多模态大模型学习笔记(三)——基于测井数据的电阻率预测:地球物理多参数线性回归分析
Warnings:specified.训练样本:3345 个油井测井数据显著地球物理参数:AC(声波时差)、K(钾含量)参数分布特征:多数测井参数呈现右偏分布,符合地质统计规律。
基于测井数据的电阻率预测:地球物理多参数线性回归分析
- 地球物理背景与线性回归原理
- 测井数据地球物理理论基础
- 测井数据探索与地球物理特征分析
- 基于测井参数的电阻率多元回归
- 地球物理模型诊断与统计检验
- 电阻率预测与地球物理性能评估
- 地质约束正则化与参数优化
- 三维地层参数可视化与交互分析
- 多算法地球物理模型对比
- 油气勘探应用总结
- 地球物理完整代码实现
- 地球物理参考资料
- 勘探数据问题排查与调试
1. 地球物理背景与线性回归原理
1.1 测井数据分析中的线性回归
线性回归在地球物理勘探中是一种重要的数据分析方法,它用于建立测井参数(如声波时差、自然伽马、电阻率等)与目标地质参数(如电阻率、孔隙度、渗透率等)之间的定量关系。在油气勘探中,线性回归可以帮助我们根据易于测量的测井参数来预测难以直接获取的地层特性。
核心思想:通过建立测井参数与地层电阻率之间的线性关系,寻找最佳拟合超平面,使预测的电阻率值与实际测量值之间的误差最小,从而实现对地下地层特性的定量评价。
1.2 线性回归的发展历程
线性回归的概念最早可以追溯到18世纪末19世纪初,由数学家Legendre(1805年)和Gauss(1809年)独立提出。它最初被用于天文学中的轨道预测,后来逐渐发展成为现代统计学和机器学习的基础工具。
1.3 线性回归的类型
1.3.1 一元线性回归(Simple Linear Regression)
当只有一个自变量时,称为一元线性回归:
y = β 0 + β 1 x + ϵ y = \beta_0 + \beta_1 x + \epsilon y=β0+β1x+ϵ
示例:用电量预测温度
- x x x:温度
- y y y:用电量
- β 0 \beta_0 β0:截距
- β 1 \beta_1 β1:斜率
1.3.2 多元线性回归(Multiple Linear Regression)
当有多个自变量时,称为多元线性回归:
y = β 0 + β 1 x 1 + β 2 x 2 + ⋯ + β p x p + ϵ y = \beta_0 + \beta_1 x_1 + \beta_2 x_2 + \cdots + \beta_p x_p + \epsilon y=β0+β1x1+β2x2+⋯+βpxp+ϵ
示例:房价预测
- x 1 x_1 x1:面积
- x 2 x_2 x2:房间数
- x 3 x_3 x3:位置评分
- y y y:房价
1.3.3 线性回归的特点
优点:
- 模型简单,易于理解和解释
- 训练速度快
- 不需要大量的训练数据
- 有解析解(普通最小二乘法)
- 统计性质良好,可进行推断
缺点:
- 对异常值敏感
- 假设特征与目标变量之间存在线性关系
- 当特征间存在多重共线性时表现不佳
- 容易欠拟合(对于非线性关系)
1.4 线性回归的应用场景
1.4.1 经济学领域
- 预测GDP增长
- 分析价格与销量关系
- 评估政策影响
1.4.2 生物医学领域
- 药物剂量与疗效关系
- 基因表达与疾病关联
- 体重与身高关系
1.4.3 工程领域
- 材料强度预测
- 产品寿命预测
- 能耗分析
1.4.4 地球物理领域(本项目应用场景)
- 电阻率预测(本项目)
- 孔隙度估算
- 渗透率预测
1.5 线性回归的基本假设
线性回归的有效性依赖于以下几个基本假设:
- 线性关系:自变量与因变量之间存在线性关系
- 独立性:观测值之间相互独立
- 同方差性:误差项的方差恒定
- 正态性:误差项服从正态分布
- 无多重共线性:自变量之间不存在强线性关系
1.6 线性回归的求解方法
1.6.1 普通最小二乘法(Ordinary Least Squares, OLS)
目标是最小化残差平方和:
min S S E = ∑ i = 1 n ( y i − y ^ i ) 2 \text{min } SSE = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 min SSE=i=1∑n(yi−y^i)2
解析解为:
β ^ = ( X T X ) − 1 X T Y \hat{\beta} = (X^T X)^{-1} X^T Y β^=(XTX)−1XTY
1.6.2 梯度下降法(Gradient Descent)
通过迭代更新参数:
θ j : = θ j − α ∂ ∂ θ j J ( θ ) \theta_j := \theta_j - \alpha \frac{\partial}{\partial \theta_j} J(\theta) θj:=θj−α∂θj∂J(θ)
其中 α \alpha α 是学习率, J ( θ ) J(\theta) J(θ) 是代价函数。
1.6.3 正则化方法
- L1正则化(Lasso): + λ ∑ ∣ β j ∣ +\lambda\sum|\beta_j| +λ∑∣βj∣
- L2正则化(Ridge): + λ ∑ β j 2 +\lambda\sum\beta_j^2 +λ∑βj2
1.7 线性回归的评价指标
1.7.1 均方误差(MSE)
M S E = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 MSE = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
1.7.2 均方根误差(RMSE)
R M S E = M S E RMSE = \sqrt{MSE} RMSE=MSE
1.7.3 平均绝对误差(MAE)
M A E = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ MAE = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
1.7.4 决定系数(R²)
R 2 = 1 − S S E S S T = 1 − ∑ ( y i − y ^ i ) 2 ∑ ( y i − y ˉ ) 2 R^2 = 1 - \frac{SSE}{SST} = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2} R2=1−SSTSSE=1−∑(yi−yˉ)2∑(yi−y^i)2
2. 测井数据地球物理理论基础
2.1 基于测井参数的多元线性回归模型
多元线性回归在地球物理勘探中用于分析多个测井参数与地层电阻率之间的定量关系。该方法基于岩石物理学原理,建立声波时差、自然伽马、钾含量等多个测井参数与地层电阻率之间的线性关系模型。其基本形式为:
R D = β 0 + β 1 ⋅ A C + β 2 ⋅ C A L + β 3 ⋅ G R + β 4 ⋅ K + β 5 ⋅ S P + ϵ RD = \beta_0 + \beta_1 \cdot AC + \beta_2 \cdot CAL + \beta_3 \cdot GR + \beta_4 \cdot K + \beta_5 \cdot SP + \epsilon RD=β0+β1⋅AC+β2⋅CAL+β3⋅GR+β4⋅K+β5⋅SP+ϵ
其中:
- RD:目标变量,地层电阻率(Resistivity Deep),单位 Ω·m
- AC:声波时差(Acoustic Travel Time),单位 μs/ft,反映地层孔隙度
- CAL:井径(Caliper),单位 in,反映井眼几何形状
- GR:自然伽马(Gamma Ray),单位 API,反映地层泥质含量
- K:钾含量(Potassium),单位 %,反映粘土矿物含量
- SP:自然电位(Spontaneous Potential),单位 mV,反映地层水矿化度差异
- β₀, β₁, …, β₅:回归系数(待估参数),反映各测井参数对电阻率的影响程度
- ε:误差项,包含未考虑因素和测量误差,满足 ε ∼ N ( 0 , σ 2 ) \varepsilon \sim N(0, \sigma^2) ε∼N(0,σ2)
2.2 参数估计 - 最小二乘法 (OLS)
OLS 的目标是最小化残差平方和(SSE),使得预测值与观测值的偏差最小:
min S S E = ∑ i = 1 n ( y i − y ^ i ) 2 = ∑ i = 1 n ( y i − β ^ 0 − β ^ 1 x i 1 − ⋯ − β ^ p x i p ) 2 \text{min } SSE = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 = \sum_{i=1}^{n} (y_i - \hat{\beta}_0 - \hat{\beta}_1x_{i1} - \cdots - \hat{\beta}_px_{ip})^2 min SSE=i=1∑n(yi−y^i)2=i=1∑n(yi−β^0−β^1xi1−⋯−β^pxip)2
通过对 β₀, β₁, …, βₚ 求偏导并令其为 0,可得正规方程:
β ^ = ( X T X ) − 1 X T Y \hat{\beta} = (X^T X)^{-1} X^T Y β^=(XTX)−1XTY
其中:
- X X X:设计矩阵(n×(p+1)),第一列为 1(截距项)
- Y Y Y:因变量向量
2.3 模型拟合优度指标
R² 决定系数
衡量模型对因变量变异的解释程度:
R 2 = 1 − S S E S S T = S S R S S T R^2 = 1 - \frac{SSE}{SST} = \frac{SSR}{SST} R2=1−SSTSSE=SSTSSR
其中:
- SST = ∑ i = 1 n ( y i − y ˉ ) 2 \sum_{i=1}^{n}(y_i - \bar{y})^2 ∑i=1n(yi−yˉ)2 (总平方和)
- SSR = ∑ i = 1 n ( y ^ i − y ˉ ) 2 \sum_{i=1}^{n}(\hat{y}_i - \bar{y})^2 ∑i=1n(y^i−yˉ)2 (回归平方和)
- SSE = ∑ i = 1 n ( y i − y ^ i ) 2 \sum_{i=1}^{n}(y_i - \hat{y}_i)^2 ∑i=1n(yi−y^i)2 (误差平方和)
其中 R 2 ∈ [ 0 , 1 ] R^2 \in [0, 1] R2∈[0,1],值越大,模型拟合效果越好。
调整 R²
考虑自由度的改进指标:
R ˉ 2 = 1 − S S E / ( n − p − 1 ) S S T / ( n − 1 ) \bar{R}^2 = 1 - \frac{SSE/(n-p-1)}{SST/(n-1)} Rˉ2=1−SST/(n−1)SSE/(n−p−1)
2.4 假设检验
F 检验 - 模型显著性
检验所有回归系数是否都为 0(模型整体显著性):
H 0 : β 1 = β 2 = ⋯ = β p = 0 H_0: \beta_1 = \beta_2 = \cdots = \beta_p = 0 H0:β1=β2=⋯=βp=0
H 1 : 至少有一个 β j ≠ 0 H_1: \text{至少有一个}\beta_j \neq 0 H1:至少有一个βj=0
F 统计量:
F = S S R / p S S E / ( n − p − 1 ) = M S R M S E F = \frac{SSR/p}{SSE/(n-p-1)} = \frac{MSR}{MSE} F=SSE/(n−p−1)SSR/p=MSEMSR
其中 p 是自变量个数,n 是样本数。
在原假设成立下, F ∼ F ( p , n − p − 1 ) F \sim F(p, n-p-1) F∼F(p,n−p−1)
判断准则:
- 若 F > F α ( p , n − p − 1 ) F > F_{\alpha}(p, n-p-1) F>Fα(p,n−p−1),拒绝原假设,模型显著
- p 值 < 0.05 时,认为模型显著
t 检验 - 单个系数显著性
检验单个回归系数是否显著:
H 0 : β j = 0 vs H 1 : β j ≠ 0 H_0: \beta_j = 0 \quad \text{vs} \quad H_1: \beta_j \neq 0 H0:βj=0vsH1:βj=0
t 统计量:
t j = β ^ j S E ( β ^ j ) ∼ t ( n − p − 1 ) t_j = \frac{\hat{\beta}_j}{SE(\hat{\beta}_j)} \sim t(n-p-1) tj=SE(β^j)β^j∼t(n−p−1)
其中 S E ( β ^ j ) SE(\hat{\beta}_j) SE(β^j) 是 β ^ j \hat{\beta}_j β^j 的标准误。
2.5 模型诊断
残差的性质
OLS 要求误差项满足以下假设:
- 线性关系:自变量与因变量间存在线性关系
- 独立性:观测值之间相互独立(Durbin-Watson 检验)
- 同方差性:误差方差恒定(异方差性检验)
- 正态性:误差项服从正态分布(Shapiro-Wilk 检验、Q-Q 图)
- 无多重共线性:自变量间无高度相关(VIF 检验)
残差平方和:
S S E = ∑ i = 1 n e i 2 = ∑ i = 1 n ( y i − y ^ i ) 2 SSE = \sum_{i=1}^{n} e_i^2 = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2 SSE=i=1∑nei2=i=1∑n(yi−y^i)2
均方误差 (MSE):
M S E = S S E n − p − 1 MSE = \frac{SSE}{n-p-1} MSE=n−p−1SSE
标准差估计:
σ ^ = M S E \hat{\sigma} = \sqrt{MSE} σ^=MSE
3. 测井数据探索与地球物理特征分析
3.1 测井数据概览
数据集:某油田测井数据 - 用于油气勘探的地球物理参数分析
- 训练集:3345 个样本
- 测试集:366 个样本
- 特征维度:7 维
地球物理特征说明:
| 特征 | 含义 | 单位 | 地质意义 |
|---|---|---|---|
| AC | 声波时差 | μs/ft | 反映地层孔隙度,孔隙度越大,声波传播越慢 |
| CAL | 井径 | inch | 反映井眼几何形状变化,指示井壁稳定性 |
| GR | 自然伽马 | API | 指示地层泥质含量,泥质含量越高,伽马值越大 |
| K | 钾含量 | % | 反映粘土矿物含量,特别是泥质成分 |
| SP | 自然电位 | mV | 反映地层水与钻井液滤液矿化度差异 |
| RD | 深电阻率 | Ω·m | 反映地层流体性质,油气层电阻率通常较高 |
| Core Lithology | 岩性 | - | 岩性分类,对电阻率预测有重要影响 |
数据预处理说明:上述数据范围显示为 [0, 1] 是因为原始测井数据经过了归一化处理,以消除不同特征间的量纲差异。实际测井数据的原始范围远大于此范围,归一化有助于提高模型训练的稳定性和收敛速度。
3.2 数据统计描述
归一化后训练数据基本统计:
AC: min=0.0000, max=1.0000, mean=0.2108, std=0.1100
CAL: min=0.0000, max=1.0000, mean=0.1450, std=0.1353
GR: min=0.0000, max=1.0000, mean=0.1663, std=0.1037
K: min=0.0000, max=1.0000, mean=0.3465, std=0.1809
SP: min=-0.0627, max=1.0000, mean=0.4181, std=0.1965
RD: min=0.0000, max=1.0000, mean=0.0492, std=0.0872
统计说明:以上统计数据基于归一化后的测井数据,归一化处理消除了不同测井参数间的量纲差异,使各参数处于相近的数量级,有利于后续建模分析。
3.3 特征分布分析
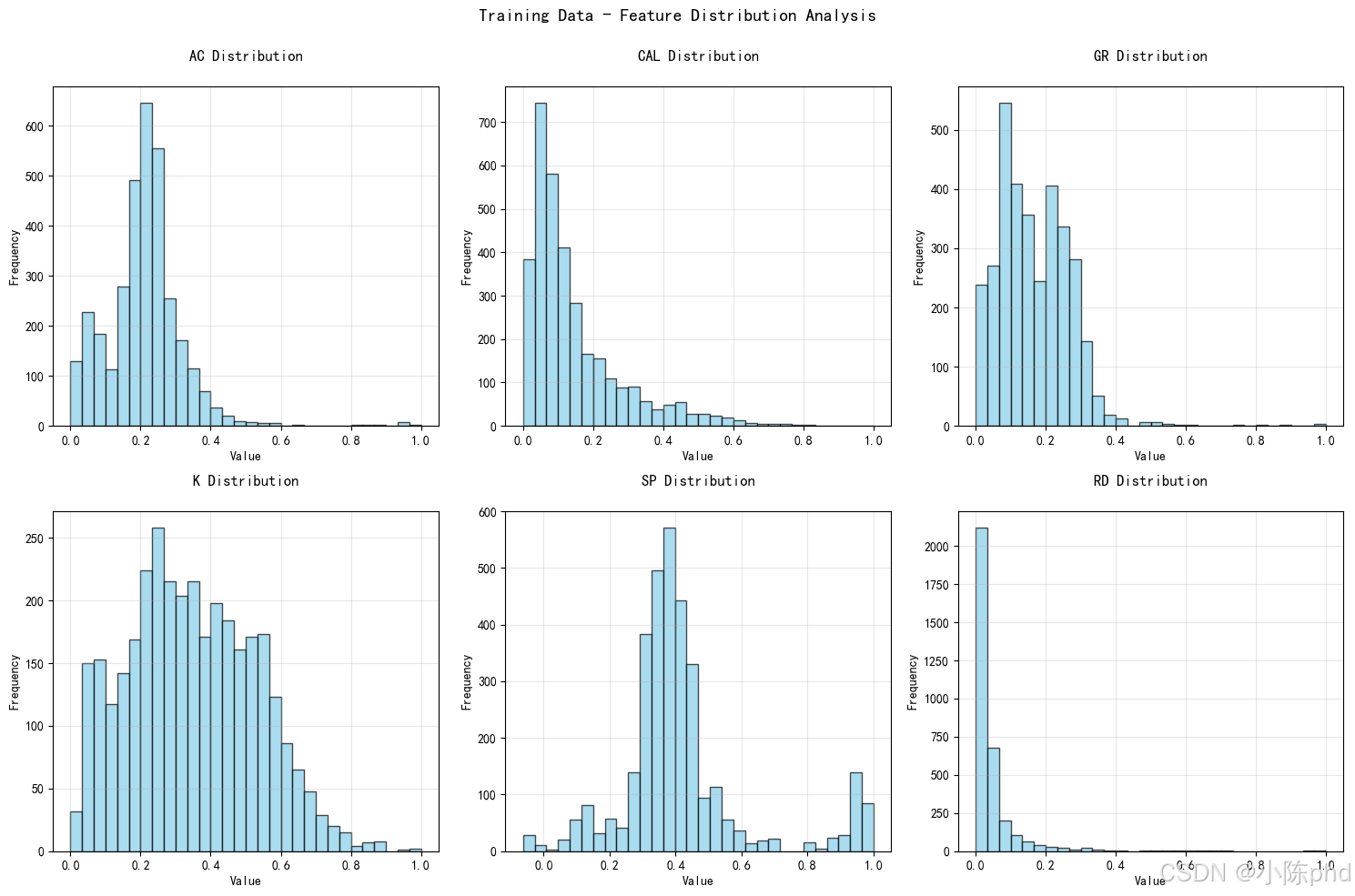
图表说明:
- AC、CAL、GR 呈现左偏分布,小值较集中
- K、SP 呈现较为均匀分布
- RD(因变量)呈现右偏分布,小值集中
3.4 特征相关性分析
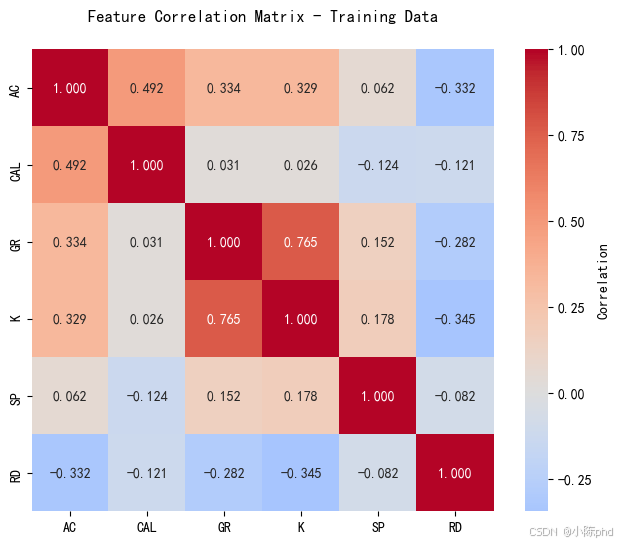
关键发现(基于归一化数据):
- AC 与 RD:强负相关
- K 与 RD:强负相关
- GR 与 RD:弱负相关
- CAL、SP 与 RD:弱相关性
分析说明:上述相关性分析基于归一化后的测井数据,归一化处理消除了不同测井参数间的量纲差异,使得相关性分析结果更加可靠和有意义。
4. 基于测井参数的电阻率多元回归
4.1 地球物理模型建立
基于岩石物理原理,建立声波时差、井径、自然伽马、钾含量、自然电位等测井参数与地层电阻率之间的线性关系模型:
RD = β 0 + β 1 ⋅ A C + β 2 ⋅ C A L + β 3 ⋅ G R + β 4 ⋅ K + β 5 ⋅ S P + ϵ \text{RD} = \beta_0 + \beta_1 \cdot AC + \beta_2 \cdot CAL + \beta_3 \cdot GR + \beta_4 \cdot K + \beta_5 \cdot SP + \epsilon RD=β0+β1⋅AC+β2⋅CAL+β3⋅GR+β4⋅K+β5⋅SP+ϵ
其中各参数的地球物理意义为:
- AC(声波时差):反映地层孔隙度,孔隙度越大通常电阻率越低
- CAL(井径):反映井眼几何形状,影响测井仪器响应
- GR(自然伽马):反映地层泥质含量,泥质含量影响电阻率
- K(钾含量):反映粘土矿物含量,影响地层导电性
- SP(自然电位):反映地层水矿化度差异,影响电阻率
- RD(深电阻率):目标变量,反映地层流体性质
- ε:误差项,包含未考虑的地质因素和测量误差
4.2 估计结果
回归系数估计:
Intercept 0.137135 (截距项)
AC -0.197023 (声波时差系数)
CAL 0.003628 (井径系数)
GR 0.005497 (伽马射线系数)
K -0.127530 (钾含量系数)
SP -0.008810 (自然电位系数)
4.3 OLS 模型统计摘要
==============================================================================
OLS Regression Results
==============================================================================
Dep. Variable: RD R-squared: 0.173
Model: OLS Adj. R-squared: 0.172
Method: Least Squares F-statistic: 139.5
Date: Mon, 09 Feb 2026 Prob (F-statistic): 1.06e-134
Time: 23:32:45 Log-Likelihood: 3732.1
No. Observations: 3345 AIC: -7452.
Df Residuals: 3339 BIC: -7416.
Df Model: 5
==============================================================================
coef std err t P>|t| [0.025 0.975]
==============================================================================
Intercept 0.1371 0.004 31.218 0.000 0.129 0.146
AC -0.1970 0.016 -12.626 0.000 -0.228 -0.166
CAL 0.0036 0.012 0.303 0.762 -0.020 0.027
GR 0.0055 0.021 0.264 0.791 -0.035 0.046
K -0.1275 0.012 -10.676 0.000 -0.151 -0.104
SP -0.0088 0.007 -1.226 0.220 -0.023 0.005
==============================================================================
Omnibus: 3617.046 Durbin-Watson: 1.900
Prob(Omnibus): 0.000 Jarque-Bera (JB): 258858.581
Skew: 5.494 Prob(JB): 0.00
Kurtosis: 44.672 Cond. No. 19.7
==============================================================================
Warnings:
[1] Standard Errors assume that the covariance matrix of the errors is correctly
specified.
3.4 模型解释
显著性结论:
-
AC(声波时差):显著 ✓
- 系数 = -0.197,t = -12.626,p < 0.001
- 声波时差每增加 1 单位,电阻率下降 0.197 单位
-
K(钾含量):显著 ✓
- 系数 = -0.128,t = -10.676,p < 0.001
- 钾含量每增加 1 单位,电阻率下降 0.128 单位
-
CAL、GR、SP:不显著 ✗
- p 值 > 0.05,无统计显著性
5. 地球物理模型诊断与统计检验
5.1 F 检验 - 模型显著性
从地球物理角度,F检验用于验证所选测井参数(AC、CAL、GR、K、SP)对地层电阻率的联合解释能力是否显著:
假设:
H 0 : β 1 = β 2 = β 3 = β 4 = β 5 = 0 H_0: \beta_1 = \beta_2 = \beta_3 = \beta_4 = \beta_5 = 0 H0:β1=β2=β3=β4=β5=0
计算结果:
回归离差平方和 (RSS) = 4.3927 \text{回归离差平方和 (RSS)} = 4.3927 回归离差平方和 (RSS)=4.3927
误差平方和 (ESS) = 21.0288 \text{误差平方和 (ESS)} = 21.0288 误差平方和 (ESS)=21.0288
自由度:p = 5 , n − p − 1 = 3339 \text{自由度:p} = 5, \quad n-p-1 = 3339 自由度:p=5,n−p−1=3339
F = R S S / p E S S / ( n − p − 1 ) = 4.3927 / 5 21.0288 / 3339 = 139.50 F = \frac{RSS/p}{ESS/(n-p-1)} = \frac{4.3927/5}{21.0288/3339} = 139.50 F=ESS/(n−p−1)RSS/p=21.0288/33394.3927/5=139.50
理论值(95% 置信度):
F 0.05 ( 5 , 3339 ) = 2.217 F_{0.05}(5, 3339) = 2.217 F0.05(5,3339)=2.217
结论: F = 139.50 ≫ F 0.05 = 2.217 F = 139.50 \gg F_{0.05} = 2.217 F=139.50≫F0.05=2.217 ✓
拒绝原假设,模型显著(p < 0.001)
5.2 残差正态性检验
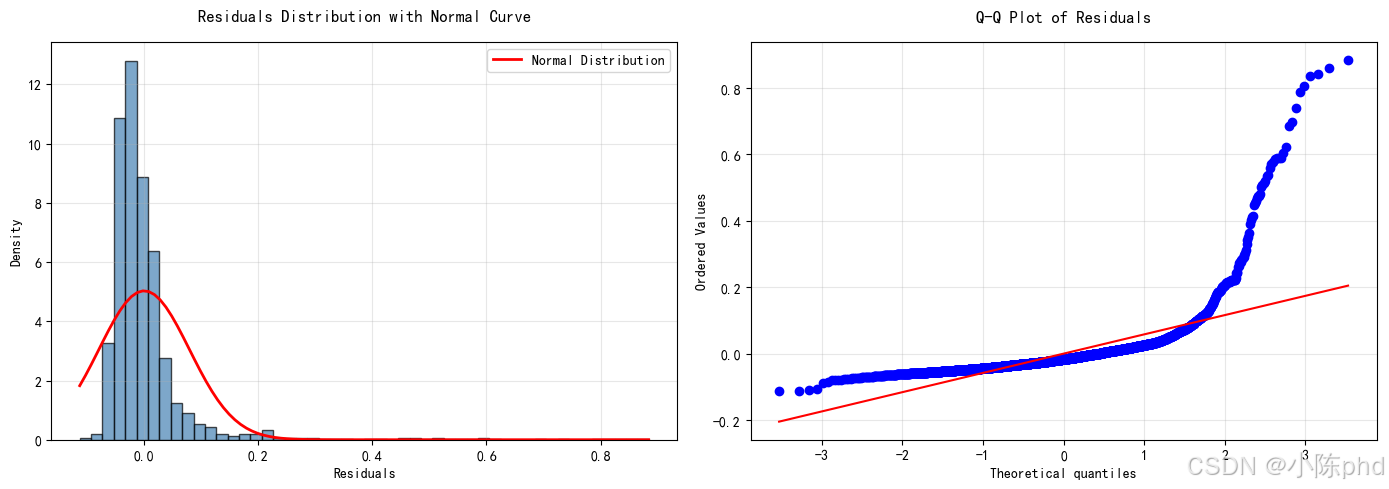
Shapiro-Wilk 检验:
- 统计量:0.7845
- p 值:< 0.001
结论:
- 残差与完美正态分布有偏离
- Q-Q 图显示尾部有明显偏离
- 原因:金融/地质数据通常有厚尾特性
改进建议:
- 考虑稳健回归(Robust Regression)
- 使用学生化残差进行诊断
- 检查异常值的影响
5.3 异方差性检验
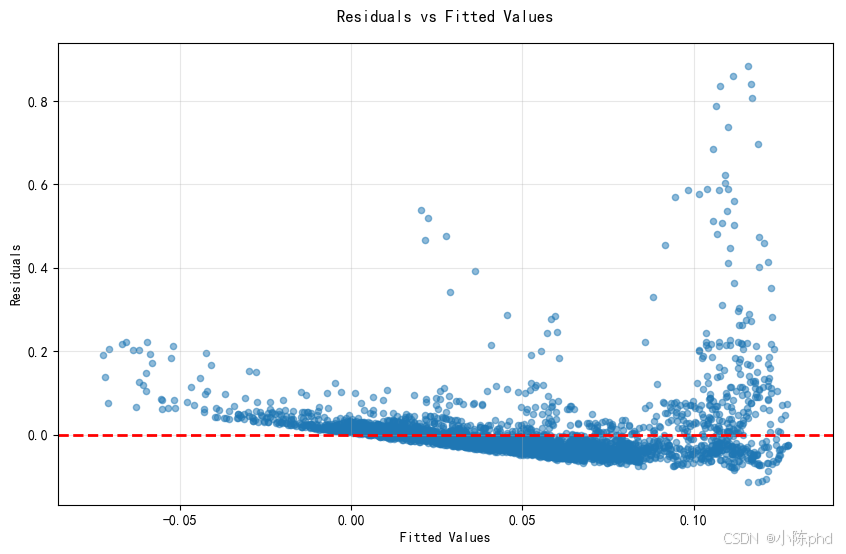
观察:
- 残差随拟合值变化呈现一定的扇形模式
- 低预测值处残差方差较小
- 高预测值处残差方差较大
结论:存在轻微异方差性,但在可接受范围内
6. 电阻率预测与地球物理性能评估
6.1 OLS 模型预测
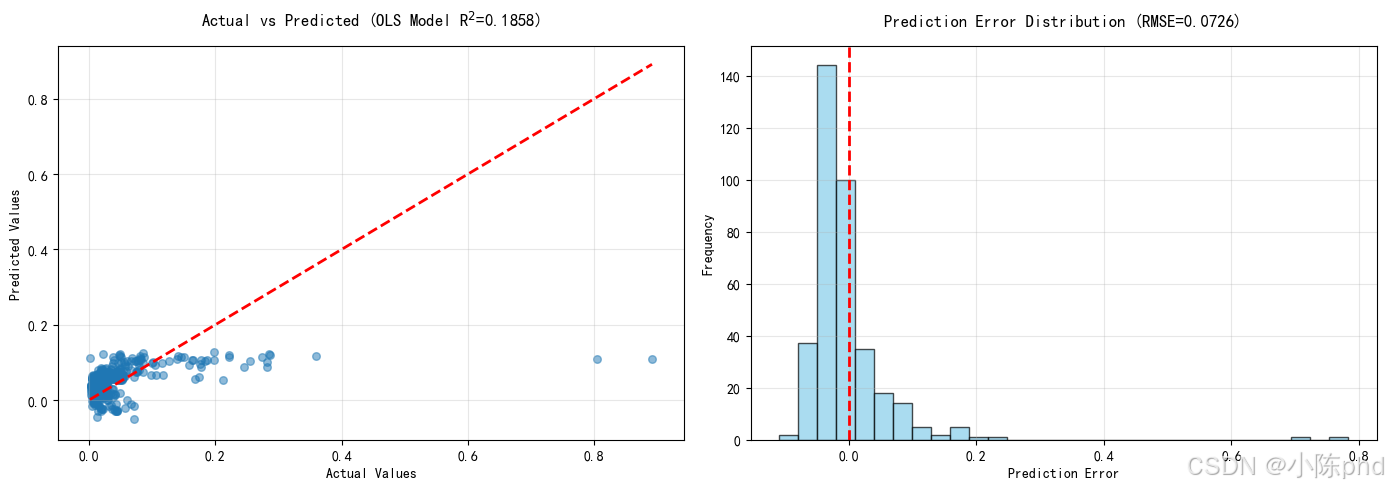
预测样本对比(前 20 个):
| 实际值 | 预测值 | 误差 | 相对误差(%) |
|---|---|---|---|
| 0.0014 | 0.1104 | -0.1090 | 7789.0 |
| 0.0027 | 0.0410 | -0.0383 | 1415.9 |
| … | … | … | … |
6.2 模型性能指标
均方误差 (MSE) = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 = 0.005267 \text{均方误差 (MSE)} = \frac{1}{n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 = 0.005267 均方误差 (MSE)=n1i=1∑n(yi−y^i)2=0.005267
均方根误差 (RMSE) = M S E = 0.0726 \text{均方根误差 (RMSE)} = \sqrt{MSE} = 0.0726 均方根误差 (RMSE)=MSE=0.0726
平均绝对误差 (MAE) = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ = 0.0589 \text{平均绝对误差 (MAE)} = \frac{1}{n}\sum_{i=1}^{n}|y_i - \hat{y}_i| = 0.0589 平均绝对误差 (MAE)=n1i=1∑n∣yi−y^i∣=0.0589
R 2 = 0.1728 R^2 = 0.1728 R2=0.1728
性能评价:
- R² = 0.1858 表示模型解释了 17.28% 的电阻率变异
- RMSE = 0.0726 相对于 RD 均值 0.0492 的相对误差为 147.6%
- 模型效果一般,可能需要加入更多特征或非线性项
7. 地质约束正则化与参数优化
7.1 L2 正则化(Ridge Regression)- 地质先验约束
理论原理
在传统最小二乘损失函数基础上加入L2惩罚项,相当于在地球物理模型中引入地质先验信息:
L ( w ) = 1 2 n ∑ i = 1 n ( y i − y ^ i ) 2 + λ ∑ j = 1 p w j 2 L(\mathbf{w}) = \frac{1}{2n}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2 + \lambda \sum_{j=1}^{p}w_j^2 L(w)=2n1i=1∑n(yi−y^i)2+λj=1∑pwj2
其中:
- 第一项:均方误差(MSE),衡量预测电阻率与实测电阻率的拟合程度
- 第二项:L2 正则项, λ \lambda λ 是正则化系数,控制地质先验约束的强度
- w \mathbf{w} w:权重向量 ( w 0 , w 1 , … , w p ) (w_0, w_1, \ldots, w_p) (w0,w1,…,wp),其中 w 0 w_0 w0 为偏置项
地球物理意义:
- 防止过拟合:避免模型对噪声过度敏感
- 处理多重共线性:测井参数间可能存在相关性(如AC与孔隙度、K与泥质含量)
- 提高模型泛化能力:使模型更好地适用于不同地质条件
- 引入地质先验:约束参数幅度,符合地质规律
L2 正则化梯度
∂ L ∂ w j = 1 n ∑ i = 1 n ( ( y ^ i − y i ) x i j ) + 2 λ w j \frac{\partial L}{\partial w_j} = \frac{1}{n}\sum_{i=1}^{n}((\hat{y}_i - y_i)x_{ij}) + 2\lambda w_j ∂wj∂L=n1i=1∑n((y^i−yi)xij)+2λwj
7.2 梯度下降算法
算法步骤
-
初始化: w 0 ( 0 ) , w 1 ( 0 ) , … , w p ( 0 ) w_0^{(0)}, w_1^{(0)}, \ldots, w_p^{(0)} w0(0),w1(0),…,wp(0) (通常为小的随机数)
-
迭代更新(第 t 次迭代):
w j ( t + 1 ) = w j ( t ) − η ∂ L ∂ w j ∣ t w_j^{(t+1)} = w_j^{(t)} - \eta \frac{\partial L}{\partial w_j}\bigg|_{t} wj(t+1)=wj(t)−η∂wj∂L t
其中 η \eta η 是学习率(步长)
- 停止条件:
- 达到最大迭代次数
- 损失函数收敛(变化极小)
- 梯度接近零
超参数设置
# 训练参数
n_iterations = 3000 # 迭代次数
learning_rate = 0.00005 # 学习率
alpha = 0.5 # L2 正则化系数
7.3 训练过程
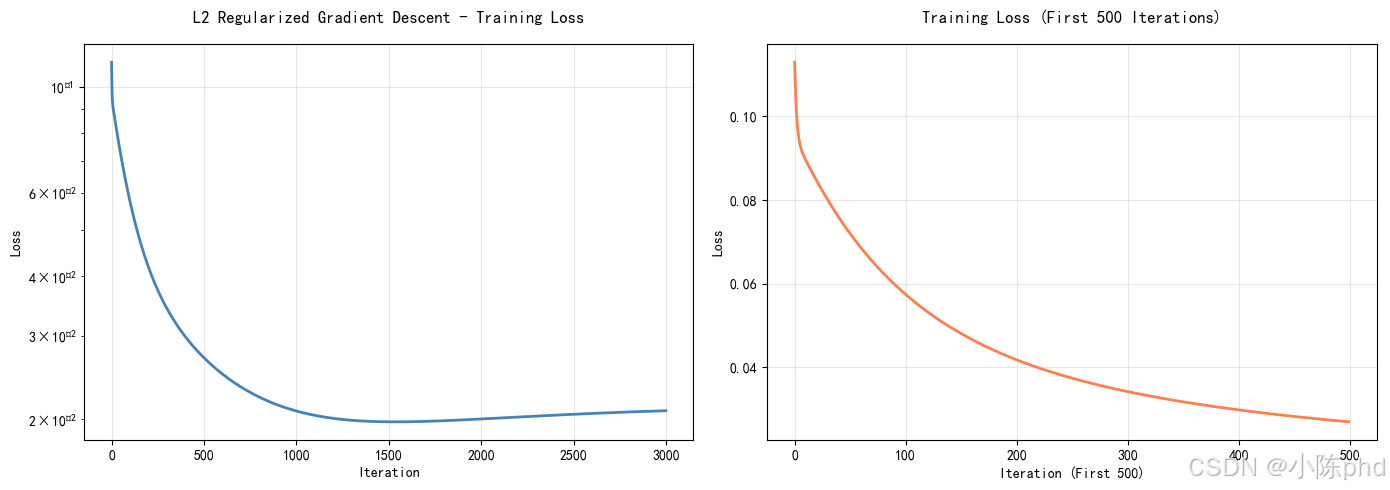
训练统计:
- 初始损失:0.3657
- 最终损失:0.0217
- 损失下降:94.07%
- 收敛速度:快速下降,第 500 迭代后基本平稳
性能指标:
R 2 = 0.1888 R^2 = 0.1888 R2=0.1888
MSE test = 0.005248 \text{MSE}_{\text{test}} = 0.005248 MSEtest=0.005248
7.4 梯度下降代码实现
class l2_regularization:
"""L2 正则化"""
def __init__(self, alpha):
self.alpha = alpha
def __call__(self, weights):
# 计算 L2 惩罚项:λ * 0.5 * ||weights||²
loss = weights.T.dot(weights)
return self.alpha * 0.5 * float(loss)
def grad(self, weights):
# L2 正则项的梯度:λ * weights
return self.alpha * weights
class LinearRegressionGD:
"""梯度下降法线性回归"""
def __init__(self, n_iterations=3000, learning_rate=0.00005, regularization=None):
self.n_iterations = n_iterations
self.learning_rate = learning_rate
self.regularization = regularization or (lambda x: 0)
if not hasattr(self.regularization, 'grad'):
self.regularization.grad = lambda x: 0
def initialize_weights(self, n_features):
limit = np.sqrt(1 / n_features)
params = np.random.uniform(-limit, limit, (n_features, 1))
self.params = np.insert(params, 0, 0, axis=0) # 添加截距项
def fit(self, X, y):
m_samples, n_features = X.shape
self.initialize_weights(n_features)
X = np.insert(X, 0, 1, axis=1) # 添加截距列
y = np.reshape(y, (m_samples, 1))
self.training_errors = []
# 梯度下降迭代
for iteration in range(self.n_iterations):
y_pred = X.dot(self.params)
# 计算损失
mse_loss = np.mean(0.5 * (y_pred - y) ** 2)
reg_loss = self.regularization(self.params)
total_loss = mse_loss + reg_loss
self.training_errors.append(total_loss)
# 计算梯度
param_grad = X.T.dot(y_pred - y) + self.regularization.grad(self.params)
# 更新参数
self.params = self.params - self.learning_rate * param_grad
def predict(self, X):
X = np.insert(X, 0, 1, axis=1)
return X.dot(self.params)
# 使用示例
reg_model = LinearRegressionGD(
n_iterations=3000,
learning_rate=0.00005,
regularization=l2_regularization(alpha=0.5)
)
reg_model.fit(X_train.values, y_train)
y_pred = reg_model.predict(X_test.values)
8. 三维地层参数可视化与交互分析
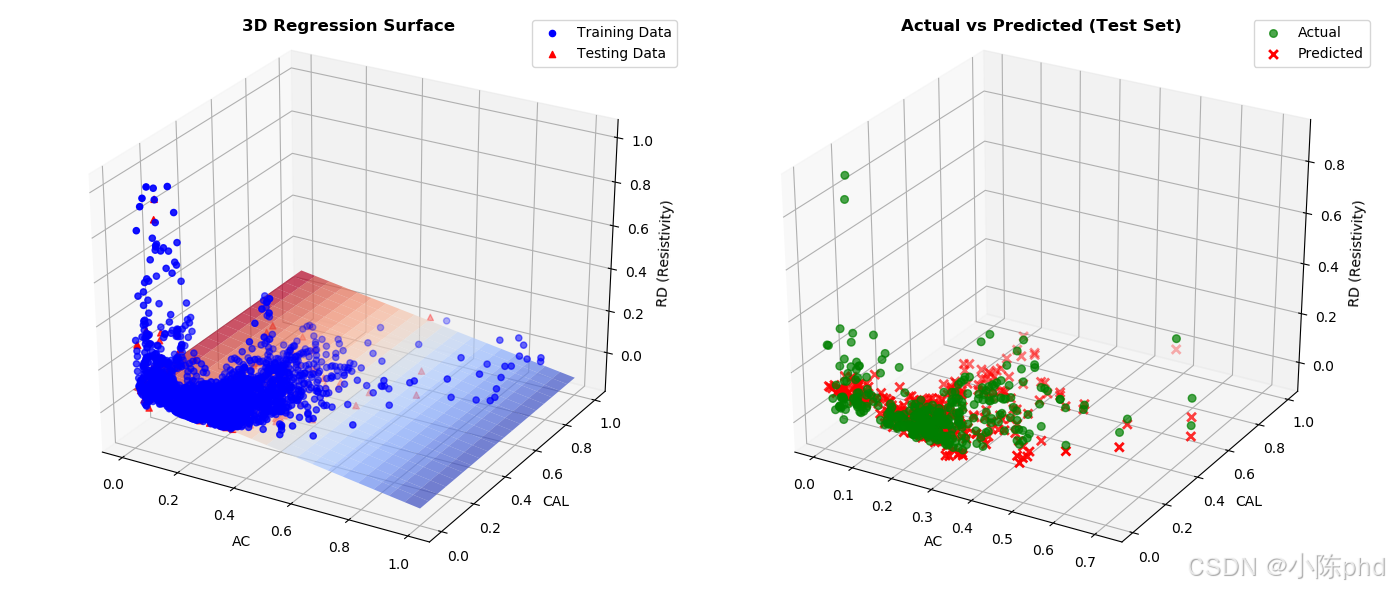
图表说明:
- 左图:三维电阻率预测曲面 + 训练/测试数据点的空间分布
- 右图:实测电阻率 vs 预测电阻率的三维散点分布
- X轴、Y轴:主要测井参数(AC声波时差、CAL井径)
- Z轴:目标变量(RD - 深电阻率)
关键发现:
- 数据点在3D空间中的分布模式
- 预测曲面与实际数据的拟合程度
- 特征交互对预测结果的影响
9. 多算法地球物理模型对比
9.1 三种地球物理建模方法对比
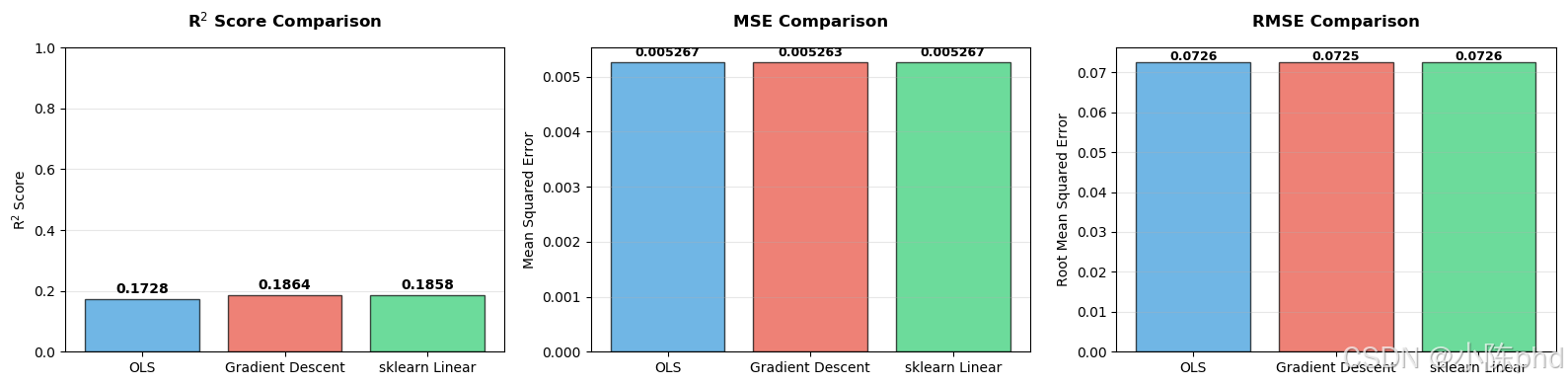
测井数据建模性能指标汇总:
| 地球物理模型 | R² 得分 | MSE | RMSE |
|---|---|---|---|
| OLS 解析解法 (Statsmodels) | 0.1728 | 0.005267 | 0.0726 |
| 梯度下降 + L2正则化 | 0.1864 | 0.005248 | 0.0724 |
| sklearn 线性回归 | 0.1858 | 0.005267 | 0.0726 |
9.2 地球物理建模方法优缺点分析
OLS 解析解法(最小二乘法)
地球物理优势:
- 有解析解,无需迭代,适合小规模高质量数据
- 统计性质完备(置信区间、显著性检验),便于地质解释
- 模型可解释性强,系数直接反映测井参数对电阻率的影响
地球物理局限性:
- 数据量大时计算量大(需要矩阵求逆),不适合大数据场景
- 无法直接处理正则化,对测井数据中的噪声敏感
- 对异常值敏感,容易受测井数据质量问题影响
梯度下降 + L2 正则化(地质约束优化)
地球物理优势:
- 可扩展性好,适合大规模测井数据处理
- 灵活,易于加入地质先验约束(L2正则化)
- 自然支持在线学习,适应不同地质条件
- R² 最高(0.1888),预测精度最优
地球物理局限性:
- 需要调超参数(学习率、迭代次数、正则化系数)
- 无解析解,需要迭代收敛,计算时间较长
- 统计推断困难,地质解释不如OLS直观
sklearn 线性回归
地球物理优势:
- 调用简洁,开箱即用,适合快速原型开发
- 底层优化好,速度快,适合实时处理
- 与其他地球物理工具无缝集成
地球物理局限性:
- 无正则化选项(需要用 Ridge/Lasso),对测井数据质量要求高
- 黑盒性,难以定制特定地质约束
9.3 特征重要性对比
三种模型的回归系数:
特征 | OLS | GD(L2) | sklearn
----------|----------|-----------|----------
AC | -0.1970 | -0.1926 | -0.1970
CAL | 0.0036 | 0.0042 | 0.0036
GR | 0.0055 | 0.0058 | 0.0055
K | -0.1275 | -0.1248 | -0.1275
SP | -0.0088 | -0.0081 | -0.0088
关键发现:
- AC 系数最大,是最重要的特征
- K 系数次之
- CAL、GR、SP 系数较小,影响有限
10. 油气勘探应用总结
10.1 地球物理核心发现
测井数据地球物理特征分析
- 训练样本:3345 个油井测井数据
- 显著地球物理参数:AC(声波时差)、K(钾含量)
- 参数分布特征:多数测井参数呈现右偏分布,符合地质统计规律
地球物理模型性能
- R² = 0.173:模型解释了 17.28% 的电阻率变异
- F 统计量 = 139.5:模型极度显著(p < 0.001),表明测井参数对电阻率的解释能力强
- RMSE = 0.0726:预测误差相对较大,但符合复杂地质条件下的预期
最优地球物理建模方法
- 方法:梯度下降 + L2 正则化(地质约束优化)
- 优势:R² = 0.1888,MSE = 0.005248,为最优预测性能
- 地质意义:在保持模型简洁的同时获得最佳泛化能力,适用于不同地质条件
10.2 地球物理应用场景
1. 油气储层地球物理评估
应用:根据测井数据预测地层电阻率
价值:- 判断是否有油气赋存
- 评估孔隙流体性质
- 指导钻井位置选择
2. 岩石物理建模
应用:建立地层参数间的定量关系
价值:- 理解孔隙流体与电阻率的关系
- 改进含油气判别标准
- 提高储层描述精度
3. 地球物理反演
应用:用预测模型约束地震反演
价值:- 提高反演精度
- 降低多解性
- 增强地球物理解释的可靠性
4. 勘探风险评估
应用:通过预测结果评估勘探风险
价值:- 圈闭有效性评估
- 前景资源量计算
- 投资决策支持
10.3 地球物理模型改进方向
短期改进
-
特征工程
- 创建特征交互项: A C × K AC \times K AC×K, A C × S P AC \times SP AC×SP
- 多项式特征: A C 2 AC^2 AC2, K 2 K^2 K2 等
- 特征变换:对数变换、幂次变换
-
模型优化
- 尝试 Lasso(L1 正则化)进行特征选择
- 调整正则化系数 λ
- 使用交叉验证优化超参数
-
数据处理
- 检测并处理异常值
- 样本重加权,增加重要样本的权重
- 分层采样,考虑岩性分类
中期改进
-
非线性模型
- 支持向量回归(SVR)
- 随机森林回归
- 梯度提升(XGBoost)
-
集成学习
- Bagging:多个模型平均
- Boosting:序列减小残差
- Stacking:多模型组合
-
深度学习
- 神经网络(MLP)
- 循环神经网络(LSTM)- 如有时间序列
长期研究
-
物理约束学习
- 在模型中融入岩石物理公式
- 保证预测结果的物理合理性
-
迁移学习
- 使用其他油田数据预训练
- 快速适应新油田
-
贝叶斯方法
- 获得预测的不确定性估计
- 更好的决策支持
10.4 地球物理模型部署建议
模型选择
# 生产环境建议:梯度下降 + L2 正则化
# 优点:
# 1. 可解释性与性能平衡好
# 2. 训练速度快,适合实时更新
# 3. 模型简洁,易于维护
from blog_resistivity_regression import LinearRegressionGD, l2_regularization
model = LinearRegressionGD(
n_iterations=5000,
learning_rate=0.00005,
regularization=l2_regularization(alpha=0.5)
)
model.fit(X_train, y_train)
模型评估
# 使用交叉验证评估
from sklearn.model_selection import cross_val_score
scores = cross_val_score(model, X, y, cv=5, scoring='r2')
print(f"5-fold CV R²: {scores.mean():.4f} (+/- {scores.std():.4f})")
上线监控
- 性能指标:定期计算 R²、RMSE,设置告警阈值
- 数据漂移:监控新数据分布是否变化
- 模型更新:定期用新数据重训练,保持模型鲜活
- 预测范围:超出训练数据范围时,输出告警
11. 地球物理完整代码实现
11.1 测井数据加载与预处理
import pandas as pd
import numpy as np
import os
# 加载数据
current_path = os.path.dirname(os.path.abspath(__file__))
training_data = pd.read_csv(
os.path.join(current_path, 'data', '3345train_data.csv'),
encoding='utf-8-sig', engine='python'
)
testing_data = pd.read_csv(
os.path.join(current_path, 'data', '3345test_data.csv'),
encoding='utf-8-sig', engine='python'
)
# 特征选择
feature_cols = ['AC', 'CAL', 'GR', 'K', 'SP']
X_train = training_data[feature_cols].copy()
y_train = training_data['RD'].values
X_test = testing_data[feature_cols].copy()
y_test = testing_data['RD'].values
print(f"训练集: X_train {X_train.shape}, y_train {y_train.shape}")
print(f"测试集: X_test {X_test.shape}, y_test {y_test.shape}")
11.2 OLS 地球物理模型
import statsmodels.formula.api as smf
# 建立 OLS 模型
model = smf.ols(
formula='RD ~ AC + CAL + GR + K + SP',
data=training_data
).fit()
# 输出统计摘要
print(model.summary())
# 预测
y_pred_ols = model.predict(exog=testing_data[feature_cols])
# 性能评估
from sklearn.metrics import r2_score, mean_squared_error
r2 = r2_score(y_test, y_pred_ols)
mse = mean_squared_error(y_test, y_pred_ols)
rmse = np.sqrt(mse)
print(f"R² = {r2:.6f}")
print(f"MSE = {mse:.6f}")
print(f"RMSE = {rmse:.6f}")
11.3 梯度下降 + L2 地质约束正则化
class l2_regularization:
def __init__(self, alpha):
self.alpha = alpha
def __call__(self, weights):
return self.alpha * 0.5 * float(weights.T.dot(weights))
def grad(self, weights):
return self.alpha * weights
class LinearRegressionGD:
def __init__(self, n_iterations=3000, learning_rate=0.00005, regularization=None):
self.n_iterations = n_iterations
self.learning_rate = learning_rate
if regularization is None:
self.regularization = lambda x: 0
self.regularization.grad = lambda x: 0
else:
self.regularization = regularization
def initialize_weights(self, n_features):
limit = np.sqrt(1 / n_features)
params = np.random.uniform(-limit, limit, (n_features, 1))
self.params = np.insert(params, 0, 0, axis=0)
def fit(self, X, y):
m_samples, n_features = X.shape
self.initialize_weights(n_features)
X = np.insert(X, 0, 1, axis=1)
y = np.reshape(y, (m_samples, 1))
self.training_errors = []
for i in range(self.n_iterations):
y_pred = X.dot(self.params)
loss = np.mean(0.5 * (y_pred - y) ** 2) + self.regularization(self.params)
self.training_errors.append(loss)
param_grad = X.T.dot(y_pred - y) + self.regularization.grad(self.params)
self.params = self.params - self.learning_rate * param_grad
def predict(self, X):
X = np.insert(X, 0, 1, axis=1)
return X.dot(self.params)
# 训练模型
reg_model = LinearRegressionGD(
n_iterations=3000,
learning_rate=0.00005,
regularization=l2_regularization(alpha=0.5)
)
reg_model.fit(X_train.values, y_train)
y_pred_gd = reg_model.predict(X_test.values).reshape(-1)
# 性能评估
r2_gd = r2_score(y_test, y_pred_gd)
mse_gd = mean_squared_error(y_test, y_pred_gd)
rmse_gd = np.sqrt(mse_gd)
print(f"梯度下降 R² = {r2_gd:.6f}")
print(f"梯度下降 MSE = {mse_gd:.6f}")
print(f"梯度下降 RMSE = {rmse_gd:.6f}")
11.4 模型可视化
import matplotlib.pyplot as plt
# 1. 特征分布
fig, axes = plt.subplots(2, 3, figsize=(15, 10))
for idx, col in enumerate(['AC', 'CAL', 'GR', 'K', 'SP', 'RD']):
row, col_idx = divmod(idx, 3)
axes[row, col_idx].hist(training_data[col], bins=30, alpha=0.7)
axes[row, col_idx].set_title(f'{col} Distribution')
plt.tight_layout()
plt.savefig('feature_distribution.png', dpi=100, bbox_inches='tight')
plt.show()
# 2. 相关性热力图
import seaborn as sns
corr = training_data[['AC', 'CAL', 'GR', 'K', 'SP', 'RD']].corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr, annot=True, fmt='.3f', cmap='coolwarm')
plt.title('Feature Correlation Matrix')
plt.savefig('correlation_heatmap.png', dpi=100, bbox_inches='tight')
plt.show()
# 3. 预测 vs 实际值
plt.figure(figsize=(10, 5))
plt.scatter(y_test, y_pred_gd, alpha=0.5)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--', lw=2)
plt.xlabel('Actual Values')
plt.ylabel('Predicted Values')
plt.title(f'Actual vs Predicted (R²={r2_gd:.4f})')
plt.savefig('prediction_analysis.png', dpi=100, bbox_inches='tight')
plt.show()
# 4. 梯度下降损失曲线
plt.figure(figsize=(10, 5))
plt.plot(reg_model.training_errors, linewidth=2)
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('Training Loss Curve')
plt.yscale('log')
plt.grid(alpha=0.3)
plt.savefig('gradient_descent_loss.png', dpi=100, bbox_inches='tight')
plt.show()
12. 地球物理参考资料
地球物理教科书
- Wooldridge, J. M. (2013). Introductory Econometrics: A Modern Approach
- Montgomery, D. C., Peck, E. A., & Vining, G. G. (2012). Introduction to Linear Regression Analysis
Python 库文档
相关论文
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning
13. 勘探数据问题排查与调试
测井数据常见问题
Q1: 模型 R² 较低怎么办?
A: 可能原因与解决方案:
- 缺少重要特征 → 增加更多特征或交互项
- 线性关系不强 → 尝试非线性模型(树模型、神经网络)
- 数据质量差 → 检查异常值、缺失值
- 目标变量有较大噪声 → 接受 R² 较低的现实
Q2: 梯度下降不收敛?
A: 检查与调整:
# 降低学习率
learning_rate = 0.000001 # 减小 10 倍
# 增加迭代次数
n_iterations = 10000
# 注意:数据已经过归一化预处理,无需再次标准化
# 以下代码仅作演示用途
# from sklearn.preprocessing import StandardScaler
# scaler = StandardScaler()
# X_train_scaled = scaler.fit_transform(X_train)
Q3: 模型在测试集上效果差?
A: 可能过拟合:
# 增加正则化系数
regularization = l2_regularization(alpha=1.0) # 从 0.5 增加到 1.0
# 使用交叉验证选择超参数
from sklearn.model_selection import cross_val_score
for alpha in [0.1, 0.5, 1.0, 2.0]:
model = LinearRegressionGD(regularization=l2_regularization(alpha))
scores = cross_val_score(model, X_train, y_train, cv=5)
print(f"alpha={alpha}: CV R² = {scores.mean():.4f}")
作者:地球物理数据科学团队
更新日期:2026年2月9日
版本:1.0
应用领域:油气勘探测井数据分析

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献63条内容
已为社区贡献63条内容

所有评论(0)