询是否⽤到了索引?当前的索引还有没有优化的空间?
为了⽅便演⽰先来构建⼀个100万条数据的表,运⾏下⾯这个存储过程,耗时较⻓,等待数据构建完成。
use topic01;
-- 修改SQL结束符
delimiter //
-- 创建存储过程
CREATE PROCEDURE p_init_index_data ()
BEGIN
-- 生成学号和主键
DECLARE id BIGINT DEFAULT 100000;
-- 年龄
DECLARE age TINYINT DEFAULT 18;
-- 性别
DECLARE gender BIGINT DEFAULT 1;
-- 班级编号
DECLARE class_id BIGINT DEFAULT 1;
-- 循环计算
DECLARE count INT DEFAULT 0;
-- 创建表
DROP TABLE IF EXISTS index_demo;
CREATE TABLE index_demo (
id bigint auto_increment,
sn varchar(10) NOT NULL,
name varchar(20) NOT NULL,
mail VARCHAR(20),
age TINYINT(1),
gender TINYINT(1),
password VARCHAR(36) NOT NULL,
class_id bigint NOT NULL,
create_time DATETIME NOT NULL,
update_time DATETIME NOT NULL,
PRIMARY KEY (id),
index (class_id)
);
-- 插入一条测试数据
INSERT INTO index_demo VALUES (100000, '100000', 'testUser', '100000@qq.com', 18, 1, UUID(), 1, NOW(), NOW());
-- 循环构建数据
WHILE count < 1000000 DO
-- ID和学号
SET id := id + 1;
-- 年龄
IF count % 10 = 0 THEN
SET age := age + 1;
END IF;
IF age > 50 THEN
SET age := 16;
END IF;
-- 性别
IF count % 3 = 0 THEN
SET gender := 0;
ELSE
SET gender := 1;
END IF;
-- 班级编号
SET class_id := class_id + 1;
IF class_id > 10 THEN
SET class_id := 1;
END IF;
-- 写入数据
INSERT INTO index_demo VALUES (id, id, CONCAT('user_',id), CONCAT(id,'@qq.com'), age, gender, UUID(), class_id, NOW(), NOW());
-- 更新count
SET count := count + 1;
END WHILE;
END //
-- 还原SQL结束符
delimiter ;
-- 调用存储过程,开始构建数据,大约20 - 100分钟左右
CALL p_init_index_data();
这样我们就生成了100万条数据了
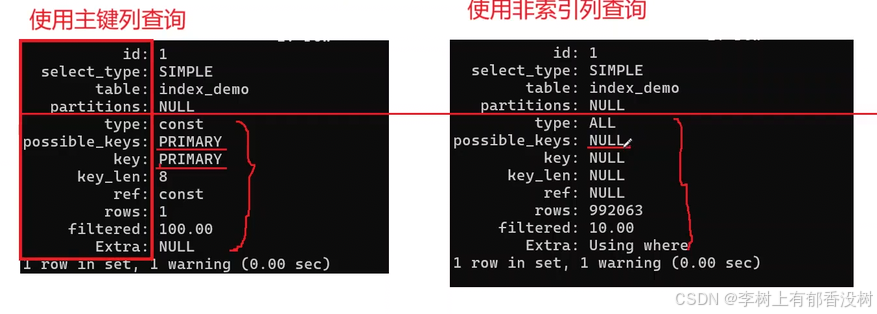
使⽤主键查询
• 使⽤主键查询⼀条记录,观察耗时
select id, sn, name, mail, age, gender, class_id from index_demo where id =1020000;

发现只耗时291ms
使⽤⾮索引列查询
• 使⽤⾮索引字段查询⼀条记录,⽐如使⽤sn,观察耗时
select id, sn, name, mail, age, gender, class_id from index_demo where sn ='1020000';

发现直接变成一秒多了
压测⼯具
• 使⽤MySQL⾃带的压测⼯具模拟多个客⼾端同时查询,观察测试结果
这个压测工具的作用就是模拟多个客户端
mysqlslap -uroot -p123456 --concurrency=100 --iterations=100 --create-schema="topic01" --engine="innodb" --number-of-queries=10000 --query "select id, sn, name, mail, age, gender, class_id from topic01.index_demo where id = 1020000;"
concurrency就是并发数,就是模拟多少个客户端
iterations表示一个客户端的查询次数
–create-schema是指定数据库名
–number-of-queries总共的查询次数的最大限制
我们可以直接进入容器里面执行这个命令,因为容器里面有mysql这些命令
但是容器内部没有mysqlslap这个命令,而且还没有apt这些命令,所以我们无法使用mysqlslap了
只能去本地虚拟机安装mysqlslap这个命令来执行了,或者WIndows上安装
但是WIndows比较麻烦,要配置bin,还是在虚拟机上安装吧
sudo apt update
sudo apt install -y mysql-client
# 查看版本,确认安装成功
mysqlslap --version
mysqlslap -h 192.168.26.4 -uroot -p123456 --concurrency=100 --iterations=100 --create-schema="topic01" --engine="innodb" --number-of-queries=10000 --query "select id, sn, name, mail, age, gender, class_id from topic01.index_demo where id = 1020000;"
在WIndows上使用ipconfig可以查看到ip
我们发现平均提交数据查询是1.9秒
所以很慢
为什么呢,因为是在虚拟机上
我们在WIndows上执行试一下
- 下载 MySQL 免安装压缩包
访问 MySQL 官方下载页:https://dev.mysql.com/downloads/mysql/
选择对应版本:
Operating System:Microsoft Windows
下载选项:Windows (x86, 64-bit), ZIP Archive(大小约 200MB,不是 MSI 安装包)
无需登录 / 注册,直接点击No thanks, just start my download.开始下载。
-
解压并找到 mysqlslap.exe
把下载的 ZIP 包解压到任意目录(比如C:\mysql-8.0.45-winx64);
进入解压目录的bin文件夹:C:\mysql-8.0.45-winx64\bin,里面能看到mysqlslap.exe(这就是核心可执行文件)。 -
使用 mysqlslap(两种方式)
方式 2:全局使用(任意目录都能执行,推荐)
如果想在任意目录直接用mysqlslap,需要把bin目录添加到系统环境变量:
复制bin目录路径(比如C:\mysql-8.0.45-winx64\bin);
右键「此电脑」→「属性」→「高级系统设置」→「环境变量」;
在「系统变量」里找到Path,点击「编辑」→「新建」,粘贴刚才复制的路径;
点击「确定」保存,重启 CMD/PowerShell;
任意目录执行mysqlslap --version,能正常输出即配置成功。
配置好环境变量
在cmd中,记得重新打开cmd
mysqlslap -uroot -p123456 --concurrency=100 --iterations=100 --create-schema="topic01" --engine="innodb" --number-of-queries=10000 --query "select id, sn, name, mail, age, gender, class_id from topic01.index_demo where id = 1020000;"
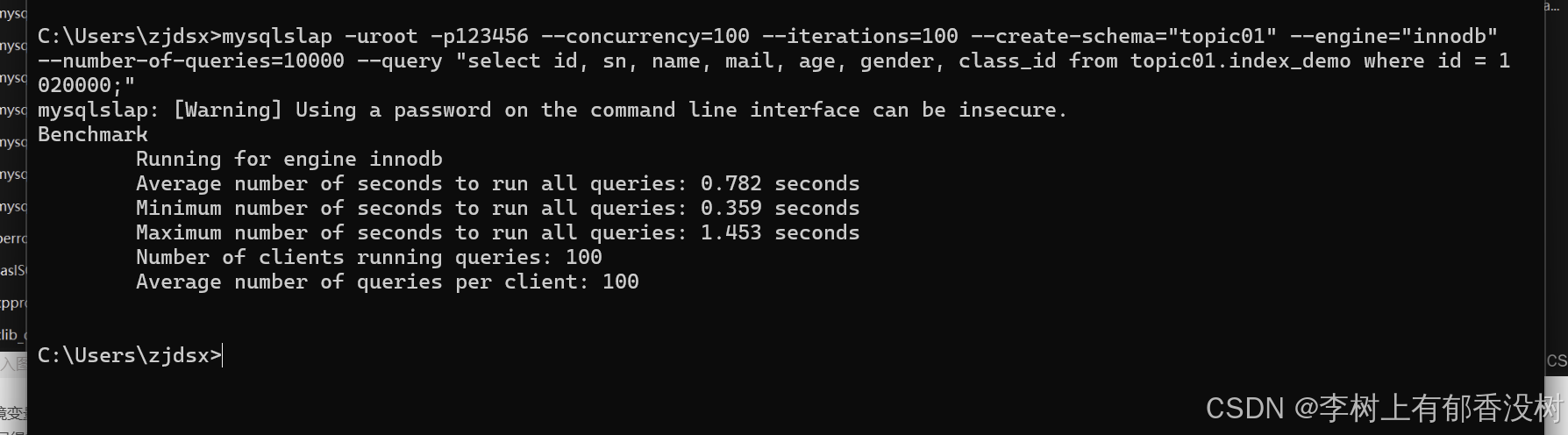
发现WIndows就快多了,但还是0.7 秒平均
mysqlslap -uroot -p123456 --concurrency=30 --iterations=3 --create-schema="topic01" --engine="innodb" --number-of-queries=90 --query "select id, sn, name, mail, age, gender, class_id from topic01.index_demo where sn = '1020000';"
这个是非主键查询
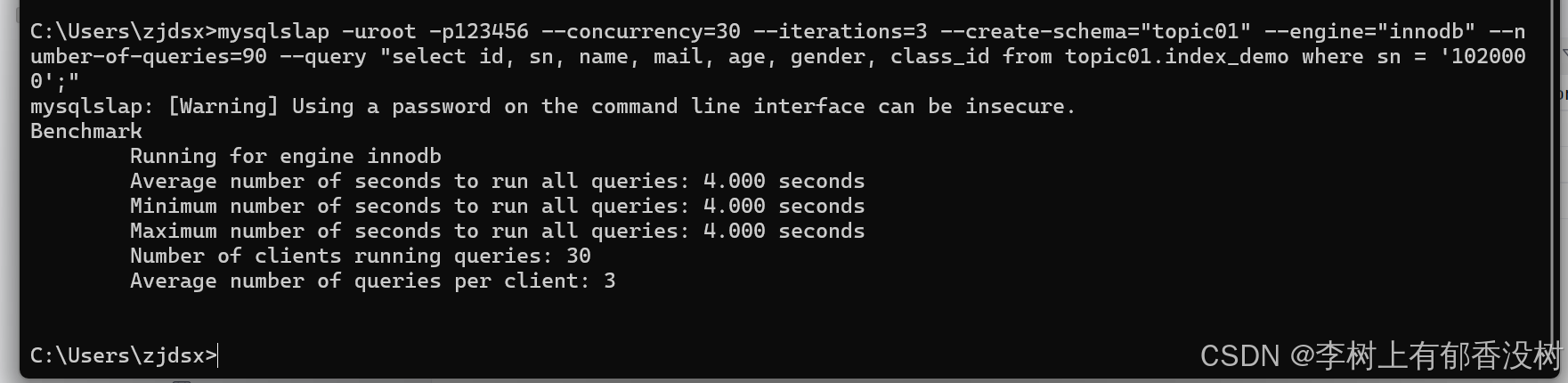
可以看到查询时间随着访问量的增⼤还迅速增⾼
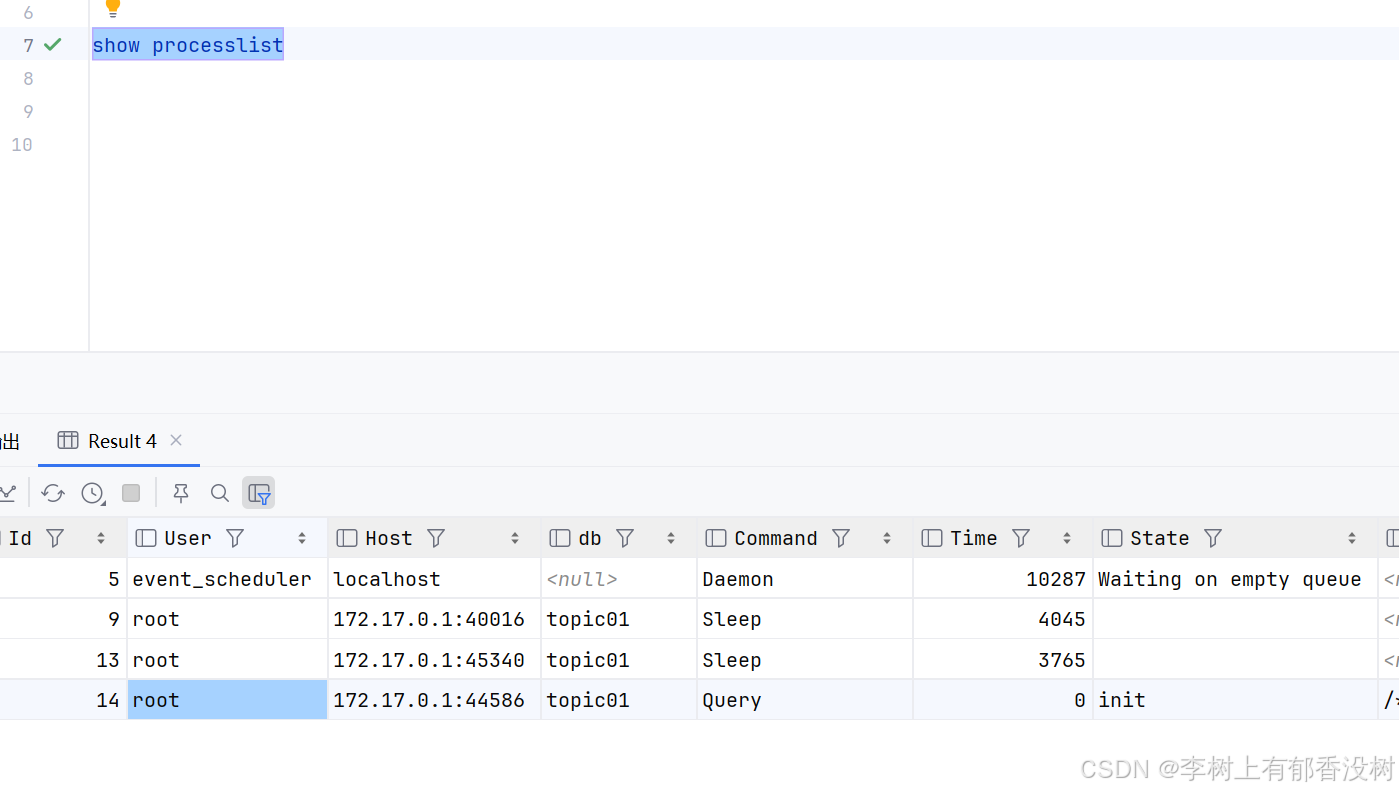
• 同时也可以使⽤ show processlist 显⽰当前正在运⾏的线程,以下是并发查询的线程列表
2.2 使用执行计划
在执⾏ SELECT , DELETE , INSERT , REPLACE ,和 UPDATE 之前都可以⽤执⾏计划分析SQL语句的执⾏情况,以便优化SQL语句。并不会真正执行SQL,只是对SQL进行分析,返回分析结果
具体用法就是在正常的SQL前面加上一个explain
EXPLAIN select id, sn, name, mail, age, gender, class_id from index_demo where id = 1020000
G的意思就是以行的形式显示

EXPLAIN select id, sn, name, mail, age, gender, class_id from index_demo where sn = '1020000'

对比一下
执⾏计划字段说明
列名 说明
id SELECT标识符
select_type SELECT类型
table 查询的表
partitions 查询的分区
type JOIN类型
possible_keys 可能选择的索引
key 实际选择的索引
key_len 索引⻓度
ref 与索引⽐较的列
rows 估算要检查的⾏数
filtered 按条件筛选⾏的百分⽐
Extra 附加信息
type字段就是告诉我们执行效率的关键字段
2.3 执行计划字段说明
id列
SELECT标识符,查询语句中SELECT的序号。如果整条查询语句中包含⼦查询或合并查询,则每个查询的编号依次递增
⼦查询
explain select * from student where id = (select id from student where name = '宋江')

这个就显示了两条记录了
SUBQUERY表示是子查询,PRIMARY表示是主键查询
合并查询
explain select * from student union select * from student

第一个PRIMARY表示是主键查询
select_type列
SELECT的类型,可以是下表中的任何⼀种(部分):
select_type 值 说明
SIMPLE 简单SELECT(不使⽤UNION或⼦查询)
PRIMARY 外层查询
UNION UNION中的第⼆个及之后的SELECT语句
UNION RESULT UNION的结果。
SUBQUERY ⼦查询中
INSERT INSERT 语句
UPDATE UPDATE 语句
DELETE DELETE 语句
table列
• 查询时数据⾏所指在表的名称
• <unionM,N> : 表⽰合并查询⽤到的表,M 和 N是id列的值
• <subqueryN> : 表⽰⼦查询⽤到的表,N是id列的值
partitions列
查询时数据⾏所在的分区,对于⾮分区表,值为 NULL 。
type列
连接类型,稍后重点讨论。
possible_keys列
possible_keys 列显⽰SQL语句可能会⽤到的索引,如果该列为 NULL 则SQL语句没有可⽤的索引。这时可以检查 WHERE ⼦句中引⽤的列,并考虑是否需要在这些列上建⽴索引来提⾼查询的性能。
key列
key 列表⽰SQL语句实际使⽤的索引,如果该列为NULL, MySQL则SQL语句没有可⽤的索引
key_len列
key_len 列表⽰SQL语句使⽤索引的字节⻓度,如果 key 列为 NULL ,则 key_len 列也为NULL 。
ref列
ref 列显⽰在查询过程中哪些列或常量与key列中指定的索引进⾏⽐较。如果值是 func ,则使⽤的值是某个函数的结果,要查看具体使⽤了哪个函数,请使⽤ EXPLAIN 后⾯的 SHOW WARNINGS 来查看扩展的 EXPLAIN 输出。
rows列
rows 列表⽰SQL语句执⾏查询需要检查的⾏数,对于InnoDB表这是⼀个估计值。数据越⼩效率越⾼
filtered列
• filtered 表⽰按表条件筛选的表中数据⾏的百分⽐。最⼤值是100,这意味着没有对数据⾏进⾏过滤。从100开始递减的值表⽰过滤量在增加。
• 如果Rows列显⽰的预估⾏数为1000,filtered为50.00(50%),Rows × filtered的结果是根据条件过滤后的⾏数,也就是符合查询条件的记录数为1000 × 50% = 500⾏
• 这个值越⼤表⽰过滤的效率越⾼
Extra列
Extra 列包含MySQL如何解析查询语句附加信息。稍后讨论
2.4 type列详解
EXPLAIN输出的type列描述了表是如何连接的,性能从最好到最差的排序如下:
◦ system
◦ const
◦ eq_ref
◦ ref
◦ fulltext
◦ ref_or_null
◦ index_merge
◦ unique_subquery
◦ index_subquery
◦ range
◦ index
◦ ALL
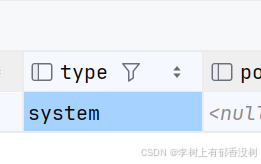
system
• 表中只有⼀⾏数据,不⽤任何扫描,性能极⾼,是const类型的特殊情况,而且必须是MyISAM引擎
CREATE TABLE test_system_myisam (
id INT PRIMARY KEY,
name VARCHAR(255)
) ENGINE = MyISAM;
INSERT INTO test_system_myisam VALUES (1, 'name');
-- MyISAM表中只有一行记录时type=system
explain select * from test_system_myisam;
CREATE TABLE test_system_innodb (
id INT PRIMARY KEY,
name VARCHAR(255)
) ENGINE = innodb;
INSERT INTO test_system_innodb VALUES (1, 'name');
-- 观察Innodb表,并不会显示system
explain select * from test_system_innodb;
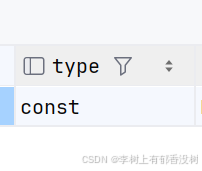
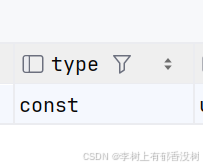
const
• 当查询中的条件通过主键索引或唯⼀索引与常量进⾏⽐较时,结果最多有⼀个匹配的⾏,类型显⽰为 const ,这种类型查询性能极⾼,且只会返回⼀⾏数据。
explain select id, sn, name, mail, age, gender, class_id from index_demo where id = 1020000
• 为sn列创建唯⼀索引
alter table index_demo add unique un_sn (sn) ;
show index from index_demo;
• 在WHERE⼦句中使⽤sn作为条件查询
EXPLAIN select id, sn, name, mail, age, gender, class_id from index_demo where sn = '1020000'
eq_ref
• eq_ref 是除了system类型和const类型之外最⾼效的连接类型。应⽤于多表连接的场景,表关联条件是主键索引或唯⼀⾮空索引时使⽤等号 ( = ) 进⾏索引列的⽐较,每⾏只匹配⼀条记录。
就是一对一关系,两个表的键都必须是唯一索引,非空索引,因为是唯一索引,所以只能一对一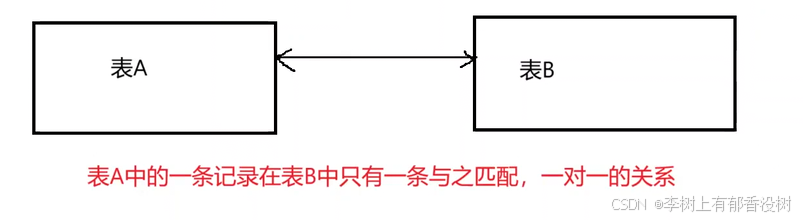
-- 创建用户表, 与student表是一对一关系
drop table if exists account;
create table account (
id bigint primary key auto_increment,
username varchar(20) not null,
password varchar(32) not null,
student_id bigint not null,
UNIQUE (student_id)
);
-- 写入数据
insert into account (username, password, student_id) values ('user_001', 'pwd_123456', 1);
insert into account (username, password, student_id) values ('user_002', 'pwd_123456', 2);
insert into account (username, password, student_id) values ('user_003', 'pwd_123456', 3);
insert into account (username, password, student_id) values ('user_004', 'pwd_123456', 4);
insert into account (username, password, student_id) values ('user_005', 'pwd_123456', 5);
insert into account (username, password, student_id) values ('user_006', 'pwd_123456', 6);
insert into account (username, password, student_id) values ('user_007', 'pwd_123456', 7);
insert into account (username, password, student_id) values ('user_008', 'pwd_123456', 8);
explain select * from student s, account a where s.id = a.id

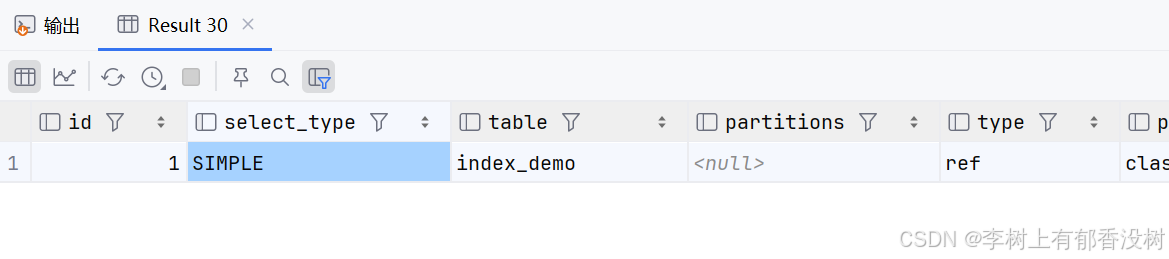
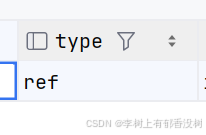
ref
• ref 表⽰SQL语句中使⽤了普通索引,返回的结果可能是多⾏组成的结果集。
这个就不是唯一索引,意思就是值可以重复,但是必须非空
因为不是唯一索引—》结果集,或者是一对多或者多对一关系
explain select * from index_demo where class_id = 1
• 为name列创建普通索引
create index idx_name on index_demo(name);
show index from index_demo
• 以name为条件查询并查看执⾏计划
explain select * from index_demo where name = 'user_1020021'
select id, sn, name, mail, age, gender, password, class_id from index_demo where name = 'user_1020021'

fulltext
使⽤全⽂索引时显⽰为 FULLTEXT,文章作为索引
这⾥不做过多讨论
ref_or_null
• 类型与ref类似,但包括对null值的检索,索引列必须是可以为空的列,而且不唯一
• 先把name列修改为可以为空
alter table index_demo modify name varchar(20) null;
• 修改某⾏数据的name为空
update index_demo set name = null where id = 100000;
• 以name列为条件进⾏查询,同时查找为null的列
explain select * from index_demo where name = 'user_1020021' or name is null
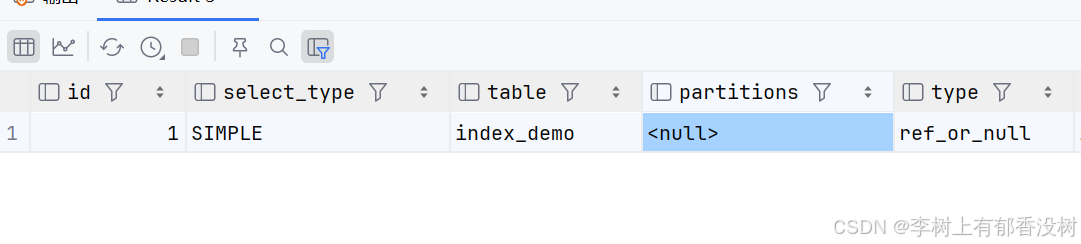
不加name is null就是ref类型
index_merge
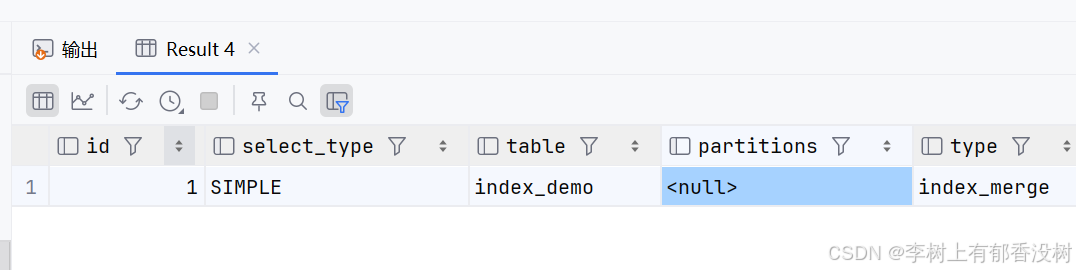
• 在查询中使⽤了多个索引,OR 两边必须是单独索引,最终通过不同索引检索数据,然后对结果集进⾏合并,Key_len显⽰最⻓的索引⻓度。
• where条件中使⽤name和id同时进⾏查询
explain select * from index_demo where name = 'user_1020021' or id = 1030300
unique_subquery
• ⽤eq_ref 替换⼦查询中的IN,表达式如下所⽰
unique_subquery
• ⽤eq_ref 替换⼦查询中的IN,表达式如下所⽰
-- ⼦查询中返回的是外层表的主键索引或唯⼀索引
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery
• 类似于unique_subquery,只不过⼦查询中返回的是普通索引列,表达式如下所⽰:
-- ⼦查询中返回的是外层表的普通索引
value IN (SELECT key_column FROM single_table WHERE some_expr)
range
使⽤索引列进⾏范围查询,当使⽤<>、>、>=、<、<=、is NULL、<=>、BETWEEN、LIKE或IN()操作符,索引列与常量进⾏⽐较时为range:
-- id在⼀个范围之内
explain select * from index_demo where id > 110000 and id < 200000
-- 条件中使⽤IN
explain select * from index_demo where id in (100000, 110000, 120000)
-- 条件中使⽤Like
explain select id from index_demo where name like 'user_10000%'
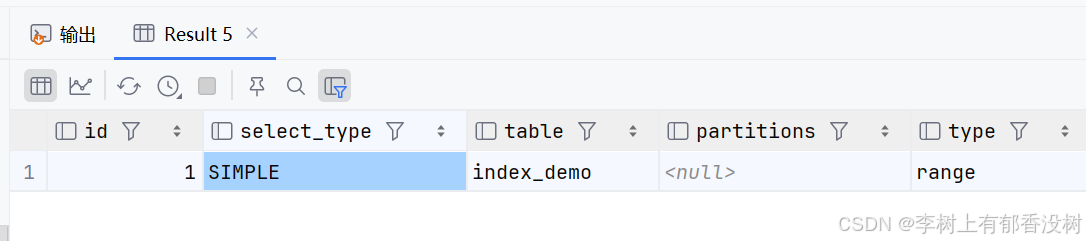
使用常量字符串+通配符=====确定了范围
但是通配符+字符串----》没有确定范围,不是range,就是完全扫描
explain select id from index_demo where name like '%user_10000'

就是扫描全索引了
index
• 扫描整个索引树⽽不扫描整个表,⽐如只使⽤索引排序⽽不使⽤条件查询时
explain select * from index_demo order by sn limit 10
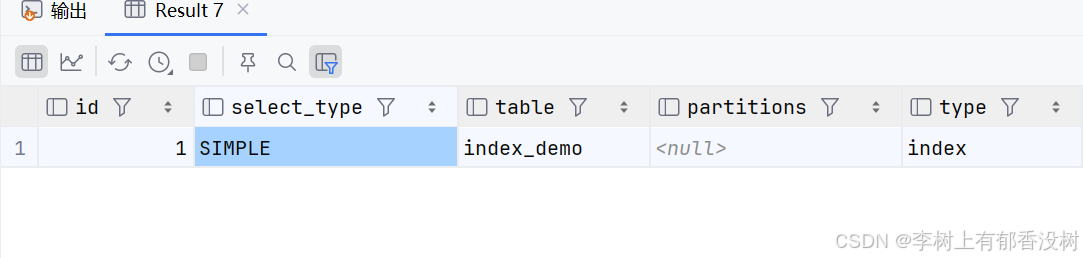
explain select * from index_demo order by sn limit 10000
这个是因为mysql觉得全表扫描更快,所以就不进行全索引的扫描了
ALL
• 最差的情况,表⽰MySQL必须对全表进⾏逐⾏扫描才可以以找到匹配⾏,遇到这种情况通常建议在查询的列上加索引来避免全表扫描。
explain select * from index_demo where age = 18
这个就是使用没有索引的列来查询
explain select * from index_demo where id <1000 and age = 18

这个是因为先进行的id <1000
案例分析
• 对于开始的两条SQL语句对照执⾏计划字段说明可以得到以下结果:
◦ 使⽤主键查询的语句:查询标识符为1,查询的是index_demo表中的数据,JOIN类型是常量级别,可能⽤到的索引是主键索引,实际⽤到的索引是主键索引,索引⻓度为8字节,索引⽐较的列是常量,估算要检查的⾏数为1⾏,按条件筛选率是100%。
◦ 使⽤⾮索引列查询的语句:查询标识符为1,查询的是index_demo表中的数据,JOIN类型是全表扫描,没有⽤到索引,估算要检查的⾏数为982666⾏,按条件筛选率仅为10%。
• 可以看到⼀个⽤到了索引,⼀个没有⽤到索引,在真实执⾏相应查询语句的时候,从结果耗时也可以看出⽤到索引的效率明显要⾼于没有⽤到索引的查询,所以在编写SQL语句时,尽量使⽤索引。
2.5 Extra 列详解
Extra 列中如果出现 Using filesort 和 Using temporary ,将会对查询效率有⽐较严重的影响。
就是临时表和文件来排序,就是对非索引和无序的列进行排序的时候,先把数据加载到临时表中,在进行排序,如果临时表这个内存存不下的时候,就会存储到临时文件中去排序,这个是很慢的,这个是磁盘io
Using temporary
• 当使⽤⾮索引列进⾏分组时,会⽤临时表进⾏排序,优化时可以考虑为分组的列加索引
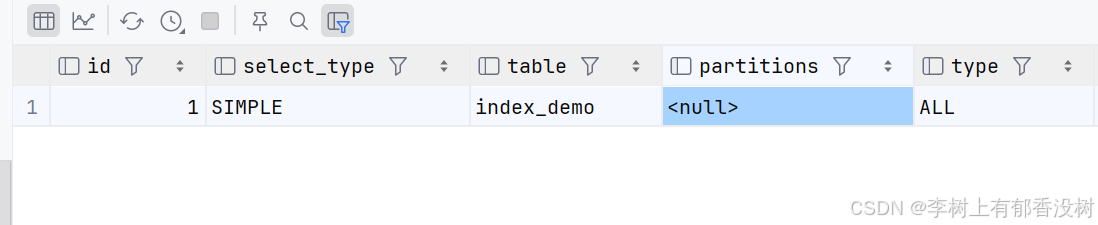
explain select avg(age) from index_demo group by gender
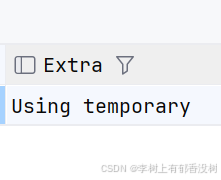
创建了索引,那么这个字段就是有序的,就不用使用临时表了
这个也是使用临时表
Using filesort
• 当使⽤⾮索引列进⾏排序时会⽤到⽂件内排序,优化时可以考虑为排序的列加索引
explain select * from index_demo where id < 1020000 order by age limit 10
就是临时表存不下了,在内存中存不下,所以去文件中了,这个一看就是大范围的排序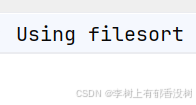
Using where
• 当使⽤⾮索引列进⾏检索数据,且进⾏了全表扫描
explain select * from index_demo where gender = 1
• 当使⽤索引列进⾏检索数据时,进⾏范围查找,此时扫描的是索引树
explain select * from index_demo where id < 102000
扫描整个索引树的时候,也是这个Using where
Using index
发⽣索引覆盖时显⽰using index,表⽰这是⼀个⾼效查询
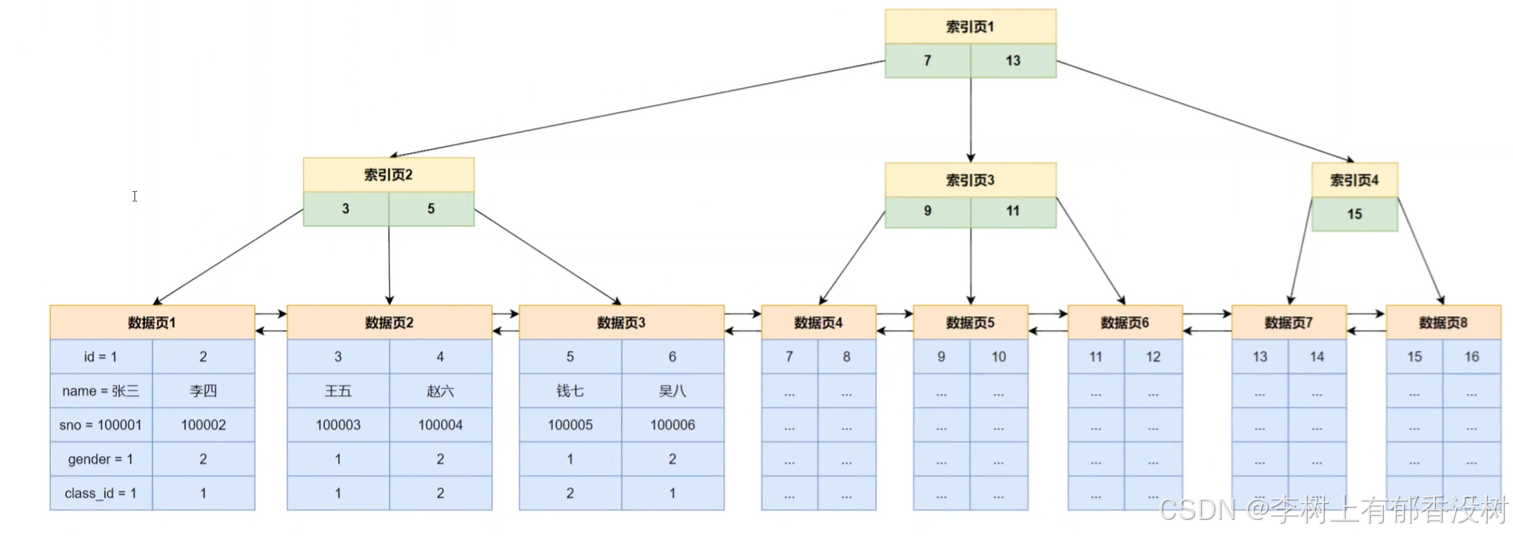

索引覆盖
• 要使⽤的索引中包含要查询列,这时直接返回索引中列的值,⽽不⽤回表查询
• 创建⼀个复合索引,包含mail, age, create_time
create index idx_mail_age_classId on index_demo(mail, age, class_id);
show index from index_demo;
• 复合索引的索引树中的叶⼦结点中包含name, age, create_time列值,以及主键的值,当⼀个查询使⽤这个复合索引进⾏检索,并且查询列表中只有name列、age列、create_time列和主键列的全部或其中之⼀时,可以直接从索引树中返回数据,这个现象叫做索引覆盖,如下所⽰
explain select mail,age,class_id from index_demo where mail ='1020000@qq.com'
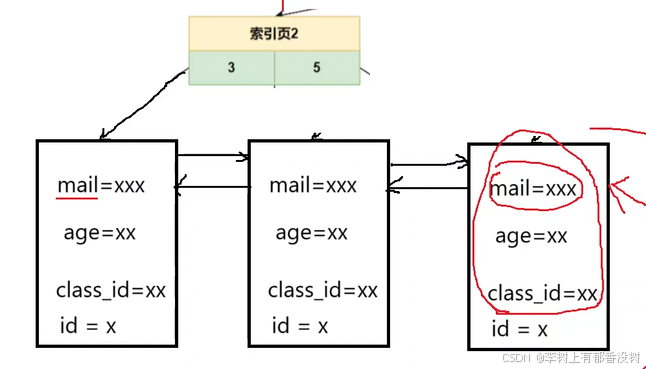
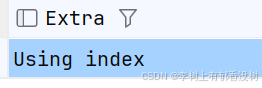
Extra: Using index – using index 表⽰发⽣了索引覆盖
回表查询
• 当使⽤索引检索数据时,查询的列不只包含索引列,这时需要通过索引中记录的主键值到主表中进⾏查询,这个现象叫做回表查询
explain select * from index_demo where mail = '1020000@qq.com'
Extra: NULL – 没有using index标识

效率不如索引覆盖
总结

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)