Gen_AI 第五课 深度学习&机器学习基本概念
摘要:生成式AI通过函数f(x)实现输入到输出的转换。机器学习分为三步:(1)设定评估目标(如最小化Loss);(2)确定函数选择范围;(3)优化函数参数。优化方法包括暴力求解和梯度下降法,后者可能陷入局部最优或鞍点。采用Batch和Shuffle技术可加速训练。需通过训练-验证-测试流程评估模型,注意过拟合问题,可通过调整函数范围或EarlyStopping解决。实践建议从简单模型开始,逐步增加
生成式人工智能的基本原理
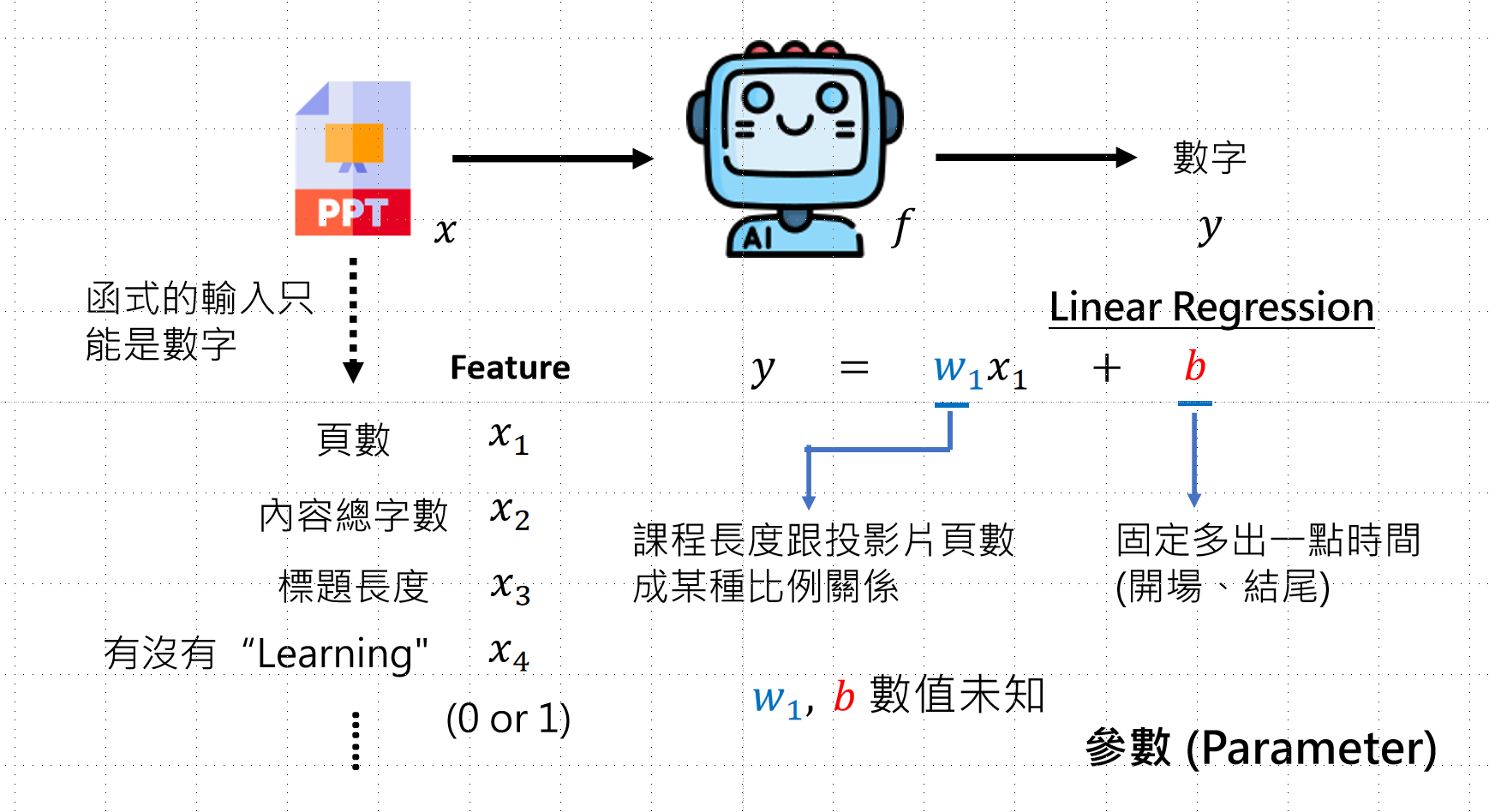
x → f(x):中间通过函数 f 进行转换
找出 f 函数 就是机器学习的内容
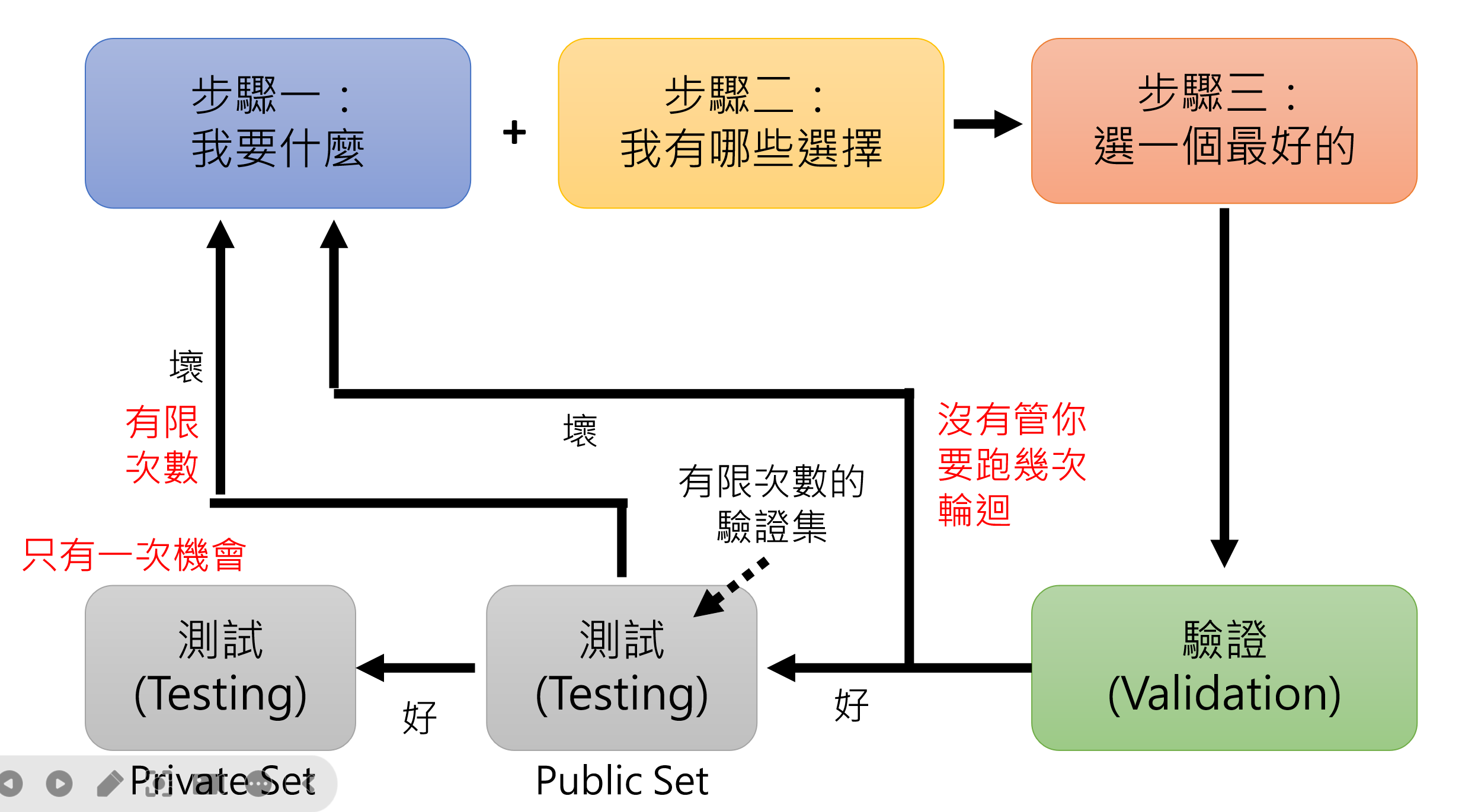
找出函数的步骤(3+1)
第一步:确认目标
- 给一个函数,评估这个函数是否满足需求
- 参考第四课:模型能力评估
- 用给定的函数观察表现,根据得分判断(如 MSE 分数)
- Loss 越小越好,Objective 越大越好
- 确定优化目标(例如:让 Loss 最小)
第二部:我有哪些选择
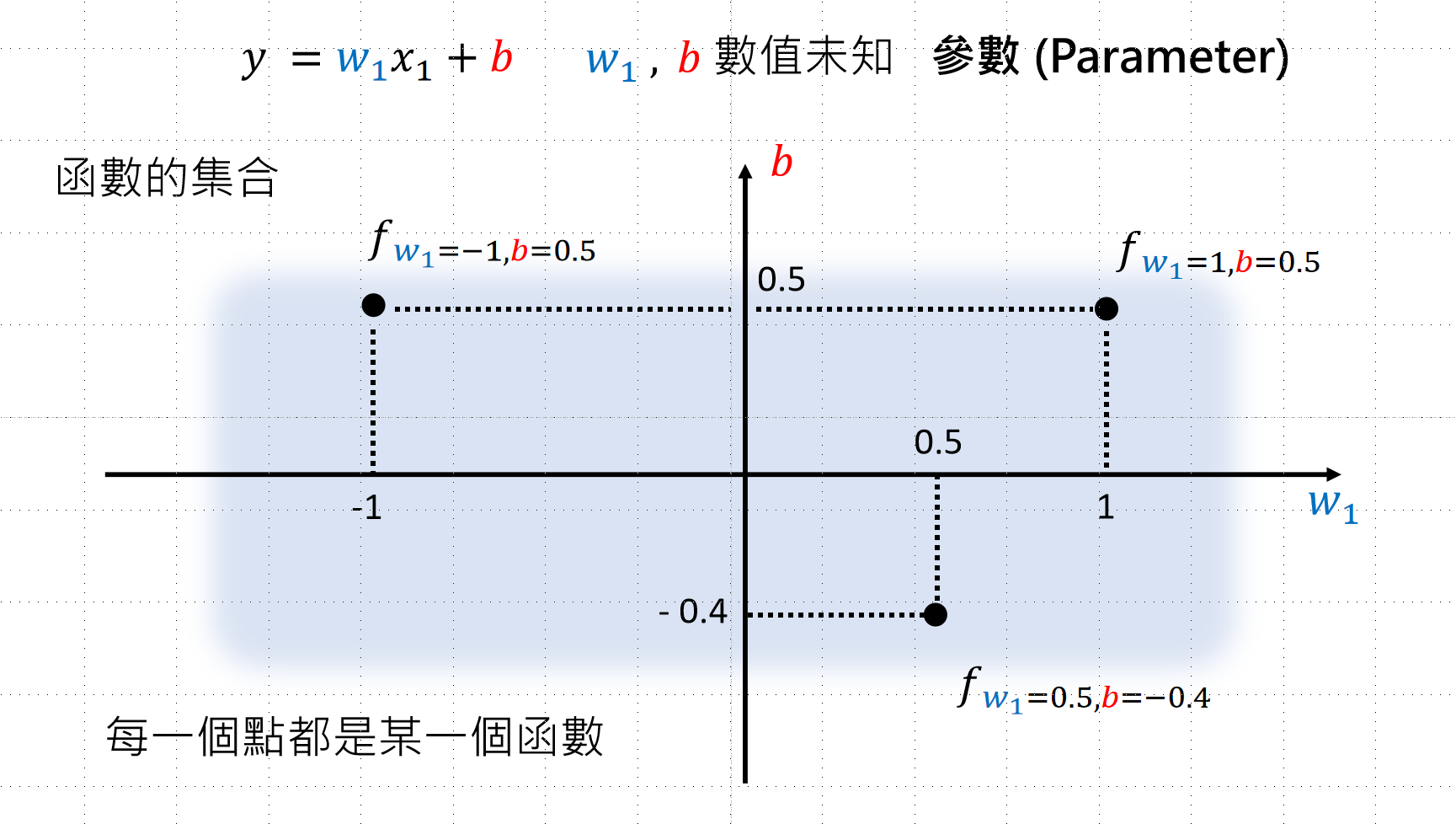
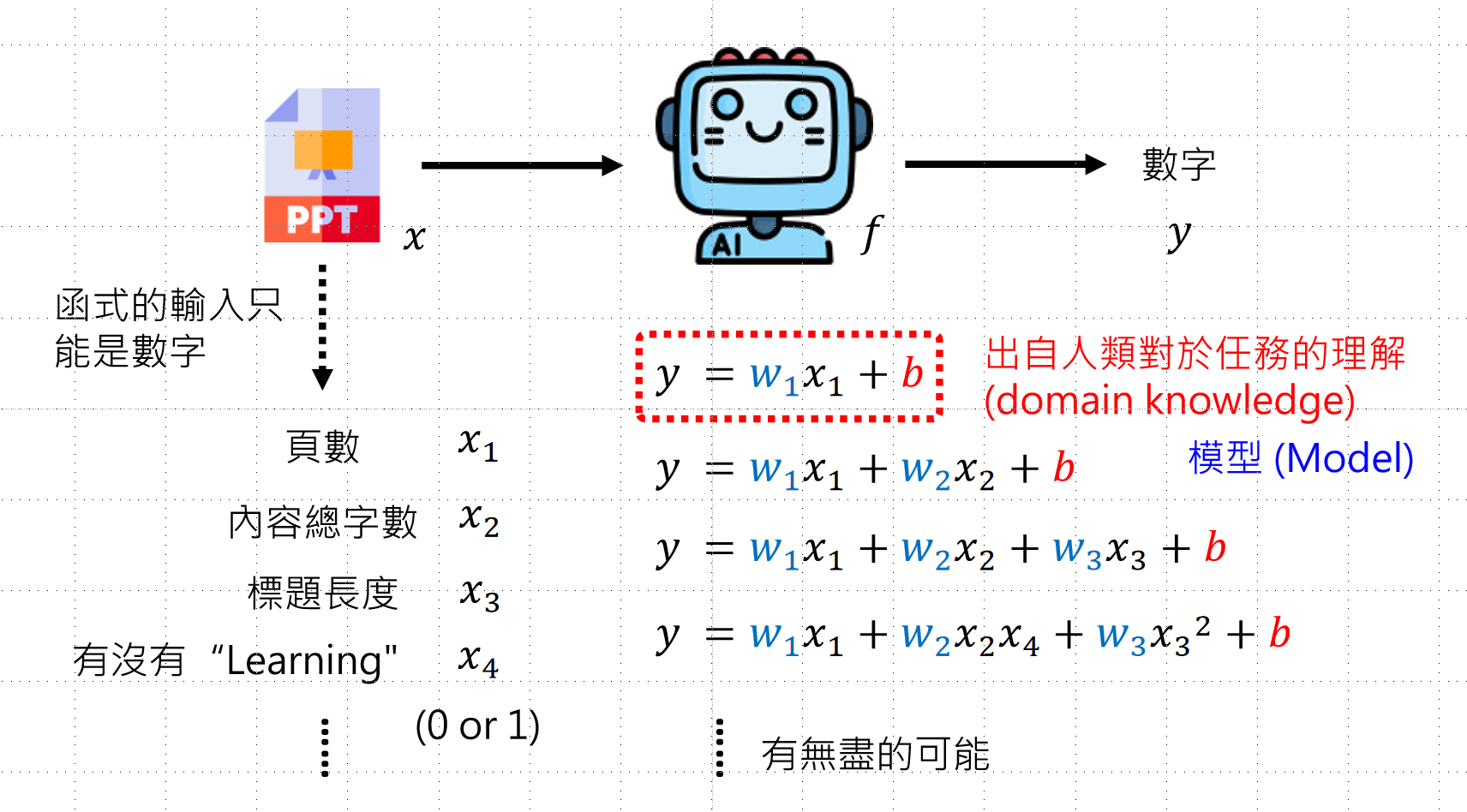
- 确定可选的函数范围
- 函数由人决定,可以选择各种各样的函数
第三步:选择最优函数
目标:找到让 Loss 最低(或最高)的函数
步骤:
- 先写出 Loss 的方程式
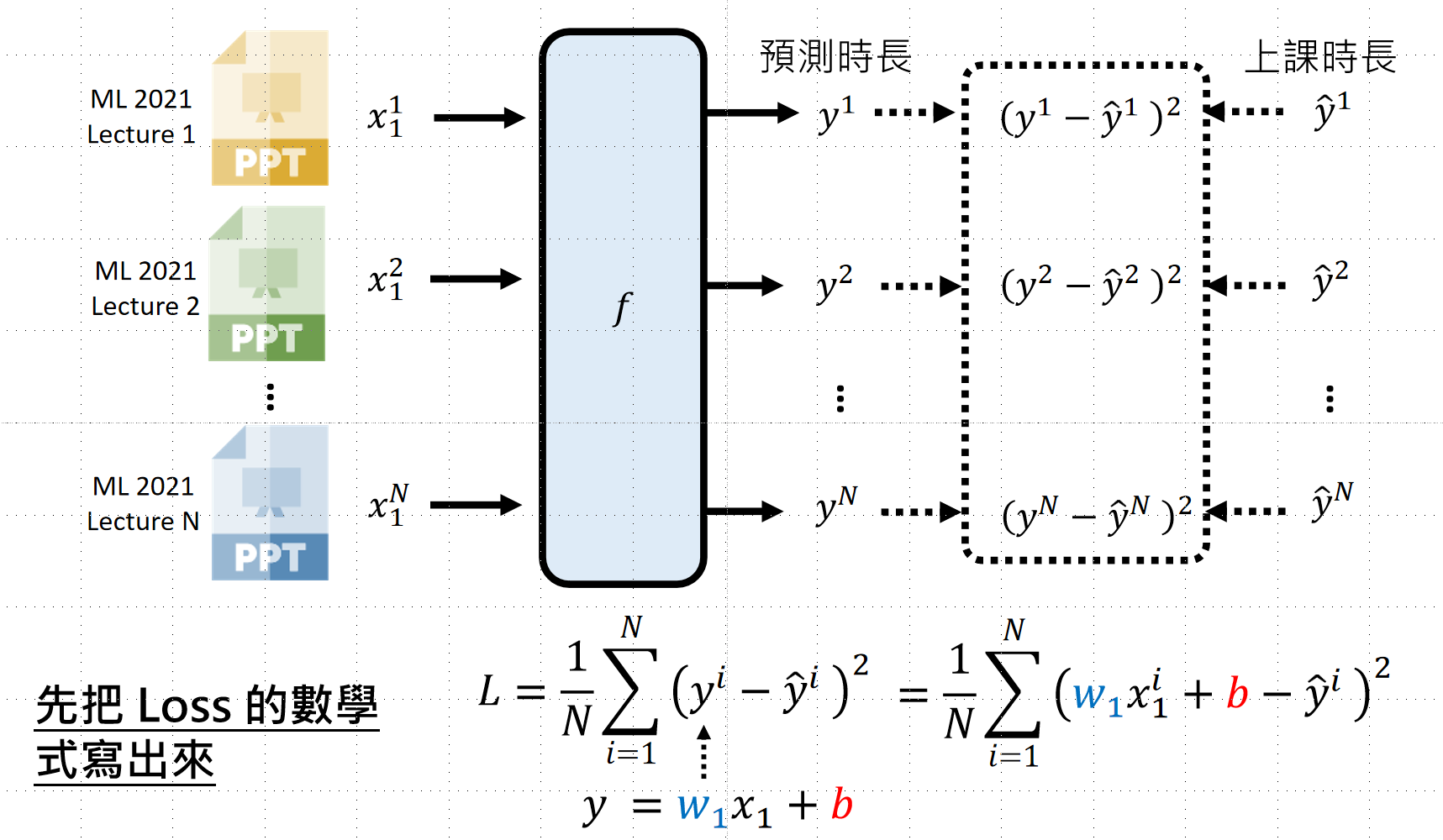
- 找到让 Loss 最小/最大的参数
优化方法
|
方法 |
原理 |
缺点 |
|
暴力求解 |
遍历所有可能,找最小值 |
参数增加时, 速度太慢 |
|
梯度下降法 (Gradient Descent) |
利用微积分斜率判断方向和平衡点(计算微积分可以直接使用相关的封装方法,pytorch有相应的方法) |
可能陷入局部最优 (Local Minimum) |
梯度下降法详解:
- 类似高等数学微积分知识
- 斜率可判断是否到达平衡点
- 斜率指示移动方向(左/右)
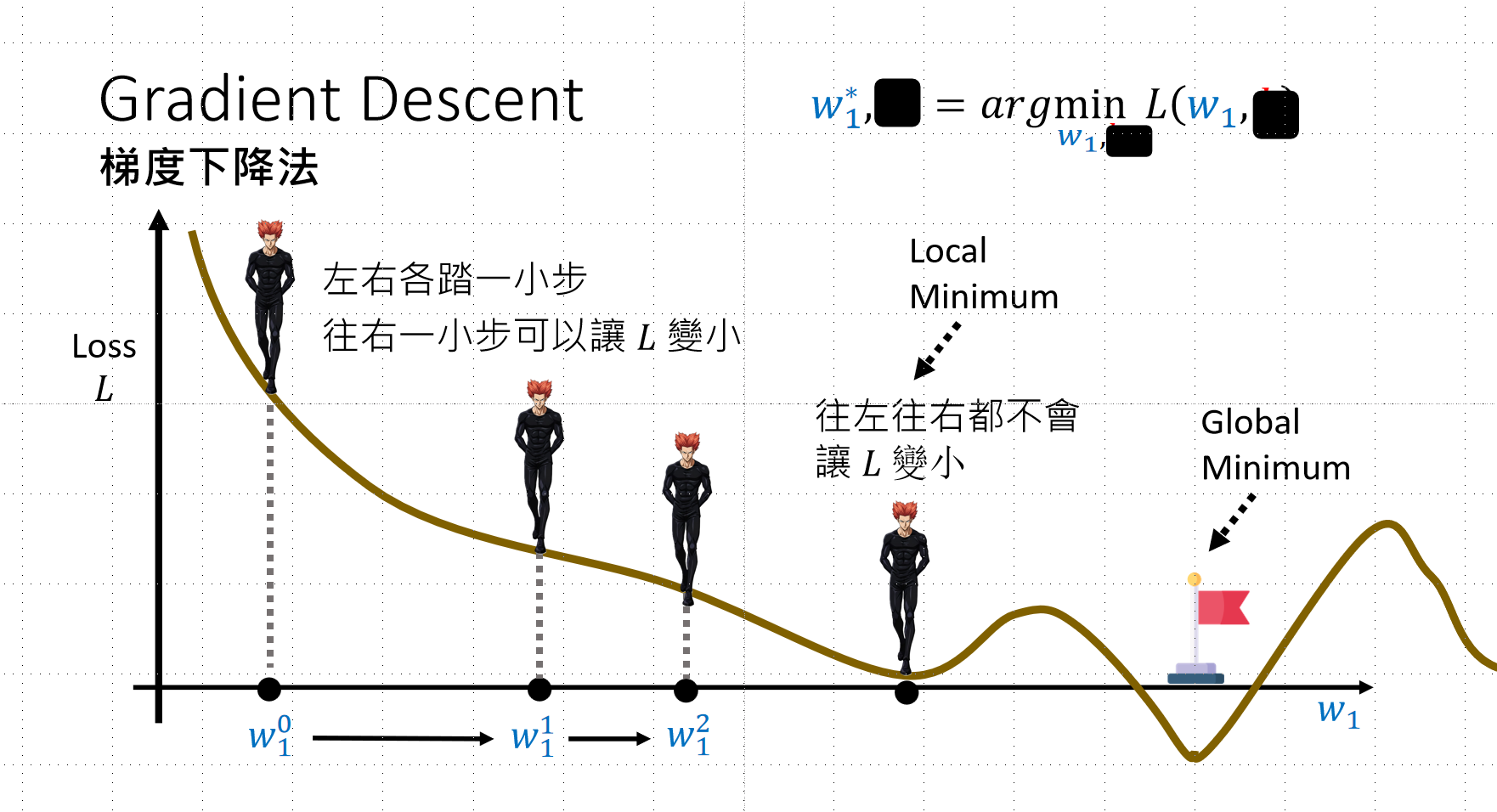

多参数通用方法:


注意点:
学习率不能太小也不能太大,需要设置一个合适的值。
还有一点是参数更新的时间可能很长,因为每一次都要计算Loss的值,并且这个值是根据所有资料计算得到的,所以会很久。
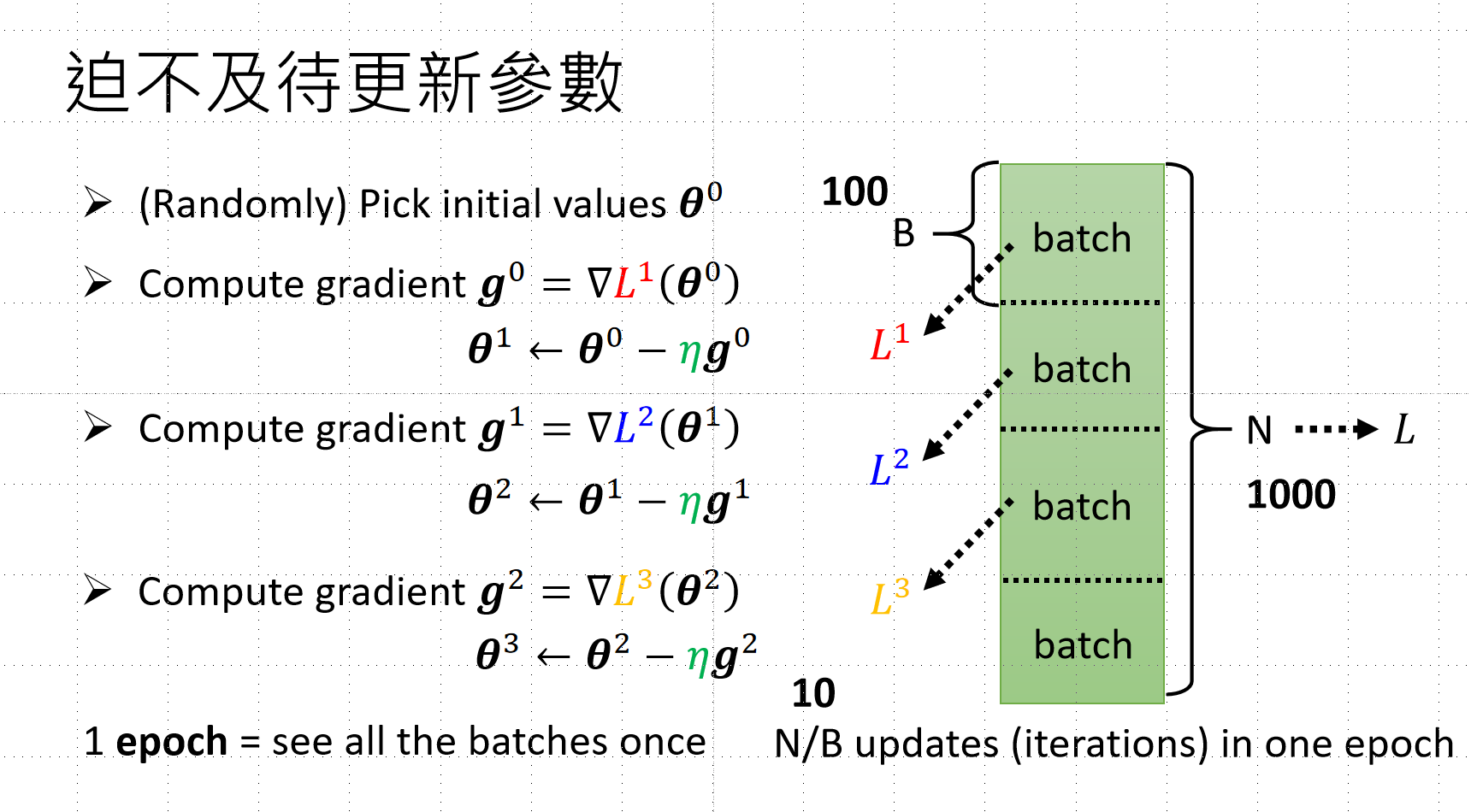
加速训练:Batch 技术
问题:每次计算 Loss 都要用所有资料(N),耗时太长
解决方案:将资料切片成 Batch(B)
- 一个 Batch 更新一次参数(而非看完所有资料)
- 一个 Epoch = 所有 Batch 都使用过一次
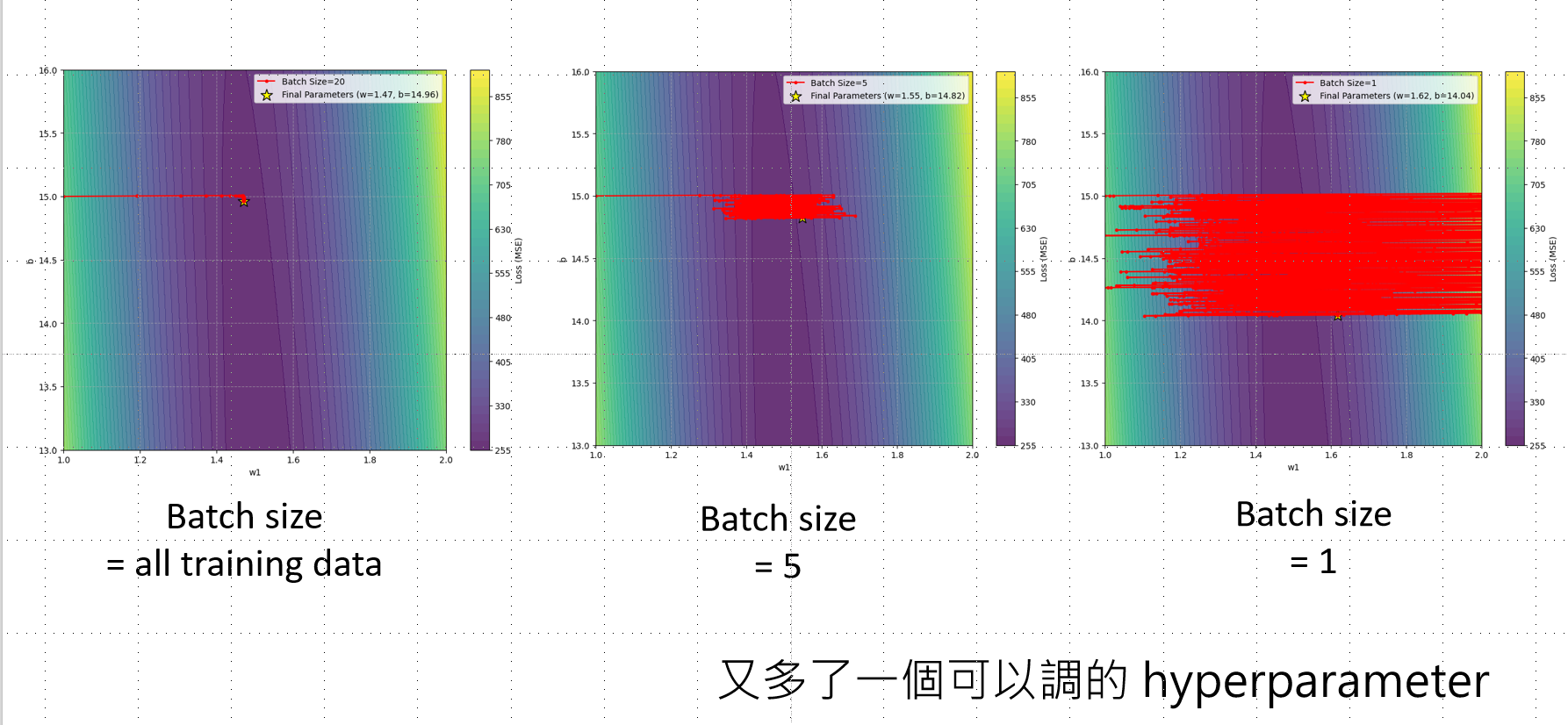
batch size也是需要调的,不能太大或者太小,二者都不行
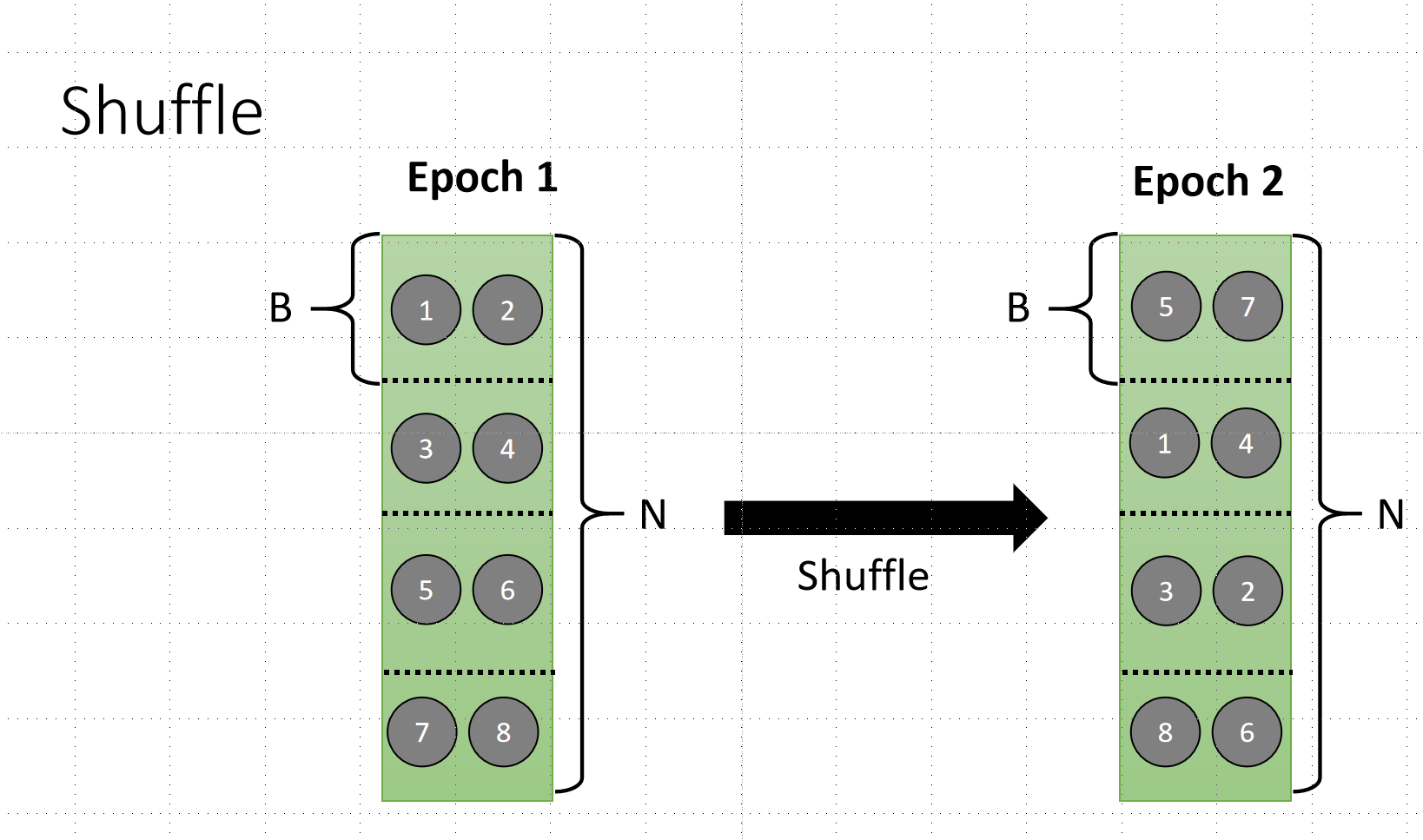
Shuffle 技术: 并且我们要用到这个技术的时候,需要用到shuffle的技术,可以增加更多的随机性,让模型看到不同的结果,增加更多的随机性。
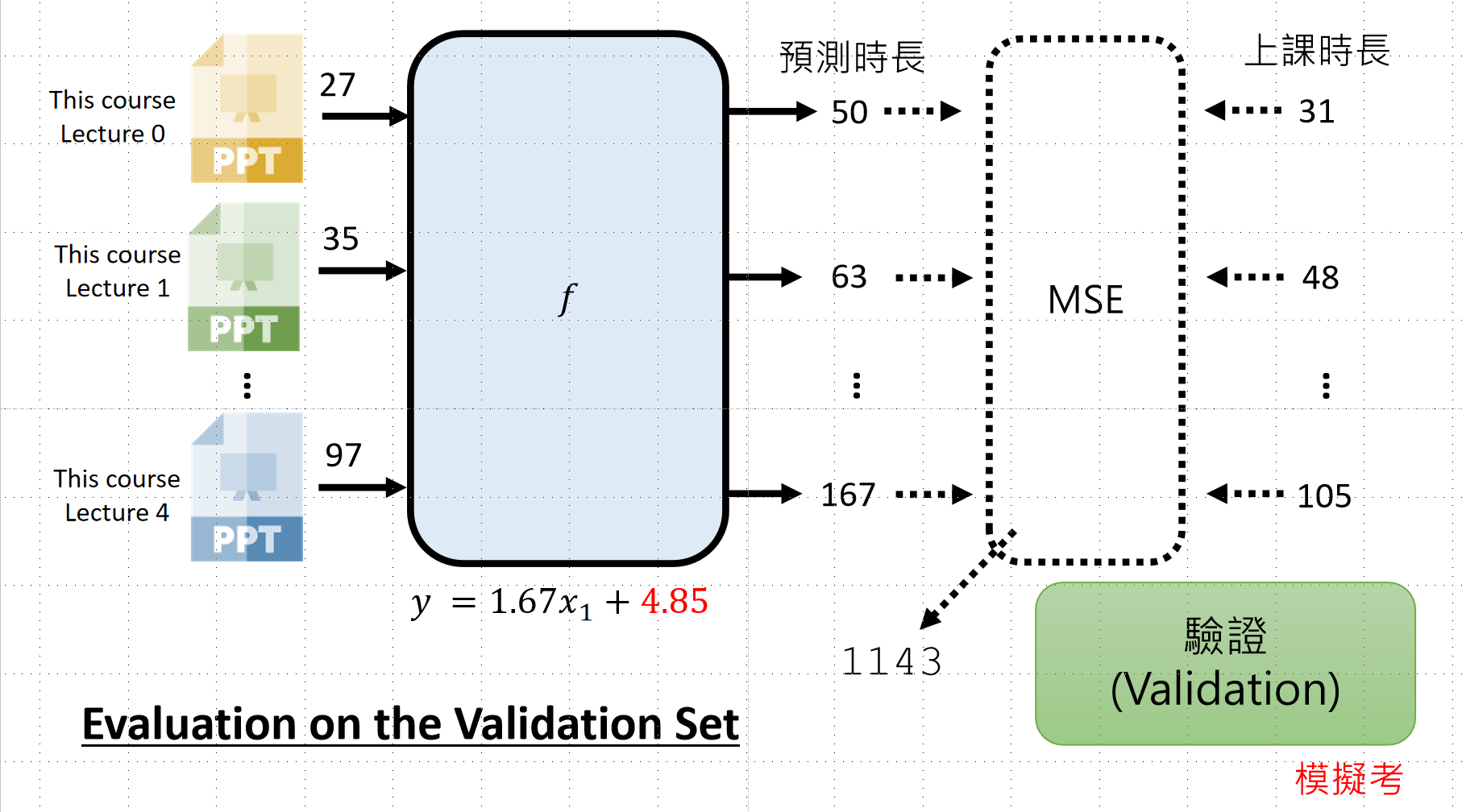
模型验证与测试流程
当我们通过上述的步骤得到函数的时候,我们需要先进行验证(模拟考),最后再进行测试(大考)。
训练 → 验证(模拟考)→ 测试(大考)
进行验证的时候,我们需要先有一个用于验证的资料集,然后进行比较。验证结果不好时,逐步回溯检查:
逐步排查
|
步骤 |
可能问题 |
解决方案 |
|
步骤一 |
训练资料错误 |
更新训练资料,确保与测试内容匹配 |
|
步骤二 |
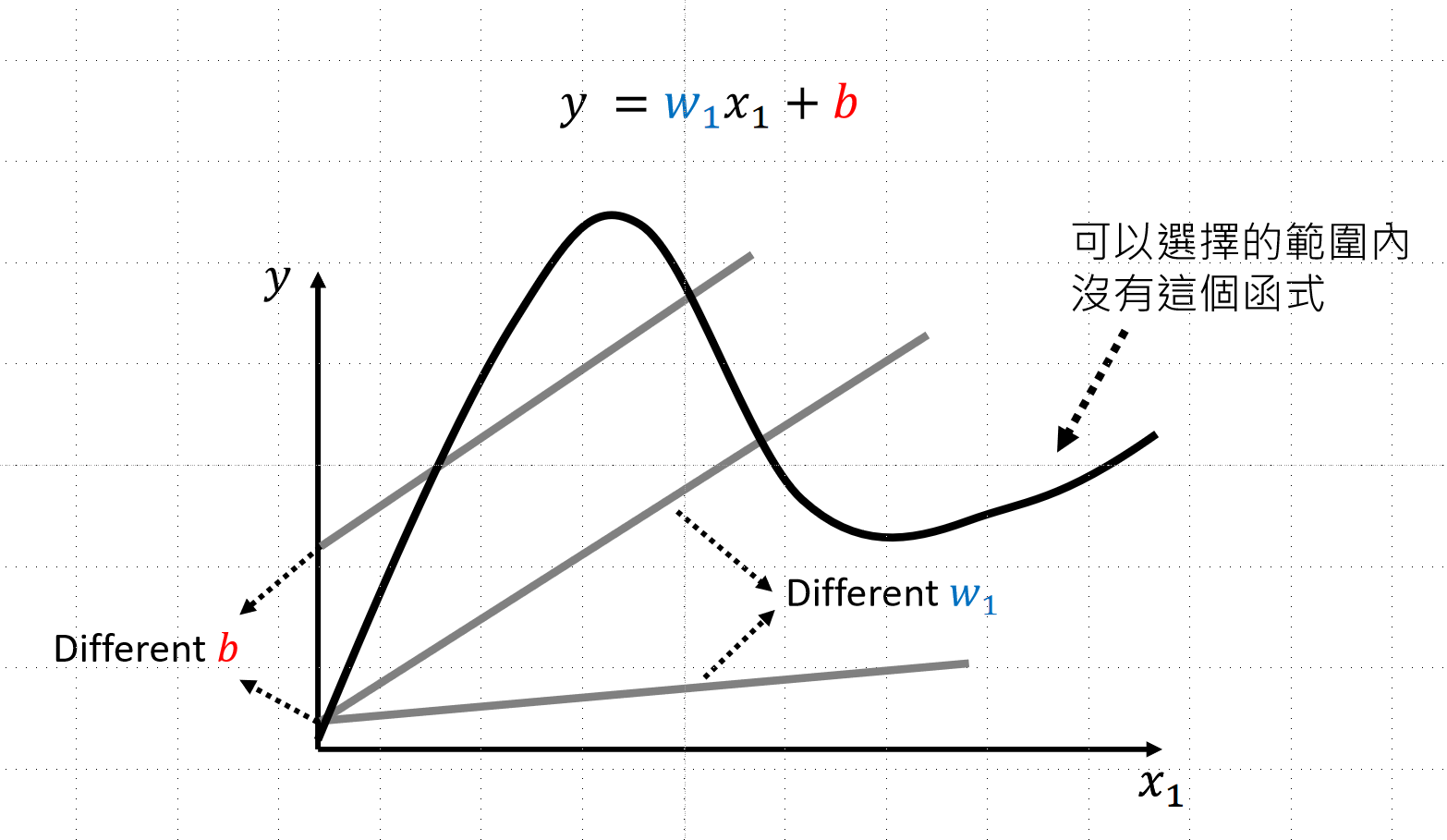
函数选择太少 |
扩大函数集合范围 |
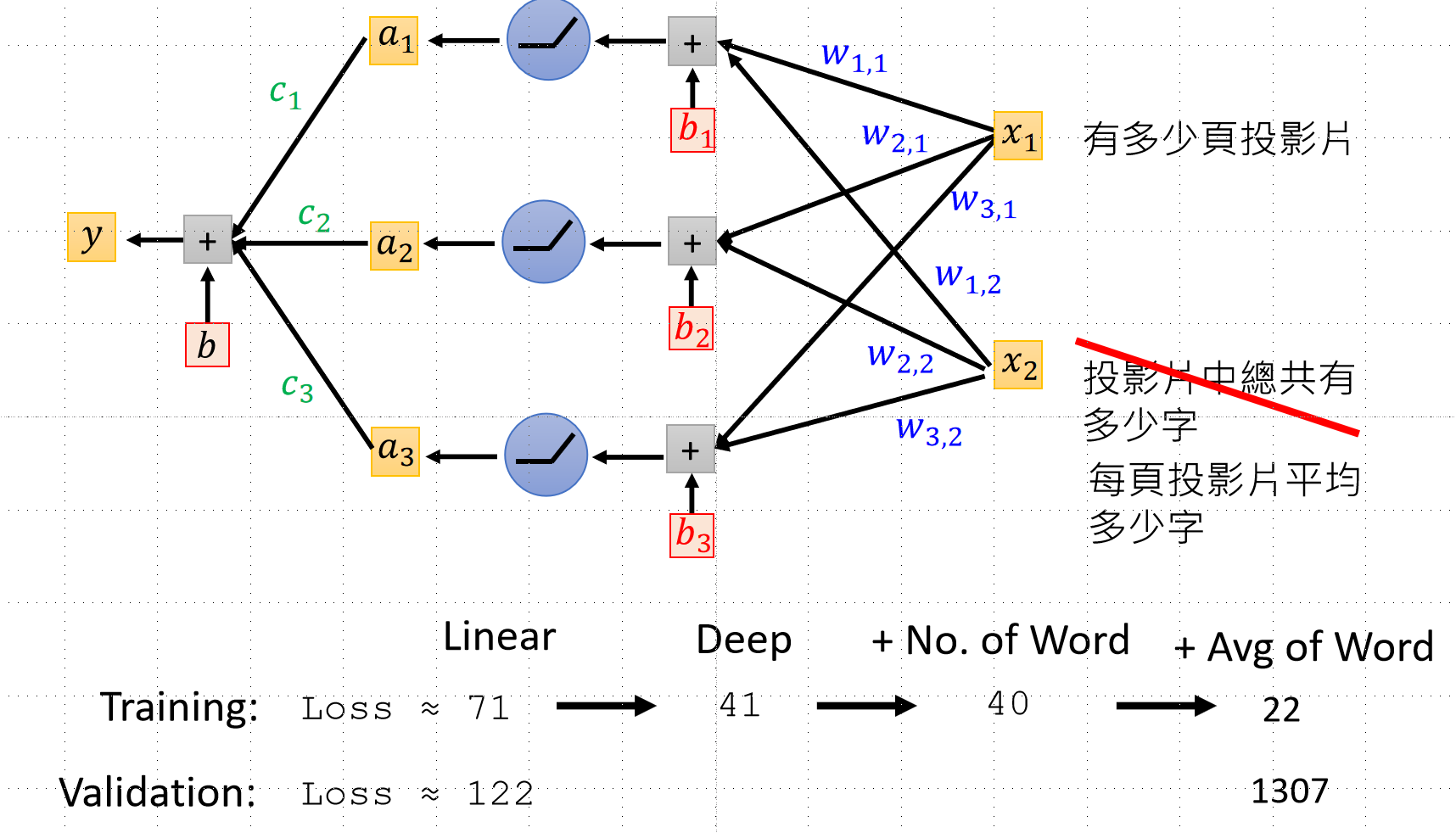
比如我们的函数可能是下图中的曲线状的,我们应该怎么去确定函数呢?方法是取函数上的多个点,用直线连接,分段线性逼近 (Piecewise Linear),后续用ReLu的方法去拟合函数,并且ReLu的操作可以多次进行,这就是类神经网络,如果进行多次的ReLu那就是深度学习
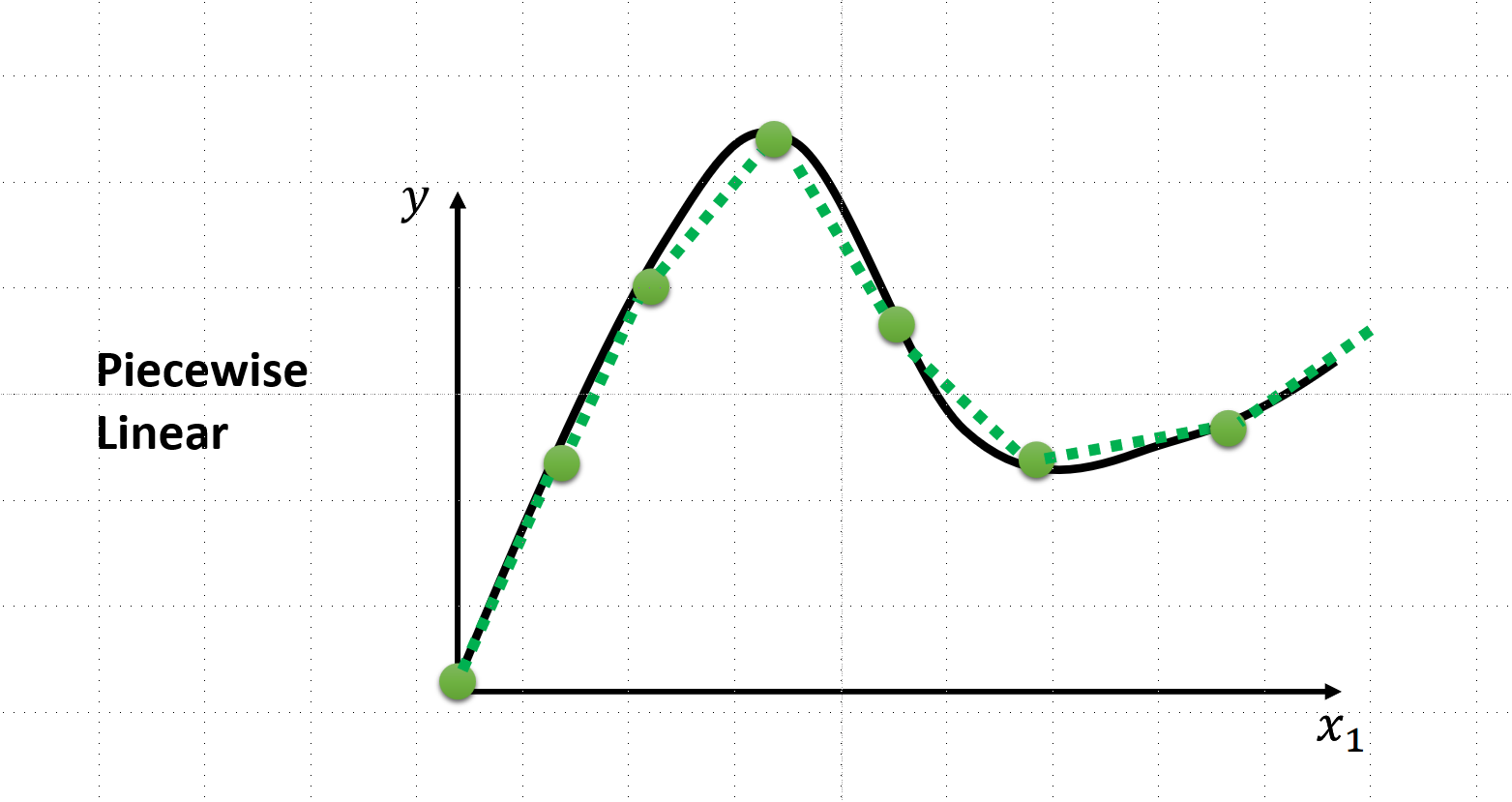
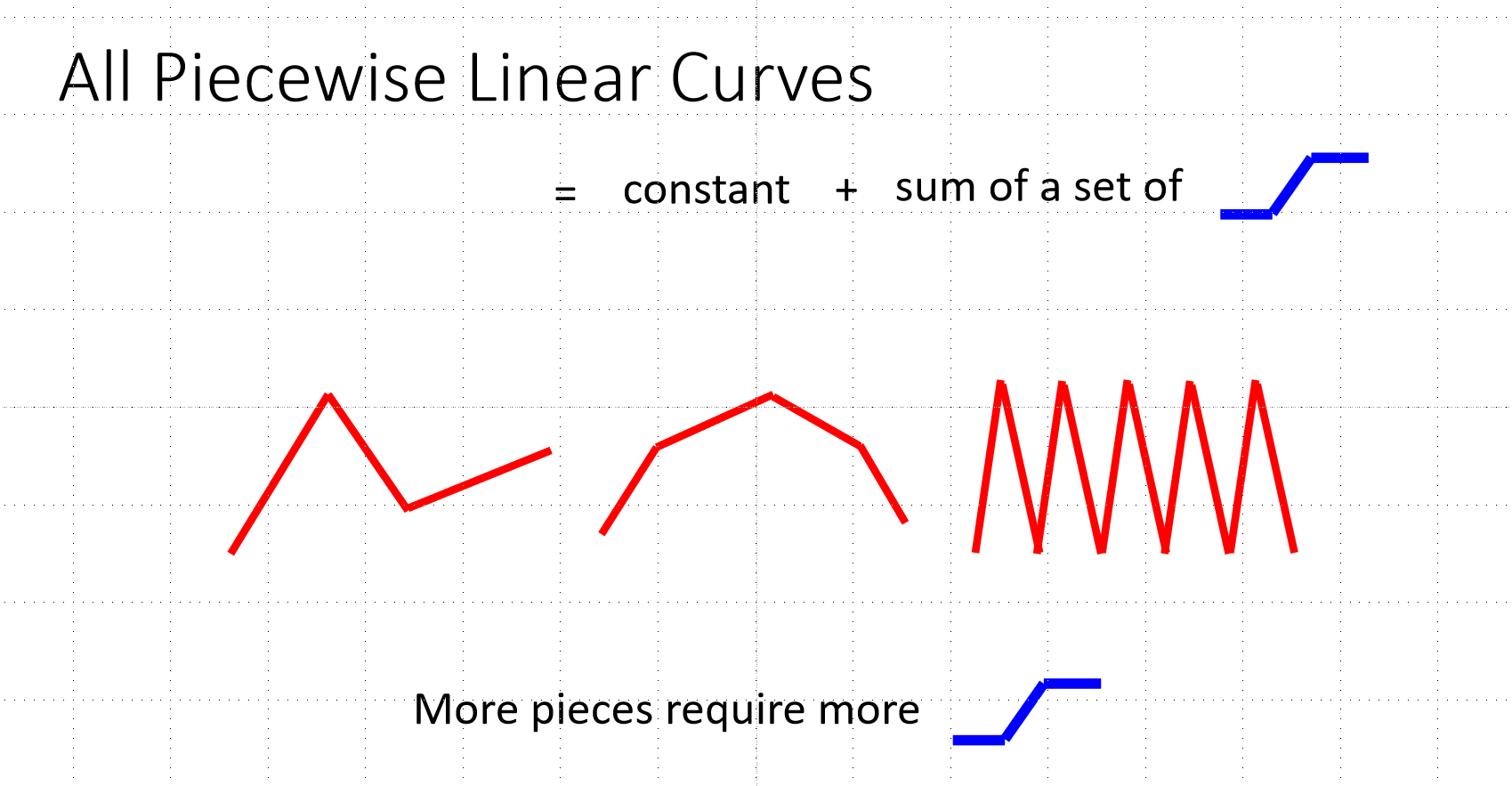
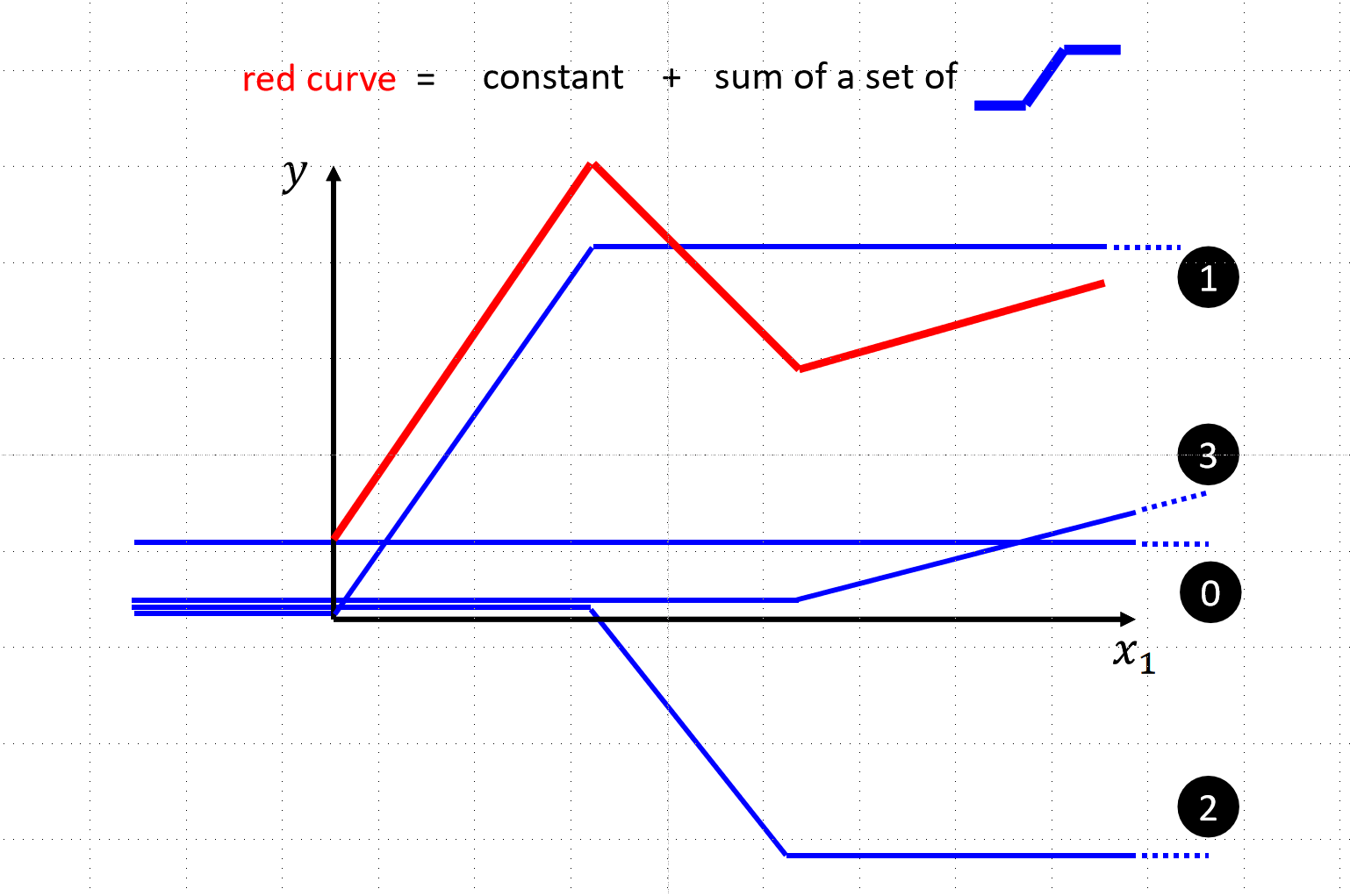
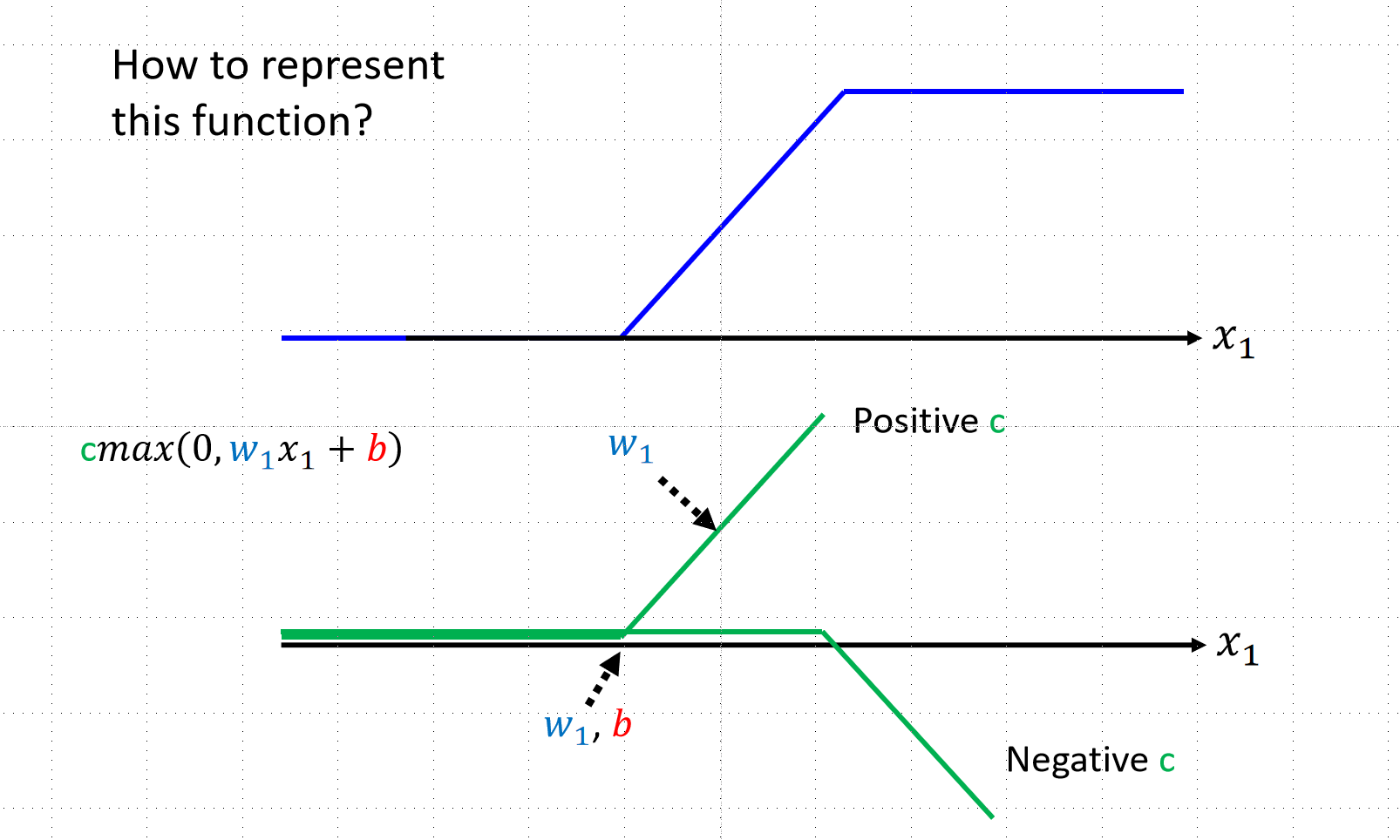
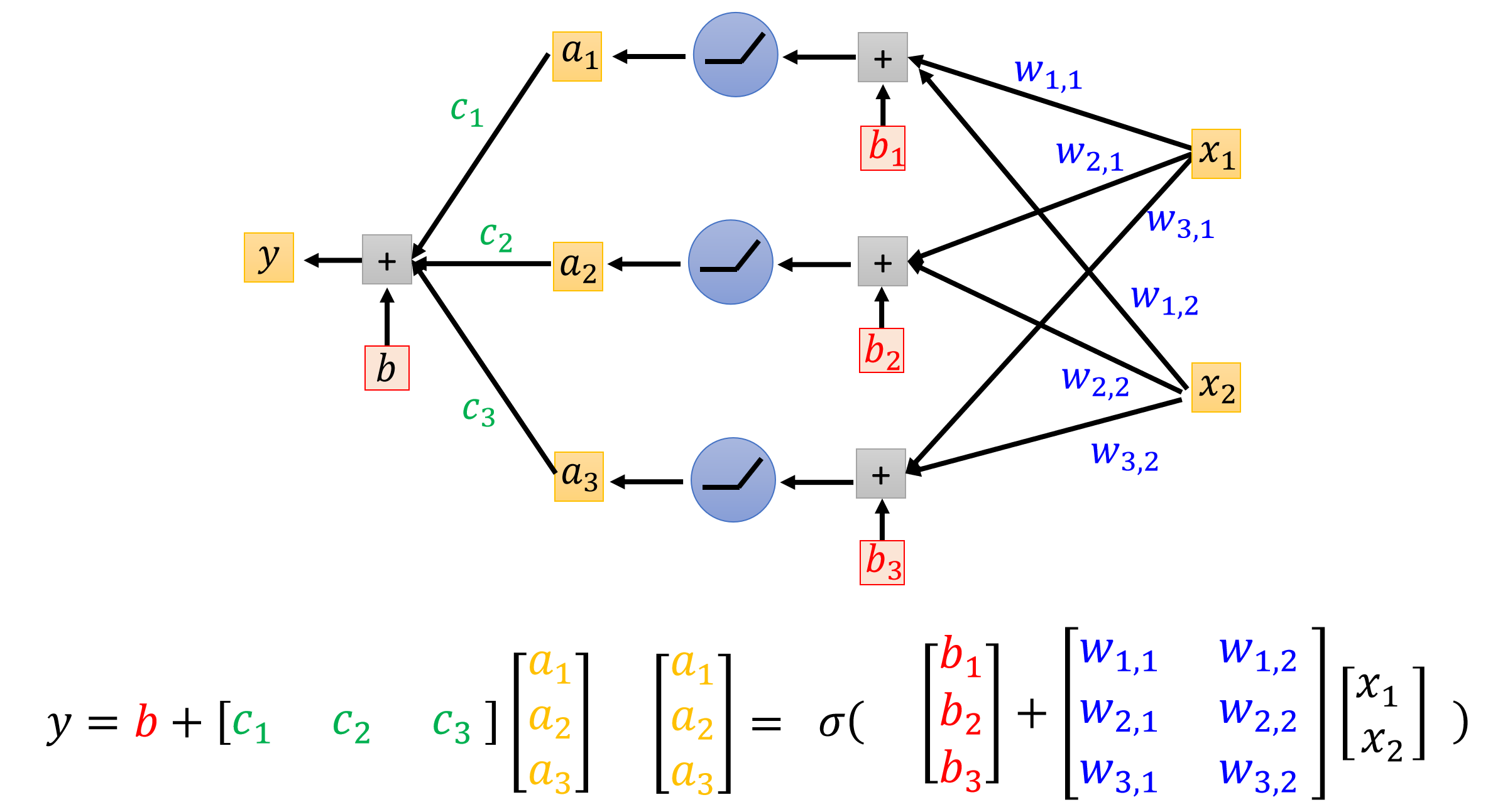
深度学习训练:同样使用梯度下降法,下面的视频是讲述更加有效的方法:

训练中的问题
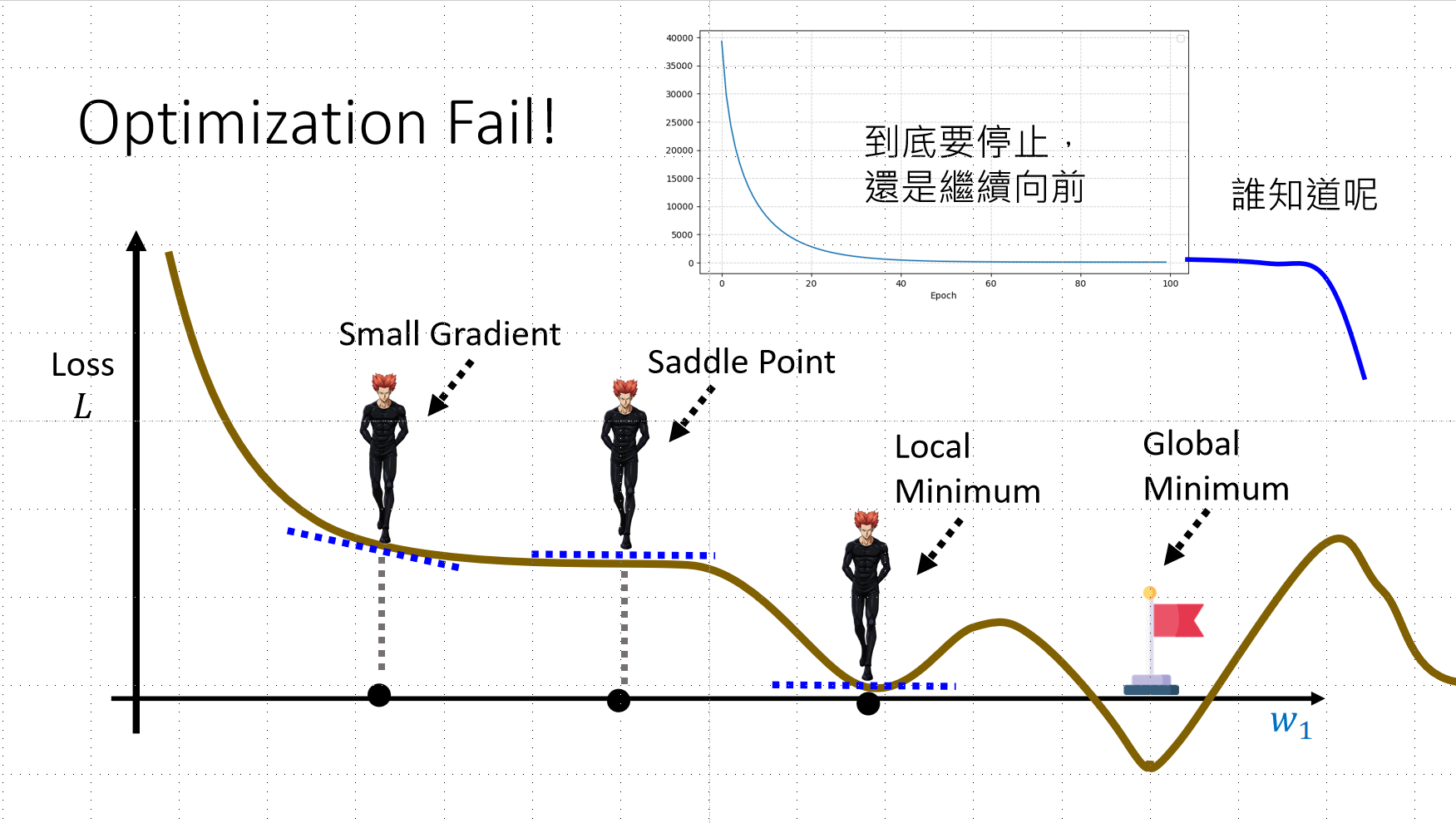
问题1:陷入局部最优或鞍点
后续如果Loss依旧不满意,有可能是步骤三的问题,我们可能训练的时候,没有训练到更好的函数,而是卡在了某些平衡点(山谷),也有可能是卡到了Saddle Point,此处的微分是0,但是实际上函数可能是左边是向下的,这个点是平的,后续的一部分函数也是平的,这时候模型会以为已经到达了平衡点,我们一旦往右边多跨一点,就有可能让loss更低。
- 局部最优 (Local Minimum):微分为0,但不是全局最低
- 鞍点 (Saddle Point):微分为0,但一侧仍可下降
实践建议
从简单模型开始 → 获取 baseline 结果 → 逐步增加复杂度
- 若复杂模型表现更差 → 优化做得不够好
- 若相同 x 对应相同 y → 需要增加更多变量
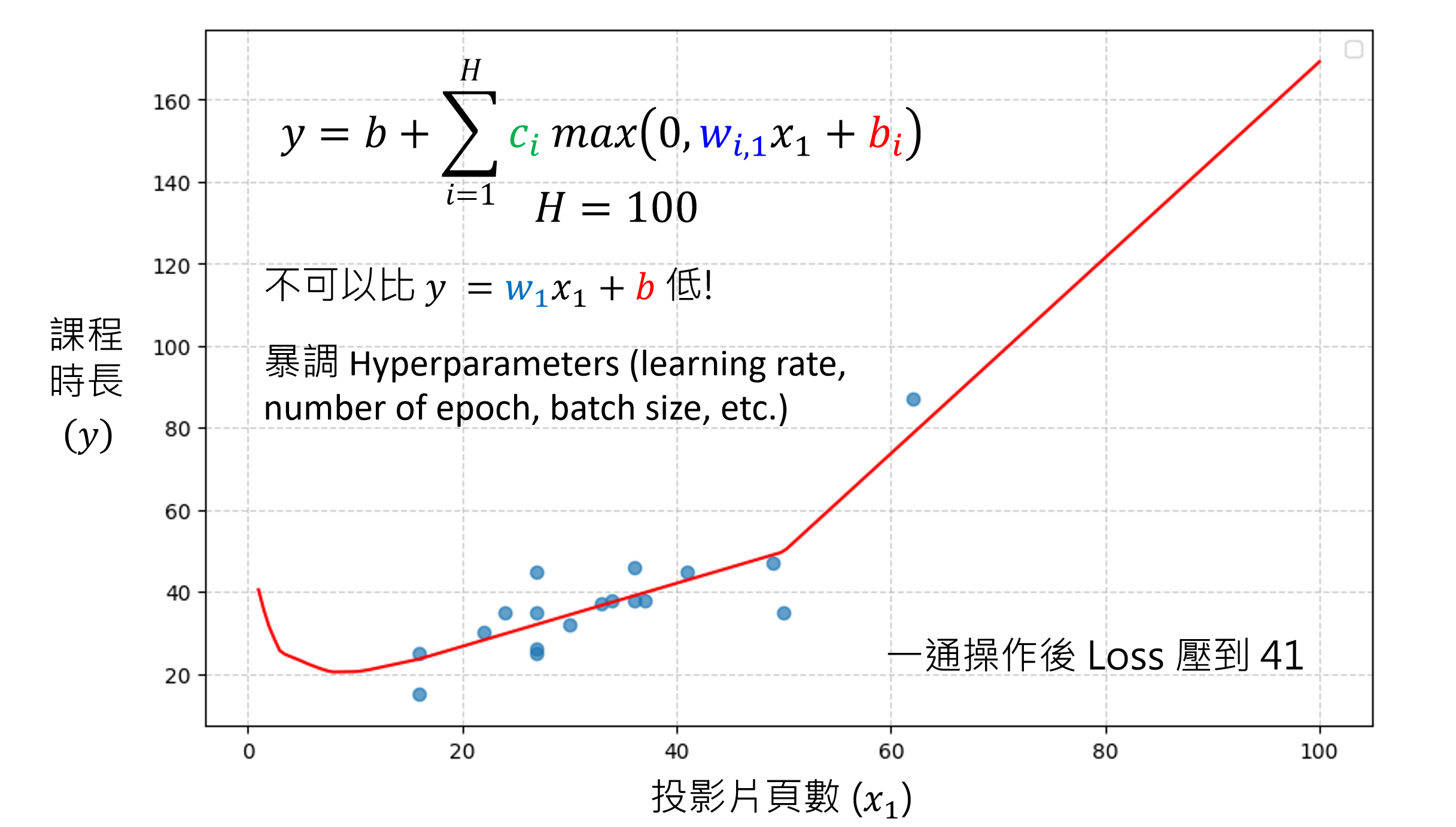
同时,我们画出了函数以及数据点,可以看到相同的x,有着相同的y,根据这个特征,我们可以发现我们当前函数的变量取的还不够准确,应该找到更多的变量。
问题二:过拟合 (Overfitting)
现象
- 训练 Loss 很低
- 验证分数很高(表现差)
原因
这种现象的原因是:划定的函数集合范围越大,越容易发生这种现象,找到一个不好的函数。比如有这样一个函数,在训练资料上,直接根据输入,输出标准答案,而对于在训练集外的输入,则直接输出为0。这样的函数我们得到的loss是很低的,但是放到验证上,loss就会很大。
拓展:可以去看下面的链接,给定了为什么划定范围越大,越容易发生overfitting的理论分析
发生了这种现象,我们就需要去调整步骤二,调整函数的划分范围。而且在实际的时候,我们可以在更新参数的时候,也进行验证的步骤,去看看当前训练是否合适。
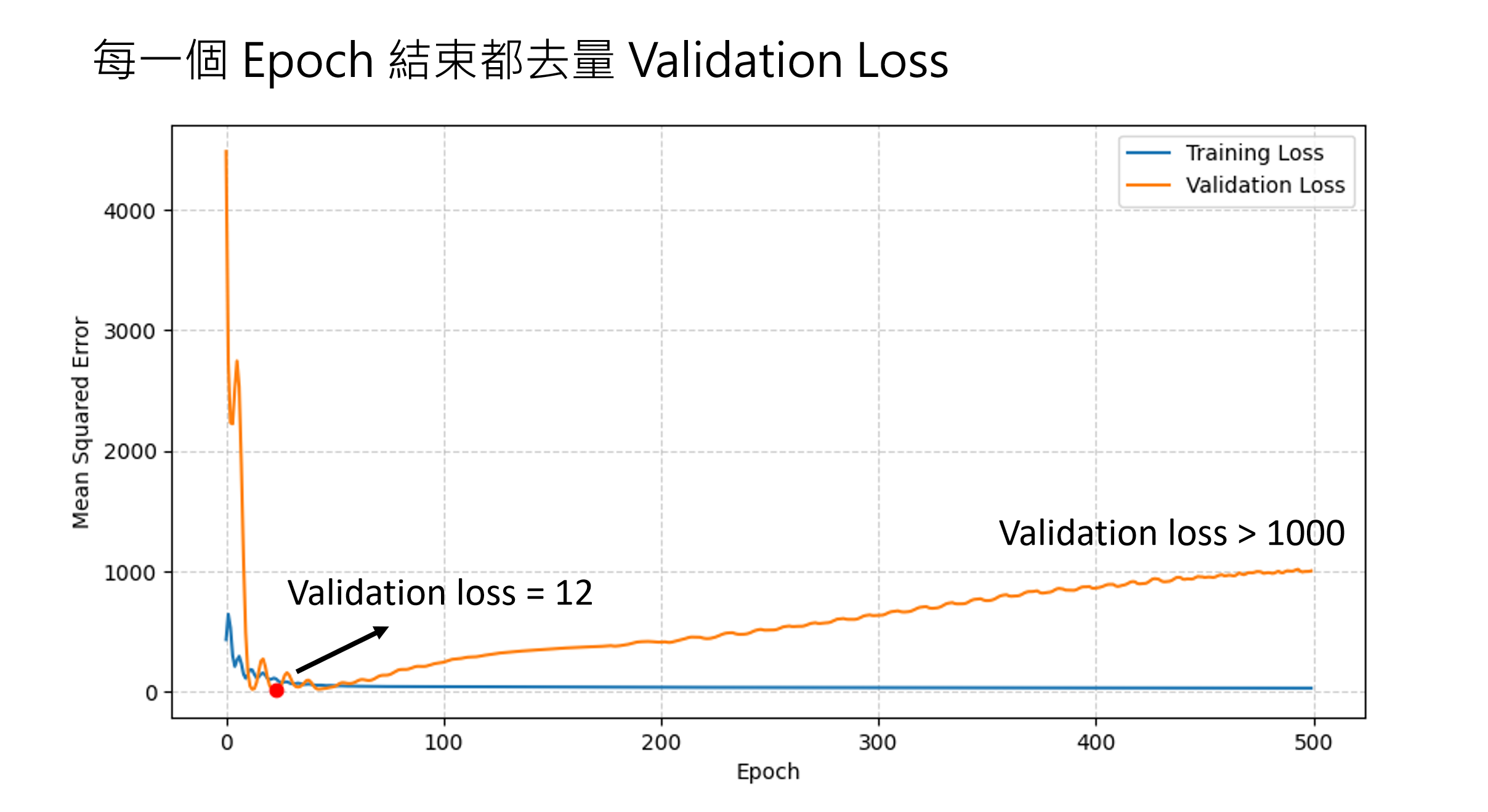
具体看下图:并且我们发现当epoch次数少一些的时候,就达到了一个很不错的结果,我们就可以进行early stopping,去避免overfitting。
Early Stopping(早停):
- 训练时同步验证
- 发现 Epoch 较少时已达不错结果,提前停止
⚠️ 警告:多次调整可能导致验证集过拟合,最终测试表现不佳
但是如果我们进行了很多次去调整函数,发生了很多overfitting现象,我们最终也有可能得到了一个在验证资料上也overfitting的函数,当我们一旦把这个函数放到了测试资料上,就会出错。但是也没有问题,我们还可以重新开始。但是如果最后我们也在测试资料上overfitting.........这也是为什么有些模型在实际使用的时候,可能表现的不如测试的时候那样。
完整解决策略

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)