如何用python语言构建AI native agent | 学习日志+踩坑点整理 (1)
4.缺乏一个全局的、长远的规划,可能会因为眼前的。方法是核心,它将记忆轨迹“序列化”成一段文本,可以直接插入到后续的提示词中,为模型的反思和优化提供完整的上下文。通过一种特殊的提示工程来引导模型,使其每一步的输出都遵循一个固定的轨迹,形成一个“思考-行动-观察”的循环。,智能体在下一轮生成提示词时,就能“看到”上一步行动的结果,并据此进行新一轮的思考和规划。的循环,将新的观察结果追加到历史记录中,
智能体环境部署
智能体定义:能够通过传感器(Sensors)感知其所处环境(Environment),并自主地通过执行器(Actuators)采取行动(Action)以达成特定目标的实体。
学习型智能体:不依赖预设,而是通过与环境的互动自主学习。
LLM智能体:需要我们引导一个通用的“大脑”去规划、行动和学习。
ps:不同大模型的api调用方式不一样。gemini没有base url。
e.g.:
-调用Google Generative AI
import google.generativeai as genai
genai.configure(api_key="你的_Google_API_Key")
model = genai.GenerativeModel("gemini-1.5-flash")
response = model.generate_content("用一句话解释什么是 Base URL")
print(response.text)
-调用open ai
from openai import OpenAI
client = OpenAI(api_key="sk-xxx")
resp = client.responses.create(
model="gpt-4o-mini",
input="用一句话解释大模型"
)
print(resp.output_text)
#第三方中转 / 私有部署 / OpenAI 兼容接口必须写上base_url
from openai import OpenAI
client = OpenAI(
api_key="sk-xxxx", # 有的中转随便写,有的必须真 key
base_url="https://api.xxx.com/v1" # ⚠️ 一定以 /v1 结尾
)
resp = client.responses.create(
model="gpt-4o-mini", # 或你部署的模型名
input="你好"
)
print(resp.output_text)
- Ollama(完全本地,不需要APIkey)
import ollama
resp = ollama.chat(
model="llama3",
messages=[
{"role": "user", "content": "介绍一下你自己"}
]
)
print(resp["message"]["content"])
智能体经典范式
ReAct (Reasoning and Acting):智能体边想边做,动态调整。
Plan-and-Solve:智能体首先生成一个完整的行动计划,然后严格执行。
Reflection:通过自我批判和修正来优化结果。u
-环境准备:(准备LLM客户端)
1.安装依赖库;2.配置相关信息在环境中(配置api密匙):让我们的代码更通用;3.基础LLM调用函数:让代码结构更清晰、更易于复用,封装所有与模型服务交互的细节,让我们的主逻辑可以更专注于智能体的构建。
-Gemini:
1.
pip install google-generativeai python-dotenv typing-extensions
or 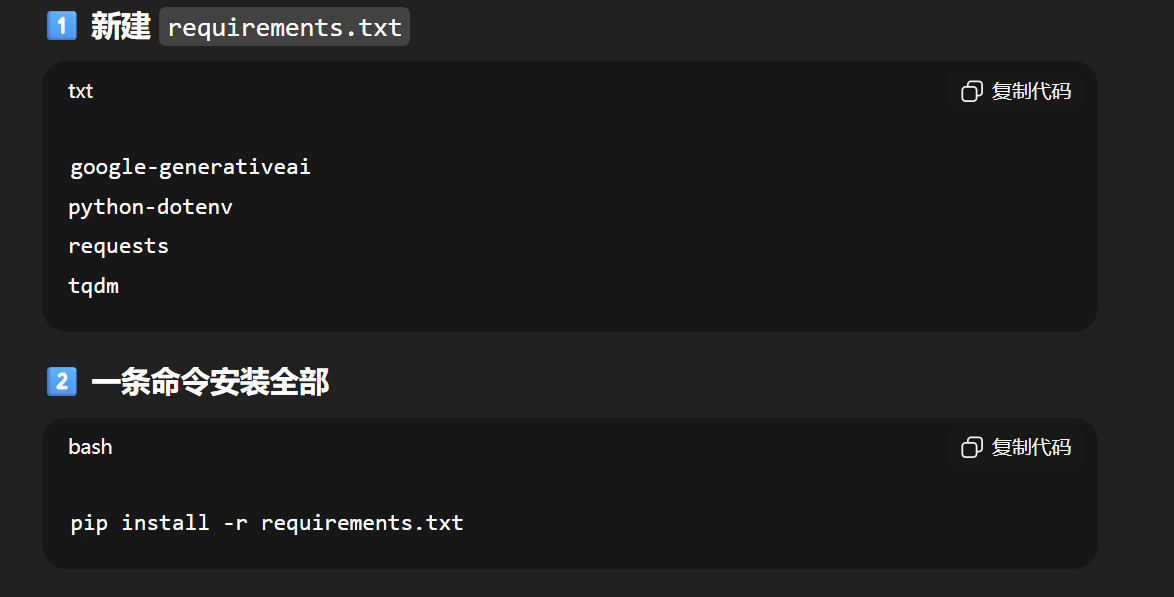
2.
GEMINI_API_KEY=AIza-xxxx
GEMINI_MODEL=gemini-1.5-flash
3.
import os
from typing import List, Dict
from dotenv import load_dotenv
import google.generativeai as genai
# 加载 .env
load_dotenv()
class HelloAgentsGeminiLLM:
"""
基于 Gemini 的 LLM 客户端封装
"""
def __init__(self, model: str = None, apiKey: str = None):
self.model_name = model or os.getenv("GEMINI_MODEL")
api_key = apiKey or os.getenv("GEMINI_API_KEY")
if not self.model_name or not api_key:
raise ValueError("GEMINI_MODEL 或 GEMINI_API_KEY 未配置")
genai.configure(api_key=api_key)
self.model = genai.GenerativeModel(self.model_name)
def think(self, messages: List[Dict[str, str]], temperature: float = 0.7):
"""
模拟 OpenAI chat messages 风格
"""
print(f"🧠 正在调用 Gemini 模型:{self.model_name}")
# 把 OpenAI messages 转成 Gemini prompt
prompt = self._convert_messages(messages)
try:
response = self.model.generate_content(
prompt,
generation_config={
"temperature": temperature
}
)
print("✅ Gemini 响应成功")
return response.text
except Exception as e:
print(f"❌ Gemini 调用失败: {e}")
return None
#做「接口适配(Adapter)」,上层代码已经“约定”使用 messages。message对于大多数LLM更加适配,所以要把message翻译成gamini更理解的语言,而非直接把上层代码换成适合Gemini的。(Adapter Pattern)
def _convert_messages(self, messages: List[Dict[str, str]]) -> str:
"""
OpenAI messages → Gemini prompt
"""
prompt_lines = []
for msg in messages:
role = msg["role"]
content = msg["content"]
if role == "system":
prompt_lines.append(f"[System]\n{content}")
elif role == "user":
prompt_lines.append(f"[User]\n{content}")
elif role == "assistant":
prompt_lines.append(f"[Assistant]\n{content}")
return "\n\n".join(prompt_lines)
添加流式:模型一边生成,一边把“正在生成的内容”立刻返回给你,而不是等全部生成完。
def think_stream(
self,
messages: List[Dict[str, str]],
temperature: float = 0.7
) -> Generator[str, None, None]:
prompt = self._convert_messages(messages)
stream = self.model.generate_content(
prompt,
stream=True,
generation_config={
"temperature": temperature
}
)
for chunk in stream:
if chunk.text:
yield chunk.text
ReAct (Reason + Act)构建
通过一种特殊的提示工程来引导模型,使其每一步的输出都遵循一个固定的轨迹,形成一个“思考-行动-观察”的循环。智能体将不断重复这个 Thought -> Action -> Observation 的循环,将新的观察结果追加到历史记录中,形成一个不断增长的上下文,直到它在Thought中认为已经找到了最终答案,然后输出结果。这个过程形成了一个强大的协同效应:推理使得行动更具目的性,而行动则为推理提供了事实依据。
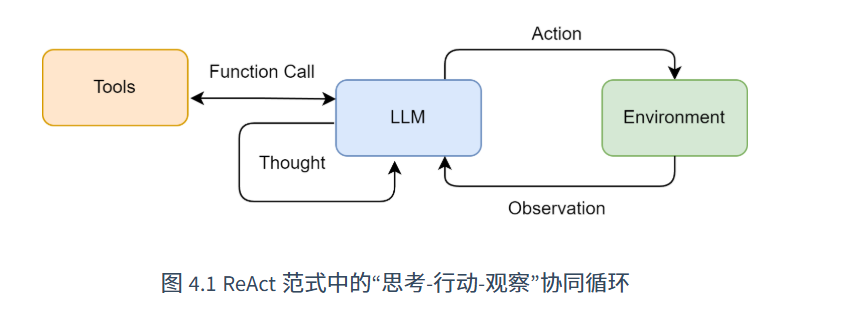
-tools:使智能体具有调用外部工具的能力:1.安装相关库;2.找到相关tool的api,添加到env.中;3.用代码定义并管理该tool---name,description,execution logic。
-编码实现:
1.系统提示词模板:
# ReAct 提示词模板
REACT_PROMPT_TEMPLATE = """
请注意,你是一个有能力调用外部工具的智能助手。 #角色定义
可用工具如下:
{tools} #工具清单
请严格按照以下格式进行回应:
Thought: 你的思考过程,用于分析问题、拆解任务和规划下一步行动。
Action: 你决定采取的行动,必须是以下格式之一: #格式规约
- `{{tool_name}}[{{tool_input}}]`:调用一个可用工具。
- `Finish[最终答案]`:当你认为已经获得最终答案时。
- 当你收集到足够的信息,能够回答用户的最终问题时,你必须在Action:字段后使用 Finish[最终答案] 来输出最终答案。
现在,请开始解决以下问题: #动态上下文
Question: {question}
History: {history}
"""
2.实现核心循环:
class ReActAgent:
def __init__(self, llm_client: HelloAgentsLLM, tool_executor: ToolExecutor, max_steps: int = 5):
self.llm_client = llm_client
self.tool_executor = tool_executor
self.max_steps = max_steps
self.history = []
def run(self, question: str):
"""
运行ReAct智能体来回答一个问题。
"""
self.history = [] # 每次运行时重置历史记录
current_step = 0
while current_step < self.max_steps:
current_step += 1
print(f"--- 第 {current_step} 步 ---")
# 1. 格式化提示词
tools_desc = self.tool_executor.getAvailableTools()
history_str = "\n".join(self.history)
prompt = REACT_PROMPT_TEMPLATE.format(
tools=tools_desc,
question=question,
history=history_str
)
# 2. 调用LLM进行思考
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages)
if not response_text:
print("错误:LLM未能返回有效响应。")
break
# ... (后续的解析、执行、整合步骤)
run 方法是智能体的入口。它的 while 循环构成了 ReAct 范式的主体,max_steps 参数则是一个重要的安全阀,防止智能体陷入无限循环而耗尽资源。
3.输出解析器:LLM 返回的是纯文本,我们需要从中精确地提取出Thought和Action。这是通过几个辅助解析函数完成的,它们通常使用正则表达式来实现。
# (这些方法是 ReActAgent 类的一部分)
def _parse_output(self, text: str):
"""解析LLM的输出,提取Thought和Action。
"""
# Thought: 匹配到 Action: 或文本末尾
thought_match = re.search(r"Thought:\s*(.*?)(?=\nAction:|$)", text, re.DOTALL)
# Action: 匹配到文本末尾
action_match = re.search(r"Action:\s*(.*?)$", text, re.DOTALL)
thought = thought_match.group(1).strip() if thought_match else None
action = action_match.group(1).strip() if action_match else None
return thought, action
def _parse_action(self, action_text: str):
"""解析Action字符串,提取工具名称和输入。
"""
match = re.match(r"(\w+)\[(.*)\]", action_text, re.DOTALL)
if match:
return match.group(1), match.group(2)
return None, None
_parse_output: 负责从LLM的完整响应中分离出Thought和Action两个主要部分。_parse_action: 负责进一步解析Action字符串,例如从Search[华为最新手机]中提取出工具名Search和工具输入华为最新手机。
4.工具调用并执行:
# (这段逻辑在 run 方法的 while 循环内)
# 3. 解析LLM的输出
thought, action = self._parse_output(response_text)
if thought:
print(f"思考: {thought}")
if not action:
print("警告:未能解析出有效的Action,流程终止。")
break
# 4. 执行Action
if action.startswith("Finish"):
# 如果是Finish指令,提取最终答案并结束
final_answer = re.match(r"Finish\[(.*)\]", action).group(1)
print(f"🎉 最终答案: {final_answer}")
return final_answer
tool_name, tool_input = self._parse_action(action)
if not tool_name or not tool_input:
# ... 处理无效Action格式 ...
continue
print(f"🎬 行动: {tool_name}[{tool_input}]")
tool_function = self.tool_executor.getTool(tool_name)
if not tool_function:
observation = f"错误:未找到名为 '{tool_name}' 的工具。"
else:
observation = tool_function(tool_input) # 调用真实工具
这段代码是Action的执行中心。它首先检查是否为Finish指令,如果是,则流程结束。否则,它会通过tool_executor获取对应的工具函数并执行,得到observation。
5.整合观测结果,形成闭环:将Action本身和工具执行后的Observation添加回历史记录中,为下一轮循环提供新的上下文。
# (这段逻辑紧随工具调用之后,在 while 循环的末尾)
print(f"👀 观察: {observation}")
# 将本轮的Action和Observation添加到历史记录中
self.history.append(f"Action: {action}")
self.history.append(f"Observation: {observation}")
# 循环结束
print("已达到最大步数,流程终止。")
return None
通过将Observation追加到self.history,智能体在下一轮生成提示词时,就能“看到”上一步行动的结果,并据此进行新一轮的思考和规划。
6. 将以上所有部分组合起来,我们就得到了完整的 ReActAgent 类。
-Evaluation:
+: 1.透明,通过Thought链,展现思考历程;2.走一步,看一步,动态调整;3.可工具协同,调用外部工具的执行能力;
-:1.自身能力高度依赖于底层 LLM 的综合能力;2.完成一个任务通常需要多次调用 LLM,可能会导致较高的总耗时和费用;3.模板中的任何微小变动,都可能影响 LLM 的行为,增加了在实际应用中的不确定性;4.缺乏一个全局的、长远的规划,可能会因为眼前的 Observation 而选择一个看似正确但长远来看并非最优的路径,甚至在某些情况下陷入“原地打转”的循环中。
solution:

Plan-and-Solve
先规划 (Plan),后执行 (Solve)。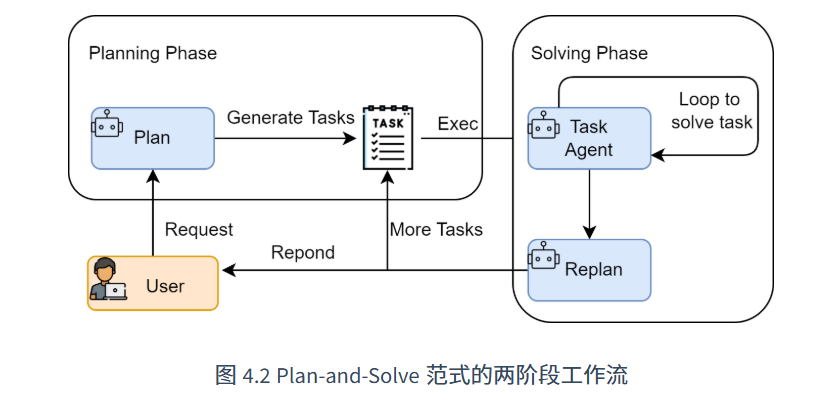
1.规划阶段:LLM接受问题后,拆解问题,并制定一个清晰、分步骤的计划;
PLANNER_PROMPT_TEMPLATE = """
#角色设定
你是一个顶级的AI规划专家。你的任务是将用户提出的复杂问题分解成一个由多个简单步骤组成的行动计划。
#任务描述
请确保计划中的每个步骤都是一个独立的、可执行的子任务,并且严格按照逻辑顺序排列。
#格式约束
你的输出必须是一个Python列表,其中每个元素都是一个描述子任务的字符串。
问题: {question}
请严格按照以下格式输出你的计划,```python与```作为前后缀是必要的:
```python
["步骤1", "步骤2", "步骤3", ...]
```
"""
Planner类规划器:
# 假定 llm_client.py 中的 HelloAgentsLLM 类已经定义好
# from llm_client import HelloAgentsLLM
class Planner:
def __init__(self, llm_client):
self.llm_client = llm_client
def plan(self, question: str) -> list[str]:
"""
根据用户问题生成一个行动计划。
"""
prompt = PLANNER_PROMPT_TEMPLATE.format(question=question)
# 为了生成计划,我们构建一个简单的消息列表
messages = [{"role": "user", "content": prompt}]
print("--- 正在生成计划 ---")
# 使用流式输出来获取完整的计划
response_text = self.llm_client.think(messages=messages) or ""
print(f"✅ 计划已生成:\n{response_text}")
# 解析LLM输出的列表字符串
try:
# 找到```python和```之间的内容
plan_str = response_text.split("```python")[1].split("```")[0].strip()
# 使用ast.literal_eval来安全地执行字符串,将其转换为Python列表
plan = ast.literal_eval(plan_str)
return plan if isinstance(plan, list) else []
except (ValueError, SyntaxError, IndexError) as e:
print(f"❌ 解析计划时出错: {e}")
print(f"原始响应: {response_text}")
return []
except Exception as e:
print(f"❌ 解析计划时发生未知错误: {e}")
return []
2.执行阶段:严格按步骤执行,最终得出答案。
*状态管理:必须记录每一步的执行结果,并将其作为上下文提供给后续步骤,确保信息在整个任务链条中顺畅流动
在已有上下文的基础上,专注解决当前这一个步骤。
EXECUTOR_PROMPT_TEMPLATE = """
你是一位顶级的AI执行专家。你的任务是严格按照给定的计划,一步步地解决问题。
你将收到原始问题、完整的计划、以及到目前为止已经完成的步骤和结果。
请你专注于解决“当前步骤”,并仅输出该步骤的最终答案,不要输出任何额外的解释或对话。
# 原始问题:
{question}
# 完整计划:
{plan}
# 历史步骤与结果:
{history}
# 当前步骤:
{current_step}
请仅输出针对“当前步骤”的回答:
"""
Excecutor类:循环遍历计划,调用 LLM,并维护一个历史记录(状态)。
class Executor:
def __init__(self, llm_client):
self.llm_client = llm_client
def execute(self, question: str, plan: list[str]) -> str:
"""
根据计划,逐步执行并解决问题。
"""
history = "" # 用于存储历史步骤和结果的字符串
print("\n--- 正在执行计划 ---")
for i, step in enumerate(plan):
print(f"\n-> 正在执行步骤 {i+1}/{len(plan)}: {step}")
prompt = EXECUTOR_PROMPT_TEMPLATE.format(
question=question,
plan=plan,
history=history if history else "无", # 如果是第一步,则历史为空
current_step=step
)
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
# 更新历史记录,为下一步做准备
history += f"步骤 {i+1}: {step}\n结果: {response_text}\n\n"
print(f"✅ 步骤 {i+1} 已完成,结果: {response_text}")
# 循环结束后,最后一步的响应就是最终答案
final_answer = response_text
return final_answer
3.将Planner和Executor整合到一起,赋予其完整的解决问题能力(Orchestrator):创建一个主类 PlanAndSolveAgent,收一个 LLM 客户端,初始化内部的规划器和执行器,并提供一个简单的 run 方法来启动整个流程。
class PlanAndSolveAgent:
def __init__(self, llm_client):
"""
初始化智能体,同时创建规划器和执行器实例。
"""
self.llm_client = llm_client
self.planner = Planner(self.llm_client)
self.executor = Executor(self.llm_client)
def run(self, question: str):
"""
运行智能体的完整流程:先规划,后执行。
"""
print(f"\n--- 开始处理问题 ---\n问题: {question}")
# 1. 调用规划器生成计划
plan = self.planner.plan(question)
# 检查计划是否成功生成
if not plan:
print("\n--- 任务终止 --- \n无法生成有效的行动计划。")
return
# 2. 调用执行器执行计划
final_answer = self.executor.execute(question, plan)
print(f"\n--- 任务完成 ---\n最终答案: {final_answer}")
Reflection
内部纠错回路;核心点:迭代
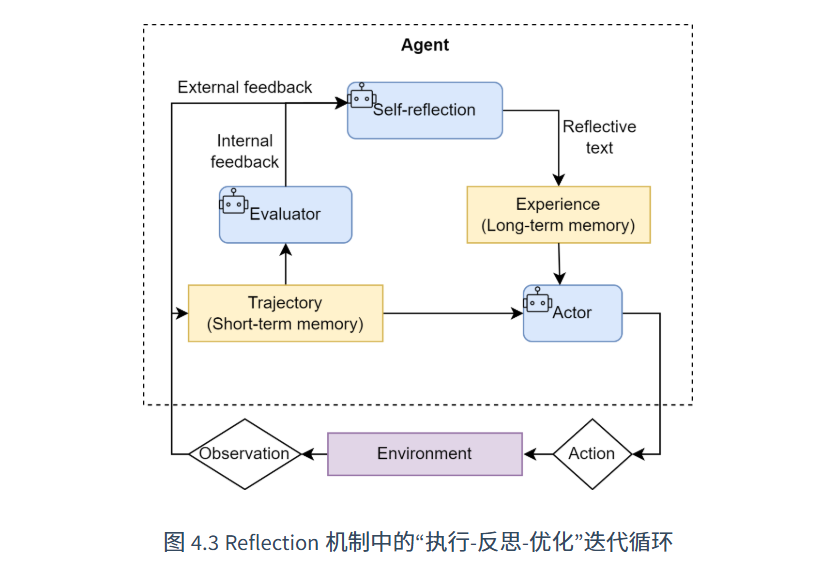
1.记忆管理机制(Memory类)
from typing import List, Dict, Any, Optional
class Memory:
"""
一个简单的短期记忆模块,用于存储智能体的行动与反思轨迹。
"""
def __init__(self):
"""
初始化一个空列表来存储所有记录。
"""
self.records: List[Dict[str, Any]] = []
def add_record(self, record_type: str, content: str):
"""
向记忆中添加一条新记录。
参数:
- record_type (str): 记录的类型 ('execution' 或 'reflection')。
- content (str): 记录的具体内容 (例如,生成的代码或反思的反馈)。
"""
record = {"type": record_type, "content": content}
self.records.append(record)
print(f"📝 记忆已更新,新增一条 '{record_type}' 记录。")
def get_trajectory(self) -> str:
"""
将所有记忆记录格式化为一个连贯的字符串文本,用于构建提示词。
"""
trajectory_parts = []
for record in self.records:
if record['type'] == 'execution':
trajectory_parts.append(f"--- 上一轮尝试 (代码) ---\n{record['content']}")
elif record['type'] == 'reflection':
trajectory_parts.append(f"--- 评审员反馈 ---\n{record['content']}")
return "\n\n".join(trajectory_parts)
def get_last_execution(self) -> Optional[str]:
"""
获取最近一次的执行结果 (例如,最新生成的代码)。
如果不存在,则返回 None。
"""
for record in reversed(self.records):
if record['type'] == 'execution':
return record['content']
return None
- 使用一个列表
records来按顺序存储每一次的行动和反思。 add_record方法负责向记忆中添加新的条目。get_trajectory方法是核心,它将记忆轨迹“序列化”成一段文本,可以直接插入到后续的提示词中,为模型的反思和优化提供完整的上下文。get_last_execution方便我们获取最新的“初稿”以供反思。
2.ReleactionAgent
Reflection 机制需要多个不同角色的提示词来协同工作。
-初始执行
INITIAL_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。请根据以下要求,编写一个Python函数。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
要求: {task}
请直接输出代码,不要包含任何额外的解释。
"""
-反思提示词
REFLECT_PROMPT_TEMPLATE = """
你是一位极其严格的代码评审专家和资深算法工程师,对代码的性能有极致的要求。
你的任务是审查以下Python代码,并专注于找出其在<strong>算法效率</strong>上的主要瓶颈。
# 原始任务:
{task}
# 待审查的代码:
```python
{code}
```
请分析该代码的时间复杂度,并思考是否存在一种<strong>算法上更优</strong>的解决方案来显著提升性能。
如果存在,请清晰地指出当前算法的不足,并提出具体的、可行的改进算法建议(例如,使用筛法替代试除法)。
如果代码在算法层面已经达到最优,才能回答“无需改进”。
请直接输出你的反馈,不要包含任何额外的解释。
"""
-优化提示词
REFINE_PROMPT_TEMPLATE = """
你是一位资深的Python程序员。你正在根据一位代码评审专家的反馈来优化你的代码。
# 原始任务:
{task}
# 你上一轮尝试的代码:
{last_code_attempt}
评审员的反馈:
{feedback}
请根据评审员的反馈,生成一个优化后的新版本代码。
你的代码必须包含完整的函数签名、文档字符串,并遵循PEP 8编码规范。
请直接输出优化后的代码,不要包含任何额外的解释。
"""
——整合
# 假设 llm_client.py 和 memory.py 已定义
# from llm_client import HelloAgentsLLM
# from memory import Memory
class ReflectionAgent:
def __init__(self, llm_client, max_iterations=3):
self.llm_client = llm_client
self.memory = Memory()
self.max_iterations = max_iterations
def run(self, task: str):
print(f"\n--- 开始处理任务 ---\n任务: {task}")
# --- 1. 初始执行 ---
print("\n--- 正在进行初始尝试 ---")
initial_prompt = INITIAL_PROMPT_TEMPLATE.format(task=task)
initial_code = self._get_llm_response(initial_prompt)
self.memory.add_record("execution", initial_code)
# --- 2. 迭代循环:反思与优化 ---
for i in range(self.max_iterations):
print(f"\n--- 第 {i+1}/{self.max_iterations} 轮迭代 ---")
# a. 反思
print("\n-> 正在进行反思...")
last_code = self.memory.get_last_execution()
reflect_prompt = REFLECT_PROMPT_TEMPLATE.format(task=task, code=last_code)
feedback = self._get_llm_response(reflect_prompt)
self.memory.add_record("reflection", feedback)
# b. 检查是否需要停止
if "无需改进" in feedback:
print("\n✅ 反思认为代码已无需改进,任务完成。")
break
# c. 优化
print("\n-> 正在进行优化...")
refine_prompt = REFINE_PROMPT_TEMPLATE.format(
task=task,
last_code_attempt=last_code,
feedback=feedback
)
refined_code = self._get_llm_response(refine_prompt)
self.memory.add_record("execution", refined_code)
final_code = self.memory.get_last_execution()
print(f"\n--- 任务完成 ---\n最终生成的代码:\n```python\n{final_code}\n```")
return final_code
def _get_llm_response(self, prompt: str) -> str:
"""一个辅助方法,用于调用LLM并获取完整的流式响应。"""
messages = [{"role": "user", "content": prompt}]
response_text = self.llm_client.think(messages=messages) or ""
return response_text
Evaluations:
+:质量高,可靠性强
-:成本高:模型调用花费、任务延迟、工程复杂度(开发精力);
学习资料参考来源:https://github.com/datawhalechina/hello-agents, Chatgpt

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)