IPT技术详解:如何实现纳秒级精度路径性能测量
IPT(带内路径遥测)通过将网络测量任务内嵌至数据报文本身,让业务流在转发过程中自动收集并携带每一跳设备的实时状态信息(如时延、队列深度)。在超大规模AI训练集群中,IPT能精准定位导致All-Reduce同步延迟的网络瓶颈,极大缩短故障排查时间,保障万卡集群算力高效稳定输出。
在分布式计算、人工智能训练和实时交互应用日益成为主流的今天,网络已从底层连接设施演进为决定业务性能与效率的核心支柱。
然而,传统的网络监控手段在面对复杂、动态、高性能的网络环境时,常陷入“盲人摸象”的困境:我们能知道网络“病了”,却难以快速诊断“病灶”何在。IPT(In-band Path Telemetry,带内路径遥测)技术标志着网络可观测性的一次范式革命,它将测量能力注入数据报文本身,为构建数据平面的“全景数字孪生”提供了可能。(构建一个与物理网络实时同步、全要素映射、且具备深度洞察与模拟能力的虚拟副本。)
困境与革新:为何我们需要IPT?
传统网络监控主要依赖“带外遥测”(如SNMP、CLI抓取、NetFlow)和主动探测(如ICMP Ping)。这些方法存在固有局限性:
- 采样与实时的矛盾:带外数据多为周期性采样,可能错过瞬间的微突发拥塞或毫秒级延迟抖动,而这些正是影响AI训练同步和金融交易的关键。
- 聚合与精度的妥协:流量聚合分析(如sFlow)损失了单流粒度,无法追踪特定关键业务流的精确路径与性能。
- 表象与根因的距离:网管系统告警“服务器间延迟高”,但运维人员仍需耗费大量时间逐跳登录设备排查,定位效率低下,平均修复时间(MTTR)长。
IPT的核心革新在于 “将测量仪器植入数据流” 。它要求支持INT的设备(交换机、路由器)在转发特定报文时,依据报文内的指令,将其本地状态(如设备ID、进出端口、时间戳、队列深度等)直接写入该报文。最终,单个报文携带着其完整路径的“旅行日记”到达收集点,实现与业务流量完全同步的、逐跳的、实时的路径状态洞察。
技术深潜:IPT如何工作?
IPT的实现非侵入式地嵌入了转发过程,其技术栈包含几个关键层面:
报文格式与指令集
IPT并非定义全新的报文类型,而是在现有以太网/IP报文基础上,插入一个轻量化的INT头部(Shim Header)。该头部包含关键的控制信息:
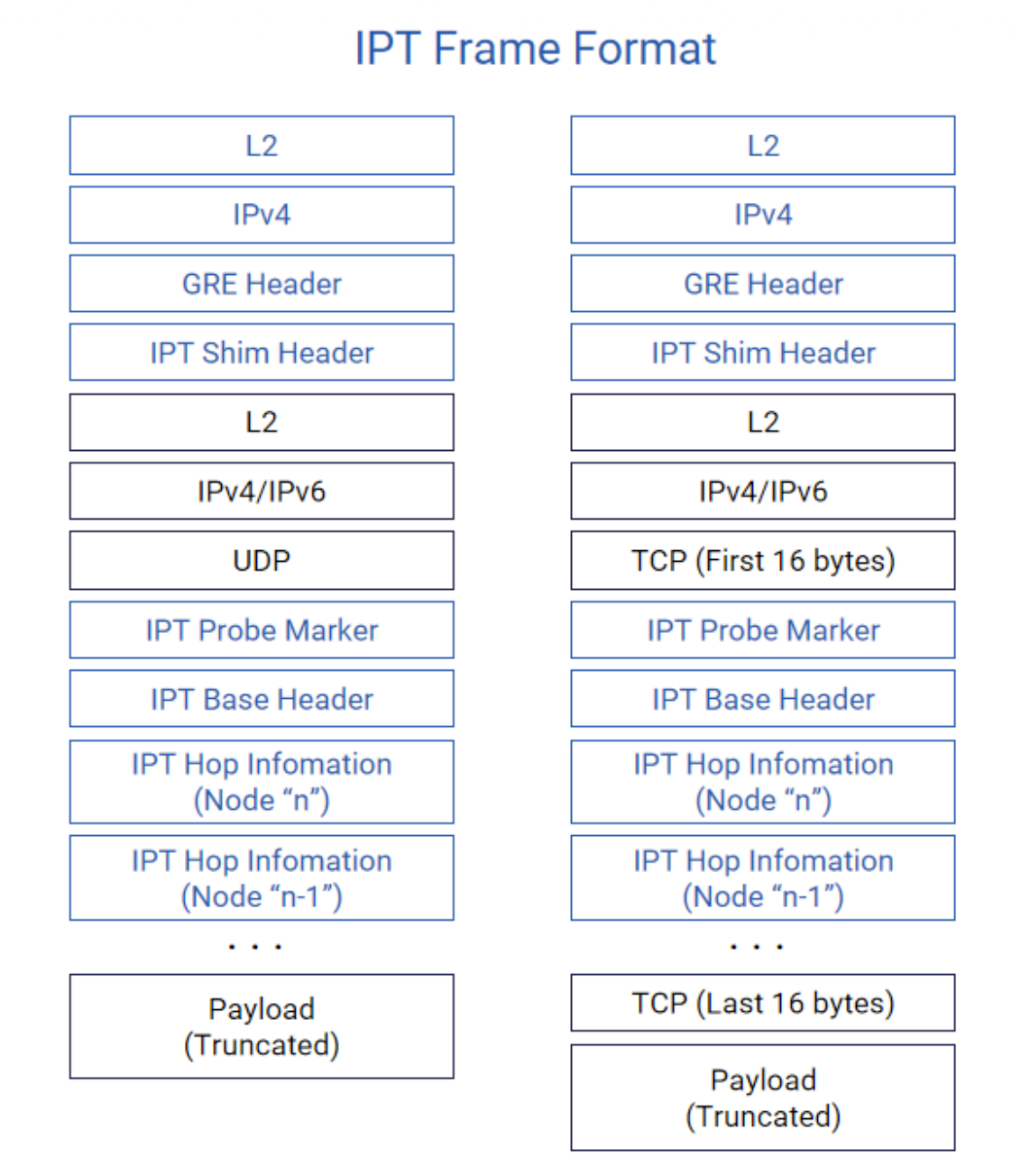
- 指令域:指明需要收集的数据类型(如只需时戳,或还需队列深度、链路利用率等)。
- 元数据空间:预留出用于各跳设备填充信息的可扩展字段序列。
数据平面处理流程
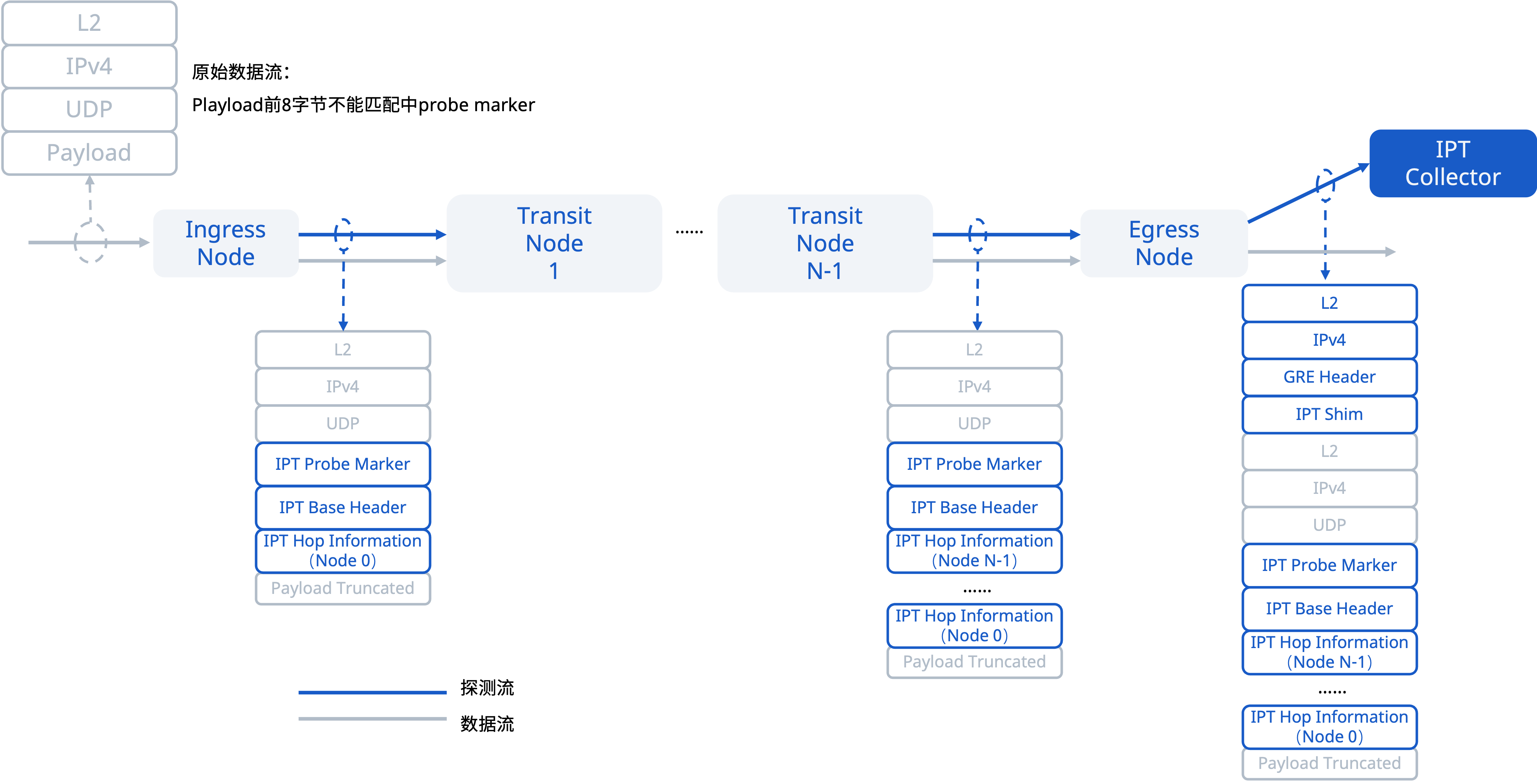
- 生成与注入:由网络边缘设备(如支持INT的交换机)根据策略,对选定的业务流进行采样或克隆,并插入INT头部,生成INT探测包。
- 路径收集:网络中每一台支持INT的设备(称为INT节点)在转发该报文时,硬件数据平面识别INT头部,并根据指令,以纳秒级精度将本跳信息(如Ingress/Egress端口ID、设备ID、进入和离开的时间戳、出口队列深度等)顺序填入元数据区。
- 封装与上报:报文到达路径终点或指定的出口节点时,该节点将完整的INT元数据(可能经过封装,如通过GRE隧道)发送至远程遥测收集器进行分析。
从“可视”到“可行动”的洞察
-
亚秒级故障根因定位:当数据库查询变慢或视频会议卡顿时,IPT报告能直接揭示是“数据中心A Spine交换机第5端口队列3存在持续50ms缓冲”,而非仅提示“网络延迟高”。这将MTTR从小时级降至分钟甚至秒级。
- 性能基线与异常检测:通过对关键应用流的持续监测,建立包括逐跳延迟、抖动在内的动态性能基线。利用机器学习,可自动识别偏离基线的异常模式,实现预测性运维,在用户感知前发现问题。
IPT提供的实时、精细数据是SDN控制器和AIOps平台的“黄金输入”。控制器根据IPT报告的实时拥塞热点,动态计算并下发新路径,实现流量调优。为金融交易、云游戏等业务提供端到端、逐跳的SLA达标证据,实现基于数据的服务保障。
典型应用场景 - 队列状态动态感知
在万卡GPU集群中,海量All-Reduce操作使得网络成为训练扩展性的关键瓶颈。
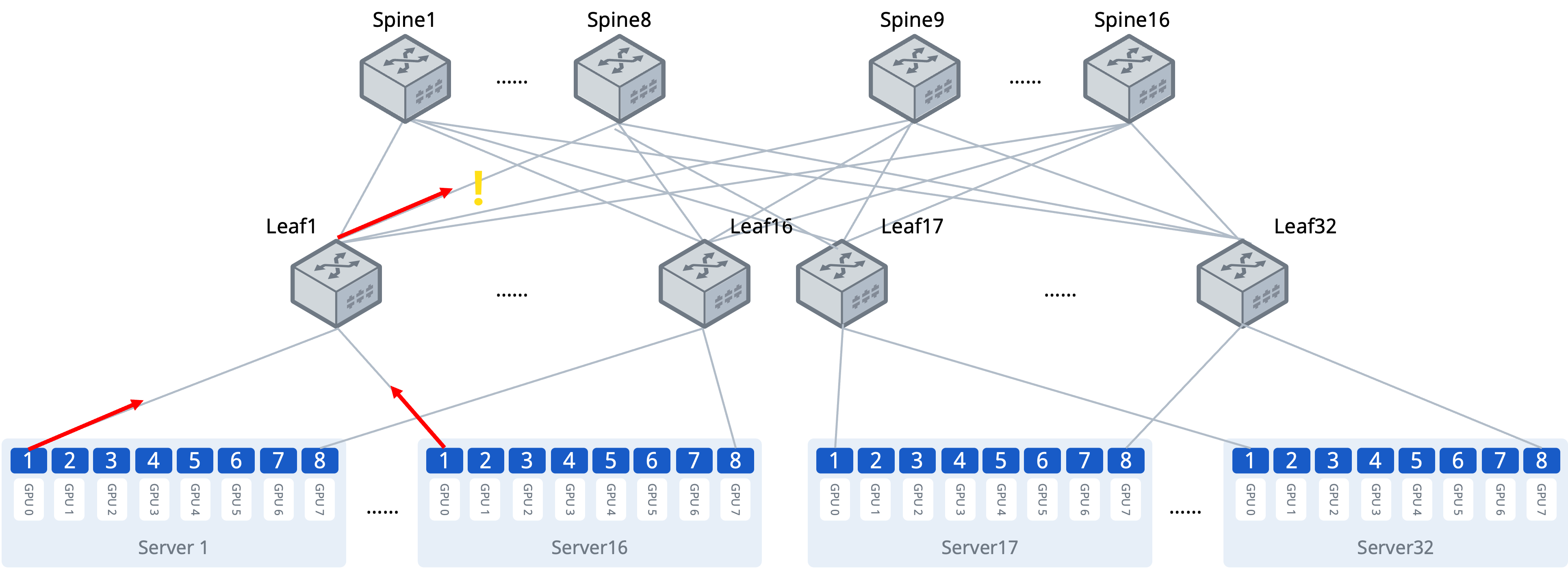
多台GPU服务器通过同一交换机端口发送数据
在超大规模GPU集群中,多台服务器的高速数据流常汇聚于同一上游交换机端口,极易因微突发流量超出预期规划而导致出方向队列瞬时拥塞。这种拥塞具有隐蔽性强、持续时间短、但危害大的特点,会直接造成All-Reduce等集合通信操作的同步延迟陡增,进而拖慢整个训练任务。
基于IPT的实时数据,运维体系可实现从被动响应到主动预防的转变。秒级锁定引发拥塞的具体交换机、端口及队列,并关联至产生该流量的GPU服务器或任务。IPT探测数据包携带队列占用大小、QP(Queue Pair)等信息,运维人员可快速识别拥塞队列,动态调整缓冲区分配策略,例如为易拥塞队列增加突发吸收容量,或为关键训练流量配置独立的优先队列。分析拥塞模式历史数据,指导网络架构调整或流量工程策略,从根源上避免拥塞热点形成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 6
6 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)